编译原理作业集-第三章-修订版
蒋立源编译原理 第三版 第三章 习题与答案(修改后)

第3章习题3-1 试构造一右线性文法,使得它与如下得文法等价S→AB A→UT U→aU|a D→bT|b B→cB|c 并根据所得得右线性文法,构造出相应得状态转换图。
3-2 对于如题图3-2所示得状态转换图(1) 写出相应得右线性文法;(2) 指出它接受得最短输入串;(3) 任意列出它接受得另外4个输入串;(4) 任意列出它拒绝接受得4个输入串。
3-3 对于如下得状态转换矩阵:(1) 分别画出相应得状态转换图;(2) 写出相应得3型文法;(3) 用自然语言描述它们所识别得输入串得特征。
3-4 将如下得NFA确定化与最小化:3-5 将如题图3-5所示得具有ε动作得NFA确定化。
题图3-5 具有ε动作得NFA3-6 设有文法G[S]:S→aA A→aA|bB B→bB|cC|c C→cC|c 试用正规式描述它所产生得语言。
3-7 分别构造与如下正规式相应得NFA。
(1) ((0* |1)(1* 0))*(2) b|a(aa*b)*b3-8 构造与正规式(a|b)*(aa|bb)(a|b)*相应得DFA。
第3章习题答案3-1 解:根据文法知其产生得语言就是:L[G]={a m b n c i| m,n,i≧1}可以构造与原文法等价得右线性文法:S→aA A→aA|bB B→bB|cC|c C→cC|c 其状态转换图如下:3-2 解:(1) 其对应得右线性文法就是G[A]:A →0D B→0A|1C C→0A|1F|1D→0B|1C E→0B|1C F→1A|0E|0(2) 最短输入串为011(3) 任意接受得四个输入串为:0110,0011,000011,00110(4) 任意拒绝接受得输入串为:0111,1011,1100,10013-3 解:(1) 相应得状态转换图为:(2) 相应得3型文法为:(ⅰ) S→aA|bS A→aA|bB|b B→aB|bB|a|b(ⅱ) S→aA|bB|a A→bA|aC|a|b B→aB|bC|b C→aC|bC|a|b(ⅲ) S→aA|bB|b A→aB|bA|a B→aB|bB|a|b(ⅳ) S→bS|aA A→aC|bB|a B→aB|bC|b C→aC|bC|a|b(3) 用自然语言描述得输入串得特征为:(ⅰ) 以任意个(包括0个)b开头,中间有任意个(大于1)a,跟一个b,还可以有一个由a,b组成得任意字符串。
奥鹏14秋《编译原理》作业3满分答案

14秋《编译原理》作业3
一,多选题
1. 四元式是一种比较普遍采用的中间代码形式,它的四个组成成分是()。
A. 算法op
B. 第一运算对象ARG1
C. 第二运算对象ARG2
D. 运算结果RESULT
?
正确答案:ABCD
2. 编译中的语义处理是指()两个功能。
A. 审查每个语法结构的静态语义
B. 生成程序的一种中间表示形式(中间代码),或者生成实际的目标代码
C. 分析栈
D. 向前搜索符集合
?
正确答案:AB
3. 运行时的存储区常常划分为:()
A. 目标区
B. 静态数据区
C. 栈区
D. 堆区
?
正确答案:ABCD
4. 一个LR(1) 项目可以看成()两个部分组成。
A. 心
B. 向前搜索符集合
C. 分析表
D. 分析函数
?
正确答案:AB
5. 一个LR分析器由()组成。
A. 驱动程序
B. 分析函数
C. 分析栈
D. 向前搜索符集合
?
