hadoop伪分布式搭建2.0
《大数据技术原理与操作应用》第6章习题答案

第六章单选题1、Hadoop2.0集群服务启动进程中,下列选项不包含的是()。
•A、NameNode•B、JobTracker•C、DataNode•D、ResourceManager参考答案:B答案解析:暂无解析2、关于SecondaryNameNode哪项是正确的?•A、它是NameNode的热备•B、它对内存没有要求•C、它的目的是帮助NameNode合并编辑日志,减少NameNode启动时间•D、SecondaryNameNode应与NameNode部署到一个节点参考答案:C答案解析:暂无解析3、HDFS中的Block默认保存()份。
•A、3份•B、2份•C、1份•D、不确定参考答案:A答案解析:HDFS中的Block默认保存3份。
4、一个gzip文件大小75MB,客户端设置Block大小为64MB,占用Block的个数是()。
•A、1•B、2•C、3•D、4参考答案:B答案解析:暂无解析5、下列选项中,Hadoop2.x版本独有的进程是()。
•A、JobTracker•B、TaskTracker•C、NodeManager•D、NameNode参考答案:C答案解析:暂无解析6、下列哪项通常是集群的最主要的性能瓶颈?•A、CPU•B、网络•C、磁盘•D、内存参考答案:C答案解析:暂无解析判断题1、NameNode的Web UI端口是50030,它通过jetty启动的Web服务。
•对•错参考答案:错答案解析:端口号为500702、NodeManager会定时的向ResourceManager汇报所在节点的资源使用情况,并接受处理来自ApplicationMaster的容器启动、停止等各种请求•对•错3、Hadoop HA是集群中启动两台或两台以上机器充当NameNode,避免一台NameNode 节点发生故障导致整个集群不可用的情况。
•对•错参考答案:对答案解析:Hadoop HA是集群中启动两台或两台以上机器充当NameNode,避免一台NameN ode节点发生故障导致整个集群不可用的情况。
hadoop2.0安装

Hadoop2.0配置SSH安装在线安装ssh #sudo apt-get install openssh-serveropenssh-client手工安装ssh存储ssh密码#ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa#cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys#sudo chmod go-w $HOME $HOME/.ssh#sudo chmod 600 $HOME/.ssh/authorized_keys#sudo chown `whoami` $HOME/.ssh/authorized_keys测试连接本地服务,无密码登陆,则说明ssh服务安装配置正确#ssh localhost#exit安装JDK安装必须1.6或者1.6以上版本。
#sudo mkdir /usr/java#cd /usr/java#sudo wget/otn-pub/java/jdk/6u31-b04/jdk-6u31-linux-i586.bin #sudo chmod o+w jdk-6u31-linux-i586.bin#sudo chmod +x jdk-6u31-linux-i586.bin#sudo ./jdk-6u31-linux-i586.bin修改环境变量/etc/profile文件中增加如下代码export JA V A_HOME=/usr/java/jdk1.6.0_24export PATH=$PATH:/usr/java/jdk1.6.0_24/binexport CLASSPA TH=/usr/java/jdk1.6.0_24/lib/dt.jar:/usr/java/jdk1.6.0_24/lib/tools.jar#source /etc/profile测试# java -version显示java版本,则证明安装配置正确安装hadoop选择一个linux系统,下载并解压hadoop2.0.x并解压到/home/hadoop-2.0.0-alpha。
Hadoop伪分布式安装

Hadoop伪分布式安装1.安装Hadoop(伪分布式)
上传Hadoop
将hadoop-2.9.2.tar.gz 上传到该目录
解压
ls
将Hadoop添加到环境变量
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出vim
验证环境变量是否正确hadoop version
修改配置文件hadoop-env.sh
保存并退出vim
修改配置文件core-site.xml
保存并退出vim
修改配置文件hdfs-site.xml
</property>
保存并退出vim
格式化HDFS
hdfs namenode -format
格式化成功的话,在/bigdata/data目录下可以看到dfs目录
