sas聚类分析(SAS)
SAS中的聚类分析方法总结

SAS中的聚类分析方法总结(1)——聚类分析概述说起聚类分析,相信很多人并不陌生。
这篇原创博客我想简单说一下我所理解的聚类分析,欢迎各位高手不吝赐教和拍砖。
按照正常的思路,我大概会说如下几个问题:1. 什么是聚类分析?2. 聚类分析有什么用?3. 聚类分析怎么做?下面我将分聚类分析概述、聚类分析算法及sas实现、案例三部分来系统的回答这些问题。
聚类分析概述1. 聚类分析的定义中国有句俗语叫“物以类聚,人以群分”——剔除这句话的贬义色彩。
说白了就是物品根据物品的特征和功用可以分门别类,人和人会根据性格、偏好甚至利益结成不同的群体。
分门别类和结成群体之后,同类(同群)之间的物品(人)的特征尽可能相似,不同类(同群)之间的物品(人)的特征尽可能不同。
这个过程实际上就是聚类分析。
从这个过程我们可以知道如下几点:1) 聚类分析的对象是物(人),说的理论一点就是样本2) 聚类分析是根据物或者人的特征来进行聚集的,这里的特征说的理论一点就是变量。
当然特征选的不一样,聚类的结果也会不一样;3) 聚类分析中评判相似的标准非常关键。
说的理论一点也就是相似性的度量非常关键;4) 聚类分析结果的好坏没有统一的评判标准;2. 聚类分析到底有什么用?1) 说的官腔一点就是为了更好的认识事物和事情,比如我们可以把人按照地域划分为南方人和北方人,你会发现这种分法有时候也蛮有道理。
一般来说南方人习惯吃米饭,北方习惯吃面食;2) 说的实用一点,可以有效对用户进行细分,提供有针对性的产品和服务。
比如银行会将用户分成金卡用户、银卡用户和普通卡用户。
这种分法一方面能很好的节约银行的资源,另外一方面也能很好针对不同的用户实习分级服务,提高彼此的满意度。
再比如移动会开发全球通、神州行和动感地带三个套餐或者品牌,实际就是根据移动用户的行为习惯做了很好的用户细分——聚类分析;3) 上升到理论层面,聚类分析是用户细分里面最为重要的工具,而用户细分则是整个精准营销里面的基础。
sas聚类作业
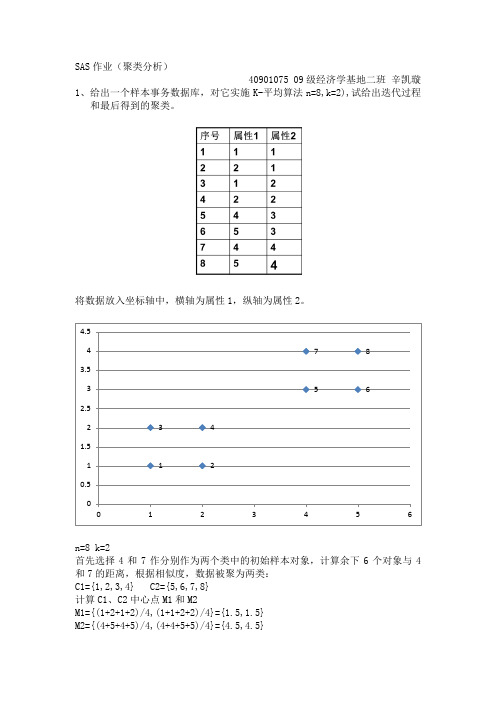
SAS作业(聚类分析)40901075 09级经济学基地二班辛凯璇1、给出一个样本事务数据库,对它实施K-平均算法n=8,k=2),试给出迭代过程和最后得到的聚类。
将数据放入坐标轴中,横轴为属性1,纵轴为属性2。
n=8 k=2首先选择4和7作分别作为两个类中的初始样本对象,计算余下6个对象与4和7的距离,根据相似度,数据被聚为两类:C1={1,2,3,4} C2={5,6,7,8}计算C1、C2中心点M1和M2M1={(1+2+1+2)/4,(1+1+2+2)/4}={1.5,1.5}M2={(4+5+4+5)/4,(4+4+5+5)/4}={4.5,4.5}此时,E2=e12+e22=2+2=4重新计算1-8与M1,M2的距离,数据的聚类仍然保持不变,C1={1,2,3,4} C2={5,6,7,8}此时,算法停止,因为如果继续分析新中心和样本之间的距离,样本会全部分配给同样的类。
因此,数据被分为两类,第一类中心点为{1.5,1.5},C1={1,2,3,4},第二类中心点为{4.5,4.5},C2={5,6,7,8}。
2、给出一个样本事务数据库,采用凝聚层次聚类(n=8,k=2),利用最小距离方法,试给出聚类过程和最后形成的聚类。
将数据放入坐标轴中,横轴为属性1,纵轴为属性2。
n=8 k=2将每个对象看成一个新类。
首先计算两两对象之间的距离,根据最小距离法,分别由1,2和5,6形成一个新类,1,2与3,5,6与7可以分别再形成一个新类,1,2,3与4,5,6,7与8分别可以再形成一个新类。
此时,形成的两个聚类是:C1={1,2,3,4},C2={5,6,7,8}。
甚至还可以将1,2,3,4,5,6,7,8形成一个聚类。
凝聚层次聚类法需要设定阀值,因此最终的聚类结果和设定的距离阀值有关。
SAS聚类分析程序

