主成分SAS程序
主成分分析、判别分析、聚类分析sas程序

一、主成分分析1、数据引入PROC IMPORT OUT= WORK.shuruDA TAFILE= "E:\****\****\数据分析\试验\shouru.xls"DBMS=EXCEL2000 REPLACE;GETNAMES=YES;RUN;2、程序proc princomp data=shouru out=defen;var x1-x9;run;proc sort data=defen;by prin1 prin2;run;proc print data=defen;run;二、判别分析程序2.2方法1:先改变shuru 数据的结构,把待判的数据去掉,再引入数据data shouru1;input diqu $ x1-x9;cards;广东211.3 114 41.44 33.2 11.2 48.72 30.77 14.9 11.1西藏175.93 163.8 57.89 4.22 3.37 17.81 82.32 15.7 0;run;proc discrim data=shourutestdata=shouru1 method=normallist all crosslist testlist;class leixing;var x1-x9;run;方法2:原shuru数据不变,直接判别,但此法虽可判断待判的两省属于那类,但无法给出误判率;proc discrim data=shouruout=a1outstat=a2 outcross=a3method=normallist all crosslist testlist;class leixing;var x1-x9;run;程序2.3proc discrim data=shourutestdata=shouru1 method=normallist all crosslist crossvalidate testlist;class leixing;var x1-x9;priors prop;run;三、聚类分析程序proc cluster data=yjshr method=sin outtree=y1 ;/*最短距离法*/ var x1-x9;run;proc tree data=y1 nclusters=3 out=z1;run;proc print data=z1;run;proc cluster data=yjshr method=com outtree=y2 ;/*最长距离法*/ var x1-x9;run;proc tree data=y2 nclusters=3 out=z2;run;proc print data=z2;run;proc cluster data=yjshr method=ave outtree=y3 ;/*类平均距离法*/ var x1-x9;run;proc tree data=y3 nclusters=3 out=z3;run;proc print data=z3;run;proc fastclus data=yjshr out=a1maxc=3 cluster=c distance list; /*快速聚类分三类情况*/ proc plot;plot x2*x1=c;run;。
SAS学习系列33.-主成分分析

SAS学习系列33.-主成分分析33. 主成分分析(一)原理一、基本思想主成份分析,是数学上对数据降维的一种方法,是将多个变量转化为少数综合变量(集中了原始变量的大部分信息)的一种多元统计方法。
其主要目的是将变量减少,并使其改变为少数几个相互独立的线性组合形成的新变量(主成份,其方差最大),使得原始资料在这些成份上显示最大的个别差异来。
在所有的线性组合中所选取的F1应该是方差最大的,称为第一主成分。
如果第一主成分不足以代表原来所有指标的信息,再考虑选取第二个线性组合F2, 称为第二主成分。
为了有效地反映原有信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1,F2)=0. 依此类推可以构造出第三、第四、…、第p个主成分。
主成份分析,可以用来综合变量之间的关系,也可用来减少回归分析或聚类分析中的变量数目。
二、基本原理设有n个样品(多元观测值),每个样品观测p项指标(变量):X1,…,X p,得到原始数据资料阵:其中,X i = (x1i,x2i,…,x ni)T,i = 1, …, p.用数据矩阵X的p个列向量(即p个指标向量)X1,…,X p作线性组合,得到综合指标向量:简写成:F i = a1i X1 + a2i X2+…+a pi X p i = 1, …, p限制系数a i = (a1i,a2i,…,a pi)T为单位向量,即且由下列原则决定:(1)F i与F j互不相关,即COV(F i, F j)=a i T∑a i=0,其中∑为X 的协方差矩阵;(2)F1是X1,X2,…,X p的所有满足上述要求的线性组合中方差最大的,即F2是与F1不相关的X1,…,X p所有线性组合中方差最大的,…,F p是与F1,…,F p-1都不相关的X1,…,X p所有线性组合中方差最方向对应。
