Mybayes 构建系统发生树方法
贝叶斯网络构建算法

贝叶斯网络构建算法贝叶斯网络(Bayesian Network)是一种概率图模型,用于表示和推断变量之间的因果关系。
构建一个准确、有效的贝叶斯网络需要采用相应的构建算法。
本文将介绍几种常用的贝叶斯网络构建算法及其应用。
一、完全数据集算法完全数据集算法是贝叶斯网络构建中最简单、最常用的方法之一。
它假设已有一个完整的数据集,其中包含了所有要构建贝叶斯网络所需的信息。
该算法的主要步骤如下:1. 数据预处理:对数据进行清洗、归一化等预处理操作,确保数据的准确性和一致性。
2. 变量分析:根据数据集对变量之间的关系进行分析,确定要构建贝叶斯网络的变量。
3. 贝叶斯网络结构初始化:将变量之间的关系表示为图的结构,可以使用邻接矩阵或邻接链表等数据结构进行存储。
4. 结构学习:利用数据集中的频数统计等方法,通过学习训练数据集中的概率分布来确定贝叶斯网络结构中的参数。
5. 参数学习:在确定了贝叶斯网络结构后,进一步学习网络中各个变量之间的条件概率分布。
6. 结果评估:使用评估指标如准确率、精确率和召回率等来评估生成的贝叶斯网络模型的性能。
完全数据集算法的优点是能够利用完整数据构建准确的贝叶斯网络模型,但它的缺点是对于大规模的数据集,计算成本较高。
二、半监督学习算法半监督学习算法是一种使用有标记和无标记数据进行贝叶斯网络构建的方法。
这种方法可以在数据集不完整的情况下也能获得较好的贝叶斯网络模型。
以下是半监督学习算法的主要步骤:1. 数据预处理:对有标记和无标记数据进行预处理,清洗、归一化等操作。
2. 初始化:使用有标记数据初始化贝叶斯网络结构,可以采用完全数据集算法。
3. 标记传播:通过标记传播算法,将有标记数据的标签扩散到无标记数据中,这样可以在无需标记大量数据的情况下获得更多的有关因果关系的信息。
4. 参数学习:在获得了更多的有标记数据后,使用这些数据进行参数学习,并更新贝叶斯网络模型。
5. 结果评估:使用评估指标对生成的贝叶斯网络模型进行评估。
建系统发育树步骤
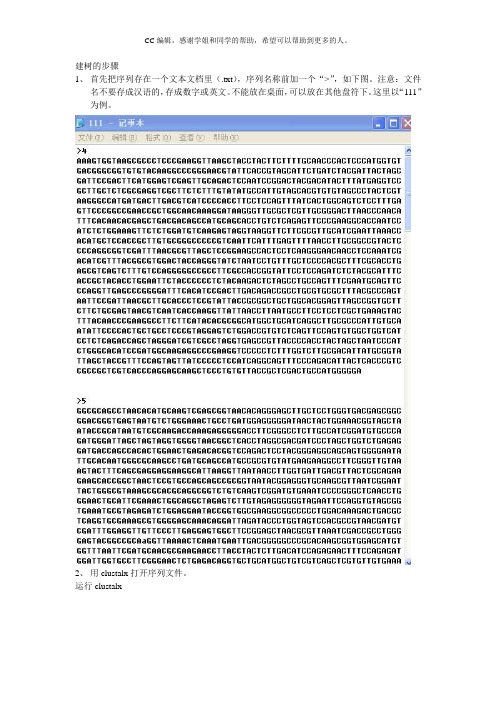
建树的步骤1、首先把序列存在一个文本文档里(.txt),序列名称前加一个“>”,如下图。
注意:文件名不要存成汉语的,存成数字或英文。
不能放在桌面,可以放在其他盘符下。
这里以“111”为例。
2、用clustalx打开序列文件。
运行clustalx点击“File”,选择Load Sequences,会弹出查找对话框,选择111所在的路径后打开。
如下图点击Aligment 选择Do Complete Aligment,选择输出文件路径,默认和111文本文档在同一个目录下。
点OK即可执行完Aligment后,序列被对齐(如果明显没有对齐,说明有反向或者互补序列,用DNAMAN或者DNASTAR进行序列的调整后再进行对齐),并产生两个文件“111.aln”“111.dnd”。
关闭clustalx。
运行MEGA点击File,选择convert to MEGA format,打开“111.aln”点OK 出现拉动滚动条到最后将#*都删去然后点工具栏的保存然后关闭两个窗口看到MEGA主界面选择找到MEGA文件格式文件 111点打开,出现下图我们选择第一个核酸序列点OK出现下列对话框是否是蛋白质编码的核酸序列我们点“NO”出现点击关闭,返回主窗口点击选择bootstrap test of tree 选择我们要建树的类型以NJ (neighbor-joining)树为例点可以修改参数,修改好后点compute计算机会自动测算,生成一个树如果对树不满意,可以用左侧的工具来修改CC编辑,感谢学姐和同学的帮助,希望可以帮助到更多的人。
点可以保存为MEGA 识别的文件,点击可以保存为其他格式。
贝叶斯法构建系统发育树

