hadoop2.7.2 伪分布式安装
《Hadoop大数据技术》课程理论教学大纲

《Hadoop大数据技术》课程教学大纲一、课程基本情况课程代码:1041139083课程名称(中/英文):Hadoop大数据技术/Hadoop Big Data Technology课程类别:专业必修课学分:3.5总学时:56理论学时:32实验/实践学时:24适用专业:数据科学与大数据技术适用对象:本科先修课程:JA V A程序设计、Linux基础教学环境:课堂、多媒体、实验机房二、课程简介《Hadoop大数据技术》课程是数据科学与大数据技术专业的专业必修课程。
《Hadoop大数据技术》主要学习当前广泛使用的大数据Hadoop平台及其主要组件的作用及使用。
通过学习Hadoop 平台框架,学会手动搭建Hadoop环境,掌握Hadoop平台上存储及计算的原理、结构、工作流程,掌握基础的MapReduce编程,掌握Hadoop生态圈常用组件的作用、结构、配置和工作流程,并具备大数据的动手及问题分析能力,使用掌握的知识应用到实际的项目实践中。
课程由理论及实践两部分组成,课程理论部分的内容以介绍Hadoop平台主要组件的作用、结构、工作流程为主,对Hadoop 平台组件的作用及其工作原理有比较深入的了解;课程同时为各组件设计有若干实验,使学生在学习理论知识的同时,提高实践动手能力,做到在Hadoop的大数据平台上进行大数据项目开发。
三、课程教学目标2.课程教学目标及其与毕业要求指标点、主要教学内容的对应关系四、教学内容(一)初识Hadoop大数据技术1.主要内容:掌握大数据的基本概念、大数据简史、大数据的类型和特征、大数据对于企业带来的挑战。
了解对于大数据问题,传统方法、Google的解决方案、Hadoop框架下的解决方案,重点了解Google的三篇论文。
掌握Hadoop核心构成、Hadoop生态系统的主要组件、Hadoop发行版本的差异及如何选择;了解Hadoop典型应用场景;了解本课程内容涉及到的Java语言基础;了解本课程实验涉及到的Linux基础。
Hadoop伪分布式安装

Hadoop伪分布式安装1.安装Hadoop(伪分布式)
上传Hadoop
将hadoop-2.9.2.tar.gz 上传到该目录
解压
ls
将Hadoop添加到环境变量
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出vim
验证环境变量是否正确hadoop version
修改配置文件hadoop-env.sh
保存并退出vim
修改配置文件core-site.xml
保存并退出vim
修改配置文件hdfs-site.xml
</property>
保存并退出vim
格式化HDFS
hdfs namenode -format
格式化成功的话,在/bigdata/data目录下可以看到dfs目录
启动NameNode
启动DataNode
查看NameNode管理界面
在windows使用浏览器访问http://bigdata:50070可以看到HDFS的管理界面
如果看不到,(1)检查windows是否配置了hosts;
位于C:\Windows\System32\drivers\etc\hosts
关闭HDFS的命令
2.配置SSH免密登录生成密钥
回车四次即可生成密钥
复制密钥,实现免密登录
根据提示需要输入“yes”和root用户的密码
新的HDFS启停命令
免密登录做好以后,可以使用start-dfs.sh和stop-dfs.sh命令启停HDFS,不再需要使用hadoop-daemon.sh脚本
stop-dfs.sh
注意:第一次用这个命令可能还是需要输入yes,按提示输入即可。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
简述hadoop伪分布式安装配置过程

Hadoop伪分布式安装配置过程在进行Hadoop伪分布式安装配置之前,首先需要确保系统环境符合安装要求。
Hadoop的安装需要在Linux系统下进行,并且需要安装好Java环境。
以下将详细介绍Hadoop伪分布式安装配置的步骤。
一、准备工作1. 确保系统为Linux系统,并且已经安装好Java环境。
2. 下载Hadoop安装包,并解压至指定目录。