F1,F2,…,F p可以理解为p维空间中互相垂直的p 个坐标轴。
三、基本步骤1. 计算样品数据协方差矩阵Σ = (s ij)p p,其中2. 求出Σ的特征值及相应的特征向量λ1>λ2>…>λp>0, 及相应的正交化单位特征向量:则X的第i个主成分为F i= a i T X,i=1, …, p.3. 选择主成分在已确定的全部p个主成分中合理选择m个来实现最终的评价分析。
SASprincomp

SAS/STAT主成分分析(princomp)过程一、Princomp过程语句SAS/STAT(Princomp)主要的语句如下:二、实例分析例一应收账款是指企业因对外销售产品、材料、提供劳务及其它原因,应向购货单位或接受劳务的单位收取的款项,包括应收销货款、其它应收款和应收票据等。
出于扩大销售的竞争需要,企业不得不以赊销或其它优惠的方式招揽顾客,由于销售和收款的时间差,于是产生了应收款项。
应收款赊销的效果的好坏,不仅依赖于企业的信用政策,还依赖于顾客的信用程度。
由此,评价顾客的信用等级,了解顾客的综合信用程度,做到“知己知彼,百战不殆”,对加强企业的应收账款管理大有帮助。
某企业为了了解其客户的信用程度,采用西方银行信用评估常用的5C方法,5C的目的是说明顾客违约的可能性。
它们是:1、品格(用X1表示),指顾客的信誉,履行偿还义务的可能性。
企业可以通过过去的付款记录得到此项。
2、能力(用X2表示),指顾客的偿还能力。
即其流动资产的数量和质量以及流动负载的比率。
顾客的流动资产越多,其转化为现金支付款项的能力越强。
同时,还应注意顾客流动资产的质量,看其是否会出现存货过多过时质量下降,影响其变现能力和支付能力。
3、资本(用X3表示),指顾客的财务势力和财务状况,表明顾客可能偿还债务的背景。
4、附带的担保品(用X4表示),指借款人以容易出售的资产做抵押。
5、环境条件(用X5表示),指企业的外部因素,即指非企业本身能控制或操纵的因素。
首先并抽取了10家具有可比性的同类企业作为样本,又请8位专家分别给10个企业的5个指标打分,然后分别计算企业5个指标的平均值,如表。
这5个指标是按照百分制给出的分数,它们有同样的量纲,所以我们可以利用协方差阵做主成份分析。
程序:data c;input x1-x5@@;cards;76.5 81.5 76 75.8 71.7 85 79.2 80.3 84.4 76.570.6 73 67.6 68.1 78.5 94 94 87.5 89.5 9290.7 87.3 91 81.5 80 84.6 66.9 68.8 64.8 66.477.5 73.6 70.9 69.8 74.8 57.7 60.4 57.4 60.8 6585.6 68.5 70 62.2 76.5 70 69.2 71.7 64.9 68.9;PROC PRINCOMP data=c COV OUTstat=P out=b;Var x1 x2 x3 x4 x5;proc print data=p;proc print data=b;run;程序解释:PROC Princomp语句启动Princomp过程。
SAS软件应用之主成分分析

本章小节
在大部分实际问题中,变量之间是有一定的相关性的,人们 自然希望找到较少的几个彼此不相关的综合指标尽可能多地 反映原来众多变量的信息。本章介绍了主成分分析的数学模 型、方法步骤以及主成分分析的应用。我们需要一种综合性 的分析方法,既可减少指标变量的个数,又尽量不损失原指 标变量所包含的信息,对资料进行全面的综合分析。主成分 分析正是适应这一要求产生的,是解决这类题的理想工具。 主成份分析的基本思想就是将彼此相关的一组指标变量转化 为彼此独立的一组新的指标变量,并用其中较少的几个新指 标变量就能综合反应原多个指标变量中所包含的主要信息, 符合专业含义。
主成分分析的方法步骤
计算主成分得分 如果标准化指标变量 X 1 , X 2 ,, X k 的第i个主成分是:
Z i liX li1 X 1 li 2 X 2 lik X k xij x j 其中, X ij , j, 1,2,, k sj 是xj的标准化指标变量。那么,第i个主成分可以 转换为原始指标变量的线性组合:
主成分分析的方法步骤
对原始指标数据进行标准化变换:
X ij xij x j sj , j 1,2,, k
将原始数据标准化,然后利用标准化的数据 计算主成分。X为标准化后的数据矩阵,则:
X 11 X X 21 X n1 X 12 X 22 X n2 X 1k X 2k X nk
li1 li 2 lik li1 x1 li 2 x2 lik xk zi x1 x2 xk ( ),i 1,2,, k s1 s2 sk s1 s2 sk
主成分分析的应用
主成分分析与因子分析(三):使用SAS实现主成分分析-FACTOR过程

