最新手把手教你将面板数据导入eviews资料
最新手把手教你将面板数据导入eviews资料

1)下图是面板数据。
BJ表示北京的意思,CONS表示变量“消费”,INC表示变量“收入”。
研究的是5个城市,1994年至1999年的消费与收入。
2)打开软件eviews6.0,依次打开:File-new-workfile,最后应该如图所示那样。
图中“Number of cross sections:”填写样本数量,这里指BJ、TJ等5个样本,
3)点击“OK”后应该如下图所示
4)依次打开:Proc-import-read text-lotus-excel,打开EXCEL面板数据的文件名,弹出一个菜单,填写如下图所示:c2是数据开始的地方,中间方框里填写变量名:CONS和INC;
5)点击“OK”后如下图所示。
此时,已经成功将面板数据导入eviews,
6)检验是否正确,可双击上图中cons,结果如下图,和EXCEL面板数据一样。
7)如果对你有帮助,给点鼓励啊。
动态面板数据与Eviews操作

动态面板数据与Eviews操作面板数据与Eviews 操作指南新浪微博:数说工作室一、面板数据简介二、静态面板数据及Eviews 实现(1) 静态面板数据简介(2) EVIEWS操作三、动态面板数据及Eviews 实现(1)动态面板数据简介(2)Eviews 操作一、面板数据简介信息技术的发展使得数据越来越膨胀,传统的截面数据和时间序列已经不能全面刻画经济的演变,在大数据背景下,同时分析比较横截面观察值和时间序列观察值的需求越来越大。
面板数据就是指既含有截面又含有时间序列的数据,分析比较这种数据的模型就是面板数据模型。
相对于一般的回归模型,面板数据模型不仅能够更好的识别和度量单纯时间序列模型和单纯横截面数据模型所不能发现的影响因素, 而且可以克服多重共线性的困扰,能够提供更多的信息、更多的变化、更高的自由度和更高的估计效率,减少共线性。
因此,面板数据可以更准确地刻画更为复杂的经济行为,具有更好的理论价值和应用价值。
按照模型中是否含有滞后项,又分为静态面板数据和动态面板数据,本指南将分别简介原理和Eviews 操作方法。
二、静态面板数据及Eviews 实现(1) 静态面板数据简介一般的静态面板数据模型的一般形式如下:yyiiii=CC+bbxxiiii+vviiii, ii=11, …NN, ii=11, …, TT (1)标,T 表示时间序列的长度。
面板数据由于同时含有了多个横截面数据,有时需要考虑不同横截面个体存在的特殊效应,其误差项被设定为:vviiii=ααii+eeiiii (2)其中αi 代表个体效应,反映了不同个体之间的差别。
当个体效应为固定常数时,式(1)为固定效应模型,此时每个个体截面都有不同的截距项α1、α2... αn ,即其分布式与X it 是有关的,反映了该个体的固定其中C 为截距,v it 为误差项,i 为截面下标,N 表示截面的个数,t 为时间下效应,因此固定效应模型又称为相关效应模型,严格说来,这个名字更加准确。
面板数据的联立方程模型在eviews中估计的详细图解
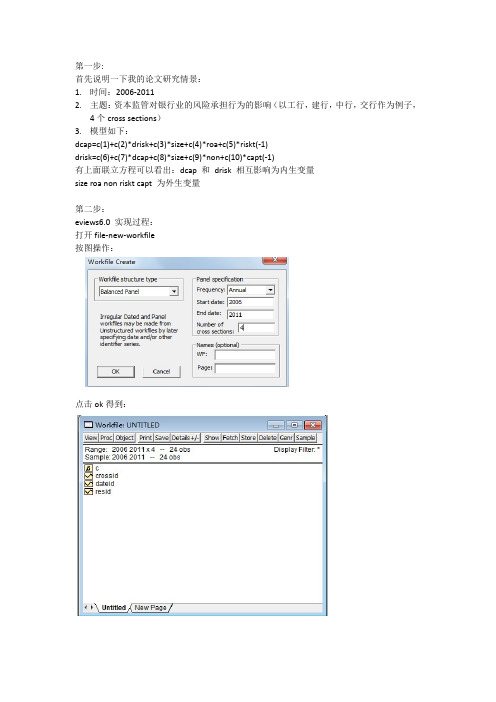
第一步:首先说明一下我的论文研究情景:1.时间:2006-20112.主题:资本监管对银行业的风险承担行为的影响(以工行,建行,中行,交行作为例子,4个cross sections)3.模型如下:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)有上面联立方程可以看出:dcap 和drisk 相互影响为内生变量size roa non riskt capt 为外生变量第二步:eviews6.0 实现过程:打开file-new-workfile按图操作:点击ok得到:点击object-new objectType选pool,ok:跳出的横框:Cross Section Identifiers 填入数据变量名称:(这是纵轴的)GSYHJSYHZGYHJTYH(前面提及的四大银行)然后点view-spreadsheet(stacked