启动NameNode
启动DataNode
查看NameNode管理界面
在windows使用浏览器访问http://bigdata:50070可以看到HDFS的管理界面
如果看不到,(1)检查windows是否配置了hosts;
位于C:\Windows\System32\drivers\etc\hosts
关闭HDFS的命令
2.配置SSH免密登录生成密钥
回车四次即可生成密钥
复制密钥,实现免密登录
根据提示需要输入“yes”和root用户的密码
新的HDFS启停命令
免密登录做好以后,可以使用start-dfs.sh和stop-dfs.sh命令启停HDFS,不再需要使用hadoop-daemon.sh脚本
stop-dfs.sh
注意:第一次用这个命令可能还是需要输入yes,按提示输入即可。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
简述hadoop伪分布式安装配置过程

Hadoop伪分布式安装配置过程在进行Hadoop伪分布式安装配置之前,首先需要确保系统环境符合安装要求。
Hadoop的安装需要在Linux系统下进行,并且需要安装好Java环境。
以下将详细介绍Hadoop伪分布式安装配置的步骤。
一、准备工作1. 确保系统为Linux系统,并且已经安装好Java环境。
2. 下载Hadoop安装包,并解压至指定目录。
二、配置Hadoop环境变量1. 打开.bashrc文件,添加以下内容:```bashexport HADOOP_HOME=/path/to/hadoopexport PATH=$PATH:$HADOOP_HOME/binexport HADOOP_CONF_DIR=/path/to/hadoop/etc/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOME```2. 执行以下命令使环境变量生效:```bashsource ~/.bashrc```三、配置Hadoop1. 编辑hadoop-env.sh文件,设置JAVA_HOME变量:```bashexport JAVA_HOME=/path/to/java```2. 编辑core-site.xml文件,添加以下内容:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>```3. 编辑hdfs-site.xml文件,添加以下内容:```xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>```4. 编辑mapred-site.xml.template文件,添加以下内容并保存为mapred-site.xml:```xml<configuration><property><name></name><value>yarn</value></property></configuration>```5. 编辑yarn-site.xml文件,添加以下内容:```xml<configuration><property><name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name> <value>localhost</value></property></configuration>```四、格式化HDFS执行以下命令格式化HDFS:```bashhdfs namenode -format```五、启动Hadoop1. 启动HDFS:```bashstart-dfs.sh```2. 启动YARN:```bashstart-yarn.sh```六、验证Hadoop安装通过浏览器访问xxx,确认Hadoop是否成功启动。
《Hadoop大数据技术》课程实验教学大纲
《Hadoop大数据技术》实验教学大纲一、课程基本情况课程代码:1041139课程名称:Hadoop大数据技术/Hadoop Big Data Technology课程类别:专业必修课总学分:3.5总学时:56实验/实践学时:24适用专业:数据科学与大数据技术适用对象:本科先修课程:JA V A程序设计、Linux基础二、课程简介《Hadoop大数据技术》课程是数据科学与大数据技术专业的专业必修课程,是数据科学与大数据技术的交叉学科,具有极强的实践性和应用性。
《Hadoop大数据技术》实验课程是理论课的延伸,它的主要任务是使学生对Hadoop平台组件的作用及其工作原理有更深入的了解,提高实践动手能力,并为Hadoop大数据平台搭建、基本操作和大数据项目开发提供技能训练,是提高学生独立操作能力、分析问题和解决问题能力的一个重要环节。
三、实验项目及学时安排四、实验内容实验一Hadoop环境搭建实验实验目的:1.掌握Hadoop伪分布式模式环境搭建的方法;2.熟练掌握Linux命令(vi、tar、环境变量修改等)的使用。
实验设备:1.操作系统:Ubuntu16.042.Hadoop版本:2.7.3或以上版本实验主要内容及步骤:1.实验内容在Ubuntu系统下进行Hadoop伪分布式模式环境搭建。