二、配置Hadoop环境变量1. 打开.bashrc文件,添加以下内容:```bashexport HADOOP_HOME=/path/to/hadoopexport PATH=$PATH:$HADOOP_HOME/binexport HADOOP_CONF_DIR=/path/to/hadoop/etc/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOME```2. 执行以下命令使环境变量生效:```bashsource ~/.bashrc```三、配置Hadoop1. 编辑hadoop-env.sh文件,设置JAVA_HOME变量:```bashexport JAVA_HOME=/path/to/java```2. 编辑core-site.xml文件,添加以下内容:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>```3. 编辑hdfs-site.xml文件,添加以下内容:```xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>```4. 编辑mapred-site.xml.template文件,添加以下内容并保存为mapred-site.xml:```xml<configuration><property><name></name><value>yarn</value></property></configuration>```5. 编辑yarn-site.xml文件,添加以下内容:```xml<configuration><property><name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name> <value>localhost</value></property></configuration>```四、格式化HDFS执行以下命令格式化HDFS:```bashhdfs namenode -format```五、启动Hadoop1. 启动HDFS:```bashstart-dfs.sh```2. 启动YARN:```bashstart-yarn.sh```六、验证Hadoop安装通过浏览器访问xxx,确认Hadoop是否成功启动。
《Hadoop大数据技术》课程实验教学大纲
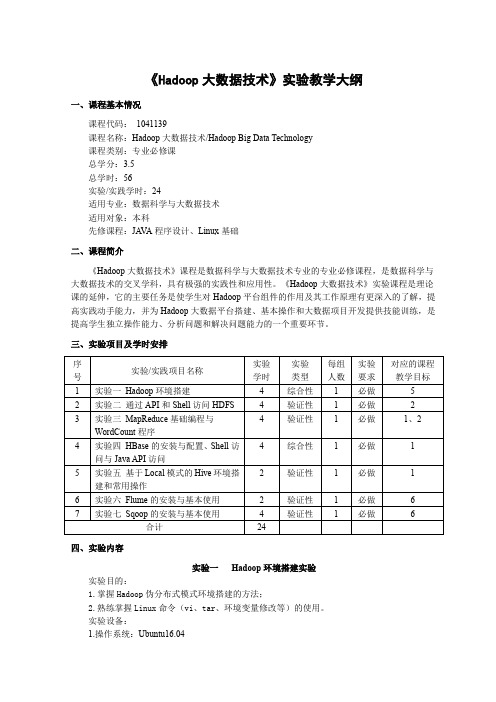
《Hadoop大数据技术》实验教学大纲一、课程基本情况课程代码:1041139课程名称:Hadoop大数据技术/Hadoop Big Data Technology课程类别:专业必修课总学分:3.5总学时:56实验/实践学时:24适用专业:数据科学与大数据技术适用对象:本科先修课程:JA V A程序设计、Linux基础二、课程简介《Hadoop大数据技术》课程是数据科学与大数据技术专业的专业必修课程,是数据科学与大数据技术的交叉学科,具有极强的实践性和应用性。
《Hadoop大数据技术》实验课程是理论课的延伸,它的主要任务是使学生对Hadoop平台组件的作用及其工作原理有更深入的了解,提高实践动手能力,并为Hadoop大数据平台搭建、基本操作和大数据项目开发提供技能训练,是提高学生独立操作能力、分析问题和解决问题能力的一个重要环节。
三、实验项目及学时安排四、实验内容实验一Hadoop环境搭建实验实验目的:1.掌握Hadoop伪分布式模式环境搭建的方法;2.熟练掌握Linux命令(vi、tar、环境变量修改等)的使用。
实验设备:1.操作系统:Ubuntu16.042.Hadoop版本:2.7.3或以上版本实验主要内容及步骤:1.实验内容在Ubuntu系统下进行Hadoop伪分布式模式环境搭建。
2.实验步骤(1)根据内容要求完成Hadoop伪分布式模式环境搭建的逻辑设计。
(2)根据设计要求,完成实验准备工作:关闭防火墙、安装JDK、配置SSH免密登录、Hadoop 安装包获取与解压。
(3)根据实验要求,修改Hadoop配置文件,格式化NAMENODE。
(4)启动/停止Hadoop,完成实验测试,验证设计的合理性。
(5)撰写实验报告,整理实验数据,记录完备的实验过程和实验结果。
实验二(1)Shell命令访问HDFS实验实验目的:1.理解HDFS在Hadoop体系结构中的角色;2.熟练使用常用的Shell命令访问HDFS。
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
1.Hadoop集群搭建(单机伪分布式)

1.Hadoop集群搭建(单机伪分布式)>>>加磁盘1)⾸先先将虚拟机关机2)选中需要加硬盘的虚拟机:右键-->设置-->选中硬盘,点击添加-->默认选中硬盘,点击下⼀步-->默认硬盘类型SCSI(S),下⼀步-->默认创建新虚拟磁盘(V),下⼀步-->根据实际需求,指定磁盘容量(单个或多个⽂件⽆所谓,选哪个都⾏),下⼀步。
-->指定磁盘⽂件,选择浏览,找到现有虚拟机的位置(第⼀次出现.vmdk⽂件的⽂件夹),放到⼀起,便于管理。
点击完成。
-->点击确定。
3) 可以看到现在选中的虚拟机有两块硬盘,点击开启虚拟机。
这个加硬盘只是在VMWare中,实际⼯作中直接买了硬盘加上就可以了。