data)series list小框输入(这是横轴的变量名称)dcap drisk size roa non riskt capt点击edit+/- 手动输入数据或用import导入数据或粘贴复制进去也行:此时点object-new object,这次type选择system 用以联立方程分析:在system框内输入联立方程和工具变量:dcap=c(1)+c(2)*drisk+c(3)*size+c(4)*roa+c(5)*riskt(-1)drisk=c(6)+c(7)*dcap+c(8)*size+c(9)*non+c(10)*capt(-1)inst dcap drisk size roa non riskt(-1) capt(-1)点右上方的estimate,method选择TSLS(两阶段最小二乘估计):整个过程就是先建立workfile再建立panel data最后建立联立方程systemTSLS估计即可。
动态面板数据与Eviews操作

面板数据与Eviews操作指南新浪微博:数说工作室一、面板数据简介二、静态面板数据及Eviews实现(1) 静态面板数据简介(2) EVIEWS操作三、动态面板数据及Eviews实现(1)动态面板数据简介(2)Eviews操作一、面板数据简介信息技术的发展使得数据越来越膨胀,传统的截面数据和时间序列已经不能全面刻画经济的演变,在大数据背景下,同时分析比较横截面观察值和时间序列观察值的需求越来越大。
面板数据就是指既含有截面又含有时间序列的数据,分析比较这种数据的模型就是面板数据模型。
相对于一般的回归模型,面板数据模型不仅能够更好的识别和度量单纯时间序列模型和单纯横截面数据模型所不能发现的影响因素,而且可以克服多重共线性的困扰,能够提供更多的信息、更多的变化、更高的自由度和更高的估计效率,减少共线性。
因此,面板数据可以更准确地刻画更为复杂的经济行为,具有更好的理论价值和应用价值。
按照模型中是否含有滞后项,又分为静态面板数据和动态面板数据,本指南将分别简介原理和Eviews操作方法。
二、静态面板数据及Eviews实现(1) 静态面板数据简介一般的静态面板数据模型的一般形式如下:yy ii ii=CC+bbxx ii ii+vv ii ii,ii=11,…NN,ii=11,…,TT (1)其中C为截距,v it为误差项,i为截面下标,N表示截面的个数,t为时间下标,T表示时间序列的长度。
面板数据由于同时含有了多个横截面数据,有时需要考虑不同横截面个体存在的特殊效应,其误差项被设定为:vv ii ii=ααii+ee ii ii(2)其中αi代表个体效应,反映了不同个体之间的差别。
当个体效应为固定常数时,式(1)为固定效应模型,此时每个个体截面都有不同的截距项α1、α2...αn,即其分布式与X it是有关的,反映了该个体的固定效应,因此固定效应模型又称为相关效应模型,严格说来,这个名字更加准确。
固定效应模型的形式为:yy ii ii=CC+bbxx ii ii+ααii+vv ii ii,ii=11,…NN,ii=11,…,TT (3) 用矩阵表示为:1111222210...001...0............00...000...1n N n n y x e y x e y x e ααβα =++(4) 即, Y=D α+x β+e (5)当个体效应αi 为随机变量时,式(5)为随机效应模型,此时其分布与X it 是无关的,因此随机效应相应又称为非相关效应模型,随机效应模型的形式为: yy ii ii =CC +bbxx ii ii +ααii +vv ii ii ,ii =11,…NN ,ii =11,…,TT (6)对于这两种模型,最长采用的估计方法为虚拟变量最小二乘法和广义最小二乘法。
使用Eviews进行面板数据操作(有详图,包括Hausman检验,单位根检验)

每个个体有共
同的参数 bi
bi 随个体不
同而发生
变
变化
参
数
bi 随个体不 同而发生