2.实验步骤(1)根据内容要求完成Hadoop伪分布式模式环境搭建的逻辑设计。
(2)根据设计要求,完成实验准备工作:关闭防火墙、安装JDK、配置SSH免密登录、Hadoop 安装包获取与解压。
(3)根据实验要求,修改Hadoop配置文件,格式化NAMENODE。
(4)启动/停止Hadoop,完成实验测试,验证设计的合理性。
(5)撰写实验报告,整理实验数据,记录完备的实验过程和实验结果。
实验二(1)Shell命令访问HDFS实验实验目的:1.理解HDFS在Hadoop体系结构中的角色;2.熟练使用常用的Shell命令访问HDFS。
《大数据技术基础》-课程教学大纲

《大数据技术基础》课程教学大纲一、课程基本信息课程代码:16176903课程名称:大数据技术基础英文名称:Fundamentals of Big Data Technology课程类别:专业课学时:48学分:3适用对象: 软件工程,计算机科学与技术,大数据管理考核方式:考核先修课程:计算机网络,云计算基础,计算机体系结构,数据库原理,JA V A/Python 程序设计二、课程简介当前在新基建和数字化革命大潮下,各行各业都在应用大数据分析与挖掘技术,并紧密结合机器学习深度学习算法,可为行业带来巨大价值。
这其中大数据处理与开发框架等大数据技术是进行数字化,数智化应用建设的核心和基础,只有努力提升大数据处理与开发技术与性能,建立行业数字化和智能化转型升级才能成功。
大数据处理与开发技术是新基建和数字化革命核心与基础。
大数据技术基础课程,为学生搭建起通向“大数据知识空间”的桥梁和纽带,以“构建知识体系、阐明基本原理、引导初级实践、了解相关应用”为原则,为学生在大数据领域“深耕细作”奠定基础、指明方向。
课程将系统讲授大数据的基本概念、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、分布式并行编程模型MapReduce、基于内存的大数据处理架构Spark、大数据在互联网、生物医学和物流等各个领域的应用。
在Hadoop、HDFS、HBase、MapReduce、Spark等重要章节,安排了入门级的实践操作,让学生更好地学习和掌握大数据关键技术。
同时本课程将介绍最前沿的业界大数据处理与开发技术和产品平台,包括阿里大数据服务平台maxcompute,华为大数据云服务平台FusionInsight,华为高性能分布式数据库集群GaussDB等业界最先进技术,以及国家大数据竞赛平台网站和鲸社区。
让学生学以致用,紧跟大数据领域最领先技术水平,同时,面对我国民族企业,头部公司在大数据领域取得的巨大商业成功与前沿技术成果应用产生强烈民族自豪感,为国家数字化经济与技术发展努力奋斗,勇攀知识高峰立下志向。
Hadoop集群部署有几种模式?Hadoop集群部署方法介绍
Hadoop集群的部署分为三种,分别独立模式(Standalonemode)、伪分布式模式(Pseudo-Distributedmode)、完全分布式模式(Clustermode),具体介绍如下。
(1)独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的
程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常
方便,所以一般情况下,该模式在学习或者发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台节上,通常使用伪分布
式模式用来调试Hadoop分布式程序的代码,以及程序执行否正确,伪分布式模式完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节担任不同的角色,在实际工作应用发中,通常使用该模式构建级Hadoop系统。
在Hadoop环境中,所有器节仅划分为两种角色,分别master(主节,1个)和slave(从节,多个)。
因此,伪分布模式集群模式的特例,只将主节和从节合二
为一罢了。
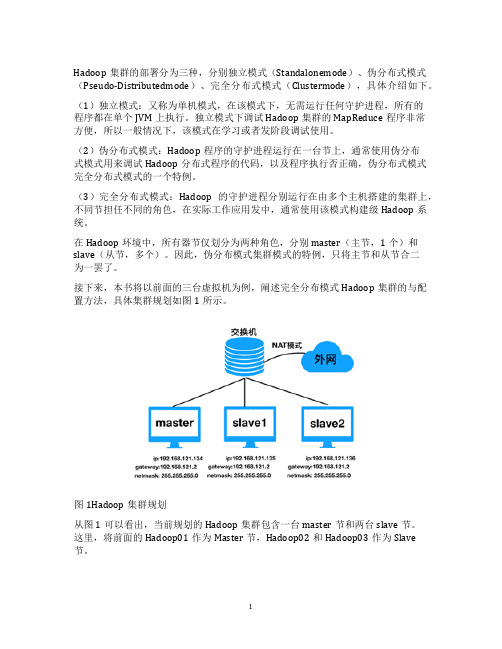
接下来,本书将以前面的三台虚拟机为例,阐述完全分布模式Hadoop集群的与配置方法,具体集群规划如图1所示。
图1Hadoop集群规划
从图1可以看出,当前规划的Hadoop集群包含一台master节和两台slave节。
这里,将前面的Hadoop01作为Master节,Hadoop02和Hadoop03作为Slave
节。
