Hadoop环境的安装
Hadoop的安装与配置

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。
hadoop安装实验总结

hadoop安装实验总结Hadoop安装实验总结Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。
在本次实验中,我成功安装了Hadoop,并进行了相关的配置和测试。
以下是我对整个过程的总结和经验分享。
1. 环境准备在开始安装Hadoop之前,我们需要确保已经具备了以下几个环境条件:- 一台Linux操作系统的机器,推荐使用Ubuntu或CentOS。
- Java开发环境,Hadoop是基于Java开发的,因此需要安装JDK。
- SSH服务,Hadoop通过SSH协议进行节点之间的通信,因此需要确保SSH服务已启动。
2. 下载和安装Hadoop可以从Hadoop官方网站上下载最新的稳定版本。
下载完成后,解压缩到指定目录,并设置环境变量。
同时,还需要进行一些配置,包括修改配置文件和创建必要的目录。
3. 配置Hadoop集群Hadoop是一个分布式系统,通常会配置一个包含多个节点的集群。
在配置文件中,我们需要指定集群的各个节点的IP地址和端口号,并设置一些重要的参数,如数据存储路径、副本数量等。
此外,还可以根据实际需求调整其他配置参数,以优化集群性能。
4. 启动Hadoop集群在完成集群配置后,我们需要启动Hadoop集群。
这一过程需要先启动Hadoop的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager等。
启动成功后,可以通过Web 界面查看集群的状态和运行情况。
5. 测试Hadoop集群为了验证Hadoop集群的正常运行,我们可以进行一些简单的测试。
例如,可以使用Hadoop提供的命令行工具上传和下载文件,查看文件的副本情况,或者运行一些MapReduce任务进行数据处理。
这些测试可以帮助我们了解集群的性能和可靠性。
6. 故障排除与优化在实际使用Hadoop时,可能会遇到一些故障和性能问题。
为了解决这些问题,我们可以通过查看日志文件或者使用Hadoop提供的工具进行故障排查。
hadoop环境搭建
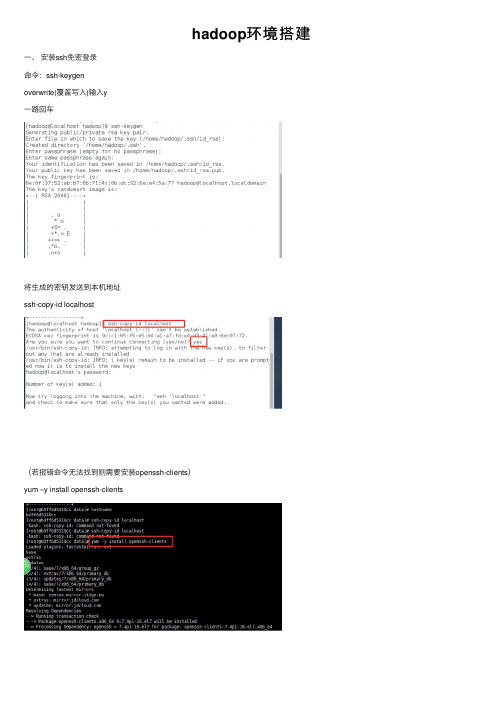
hadoop环境搭建⼀、安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost⼆、卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看三、安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version四、安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
hadoop安装以及配置启动命令

hadoop安装以及配置启动命令本次安装使⽤的Hadoop⽂件是badou学院的Hadoop1.2.1.tar.gz,以下步骤都是在此版本上进⾏。
1、安装,通过下载tar.gz⽂件安装到指定⽬录2、安装好后需要配置Hadoop集群配置信息: 在hadoop的conf路径中的masters中添加master(集群机器主的hostname)在slaves中添加集群的slave的hostname名称名称对应的是各⾃机器的hostname这样通过hosts⽂件中配置的域名地址映射可以直接找到对应的机器 a、core-site.xml 在xml⽂件中添加<property><name>hadoop.tmp.dir</name><value>/usr/local/src/hadoop.1.2.1/tmp</value></property> <property><name></name><value>hdfs://192.168.79.10:9000</value></property> c、hdfs-site.xml 在⽂件中添加<property><name>dfs.replication</name><value>3</value></property><!