计量经济学作业第5章(含答案)
第五章习题讲解计量经济学庞皓

第五章习题答案练习题5.1参考答案(1)因为222()i i Var u X σ=,所以22()i i f X X =,所以取221i iW X =,用2i W 乘给定模型两端,得312322221i i iii i i Y X u X X X X βββ=+++ 上述模型的随机误差项的方差为一固定常数,即22221()()i i i iu Var Var u X X σ==(2)根据加权最小二乘法,可得修正异方差后的参数估计式为***12233ˆˆˆY X X βββ=--()()()()()()()***2****22232322322*2*2**2223223ˆii i i i i i i i i i i i i i i i iW y x W x W y x W x x W x W x W x x β-=-∑∑∑∑∑∑∑()()()()()()()***2****23222222332*2*2**2223223ˆii i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-=-∑∑∑∑∑∑∑其中22232***23222,,i ii ii i iiiW X W X W Y XXYWWW ===∑∑∑∑∑∑******222333i i i i i x X X x X X y Y Y =-=-=-练习题5.2参考答案(注意:数据是竖着看)(1) 模型的估计Dependent Variable: Y Method: Least Squares Date: 05/16/11 Time: 01:14 Sample: 1 60Included observations: 60Variable Coefficient Std. Error t-Statistic Prob. C 9.347522 3.638437 2.569104 0.0128 X 0.6370690.019903 32.00881 0.0000R-squared0.946423 Mean dependent var 119.6667 Adjusted R-squared 0.945500 S.D. dependent var 38.68984 S.E. of regression 9.032255 Akaike info criterion 7.272246 Sum squared resid 4731.735 Schwarz criterion 7.342058 Log likelihood -216.1674 F-statistic 1024.564 Durbin-Watson stat1.790431 Prob(F-statistic)0.000000该模型样本回归估计式的书写形式为:22ˆ9.347522+0.637069t= (2.569104) (32.00881)R =0.946423 R =0.945500 F=1024.564 DW=1.790431i i Y X =(2)模型的检验1.Goldfeld-Quandt 检验。
计量经济学作业第5章(含答案)

计量经济学作业第5章(含答案)第5章习题一、单项选择题1.对于一个含有截距项的计量经济模型,若某定性因素有m个互斥的类型,为将其引入模型中,则需要引入虚拟变量个数为()A. mB. m-1C. m+1D. m-k2.在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。
例如,研究中国城镇居民消费函数时。
1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X的回归关系明显不同。
现以1991年为转折时期,设虚拟变量,数据散点图显示消费函数发生了结构性变化:基本消费部分下降了,边际消费倾向变大了。
则城镇居民线性消费函数的理论方程可以写作()A. B.C. D.3.对于有限分布滞后模型在一定条件下,参数可近似用一个关于的阿尔蒙多项式表示(),其中多项式的阶数m必须满足()A. B. C.D.4.对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数据就会( )A. 增加1个B. 减少1个C. 增加2个D. 减少2个5.经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为()A.异方差问题 B. 多重共线性问题C.序列相关性问题 D. 设定误差问题6.将一年四个季度对因变量的影响引入到模型中(含截距项),则需要引入虚拟变量的个数为()A. 4B. 3C.2 D. 17.若想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比较适合(Y代表消费支出;X代表可支配收入;D2、D3表示虚拟变量)()A. B.C. D.二、多项选择题1.以下变量中可以作为解释变量的有()A. 外生变量B. 滞后内生变量C. 虚拟变量D. 先决变量E. 内生变量2.关于衣着消费支出模型为:,其中Y i 为衣着方面的年度支出;Xi为收入,⎩⎨⎧=女性男性12iD;⎩⎨⎧=大学毕业及以上其他13iD则关于模型中的参数下列说法正确的是()A.表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出(或少支出)差额B.表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消费支出方面多支出(或少支出)差额C.表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以下文凭者在衣着消费支出方面多支出(或少支出)差额D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额E. 表示性别和学历两种属性变量对衣着消费支出的交互影响三、判断题1.通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容量大小有关。