1。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. virtualbox安装1. 1. 安装步骤1. 2. virtualbox安装出错情况1. 2.1. 安装时直接报发生严重错误1. 2.2. 安装好后,打开Vitualbox报创建COM对象失败,错误情况11. 2.3. 安装好后,打开Vitualbox报创建COM对象失败,错误情况21. 2.4. 安装将要成功,进度条回滚,报“setup wizard ended prematurely”错误2. 新建虚拟机2. 1. 创建虚拟机出错情况2. 1.1. 配制好虚拟光盘后不能点击OK按钮3. 安装Ubuntu系统3. 1. 安装Ubuntu出错情况3. 1.1. 提示VT-x/AMD-V硬件加速在系统中不可用4. 安装增强功能4. 1. 安装增强功能出错情况4. 1.1. 报未能加载虚拟光盘错误5. 复制文件到虚拟机5. 1. 复制出错情况5. 1.1. 不能把文件从本地拖到虚拟机6. 配置无秘登录ssh7. Java环境安装7. 1. 安装Java出错情况7. 1.1. 提示不能连接8. hadoop安装8. 1. 安装hadoop的时候出错情况8. 1.1. DataNode进程没启动9. 开机自启动hadoop10. 关闭服务器(需要时才关)1. virtualbox安装1. 1. 安装步骤1.选择hadoop安装软件中的VirtualBox-6.0.8-130520-Win2.双击后进入安装界面,然后直接点击下一步3.如果不想把VirtualBox安装在C盘,那么点击浏览4.直接把最前面的C改成D注意:安装路径中不能有中文如果只有一个C盘,那么这里就不用改动了5.然后直接点击下一步就行了6.这个界面直接点下一步就行7.网络界面的时候直接点“是”就行8.然后点击安装9.在用户账户控制里面点击“是”10.安装完成出现如下界面,点击完成就行11.然后出现如下界面1. 2. virtualbox安装出错情况1. 2.1. 安装时直接报发生严重错误1. 右键点击此电脑,选择管理2. 选择服务和应用程序下面的服务3. 查看如下两个服务的状态4. 如果不是显示的正在运行,那么右键点击服务,然后启动它5. 启动好这两个服务过后,再重新安装VirtulBox1. 2.2. 安装好后,打开Vitualbox报创建COM对象失败,错误情况1这种错误也有可能是没有启用硬件虚拟化,以下是常用笔记本启用虚拟化技术的方法1. 惠普笔记本启用虚拟化功能2. 戴尔笔记本启用虚拟化功能3. 联想笔记本启用虚拟化功能4. 华硕笔记本启用虚拟化功能5. 其他品牌电脑可以按如下方式到百度中搜索电脑品牌怎么启用虚拟化技术1. 2.3. 安装好后,打开Vitualbox报创建COM对象失败,错误情况2这种可能是你的路径中有中文。
如果确实有中文,那就需要把VirtualBox卸载掉,然后重新安装,不要安装在有中文的路径中。
1. 2.4. 安装将要成功,进度条回滚,报“setup wizard ended prematurely”错误这种错误往往是因为之前安装过VirtualBox,卸载后重装可能遇到这种问题,遇到这种问题,在下图的步骤中把红色方框标注的这两个功能,点击一下,然后选择不安装这个功能,基本能解决2. 新建虚拟机新建虚拟机相当于你自己制作了一台电脑,当然这台电脑是虚拟的,不是我们看得见的电脑。
新建虚拟机需要设置内存和磁盘容量。
1.点击新建,我们开始制作电脑了。
2.这里我们要设置这个电脑安装什么系统,我们名称那里写Ubuntu,写完这个名称过后,它能自动检测是什么系统,你们可以看看类型这里是不是Linux,版本是不是Ubuntu(64-bit)或者Ubuntu-64,如果是的,就没有问题。
3.然后弹出内存设置界面,如果你电脑内存是8G,那么这里填2048,;如果你电脑内存是4G,那么这里填15004.然后就是虚拟硬盘的配置,我们选择现在创建虚拟硬盘5.接下来的这步直接点击下一步就OK6.然后选择动态分配7.然后选择虚拟硬盘存储位置,这个存储目录要足够大,至少要分配20G的存储空间存储目录不要选在磁盘根目录下,存储目录中最好不要有中文8.然后点击下一步,然后弹出的界面就有一个这个界面9.选中Ubuntu,然后点击设置10. 然后选择存储,之后选择控制器:IDE下面的没有盘片,然后点选右侧的圆形的像光盘的按钮11. 然后点击选择一个虚拟光盘文件,然后选择我给你们的ubuntu-19.04-desktop-amd64.iso这个文件,然后点击OK,出现如下界面12. 然后点击OK,返回主界面至此虚拟机的设置就完毕了,恭喜你,可以进入下一步了。
2. 1. 创建虚拟机出错情况2. 1.1. 配制好虚拟光盘后不能点击OK按钮如果这里的OK按钮是灰色的,那就是你电脑的虚拟化技术没有启用。
需参照1.2.2小节3. 安装Ubuntu系统在安装Ubuntu之前最好把电脑网络断开,这样安装时间能够大大节省1.首先点击启动,这样就相当于启动了你制造的电脑2.等待一会出现如下界面,表示进入安装Ubuntu系统的界面了3.左边的语言栏,拖到最下面,有中文(简体),选择它3.然后点击安装Ubuntu4. 弹出键盘布局界面,直接继续,如果默认的是英语,也没关系的,直接点击继续5. 弹出如下界面,也选继续6. 弹出如下界面,直接选择现在安装7. 出现如下界面,选择继续8. 弹出如下界面时,现在圆点的那个地方用鼠标左键点击一下,然后选择继续9. 弹出如下界面,按照我的截图进行填写,密码直接使用hadoop,填好后点击继续然后等着就行。