正确答案:ABC。
编译原理教程课后习题答案——第三章

第三章语法分析3.1 完成下列选择题:(1) 文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. xnyxn(n≥0)d. x*yx*(2) 如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同(3) 采用自上而下分析,必须。
a. 消除左递 a. 必有ac归b. 消除右递归c. 消除回溯d. 提取公共左因子(4) 设a、b、c是文法的终结符,且满足优先关系ab和bc,则。
b. 必有cac. 必有bad. a~c都不一定成立(5) 在规范归约中,用来刻画可归约串。
a. 直接短语b. 句柄c. 最左素短语d. 素短语(6) 若a为终结符,则A→α·aβ为项目。
a. 归约b. 移进c. 接受d. 待约(7) 若项目集Ik含有A→α·,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时,才采取“A→α·”动作的一定是。
a. LALR文法b. LR(0)文法c. LR(1)文法d. SLR(1)文法(8) 同心集合并有可能产生新的冲突。
a. 归约b. “移进”/“移进”c.“移进”/“归约”d. “归约”/“归约”【解答】(1) c (2) a (3) c (4) d (5) b (6) b (7) d (8) d3.2 令文法G[N]为G[N]: N→D|NDD→0|1|2|3|4|5|6|7|8|9(1) G[N]的语言L(G[N])是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
【解答】(1) G[N]的语言L(G[N])是非负整数。
(2) 最左推导:NNDNDDNDDDDDDD0DDD01DD012D0127NNDDD3D34NNDNDDDDD5DD56D568最右推导:NNDN7ND7N27ND27N127D1270127NNDN4D434NNDN8ND8N68D685683.3 已知文法G[S]为S→aSb|Sb|b,试证明文法G[S]为二义文法。
编译原理第三版课后习题答案解析

目录P36-62P36-72P36-82P36-92P36-102P36-112P64–72P64–83P64–123 P64–144 P81–15P81–26P81–38P133–18 P133–28 P133–310 P134–511 P164–513 P164–713 P217–114 P217–314 P218–415 P218–515 P218–616 P218–716 P219–1217 P270–918P36-6<1>LG ()1是0~9组成的数字串<2>最左推导: 最右推导:P36-7G<S>P36-8文法: 最左推导: 最右推导:语法树:/******************************** *****************/P36-9句子iiiei 有两个语法树:P36-10/************** ***************/P36-11/*************** L1: L2: L3: L4:***************/第三章习题参考答案P64–7<1>101101(|)*最小化:P64–8<1> <2> <3>P64–12<a>aa,b aaaa b b b最小化:a ab ba b <b>已经确定化了,进行最小化 最小化:aP64–14<1> 01 0 <2>:(|εε0 00 YY给状态编号:最小化: 01 1 1 0 0第四章P81–1<1> 按照T,S 的顺序消除左递归 递归子程序: procedure S; beginif sym='a' or sym='^' then abvance else if sym='<' then begin advance;T;if sym='>' then advance; else error; end else error end;procedure T; begin S;'T end;procedure 'T ; beginif sym=',' then