Hadoop、hive环境搭建详解
我学大数据技术(hadoop2.7+hbase1.0+hive1.2)

这个地方有点奇怪,应该是 1.7.0_45 ,我查一下。系统默认安装了 java 我全部删除,重新安 装 先查询一下有哪些 jdk : rpm -qa jdk 然后 rpm -e 把查询的都删除 然后重新安装: rpm -ivh jdk-7u45-linux-x64.rpm
2、切换到 hadoop 用户,创建安装所需要的文件夹
2015 年 8 月 13 日 17:12 1、关机和重启 ?
1 shutdown -h now 2 shutdown -r now
2、创建用户,并设置密码 ?
1 useradd wukong ?
1 d wukong
根据提示输入密码,回车,并再确认输入一次密码。 3、查看,删除用户 ?
1 cat /etc/passwd ?
Prerequisites
Install Java. See the Hadoop Wiki for known good versions. Download a stable version of Hadoop from Apache mirrors. /hadoop/HadoopJavaVersions 说明 下载地址 java1.7.45 /technetwork/java/javase/downloads/index-jdk5-jsp-142662.html
来自 </allman90/blog/295173>
2、VMware 虚拟机的安装配置
2015 年 8 月 13 日 21:08
一、基础篇
1、环境的搭建 基础支撑环境的搭建
首先基于 VMware 搭建一个简单机器测试集群环境 1.1VM13808.html?ald 各位可以随意网站下载,系统用 64 位。
hive环境搭建

hive环境搭建注:本次搭建是基于已经搭建好的hadoop3集群搭建的,故对于hadoop3搭建不做介绍,且本次搭建是以本地模式为例特别关注:由于hadoop3xy不兼容hive2xy,如使⽤hive安装会出现各种问题,故使⽤hive3作为本次环境搭建1.安装mysql1.1安装mysql数据库yum install -y mysql-server1.2对字符集进⾏设置:进⼊/etc/f⽂件中,加⼊default-character-set=utf8,代码如下:1.3启动mysql服务,代码如下:service mysqld start #启动mysql服务service mysqld status #查看mysql是否启动systemctl enable mysqld #设置myql开机启动1systemctl daemon-reload #设置myql开机启动21.4设置myql的root密码mysql -uroot -p ,第⼀次进⼊时,默认密码为空,输⼊密码时直接回车可直接进⼊set password for 'root'@'localhost' = password('123456'); 设置密码为1234561.5新建root1⽤户,并且赋予两个⽤户远程登陆权限;create user 'root1'@'%' identified by '123456'; #如果使⽤root作为连接⽤户此步可以省略,本次安装使⽤root⽤户作为连接⽤户grant all on *.* to'root1'@'%'; #如果使⽤root作为连接⽤户此步可以省略,本次安装使⽤root⽤户作为连接⽤户grant all on *.* to'root'@'%';2.1配置hive-env.sh ,进⼊conf⽬录,cp hive-env.sh.template hive-env.sh ,打开 hive-env.sh⽂件:export HADOOP_HOME=/app/hadoop-3.2.1export HIVE_CONF_DIR=/app/hive-3.1.2/conf2.2配置hive-site.xml,进⼊conf⽬录,cp hive-default.xml.template hive-site.xml,打开hive-env.sh⽂件,对于如下内容有则修改,⽆则新增:<property><name>system:java.io.tmpdir</name><value>/user/hive/warehouse</value></property><property><name>system:</name><value>${}</value></property><property><name>hive.metastore.db.type</name><value>mysql</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>user name for connecting to mysql server</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value><description>password for connecting to mysql server</description></property>2.3创建⽬录:hadoop fs -mkdir -p /tmphadoop fs -mkdir -p /user/hive/warehousehadoop fs -chmod g+w /tmphadoop fs -chmod g+w /user/hive/warehouse2.4替换低版本的guava.jar⽂件,否则初始化时会报错:错误⼀:Exception in thread "main" ng.NoSuchMethodError: mon.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V原因:hadoop和hive的两个guava.jar版本不⼀致两个位置分别位于下⾯两个⽬录: - /usr/local/hive/lib/ - /usr/local/hadoop/share/hadoop/common/lib/解决办法:除低版本的那个,将⾼版本的复制到低版本⽬录下2.5删除hive-site.xml中的特殊字符,否则初始化时会报如下错误:错误⼆:Exception in thread "main" ng.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8at [row,col,system-id]: [3224,96,"file:/app/hive-3.1.2/conf/hive-site.xml"]原因: hive-site.xml配置⽂件中,3224⾏有特殊字符解决办法:进⼊hive-site.xml⽂件,跳转到对应⾏,删除⾥⾯的特殊字符即可2.6上次jdbc驱动⾄hive/lib⽬录下,否则会报如下错误:错误三:org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driverUnderlying cause: ng.ClassNotFoundException : com.mysql.jdbc.Driver原因:缺少jdbc驱动解决办法:上传jdbc( mysql-connector-java-5.1.36-bin.jar )驱动到 hive的lib下2.7初始化hiveschematool -dbType mysql -initSchema2.8启动 metastore服务(不启⽤会报:HiveException ng.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient。
