Hadoop环境搭建及wordcount实例运行
Hadoop的配置及运行WordCount

Hadoop的配置及运行WordCount目录Hadoop的配置及运行WordCount (1)一、环境: (1)二、步骤: (1)1 JDK及SSH安装配置: (1)1.1 卸载Fedora自带的OpenJDK,安装Oracle的JDK (1)1.2 配置SSH (2)2 Hadoop安装配置: (4)2.1 下载并配置Hadoop的JDK环境 (4)2.2 为系统配置Hadoop环境变量 (5)2.3 修改Hadoop的配置文件 (6)2.4 初始化HDFS文件系统,和启动Hadoop (8)2.5 关闭HDFS (11)3 运行WordCount: (11)3.1 下载和编译WordCount示例 (11)3.2 建立文本文件并上传至DFS (13)3.3 MapReduce执行过程显示信息 (14)结尾: (15)一、环境:计算机Fedora 20、jdk1.7.0_60、Hadoop-2.2.0二、步骤:1 JDK及SSH安装配置:1.1 卸载Fedora自带的OpenJDK,安装Oracle的JDK*由于Hadoop,无法使用OpenJDK,所以的下载安装Oracle的JDK。
1.1.1、以下为卸载再带的OpenJDK:然后到/technetwork/java/javase/downloads/index.html下载jdk,可以下载rpm格式的安装包或解压版的。
rpm版本的下载完毕后可以运行安装,一般会自动安装在/usr/java/的路径下面。
接下来就配置jdk的环境变量了。
1.1.2、进入到系统的环境变量配置文件,加入以下内容:(按i进行编辑,编辑完毕按ESC,输入:wq,回车即保存退出)截图如下:Java环境变量配置输入这个回车即可保存退出java –version,检测配置是否成功。
如下结果则Java 配置安装成功。
1.2 配置SSH搭建hadoop分布式集群平台,为了实现通讯之间的可靠,防止远程管理过程中的信息泄露问题。
Cygwin+Eclipse搭建Hadoop开发环境

Cygwin的安装1.先在/install.html上下载安装文件打开后双击setup.exe安装。
如下图:2. 直接点击下一步后如下图:图中有三个选项,意思一看就懂啊。
这里直选择下一步3.直接点击下一步后如下图:这里是要选择安装路径,设置在哪里都可以。
没有特殊要求。
4. 设置好路径后下一步进入下图:这是设置Cygwin安装文件的目录。
先安装的exe只是个引导它需要自己下载安装文件。
设置这个目录就是存储这些文件的。
5.设置好后下一步进入下图:这里是你网络的链接方式,第一个是直接链接,第二个是使用IE代理,第三个使用你指定的HTTP/FTP代理。
你要根据你自己的情况选择。
通常选第一个如不好使则查看你的联网是否使用了代理用了就选下面两个中的一个。
6.设置好后下一步进入下图:选择其中一个url用作下载的站点。
我选第一就行挺快的。
你的不行可以试试别的。
也可以在下面的User URL中添加url写完地址一点Add就加入到上面的url列表中了。
然后选择你自己加入的url即可。
如果自己加入可以尝试一下这个url:/pub/。
然后点击下一步进行安装文件的下载,需要点时间。
如果点击下一步后出现这个错误Internal Error: gcrypt library error 60 illegal tag。
就是上一步网络选择的问题或者选择的url不能下载。
自己可以尝试改动一下。
正常下载的话也可能出现一个警告窗口如下图:点击确定即可。
随即会进入下图。
7. 来到此图就要开始进行一些配置了。
选择一下要安装的包。
如下图:首先:选择其中的Base Default,通常这里的包都已经选择上了。
你要确保sed已选择上,这样你可以在eclipse中使用hadoop了。
如下图这样即可:其次:选择Devel Default,将其中的subversion选中第一个即可。
如下图:最后:选择Net default包,将其中的openssh及openssl选上。
hadoop环境搭建
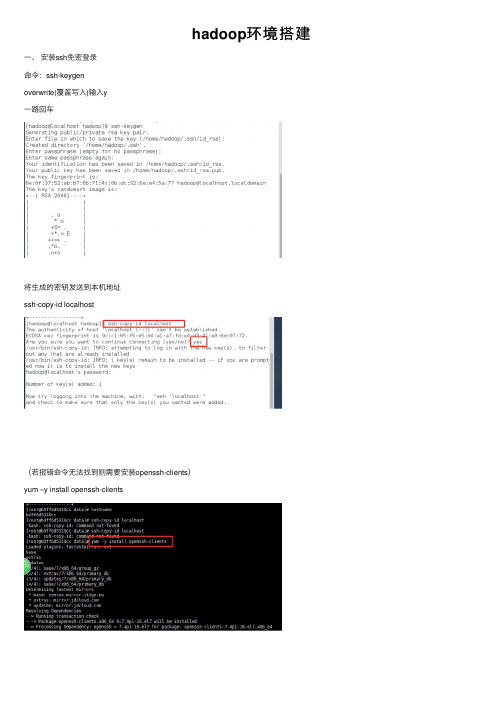
hadoop环境搭建⼀、安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost⼆、卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看三、安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version四、安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
hadoop实例运行

• 上传文本内容到HDFS 下inputdata目录 内