模 型
变化
下面为个体固定效应的结果。 点击view——representation可以显示具体的回归方程式。
2. 面板数据的检验
① Hausman检验(要在随机效应结果窗口中进行) 对数据进行随机效应模型估计,在估计结果窗口点击view——Fixed/Random Effects testing——Correlated Random Effect-Hausman Test(6.0以上的 版本才可以)
⑤ 在打开的数据组中点击view——graph——scatter——simple scatter, 便可得到不同时间的散点图。
⑥ 同理,按ctrl键,分别选择ip_i, ip_ah,I p_bj, ip_hb…便可得到不同个体 的散点图。
由于是用同一组数据画出的图形,所以虽然采用的 是不同的方法,但是绘出的两个图形一样。
在估计结果中点击proc——Make Model可以出现估计结果的联立方 程形式,进一步点击Solve键可以 在弹出的对话框中进行动态和静态 预测。
在估计结果或原始的面包数据窗口中点击view——unit root test
这里默认为 Schwarz检 验,因为在 小样本情况 下Schwarz 检验效果最 好。
注意:只有在随机效应估计窗口中才能 进行Hausman检验,只有在固定效应估 计窗口中才能进行似然比检验
Hausman检验的原假设是个体效 应与回归变量无关,应建立随机效 应模型,因此当Hausman值较大, 其对应的P值远小于0.05时,拒绝
详细的EVIEWS面板数据分析操作

详细的EVIEWS面板数据分析操作引言EVIEWS是一款专业的经济统计软件,广泛应用于经济学和金融领域的数据分析和建模。
EVIEWS提供了丰富的面板数据分析功能,可以帮助用户进行面板数据的处理、描述统计、回归分析等操作。
本文将详细介绍EVIEWS中面板数据分析的操作流程和常用功能。
EVIEWS面板数据的导入首先,我们需要将面板数据导入到EVIEWS中进行分析。
EVIEWS支持多种数据格式的导入,包括Excel、CSV、数据库等。
在导入面板数据时,需要保证数据具有正确的格式,例如面板数据应包含个体(cross-sectional)和时间(time-series)的维度,且面板数据的变量应按照一定的顺序排列。
在导入面板数据后,我们可以利用EVIEWS提供的数据操作命令对数据进行处理和调整。
例如,可以通过group命令将数据按照个体或时间进行分组,通过sort命令对数据进行排序,以便后续的面板数据分析。
面板数据的描述统计分析在面板数据导入并处理完毕后,我们可以进行面板数据的描述统计分析。
EVIEWS提供了丰富的统计功能,可以计算面板数据的平均值、标准差、相关系数等指标。
下面介绍几个常用的描述统计功能:1.summary命令:该命令可以计算面板数据每个变量的平均值、标准差、最大值、最小值等统计指标,并输出到EVIEWS的结果窗口中。
2.correlation命令:该命令可以计算面板数据各变量之间的相关系数矩阵,并输出到结果窗口中。
3.tabulate命令:该命令可以对面板数据进行交叉分组统计,例如计算变量A在变量B的每个取值下的频数和比例。
通过对面板数据进行描述统计分析,可以初步了解数据的分布特征和变量间的关系,为后续的面板数据分析提供基础。
面板数据的回归分析除了描述统计分析,EVIEWS还提供了面板数据的回归分析功能。
通过面板数据回归分析,可以探究变量间的因果关系和影响程度。
下面介绍两个常用的回归分析命令:1.panel least squares(PLS)命令:该命令可以进行面板数据的最小二乘回归分析。
eviews处理面板数据操作步骤(特别好)
File/New/ Workfile Workfile structure type : Balanced Panel
Start date 1935 End date 1954 Number of cross 1 OK Cross Section Identifiers:_GM _CH _GE _WE _US
.
