hadoop安装最终版
hadoop安装

Impala安装——Hadoop安装1.安装jdk下载jdk安装文件,注意版本(请根据自己系统选择正确版本jdk,建议使用64位jdk1.6以上版本),这里以jdk-6u45-linux-x64.bin为例:1)创建java安装路径(/usr/local/java):2)将jdk-6u45-linux-x64.bin拷贝到/usr/local/java下面,修改权限,并开始安装:3)修改配置文件,并使之生效:4)现在可以在控制台窗口下面,键入查看jdk版本,正确安装的话将会像是jdk版本:5)至此,jdk安装成功。
如果配置没有生效的话,建议重启。
2.配置ssh服务Hadoop在运行过程中,会远程调用其他机器上的命令,因此要求集群机器之间实现免密码登陆,因此我们需要配置ssh。
1)假设hadoop集群由三台机器构成,分别IP是:192.168.1.101、192.168.1.102、192.168.1.103。
其中我们以101为namenode和master,修改本机hostname和/etc/hosts,方便用户访问(以101为例),内容如下:2)建议永久关闭防火墙,并重启系统,命令如下:3)开始配置ssh服务,在hadoop1机器上,运行以下命令生成公私钥:4)将公钥添加到认证文件中:5)修改sshd配置服务,修改内容如下:6)重启sshd服务,命令如下:自此,可以实现本地的免密钥登陆。
为实现本机可以实现免密钥登陆其他机器,可以将本机的公钥(id_rsa.pub)远程复制到其他机器(使用scp命令),并将该公钥添加到远程机器的相同位置的authorized_keys里,即可实现当前机器免密钥登陆到远程机器(如果无法实现无密码访问,请查看authorized_keys文件的权限600)。
重复上述修改hostname、/etc/hosts、防火墙、ssh的过程,即可实现机器之间两两免密钥登陆的目的。
简单梳理hadoop安装流程文字

简单梳理Hadoop安装流程
今儿个咱们来简单梳理下Hadoop的安装流程,让各位在四川的兄弟姐妹也能轻松上手。
首先,你得有个Linux系统,比如说CentOS或者Ubuntu,这点很重要。
然后在系统上整个Java环境,Hadoop 是依赖Java运行的。
把JDK下载安装好后,记得配置下环境变量,就是修改`/etc/profile`文件,把Java的安装路径加进去。
接下来,你需要在系统上整个SSH服务,Hadoop集群内部的通信要用到。
安好SSH后,记得配置下无密钥登录,省得每次登录都要输密码,多麻烦。
Hadoop的安装包可以通过官方渠道下载,也可以在网上找现成的。
下载好安装包后,解压到你的安装目录。
然后就开始配置Hadoop的环境变量,跟配置Java环境变量一样,也是在
`/etc/profile`文件里加路径。
配置Hadoop的文件是重点,都在Hadoop安装目录下的`etc/hadoop`文件夹里。
有`hadoop-env.sh`、`core-site.xml`、`hdfs-site.xml`这些文件需要修改。
比如`core-site.xml`里要设置HDFS的地址和端口,`hdfs-site.xml`里要设置临时目录这些。
最后,就可以开始格式化HDFS了,用`hdfs namenode-format`命令。
然后启动Hadoop,用`start-all.sh`脚本。
如果一
切配置正确,你就可以用`jps`命令看到Hadoop的各个进程在运行了。
这整个过程看似复杂,但只要你跟着步骤来,注意配置文件的路径和内容,相信你也能轻松搞定Hadoop的安装。
Hadoop集群安装详细步骤亲测有效

Hadoop集群安装详细步骤亲测有效第一步:准备硬件环境- 64位操作系统,可以是Linux或者Windows-4核或更高的CPU-8GB或更高的内存-100GB或更大的硬盘空间第二步:准备软件环境- JDK安装:Hadoop运行需要Java环境,所以我们需要先安装JDK。
- SSH配置:在主节点和从节点之间建立SSH连接是Hadoop集群正常运行的前提条件,所以我们需要在主节点上生成SSH密钥,并将公钥分发到从节点上。
第四步:配置Hadoop- core-site.xml:配置Hadoop的核心参数,包括文件系统的默认URI和临时目录等。
例如,可以将`hadoop.tmp.dir`设置为`/tmp/hadoop`。
- hdfs-site.xml:配置Hadoop分布式文件系统的参数,包括副本数量和块大小等。
例如,可以将副本数量设置为`3`。