主成分分析与因子分析(三):使用SAS实现主成分分析-FACTOR过程上一系列文章介绍了使用PRINCOMP过程进行主成分分析。
今天,我们将介绍使用FACTOR过程进行主成分分析。
FACTOR 过程除了PROC PRINCOMP外,还可以使用PROC FACTOR来进行主成分分析。
事实上,在进行标准化后,二者的结果是一样的。
为了比较二者的结果,首先介绍如何对数据进行标准化。
SAS对数据的标准化是通过PROC STDIZE实现的,PROC STDIZE的一般形式如下:其中:•选项METHOD=指定用于标准化的方法,常见的标准化方法有MEAN、SUM、EUCLEN和STD。
•VAR语句指定数据集中用来进行主成分分析的变量,变量类型必须为数值型。
若该语句缺失,那么PROC FACTOR将分析数据集中的所有数值型变量。
标准化的计算方法如下:这里LOCATION和SCALE的值与标准化方法有关。
表12.3列举了一些常见的标准化方法的LOCATION和SCALE值。
有关其他方法具体参数值建议读者参考SAS官方帮助文档。
表12.3 常见标准化方法中的LOCATION值与SCALE值这里仅简单介绍PROC FACTOR中与主成分分析相关部分的选项,在后面使用PROC FACTOR进行因子分析时,会对其他选项进行介绍。
PROC FACTOR的语法如下:其中:•常见的选项有:“DATA=”用于指定输入数据集,“SIMPLE”输出常见的统计量,“CORR”输出原始变量的相关矩阵。
•VAR语句指定数据集中用于分析的变量。
例12.2:使用PROC FACTOR对数据集sashelp.cars进行主成分分析。
示例代码如下:输出结果中基本统计量与相关矩阵的部分如图12.8所示。
图12.8 使用PROC FACTOR进行主成分分析过程中输出基本统计量与相关矩阵同时,PROC FACTOR还输出了相关矩阵的特征值与解释的变异比例,这部分内容也和PROC PRINCOMP一致(如图12.9所示)。
主成分分析和主成分回归(附实际案例和sas代码)

目录主成分分析和主成分回归(附实际案例和sas代码) (2)1 主成分分析的主要思想 (2)2 主成分分析的定义 (2)3 案例基本情况介绍餐饮业零售额相关因素 (3)4 案例相关因素的介绍相关因素的具体数据 (3)5 影响餐饮业零售额因素的主成分分析 (4)6 主成分回归 (9)主成分分析和主成分回归(附实际案例和sas 代码)1 主成分分析的主要思想在进行高维数据系统分析时,通过主成分分析,可以在纷繁的指标变量描述下,了解影响这个系统存在与发展的主要因素。
主成分分析是1933年由霍特林首先提出来的。
在信息损失最小的前提下,将描述某一系统的多个变量综合成少数几个潜变量,从而迅速揭示系统形成的主要因素,并把原来高维空间降到低维子空间。
主成分分析是研究如何通过少数几个主成分来解释多变量的方差的分析方法,也就是求出少数几个主成分,使他们尽可能多地保留原始变量的信息,且彼此不相关它是一种数学变换方法,即把给定的一组变量通过线性变换,转换为一组不相关的变量,在这种变换中保持变量的总方差不变,同时具有最大总方差,称为第一主成分;具有次大方差,成为第二主成分。
依次类推。
若共有p 个变量,实际应用中一般不是找p 个主成分,而是找出个)(p m m <主成分就够了,只要这m 个主成分能够反映原来所有变量的绝大部分的方差。
2 主成分分析的定义设研究对象涉及P 个指标,分别用p X X X ,,21表示,这个指标构成P 维随机向量为)',,,(21p X X X X =。
设随机向量的均值为u ,协方差矩阵为Σ。
主成分分析就是对随机向量进行线性变换以形成新的综合变量,用i Z 表示,满足下式:1212,1,2,,i i i ip P Z u X u X u X i p =++⋅⋅⋅+= (1)为了使新的综合变量能够充分反映原来变量的信息,则i Z 的方差尽可能大且各个i Z 之间不相关。
由于没有限制条件方差可以任意大,设有线面的约束条件:222121,(1,2,)i i ip u u u i p ++⋅⋅⋅== (2)主成分则为满足条件的i Z 。
聚类分析与主成分分析SAS的程序

实验三我国各地区城镇居民消费性支出的主成分分析和聚类分析(王学民编写)一、实验目的1.掌握如何使用SAS软件来进行主成分分析和聚类分析;2.看懂和理解SAS输出的结果,并学会以此来作出分析;3.掌握对实际数据如何来进行主成分分析;4.对同一组数据使用五种系统聚类方法及k均值法,学会对各种聚类效果的比较,获取重要经验;5.掌握使用主成分进行聚类二、实验内容数据集sasuser.examp633中含有1999年全国31个省、直辖市和自治区的城镇居民家庭平均每人全年消费性支出的八个主要变量数据。
对这些数据进行主成分分析,可将这31个地区的前两个主成分得分标示于平面坐标系内,对各地区作直观的比较分析。
对同样的数据使用五种系统聚类方法及k均值法聚类,并对聚类效果作比较。
最后,对主成分的图形聚类和正规聚类的效果进行比较。