大数据集群配置过程_hive篇

大数据集群配置过程_hive篇JDDC_SEED_BIGDATA 2015-01-151.概述本篇文档主要讲解hive的安装过程。
Hadoop是安装hbase和hive的基础,即安装hbase和hive之前必须先安装hadoop并且hdfs和mapreduce必须都功能正常。
因为hbase和hive 其底层所使用都是应用hadoop的两个核心部分—hdfs和mapreduce。
在安装hadoop之前需要考滤操作系统的版本(32位还是64位)以及hbase和hive的版本,否则会引起jar包不支持而导致的jar包替换或jar包重新编译等问题。
Hadoop、hbase、hive的版本匹配信息如下:由于我们所使用的操作系统centos6.5是32位,而且安装的hadoop是hadoop2.2.0,所以本次安装的hive版本是0.12.0切记,在安装hbase之前一定先安装hadoop,而且要确保hadoop中的HDFS和MAPREDUCE都是可以正常使用的。
2.正文与hadoop和hbase不同,hive在安装的过程中不需要把hive的包分别发布到个节点上,只需要在namenode节点上hive包进行配置,但需要在配置的过程中指定各个datanode节点的主机名。
2.1下载安装mysql本次将Hive配置成Server模式,并且使用MySQL作为元数据数据库。
原则上MySQL不必要非得安装在namenode节点上,可以装在一个单独的服务器上,并进行远程联接。
本次技术检证,由于资源有限,把mysql安装在namenode节点上。
下载MySQL-5.6.22-1.linux_glibc2.5.i386.rpm-bundle.tar,参考下载地址/downloads/。
具体的安装以及root初始密码的修改请参考《linux下MySQL安装及设置》和《MySQL修改root密码的各种方法整理》这两篇文档。
2.2创建Hive元数据库创建数据库hive:create database if not exists hive;创建数据库用户hive:create user hive identified by 'hive2015';授权可以访问数据库hive的主机和用户:grant all on hive.* to 'hive'@'hadoop01' identified by 'hive2015';grant all on hive.* to 'hive'@'hadoop02' identified by 'hive2015';grant all on hive.* to 'hive'@'hadoop03' identified by 'hive2015';grant all on hive.* to 'hive'@'hadoop04' identified by 'hive2015';2.3安装以及配置hive下载hive-0.12.0-bin.tar.gz,参考下载地址/downloads.html。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
hadoop环境搭建
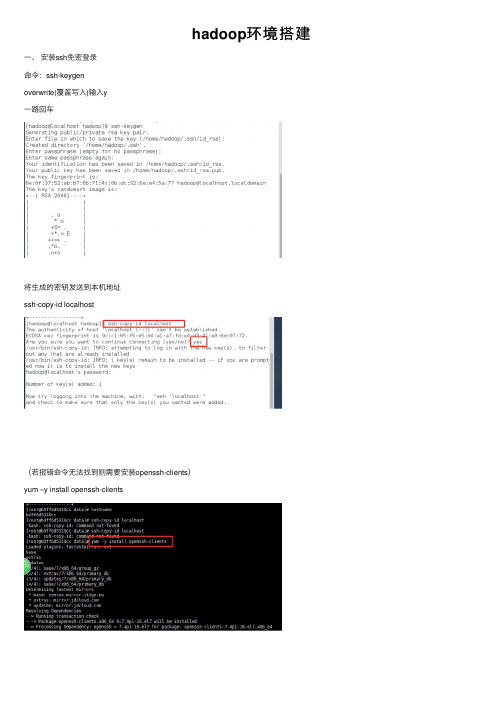
hadoop环境搭建⼀、安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost⼆、卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看三、安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version四、安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
Hadoop2.4、Hbase0.98、Hive集群安装配置手册

Hadoop、Zookeeper、Hbase、Hive集群安装配置手册运行环境机器配置虚机CPU E5504*2 (4核心)、内存 4G、硬盘25G进程说明QuorumPeerMain ZooKeeper ensemble member DFSZKFailoverController Hadoop HA进程,维持NameNode高可用 JournalNode Hadoop HA进程,JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,保证数据高可用 NameNode Hadoop HDFS进程,名字节点DataNode HadoopHDFS进程, serves blocks NodeManager Hadoop YARN进程,负责 Container 状态的维护,并向 RM 保持心跳。
ResourceManager Hadoop YARN进程,资源管理 JobTracker Hadoop MR1进程,管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
TaskTracker Hadoop MR1进程,manages the local Childs RunJar Hive进程HMaster HBase主节点HRegionServer HBase RegionServer, serves regions JobHistoryServer 可以通过该服务查看已经运行完的mapreduce作业记录应用 服务进程 主机/hostname 系统版本mysql mysqld10.12.34.14/ Centos5.810.12.34.15/h15 Centos5.8 HadoopZookeeperHbaseHiveQuorumPeerMainDFSZKFailoverControllerNameNodeNodeManagerRunJarHMasterJournalNodeJobHistoryServerResourceManagerDataNodeHRegionServer10.12.34.16/h16 Centos5.8 HadoopZookeeperHbaseHiveDFSZKFailoverControllerQuorumPeerMainHMasterJournalNodeNameNodeResourceManagerDataNodeHRegionServerNodeManager10.12.34.17/h17 Centos5.8 HadoopZookeeperHbaseHiveNodeManagerDataNodeQuorumPeerMainJournalNodeHRegionServer环境准备1.