【最新试题库含答案】庞皓计量经济学课后答案第五章

【最新试题库含答案】庞皓计量经济学课后答案第五章庞皓计量经济学课后答案第五章:篇一:计量经济学庞皓第二版第五章答案5.2 (1) 对原模型OLS回归分析结果:Dependent Variable: Y Method: Least Squares Date: 04/01/09Time: 15:44 Sample: 1 60Included observations: 60Variable C XR-squaredAdjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson statCoefficient 9.347522 0.637069Std. Error 3.638437 0.019903t-Statistic 2.569104 32.00881Prob.0.0128 0.0000 119.6667 38.68984 7.272246 7.342058 1024.564 0.0000000.946423 Mean dependent var 0.945500 S.D. dependent var 9.032255 Akaike info criterion 4731.735 Schwarz criterion -216.1674 F-statistic 1.790431 Prob(F-statistic)(2)White检验结果:White Heteroskedasticity Test: F-statistic Obs*R-squaredTest Equation:Dependent Variable: RESID Method: Least Squares Date: 04/01/09Time: 15:45 Sample: 1 60Included observations: 60Variable C X XR-squaredAdjusted R-squared S.E. of regressionCoefficient -10.03614 0.165977 0.001800Std. Error 131.1424 1.619856 0.004587t-Statistic -0.076529 0.102464 0.392469Prob.0.9393 0.9187 0.6962 78.86225 111.1375 12.142856.301373 Probability 10.86401 Probability0.003370 0.0043740.181067 Mean dependent var 0.152332 S.D. dependent var 102.3231 Akaike info criterionSum squared resid Log likelihood Durbin-Watson stat596790.5 Schwarz criterion -361.2856 F-statistic 1.442328 Prob(F-statistic)12.24757 6.301373 0.003370nR2=10.86401, 查表得?20.05(2)=5.99147,nR2 5.99147,所以拒绝原假设,表明模型中随机误差项存在异方差。
计量经济学课后答案第五章 异方差性汇总

第五章课后答案5.1(1)因为22()i i f X X =,所以取221iiW X =,用2i W 乘给定模型两端,得 312322221i i ii i i i Y X u X X X X βββ=+++ 上述模型的随机误差项的方差为一固定常数,即22221()()i i i iu Var Var u X X σ==(2)根据加权最小二乘法,可得修正异方差后的参数估计式为***12233ˆˆˆY X X βββ=-- ()()()()()()()***2****22232322322*2*2**2223223ˆi i i i i i i i i i i i i i i i i iW y x W x W y x W x x W x W x W x x β-=-∑∑∑∑∑∑∑()()()()()()()***2****23222222332*2*2**2223223ˆii ii i i iii i i ii i i i i iW y x W x W y x W x x Wx W x W x x β-=-∑∑∑∑∑∑∑其中22232***23222,,iii i i i iiiW XW X W Y X X Y WWW ===∑∑∑∑∑∑******222333i i i i i x X X x X X y Y Y=-=-=- 5.2(1)2222211111 ln()ln()ln(1)1 u ln()1Y X Y X Yu u X X X u ββββββββββ--==+≈=-∴=+[ln()]0()[ln()1][ln()]11E u E E u E u μ=∴=+=+=又(2)[ln()]ln ln 0 1 ()11i i iiP P i i i i P P i i E P E μμμμμμμ===⇒====∑∏∏∑∏∏不能推导出所以E 1μ()=时,不一定有E 0μ(ln )= (3) 对方程进行差分得:1)i i βμμ--i i-12i i-1lnY -lnY =(lnX -X )+(ln ln 则有:1)]0i i μμ--=E[(ln ln5.3(1)该模型样本回归估计式的书写形式为:Y = 11.44213599 + 0.6267829962*X (3.629253) (0.019872)t= 3.152752 31.5409720.944911R =20.943961R = S.E.=9.158900 DW=1.597946 F=994.8326(2)首先,用Goldfeld-Quandt 法进行检验。
《计量经济学》第五章习题及参考答案.doc

第五章经典单方程计量经济学模型:专门问题一、内容提要本章主要讨论了经典单方程回归模型的几个专门题。
第一个专题是虚拟解释变量问题。
虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。