-- 复制节点数 --> d、hadoop-env.xml 在⽂件中添加export JAVA_HOME=/usr/local/src/jdk1.6.0_45 步骤2配置好后将当前hadoop⽂件夹复制到集群中其他机器上,只需要在对应机器上修改其对应的ip、port、jdk路径等信息即可搭建集群3、配置好Hadoop环境后需要测试环境是否可⽤: a、⾸先进⼊Hadoop的安装⽬录,进⼊bin⽬录下,先将Hadoop环境初始化,命令:./hadoop namenode -format b、初始化之后启动Hadoop,命令:./start_all.sh c、查看Hadoop根⽬录下的⽂件,命令:./hadoop fs -ls/ d、上传⽂件,命令:./hadoop fs -put ⽂件路径 e、查看⽂件内容,命令:./hadoopo fs -cat hadoop⽂件地址注意:在安装Hadoop环境时先安装好机器集群,使得⾄少3台以上(含3台)机器之间可以免密互相登录(可以查看上⼀篇的linux的ssh免密登录)执⾏Python⽂件时的部分配置/usr/local/src/hadoop-1.2.1/bin/hadoop/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar。
linuxxshelljdkhadoop(环境搭建)虚拟机安装(大数据搭建环境)

linuxxshelljdkhadoop(环境搭建)虚拟机安装(⼤数据搭建环境)【hadoop是2.6.5版本xshell是6版本jdk是1.8.0.131 虚拟机是CentOS-6.9-x86_64-bin-DVD1.iso vmware10】1.创建虚拟机第⼀步:在VMware中创建⼀台新的虚拟机。
如图2.2所⽰。
图2.2第⼆步:选择“⾃定义安装”,然后单击“下⼀步”按钮,如图2.3所⽰。
图2.3第三步:单击“下⼀步” 按钮,如图2.4所⽰。
图2.4第四步:选择“稍后安装操作系统”,然后单击“下⼀步” 按钮,如图2.5所⽰。
图2.5第五步:客户机操作系统选择Linux,版本选择“CentOS 64位”,然后单击“下⼀步” 按钮,如图2.6所⽰。
图2.6第六步:在这⾥可以选择“修改虚拟机名称”和“虚拟机存储的物理地址”,如图2.7所⽰。
图2.7第七步:根据本机电脑情况给Linux虚拟机分配“处理器个数”和每个处理器的“核⼼数量”。
注意不能超过⾃⼰电脑的核数,推荐处理数量为1,每个处理器的核⼼数量为1,如图2.8所⽰。
图2.8第⼋步:给Linux虚拟机分配内存。
分配的内存⼤⼩不能超过⾃⼰本机的内存⼤⼩,多台运⾏的虚拟机的内存总合不能超过⾃⼰本机的内存⼤⼩,如图2.9所⽰。
图2.9第九步:使⽤NAT⽅式为客户机操作系统提供主机IP地址访问主机拨号或外部以太⽹⽹络连接,如图2.10所⽰。
图2.10第⼗步:选择“SCSI控制器为LSI Logic(L)”,然后单击“下⼀步” 按钮,如图2.11所⽰。
图2.11第⼗⼀步:选择“虚拟磁盘类型为SCSI(S)”,然后单击“下⼀步” 按钮,如图2.12所⽰。
图2.12第⼗⼆步:选择“创建新虚拟磁盘”,然后单击“下⼀步” 按钮,如图2.13所⽰。
图2.13第⼗三步:根据本机的磁盘⼤⼩给Linux虚拟机分配磁盘,并选择“将虚拟机磁盘拆分为多个⽂件”,然后单击“下⼀步”按钮,如图2.14所⽰。
hadoop的基本使用

hadoop的基本使用Hadoop的基本使用Hadoop是一种开源的分布式计算系统和数据处理框架,具有可靠性、高可扩展性和容错性等特点。
它能够处理大规模数据集,并能够在集群中进行并行计算。
本文将逐步介绍Hadoop的基本使用。
一、Hadoop的安装在开始使用Hadoop之前,首先需要进行安装。
以下是Hadoop的安装步骤:1. 下载Hadoop:首先,从Hadoop的官方网站(2. 配置环境变量:接下来,需要将Hadoop的安装目录添加到系统的环境变量中。
编辑~/.bashrc文件(或其他相应的文件),并添加以下行:export HADOOP_HOME=/path/to/hadoopexport PATH=PATH:HADOOP_HOME/bin3. 配置Hadoop:Hadoop的配置文件位于Hadoop的安装目录下的`etc/hadoop`文件夹中。
其中,最重要的配置文件是hadoop-env.sh,core-site.xml,hdfs-site.xml和mapred-site.xml。
根据具体需求,可以在这些配置文件中进行各种参数的设置。
4. 启动Hadoop集群:在完成配置后,可以启动Hadoop集群。
运行以下命令以启动Hadoop集群:start-all.sh二、Hadoop的基本概念在开始使用Hadoop之前,了解一些Hadoop的基本概念是非常重要的。
以下是一些重要的概念:1. 分布式文件系统(HDFS):HDFS是Hadoop的核心组件之一,用于存储和管理大规模数据。
它是一个可扩展的、容错的文件系统,能够在多个计算机节点上存储数据。
