Hadoop环境的搭建与管理 (1)
基于Hadoop的大数据处理平台搭建与部署

基于Hadoop的大数据处理平台搭建与部署一、引言随着互联网和信息技术的快速发展,大数据已经成为当今社会中不可或缺的重要资源。
大数据处理平台的搭建与部署对于企业和组织来说至关重要,而Hadoop作为目前最流行的大数据处理框架之一,其搭建与部署显得尤为重要。
本文将介绍基于Hadoop的大数据处理平台搭建与部署的相关内容。
二、Hadoop简介Hadoop是一个开源的分布式存储和计算框架,能够高效地处理大规模数据。
它由Apache基金会开发,提供了一个可靠、可扩展的分布式系统基础架构,使用户能够在集群中使用简单的编程模型进行计算。
三、大数据处理平台搭建准备工作在搭建基于Hadoop的大数据处理平台之前,需要进行一些准备工作: 1. 硬件准备:选择合适的服务器硬件,包括计算节点、存储节点等。
2. 操作系统选择:通常选择Linux系统作为Hadoop集群的操作系统。
3. Java环境配置:Hadoop是基于Java开发的,需要安装和配置Java环境。
4. 网络配置:确保集群内各节点之间可以相互通信。
四、Hadoop集群搭建步骤1. 下载Hadoop从Apache官网下载最新版本的Hadoop压缩包,并解压到指定目录。
2. 配置Hadoop环境变量设置Hadoop的环境变量,包括JAVA_HOME、HADOOP_HOME等。
3. 配置Hadoop集群编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等,配置各个节点的角色和参数。
4. 启动Hadoop集群通过启动脚本启动Hadoop集群,可以使用start-all.sh脚本启动所有节点。
五、大数据处理平台部署1. 数据采集与清洗在搭建好Hadoop集群后,首先需要进行数据采集与清洗工作。
通过Flume等工具实现数据从不同来源的采集,并进行清洗和预处理。
2. 数据存储与管理Hadoop提供了分布式文件系统HDFS用于存储海量数据,同时可以使用HBase等数据库管理工具对数据进行管理。
《Hadoop大数据技术》课程实验教学大纲
《Hadoop大数据技术》实验教学大纲一、课程基本情况课程代码:1041139课程名称:Hadoop大数据技术/Hadoop Big Data Technology课程类别:专业必修课总学分:3.5总学时:56实验/实践学时:24适用专业:数据科学与大数据技术适用对象:本科先修课程:JA V A程序设计、Linux基础二、课程简介《Hadoop大数据技术》课程是数据科学与大数据技术专业的专业必修课程,是数据科学与大数据技术的交叉学科,具有极强的实践性和应用性。
《Hadoop大数据技术》实验课程是理论课的延伸,它的主要任务是使学生对Hadoop平台组件的作用及其工作原理有更深入的了解,提高实践动手能力,并为Hadoop大数据平台搭建、基本操作和大数据项目开发提供技能训练,是提高学生独立操作能力、分析问题和解决问题能力的一个重要环节。
三、实验项目及学时安排四、实验内容实验一Hadoop环境搭建实验实验目的:1.掌握Hadoop伪分布式模式环境搭建的方法;2.熟练掌握Linux命令(vi、tar、环境变量修改等)的使用。
实验设备:1.操作系统:Ubuntu16.042.Hadoop版本:2.7.3或以上版本实验主要内容及步骤:1.实验内容在Ubuntu系统下进行Hadoop伪分布式模式环境搭建。
2.实验步骤(1)根据内容要求完成Hadoop伪分布式模式环境搭建的逻辑设计。
(2)根据设计要求,完成实验准备工作:关闭防火墙、安装JDK、配置SSH免密登录、Hadoop 安装包获取与解压。
(3)根据实验要求,修改Hadoop配置文件,格式化NAMENODE。
(4)启动/停止Hadoop,完成实验测试,验证设计的合理性。
(5)撰写实验报告,整理实验数据,记录完备的实验过程和实验结果。
实验二(1)Shell命令访问HDFS实验实验目的:1.理解HDFS在Hadoop体系结构中的角色;2.熟练使用常用的Shell命令访问HDFS。
Hadoop的安装与配置

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
hadoop环境搭建
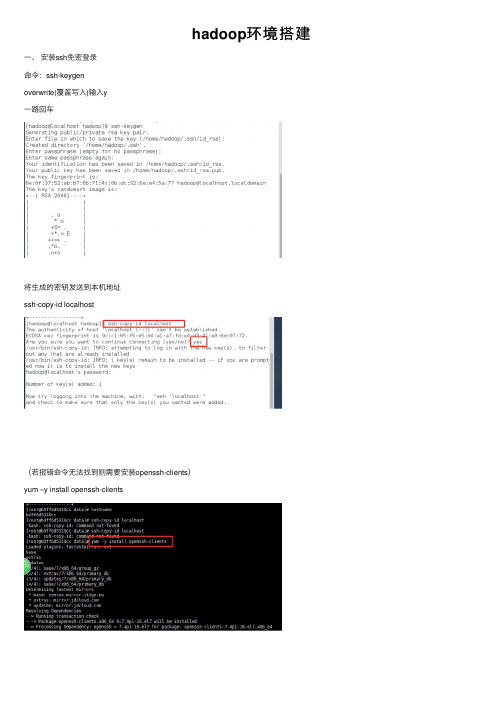
hadoop环境搭建⼀、安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost⼆、卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看三、安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version四、安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
Hadoop集群的搭建方法与步骤

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop环境的搭建与管理1、Hadoop的安装与配置HDFS在Master节点启动dfs和yarn服务时,需要自动启动Slave节点服务,HDFS需要通过ssh访问Slave节点机。
HDFS需要搭建多台服务器组成分布式系统,节点机间需要无密码访问。
本节任务是进行ssh的设置、用户的创建、hadoop参数的设置,完成HDFS分布式环境的搭建。
任务实施:本节任务需要四台节点机组成集群,每个节点机上安装CentOS-6.5-x86_64系统。
四台节点机使用的IP地址分别为:192.168.23.111、192.168.23.112、192.168.23.113、192.168.23.114,对应节点主机名为:node1、node2、node3、node4。
节点机node1作为NameNode,其他作为DataNode。
创建hadoop用户,分别在四台节点机上创建用户hadoop,uid=660,密码分别为h1111, h2222, h3333, h4444。
登录node1节点机,创建hadoop用户和设置密码。
操作命令如下。
[root@node1 ~]# useradd -u 660 hadoop[root@node1 ~]# passwd hadoop其他节点机的操作相同。
步骤2设置master节点机ssh无密码登录slave节点机。
(1)在node1节点机上,以用户hadoop用户登录或者使用su – hadoop切换到hadoop 用户。
操作命令如下。
[root@node1 ~]# su - hadoop(2)使用ssh-keygen生成证书密钥,操作命令如下。
[hadoop@node1 ~]$ssh-keygen -t dsa(3)使用ssh-copy-id分别拷贝证书公钥到node1,node2,node3,node4节点机上,操作命令如下。
[hadoop@node1 ~]$ ssh-copy-id -i .ssh/id_dsa.pub node1[hadoop@node1 ~]$ ssh-copy-id -i .ssh/id_dsa.pub node2[hadoop@node1 ~]$ ssh-copy-id -i .ssh/id_dsa.pub node3[hadoop@node1 ~]$ ssh-copy-id -i .ssh/id_dsa.pub node4(4)在node1节点机上使用ssh测试无密码登录node1节点机,操作命令如下。
[hadoop@node1 ~]$ ssh node1Last Login: Mon Dec 22 08:42:38 2014 from node1[hadoop@node1 ~]$ exitLogoutConnection to node1 closed.以上表示操作成功。
在node1节点机上继续使用ssh测试无密码登录node2、node3和node4节点机,操作命令如下。
[hadoop@node1 ~]$ ssh node2[hadoop@node1 ~]$ ssh node3[hadoop@node1 ~]$ ssh node4测试登录每个节点机后,输入exit退出。
步骤3使用WinSCP上传hadoop-2.6.0.tar.gz软件包到node1节点机的root目录下。
如果hadoop 软件包在node1节点机上编译,则把编译好的包拷贝到root目录下即可。
如图7.3所示。
图7.3 使用WinSCP上传hadoop-2.6.0.tar.gz软件包步骤4解压文件,安装文件。
操作命令如下。
[root@node1 ~]# cd[root@node1 ~]# tar xvzf hadoop-2.6.0.tar.gz[root@node1 ~]# cd hadoop-2.6.0[root@node1 hadoop-2.6.0]# mv * /home/hadoop步骤5修改hadoop配置文件。
Hadoop配置文件主要有:hadoop-env.sh、yarn-env.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。
配置文件在/home/hadoop/etc/hadoop/目录下,可进入该目录进行配置。
操作命令如下。
[root@node1 hadoop-2.6.0]# cd /home/hadoop/etc/hadoop/(1)修改hadoop-env.sh,将文件中的export JAVA_HOME=${JAVA_HOME}修改为export JAVA_HOME=/usr/lib/jvm/java-1.7.0。
如下所示。
[root@node1 hadoop]# vi hadoop-env.sh# The java implementation to use.# export JAVA_HOME=${JAVA_HOME}export JAVA_HOME=/usr/lib/jvm/java-1.7.0(2)修改slaves,该文件登记DataNode节点主机名,本处添加node2,node3,node4三台节点主机名。
如下所示。
[root@node1 hadoop]# vi slavesnode2node3node4(3)修改core-site.xml,将文件中的<configuration></configuration>修改为如下内容。
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:9000</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/home/hadoop/tmp</value><description>Abase for other temporary directories.</description></property><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property></configuration>其中node1为集群的NameNode(Master)节点机,node1可以使用IP地址表示。
(4)修改hdfs-site.xml,将文件中的<configuration></configuration>修改为如下内容。
<configuration><property><name>node.secondary.http-address</name><value>node1:9001</value></property><property><name>.dir</name><value>file:/home/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/home/hadoop/dfs/data</value></property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property></configuration>其中为了便于教学,第二个NameNode也使用node1节点机,NameNode产生的数据存放在/home/hadoop/dfs/name目录下,DataNode产生的数据存放在/home/hadoop/dfs/data目录下,设置3份备份。
(5)将文件mapred-site.xml.template改名为mapred-site.xml。
操作如下。
[root@node1 hadoop]# mv mapred-site.xml.template mapred-site.xml将文件中的<configuration></configuration>修改为如下内容。
<configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property></configuration>(6)修改yarn-site.xml,将文件中的<configuration></configuration>修改为如下内容。