• hadoop fs -mkdir inputdata创建新目录 • hadoop fs -put ./data.txt inputda个块存为3个副本。分别为以下
• 执行WordCount程序
hadoop实例演示
2015.3.31
目录
实验一:对20 News Groups Dataset 文本分类数据集做WordCount处理及 分析
实验1.1:对20 News Groups Dataset 文本分类数据集做
WordCount处理(多文件上传处理)
• 数据集格式内容:数据集含有19124个文本文件,每个文件大小仅有几kb。
HDFS上传时间相对漫长 HDFS上传切分成64MB为一个block,浪费大量内存空间 mapreduce处理时间在1个小时以上
实验1.2:对20 News Groups Dataset 文本分类数据集做WordCount处理
(通过软件或者程序实现文本内容进行处理合并成一个大文件)
• 数据集格式内容:为上例中一万多个文档合并成一 个文本文档,数据集不变,数据集为74MB左右
Hadoop在处理多文件并且每个文件很小时, 文件只有几MB或者几KB时,执行效率将会相 当的低下。也会浪费大量的HDFS存储量。这 就是hadoop所具有的局限性。
Hadoop可以实现一个高吞吐量的数据的执行, 可以高效的执行
• 文本内容格式:
• 上传HDFS:
在我们上传到HDFS,被分成了一个个的块内容(64MB),浪费了大量的内存
• 执行WordCount程序
从右图中我 们可以看到, 执行时间相 当缓慢。 原因:大部 分的时间不 是用在了计 算数据上, 而是在寻址 上。
ubuntu下hadoop配置指南

ubuntu下hadoop配置指南目录1.实验目的2.实验内容(hadoop伪分布式与分布式集群环境配置)3.运行wordcount词频统计程序一 . 实验目的通过学习和使用开源的Apache Hadoop工具,亲身实践云计算环境下对海量数据的处理,理解并掌握分布式的编程模式MapReduce,并能够运用MapReduce编程模式完成特定的分布式应用程序设计,用于处理实际的海量数据问题。
二 . 实验内容1.实验环境搭建1.1. 前期准备操作系统:Linux Ubuntu 10.04Java开发环境:需要JDK 6及以上,Ubuntu 10.04默认安装的OpenJDK可直接使用。
不过我使用的是sun的jdk,从官方网站上下载,具体可以参考博客:ubuntu下安装JDK 并配置java环境Hadoop开发包:试过了hadoop的各种版本,包括0.20.1,0.20.203.0和0.21.0,三个版本都可以配置成功,但是只有0.20.1这个版本的eclipse插件是可用的,其他版本的eclipse插件都出现各种问题,因此当前使用版本为hadoop-0.20.1Eclipse:与hadoop-0.20.1的eclipse插件兼容的只有一些低版本的eclipse,这里使用eclipse-3.5.2。
1.2. 在单节点(伪分布式)环境下运行Hadoop(1)添加hadoop用户并赋予sudo权限(可选)为hadoop应用添加一个单独的用户,这样可以把安装过程和同一台机器上的其他软件分离开来,使得逻辑更加清晰。
可以参考博客:Ubuntu-10.10如何给用户添加sudo权限。
(2)配置SSH无论是在单机环境还是多机环境中,Hadoop均采用SSH来访问各个节点的信息。
在单机环境中,需要配置SSH 来使用户hadoop 能够访问localhost 的信息。
首先需要安装openssh-server。
[sql]view plaincopyprint?1. s udo apt-get install openssh-server其次是配置SSH使得Hadoop应用能够实现无密码登录:[sql]view plaincopyprint?1. s u - hadoop2. s sh-keygen -trsa -P ""3. c p ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys第一条命令将当前用户切换为hadoop(如果当前用户就是hadoop,则无需输入),第二条命令将生成一个公钥和私钥对(即id_dsa和id_dsa.pub两个文件,位于~/.ssh文件夹下),第三条命令使得hadoop用户能够无需输入密码通过SSH访问localhost。
Hadoop平台搭建简介

点击Arguments进行输入输出路径的设臵,如上图: 其中hdfs://node3/user/fengling/400为输入路径 hdfs://node3/user/fengling/out400为输出路径
JobTracker
应用程序提交到集群后由它决定哪个文件被处理,为不同的 task分配节点。每个集群只有一个JobTracker,一般运行在集群 的Master节点上。
DataNode
集群每个服务器都运行一个DataNode后台程序,这个后台
程序负责把HDFS数据块读写到本地的文件系统。