2. MapReduce:MapReduce是Hadoop的编程模型,用于并行计算和处理大规模数据。
它由两个主要的阶段组成:Map阶段和Reduce阶段。
Map阶段将输入数据切分为一系列键值对,并运行在集群中的多个节点上。
Reduce阶段将Map阶段的输出结果进行合并和计算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop系统的安装方式
单机方式
在一台运行Linux或Windows下虚拟Linux的单机上安装运行Hadoop系统 单机伪分布方式 在一台运行Linux或Window下虚拟Linux的单机上,用伪分布方式,用不同 的java进程模拟分布运行中的NameNode、DataNode、JobTracker、 TaskTracker等各类节点 集群分布模式 在一个真实的集群环境下安装运行Hadoop系统,集群的每个节点可以运 行Linux或Window下的虚拟Linux。 单机和伪分布模式下编写调试完成的程序不需修改即可在真实的分布式 Hadoop集群下运行(但通常需要修改配置)
9.2. 运行测试:将文件复制到HDFS文件系统中 [hadoop@ ubuntu: ~/file]$ hadoop fs –mkdir input [hadoop@ ubuntu: ~/file]$ hadoop fs –put ~/file/file*.txt input 运行hadoop安装包中自带的WorldCount程序进行测试: [hadoop@ Master ~]$ hadoop jar hadoop-0.21.0-examples.jar wordcount test-in test-out
什么是SSH?
SSH(Secure Shell),是建立在应用层和传输层基础上的安全协议。 传统的网络服务程序,如FTP、POP和Telnet本质上都是不安全的; 它们在网络上用明文传送数据、用户帐号和用户口令,很容易受 到中间人(man-in-the-middle)攻击方式的攻击。 而SSH是目前较为可靠的、专为远程登录会话和其他网络服务提 供安全性的协议。利用SSH协议可以有效防止远程管理过程中的 信息泄露问题。通过SSH可以对所有传输的数据进行加密,也能 够防止DNS欺骗和IP欺骗。 SSH另一项优点是其传输的数据是经过压缩的,所以可以加快传 输的速度。SSH有很多功能,它既可以代替Telnet,又可以为FTP、 POP、PPP提供一个安全的登陆会话“通道”。 Hadoop使用SSH保证在远程管理Hadoop节点和节点间用户共享访 问时的安全性。
11. 停止HDFS和MapReduce
执行以下命令启动HDFS和MapReduce
[hadoop@ubuntu:/opt/hadoop]$ ./stop-all.sh
单机和单机伪分布式安装过程
9. 运行测试
wordcount是一个简单而却能直观体现mapreduce编程思想一 个示例程序,可以在hadoop的安装包下找到,主要功能就是 在一系列文本中统计出每个单词的出现次数。
单机和单机伪分布方式安装过程
Hadoop版本信息
根据Apache Hadoop官方提供的release,目前有以下版本可下载: 0.20.x.x :hadoop-0.20.2/,hadoop-0.20.203.0/,hadoop-0.20.204.0/,hadoop-0.20.205.0/ 0.21.x, 0.22.x, 0.23.x:hadoop-0.21.0/,hadoop-0.22.0/,hadoop-0.23.0/,hadoop-0.23.1/ 1.0版本:hadoop-1.0.0/,hadoop-1.0.1/ 2.0版本:hadoop-2.4.0/, hadoop-2.3.0/, hadoop-2.2.0/ …. 其中0.20.203.0 是目前最稳定的版本之一,发布于2011年5月11日,官方的说明是: “It is stable and has been deployed in large (4,500 machine) production clusters”。 1.2.1是目前最新的稳定版本,发布于2013年8月1日 Hadoop-1.2.1 的API可以参考/docs/r1.2.1/api/index.html 或者参考所下载的Hadoop包中docs文件夹下的内容
[hadoop@ubuntu : /opt/hadoop/bin]$ ./hadoop namenode -format
如果格式化成功,会返回一堆有关NameNode的启动信息,其 中会有一句“…. has been successfully formatted.”
单机和单机伪分布方式安装过程
8. 启动HDFS和MapReduce
第三步、配置环境变量 打开/etc/environment文件 在文件中追加红色框内的内容
使配置生效
如果有默认JDK:
第四步、配置默认JDK版本 改变系统bin默认java的指向,这个意思是把/usr/bin/java下的java命 令 指向/usr/lib/jvm/java-7-sun/bin/java并设置优先级为300(优先级 最高的为默认的程序使用路径).
单机和单机伪分布式安装过程
9.1. 运行测试:创建文件
在Linux文件系统下(如/home/hadoop/file)创建两个文本文件: file1.txt:hello NCUT hello Bruce file2.txt:hello China wo zai yunjisuan shiyanshi
其中test-out只能由程序创建,不能事先存在
单机和单机伪分布式安装过程
9.3. 运行wordcount [hadoop@ ubuntu: ~]$ hadoop jar /opt/hadoop/hadoop-examples.1.1.1.jar wordcount input output
[hadoop@ubuntu : ~]$ mkdir file
[hadoop@ubuntu : ~]$ cd file [hadoop@ubuntu : ~/file]$ vi file1.txt [hadoop@ubuntu : ~/file]$ vi file2.txt
单机和单机伪分布式安装过程
基本安装步骤
安装JDK 下载安装Hadoop 配置SSH 配置Hadoop的环境 格式化HDFS文件系统 启动Hadoop环境 运行程序测试 查看集群状态
单机和单机伪分布方式安装过程
1. 单机操作系统安装
在单机上安装Linux或Window下虚拟Linux,手册以操作系统Linux Ubuntu 12.10为例(VMware下安装ubuntu,并实现与windows共享文件,请参看) 2. 安装JDK 第一步、下载JDK FOR LINUX 下载地址: /technetwork/java/javase/downloads/index.ht ml 第二步、指定目录,解压安装。 当前目录下解压 以最高权限拷贝到安装目录 可按照个人习惯改名
6.2 修改hadoop配置文件hdfs-site.xml
单机和单机伪分布方式安装过程
6.2 修改hadoop配置文件mapred-site.xml
单机和单机伪分布方式安装过程
7.格式化NameNode
首先需要格式化HDFS,需要运行的主要脚本位于 HADOOP_HOME(hadoop解压后的根目录)/bin目录下, 在此目录下进行格式化,执行Hadoop的bin文件夹中的格式化 命令:
单机和单机伪分布方式安装过程
使hadoop应用能够实现无码登陆 生成一个公钥和私钥对,即id_dsa和id_dsa.pub两个文件,位于 ~/.ssh/authorized_keys文件夹下。
可以在默认目录下看到两个密钥 配置密钥,使得hadoop用户能够无须输入密码,通过SSH访问 localhost。 到此,SSH配置完毕,可以通过ssh localhost验证是否配置成功, 即无须密码可以直接登陆localhost。如果成功,测试结果如下,
单机和单机伪分布方式安装过程
5. 解压安装Hadoop
到Hadoop官网下载hadoop,实验手册中是hadoop-1.1.1-bin.tar.gz 解压缩到/opt/hadoop目录下 更改根目录名称:
[hadoop@ubuntu:/opt]$ sudo mv hadoop-1.1./ hadoop 将hadoop文件夹的own改为用户hadoop [hadoop@ubuntu:~]$ sudo chown –R hadoop:hadoop /opt/hadoop 解压好以后,所有的hadoop相关的配置文件都可以在/opt/hadoop/conf 下找到,下面主要针对以下四个文件进行配置,分别是core-site.xml, hadoop-env.sh, hdsf-site.xml, mapred-site.xml。
单机和单机伪分布方式安装过程
6.1. 修改hadoop配置文件hadoop-env.sh,设置JAVA_HOME
将
改为
单机和单机伪分布方式安装过程
6.2 修改hadoop配置文件core-site.xml
在hadoop文件夹下建立tmp文件夹。 修改core-site.xml内容如下,
单机和单机伪分布方式安装过程
执行以下命令启动HDFS和MapReduce
[hadoop@ubuntu:/opt/hadoop]$ ./start-all.sh
用JPS命令检查一下是否正常启动:
[hadoop@ubuntu ~]$ jps 显示以下各进程信息则说明HDFS和MapReduce都已正常启动:
4706 JobTracker 4582 SecondaryNameNode 4278 NameNode 4413 DataNode 4853 TaskTracker 488
第五步、或者直接删除UBUNTU自带的OPENJDK(如果有OPENJDK, 第四步与第五步选其一即可,否则第四步必选)