贝叶斯法构建系统发育树1.打开PAUP软件,打开目标文件和primates文件,将目标文件修改成primates文件格式。
2. 用modeltest3.7软件分析模型参数。
3. 打开mrbayes软件,文件输入。
命令:>execute 文件名.nex4. 设置参数,模型(上面modeltest3.7软件分析模型参数)。
命令:>lset nst=6/2 rates =gamma/invgamma/propinv,若要检查模型的参数,输入命令showmodel。
若设定lset nst=2,需输入命令report tratio=dirichlet。
3.1 >mcmc ngen=100000(1000000) (samplefreq=10(100)),注意:代数可以先设为10000,以便估计时间的长短。
>help mcmc来确认设置。
3.2 运行结束前,标准误差要小于0.01,否则增加代数,继续运行4.1 >sump burnin=250(2500);抽样的25%划为老化样本,舍去。
PSRF值需约等于1.0,否则要运行更长时间。
4.2 >sumt burnin=250(2500),输出所得的进化树,可用treeview打开.Modeltest 3.7基本操作步骤(中文)Moedltest是进行似然法计算必须的软件之一,它可以帮助大家为所获数据选择最佳的模型进行计算,得到最优的结果。
目前该软件的这里介绍一下Modeltest3.7的基本操作步骤:1. 下载Modeltest3.7软件和模型文件modelblockPAUPb10.txt;2. 将序列同源排序后保存为XXX.nex文件;全部拷贝到C盘。
3. 打开模型文件,将文件内容拷贝到XXX.nex文件的末尾,可以将该文件另存为XXX.test.model.nex,保留原来的*.nex文件;;4. 打开PAUP4.0应用程序,将XXX.test.model.nex文件拖入PAUP窗口,然后在命令行输入:execute XXX.test.model.nex,回车后PAUP就开始对数据进行模型估计,结果将保存为model.scores文件和modelfit两个文件,文件位于PAUP4.0软件的文件夹中;5. 将model.scores文件拷贝到Modeltest3.7.win.exe所在的文件夹中。
构建系统发生树的方法

构建系统发生树的方法构建系统发生树是一种对于系统进行分析和优化的有效方法,在实践中有许多种方法可以构建系统发生树。
以下是10条关于构建系统发生树的方法,并对每条方法进行详细描述。
1. 系统流程图系统流程图是一种常见的构建系统发生树的方法。
通过对系统的主要流程进行图形化的描述,可以更好地了解系统的组成部分以及它们之间的关系。
系统流程图往往是由开始和结束节点、处理节点和决策节点组成的。
前者用来表示系统的输入和输出,后者则用来表示系统的核心过程和逻辑判断。
2. 系统分层结构图系统分层结构图是将系统按照层次进行组织和描述的一种方法。
通过将系统分解为多个层次,并描述这些层次之间的关系,可以更好地了解系统的组成和结构。
这种方法通常用于处理大型和复杂的系统,能够帮助开发人员更好地管理和优化系统。
3. 系统模块图系统模块图是一种用于展示系统模块和它们之间关系的图形化表示方法。
系统模块图通常由多个模块和模块之间的输入和输出组成。
每个模块通常都对应一个特定的功能或业务逻辑。
通过了解系统中各个模块之间的关系和作用,可以更好地理解系统的架构和逻辑。
4. 系统数据流图系统数据流图是一种用来描述系统数据传输流程的图形化表示方法。
该方法通常由多个数据流和与这些数据流相关的处理过程组成。
每个数据流都对应一个特定的数据,而每个处理过程通常都包含两个或多个数据流。
通过了解系统中各个数据流之间的关系和流动过程,可以更好地理解系统的功能和性能。
5. 系统性能图系统性能图是一种用于展示系统性能指标和变化趋势的图形化表示方法。
该方法通常包括多个参数和变量,比如系统响应时间、吞吐量、并发数等。
