SAS聚类分析程序
sas聚类作业
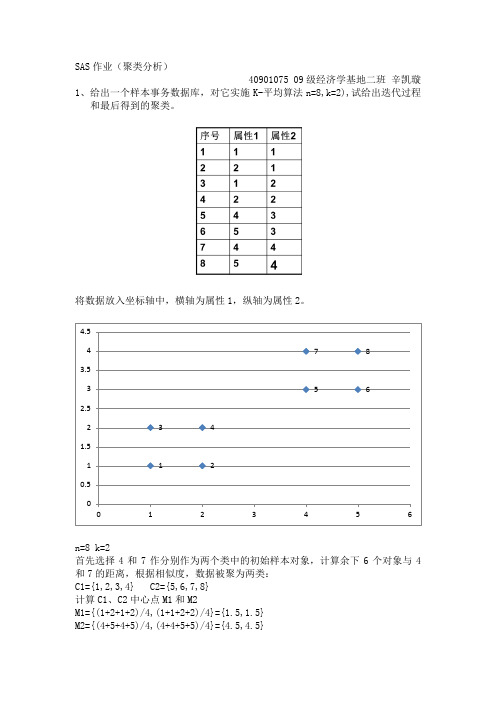
SAS作业(聚类分析)40901075 09级经济学基地二班辛凯璇1、给出一个样本事务数据库,对它实施K-平均算法n=8,k=2),试给出迭代过程和最后得到的聚类。
将数据放入坐标轴中,横轴为属性1,纵轴为属性2。
n=8 k=2首先选择4和7作分别作为两个类中的初始样本对象,计算余下6个对象与4和7的距离,根据相似度,数据被聚为两类:C1={1,2,3,4} C2={5,6,7,8}计算C1、C2中心点M1和M2M1={(1+2+1+2)/4,(1+1+2+2)/4}={1.5,1.5}M2={(4+5+4+5)/4,(4+4+5+5)/4}={4.5,4.5}此时,E2=e12+e22=2+2=4重新计算1-8与M1,M2的距离,数据的聚类仍然保持不变,C1={1,2,3,4} C2={5,6,7,8}此时,算法停止,因为如果继续分析新中心和样本之间的距离,样本会全部分配给同样的类。
因此,数据被分为两类,第一类中心点为{1.5,1.5},C1={1,2,3,4},第二类中心点为{4.5,4.5},C2={5,6,7,8}。
2、给出一个样本事务数据库,采用凝聚层次聚类(n=8,k=2),利用最小距离方法,试给出聚类过程和最后形成的聚类。
将数据放入坐标轴中,横轴为属性1,纵轴为属性2。
n=8 k=2将每个对象看成一个新类。
首先计算两两对象之间的距离,根据最小距离法,分别由1,2和5,6形成一个新类,1,2与3,5,6与7可以分别再形成一个新类,1,2,3与4,5,6,7与8分别可以再形成一个新类。
此时,形成的两个聚类是:C1={1,2,3,4},C2={5,6,7,8}。
甚至还可以将1,2,3,4,5,6,7,8形成一个聚类。
凝聚层次聚类法需要设定阀值,因此最终的聚类结果和设定的距离阀值有关。
SAS 聚类分析方法

SAS 聚类分析(描述算法)系统聚类法系统聚类法(Hierarchical clustering method )是目前使用最多的一种方法。
其基本思想是首先将n 个样品看成n 类(即一类包括一个样品),然后规定样品之间的距离和类与类之间的距离。
将距离最近的两类合并为一个新类,在计算新类和其他类之间的距离,再从中找出最近的两类合并,继续下去,最后所有的样品全在一类。
将上述并类过程画成聚类图,便可以决定分多少类,每类各有什么样品。
系统聚类法的步骤为:①首先各样品自成一类,这样对n 组样品就相当于有n 类;②计算各类间的距离,将其中最近的两类进行合并;③计算新类与其余各类的距离,再将距离最近的两类合并;④重复上述的步骤,直到所有的样品都聚为一类时为止。
下面我们以最短距离法为例来说明系统聚类法的过程。
最短距离法的聚类步骤如下:① 规定样品之间的距离,计算样品的两两距离,距离矩阵记为()0S ,开始视每个样品分别为一类,这时显然应有pq d q p D =),(;② 选择距离矩阵()0S 中的最小元素,不失一般性,记其为),(q p D ,则将p G 与q G 合并为一新类,记为m G ,有q p m G G G ⋃=;③ 计算新类m G 与其他各类的距离,得到新的距离矩阵记为()1S ;④ 对()1S 重复开始进行第②步,…,直到所有样本成为一类为止。
值得注意的是在整个聚类的过程中,如果在某一步的距离矩阵中最小元素不止一个时,则可以将其同时合并。
● 系统聚类法是最常用的一种聚类方法,常用的系统聚类方法有最短距离法、最长距离法、中间距离法、类平均法、重心法、Ward 最小方差法、密度估计法、两阶段密度估计法、最大似然估计法、相似分析法和可变类平均法。
● 大多数的研究表明:最好综合特性的聚类方法为类平均法或Ward 最小方差法,而最差的则为最短距离法。
Ward 最小方差法倾向于寻找观察数相同的类。
类平均法偏向寻找等方差的类。
SPSS聚类分析具体操作步骤spss如何聚类