10. 出现如下界面,表示安装完成,点击现在重启11. 重启后界面如下,直接按回车键就行12. 出现这个界面,选中hadoop用户名,左键点击一下13. 然后输入密码就能进入系统14. 第一次进入系统会出现如下界面,直接点击跳过3. 1. 安装Ubuntu出错情况3. 1.1. 提示VT-x/AMD-V硬件加速在系统中不可用如果启动虚拟机出现上面图片中的错误,那么就是硬件虚拟化技术没有启用,请参考1.2.2小节4. 安装增强功能增强功能能够实现本地电脑和虚拟电脑之间的粘贴板互通,相互复制,还可以相互之间复制文件,也能把虚拟机的分辨率调成和本地电脑一样刚开始你们的虚拟机的窗口就和这一样,很小。
这个时候需要安装增强功能1. 进入系统过后,选择最上方的菜单栏中的设备,设备下面有个安装增强功能,点击一下2. 弹出界面,直接点击运行3. 弹出界面,这个时候输入密码,然后点击认证4. 等待安装完成,安装完之后会出现Press Return to close this window,这个时候你们直接按回车就行。
5. 这时你的虚拟机屏幕就变大了6. 设置粘贴板共享,选择设备下面的共享粘贴板,然后设置为双向7. 启用拖放功能,能够实现本机和虚拟机之间的文件相互复制8. 一定要记得重启虚拟机4. 1. 安装增强功能出错情况4. 1.1. 报未能加载虚拟光盘错误如果出现上面这种错误,这需要如下几步来解决1. 点击系统左侧栏中的文件夹图标2. 点击光盘右侧的那个三角图标,卸载光盘3. 卸载后,再次点击安装增强功能,等安装完成后,重启虚拟机5. 复制文件到虚拟机1. 缩小虚拟机和hadoop安装软件的界面,让他们能够在一个屏幕显示需要复制的是hadoop-2.9.2.tar.gz和jdk-12.0.2_linux-x64_bin.tar.gz这两个文件2. 打开虚拟机中的主目录,通过点击左侧栏的文件夹图标3. 复制hadoop文件到虚拟机,步骤参考下面的图片4. 同理复制jdk文件5. 1. 复制出错情况5. 1.1. 不能把文件从本地拖到虚拟机这种情况下需要按照如下几步来解决,要首先联网,确保能够上网的情况下执行下面几步1. 如果终端界面没有打开,使用Ctrl+Alt+T三个按键一起按,然后会弹出如下界面调出界面后,就在这个终端里面输入后面的这些命令。
首先更新apt资源池,输入如下命令sudo apt update安装gcc、perl、make,输入如下命令sudo apt install gcc make perl调出界面后,就在这个终端里面输入后面的这些命令。
2. 首先更新apt资源池,输入如下命令sudo apt update命令输入后,会出现如下的类似界面命令执行完成后,有类似的界面,你要注意看看有没有报错,有报错的情况一般都是你没有联网3. 安装ssh程序,输入如下命令7. Java环境安装5. 在文件末尾加入下面的两行文字export JAVA_HOME=/usr/local/jdk export PATH=$PATH:$JAVA_HOME/bin修改后的应该是这样的情况如果出现如下提示信息说明安装成功,否则配置不成功在文件末尾加上如下两行命令export HADOOP_HOME=/usr/local/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后把下面的内容整体替换掉当前文件的内容<configuration><!--- global properties -->7. 编辑hdfs-site.xml文件,这个文件是用作配置hdfs的各项属性的,输入如下命令然后把下面的内容整体替换掉当前文件的内容<configuration><property><name>dfs.replication</name><value>1</value><description>Default block replication.8. 编辑mapred-site.xml文件,这个文件主要是对mapreduce进行配置,输入如下命令sudo gedit mapred-site.xml这个文件原来不存在,所以弹出的界面里面显示为空然后把下面的内容拷贝到文件中9. 编辑yarn-site.xml文件,这个文件主要是对yarn进行设置,输入如下命令sudo gedit yarn-site.xml打开成功,弹出如下界面把如下内容替换掉文件中的内容<configuration><property><description>The hostname of the RM.</description> <name>yarn.resourcemanager.hostname</name><value>localhost</value></property>10. 编辑hadoop-env.sh文件,设置JAVA_HOME环境变量,输入如下命令sudo gedit hadoop-env.sh打开成功后,出现如下界面然后使用Ctrl+F,调出查找界面,输入JAVA_HOME,我们需要修改的就是红色方框里面。