TaskTracker
指令sudo vi hdfs-site.xml
指令sudo vi mapred-site.xml
至此,Master节点的配臵已经基本完成,重启系统后执行 Hadoop,成果结果如下图所示
安装Slaves节点 将配臵好的Master(node3)复制为node4,node5,node6虚拟机。 复制前关闭Master,复制过程如下:
在hadoop installation directory后面填写保存的路径。设臵完 即可点击确定。
在如下图所示的Map/Reduce Location下空白地方点击,选 择New Hadoop location
Location nam可以随意填写,左边Host内填写的是jobtrack er所在集群机器,这里写node3。左边的port为node3的port, 为8021,右边的port为namenode的port,为8020。User na me为用户名。
以程序wordcount为例用指令hadoopdfscatout400进行查看即可看到输出文件out400自己设定中的部分内容程序分析程序分析wordcount是一个词频统计程序用来输入文件内的每个单词出现的次数统计出来如下
hadoop分布式环境搭建实验总结
hadoop分布式环境搭建实验总结Hadoop分布式环境搭建实验总结一、引言Hadoop是目前最流行的分布式计算框架之一,它具有高可靠性、高扩展性和高效性的特点。
在本次实验中,我们成功搭建了Hadoop分布式环境,并进行了相关测试和验证。
本文将对实验过程进行总结和归纳,以供参考。
二、实验准备在开始实验之前,我们需要准备好以下几个方面的内容:1. 硬件环境:至少两台具备相同配置的服务器,用于搭建Hadoop 集群。
2. 软件环境:安装好操作系统和Java开发环境,并下载Hadoop 的安装包。
三、实验步骤1. 安装Hadoop:解压Hadoop安装包,并根据官方文档进行相应的配置,包括修改配置文件、设置环境变量等。
2. 配置SSH无密码登录:为了实现集群间的通信,需要配置各个节点之间的SSH无密码登录。
具体步骤包括生成密钥对、将公钥分发到各个节点等。
3. 配置Hadoop集群:修改Hadoop配置文件,包括core-site.xml、hdfs-site.xml和mapred-site.xml等,设置集群的基本参数,如文件系统地址、数据存储路径等。
4. 启动Hadoop集群:通过启动NameNode、DataNode和ResourceManager等守护进程,使得集群开始正常运行。
可以通过jps命令来验证各个进程是否成功启动。
5. 测试Hadoop集群:可以使用Hadoop自带的例子程序进行测试,如WordCount、Sort等。
通过执行这些程序,可以验证集群的正常运行和计算能力。
四、实验结果经过以上步骤的操作,我们成功搭建了Hadoop分布式环境,并进行了相关测试。
以下是我们得到的一些实验结果:1. Hadoop集群的各个节点正常运行,并且能够相互通信。
2. Hadoop集群能够正确地处理输入数据,并生成期望的输出结果。
3. 集群的负载均衡和容错能力较强,即使某个节点出现故障,也能够继续运行和处理任务。
hadoop的基本使用
hadoop的基本使用Hadoop的基本使用Hadoop是一种开源的分布式计算系统和数据处理框架,具有可靠性、高可扩展性和容错性等特点。
它能够处理大规模数据集,并能够在集群中进行并行计算。
本文将逐步介绍Hadoop的基本使用。
一、Hadoop的安装在开始使用Hadoop之前,首先需要进行安装。
以下是Hadoop的安装步骤:1. 下载Hadoop:首先,从Hadoop的官方网站(2. 配置环境变量:接下来,需要将Hadoop的安装目录添加到系统的环境变量中。
编辑~/.bashrc文件(或其他相应的文件),并添加以下行:export HADOOP_HOME=/path/to/hadoopexport PATH=PATH:HADOOP_HOME/bin3. 配置Hadoop:Hadoop的配置文件位于Hadoop的安装目录下的`etc/hadoop`文件夹中。
其中,最重要的配置文件是hadoop-env.sh,core-site.xml,hdfs-site.xml和mapred-site.xml。
根据具体需求,可以在这些配置文件中进行各种参数的设置。
4. 启动Hadoop集群:在完成配置后,可以启动Hadoop集群。
运行以下命令以启动Hadoop集群:start-all.sh二、Hadoop的基本概念在开始使用Hadoop之前,了解一些Hadoop的基本概念是非常重要的。
以下是一些重要的概念:1. 分布式文件系统(HDFS):HDFS是Hadoop的核心组件之一,用于存储和管理大规模数据。
它是一个可扩展的、容错的文件系统,能够在多个计算机节点上存储数据。
2. MapReduce:MapReduce是Hadoop的编程模型,用于并行计算和处理大规模数据。