10
思路一:变量之间是非同阶单整 :序列变换
◎变量之间是非同阶单整的指即面板数据中有些序列平稳而有些序列不平稳,
此时不能进行协整检验与直接对原序列进行回归。
◎对序列进行差分或取对数使之变成同阶序列
若变换序列后均为平稳序列可用变换后的序列直接进行回归
思路二 若变换序列后均为同阶非平稳序列,则请点
.
若拒绝H1 ,则模型为变参数模型(模型一)。 构建统计量:请点F统计量
.
26
假设检验的 F 统计量的计算方法
构建变参数模型得残差平方和S1 并考虑其自由度 请点
构建变截距模型得残差平方和S2并考虑其自由度 请点
构建不变参数模型得残差平方和S3并考虑其自由度 请点
计算 F2 统计量
F 2 ( S 3 S 1 S ( 1 N ) / N [ N T ( 1 k ( ) k 1 ) ( 1 ) ) ~ ] F [N ( 1 )k ( 1 )N , ( T k 1 )]
第十章 Panel Data模型
第一步 录入数据
第二步 分析数据的平稳性(单位根检验)
第三步 平稳性检验后分析路径选择
第四步 协整检验`
第五步 回归模型
.
1
第一步 录入数据
一 请点 实例数据 二 请点 录入数据软件操作
计量经济学eviews操作步骤
计量经济学eviews操作步骤嘿,朋友们!今天咱就来聊聊计量经济学 eviews 的操作步骤。
这玩意儿啊,就像是打开经济学奥秘大门的一把钥匙呢!
首先,你得把 eviews 这个软件给装上吧。
就跟你要出门得先穿好鞋一样,这可是基础中的基础呀。
装好了之后,打开软件,那界面就展现在你眼前啦。
就好像进入了一个神秘的数字世界。
接下来,你得把你要用的数据给弄进去呀。
这就好比做饭得先有食材呀,没数据你可玩不转呢。
把数据整整齐齐地放进去,就跟给它们排好队似的。
然后呢,就是各种分析啦。
什么回归分析呀,什么统计检验呀。
这就像给数据做各种体检,看看它们是不是健康,有没有啥问题。
你得仔细盯着那些结果,就像医生看检查报告一样认真。
比如说回归分析吧,你得选好自变量和因变量,就像给它们配对似的。
然后看着软件给你算出一堆数字和图表,你得能看懂呀,这可需要点本事呢。
还有啊,统计检验也很重要呢。
就像给数据做质量检测,看看合不合格。
要是不合格,那你就得重新琢磨琢磨啦。
在操作的过程中,可别马虎呀!就跟走路一样,一步一步都得走稳了。
要是不小心弄错了,那可就麻烦啦。
哎呀,这计量经济学 eviews 操作步骤其实说起来也不难,但就是得细心、耐心。
你想想,要是你盖房子,那每一块砖不都得放好呀,这eviews 操作也是一样的道理。
总之呢,多练习,多琢磨,你肯定能掌握好这门技术。
到时候,你
就能在经济学的世界里畅游啦,就像鱼儿在大海里自由自在地游一样!加油吧,朋友们!相信你们一定可以的!。
eviews使用指南与案例
eviews使用指南与案例EViews是一款经济统计软件,广泛应用于经济学、金融学等领域的数据分析和建模工作。
本文将为大家介绍EViews的使用指南和一些实际案例,帮助读者更好地了解和应用EViews。
一、EViews的使用指南1. EViews的安装和启动:首先,用户需要下载并安装EViews软件。
安装完成后,双击桌面上的EViews图标即可启动软件。
2. 数据导入和处理:EViews支持导入多种数据格式,如Excel、CSV等。
用户可以使用“File”菜单中的“Import”选项将数据导入EViews中,并进行必要的数据清洗和处理。
3. 数据探索和描述统计分析:在导入数据后,用户可以使用EViews提供的数据探索功能进行数据分析,包括数据的描述统计分析、数据可视化等。
4. 模型建立和估计:EViews提供了多种经济学模型的建立和估计方法,如回归分析、时间序列分析等。