4)对/dev/sdb进⾏分区df -h 查看当前已⽤磁盘分区fdisk -l 查看所有磁盘情况磁盘利⽤情况,依次对磁盘命名的规范为,第⼀块磁盘sda,第⼆块为sdb,第三块为sdc。
可以看到下图的Disk /dev/sda以第⼀块磁盘为例,磁盘分区的命名规范依次为sda1,sda2,sda3。
同理也会有sdb1,sdb2,sdb3。
可以参照下图的/dev/sda1。
下⾯的含义代表sda盘有53.7GB,共分为6527个磁柱,每个磁柱单元Units的⼤⼩为16065*512=8225280 bytes。
sda1分区为1-26号磁柱,sda2分区为26-287号磁柱,sda3为287-6528号磁柱下⾯的图⽚可以看到,还未对sdb磁盘进⾏分区fdisk /dev/sdb 分区命令可以选择m查看帮助,显⽰命令列表p 显⽰磁盘分区,同fdisk -ln 新增分区d 删除分区w 写⼊并退出选w直接将分区表写⼊保存,并退出。
mkfs -t ext4 /dev/sdb1 格式化分区,ext4是⼀种格式mkdir /newdisk 在根⽬录下创建⼀个⽤于挂载的⽂件mount /dev/sdb1 /newdisk 挂载sdb1到/newdisk⽂件(这只是临时挂载的解决⽅案,重启机器就会发现失去挂载)blkid /dev/sdb1 通过blkid命令⽣成UUIDvi /etc/fstab 编辑fstab挂载⽂件,新建⼀⾏挂载记录,将上⾯⽣成的UUID替换muount -a 执⾏后⽴即⽣效,不然的话是重启以后才⽣效。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
hadoop:建立一个单节点集群伪分布式操作
安装路径为:/opt/hadoop-2.7.2.tar.gz
解压hadoop: tar -zxvf hadoop-2.7.2.tar.gz
配置文件
1. etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8
2. etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.7.2/tmp</value>
</property>
</configuration>
3. etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>.dir</name>
<value>file:/opt/hadoop-2.7.2/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.7.2/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
设置ssh无密码登录
$ ssh localhost
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
格式化文件系统
$ bin/hdfs namenode -format
启动namenode和datanode
$ sbin/start-dfs.sh
浏览界面
http://localhost:50070
yarn一个简单的节点
配置文件
etc/hadoop/mapred-site.xml
<configuration>
<property>
<name></name>
<value>yarn</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动resourcemanager和nodemanager
$ sbin/start-yarn.sh
浏览界面
http://localhost:8088/
运行wordcount事例
查看文件目录
bin/hdfs dfs -ls /
创建目录文件
bin/hdfs dfs -mkdir /test/input
touch wc.input
vi wc.input (输入内容)
bin/hdfs dfs -put ./wc.input /test/input/ (把wc.input文件放到input中)
bin/hdfs dfs -text /test/input/wc.input(查看文件内容)
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.7.jar wordcount /test/input/ /test/output/
bin/hdfs dfs -ls /test/output/
bin/hdfs dfs -text /test/output/part-r-00000 (显示执行结果)
bin/hdfs dfs -text /test/input/wc.input (查看内容)
sbin/mr-jobhistory-daemon.sh start historyserver。