Hadoop的安装与配置及示例wordcount的运行
Hadoop的配置及运行WordCount

Hadoop的配置及运行WordCount目录Hadoop的配置及运行WordCount (1)一、环境: (1)二、步骤: (1)1 JDK及SSH安装配置: (1)1.1 卸载Fedora自带的OpenJDK,安装Oracle的JDK (1)1.2 配置SSH (2)2 Hadoop安装配置: (4)2.1 下载并配置Hadoop的JDK环境 (4)2.2 为系统配置Hadoop环境变量 (5)2.3 修改Hadoop的配置文件 (6)2.4 初始化HDFS文件系统,和启动Hadoop (8)2.5 关闭HDFS (11)3 运行WordCount: (11)3.1 下载和编译WordCount示例 (11)3.2 建立文本文件并上传至DFS (13)3.3 MapReduce执行过程显示信息 (14)结尾: (15)一、环境:计算机Fedora 20、jdk1.7.0_60、Hadoop-2.2.0二、步骤:1 JDK及SSH安装配置:1.1 卸载Fedora自带的OpenJDK,安装Oracle的JDK*由于Hadoop,无法使用OpenJDK,所以的下载安装Oracle的JDK。
1.1.1、以下为卸载再带的OpenJDK:然后到/technetwork/java/javase/downloads/index.html下载jdk,可以下载rpm格式的安装包或解压版的。
rpm版本的下载完毕后可以运行安装,一般会自动安装在/usr/java/的路径下面。
接下来就配置jdk的环境变量了。
1.1.2、进入到系统的环境变量配置文件,加入以下内容:(按i进行编辑,编辑完毕按ESC,输入:wq,回车即保存退出)截图如下:Java环境变量配置输入这个回车即可保存退出java –version,检测配置是否成功。
如下结果则Java 配置安装成功。
1.2 配置SSH搭建hadoop分布式集群平台,为了实现通讯之间的可靠,防止远程管理过程中的信息泄露问题。
Hadoop环境搭建及wordcount实例运行
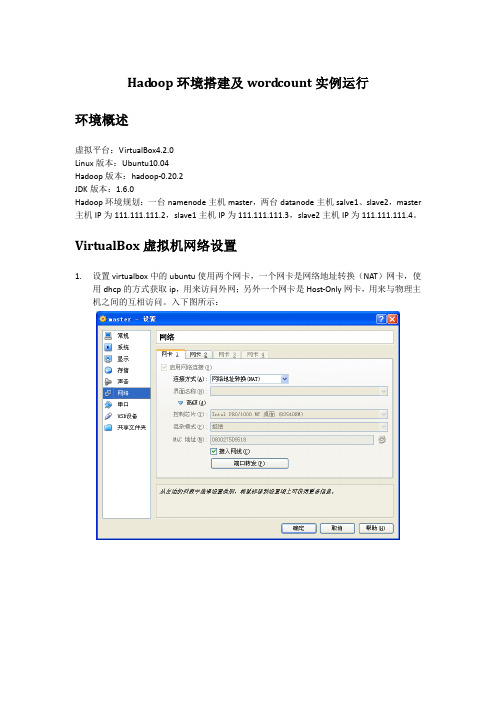
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
Hadoop安装部署手册

1.1软件环境1)CentOS6.5x642)Jdk1.7x643)Hadoop2.6.2x644)Hbase-0.98.95)Zookeeper-3.4.61.2集群环境集群中包括 3个节点:1个Master, 2个Slave2安装前的准备2.1下载JDK2.2下载Hadoop2.3下载Zookeeper2.4下载Hbase3开始安装3.1 CentOS安装配置1)安装3台CentOS6.5x64 (使用BasicServer模式,其他使用默认配置,安装过程略)2)Master.Hadoop 配置a)配置网络修改为:保存,退出(esc+:wq+enter ),使配置生效b) 配置主机名修改为:c)配置 hosts修改为:修改为:在最后增加如下内容以上调整,需要重启系统才能生效g) 配置用户新建hadoop用户和组,设置 hadoop用户密码id_rsa.pub ,默认存储在"/home/hadoop/.ssh" 目录下。
a) 把id_rsa.pub 追加到授权的 key 里面去b) 修改.ssh 目录的权限以及 authorized_keys 的权限c) 用root 用户登录服务器修改SSH 配置文件"/etc/ssh/sshd_config"的下列内容3) Slavel.Hadoop 、Slavel.Hadoop 配置及用户密码等等操作3.2无密码登陆配置1)配置Master 无密码登录所有 Slave a)使用 hadoop 用户登陆 Master.Hadoopb)把公钥复制所有的 Slave 机器上。
使用下面的命令格式进行复制公钥2) 配置Slave 无密码登录Mastera) 使用hadoop 用户登陆Slaveb)把公钥复制Master 机器上。
使用下面的命令格式进行复制公钥id_rsa 和相同的方式配置 Slavel 和Slave2的IP 地址,主机名和 hosts 文件,新建hadoop 用户和组c) 在Master机器上将公钥追加到authorized_keys 中3.3安装JDK所有的机器上都要安装 JDK ,先在Master服务器安装,然后其他服务器按照步骤重复进行即可。
Hadoop的安装与配置

Hadoop的安装与配置建立一个三台电脑的群组,操作系统均为Ubuntu,三个主机名分别为wjs1、wjs2、wjs3。
1、环境准备:所需要的软件及我使用的版本分别为:Hadoop版本为0.19.2,JDK版本为jdk-6u13-linux-i586.bin。
由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
所以在三台主机上都设置一个用户名为“wjs”的账户,主目录为/home/wjs。
a、配置三台机器的网络文件分别在三台机器上执行:sudo gedit /etc/network/interfaceswjs1机器上执行:在文件尾添加:auto eth0iface eth0 inet staticaddress 192.168.137.2gateway 192.168.137.1netmask 255.255.255.0wjs2和wjs3机器上分别执行:在文件尾添加:auto eth1iface eth1 inet staticaddress 192.168.137.3(wjs3上是address 192.168.137.4)gateway 192.168.137.1netmask 255.255.255.0b、重启网络:sudo /etc/init.d/networking restart查看ip是否配置成功:ifconfig{注:为了便于“wjs”用户能够修改系统设置访问系统文件,最好把“wjs”用户设为sudoers(有root权限的用户),具体做法:用已有的sudoer登录系统,执行sudo visudo -f /etc/sudoers,并在此文件中添加以下一行:wjsALL=(ALL)ALL,保存并退出。
}c、修改三台机器的/etc/hosts,让彼此的主机名称和ip都能顺利解析,在/etc/hosts中添加:192.168.137.2 wjs1192.168.137.3 wjs2192.168.137.4 wjs3d、由于Hadoop需要通过ssh服务在各个节点之间登陆并运行服务,因此必须确保安装Hadoop的各个节点之间网络的畅通,网络畅通的标准是每台机器的主机名和IP地址能够被所有机器正确解析(包括它自己)。
hadoop环境搭建
hadoop环境搭建⼀、安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost⼆、卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看三、安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib export PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version四、安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
hadoop安装以及配置启动命令

hadoop安装以及配置启动命令本次安装使⽤的Hadoop⽂件是badou学院的Hadoop1.2.1.tar.gz,以下步骤都是在此版本上进⾏。
1、安装,通过下载tar.gz⽂件安装到指定⽬录2、安装好后需要配置Hadoop集群配置信息: 在hadoop的conf路径中的masters中添加master(集群机器主的hostname)在slaves中添加集群的slave的hostname名称名称对应的是各⾃机器的hostname这样通过hosts⽂件中配置的域名地址映射可以直接找到对应的机器 a、core-site.xml 在xml⽂件中添加<property><name>hadoop.tmp.dir</name><value>/usr/local/src/hadoop.1.2.1/tmp</value></property> <property><name></name><value>hdfs://192.168.79.10:9000</value></property> c、hdfs-site.xml 在⽂件中添加<property><name>dfs.replication</name><value>3</value></property><!