SAS聚类分析程序:聚类分析过程命令Data pgm33b;Input x1-x3;cards;9.30 30.55 8.7(样品数据)1.85 20.66 12.75;Proc cluster standard method= single nonormnosquare ccc pseudo out=tree;Proc tree data=tree horizontal spaces=1; run;Data pgm33bInput x1-x4;cards;9.30 30.55 8.7(样品数据)1.85 20.66 12.75;Proc cluster standard method=complete nonormnosquare ccc pseudo out=tree;Proc tree data=tree horizontal spaces=1; run;刷黑该块过程命令程序,提交便计算出相应聚类结果。
语句解释: 聚类指定的方法是在“method=”后面填入一个相应的选择项,它们是:single(最短距离法),complete(最长距离法),average(类平均法), centroid(重心法),median(中位数法),ward(离差平方和法),flexible (可变类平均法),density(非参数概率密度估计法),eml(最大似然法),twostage(两阶段密度法)。
主成分分析程序:1. 主成分分析实验程序例:主成分分析过程命令data socecon;input x1-x6;cards;16369 3504887 66047 2397739 198.46 104395513379 566257 4744 456100 76.96 2026379707 397183 1303 887034 18.88 10594810572 414932 1753 751984 27.67 12826112284 876667 18269 1015669 60.09 3327009738 604935 5822 1307908 30.54 22279916970 778830 2438 630014 76.64 27220310006 617436 13543 866013 58.59 22279410217 636760 9967 996912 34.55 16102520946 1380781 16406 526527 150.15 42693711469 720416 7141 853778 43.41 15727414165 1504005 29413 1025363 149.17 56889912795 966188 11580 723278 45.13 16531912762 584696 13583 343107 65.31 16645412008 501780 4986 278310 15.04 86575 11208 981367 13364 1295189 79.8 337947 12719 716491 4448 408796 15.68 99949 ;proc princomp out=aaa prefix=z;var x1-x6; run;data a2;set aaa;proc print;var z1-z2 ;run;。
SAS 聚类

1、类平均法(METHOD=AVERAGE)测量两类每对观测间的平均距离,2、重心法(METHOD=CENTROID)重心法测量两个类的重心(均值)之间的(平方)欧氏距离。
3、最长距离法(METHOD=COMPLETE)计算两类观测间最远一对的距离,4、最短距离法(METHOD=SINGLE)计算两类观测间最近一对的距离,5、密度估计法(METHOD=DENSITY)密度估计法按非参数密度来定义两点间的距离。
如果两个点和是近邻(两点距离小于某指定常数或在距离最近的若干点内)则距离是两点密度估计的倒数的平均,否则距离为正无穷。
密度估计有最近邻估计(K=)、均匀核估计(R=)和Wong 混合法(HYBRID)。
6、Ward最小方差法(或称Ward离差平方和法,METHOD=WARD)Ward方法并类时总是使得并类导致的类内离差平方和增量最小。
其它的聚类方法还有EML法、可变类平均法(FLEXIBLE)、McQuitty相似分析法(MCQUITTY )、中间距离法(MEDIAN)、两阶段密度估计法(TWOSTAGE)等。