通过了解系统性能参数的表现和变化趋势,可以更好地理解系统的性能瓶颈和瓶颈优化的方向。
6. 事件序列图事件序列图是一种用于展示系统中事件和处理过程之间关系的图形化表示方法。
该方法通常由一个或多个故障事件和与之相关的处理过程组成。
通过了解系统中各个事件和处理过程之间的关系,可以更好地了解系统的运行过程和故障排查过程。
重建系统发育树(PAUP的ML法和贝叶斯法)

重建系统发育树(PAUP的ML法和贝叶斯法)1 多重序列比对将待比对的序列以fasta格式保存,利用clustalx2.1或MEGA中的clustalW 软件进行多序列比对。2 保守区的选择将1得到的序列提交Gblock在线服务器(http://www.phylogeny.fr/one_task.cgi?task_type=gblocks),得到保守区的序列.fasta,并通过MEGA软件将其转换为.nex;3 核苷酸替换饱和度检测用DAMBE 软件验证替换饱和。只要比较ISS和ISS.c 值大小及显著与否,即可。当ISS小于ISS.c 且p=0.0000(极显著),就说明没序列替换未饱和,可以建树。4 核苷酸替换模型的选择在进行系统发育分析过程中,建树序列的进化模型选择是至关重要的一步,尤其对进化模型敏感的ML法和BI法。通过MrMTgui 软件选择核酸替代模型。4.1 安装PAUP、ModelTest (或MrModelTest) 软件,然后再安装MrMTgui 软件。配置MrMTgui,分别设置PAUP、ModelTest和MrModelTest路径。4.2 运行PAUP点击Run Paup,选择2中.nex文件。当模型参数值计算完毕,程序会提示是否立即启动分析,选择“否”,先保存scores文件。然后选择,运行MrModeltest,就得到模型数据了。一种是基于hLRT 标准选择的模型,另一种是基于AIC标准选择的模型,一般选择AIC标准。4.3添加模型参数,添加到建树的文件 .nex。5 使用PAUP软件重建ML树(运行时间较长)将用AIC标准选择的模型参数直接拷贝到Nexus文件的最后。参数设置:set criterion=likelihood 转化为似然法。outgroup 1 2 …….设定外类群bootstrap nreps=1000 keepall=yes brlens=yes 此命令设定循环次数为1000次(具体次数可根据实际情况自定),保存枝长。describetrees 1/plot=both brlens=yes 此命令设定了描述树的方式,即phylogram和cladogram均显示,显示枝长。最后用 savetrees from=1 to=1000 保存树。6 贝叶斯树6.1在Nexus文件的最后加入一个MrBayes block。(MEGA输出Nexus格式文件不能被Mrbayes识别,因此要进行修改)格式修改前:格式修改后:6.2运行mrbayes.exe,在命令行界面中输入转换或者修改的Nexus文件,点击回车,最后生成 *.tre,即最终的BI树。用Figtree 查看生成 .tre在运行1000代后都会显示 Average standard deviation of split frequencies。注:当这个值 < 0.01 时,说明两次运行的结果差异显著,Convergence 已经达到,这时可以输入 no 终止运行;这个值<0.05也可以,但不能>0.05。
贝叶斯法系统树

贝叶斯法系统树全文共四篇示例,供读者参考第一篇示例:贝叶斯法系统树(Bayesian System Tree,BST)是一种基于贝叶斯方法的机器学习模型,它结合了贝叶斯网络和决策树的优点,能够有效地处理复杂的分类和回归问题。
BST模型不仅具有较高的准确率和鲁棒性,还能够提供对模型推理过程的可解释性,因此在各个领域都取得了广泛的应用。
BST模型的核心思想是将贝叶斯网络和决策树进行结合,通过后验概率的计算来表示不同特征之间的关联性,并通过递归划分特征空间来构建树结构。
在进行预测时,BST模型会同时考虑先验知识和数据信息,从而得到更加精确和可靠的结果。
在构建贝叶斯法系统树模型时,首先需要确定节点的分裂准则。
一般而言,可以采用信息增益或基尼系数等指标来评估节点的分裂效果,从而选择最优的分裂点。
接着,需要确定每个叶子节点的概率分布,一般可以采用最大后验估计或极大似然估计等方法来估计参数值。
通过计算后验概率来选择最优的划分方式,从而得到最终的贝叶斯法系统树模型。
贝叶斯法系统树模型具有许多优点。
它具有较高的准确率和泛化能力,能够有效地处理复杂的分类和回归问题。
BST模型能够提供对模型推理过程的可解释性,使得用户可以清晰地了解模型的判断依据。
BST模型还可以处理缺失数据和噪声数据,具有较好的鲁棒性和稳定性。
在实际应用中,贝叶斯法系统树模型已经被广泛应用于各个领域。
在医疗领域,BST模型可以帮助医生进行疾病诊断和预测治疗效果;在金融领域,BST模型可以帮助分析师进行股票价格预测和风险评估;在智能驾驶领域,BST模型可以帮助自动驾驶汽车进行交通预测和路径规划。
第二篇示例:贝叶斯法系统树是一种基于贝叶斯理论的决策树算法,它将贝叶斯理论和系统树结合起来,能够有效地处理不确定性和推理问题。
这种算法在机器学习和数据挖掘领域有着广泛的应用,可以用于分类、回归和聚类等任务。
贝叶斯法系统树的基本原理是将特征空间划分成若干个区域,每个区域内的数据点都具有相同的特征。
贝叶斯法系统树

贝叶斯法系统树全文共四篇示例,供读者参考第一篇示例:贝叶斯法系统树的基本原理是基于贝叶斯定理,通过表示变量之间的依赖关系来建立模型。
在一个贝叶斯法系统树中,每个节点表示一个变量,每条边表示一个变量之间的依赖关系。
每个节点还包含一个概率分布,用于描述该节点给定其父节点的条件概率。
通过这种方式,可以构建一个树形结构,描述多个变量之间的复杂关系。
在进行推理或预测时,可以利用这个模型计算后验概率,从而得到最可能的结果。
贝叶斯法系统树在许多领域都有广泛的应用。
在医疗诊断领域,可以利用贝叶斯法系统树建立疾病诊断模型,从而帮助医生更准确地做出诊断。
在金融领域,可以利用贝叶斯法系统树进行信用评估,预测客户的信用评分和违约风险。
在自然语言处理领域,可以利用贝叶斯法系统树进行文本分类、情感分析等任务。
贝叶斯法系统树在处理不确定性信息和复杂关系时具有很大的优势,被广泛应用于各种领域。
贝叶斯法系统树的优点在于可以表示复杂的概率关系,处理不确定性信息,同时具有较强的推理和预测能力。
它可以利用概率分布描述变量的不确定性,通过条件概率计算后验概率,从而得到最可能的结果。
贝叶斯法系统树还具有参数少、计算简单、结构清晰等优点,适用于大规模数据和复杂模型。
贝叶斯法系统树也存在一些缺点,如模型训练过程需要大量数据、难以处理高维数据等。
在未来的研究中,需要进一步提高模型的效率和准确性,解决这些问题。
第二篇示例:贝叶斯法系统树(Bayesian network)是一种用概率和图形结构描述复杂系统的方法。
它是基于贝叶斯定理的一种概率图模型,能够对不同变量之间的关系进行建模,并利用条件概率来推断未知变量的概率分布。
贝叶斯法系统树最早由美国学者Pearl在1988年提出,是一种用来表示变量之间概率关系的有向无环图(DAG)。
在这种图中,节点表示随机变量,边表示变量之间的依赖关系。
每个节点都代表一个随机变量,它的父节点则表示影响该节点的因素。
贝叶斯法系统树通常由两部分组成:一个结构模型和一个概率模型。
系统发育树构建方法优劣

2.最大简约法最大简约法(maximum parsimony method,MP)最早是基于形态特征分类的需要发展起来的,具体的算法有许多不同版本,其中有些已被广泛地应用于分子进化研究中。
利用MP方法重建系统发生树,实际上是一个对给定OTUs其所有可能的树进行比较的过程。