关闭防火墙15、16、17主机:# service iptables stop2.配置主机名a) 15、16、17主机:# vi /etc/hosts添加如下内容:10.12.34.15 h1510.12.34.16 h1610.12.34.17 h17b) 立即生效15主机:# /bin/hostname h1516主机:# /bin/hostname h1617主机:# /bin/hostname h173. 创建用户15、16、17主机:# useraddhduser密码为hduser# chown -R hduser:hduser /usr/local/4.配置SSH无密码登录a)修改SSH配置文件15、16、17主机:# vi /etc/ssh/sshd_config打开以下注释内容:#RSAAuthentication yes#PubkeyAuthentication yes#AuthorizedKeysFile .ssh/authorized_keysb)重启SSHD服务15、16、17主机:# service sshd restartc)切换用户15、16、17主机:# su hduserd)生成证书公私钥15、16、17主机:$ ssh‐keygen ‐t rsae)拷贝公钥到文件(先把各主机上生成的SSHD公钥拷贝到15上的authorized_keys文件,再把包含所有主机的SSHD公钥文件authorized_keys拷贝到其它主机上)15主机:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys16主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'17主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'15主机:# cat ~/.ssh/authorized_keys | ssh hduser@h16 'cat >> ~/.ssh/authorized_keys'# cat ~/.ssh/authorized_keys | ssh hduser@h17 'cat >> ~/.ssh/authorized_keys'5.Mysqla) Host10.12.34.14:3306b) username、passwordhduser@hduserZookeeper使用hduser用户# su hduser安装(在15主机上)1.下载/apache/zookeeper/2.解压缩$ tar ‐zxvf /zookeeper‐3.4.6.tar.gz ‐C /usr/local/配置(在15主机上)1.将zoo_sample.cfg重命名为zoo.cfg$ mv /usr/local/zookeeper‐3.4.6/conf/zoo_sample.cfg /usr/local/zookeeper‐3.4.6/conf/zoo.cfg2.编辑配置文件$ vi /usr/local/zookeeper‐3.4.6/conf/zoo.cfga)修改数据目录dataDir=/tmp/zookeeper修改为dataDir=/usr/local/zookeeper‐3.4.6/datab)配置server添加如下内容:server.1=h15:2888:3888server.2=h16:2888:3888server.3=h17:2888:3888server.X=A:B:C说明:X:表示这是第几号serverA:该server hostname/所在IP地址B:该server和集群中的leader交换消息时所使用的端口C:配置选举leader时所使用的端口3.创建数据目录$ mkdir /usr/local/zookeeper‐3.4.6/data4.创建、编辑文件$ vi /usr/local/zookeeper‐3.4.6/data/myid添加内容(与zoo.cfg中server号码对应):1在16、17主机上安装、配置1.拷贝目录$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.16:/usr/local/$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.17:/usr/local/2.修改myida)16主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1 修改为2b)17主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1修改为3启动$ cd /usr/local/zookeeper‐3.4.6/$./bin/zkServer.sh start查看状态:$./bin/zkServer.sh statusHadoop使用hduser用户# su hduser安装(在15主机上)一、安装Hadoop1.下载/apache/hadoop/common/2.解压缩$ tar ‐zxvf /hadoop‐2.4.0.tar.gz ‐C /usr/local/二、 编译本地库,主机必须可以访问internet。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
Hadoop集群的搭建方法与步骤

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、Hadoop 环境搭建 首先在 Apache 官网下载 hadoop 的包 hadoop-0.20.2.tar.gz。
解压 hadoop-0.20.2.tar.gz 包,具体命令如下: tar zxvf hadoop-0.20.2.tar.gz 其中要注意的是,tar 包用 xvf ,gz 包用 zxvf。
在安装中,如果遇到识别问题,或者无法解压,很有可能是权限问题,解决方案 是修改此文件的使用权限,命令如下: chmod 777 hadoop-0.20.2.tar.gz 其中,777 为所有权限。
如果依然报错,如:Archive contains obsolescent base-64 headers;Error exit delayed from previous errors。
这种情况,一般是压缩包损坏的问题。
因为大多数人会将包下载到 windows 环境,再通过 ftp 等方法上传到 Linux 环境。
容易产生包损坏。
建议大 家直接下载到 Linux 即可。