Data d;Input name$ x;Datalines;li 56jin 58tong 59tie 61xi 62qian 65xin 89gai 95;Proc distance data=d method=euclid out=dist; var interval(x);id name;Run;Proc print data=dist;Id name;Run;proc cluster data=dist method=centroid;id name;var li--gai;run;proc tree h;id name;run;proc tree spaces=2 graphics horizontal h=n ; run;proc tree spaces=2 horizontal n=2 out=result; proc print data=result;run;proc freq data=result;table cluster;run;。
sas聚类分析(SAS)分解

个体与小类、小类与小类间“亲 疏程度”的度量方法
SPSS中提供了多种度量个体与小类、小类 与小类间“亲疏程度”的方法。与个体 间“亲疏程度”的测度方法类似,应首 先定义个体与小类、小类与小类的距离。 距离小的关系亲密,距离大的关系疏远。 这里的距离是在个体间距离的基础上定 义的,常见的距离有:
似程度通常可以用简单相关系数或者等 级相关系数等;一是个体间的差异程度 ,通常通过某种距离来测度。
1、定距型变量个体间距离的计算方式
欧式距离(Euclidean distance)
k
(xi yi )2 (73 66)2 (68 64)2 i1
平方欧式距离(Squared Euclidean distance ) 切比雪夫(Chebychev)距离
各变量间不应有较强的线性相关关系
学校
参加科研 人数
(人)
投入经费 (元)
立项课题 数(项)
样本的欧氏距离
元
万元
1
410
4380000
19
(1,2) 265000
81.623
2
336
1730000
21
(1,2) 218000
193.7
3
490
220000
8
(1,2)
47000
254.897
层次聚类
1 层次聚类的两种类型和两种方式 层次聚类又称系统聚类,简单地讲是指聚类过程
(1)间隔尺度。变量用连续的量来表示,如“ 各种奖金”、“各种津贴”等。
(2)有序尺度。指标用有序的等级来表示,如 文化程度分为文盲、小学、中学、中学以上 等有次序关系,但没有数量表示。
(3)名义尺度。指标用一些类来表示,这些类 之间没有等级关系也没有数量关系,如表中 的性别和职业都是名义尺度。
使用SAS进行数据分析的基础知识

使用SAS进行数据分析的基础知识一、SAS数据分析简介SAS(Statistical Analysis System)是一套全面的数据分析软件工具,它具备强大的数据处理和统计分析能力。
它适用于各种领域的数据分析,包括市场调研、金融分析、医疗研究等。
二、数据准备在进行SAS数据分析之前,首先要进行数据准备。
这包括数据的收集、整理和清洗。
收集数据可以通过调查问卷、实地观察、数据库查询等方式。
整理数据即将数据格式统一,包括去除重复数据、统一变量命名等。
清洗数据则是去除异常值、缺失值处理等。
三、SAS基础语法1. 数据集(Data set)的创建和导入SAS中的数据以数据集的形式存在,可以使用DATA步骤创建数据集,也可以从外部文件导入数据集。
导入数据可使用INFILE 语句指定文件位置,并使用INPUT语句将数据导入到数据集中。
2. 数据操作和处理SAS提供了多种数据操作和处理函数,如排序、合并、拆分等。
常用的函数有SUM、MEAN、COUNT、MAX、MIN等,它们可以对数据集中的变量进行统计和计算。
3. 数据可视化SAS提供了多种可视化方式,用于更直观地展示数据。
可以使用PROC SGPLOT语句进行绘图,如折线图、散点图、柱状图等。
还可以使用PROC TABULATE语句生成数据报表。
四、统计分析SAS强大的统计分析功能是其独特的优势之一。
以下为几种常用的统计分析方法:1. 描述统计分析描述统计分析用于对数据进行概括和描述。
可以使用PROC MEANS进行均值、中位数、标准差等统计指标的计算,使用PROC FREQ进行频数分析。
2. t检验t检验用于比较两组样本均值的差异是否显著。
可以使用PROC TTEST进行t检验分析,根据t值和显著性水平判断差异是否显著。
3. 方差分析方差分析用于比较两个或多个样本均值的差异是否显著。