用户可以通过选择相应的命令和参数来进行模型建立和估计。
5. 模型诊断和检验:在模型建立和估计完成后,用户需要对模型进行诊断和检验。
EViews提供了多种模型诊断和检验的功能,如残差分析、异方差性检验等。
6. 模型预测和模拟:EViews可以基于已建立的模型进行预测和模拟。
用户可以输入新的自变量数据,通过模型预测因变量的值,或者进行模型的蒙特卡洛模拟分析。
7. 结果输出和报告生成:EViews可以将分析结果以表格、图形等形式输出,并支持生成报告和文档。
用户可以选择相应的输出选项和格式,方便结果的展示和分享。
二、EViews的应用案例1. 时间序列分析:使用EViews可以进行时间序列数据的建模和分析。
例如,可以通过ARIMA模型对股票价格进行预测,或者通过VAR模型分析宏观经济变量之间的关系。
2. 经济政策评估:EViews可以用于评估不同经济政策对经济变量的影响。
例如,可以建立一个VAR模型,通过冲击响应分析来评估货币政策对通胀和经济增长的影响。
面板数据eviews应用
高效稳定
03
Eviews在处理大规模数据集时表现出高效稳定的性能,能够快
速得出分析结果。
Eviews软件应用领域
经济学
Eviews在经济学领域的应用非常 广泛,主要用于实证研究和政策 分析,如劳动经济学、发展经济 学等。
金融学
Eviews在金融学领域的应用主要 涉及时间序列分析和回归分析, 如股票价格分析、风险管理等。
感谢您的观看
THANKS
社会学
Eviews在社会学领域的应用主要 涉及面板数据分析,如人口统计 学、社会调查等。
02 面板数据基础知识
面板数据定义
面板数据
面板数据也称为时间序列数据,它同时包含了横截面和时间序列两个维度的信息,能够更全面地反映经济现象的 变化规律。
面板数据的特点
面板数据能够提供更丰富的信息,可以控制不可观测的异质性,并且能够更好地揭示经济现象的动态变化。
根据诊断结果对模型进行调整或优化,如添加或删除变 量、调整模型形式等。
对模型的残差进行自相关检验和异方差检验,以判断模 型的残差是否存在自相关或异方差问题。
对优化后的模型进行重新估计和检验,确保模型的质量 和稳定性。
04 面板数据Eviews应用实例
实例一:混合效应模型分析
总结词
混合效应模型是一种同时考虑固定效应和随机效应的模型,适用于面板数据。
面板数据类型
长面板
长面板是指样本数量相对较小,但每个样本的观测期较长。
短面板
短面板是指样本数量相对较大,但每个样本的观测期较短。
超长面板
超长面板是指样本数量和观测期都较长,通常用于研究长期经济 现象。
面板数据估计方法
固定效应模型
固定效应模型是一种常用的面板数据估计 方法,它通过控制不可观测的异质性来估
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1)下图是面板数据。
BJ表示北京的意思,CONS表示变量“消费”,INC表示变量“收入”。
研究的是5个城市,1994年至1999年的消费与收入。
2)打开软件eviews6.0,依次打开:File-new-workfile,最后应该如图所示那样。
图中“Number of cross sections:”填写样本数量,这里指BJ、TJ等5个样本,
3)点击“OK”后应该如下图所示
4)依次打开:Proc-import-read text-lotus-excel,打开EXCEL面板数据的文件名,弹出一个菜单,填写如下图所示:c2是数据开始的地方,中间方框里填写变量名:CONS和INC;
5)点击“OK”后如下图所示。
此时,已经成功将面板数据导入eviews,
6)检验是否正确,可双击上图中cons,结果如下图,和EXCEL面板数据一样。
7)如果对你有帮助,给点鼓励啊。