beginadvance;S;'Tendend;其中:sym:是输入串指针IP所指的符号advance:是把IP调至下一个输入符号error:是出错诊察程序<2>FIRST<S>={a,^,<}FIRST<T>={a,^,<}FIRST<'T>={,,ε}FOLLOW<S>={>,,,#}FOLLOW<T>={>}FOLLOW<'T>={>}预测分析表是LL<1>文法P81–2文法:<1>FIRST<E>={<,a,b,^}FIRST<E'>={+,ε}FIRST<T>={<,a,b,^}FIRST<T'>={<,a,b,^,ε}FIRST<F>={<,a,b,^}FIRST<F'>={*,ε}FIRST<P>={<,a,b,^}FOLLOW<E>={#,>}FOLLOW<E'>={#,>}FOLLOW<T>={+,>,#}FOLLOW<T'>={+,>,#}FOLLOW<F>={<,a,b,^,+,>,#}FOLLOW<F'>={<,a,b,^,+,>,#}FOLLOW<P>={*,<,a,b,^,+,>,#}<2>考虑下列产生式:FIRST<+E>∩FIRST<ε>={+}∩{ε}=φFIRST<+E>∩FOLLOW<E'>={+}∩{#,>}=φFIRST<T>∩FIRST<ε>={<,a,b,^}∩{ε}=φFIRST<T>∩FOLLOW<T'>={<,a,b,^}∩{+,>,#}=φFIRST<*F'>∩FIRST<ε>={*}∩{ε}=φFIRST<*F'>∩FOLLOW<F'>={*}∩{<,a,b,^,+,>,#}=φFIRST<<E>>∩FIRST<a>∩FIRST<b>∩FIRST<^>=φ所以,该文法式LL<1>文法.<3><4>procedure E;beginif sym='<' or sym='a' or sym='b' or sym='^' then begin T; E' endelse errorendprocedure E';beginif sym='+'then begin advance; E endelse if sym<>'>' and sym<>'#' then error endprocedure T;beginif sym='<' or sym='a' or sym='b' or sym='^' then begin F; T' endelse errorendprocedure T';beginif sym='<' or sym='a' or sym='b' or sym='^' then Telse if sym='*' then errorendprocedure F;beginif sym='<' or sym='a' or sym='b' or sym='^' then begin P; F' endelse errorendprocedure F';beginif sym='*'then begin advance; F' endendprocedure P;beginif sym='a' or sym='b' or sym='^'then advanceelse if sym='<' thenbeginadvance; E;if sym='>' then advanceelse errorendelse errorend;P81–3/***************(1)是,满足三个条件。
蒋立源编译原理第三版第三章习题与答案(修改后)
3-1 试构造一右线性文法,使得它与如下的文法等价 S→AB A → UT U → aU|a D →bT|b B → cB|c
并根据所得的右线性文法,构造出相应的状态转换图。
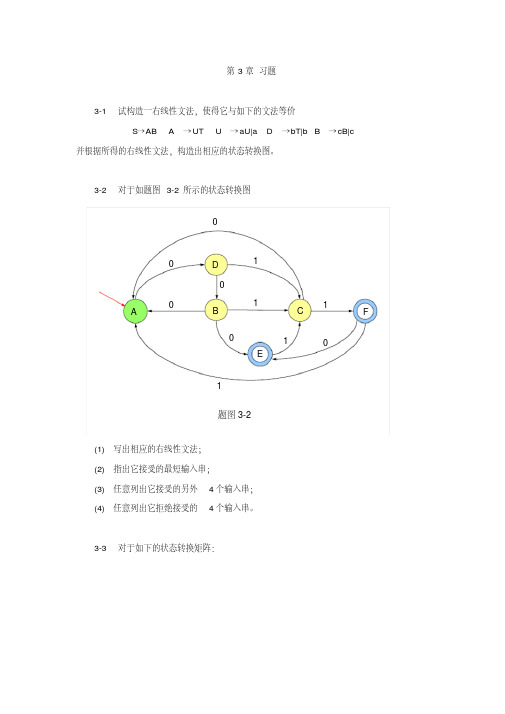
3-2 对于如题图 3-2 所示的状态转换图 0
0 0 A
D
1
0 1
B
C1
F
0
1
0
E
1 题图 3-2
(1) 写出相应的右线性文法; (2) 指出它接受的最短输入串; (3) 任意列出它接受的另外 4 个输入串; (4) 任意列出它拒绝接受的 4 个输入串。
但
{1}
b=
故 1 和 2 可区分,于是便得到下一分划
π1: {1}, {2}, {3}
此时子集已全部分裂,故最小化的过程宣告结束, M′即为状态数最小的 DFA。
(3) 将 NFA M确定化后得 DFA M′,其状态转换矩阵如答案图 3-4-(3) 之 (a) 所示, 给各状态重新命名,即令:
[S]=1, [A]=2, [S,B]=3 且由于 3 的组成中含有 M的终态 B,故 3 为 DFAM′的终态。于是,所构造之 DFAM′的 状态转换矩阵和状态转换图如答案图 3-4-(3) 之(b) 及(c) 所示。
π0:{1,2}, {3}
( ⅱ) 为得到下一分划,考察子集 {1,2} 。因为
{2} b ={3}
但
{1}
b=
故 1 和 2 可区分,于是便得到下一分划
π1: {1}, {2}, {3}
此时子集已全部分裂,故最小化的过程宣告结束, M′即为状态数最小的 DFA。
(4) 将 NFA M确定化后得 DFA M′,其状态转换矩阵如答案图 3-4-(4) 之 (a) 所示, 给各状态重新命名,即令:
蒋立源编译原理第三版第三章习题与答案

第 3 章习题3-1 试构造一右线性文法,使得它与如下的文法等价4AB A f UT U faU|a D fbT|b B fcB|c并根据所得的右线性文法,构造出相应的状态转换图。
3-2 对于如题图3-2 所示的状态转换图(1) 写出相应的右线性文法;(2) 指出它接受的最短输入串;(3) 任意列出它接受的另外 4 个输入串;(4) 任意列出它拒绝接受的 4 个输入串。
3-3 对于如下的状态转换矩阵:(1) 分别画出相应的状态转换图;(2) 写出相应的 3 型文法;(3) 用自然语言描述它们所识别的输入串的特征。
3-4 将如下的NFA确定化和最小化:3-5 将如题图3-5所示的具有£动作的NFA确定化。
题图3-5 具有£动作的NFA试用正规式描述它所产生的语言。
3-7 分别构造与如下正规式相应的 NFA(1) ((0 |1)(1 0)) ⑵ b|a(aa *b)*b3-8 构造与正规式(a|b) *(aa|bb)(a|b)*相应的 第3章习题答案3-1 解:根据文法知其产生的语言是L[G]={am 3n c i| m,n,i 仝 1}可以构造与原文法等价的右线性文法其状态转换图如下:3-2 解:4 aA L aA|bB 4 bB|cC|c C^ cC|cDFAA ^ aA|bB4 bB|cC|cC^ cC|cc4 0A|1C0110,0011,000011,00110Df0B|1CEf0B|1CFf 1A|0E|0(2) 最短输入串为 O11(3) 任意接受的四个输入串为:(1) 其对应的右线性文法是 G[A]:0A|1F|1 (4) 任意拒绝接受的输入串为: 0111,1011,1100,10013-3 解:(1) 相应的状态转换图为:(2) 相应的 3 型文法为: (i ) S f aA|bS AfaA|bB| b Bf aB|bB|a|b(ii) S f aA|bB| AfbA|aC| a|b BfaB|bC| b Cf aC|bC|a|b(iii) S f aA|bB| AfaB|bA| a BfaB|bB|a|b (iv) S f bS|aAAfaC|bB| aBfaB|bC| bCf aC|bC|a|b(3) 用自然语言描述的输入串的特征为:(i )以任意个(包括0个)b 开头,中间有任意个(大于1) a ,跟一个b ,还可以有一个由 a,b 组成的任意字符串。
编译原理第三版课后习题与答案

目录P36-6 (2)P36-7 (2)P36-8 (2)P36-9 (3)P36-10 (3)P36-11 (3)P64–7 (4)P64–8 (5)P64–12 (5)P64–14 (7)P81–1 (8)P81–2 (9)P81–3 (12)P133–1 (12)P133–2 (12)P133–3 (14)P134–5 (15)P164–5 (19)P164–7 (19)P217–1 (19)P217–3 (20)P218–4 (20)P218–5 (21)P218–6 (22)P218–7 (22)P219–12 (22)P270–9 (24)P36-6(1)L G ()1是0~9组成的数字串(2)最左推导:N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒0010120127334556568最右推导:N ND N ND N ND N D N ND N D N ND N ND N D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒77272712712701274434886868568P36-7G(S)O N O D N S O AO A AD N→→→→→1357924680|||||||||||P36-8文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/P36-9句子iiiei 有两个语法树:S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ⇒⇒⇒⇒⇒⇒⇒⇒P36-10/**************)(|)(|S T TTS S →→***************/P36-11/*************** L1:ε||cC C ab aAb A AC S →→→ L2:bcbBc B aA A AB S ||→→→εL3:εε||aBb B aAb A AB S →→→ L4:AB B A A B A S |01|10|→→→ε ***************/第三章习题参考答案P64–7(1)确定化:最小化:{,,,,,},{}{,,,,,}{,,}{,,,,,}{,,,}{,,,,},{},{}{,,,,}{,,}{,,,},{},{},{}{,,,}{,012345601234513501234512460123456012341350123456012310100==== 3012312401234560110112233234012345610101}{,,,}{,,}{,},{,}{},{},{}{,}{}{,}{,}{,}{}{,}{}{},{},{,},{},{},{}=====P64–8(1)01)0|1(*(2))5|0(|)5|0()9|8|7|6|5|4|3|2|1|0)(9|8|7|6|5|4|3|2|1(*(3)******)110|0(01|)110|0(10P64–12(a)确定化:给状态编号:最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}012301101223032330123a ba b ====(b)已经确定化了,进行最小化最小化:{{,}, {,,,}}012345011012423451305234523452410243535353524012435011012424{,}{}{,}{,}{,,,}{,,,}{,,,}{,,,}{,}{,}{,}{,}{,}{,}{,}{,}{{,},{,},{,}}{,}{}{,}{,}{,}a b a b a b a b a b a =============={,}{,}{,}{,}{,}{,}{,}10243535353524 b a baP64–14(2):给状态编号:最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}0123011012231323301230101====第四章P81–1(1) 按照T,S 的顺序消除左递归ε|,)(||^)(T S T TS T T a S S G '→''→→' 递归子程序: procedure S; beginif sym='a' or sym='^' then abvance else if sym='('then beginadvance;T;if sym=')' then advance;else error;endelse errorend;procedure T;beginS;'Tend;procedure 'T;beginif sym=','then beginadvance;S;'Tendend;其中:sym:是输入串指针IP所指的符号advance:是把IP调至下一个输入符号error:是出错诊察程序(2)FIRST(S)={a,^,(}FIRST(T)={a,^,(}FIRST('T)={,,ε}FOLLOW(S)={),,,#}FOLLOW(T)={)}FOLLOW('T)={)}预测分析表是LL(1)文法P81–2文法:|^||)(|*||b a E P F F F P F T T T F T E E E T E →'→''→→''→+→''→εεε(1)FIRST(E)={(,a,b,^} FIRST(E')={+,ε} FIRST(T)={(,a,b,^} FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^} FIRST(F')={*,ε} FIRST(P)={(,a,b,^} FOLLOW(E)={#,)} FOLLOW(E')={#,)} FOLLOW(T)={+,),#} FOLLOW(T')={+,),#}FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#} FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b ||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φ FIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φ FIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ 所以,该文法式LL(1)文法.