它由两个主要的阶段组成:Map阶段和Reduce阶段。
Map阶段将输入数据切分为一系列键值对,并运行在集群中的多个节点上。
Reduce阶段将Map阶段的输出结果进行合并和计算。
Haoop实验环境的搭建
一、Hadoop的散布式模式安装进程:(Ubuntu Linux)一、集群环境介绍集群环境中有三个结点,其中1个namenode,2个datanode,它们之间散布在局域网中,彼此之间能够ping通。
具体的IP地址为:namenode:datanode1:datanode2:三台结点运算机都是Ubuntu Linux 系统,是在Virtual 中的虚拟机,而且都有一个相同的用户quinty(安装系统时的首个用户,具有管理员的权限),在/home/quinty目录下均有一个hadoopinstall目录,用于寄存安装文件,hadoop的整个目录结构是/home/quinty/hadoopinstall/。
二、预备工作1)ssh无密码验证配置Hadoop需要利用ssh协议,namenode利用ssh协议启动namenode和datanode进程,为使Hadoop集群能够正常启动,需要在namenode和datanode结点之间设置ssh无密码验证。
A.安装和启动ssh协议(所有机械上)$sudo apt-get install ssh (安装ssh)$sudo apt-get install rsync$ssh sudo /etc/ssh restart (启动ssh,无所谓)执行完毕,机械之间能够通过密码验证彼此登录。
B.生成密码对(所有机械)~$ssh-keygen -t rsa sh 目录下生成私钥id_rsa和公钥~$chmod 755 .sshC.在namenode结点上做配置~/.ssh$cp authorized_keys sh$scp authorized_keys data结点的ip地址:/home/quinty/.ssh datanode结点上做配置~/.ssh$scp 的ip地址.然后在namenode中,~/.ssh$cat datanode 的ip地址. >> authorized_keys如此datanode 能够无密码登录namenode(ssh ip地址验证)2)jdk安装及环境配置下载Linux环境下的JDK安装包,#chmod 755#./ 动hadoopbin/ (结束是bin/)启动hadoop成功后,在namenode中的tmp文件夹中生成了dfs文件夹,在所有datanode 中的tmp文件夹中均生成了dfs文件夹和mapred文件夹。
大数据--Hadoop集群环境搭建
⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
ssh-keygen -t rsa
111.111.111.2
slaves文件添加如下内容:
111.111.111.3
111.111.111.4
5.修改以下3个XML配置文件
首先hadoop-env.sh中添加如下语句:
export JAVA_HOME=/usr/jdk1.6.0_30
core-site.xml添加如下语句在<configuration></configuration>之间:
启动ssh server
/etc/init.d/ssh start
启动后ps -ef|grep ssh
存在sshd进程即表明ssh服务安装成功。
配置
以master主机到slave1主机的ssh信任关系配置过程为例。
先以root身份登录两台主机,修改/etc/hosts文件为以下内容:
127.0.0.1 localhost
这个命令将为用户hadoop生成密钥对,询问其保存路径时直接回车采用默认路径,当提示要为生成的密钥输入passphrase的时候,直接回车,也就是将其设定为空密码。生成的密钥对id_rsa,id_rsa.pub,保存在/home/hadoop/.ssh目录下。
hadoop@slave1:/home/hadoop
其中wordcount为程序主类名,input和output分别为输入、输出文件夹。
运行结果如下:
hadoop@master:~$ hadoop jar /usr/hadoop-0.20.2/hadoop-0.20.2-examples.jar wordcount input output
14/02/20 15:59:58 INFO input.FileInputFormat: Total input paths to process : 2
完了重启网络/etc/init.d/networking restart
4.测试网络
在物理主机ping虚拟机:
在虚拟机ping物理机:
在
打开虚拟机的设置界面,添加共享文件夹,如下图所示:
已root身份登录虚拟机
创建挂载目录:
mkdir /mnt/share
挂载共享目录:
mount -t vboxsf vmshared /mnt/share
3.在/etc/profile中增加hadoop环境变量:
export HADOOP_HOME=/usr/hadoop-0.20.2
export PATH=$PATH:$HADOOP_HOME/bin
4.修改hadoop的配置文件,在/usr/hadoop-0.20.2/conf下
masters文件添加如下内容:
到/download/explain.php?fileid=19826494下载以下三个文件
openssh-client_5.3p1-3ubuntu3_i386.deb
openssh-server_5.3p1-3ubuntu3_i386.deb
把slave1的公钥拷贝到master的authorized_keys,中间会有提示输入hadoop@slave1的密码
hadoop@master:/home/hadoop
scp~/.ssh/authorized_keys slave1:~/.ssh/authorized_keys
把authorized_keys文件拷回slave1
访问http://111.111.111.2:50030/查看mapreduce状态:
用hadoop dfsadmin -report命令查看hadoop各节点状态:
worldcount
worldcount实例相当于hadoop上的Hello Wolrd程序,是hadoop入门的必学例子。该实例的编译程序已打包在hadoop安装目录/usr/hadoop-0.20.2/hadoop-0.20.2-examples.jar文件中,可以直接启动来测试输出结果。
vmshared是共享文件夹的名字。
注意执行mount命令时当前目录一定不能是挂载目录/mnt/share。
如下图,物理主机D:\vmshared目录下的文件已在虚拟机的/mnt/share下共享。
离线安装
由于我的虚拟机在内网,无法通过apt-get来在线安装ssh服务,下面介绍一下离线安装openssh-server服务。
6.把配置好的hadoop复制到slave主机
scp -rp /usr/hadoop-0.20.2slave1:/home/hadoop
ssh slave1
su root
cp -R /home/hadoop/hadoop-0.20.2/usr/
chown -R hadoop:hadoop/usr/hadoop-0.20.2/
依次选择打开“属性”-“internet协议”,设置该网卡的IP。为了避免与公司的内网IP冲突,这里设置为111.111.111.1,点击确定。如下图所示:
3.设置ubuntu的网卡IP,第一个网卡eth0设置为dhcp获取ip,第二个网卡eth1设置为静态ip。/etc/network/interfaces文件配置如下:
此时master到slave1的shh信任关系已经配好。进入hadoop@master:/home/hadoop/.ssh目录,可以看到以下4个文件:
hadoop@masterFra bibliotek~/.ssh$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
master到slave2的信任关系如法炮制。注意如果IP有变更的话ssh信任关系需要重新配置。
hdfs-site.xml添加如下语句在<configuration></configuration>之间:
replication默认为3,如果不修改,datanode少于三台就会报错
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name></name>
<value>hdfs://111.111.111.2:9000</value>
</property>
<property>
<name>fs.tmp.dir</name>
<value>/home/hadoop/tmp</value>
1.创建本地示例文件
以hadoop身份登录master,在/home/hadoop/file目录下创建file1.txt和file2.txt,内容分别如下:
2.在HDFS上创建输入文件夹input
3.上传本地文件到HDFS的input目录下
4.运行例子
运行命令如下:
hadoop jar /usr/hadoop-0.20.2/hadoop-0.20.2-examples.jar wordcount input output
slave2如法复制。
7.格式化hadoop文件系统,启动hadoop
cd $HADOOP_HOME/bin
./hadoop namenode -format #格式化文件系统
./start-all.sh #启动namenode上的hadoop
不熟悉hadoop命令的可以直接敲入hadoop然后回车看命令的用法
export JAVA_HOME=/usr/jdk1.6.0_30
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin