Hadoop入门—Linux下伪分布式计算的安装与wordcount的实例展示
Hadoop环境搭建及wordcount实例运行
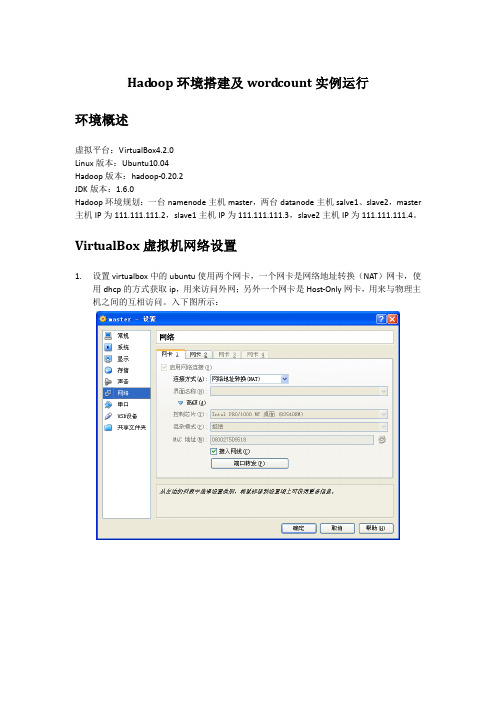
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
Hadoop伪分布式安装

Hadoop伪分布式安装1.安装Hadoop(伪分布式)
上传Hadoop
将hadoop-2.9.2.tar.gz 上传到该目录
解压
ls
将Hadoop添加到环境变量
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出vim
验证环境变量是否正确hadoop version
修改配置文件hadoop-env.sh
保存并退出vim
修改配置文件core-site.xml
保存并退出vim
修改配置文件hdfs-site.xml
</property>
保存并退出vim
格式化HDFS
hdfs namenode -format
格式化成功的话,在/bigdata/data目录下可以看到dfs目录
启动NameNode
启动DataNode
查看NameNode管理界面
在windows使用浏览器访问http://bigdata:50070可以看到HDFS的管理界面
如果看不到,(1)检查windows是否配置了hosts;
位于C:\Windows\System32\drivers\etc\hosts
关闭HDFS的命令
2.配置SSH免密登录生成密钥
回车四次即可生成密钥
复制密钥,实现免密登录
根据提示需要输入“yes”和root用户的密码
新的HDFS启停命令
免密登录做好以后,可以使用start-dfs.sh和stop-dfs.sh命令启停HDFS,不再需要使用hadoop-daemon.sh脚本
stop-dfs.sh
注意:第一次用这个命令可能还是需要输入yes,按提示输入即可。
hadoop集群搭建实训报告

实训项目名称:搭建Hadoop集群项目目标:通过实际操作,学生将能够搭建一个基本的Hadoop集群,理解分布式计算的概念和Hadoop生态系统的基本组件。
项目步骤:1. 准备工作介绍Hadoop和分布式计算的基本概念。
确保学生已经安装了虚拟机或者物理机器,并了解基本的Linux命令。
下载Hadoop二进制文件和相关依赖。
2. 单节点Hadoop安装在一台机器上安装Hadoop,并配置单节点伪分布式模式。
创建Hadoop用户,设置环境变量,编辑Hadoop配置文件。
启动Hadoop服务,检查运行状态。
3. Hadoop集群搭建选择另外两台或更多机器作为集群节点,确保网络互通。
在每个节点上安装Hadoop,并配置集群节点。
编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等。
配置SSH无密码登录,以便节点之间能够相互通信。
4. Hadoop集群启动启动Hadoop集群的各个组件,包括NameNode、DataNode、ResourceManager、NodeManager 等。
检查集群状态,确保所有节点都正常运行。
5. Hadoop分布式文件系统(HDFS)操作使用Hadoop命令行工具上传、下载、删除文件。
查看HDFS文件系统状态和报告。
理解HDFS的数据分布和容错机制。
6. Hadoop MapReduce任务运行编写一个简单的MapReduce程序,用于分析示例数据集。
提交MapReduce作业,观察作业的执行过程和结果。
了解MapReduce的工作原理和任务分配。
7. 数据备份和故障恢复模拟某一节点的故障,观察Hadoop集群如何自动进行数据备份和故障恢复。
8. 性能调优(可选)介绍Hadoop性能调优的基本概念,如调整副本数、调整块大小等。
尝试调整一些性能参数,观察性能改善情况。
9. 报告撰写撰写实训报告,包括项目的目标、步骤、问题解决方法、实验结果和总结。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
hadoop伪分布式 实验报告模板 -回复

hadoop伪分布式实验报告模板-回复什么是Hadoop伪分布式, 以及如何进行实验的报告。
实验报告模板:一、引言(100-200字)在大数据时代,Hadoop作为一个开源的分布式计算框架,被广泛应用于数据处理和分析领域。
Hadoop伪分布式是搭建在单台机器上的分布式环境的模拟实验环境,可以帮助学习者理解和掌握Hadoop的基本概念、架构和操作方法。
本实验报告将详细介绍Hadoop伪分布式的搭建和实验过程,并总结所获得的经验和教训。
二、目的和背景(200-300字)Hadoop伪分布式的实验目的是为了让学习者能够在一台机器上模拟分布式环境,学习和掌握Hadoop的基本操作和流程。
通过这个实验,学习者可以深入了解Hadoop的整体架构,包括HDFS(Hadoop分布式文件系统)和MapReduce计算框架,以及相关的工具和命令。
三、实验环境和工具(200-300字)在本次实验中,我们使用以下工具和环境进行Hadoop伪分布式搭建和实验:1. Hadoop2.10.0:作为分布式计算框架的核心组件,用于数据存储和处理;2. JDK 1.8:用于支持Hadoop的Java编程环境;3. VirtualBox 6.0:用于创建虚拟机环境,模拟分布式部署;4. Ubuntu 18.04 LTS:作为操作系统,提供稳定和可靠的环境;5. SSH工具:用于在虚拟机之间进行远程登录和通信。
四、实验步骤(800-1000字)1. 下载和安装Hadoop:根据Hadoop官方网站上的说明,下载适合的Hadoop版本并进行安装。
解压缩Hadoop安装包,并配置相应的环境变量。
2. 配置SSH无密登录:为了方便虚拟机之间的通信和远程登录,需要进行SSH无密登录的配置。
生成SSH密钥对,并将公钥分发到所有虚拟机中。
3. 配置Hadoop伪分布式:编辑Hadoop的配置文件,主要包括core-site.xml、hdfs-site.xml和mapred-site.xml。
熟悉常用的linux操作和hadoop操作实验报告

熟悉常用的linux操作和hadoop操作实验报告本实验主要涉及两个方面,即Linux操作和Hadoop操作。
在实验过程中,我深入学习了Linux和Hadoop的基本概念和常用操作,并在实际操作中掌握了相关技能。
以下是我的实验报告:一、Linux操作1.基本概念Linux是一种开放源代码的操作系统,它允许用户自由地使用、复制、分发和修改系统。
Linux具有更好的性能、更高的安全性和更好的可定制性。
2.常用命令在Linux操作中,一些常用的命令包括:mkdir:创建目录cd:更改当前目录ls:显示当前目录中的文件cp:复制文件mv:移动文件rm:删除文件pwd:显示当前所在目录chmod:更改文件权限chown:更改文件所有者3.实验操作在实验中,我对Linux的文件系统、文件权限、用户与组等进行了学习和操作。
另外,我还使用Linux命令实现了目录创建、文件复制、删除等操作。
二、Hadoop操作1.基本概念Hadoop是一种开源框架,用于处理大规模数据和分布式计算。
它使用Hadoop分布式文件系统(HDFS)来存储数据,使用MapReduce来处理大规模数据集。
2.常用命令在Hadoop操作中,一些常用的命令包括:hdfs dfs:操作HDFS文件系统hadoop fs:操作Hadoop分布式文件系统hadoop jar:运行Hadoop任务hadoop namenode -format:格式化文件系统start-all.sh:启动所有Hadoop服务3.实验操作在实验中,我熟悉了Hadoop的安装过程、配置过程和基本概念。
我使用Hadoop的命令对文件系统进行操作,如创建、删除、移动文件等。
此外,我还学会了使用MapReduce处理大规模数据集。
总结通过本次实验,我巩固了Linux和Hadoop操作的基本知识和技能。
我深入了解了Linux和Hadoop的基本概念和常用操作,并学会了使用相关命令进行实际操作。
hadoop伪分布式搭建实验报告心得

Hadoop伪分布式搭建实验报告心得一、实验目的1. 掌握Hadoop的基本原理和架构。
2. 学习并实践Hadoop的伪分布式环境的搭建。
3. 熟悉Hadoop的基本操作和管理。
二、实验环境1. 操作系统:CentOS 7.x2. Hadoop版本:2.x3. Java版本:1.8三、实验步骤1. 安装JDK首先需要在服务器上安装Java开发工具包(JDK),可以从Oracle官网下载对应版本的JDK安装包,然后按照提示进行安装。
2. 配置环境变量编辑/etc/profile文件,添加以下内容:```bashexport JAVA_HOME=/usr/local/java/jdk1.8.0_xxxexport PATH=$JAVA_HOME/bin:$PATH```使配置生效:```bashsource /etc/profile```3. 下载并解压Hadoop从Apache官网下载Hadoop的tar包,然后解压到指定目录,例如:/usr/local/hadoop。
4. 配置Hadoop环境变量编辑~/.bashrc文件,添加以下内容:```bashexport HADOOP_HOME=/usr/local/hadoopexport PATH=$HADOOP_HOME/bin:$PATH```使配置生效:```bashsource ~/.bashrc```5. 配置Hadoop的核心配置文件复制一份hadoop-env.sh.template文件到hadoop-env.sh,并修改其中的JAVA_HOME 为实际的JDK路径。
编辑core-site.xml文件,添加以下内容:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>```编辑hdfs-site.xml文件,添加以下内容:```xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>```6. 格式化HDFS文件系统在Hadoop安装目录下执行以下命令:```bashhadoop namenode -format```7. 启动Hadoop集群执行以下命令启动Hadoop集群:```bashstart-all.sh```8. 验证Hadoop集群状态执行以下命令查看Hadoop集群状态:```bashjps | grep Hadoop```如果看到NameNode、SecondaryNameNode、DataNode等进程,说明Hadoop集群已经成功启动。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
开始研究一下开源项目hadoop,因为根据本人和业界的一些分析,海量数据的分布式并行处理是趋势,咱不能太落后,虽然开始有点晚,呵呵。
首先就是安装和一个入门的小实例的讲解,这个恐怕是我们搞软件开发的,最常见也最有效率地入门一个新鲜玩意的方式了,废话不多说开始吧。
本人是在ubuntu下进行实验的,java和ssh安装就不在这里讲了,这两个是必须要安装的,好了我们进入主题安装hadoop:
1.下载hadoop-0.20.1.tar.gz:
/dyn/closer.cgi/hadoop/common/
解压:$ tar –zvxf hadoop-0.20.1.tar.gz
把Hadoop 的安装路径添加到环/etc/profile 中:
export HADOOP_HOME=/home/hexianghui/hadoop-0.20.1
export PATH=$HADOOP_HOME/bin:$PATH
2.配置hadoop
hadoop 的主要配置都在hadoop-0.20.1/conf 下。
(1)在conf/hadoop-env.sh 中配置Java 环境(namenode 与datanode 的配置相同):
$ gedit hadoop-env.sh
$ export JAVA_HOME=/home/hexianghui/jdk1.6.0_14
3.3)配置conf/core-site.xml, conf/hdfs-site.xml 及conf/mapred-site.xml(简单配置,datanode 的配置相同)
core-site.xml:
<configuration>
<!--- global properties -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/yangchao/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name></name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:( replication 默认为3,如果不修改,datanode 少于三台就会报错)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
4.运行hadoop
首先进入hadoop所在目录,执行格式化文件系统bin/hadoop namenode –format 启动hadoop: bin/start-all.sh
用jps命令查看进程,显示:
yangchao@yangchao-VirtualBox:~/Downloads/hadoop-0.20.203.0/test-in$ jp s
5238 TaskTracker
4995 SecondaryNameNode
4836 DataNode
4687 NameNode
5077 JobTracker
7462 Jps
既是正常的,接下来要上传数据到文件系统里
还有就是使用web 接口。
访问http://localhost:50030 可以查看JobTracker 的运行状态。
访问http://localhost:50060 可以查看TaskTracker 的运行状态。
访问http://localhost:50070 可以查看NameNode 以及整个分布式文件系统的状态,浏览分布式文件系统中的文件以及log 等。
5.运行wordcount.java
在hadoop所在目录里有几个jar文件,其中hadoop-examples-0.20.203.0.jar就是我们需要的,它里面含有wordcount,咱们使用命令建立测试的文件
(1)先在本地磁盘建立两个输入文件file01 和file02:
$ echo “Hello World Bye World” > file01
$ e cho “Hello Hadoop Goodbye Hadoop” > file02
(2)在hdfs 中建立一个input 目录:$ hadoop fs –mkdir input
(3)将file01 和file02 拷贝到hdfs 中:
$ hadoop fs –copyFromLocal /home/hexianghui/soft/file0* input
(4)执行wordcount:
$ hadoop jar hadoop-0.20.1-examples.jar wordcount input output
(5)完成之后,查看结果:
$ hadoop fs -cat output/part-r-00000
结果为:
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
是不是很神奇的玩意呢,这是在单机上实现hadoop的应用小实例,以后有机会再来一篇真正的分布式的,前提是需要三台机器,哎离开了学校没有实验室确实不好弄了。