(4)procedure E;beginif sym='(' or sym='a' or sym='b' or sym='^' then begin T; E' endelse errorendprocedure E';beginif sym='+'then begin advance; E endelse if sym<>')' and sym<>'#' then error endprocedure T;beginif sym='(' or sym='a' or sym='b' or sym='^' then begin F; T' endelse errorendprocedure T';beginif sym='(' or sym='a' or sym='b' or sym='^' then Telse if sym='*' then errorendprocedure F;beginif sym='(' or sym='a' or sym='b' or sym='^' then begin P; F' endelse errorendprocedure F';beginif sym='*'then begin advance; F' endendprocedure P;beginif sym='a' or sym='b' or sym='^'then advanceelse if sym='(' thenbeginadvance; E;if sym=')' then advance else error endelse errorend;P81–3/***************(1) 是,满足三个条件。
编译原理1-3章作业

(b)已是DFA,只需最少化
b
=> 0
b 2
3
b
a
a
8、令文法为 E->T|E+T|E-T T->F|T*F|T/F F->(E)|I
(1)给出i+i*i、i*(i+i)的最左推导和最右推导; (2)给出i+i+i、 i+i*i和i-i-i的语法树。
9、证明下面的文法是二义性的: S->iSeS|iS|i
证明:该文法存在一个句子iiiei有两棵不同语法分析树,如下所示, 因此该文法是二义的。
第三章
7、构造下列正规式相应的DFA 1(0|1)*101 0*10*10*10* 9、对下面情况给出DFA及正规表达式 (1){0,1}上的含有子串010的所有串; 12、将图3.18的(a)和(b)分别确定化和最少化。
1(0|1)*101 (1) 构造NFA:
(2) 确定化
构造状态转换矩阵如下:
8、令文法为 E->T|E+T|E-T T->F|T*F|T/F F->(E)|I
(1)给出i+i*i、i*(i+i)的最左推导和最右推导; (2)给出i+i+i、 i+i*i和i-i-i的语法树。 答:(1) 最左推导: E=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*i E=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F) =>i*(i+i) 最右推导: E=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i=>i+i*i E=>T=>T*F=>T*(E)=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=>T*(i+i) =>F*(i+i)=>i*(i+i)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三章词法分析本章要点1.词法分析器设计,2.正规表达式与有限自动机,3.词法分析器自动生成。
本章目标:1.理解对词法分析器的任务,掌握词法分析器的设计;2.掌握正规表达式与有限自动机;3.掌握词法分析器的自动产生。
本章重点:1.词法分析器的作用和接口,用高级语言编写词法分析器等内容,它们与词法分析器的实现有关。
应重点掌握词法分析器的任务与设计,状态转换图等内容。
2.掌握下面涉及的一些概念,它们之间转换的技巧、方法或算法。
(1)非形式描述的语言↔正规式(2)正规式→ NFA(非确定的有限自动机)(3)NFA → DFA(确定的有限自动机)(4)DFA →最简DFA本章难点(1)非形式描述的语言↔正规式(2)正规式→ NFA(非确定的有限自动机)(3)NFA → DFA(确定的有限自动机)(4)DFA →最简DFA作业题一、单项选择题(按照组卷方案,至少15道)1. 程序语言下面的单词符号中,一般不需要超前搜索a. 关键字b. 标识符c. 常数d. 算符和界符2. 在状态转换图的实现中,一般对应一个循环语句a. 不含回路的分叉结点b. 含回路的状态结点c. 终态结点d. 都不是3. 用了表示字母,d表示数字, ={l,d},则定义标识符的正则表达式可以是:。