算法步骤:初始 化聚类中心、分 配数据点到最近 的聚类中心、重 新计算聚类中心、 迭代直到聚类中 心不再变化
适用场景:探索 性数据分析、市 场细分、异常值 检测等
注意事项:选择 合适的聚类数目、 处理空值和异常 值、考虑数据的 尺度问题
定义:根据数据点间的距离或相似性,将数据点分为多个类别的过程 常用方法:层次聚类、K-均值聚类、DBSCAN聚类等 适用场景:适用于探索性数据分析,发现数据中的模式和结构 注意事项:选择合适的距离度量方法、确定合适的类别数目等
常见的聚类分析方法包括层次聚类、Kmeans聚类、DBSCAN聚类等。
聚类分析基于数据的相似性或距离度量, 将相似的数据点归为一类,使得同一类 中的数据点尽可能相似,不同类之间的 数据点尽可能不同。
聚类分析广泛应用于数据挖掘、市场细分、 模式识别等领域。
K-means聚类:将数据划分为K个簇,使得每个数据点到所在簇中心的距离之和最小
聚类结果的可视化:通过图表展示聚类结果 聚类质量的评估:使用适当的指标评估聚类效果的好坏 聚类结果的解释:根据实际需求和背景知识,对聚类结果进行合理的解释和解读 聚类结果的应用:探讨聚类结果在各个领域的应用场景和价值
SPSS聚类分析常 用方法
定义:将数据集 划分为K个聚类, 使得每个数据点 属于最近的聚类 中心
聚类结果展示:通过图表或表格展示聚类结果,包括各类别的样本数和占比
聚类质量评估:采用适当的指标评估聚类效果,如轮廓系数、Davies-Bouldin指数等
聚类结果解读:根据业务背景和数据特征,解释各类别的含义和特征 聚类结果应用:说明聚类分析在具体场景中的应用,如市场细分、客户分类等
SPSS聚类分析注 意事项
确定聚类变量:选 择与聚类目标相关 的变量,确保变量 间无高度相关性。
sas聚类分析(SAS)分解

个体与小类、小类与小类间“亲 疏程度”的度量方法
SPSS中提供了多种度量个体与小类、小类 与小类间“亲疏程度”的方法。与个体 间“亲疏程度”的测度方法类似,应首 先定义个体与小类、小类与小类的距离。 距离小的关系亲密,距离大的关系疏远。 这里的距离是在个体间距离的基础上定 义的,常见的距离有:
似程度通常可以用简单相关系数或者等 级相关系数等;一是个体间的差异程度 ,通常通过某种距离来测度。
1、定距型变量个体间距离的计算方式
欧式距离(Euclidean distance)
k
(xi yi )2 (73 66)2 (68 64)2 i1
平方欧式距离(Squared Euclidean distance ) 切比雪夫(Chebychev)距离
各变量间不应有较强的线性相关关系
学校
参加科研 人数
(人)
投入经费 (元)
立项课题 数(项)
样本的欧氏距离
元
万元
1
410
4380000
19
(1,2) 265000
81.623
2
336
1730000
21
(1,2) 218000
193.7
3
490
220000
8
(1,2)
47000
254.897
层次聚类
1 层次聚类的两种类型和两种方式 层次聚类又称系统聚类,简单地讲是指聚类过程
(1)间隔尺度。变量用连续的量来表示,如“ 各种奖金”、“各种津贴”等。
(2)有序尺度。指标用有序的等级来表示,如 文化程度分为文盲、小学、中学、中学以上 等有次序关系,但没有数量表示。
(3)名义尺度。指标用一些类来表示,这些类 之间没有等级关系也没有数量关系,如表中 的性别和职业都是名义尺度。
SPSS软件聚类分析过程的图文解释及结果的全面分析

SPSS聚类分析过程聚类的主要过程一般可分为如下四个步骤:1.数据预处理(标准化)2.构造关系矩阵(亲疏关系的描述)3.聚类(根据不同方法进行分类)4.确定最佳分类(类别数)SPSS软件聚类步骤1. 数据预处理(标准化)→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择从Transform Values框中点击向下箭头,此为标准化方法,将出现如下可选项,从中选一即可:标准化方法解释:None:不进行标准化,这是系统默认值;Z Scores:标准化变换;Range –1 to 1:极差标准化变换(作用:变换后的数据均值为0,极差为1,且|x ij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。
);Range 0 to 1(极差正规化变换/ 规格化变换);2. 构造关系矩阵在SPSS中如何选择测度(相似性统计量):→Analyze →Classify →Hierachical Cluster Analysis →Method 然后从对话框中进行如下选择常用测度(选项说明):Euclidean distance:欧氏距离(二阶Minkowski距离),用途:聚类分析中用得最广泛的距离;Squared Eucidean distance:平方欧氏距离;Cosine:夹角余弦(相似性测度;Pearson correlation:皮尔逊相关系数;3. 选择聚类方法SPSS中如何选择系统聚类法常用系统聚类方法a)Between-groups linkage 组间平均距离连接法方法简述:合并两类的结果使所有的两两项对之间的平均距离最小。
(项对的两成员分属不同类)特点:非最大距离,也非最小距离b)Within-groups linkage 组内平均连接法方法简述:两类合并为一类后,合并后的类中所有项之间的平均距离最小C)Nearest neighbor 最近邻法(最短距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法d)Furthest neighbor 最远邻法(最长距离法)方法简述:用两类之间最远点的距离代表两类之间的距离,也称之为完全连接法e)Centroid clustering 重心聚类法方法简述:两类间的距离定义为两类重心之间的距离,对样品分类而言,每一类中心就是属于该类样品的均值特点:该距离随聚类地进行不断缩小。
SPSS聚类分析详解

指标 地区(样品) 1
2
3
456
性能
9 1 10
928
颜色
827
946
式样
728
357
用分类法对6个样品进行分类,以估计哪些地区最有可能经销 这类新产品?
按公式计算两两样品间的相似系数,得相似矩阵
Q (Coij) s(qij)
1
2
3
4
5
6
1 1
2 0.933 1
Q=
3
0.994
2)形成一个由小到大的分析系统。 3)把整个分类系统画成一张分类图
二、聚类统计量
首先定义一些分类统计指标 —— 刻画样或指标之间 的相似程度(这些统计指标称为聚类统计量)
在市场研究中,样品 —— 用作分类的事物
指标 —— 用来作为分类依据的变量。(如: 年龄、收入、销售量)
(一)相似系数(夹角余弦)
0.47
X4
0.93
X2
0.68
X7
X5
-0.94
0.49
X8
主要城市日照时数
注:连续变量
SPSS提供不同类间距 离的测量方法
1、组间连接法 2、组内连接法 3、最近距离法 4、最远距离法 5、重心法 6、中位数法 7、Ward最小偏差平 方和法
观测量概述表
聚类步骤,与图结合看!
4、5
输入格式
55列为城市
15位
输出F及t 统计量
平均法 重心法 最小距离法
输出结果:
新类中的观测值数
观测值之间距离的均方根
类间距离除以 观测值间距离 均方根得来
类数
指出被合并的类
F、t**2峰值(起伏)越大 说明分类显著
如何用SAS进行统计分析

如何用SAS进行统计分析SAS(统计分析系统)是一种用于数据分析和统计建模的软件工具。
它提供了一系列功能和程序,用于数据处理、统计分析、预测建模、图形展示和报告生成等。
本文将介绍如何使用SAS进行统计分析,涵盖数据导入、数据清洗、描述性统计分析、假设检验、回归分析和聚类分析等内容。
1. 数据导入和数据清洗在使用SAS进行统计分析之前,你需要将待分析的数据导入到SAS软件中。
SAS支持多种数据格式,包括CSV、Excel、Access等。
你可以使用SAS提供的PROC IMPORT过程将数据导入到SAS的数据集中。
导入数据后,你需要对数据进行清洗。
数据清洗的目的是去除数据中的错误、缺失或异常值,以确保数据的质量。
你可以使用SAS的数据步骤(DATA STEP)来处理数据,例如删除缺失值、填补缺失值、去除异常值等。
2. 描述性统计分析描述性统计分析是对数据进行总结和描述的过程。
它包括计算数据的中心趋势(均值、中位数、众数)、数据的离散程度(标准差、方差、极差)、数据的分布形态(偏度、峰度)等。
在SAS中,你可以使用PROC MEANS过程进行描述性统计分析。
该过程可以计算多个变量的均值、标准差、最小值、最大值、中位数等统计指标。
此外,你还可以使用PROC UNIVARIATE过程计算数据的偏度、峰度等统计值,并绘制直方图和箱线图来展示数据的分布情况。
3. 假设检验假设检验是对样本数据进行推断性统计分析的一种方法。
它用于判断观察到的样本差异是否显著,从而对总体参数进行推断。
在SAS中,你可以使用PROC TTEST过程进行双样本t检验、单样本t检验和相关样本t检验等。
此外,PROC ANOVA过程可以用于方差分析,PROC FREQ过程可以用于卡方检验。
4. 回归分析回归分析是研究因变量与自变量之间关系的一种统计分析方法。
它用于预测和解释因变量的变化,并评估自变量对因变量的影响程度。
在SAS中,你可以使用PROC REG过程进行简单线性回归分析和多元线性回归分析。
SPSS19.0之聚类分析