本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。
在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。
第二个专题是滞后变量问题。
滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。
本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。
如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。
而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS 法进行估计。
由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。
第三个专题是模型设定偏误问题。
主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。
模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。
在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。
在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。
计量经济学(庞浩)第五章练习题参考解答说课讲解

第五章练习题参考解答练习题5.1 设消费函数为i i i i u X X Y +++=33221βββ式中,i Y 为消费支出;i X 2为个人可支配收入;i X 3为个人的流动资产;i u 为随机误差项,并且222)(,0)(i i i X u Var u E σ==(其中2σ为常数)。
试回答以下问题:(1)选用适当的变换修正异方差,要求写出变换过程;(2)写出修正异方差后的参数估计量的表达式。
5.2 根据本章第四节的对数变换,我们知道对变量取对数通常能降低异方差性,但须对这种模型的随机误差项的性质给予足够的关注。
例如,设模型为u X Y 21ββ=,对该模型中的变量取对数后得如下形式u X Y ln ln ln ln 21++=ββ(1)如果u ln 要有零期望值,u 的分布应该是什么? (2)如果1)(=u E ,会不会0)(ln =u E ?为什么? (3)如果)(ln u E 不为零,怎样才能使它等于零?5.3 由表中给出消费Y 与收入X 的数据,试根据所给数据资料完成以下问题: (1)估计回归模型u X Y ++=21ββ中的未知参数1β和2β,并写出样本回归模型的书写格式;(2)试用Goldfeld-Quandt 法和White 法检验模型的异方差性; (3)选用合适的方法修正异方差。
Y X Y X Y X 55 80 152 220 95 140 65 100 144 210 108 145 70 85 175 245 113 150 801101802601101607912013519012516584115140205115180981301782651301859514019127013519090125137230120200759018925014020574105558014021011016070851522201131507590140225125165651001372301081457410514524011518080110175245140225841151892501202007912018026014524090125178265130185981301912705.4由表中给出1985年我国北方几个省市农业总产值,农用化肥量、农用水利、农业劳动力、每日生产性固定生产原值以及农机动力数据,要求:(1)试建立我国北方地区农业产出线性模型;(2)选用适当的方法检验模型中是否存在异方差;(3)如果存在异方差,采用适当的方法加以修正。
计量经济学 第五章习题答案
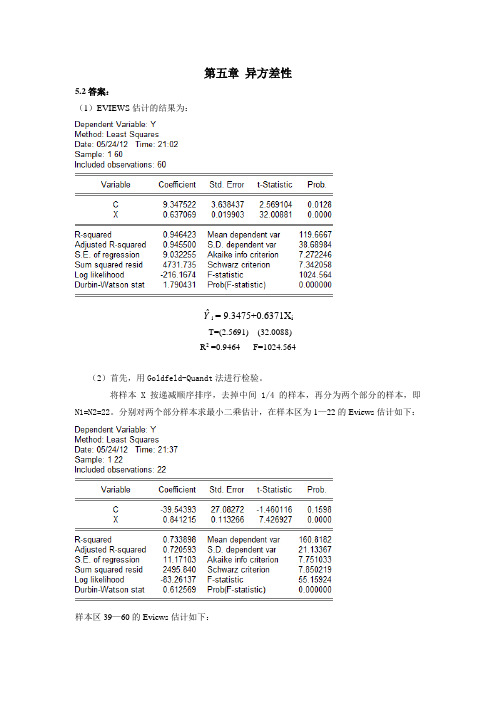
第五章异方差性5.2答案:(1)EVIEWS估计的结果为:Yˆi= 9.3475+0.6371X iT=(2.5691) (32.0088)R2 =0.9464 F=1024.564(2)首先,用Goldfeld-Quandt法进行检验。
将样本X按递减顺序排序,去掉中间1/4的样本,再分为两个部分的样本,即N1=N2=22。
分别对两个部分样本求最小二乘估计,在样本区为1—22的Eviews估计如下:样本区39—60的Eviews估计如下:得到两个部分各自的残差平方和,即∑e 12 =2495.840∑e 22 =603.0148求F 统计量为: F=∑∑e e 2221=2495.840/603.0148=4.1390给定α=0.05,查F 分布表,得临界值为F 0.05=(20,20)=2.12.比较临界值与F 统计量值,有F =4.1390>F 0.05=(20,20)=2.12,说明该模型的随机误差项存在异方差。
其次,用White 法进行检验结果如下:给定α=0.05,在自由度为2下查卡方分布表,得χ2=5.9915。
比较临界值与卡方统计量值,即nR2=10.8640>χ2=5.9915,同样说明模型中的随机误差项存在异方差。
(2)用权数W1=1/X,作加权最小二乘估计,得如下结果用White法进行检验得如下结果:F-statistic 3.138491 Probability 0.050925Obs*R-squared 5.951910 Probability 0.050999。
比较临界值与卡方统计量值,即nR2=5.9519<χ2=5.9915,说明加权后的模型中的随机误差项不存在异方差。
其估计的结果为:Yˆi= 10.3705+0.6309X iT=(3.9436) (34.0467)R2 =0.21144 F=1159.176 DW=0.95855.3答案:(1)EVIEWS估计结果:Yˆi= 179.1916+0.7195X iT=(0.808709) (15.74411)R2 =0.895260 F=247.8769 DW=1.461684 (2)利用White方法检验异方差,则White检验结果见下表:由上述结果可知,该模型存在异方差。
计量经济学第五六章作业

各地区农村居民家庭人均纯收入与家庭人均生活消费支出的数据(单位:元)(1)试根据上述数据建立2007年我国农村居民家庭人均消费支出对人均纯收入的线性回归模型。
(2)选用适当方法检验模型是否在异方差,并说明存在异方差的理由。
(3)如果存在异方差,用适当方法加以修正。
答:散点图线性回归分析图由图建立样本回归函数X̂=+R2= F=由图形法可看出残差平方随x i的变动呈增大趋势,但还需进一步检验.White检验由上述结果可知,该模型存在异方差,理由是从数据可看出一是截面数据,看出各省市经济发展不平衡3)用加权最小二乘法修正,选用权数w1=1x ,w2=x,w3=1x2.则散点图回归结果Goldfield-quanadt检验F==所以模型存在异方差t检验,F检验显著y î=+x it=()()R2=,DW= ,F=剔除价格变动因素后的回归结果如下下表是北京市连续19年城镇居民家庭人均收入与人均支出的数据。
表略(1)建立居民收入—消费函数;残差图2ˆ79.9300.690(6.38)(12.399)(0.013)(6.446)(53.621)0.9940.575t t Y X Se t R DW =+====(2)检验模型中存在的问题,并采取适当的补救措施预以处理;(2)DW =,取%5=α,查DW 上下界18.1,40.1,18.1<==DW d d U L ,说明误差项存在正自相关(3)对模型结果进行经济解释。
采用科克伦奥科特迭代法广义差分因此,原回归模型应为t t X Y 669.0985.104+=其经济意义为:北京市人均实际收入增加1元时,平均说来人均实际生活消费支出将增加元。
.为了探讨股票市场繁荣程度与宏观经济运行情况之间的关系,取股票价格指数与GDP 开展探讨,表为美国1981-2006年股票价格指数(y )和国内生产总值GDP (x )的数据。
估计回归模型y_t=β_1+β_2 X_t+µ_t检验(1)中模型是否存在自相关,若存在,用广义差分法消除自相关最小二乘法估计回归模型为Y t̂=3002527+X tSe=t=R2= F= DW= (2)LM=T R2=26*=P值为t检验和F检验不可信。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第5章习题
一、单项选择题
1.对于一个含有截距项的计量经济模型,若某定性因素有m个互斥的类型,为将其引入模型中,则需要引入虚拟变量个数为()
A. m
B. m-1
C. m+1
D. m-k
2.在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。
例如,研究中国城镇居民消费函数时。
1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X的回归关系明显不同。
现以1991年为转折时期,设虚拟变
量,数据散点图显示消费函数发生了结构性变化:基本消费部分下降了,边际消费倾向变大了。
则城镇居民线性消费函数的理论方程可以写作()
A. B.
C. D. 3.对于有限分布滞后模型
在一定条件下,参数可近似用一个关于的阿尔蒙多项式表示(),其中多项式的阶数m必须满足()
A. B. C.
D.
4.对于有限分布滞后模型,解释变量的滞后长度每增加一期,可利用的样本数据就会( )
A. 增加1个
B. 减少1个
C. 增加2个
D. 减少2个
5.经济变量的时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为()
A.异方差问题 B. 多重共线性问题
C.序列相关性问题 D. 设定误差问题
6.将一年四个季度对因变量的影响引入到模型中(含截距项),则需要引入虚拟变量的个数为()
A. 4
B. 3
C.
2 D. 1
7.若想考察某两个地区的平均消费水平是否存在显著差异,则下列那个模型比
较适合(Y代表消费支出;X代表可支配收入;D
2、D
3
表示虚拟变量)()
A. B.
C. D.
二、多项选择题
1.以下变量中可以作为解释变量的有()
A. 外生变量
B. 滞后内生变量
C. 虚拟变量
D. 先决变量
E. 内生变量
2.关于衣着消费支出模型为:,其中
Y i 为衣着方面的年度支出;X
i
为收入,
⎩
⎨
⎧
=女性
男性
1
2i
D;
⎩
⎨
⎧
=大学毕业及以上
其他
1
3i
D
则关于模型中的参数下列说法正确的是()
A.表示在保持其他条件不变时,女性比男性在衣着消费支出方面多支出(或少支出)差额
B.表示在保持其他条件不变时,大学毕业及以上比其他学历者在衣着消费支出方面多支出(或少支出)差额
C.表示在保持其他条件不变时,女性大学及以上文凭者比男性和大学以下文凭者在衣着消费支出方面多支出(或少支出)差额
D. 表示在保持其他条件不变时,女性比男性大学以下文凭者在衣着消费支出方面多支出(或少支出)差额
E. 表示性别和学历两种属性变量对衣着消费支出的交互影响
三、判断题
1.通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容量大小有关。
2.虚拟变量的取值只能取0或1。
3.通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与模型有无截距项无关。
四、问答题
1.Sen和Srivastava(1971)在研究贫富国之间期望寿命的差异时,利用101个国家的数据,建立了如下的回归模型(括号内的数值为对应参数估计值t值):
其中:X是以美元计的人均收入;Y是以年计的期望寿命。
Sen和Srivastava 认为人均收入的临界值为1097美元(),若人均收入超过1097美元,则被认定为富国;若人均收入低于1097美元,被认定为贫穷国。
(1)解释这些计算结果。
(2)回归方程中引入的原因是什么?如何解释这个回归解释变量?