(a)ld*(b)ll*(c)l(l | d)*(d)ll* | d*4. 正规表达式(ε|a|b)2表示的集合是(a){ε,ab,ba,aa,bb} (b){ab,ba,aa,bb}(c){a,b,ab,aa,ba,bb} (d){ε,a,b,aa,bb,ab,ba}5. 有限状态自动机可用五元组(V T,Q,δ,q0,Q f)来描述,设有一有限状态自动机M的定义如下:V T={0,1},Q={q0,q1,q2},Q f={q2},δ的定义为:δ(q0,0)=q1δ(q1,0)=q2δ(q2,1)=q2δ(q2,0)=q2M所对应的状态转换图为。
6. 有限状态自动机可用五元组(V T,Q,δ,q0,Q f)来描述,设有一有限状态自动机M的定义如下:V T={0,1},Q={q0,q1,q2},Q f={q2},δ的定义为:δ(q0,0)=q1δ(q1,0)=q2δ(q2,1)=q2δ(q2,0)=q2M所能接受的语言可以用正则表达式表示为。
①(0|1)*②00(0|1)*③(0|1)*00④0(0|1)*07 . 有限状态自动机可用五元组(V T,Q,δ,q0,Q f)来描述,设有一有限状态自动机M的定义如下:V T={0,1},Q={q0,q1,q2},Q f={q2},δ的定义为:δ(q0,0)=q1δ(q1,0)=q2δ(q2,1)=q2δ(q2,0)=q2M所能接受的语言为。
①由0和1所组成的符号串的集合②以0为头符号和尾符号、由0和1所组成的符号串的集合③以两个0结束的,由0和1所组成的符号串的集合④以两个0开始的,由0和1所组成的符号串的集合8. 从接受语言的能力上来说,非确定型有穷自动机和________是等价的。
a. ⅰ.正规式;ⅱ.上下文无关文法;ⅲ.确定性有穷自动机;b. ⅰ.左线性正规文法;ⅱ.右线性正规文法;ⅲ.确定性有穷自动机;c. ⅰ.正规式;ⅱ.上下文无关文法;ⅲ.正规文法;d. ⅰ.正规式;ⅱ.确定性有穷自动机;ⅲ.下推自动机;9. 下面四个选项中,关于编译过程中扫描器的任务的叙述,________是较为完整且正确的。
①组织源程序的输入;按词法规则分割出单词,识别其属性,并转换成属性字的形式输出;删除注释;删除空格和无用字符;行计数、列计数;发现并定位词法错误;建立符号表。
②按词法规则分割出单词,识别其属性,并转换成属性字的形式输出;发现并定位词法错误;建立符号表;输出状态转换图;把状态转换图自动转换成词法扫描程序。
③组织源程序的输入;按词法规则分割出单词,识别其属性,并转换成属性字的形式输出。
④组织源程序的输入;按词法规则分割出单词,识别其属性,并转换成属性字的形式输出;行计数、列计数;发现并定位词法错误;建立符号表;输出状态转换图;把状态转换图自动转换成词法扫描程序。
10. 关于NFA的叙述中,下面______是不正确的。
A.有一个有穷字母表B.有多个初始状态C.有多个终止状态D.有多个有限状态11. 词法分析的理论基础是。
A.有穷自动机理论B.图灵机理论C.图论D.无穷自动机理论12. 设有两个状态S和T,如果从S出发能读出某个字w而停于终态,那么从T出发也能读出同样的字而停于终态;反之,果从T出发能读出某个字w而停于终态,那么从S出发也能读出同样的字而停于终态。
则我们称状态S和状态T是。
A. 可区分的;B. 等价的;C. 多余的;D. 无用的。
13. 词法分析器的输出结果是。
A、单词自身值B、单词在符号表中的位置C、单词的种别编码D、单词的种别编码和自身值14. 编译过程中扫描器的任务包括______。
①组织源程序的输入②按词法规则分割出单词,识别出其属性,并转换成属性字的形式输出⑧删除注解④删除空格及无用字符⑤行计数、列计数⑥发现并定位词法错误⑦建立符号表a.②③④⑦b.②③④⑥⑦c.①②③④⑥⑦d.①②③④⑤⑥⑦15. 下述正则表达式中______与(a*+b)*(c+d)等价(即有相同符号串集)。
(x+y亦可写作x|y)①a*(c+d)+b(c+d)②a*(c+d)*+b(c+d)*③a*(c+d)+b(c+d)④(a+b)*c+(a+b)*d⑤(a*+b)*c+(a*+b)*da.①③b. ③④⑤c.③d.④⑤16、正则式的“*”读作______。
a,并且L或者c.连接d.闭包17. 在状态转换图中,结点代表,用圆圈表示。
a.输入缓冲区b.向前搜索c.状态d.字符串18. 与(a|b)*(a|b)等价的正规式是。
A. a*| b*B. (ab)*(a|b)*C. (a|b)(a|b)*D. (a|b)*19.无符号常数的识别和拼数工作通常都在阶段完成。