- yarn-site.xml:配置Hadoop的资源管理系统(YARN)的参数。
例如,可以设置YARN的内存资源分配方式为容器的最大和最小内存均为1GB。
- mapred-site.xml:配置Hadoop的MapReduce框架的参数。
例如,可以设置每个任务容器的内存限制为2GB。
第五步:格式化Hadoop分布式文件系统在主节点上执行以下命令,格式化HDFS文件系统:```hadoop namenode -format```第六步:启动Hadoop集群在主节点上执行以下命令来启动Hadoop集群:```start-all.sh```此命令将启动Hadoop的各个组件,包括NameNode、DataNode、ResourceManager和NodeManager。
第七步:测试Hadoop集群可以使用`jps`命令检查Hadoop的各个进程是否正常运行,例如`NameNode`、`DataNode`、`ResourceManager`和`NodeManager`等进程都应该在运行中。
Hadoop集群安装详细步骤

Hadoop集群安装详细步骤|Hadoop安装配置文章分类:综合技术Hadoop集群安装首先我们统一一下定义,在这里所提到的Hadoop是指Hadoop Common,主要提供DFS(分布式文件存储)与Map/Reduce的核心功能。
Hadoop在windows下还未经过很好的测试,所以笔者推荐大家在linux(cent os 5.X)下安装使用。
准备安装Hadoop集群之前我们得先检验系统是否安装了如下的必备软件:ssh、rsync和Jdk1.6(因为Hadoop需要使用到Jdk中的编译工具,所以一般不直接使用Jre)。
可以使用yum install rsync来安装rsync。
一般来说ssh是默认安装到系统中的。
Jdk1.6的安装方法这里就不多介绍了。
确保以上准备工作完了之后我们就开始安装Hadoop软件,假设我们用三台机器做Hadoop集群,分别是:192.168.1.111、192.168.1.112和192.168.1.113(下文简称111,112和113),且都使用root用户。
下面是在linux平台下安装Hadoop的过程:在所有服务器的同一路径下都进行这几步,就完成了集群Hadoop软件的安装,是不是很简单?没错安装是很简单的,下面就是比较困难的工作了。
集群配置根据Hadoop文档的描述“The Hadoop daemons are N ameNode/DataNode and JobTracker/TaskTracker.”可以看出Hadoop核心守护程序就是由NameNode/DataNode 和JobTracker/TaskTracker这几个角色构成。
Hadoop的DFS需要确立NameNode与DataNode角色,一般NameNode会部署到一台单独的服务器上而不与DataNode共同同一机器。
另外Map/Reduce服务也需要确立JobTracker和TaskTracker的角色,一般JobTracker与NameNode共用一台机器作为master,而TaskTracker与DataNode同属于slave。
Hadoop的安装及配置

Hadoop的安装及配置Hadoop的安装及配置单节点环境搭配(一)安装JDK。
版本1.7以上。
1、java -version查看是否已经安装2、sudo apt-get update3、sudo apt-get install default-jdk4、java -version 确认安装情况5、which java显示安装路径附:java安装方法:1、源码包准备;2、解压源码包通过终端在/usr/local目录下新建java文件夹,命令行:sudomkdir /usr/local/java然后将下载到压缩包拷贝到java文件夹中,命令行:进入jdk源码包所在目录cp jdk-U161-linux-x64.tar.gz /usr/local/java然后进入java目录,命令行:cd /usr/local/java解压压缩包,命令行:sudo tar xvf jdk-u161-linux-x64.tar.gz然后可以把压缩包删除,命令行:sudo rm jdk-u161-linux-x64.tar.gz3、设置jdk环境变量这里采用全局设置方法,它是是所有用户的共用的环境变量sudogedit ~/.bashrc打开之后在末尾添加//注意每行前后不要有多余的空格export JAVA_HOME=/usr/local/java/jdk1.8.0_161 export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH4、java -version看看是否安装成功(二)设置SSH无密码登录1、sudo apt-get install ssh2、sudo apt-get install rsync3、ssh-keygen -t rsa4、ll ~/.ssh 查看生成的密钥(三)hadoop下载安装1、在apache官方网站下载hadoop2、解压tar -zxvf hadoop-2.6.5.tar.gz3、sudo mv hadoop-2.6.5 /usr/local/hadoop4、ll /usr/local/hadoop 查看安装情况(四)hadoop环境变量的设置1、sudogedit ~/.bashrc2、添加下列设置设置HADOOP_HOME为Hadoop的安装路径export HADOOP_HOME=/usr/local/hadoop设置PATHexport PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin3、Hadoop其他环境变量设置export HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HADOOP_HOMEexportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/na tiveexport HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"exportJAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRA RY_PATH4、source ~/.bashrc(五)修改Hadoop配置文件1、设置hadoop-env.sh配置文件sudogedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh修改export JAVA_HOME=/usr/local/java/jdk1.8.0_1612、修改core-site.xmlsudo vim /usr/local/hadoop/etc/hadoop/core-site.xml/doc/eb13635280.html,hdfs://localhost:9000。
自制hadoop安装详细过程
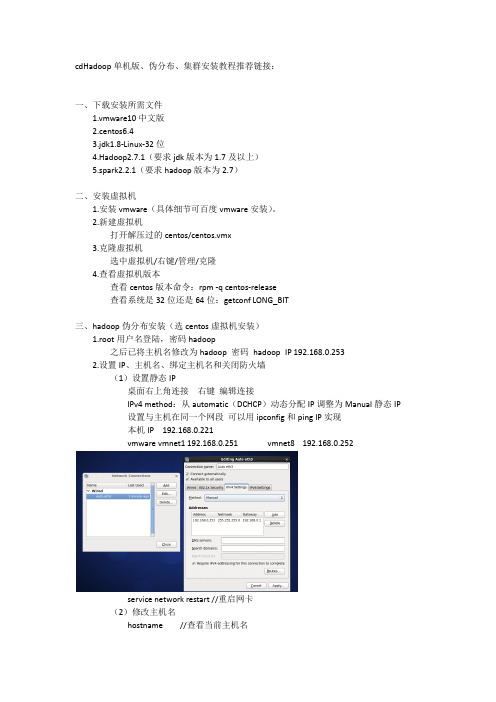
cdHadoop单机版、伪分布、集群安装教程推荐链接:一、下载安装所需文件1.vmware10中文版2.centos6.43.jdk1.8-Linux-32位4.Hadoop2.7.1(要求jdk版本为1.7及以上)5.spark2.2.1(要求hadoop版本为2.7)二、安装虚拟机1.安装vmware(具体细节可百度vmware安装)。
2.新建虚拟机打开解压过的centos/centos.vmx3.克隆虚拟机选中虚拟机/右键/管理/克隆4.查看虚拟机版本查看centos版本命令:rpm -q centos-release查看系统是32位还是64位:getconf LONG_BIT三、hadoop伪分布安装(选centos虚拟机安装)1.root用户名登陆,密码hadoop之后已将主机名修改为hadoop 密码hadoop IP 192.168.0.2532.设置IP、主机名、绑定主机名和关闭防火墙(1)设置静态IP桌面右上角连接右键编辑连接IPv4 method:从automatic(DCHCP)动态分配IP调整为Manual静态IP设置与主机在同一个网段可以用ipconfig和ping IP实现本机IP 192.168.0.221vmware vmnet1 192.168.0.251 vmnet8 192.168.0.252service network restart //重启网卡(2)修改主机名hostname //查看当前主机名hostname hadoop //对于当前界面修改主机名vi /etc/sysconfig/network 进入配置文件下修改主机名为hadoopreboot -h now //重启虚拟机//执行vi读写操作按a修改修改完之后Esc 输入:wq 回车保存退出3.hostname和主机绑定vi /etc/hosts //在前两行代码下添加第三行192.168.0.253 hadoop之后ping hadoop验证即可4.关闭防火墙service iptables stop //关闭防火墙service iptables status //查看防火墙状态chkconfig iptables off //关闭防火墙自动运行chkconfig --list | grep iptables //验证是否全部关闭5.配置ssh免密码登陆(centos默认安装了SSH client、SSH server)rpm -qa |grep ssh//验证是否安装SSH,若已安装,界面如下接着输入ssh localhost输入yes 会弹出以下窗体内容即每次登陆都需要密码exit //退出ssh localhostcd ~/.ssh/ //若不存在该目录,执行一次ssh localhostssh-keygen -t rsa 之后多次回车cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //加入授权chmod 600 ~/.ssh/authorized_keys //修改文件权限注:在Linux 系统中,~ 代表的是用户的主文件夹,即"/home/用户名" 这个目录,如你的用户名为hadoop,则~ 就代表"/home/hadoop/"。
centos6.5上搭建完全式hadoop2.7.2

Centos6.5系统搭建完全式hadoop2.7.2一、在4台服务器上分别安装Centos6.5系统四台服务器网络配置完成后ip分别为:10.245.55.17210.245.55.17410.245.55.17610.245.55.178二、在Centos6.5上安装hadoop2.7.21,修改主机名和/etc/hosts文件vim /etc/sysconfig/networkHOSTNAME=master重启后生效vim /etc/hosts 在行尾添加四行10.245.55.172 master10.245.55.174 slave110.245.55.176 slave210.245.55.178 slave32,配置免密码登录SSH1,生成密钥ssh-keygen -t -rsa 出提示后然后一直按回车到结束2,将id_dsa.pub(公钥)追加到授权的key中:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys3,将认证文件复制到其他节点上scp ~/.ssh/authorized_keys root@10.245.55.174:~/.ssh/scp ~/.ssh/authorized_keys root@10.245.55.176:~/.ssh/scp ~/.ssh/authorized_keys root@10.245.55.178:~/.ssh/4,测试ssh slave1 ssh slave2 ssh slave3其他节点也按照此方法进行配置,最后实现互相无密码登录ssh 3,各节点安装JDK选择的版本是jdk-7u79-linux-x64.tar.gzchmod 777 jdk-7u79-linux-x64.tar.gzmkdir /usr/javatar –zxvf jdk-7u79-linux-x64.tar.gz -C /usr/java配置环境变量:vi /etc/profile加入以下三行#JAVA_HOMEexport JAVA_HOME=/usr/java/jdk1.7.0_79export $PATH=$JAVA_HOME/bin:$PATH执行source /etc/profile使环境变量的配置生效执行java –version查看jdk版本,查看是否成功。
hadoop2.2安装
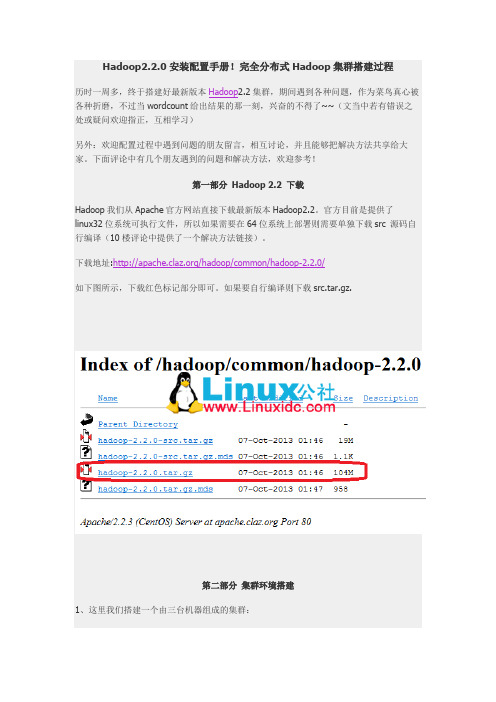
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一.在Microsoft Windows XP操作系统下,安装Ubuntu 8.04 lts server版本+ xubuntu桌面到VMware虚拟机上1.下载ubuntu server 及xubuntu1)Ubuntu 8.04 server:http://119.147.41.16/down?cid=A97349CDC5DF51672F26FCABACBF5BC5AF9AF89D&t=2&fmt=&usrinput=ubuntu 8.04&dt=1&ps=0_0&rt=0kbs&plt=02)Xubuntu: 可不下,不用桌面http://119.147.41.16/down?cid=DADD7F929F5F442A7881C2B382865468B70B8AA5&t=2&fmt=&usrinput=xubuntu&dt=1002002&ps=0_0&rt=0kbs&plt=03)VMwarehttp://119.147.41.16/down?cid=9BAA5720718DE23B4F7312C915E8028E71779B39&t=2&fmt=-1&usrinput=Vmware&dt=2056000&redirect=no2.本人硬件环境(参考)CPU: 2 core 4.12GMemory: 2G ddr3Mainboard Chip : Intel p43d3Graphic Chip : N Geoforce 9600gs03.本人软件环境(参考)OS : Microsoft windows xp sp3VM: vmware5.5.1.19175Linux: Ubuntu linux 8.04 lts server(iso) + xubuntu (ISO)4.设置虚拟环境1)安装VMware :略(出现警告仍然继续,sn: E8HFE-5MD6N-F25DC-4WRNQ, 可不汉化)2)打开VMware Workstation软件,点击“file”菜单,选择“new”-“virtual machine”命令3)弹出新建虚拟机向导,点击“下一步”按钮4)在“virtual machine configuration”中,选择第二项“custom”单选项目,点击“下一步”按钮5)在“virtual machine format”中,选择第一项“new - Workstation 5”单选项目,点击“下一步”按钮6)之后将询问虚拟机的操作系统,我们在“guest operating system”中选择“Linux”,在下面的版本中选择“Ubuntu”,点击“下一步”按钮7)这时询问虚拟机的名称和保存目录,请根据自己的需要进行设置。
在此我使用d:\\My Virtual Machines\Ubuntu,点击“下一步”按钮8)虚拟处理器数,选择“one”,点击“下一步”按钮。
(我是双核心处理器,所以有这个项目)9)这时提示分配虚拟机内存,请根据自己物理内存实际情况进行设置,建议至少分配128MB内存,如果物理内存数量允许,推荐设置256MB内存。
我的物理内存是2GB,在此我使用虚拟机推荐的内存数量384MB,点击“下一步”按钮10)网络连接类型。
如果不想让虚拟机访问,请选择“不使用网络连接”。
如果需要访问网络,请根据自己的情况设置,在此我推荐使用第二项“NAT”,这个选项让虚拟机使用宿主计算机的IP访问网络,宿主计算机将共享网络给虚拟机。
点击“下一步”按钮11)I/O适配器,选择“SCSI Logic”项目,点击“下一步”按钮12)磁盘,“Create a new virtual dis”,点击“下一步”按钮13)虚拟机磁盘类型,选择“SCSI”,点击“下一步”按钮14)磁盘容量,根据自己实际情况设置,建议至少分配4GB的磁盘容量,在此我分配12GB给虚拟机15)磁盘文件保存路径,同样根据自己情况设置,该保存路径的剩余磁盘空间必须大于您设置的虚拟机磁盘最大容量,点击“下一步”按钮。
一个虚拟机就设置完成了5.安装Utunbu 8.04 server1)切换到刚才设置好的虚拟机选项卡,点击“VM”菜单中的“setting, hardware,CD-ROM”设备,之后再右侧选择“useISO image”单选项目,在下面选择“Ubuntu8.04LTS。
.ISO”的ISO镜像。
然后点击ok按钮,关闭窗口2)点击主界面的”Power On”命令,打开虚拟机。
可能出现以下问题:点取消继续3)(这里有个可选,你可f2,f4进入设置)4)弹出安装语言选择,通过键盘上的上下左右四个按键,我们选择”English”语言,按下回车键(后面选择时区可选择Eastern)5)进入utbuntu安装界面,选择Install utunbu server . 如果需要用鼠标(在宿主机上,按ctrl+alt)6)选择english作为安装语言: Choose Language 选择english. 再选择Unitedstates7)Ubuntu 安装程序主菜单: Detect Keyboard layout? 选择"no"; Origin of thekeyboard: 选择"usa"; Keyboard layout: 选择"usa”8)配置网络: 使用默认的"ubuntu"9)磁盘分区: 可以手动分区也可以自动分区,因为我们是空的虚拟机,没有特殊要求,我们在此选择第一项“use entire disk”,自动分区。
开始自动配置分区,如提示是否确认,请选择“是”。
(可能虚拟机会死机,如果你经常切换的话)10)示输入您的用户名,您待会儿将用此用户进入系统。
请根据个人情况正确输入用户名和密码11)开始安装系统,有校对文件正确性、解包、复制文件等过程,这可能需要很长时间12)安装时卡在'Configuring apt','Scanning the mirror'的处理方法.物理上断开网络(我是选择这个,等一会就过去了).或者,启用Terminal,查看所有进程,杀死Chose-mirror进程。
ctrl+alt+F3 切到一个终端里ps -a |grep apt找到apt-get运行的进程号kill -9 那个进程号这样就跳过去了。
13)注意,安装软件时请选择上SSH14)根据提示虚拟机重起,进入utunbu server15)xubuntu 桌面(暂不安装)6.二.安装hadoop如果没有装SSH,则sudo apt-get install openssh-serverSetp 1. 设定登入免密码由于Hadoop用ssh作机器间的沟通,因此先设定登入机器免密码测试下,第一次登陆要yes下,第二次直接进入,以免日后输入密码key到手软Step2. 安装java环境由于Sun Java runtime是执行hadoop的必备工具,因此我们要安装jre或jdk。
我这里装jdk很有可能出现这个错误:Couldn't find package sun-java6-jdk解决办法:For this, you can try to execute "sudo apt-get update", it will update the dict from the sources that you have prestore their address in file /usr/etc/apt/list(i forgot the detail position).30-40分钟更新好。
安装jdk还是去get。
还要等一段很长很长很长。
的安装时间,可能把资源设置成国内镜像会快些,这个我没做。
Step3. 下载安装hadoop这里的hadoop是台湾”国网”中心TWREN的镜像//必须给它加上双引号(大小29M)Step4. 设定hadoop-env.sh进入hadoop目录,对hadoop-env.sh设定JAVA_HOME, HADOOP_HOME, HADOOP_CONF_DIR 三个环境变量export JAVA_HOME=/usr/lib/jvm/java-6-sunexport HADOOP_HOME=/opt/hadoopexport HADOOP_CONF_DIR=/opt/hadoop/confEOFStep5. 设定Hadoop-site.xml<configuration><property><name></name><value>hdfs://localhost:9000</value><description> default file system for NDFS </description></property><property><name>mapred.job.tracker</name><value>localhost:9001</value><description>The host:port that job tracker runsat.</description></property></configuration>EOFStep6. 格式化HDFS以上我们已经设定好hadoop单机测试的环境,接下来我们来启动hadoop相关服务,格式化namenode, secondarynamenode, tasktracker执行画面如下:我这边host=ubuntu/127.0.1.1Step7. 启动hadoop接着用start-all.sh来启动所有服务,包含namenode, datenode执行画面如下:我目前到这一步,一切正确进行。
因为没有装xbuntu所以没有界面,而宿主机暂还访问不到。
step8. 完成!检查运作状态。
可用宿主机访问虚拟机服务1)启动之后,可以通过网址来观看服务是否正常。
Hadoop管理界面\Hadoop TaskTracker状态\Hadoop DFS状态2)Http://localhost:50030/ - Hadoop管理界面3) 4)5)测试了下,上面的三张图就是成果了。