1.1 系统聚类本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。
1.1.1 最短距离聚类法最短距离法聚类步骤如下:1.规定样本间的距离,计算样本两两之间的距离,得到对称矩阵。
开始每个样品自成一类。
2.选择对称矩阵中的最小非零元素。
将两个样品之间最小距离记为D1,将这两个样品归并成为一类,记为G1。
3.计算G1与其他样品距离。
重复以上过程直到所有样品合并为一类。
我们在SPSS中实现最短距离分析非常简单。
单击“”-->“”-->“”。
将弹出如图1-1所示的对话框,设置相应的参数即可。
图1-1 最短距离法我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。
在绘制中选择绘制“树状图”。
单击确定,得到以下结果。
聚类表阶群集组合系数首次出现阶群集下一阶群集1 群集 2 群集 1 群集 21 21 28 .211 0 0 102 12 24 .465 0 0 63 2 27 .491 0 0 54 13 20 .585 0 0 95 2 14 .645 3 0 66 2 12 .678 5 2 77 2 7 .702 6 0 88 2 25 .773 7 0 99 2 13 .916 8 4 1110 21 29 1.085 1 0 1211 2 18 1.106 9 0 12表1-2 聚类过程我们可以通过更加形象直观的树状图来观察整个聚类过程和聚类效果。
如图1-2所示,最短距离法组内距离小,但组间距离也较小。
分类特征不够明显,无法凸显各个省份的能源消耗的特点。
但是我们可以看到广东省能源消耗组成和其他省份特别不同,在其他方法中也显现出来。
12 2 21 1.115 11 10 13 13 2 17 1.360 12 0 14 14 2 26 1.564 13 0 15 15 2 22 1.627 14 0 16 16 2 5 1.649 15 0 17 17 2 8 1.877 16 0 18 18 2 16 3.027 17 0 19 19 2 30 3.543 18 0 20 20 2 11 4.930 19 0 21 21 2 4 5.024 20 0 22 22 2 10 6.445 21 0 24 23 1 9 8.262 0 0 26 24 2 15 10.093 22 0 25 25 2 23 10.096 24 0 26 26 1 2 10.189 23 25 27 27 1 6 11.387 26 0 28 28 1 3 13.153 27 0 29 2911932.36728图1-2 最短距离法聚类图1.1.2 组间联接聚类组间联接聚类法定义为两类之间的平均平方距离,即。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SAS聚类分析程序:
聚类分析过程命令
Data pgm33b;
Input x1-x3;
cards;
9.30 30.55 8.7
(样品数据)
1.85 20.66 1
2.75;
Proc cluster standard method= single nonorm
nosquare ccc pseudo out=tree;
Proc tree data=tree horizontal spaces=1; run;
Data pgm33b
Input x1-x4;
cards;
9.30 30.55 8.7
(样品数据)
1.85 20.66 1
2.75;
Proc cluster standard method=complete nonorm
nosquare ccc pseudo out=tree;
Proc tree data=tree horizontal spaces=1; run;
刷黑该块过程命令程序,提交便计算出相应聚类结果。
语句解释: 聚类指定的方法是在“method=”后面填入一个相应的选择项,它们是:single(最短距离法),complete(最长距离法),average(类平均法), centroid(重心法),median(中位数法),ward(离差平方和法),flexible (可变类平均法),density(非参数概率密度估计法),eml(最大似然法),twostage(两阶段密度法)。
主成分分析程序:
1. 主成分分析实验程序例:
主成分分析过程命令
data socecon;
input x1-x6;
cards;
16369 3504887 66047 2397739 198.46 1043955
13379 566257 4744 456100 76.96 202637
9707 397183 1303 887034 18.88 105948
10572 414932 1753 751984 27.67 128261
12284 876667 18269 1015669 60.09 332700
9738 604935 5822 1307908 30.54 222799
16970 778830 2438 630014 76.64 272203
10006 617436 13543 866013 58.59 222794
10217 636760 9967 996912 34.55 161025
20946 1380781 16406 526527 150.15 426937
11469 720416 7141 853778 43.41 157274
14165 1504005 29413 1025363 149.17 568899
12795 966188 11580 723278 45.13 165319
12762 584696 13583 343107 65.31 166454
12008 501780 4986 278310 15.04 86575 11208 981367 13364 1295189 79.8 337947 12719 716491 4448 408796 15.68 99949 ;
proc princomp out=aaa prefix=z;
var x1-x6; run;
data a2;
set aaa;
proc print;
var z1-z2 ;run;。