A.词法分析B.语法分析C.语义分析D.代码生成一.答案:1. b;2. b;3. c;4. d;5.②;6. ②,7.④;8. b;9. ①;10. B;11. A;12. B;13. d;14. d;15.d;16.d;17.c;18. C;19. A二、填空题:(按照组卷方案,至少15道)1. 词法分析器对扫描缓冲区进行扫描时一般用两个指示器,一个_________________________________;另一个_____________________________________。
2. 一个确定性有限自动机DFA M的化简是指:寻找一个状态数比M少的DFA M’,使得。
3. 词法分析器所的输出常表示成如下形式的二元式:(______________,_________________)。
4. 一个状态转换图只包含有限个状态,其中有一个被认为是________,而且实际上至少有一个________。
5. 把状态转换图用程序实现时,对于含有回路的状态结点来说,可以让它对应一个_____________________________________程序段。
6. 词法分析阶段的任务式从左到右扫描,从而逐个识别。
7. 如果一个种别只含有一个单词符号,那么,对于这个单词符号,就可以完全代表它自身了。
8. 单词符号的属性值是指单词符号的特性或特征,其属性值则是反映特性或特征的值。
比如,对于某个标识符,常将作为其属性值。
9. 单词符号的属性值是指单词符号的特性或特征,其属性值则是反映特性或特征的值。
比如,对于常数,常将作为其属性值。
10. 如果一个种别含有多个单词符号,那么,对于它的每个单词符号,除了给出种别编码以外,还应给出有关。
11. 如果,则认为这两个正规式等价。
12. 对于∑*中的任何符号串α,如果存在一条从初态结点到某一终态结点的通路,且,则称α被该自动机所接受(识别)。
13. 一个Lex源程序主要包括两部分,一部分是,另一部分是。
14. 一个DFA可用一个矩阵表示,该矩阵的行表示,列表示,矩阵元素表示。
这个矩阵叫状态转换矩阵。
15. 对于词法分析程序来说,当程序到达“错误处理”时,意味着现行状态i和当前所面临的输入串不匹配。
如果后面还有状态图,出现在这个地方的代码应该为:。
二.答案:1. 指向当前正在识别的单词符号的开始位置,用于向前搜索以寻找单词符号的终点;2. L(M)=L(M');3. 单词种别,单词符号的属性值;4. 初态,终态;5. 由while和if 语句构成的;6. 源程序,单词;7. 种别编码;8. 存放它的有关信息的符号表项的指针;9. 存放它的常数表项的指针;10. 单词符号的属性信息(属性值);11. 两个正规式所表示的正规集相同;12. 这条通路上所有弧的标记符号连接起来形成的符号串等于α;13. 正规定义式,识别规则;14. 状态,输入字符,转换函数(或δ(s, a))的值;15. 将搜索器回退一个位置,并令下一个状态图开始工作。
三、判断题:(按照组卷方案,至少15道)1.NFA M的非确定性表现在它有多个终态。
()2. 有穷自动机接受的语言是正则语言。
()3. 若r1和r2是Σ上的正规式,则r1|r2也是。
()4. 设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
()5. 令Σ={a,b},则Σ上所有以b为首的字符构成的正规集的正规式为b*(a|b)*。
()6. 对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
()7. 对一个右线性文法G,必存在一个左线性文法G',使得L(G)=L(G'),反之亦然。
()8. 对任意一个右线性文法G,都存在一个NFA M,满足L(G)=L(M)。
( )9. 对任意一个右线性文法G,都存在一个DFA M,满足L(G)=L(M)。
( )10. 对任何正则表达式r,都存在一个NFA M,满足L(M)=L(r)。
( )11. 对任何正则表达式r,都存在一个DFA M,满足L(M)=L(r)。
( )12.一张转换图只包含有限个状态,其中有一个被认为是初态,最多只有一个终态。
()13. 一个正规式只能对应一个有限状态自动机;()14. 在词法分析的状态转换图中,有些结点是带星号的,这些结点肯定是终态结点。
()15. 适当设置扫描缓冲区的大小(比如容纳256个字符)可以保证单词符号不会被它的边界所打断。
()四.答案:1. ×;2. √;3. √;4. ×;5. ×;6. √;7. √;8. √;9. √;10. √;11. √;12×;13. ×;14. √;15. ×;四、名词解释:(按照组卷方案,至少5道)1. 状态转换图;2. 正规式(正规表达式、正则表达式)的形式化定义;3. 给出确定性有限状态自动机的形式化定义;4. 给出非确定性有限状态自动机的形式化定义;5. DFA状态最小化。