实验1进行主成分分析,根据前两个主成分得分所作的散点图对31个地区进行比较分析。
实验2分别使用最长距离法、中间距离法、两种类平均法、离差平方和法和k均值法进行聚类分析,并比较其聚类效果。
实验3主成分聚类,并与上述正规的聚类方法进行比较三、实验要求1.用SAS软件的交互式数据分析菜单系统完成主成分分析;2.完成五种系统聚类方法及k均值法,比较其聚类效果;3.根据前两个主成分得分的散点图作直观的聚类,并与上述正规的聚类方法进行比较。
四、实验指导1.进行主成分分析在inshigt中打开数据集sasuser.examp633,见图1。
选菜单过程如下:在图1中选分析⇒多元(Y X)⇒在变量框中选x1,x2,x3,x4,x5,x6,x7,x8(见图2)⇒Y⇒选输出⇒选主分量分析,主分量选项(见图3)⇒在图4中作图中的选择(主成分个数缺省时为“自动”选项,此时只输出特征值大于1的主成分)⇒确定⇒确定⇒确定图1图2图3图4 得到如图5、图6所示的结果:图5图6从图5可以看出,前两个和前三个主成分的累计贡献率分别达到80.6%和87.8%,第一主成分1ˆy 在所有变量(除在*2x 上的载荷稍偏小外)上都有近似相等的正载荷,反映了综合消费性支出的水平,因此第一主成分可称为综合消费性支出成分。
主成份分析报告(包含sas程序)
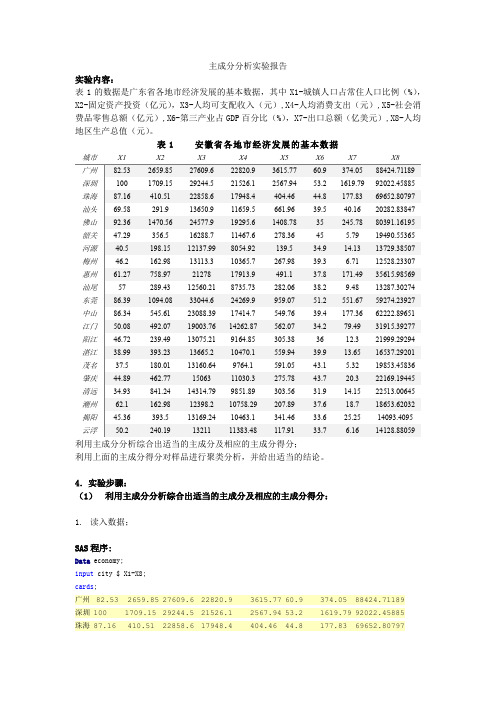
主成分分析实验报告实验内容:表1的数据是广东省各地市经济发展的基本数据,其中X1-城镇人口占常住人口比例(%),X2-固定资产投资(亿元),X3-人均可支配收入(元),X4-人均消费支出(元),X5-社会消费品零售总额(亿元),X6-第三产业占GDP百分比(%),X7-出口总额(亿美元),X8-人均地区生产总值(元)。
表1 安徽省各地市经济发展的基本数据城市X1X2X3X4X5X6X7X8广州82.532659.8527609.622820.93615.7760.9374.0588424.71189深圳1001709.1529244.521526.12567.9453.21619.7992022.45885珠海87.16410.5122858.617948.4404.4644.8177.8369652.80797汕头69.58291.913650.911659.5661.9639.540.1620282.83847佛山92.361470.5624577.919295.61408.7835245.7880391.16195韶关47.29356.516288.711467.6278.3645 5.7919490.55365河源40.5198.1512137.998054.92139.534.914.1313729.38507梅州46.2162.9813113.310365.7267.9839.3 6.7112528.23307惠州61.27758.972127817913.9491.137.8171.4935615.98569汕尾57289.4312560.218735.73282.0638.29.4813287.30274东莞86.391094.0833044.624269.9959.0751.2551.6759274.23927中山86.34545.6123088.3917414.7549.7639.4177.3662222.89651江门50.08492.0719003.7614262.87562.0734.279.4931915.39277阳江46.72239.4913075.219164.85305.383612.321999.29294湛江38.99393.2313665.210470.1559.9439.913.6516537.29201茂名37.5180.0113160.649764.1591.0543.1 5.3219853.45836肇庆44.89462.771506311030.3275.7843.720.322169.19445清远34.93841.2414314.799851.89303.5631.914.1522513.00645潮州62.1162.9812398.210758.29207.8937.618.718653.62032揭阳45.36393.513169.2410463.1341.4633.625.2514093.4095云浮50.2240.191321111383.48117.9133.7 6.1614128.88059利用主成分分析综合出适当的主成分及相应的主成分得分;利用上面的主成分得分对样品进行聚类分析,并给出适当的结论。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主成分的求解方法
1求相关矩阵
2、求特征值与特征向量
3、确定主成分个数
4、计算主成分得分。
data p108;
input x$ x1-x8;
datalines;