可以使用PROC ANOVA进行方差分析,根据F值和显著性水平判断差异是否显著。
SAS(统计分析软件)
SAS(统计分析软件)SAS(全称STATISTICAL ANALYSIS SYSTEM,简称SAS)是全球最大的私营软件公司之一,是由美国北卡罗来纳州立大学1966年开发的统计分析软件。
1976年SAS软件研究所(SAS INSTITUTE INC)成立,开始进行SAS系统的维护、开发、销售和培训工作。
期间经历了许多版本,并经过多年来的完善和发展,SAS系统在国际上已被誉为统计分析的标准软件,在各个领域得到广泛应用。
中文名统计分析系统外文名statistical analysis system缩写SAS开发北卡罗来纳州立大学地区美国同类软件SPSS, RapidMiner, KNIME,SAP目录.1软件简介.2功能模块介绍.3SAS的特点.4市场规模软件简介1966年,美国农业部(USDA)收集到巨量的农业数据,急需一种计算机化统计程序来对其进行分析。
由美国国家卫生研究院(NIH)资助的八所大学联合会共同解决了这一问题。
最终,统计分析系统(statistical analysis system),也就是SAS应运而生,既给了SAS 公司一个响亮的名字,亦成为了公司化运作的起点。
[1]位于北卡罗来纳州首府罗利市的北卡罗来纳州立大学(NCSU)成为该联盟的领导者,因为其更为强大的大型中央处理计算机计算能力而胜出。
NCSU教职员工Jim Goodnight 和Jim Barr成为项目负责人。
Barr创建了整个架构,Goodnight则负责实施和实现架构上的各种功能特性,并拓展了系统的性能。
当NIH于1972年停止供资时,社团联盟同意为该项目提供资金,使NCSU能够继续开发维护系统运作,从而支持其统计分析需求。
[1]功能模块介绍SAS (Statistical Analysis System)是一个模块化、集成化的大型应用软件系统。
sas8.1它由数十个专用模块构成,功能包括数据访问、数据储存及管理、应用开发、图形处理、数据分析、报告编制、运筹学方法、计量经济学与预测等等。
SAS学习系列35. 聚类分析
35. 聚类分析(一)概述聚类分析,相当于“物以类聚”,用于对事物的类别面貌尚不清楚,甚至在事前连总共有几类都不能确定的情况下对数据进行分类。
而判别分析,必须事先知道各种判别的类型和数目,并且要有一批来自各判别类型的样本,才能建立判别函数来对未知属性的样本进行判别和归类。
聚类分析是把分类对象按一定规则分成组或类,这些组或类不是事先给定的而是根据数据特征而定的。
在同类的对象在某种意义上倾向于彼此相似,而在不同类里的这些对象倾向于不相似。
根据这种相似性的不同定义,聚类分析也有不同的方法。
聚类分析分为:对样品的聚类,对变量的聚类。
样品聚类:其统计指标是类与类之间距离,把每一个样品看成空间中的一个点,用某种原则规定类与类之间的距离,将距离近的点聚合成一类,距离远的点聚合成另一类。
变量聚类:其统计指标是相似系数,将比较相似的变量归为一类,而把不怎么相似的变量归为另一类,用它可以把变量的亲疏关系直观地表示出来。
(二)原理一、距离和相似系数1. 距离设有n 组样品,每组样品有p 个变量的数据如下:例如,X i 到X j 的闵科夫斯基距离定义为:11||, 1,pqqij ik jkk d x x i j n =⎛⎫=-≤≤ ⎪⎝⎭∑ q=2时为欧几里得距离;还有马氏距离:d ij = (X i -X j )T S -1(X i -X j )其中,X i =(x i1, …, x ip ),S -1为n 个样品的p ×p 的协方差矩阵的逆矩阵。
注:马氏距离考虑了观测变量之间的相关性和变异性(不再受各指标量纲的影响)。
距离选择的基本原则:(1)要考虑所选择的距离公式在实际应用中有明确的意义。
如欧氏距离就有非常明确的空间距离概念。
马氏距离有消除量纲影响的作用。
(2)要综合考虑对样本观测数据的预处理和将要采用的聚类分析方法。
如在进行聚类分析之前已经对变量作了标准化处理,则通常就可采用欧氏距离。
(3)应根据研究对象的特点不同做出具体分折。
SPSS聚类分析详解
指标 地区(样品) 1
2
3
456
性能
9 1 10
928
颜色
827
946
式样
728
357
用分类法对6个样品进行分类,以估计哪些地区最有可能经销 这类新产品?