(3)如何对贫穷国进行回归?又如何对富国进行回归?
2.当模型中出现随机解释变量时,最小二乘估计量具有什么特征
五、计算题
已知某企业工业增加值Q(万元,当年价),职工人数L(人),固定资产净值+流动资金净值K(万元),数据见下表。
年份Q L K
1980 157 232 194
1981 158 290 179
1982 153 306 223
1983 171 295 229
1984 210 308 403
1985 279 561 756
1986 347 485 1225
1987 428 538 1748
1988 871 826 2165
1989 1071 541 2801
1990 1382 550 3120
1991 1535 959 3732
1992 1887 1453 4802
1993 2585 1460 5655
1994 4974 1960 7396
1995 9840 2613 11919
(1)建立C-D函数,用各种统计量检验估计结果。
(2)解释各参数估计值的经济意义,并说明此企业的规模效益如何。
参考答案
一、单项选择题
1.B 2.D 3.A 4.B 5.B 6.B 7.D
二、多项选择题
1.ABCDE (参见第六章P190)2.ABCE
三、判断题
1.错误。
引入虚拟变量的个数与样本容量大小无关,与变量属性,模型有无截距项有关。
2.错误。
虚拟变量的取值是人为设定的,也可以取其它值。
3.错误。
模型有截距项时,如果被考察的定性因素有m个相互排斥属性,则模型中引入m-1个虚拟变量,否则会陷入“虚拟变量陷阱”;模型无截距项时,若被考察的定性因素有m个相互排斥属性,可以引入m个虚拟变量,这时不会出现多重共线性。
四、问答题
1.答:(1)由,也就是说,人均收入每增加2.7183倍,平均意义上各国的期望寿命会增加9.39岁。
若当为富国时,,则平均意义上,富国的人均收入每增加2.7183倍,其期望寿命就会减少3.36岁,但其截距项的水平会增加23.52,达到21.12的水平。
但从统计检验结果看,对数人均收入lnX 对期望寿命Y的影响并不显著。
方程的拟合情况良好,可进一步进行多重共线性等其他计量经济学的检验。
(2)若代表富国,则引入的原因是想从截距和斜率两个方面考证富国的影响,其中,富国的截距为,斜率为
,因此,当富国的人均收入每增加2.7183倍,其期望寿命会增加6.03岁。
(3)对于贫穷国,设定,则引入的虚拟解释变量的形式为;对于富国,回归模型形式不变。
2.答:(1)当随机解释变量X 与随机项u 时相互独立的时候,最小二乘估计量仍然是无偏的。
(2)如果随机解释变量X 与随机项u 既不独立也不相关时,最小二乘估计量是有偏的,但是一致估计量。
(3)如果随机解释变量X 与随机项u 具有高度的相关关系,最小二乘估计量是有偏的,非一致的。
五、计算题
答:(1)设生产计量模型为
1
2
U
Q AL K e ββ=,其中U 为随机误差项,为了估计模型,两边取对数,得
12ln ln ln ln Q A L K u ββ=+++
令012ln ,ln ,ln ,ln Y Q A L X K X β====,得一般线性计量模型 01122Y X X u βββ=+++
采用OLS 方法进行估计(Eviews 输出结果见下表),
得估计模型
12
22ˆ 2.32810.79610.5151( 2.3479)
(2.5885)
(3.1735)
0.9490,0.9411,120.9152Y X X R R F =-++-===
从各参数估计值的t 统计量值,可以看出,在5%的水平上均显著的不为0。
从F
检验可以看出,总体回归方程是显著的。
2R 和2
R 的值很高,估计的回归方程与样本数据拟合的较好。
所以这个企业的C -D 生产函数为
0.79610.5151ˆ0.0975L Q K =
(2)1β为产出的劳动弹性,即产出的劳动弹性为0.7961;2β为产出的资本弹性,。