北京1394.89 2505.00 519.01 8144 373.90 117.30 112.60 843.43 天津920.11 2720.00 345.46 6501 342.80 115.20 110.60 582.51 河北2849.52 1258.00 704.87 4839 2033.30 115.20 115.80 1234.85 山西1092.48 1250.00 290.90 4721 717.30 116.90 115.60 697.25 内蒙832.88 1387.00 250.23 4134 781.70 117.50 116.80 419.39 辽宁2793.37 2397.00 387.99 4911 1371.10 116.10 114.00 1840.55 吉林1129.20 1872.00 320.45 4430 497.40 115.20 114.20 762.47 黑龙江2014.53 2334.00 435.73 4145 824.80 116.10 114.30 1240.37 上海2462.57 5343.00 996.48 9279 207.40 118.70 113.00 1642.95 江苏5155.25 1926.00 1434.95 5943 1025.50 115.80 114.30 2026.64 浙江3524.79 2249.00 1006.39 6619 754.40 116.60 113.50 916.59 安徽2003.58 1254.00 474.00 4609 908.30 114.80 112.70 824.14 福建2160.52 2320.00 553.97 5857 609.30 115.20 114.40 433.67 江西1205.11 1182.00 282.84 4211 411.70 116.90 115.90 571.84 山东5002.34 1527.00 1229.55 5145 1196.60 117.60 114.20 2207.69 河南3002.74 1034.00 670.35 4344 1574.40 116.50 114.90 1367.92 湖北2391.42 1527.00 571.68 4685 849.00 120.00 116.60 1220.72 湖南2195.70 1408.00 422.61 4797 1011.80 119.00 115.50 843.83 广东5381.72 2699.00 1639.83 8250 656.50 114.00 111.60 1396.35 广西1606.15 1314.00 382.59 5105 556.00 118.40 116.40 554.97 海南364.17 1814.00 198.35 5340 232.10 113.50 111.30 64.33 四川3534.00 1261.00 822.54 4645 902.30 118.50 117.00 1431.81 贵州630.07 942.00 150.84 4475 301.10 121.40 117.20 324.72 云南1206.68 1261.00 334.00 5149 310.40 121.30 118.10 716.65 西藏55.98 1110.00 17.87 7382 4.20 117.30 114.90 5.57 陕西1000.03 1208.00 300.27 4396 500.90 119.00 117.00 600.98 甘肃553.35 1007.00 114.81 5493 507.00 119.80 116.50 468.79 青海165.31 1445.00 47.76 5753 61.60 118.00 116.30 105.80
宁夏169.75 1355.00 61.98 5079 121.80 117.10 115.30 114.40 新疆834.57 1469.00 376.95 5348 339.00 119.70 116.70 428.76 ;
proc princomp;
var x1-x8;
run;
proc princomp out=score n=3;
var x1-x8;
run;
proc print data=score;
run;
Proc plot data=score;
Plot prin2*prin1=x;
Run;
例:进行主成分分析
1、用程序求样本相关矩阵的特征值和特征向量。
2、求两个主成分的累计贡献率,写出贡献率计算表达式。
3、写出两个主成分的模型表达式。
4、计算主成分得分,并按主成分得分名次
例:对下表的指标进行主成分分析,
5、用程序求样本相关矩阵的特征值和特征向量。
6、求两个主成分的累计贡献率,写出贡献率计算表达式。
7、写出两个主成分的模型表达式。
8、计算主成分得分,并按主成分得分名次
9、按两个主成分得分作散点图
10、对主成分得分聚类
例:
学生身体各指标的主成分分析.
随机抽取30名某年级中学生,测量其身高(X1)、体重(X2)、胸围(X3)和坐高(X4),数据见
试对中学生身体指标数据做主成分分析.。