按公式计算两两样品间的相似系数,得相似矩阵
Q (Coij) s(qij)
1
2
3
4
5
6
1 1
2 0.933 1
Q=
3
0.994
2)形成一个由小到大的分析系统。 3)把整个分类系统画成一张分类图
二、聚类统计量
首先定义一些分类统计指标 —— 刻画样或指标之间 的相似程度(这些统计指标称为聚类统计量)
在市场研究中,样品 —— 用作分类的事物
指标 —— 用来作为分类依据的变量。(如: 年龄、收入、销售量)
(一)相似系数(夹角余弦)
0.47
X4
0.93
X2
0.68
X7
X5
-0.94
0.49
X8
主要城市日照时数
注:连续变量
SPSS提供不同类间距 离的测量方法
1、组间连接法 2、组内连接法 3、最近距离法 4、最远距离法 5、重心法 6、中位数法 7、Ward最小偏差平 方和法
观测量概述表
聚类步骤,与图结合看!
4、5
输入格式
55列为城市
15位
输出F及t 统计量
平均法 重心法 最小距离法
输出结果:
新类中的观测值数
观测值之间距离的均方根
类间距离除以 观测值间距离 均方根得来
类数
指出被合并的类
F、t**2峰值(起伏)越大 说明分类显著
如何用SAS进行统计分析
如何用SAS进行统计分析SAS(统计分析系统)是一种用于数据分析和统计建模的软件工具。
它提供了一系列功能和程序,用于数据处理、统计分析、预测建模、图形展示和报告生成等。
本文将介绍如何使用SAS进行统计分析,涵盖数据导入、数据清洗、描述性统计分析、假设检验、回归分析和聚类分析等内容。
1. 数据导入和数据清洗在使用SAS进行统计分析之前,你需要将待分析的数据导入到SAS软件中。
SAS支持多种数据格式,包括CSV、Excel、Access等。
你可以使用SAS提供的PROC IMPORT过程将数据导入到SAS的数据集中。
导入数据后,你需要对数据进行清洗。
数据清洗的目的是去除数据中的错误、缺失或异常值,以确保数据的质量。
你可以使用SAS的数据步骤(DATA STEP)来处理数据,例如删除缺失值、填补缺失值、去除异常值等。
2. 描述性统计分析描述性统计分析是对数据进行总结和描述的过程。
它包括计算数据的中心趋势(均值、中位数、众数)、数据的离散程度(标准差、方差、极差)、数据的分布形态(偏度、峰度)等。
在SAS中,你可以使用PROC MEANS过程进行描述性统计分析。
该过程可以计算多个变量的均值、标准差、最小值、最大值、中位数等统计指标。
此外,你还可以使用PROC UNIVARIATE过程计算数据的偏度、峰度等统计值,并绘制直方图和箱线图来展示数据的分布情况。
3. 假设检验假设检验是对样本数据进行推断性统计分析的一种方法。
它用于判断观察到的样本差异是否显著,从而对总体参数进行推断。
在SAS中,你可以使用PROC TTEST过程进行双样本t检验、单样本t检验和相关样本t检验等。
此外,PROC ANOVA过程可以用于方差分析,PROC FREQ过程可以用于卡方检验。
4. 回归分析回归分析是研究因变量与自变量之间关系的一种统计分析方法。
它用于预测和解释因变量的变化,并评估自变量对因变量的影响程度。
在SAS中,你可以使用PROC REG过程进行简单线性回归分析和多元线性回归分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
x11• x12•
x21• x22•
重心(Centroid clustering)距离:个体 与小类的重心点的距离。重心点通常是 由小类中所有样本在各变量上的均值所 确定的点。
•
x1 , y1
•
x2 , y2
离差平方和法(Ward’s method):聚类过 程中使小类内离差平方和增加最小的两 小类应首先合并为一类。
系统聚类中每次合并的类与类之间的距离也可以 作为确定类数的一个辅助工具。在系统聚类过 程中,首先把离得近的类合并,所以在并类过 程中聚合系数(Agglomeration Coefficients) 呈增加趋势,聚合系数小,表示合并的两类的 相似程度较大,两个差异很大的类合到一起, 会使该系数很大。如果以y轴为聚合系数,x轴 表示分类数,画出聚合系数随分类数的变化曲 线,会得到类似于因子分析中的碎石图,可以 在曲线开始变得平缓的点选择合适的分类数。
相似性度量