对某一个可能的树,首先对每个位点祖先序列的核苷酸组成做出推断,然后统计每个位点用来阐明差异的核苷酸最小替换数目。
在整个树中,所有信息简约位点最小核苷酸替换数的总和称为树的长度(常青和周开亚,1998)。
MP法是一种优化标准,这种标准遵循“奥卡姆剃刀原则(Occam’S Razor principle)”:对数据最好的解释也是最简单的,而最简单的所需要的特别假定也最少。
MP法基于进化过程中所需核苷酸(或氨基酸)替代数目最少的假说,对所有可能正确的拓扑结构进行计算并挑选出所需替代数最小的拓扑结构作为最优系统树,也就是通过比较所有可能树,选择其中长度最小的树作为最终的系统发生树,即最大简约树(maximum parsimony tree)。
与其他建树方法相比,MP法无需引入处理核苷酸或者氨基酸替代时所必需的假设(替代模型)。
同时,MP法对于分析某些特殊的分子数据(如插入序列和插入/缺失)有用。
在分析的序列位点上没有回复突变或平行突变,且被检验的序列位点数很大的时候,MP法能够获得正确的(真实)系统树。
但MP法推导的树不是唯一的,在分析序列上存在较多的回复突变或平行突变,而被检验的序列位点数又比较少的时候,最大简约法可能会出现建树错误。
故MP法适用于序列残基差别小,具有近似变异率,包含信息位点比较多的长序列。
3.最大似然法最大似然法(maximum likelihood method,MI。
)是20世纪60年代末期由于对地生物信息学分析实践震波和水声信号等处理的需要而发展起来的一种非线性谱估计方法。
最早由凯佩用这种方法对空间阵列接收信号进行频率波数谱估值,后来推广到对时问信号序列的功率谱估值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
简单步骤
1 序列的比对,然后将比对好的序列转化成.nex格式
2 运行MrBayes,简单步骤如下:(依次输入命令,完成简单也最常用的分析):Execute filename.nex,打开待分析文件,文件必须和mrbayes程序在同一目录下。
Lset nst=6 rates=invgamma,该命令设置进化模型为with gamma-distributed rate variation across sites和a proportion of invariable sites的GTR模型。
模型可根据需要更改,不过一般无须更改。
3 mcmc ngen=10000 samplefreq=10,保证在后面的可能性分布中probability distribution至少取到1000个样品。
默认取样频率:every 100th generation。
4 如果分裂频率分支频率split frequencies的标准偏差standard deviation在100,000代generations以后低于0.01,当程序询问:“Continue the analysis?(yes/no)”,回答no;如果高于0.01,yes继续直到该值低于0.01。
5 sump burnin=250(在此为1000个样品,即任何相当于你取样的25%的值),参数总结summarize the parameter,程序会输出一个关于样品(sample)的替代模型参数的总结表,包括mean,mode和95 % credibility interval of each parameter,要保证所有参数PSRF(the potential scale reduction factor)的值接近1.0,如果不接近,分析时间要延长。
6 sumt burnin=250,总结树summarize tree。
程序会输出一个具有每一个分支的posterior probabilities的树以及一个具有平均枝长mean branch lengths的树。
这些树会被保存在一个可以由treeview等读取的树文件中。