具体命令如下: wget /apache-mirror/hadoop/core/hadoop-0.20.2/ hadoop-0.20.2.tar.gz 直接下载到当前目录。
当文件准备好之后,我们要修改配置,将 Hadoop 简单 run 起来。
首先,我们进入 hadoop-0.20.2/conf 目录当中,其中会存在如下配置文件: 首先修改 masters 和 slaves,这个是指定我们的 m 和 s 的 ip 地址,这里我们 就以单台机器为例子,在文件中直接输入当前机器的 IP。
之后我们修改 mapred-site.xml 文件,具体配置如下 Xml 代码 1. <span style="font-size: medium;"><?xml version="1.0"?> 2. <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3.4. <!-- Put site-specific property overrides in this file. --> 5. 6. <configuration> 7. <property> 8. 9. 10. tracker runs 11. single map 12. 13. 14. option. 15. 16. <name>mapred.job.tracker</name> <value>hdfs://192.168.216.57:8012</value> <description>The host and port that the MapReduce jobat. If "local", then jobs are run in-process as aand reduce task. Pass in the jobtracker hostname via the -Dhadoop.jobtracker=JOBTRACKER_HOST java</description> </property>17. </configuration></span><?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property> <name>mapred.job.tracker</name> <value>hdfs://192.168.216.57:8012</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. Pass in the jobtracker hostname via the -Dhadoop.jobtracker=JOBTRACKER_HOST java option. </description> </property> </configuration>job.tracker 是关键,mapReduce 会将一个 job,通过 map(),打散为 n 个 task。
之后是对文件 core-site.xml 的配置,详细配置如下: Xml 代码1. <span style="font-size: medium;"><?xml version="1.0"?> 2. <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3. 4. <!-- Put site-specific property overrides in this file. -->5. 6. <configuration> 7. 8. 9. 10. 11. 12. 13. 14. <property> <name></name> <value>hdfs://cap216057.sqa:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/admin/tmp/</value>15. <description>A base for other temporary directories. Set to a 16. directory off of the user's home directory for the simple test. 17. 18. 19. 20. </configuration></span> </description> </property><?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property> <name></name> <value>hdfs://cap216057.sqa:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/admin/tmp/</value> <description>A base for other temporary directories. Set to a directory off of the user's home directory for the simple test. </description> </property></configuration>这个主要是配置我们的文件系统。
其中, 的 value, 不可以写 IP 地址,要写域名。
域名的查询,具体命令如下:cd~cd etc vi hosts在 hosts 文件中,找到自己 IP 对应的域名。
到此,Hadoop 本身的配置就算完成了。
但 hadoop 会在 master/slaves 之间进 行文件的操作,在机器之间操作时候,就必须做到免登陆。
对此,我们就得设置 相应的公钥私钥。
具体命令如下: ssh-keygen -t rsa -P '' -P 表示密码,-P '' 就表示空密码,也可以不用-P 参数,这样就要 三车回车,用-P 就一次回车。
它在/~ 下生成.ssh 目录,.ssh 下有 id_rsa 和 id_rsa.pub。
如果是多台机器,则需要将公钥 id-rsa.pub 通过 scp 到其他机器的 相同目录。
之后,追加公钥到相应文件,具体如下: cat id_rsa.pub >> .ssh/authorized_keys chmod 600 .ssh/authorized_keys 其中,authorized_keys 要的权限是 600第一次登录是时要你输入 yes,之后就不用了。
OK,所有均搞定了,进入 hadoop-0.20.2/bin 路径,直接执行 start-all.sh 脚本,即可启动 Hadoop 的服务了。
我们可以通过 web 的方式,对 Hadoop 的运转进行监控,具体 url 如下: 控制台:http://cap216057.sqa:50030/jobtracker.jsp 数据节点:http://cap216057.sqa:50070/dfshealth.jsp cap216057.sqa 可以再 hosts 里配置,或者直接访问 IP 地址。
二、 Hive 搭建Hive 搭建在 Hadoop 的基础之上,相对就会简单很多。