从一组复杂数据产生一个相当简单的类结构,必 然要求进行“相关性”或“相似性“度量。在 相似性度量的选择中,常常包含许多主观上的 考虑,但是最重要的考虑是指标(包括离散的 、连续的和二态的)性质或观测的尺度(名义 的、次序的、间隔的和比率的)以及有关的知 识。 当对样品进行聚类时,“靠近”往往由某种距离 来刻画。另一方面,当对指标聚类时,根据相 关系数或某种关联性度量来聚类。
不同类型的指标,在聚类分析中,处理的方式是 大不一样的。总的来说,提供给间隔尺度的指 标的方法较多,对另两种尺度的变量处理的方 法不多。 聚类分析根据实际的需要可能有两个方向,一是 对样品,一是对指标聚类。第一位重要的问题 是“什么是类”?粗糙地讲,相似样品(或指 标)的集合称作类。由于经济问题的复杂性, 欲给类下一个严格的定义是困难的。
PROC TREE语句的重要选项有: DATA=数据集,指定从CLUSTER过程生成的OUTTREE= 数据集作为输入。 OUT=数据集,指定包含最后分类结果(每一个观测 属于哪一类,用一个CLUSTER变量区分)的输出数据 集。 NCLUSTERS=选项,由用户指定最后把样本观测分为 多少个类。 GRAPHICS,这是指定画谱系聚类的树图时使用高分辨 率图形(要求有SAS/GRAPH模块)。 HORIZONTAL,画树图时横向画。
1、定距型变量个体间距离的计算方式
欧式距离(Euclidean distance)
2 2 2 (x y ) (73 66) (68 64) i i i 1
k
平方欧式距离(Squared Euclidean distance ) 切比雪夫(Chebychev)距离
max xi yi max( 73 66 , 68 64)
准则1:任何类都必须在邻近各类中是突出的 ,即各类重心之间距离必须大。 准则2:各类所包含的元素都不要过分地多。 准则3:分类的数目应该符合使用的目的。 准则4:若采用几种不同的聚类方法处理,则 在各自的聚类图上应发现相同的类。
,聚类效果越好。但需 动态考察,即聚类到某一步时,样品已经 被分为k个类,下一步分为k-1类时,R2值 有明显下降,则认为分k个类合适。 2.伪F统计量:数值越大越可显著分为k个类 3.伪T统计量:数值越大上一次聚类的效果越 好。 4.半偏R2统计量:值越大上一次聚类的效果 越好。
(2 3)2 (4 3)2 2
2,4
(6 5.5)2 (5 5.5)2 0.5
6,5
(1 3)2 (5 3)2 8
1,5
红绿(2,4,6,5)8.75 离差平方和增加8.75-2.5=6.25 黄绿(6,5,1,5)14.75 离差平方和增加14.75-8.5=6.25 黄红(2,4,1,5)10-10=0 故按该方法的连接和黄红首先连接。
TREE过程用法
TREE过程可以把CLUSTER过程产生的OUTTREE= 数据集作为输入,画出谱系聚类的树图,并按 照用户指定的聚类水平(类数)产生分类结果 数据集。一般格式如下: PROC TREE DATA=输入聚类结果数据集 OUT=输 出数据集 GRAPHICS NCLUSTER=类数 选项; COPY 复制变量; RUN;
编号 A商场 B商场 C商场 D商场 E商场 购物环境 73 66 84 91 94 服务质量 68 64 82 88 90
聚类分析中“亲疏程度”的度 量
对“亲疏程度”的测度一般有2个角度: 一是个体间的相似程度,衡量个体间的相 似程度通常可以用简单相关系数或者等 级相关系数等;一是个体间的差异程度 ,通常通过某种距离来测度。
学校 参加科研 人数 (人) 410 336 490 投入经费 (元) 4380000 1730000 220000 立项课题 数(项) 19 21 8
(1,2) (1,2) (1,2) 样本的欧氏距离 元 265000 218000 47000 万元 81.623 193.7 254.897
1 2 3
凝聚方式聚类:其过程是,首先,每个个体自成一 类;然后,按照某种方法度量所有个体间的亲疏 程度,并将其中最“亲密”的个体聚成一小类, 形成n-1个类;接下来,再次度量剩余个体和小类 间的亲疏程度,并将当前最亲密的个体或小类再 聚到一类;重复上述过程,直到所有个体聚成一 个大类为止。可见,这种聚类方式对n个个体通过 n-1步可凝聚成一大类。 分解方式聚类:其过程是,首先,所有个体都属一 大类;然后,按照某种方法度量所有个体间的亲 疏程度,将大类中彼此间最“疏远”的个体分离 出去,形成两类;接下来,再次度量类中剩余个 体间的亲疏程度,并将最疏远的个体再分离出去; 重复上述过程,不断进行类分解,直到所有个体 自成一类为止。可见,这种聚类方式对包含n个个 体的大类通过n-1步可分解成n个个体。
系统聚类法 (hierarchical clustering method) 是聚类分析中诸方 法中用的最多者。 它包含下列步骤 ,见 右图
分类数的确定
到目前为止,我们还没有讨论过如何确定分类数 ,聚类分析的目的是要对研究对象进行分类, 因此如何选择分类数成为各种聚类方法中的主 要问题之一。谱系聚类法(系统聚类法)中我 们最终得到的只是一个树状结构图,从图中可 以看出存在很多类,但问题是如何确定类的最 佳个数。 实际应用中人们主要根据研究的目的,从实用的 角度出发,选择合适的分类数。Demir-men曾 提出了根据树状结构图来分类的准则:
最远邻居(Furthest Neighbor )距离: 个体与小类中每个个体距离的最大值。
组间平均链锁(Between-groups linkage )距离:个体与小类中每个个体距离的 平均值。
组内平均链锁(Within-groups linkage) 距离:个体与小类中每个个体距离以及 小类内各个体间距离的平均值。
聚类分析的思想
聚类分析是统计学中研究“物以类聚”问 题的多元统计分析方法。 聚类分析是根据样品或指标的“相似”特 征进行分类的一种多元统计分析方法。 例10.1 若我们需要将下列11户城镇居民按 户主个人的收入进行分类,对每户作了 如下的统计,结果列于下表。
某市2001年城镇居民户主个人收入数据
表中的8个指标,前6个是定量的,后2个是定性 的。如果分得更细一些,指标的类型有三种 尺度: (1)间隔尺度。变量用连续的量来表示,如“ 各种奖金”、“各种津贴”等。 (2)有序尺度。指标用有序的等级来表示,如 文化程度分为文盲、小学、中学、中学以上 等有次序关系,但没有数量表示。 (3)名义尺度。指标用一些类来表示,这些类 之间没有等级关系也没有数量关系,如表中 的性别和职业都是名义尺度。
个体 y
1 0
个体x
1
0
A
C
B
D
聚类分析的几点说明
所选择的变量应符合聚类的要求:所选变量应能够从不同的 侧面反映我们研究的目的; 各变量的变量值不应有数量级上的差异(对数据进行标准化 处理):聚类分析是以各种距离来度量个体间的“亲疏” 程度的,从上述各种距离的定义看,数量级将对距离产生 较大的影响,并影响最终的聚类结果。 各变量间不应有较强的线性相关关系
k
Phi方(Phi-Square measure)距离
[ xi E ( xi )]2 k [ yi E ( yi )]2 E ( xi ) E ( yi ) i 1 i 1 phisq( x, y) n
k
3、二值(Binary)变量个体间距离的计算方式 简单匹配系数(Simple Matching) 雅科比系数(Jaccard) 简单匹配系数表
CLUSTER过程用法
CLUSTER过程的一般格式为: PROC CLUSTER DATA=输入数据集 METHOD=聚类方法 选项; VAR 聚类用变量; COPY 复制变量; RUN;
•METHOD=选项,这是必须指定的,此选项决定我们要用的聚 类方法,主要由类间距离定义决定。方法有AVERAGE、 CENTROID、COMPLETE、SINGLE、DENSITY、WARD、 EML、FLEXIBLE、MCQUITTY 、MEDIAN等 •DATA=数据集,可以是原始观测数据集,也可以是距离矩阵 数据集。 •OUTTREE=输出谱系聚类树数据集,把谱系聚类树输出到一个 数据集,可以用TREE过程绘图并实际分类。 •STANDARD选项,把变量标准化为均值0,标准差1。 •PSEUDO选项和CCC选项。PSEUDO选项要求计算伪F和 伪 统计量,CCC选项要求计算 、半偏 和CCC统计量。其中CCC统计量也是一种考察聚类效果的统计 量,CCC较大的聚类水平是较好的。
Block距离
x i yi 73 66 68 64
i 1
k
2、计数变量个体间距离的计算方式
卡方(Chi-Square measure)距离