-- 复制节点数 --> d、hadoop-env.xml 在⽂件中添加export JAVA_HOME=/usr/local/src/jdk1.6.0_45 步骤2配置好后将当前hadoop⽂件夹复制到集群中其他机器上,只需要在对应机器上修改其对应的ip、port、jdk路径等信息即可搭建集群3、配置好Hadoop环境后需要测试环境是否可⽤: a、⾸先进⼊Hadoop的安装⽬录,进⼊bin⽬录下,先将Hadoop环境初始化,命令:./hadoop namenode -format b、初始化之后启动Hadoop,命令:./start_all.sh c、查看Hadoop根⽬录下的⽂件,命令:./hadoop fs -ls/ d、上传⽂件,命令:./hadoop fs -put ⽂件路径 e、查看⽂件内容,命令:./hadoopo fs -cat hadoop⽂件地址注意:在安装Hadoop环境时先安装好机器集群,使得⾄少3台以上(含3台)机器之间可以免密互相登录(可以查看上⼀篇的linux的ssh免密登录)执⾏Python⽂件时的部分配置/usr/local/src/hadoop-1.2.1/bin/hadoop/usr/local/src/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop的安装与配置及示例程序wordcount的运行目录前言 (1)1 机器配置说明 (2)2 查看机器间是否能相互通信(使用ping命令) (2)3 ssh设置及关闭防火墙 (2)1)fedora装好后默认启动sshd服务,如果不确定的话可以查一下[garon@hzau01 ~]$ service sshd status (3)2)关闭防火墙(NameNode和DataNode都必须关闭) (3)4 安装jdk1.6(集群中机子都一样) (3)5 安装hadoop(集群中机子都一样) (4)6 配置hadoop (4)1)配置JA V A环境 (4)2)配置conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml文件 (5)3)将NameNode上完整的hadoop拷贝到DataNode上,可先将其进行压缩后直接scp 过去或是用盘拷贝过去 (7)4)配置NameNode上的conf/masters和conf/slaves (7)7 运行hadoop (7)1)格式化文件系统 (7)2)启动hadoop (7)3)用jps命令查看进程,NameNode上的结果如下: (8)4)查看集群状态 (8)8 运行Wordcount.java程序 (8)1)先在本地磁盘上建立两个文件f1和f2 (8)2)在hdfs上建立一个input目录 (9)3)将f1和f2拷贝到hdfs的input目录下 (9)4)查看hdfs上有没有f1,f2 (9)5)执行wordcount(确保hdfs上没有output目录) (9)6)运行完成,查看结果 (9)前言最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。
具体安装及配置过程如下:1 机器配置说明总共有3台机器:hzau01、hzau02、hzau03IP地址分别为:192.168.0.4、192.168.0.17、192.168.0.6操作系统为:Linux2.6.33.3-85.fc13.i686.PAEjdk版本为:jdk1.6.0_23hadoop版本为:hadoop-0.21.0hzau01作为NameNode、JobTracker,其他两台台作为DataNode、TaskTracker2 查看机器间是否能相互通信(使用ping 命令)用root登录,在NameNode上修改/etc/hosts文件,加入三台机器的IP地址和机器名,如下:192.168.0.4 hzau01192.168.0.17 hzau02192.168.0.6 hzau03设置好后验证下各机器间是否ping通,用机器名或是IP地址都可以,例如ping hzau02或ping 192.168.0.17Hadoop要求所有机器上hadoop的部署目录结构要相同并且有一个相同的用户名的帐户,我的默认路径为/home/garon3 ssh设置及关闭防火墙1)fedora装好后默认启动sshd服务,如果不确定的话可以查一下[garon@hzau01 ~]$ service sshd status如没有启动的话,先启动[root@hzau01 ~]# service sshd start建立ssh无密码登录,在NameNode上[garon@hzau01 ~]ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa(''为两个单引号)会在~/.ssh/生成两个文件:id_dsa和id_dsa.pub,这两是成对出现的,把id_dsa.pub文件追加到DataNode上的authorized_keys[garon@hzau01 ~]$ scp ~/.ssh/id_dsa.pub hzau02:/home/garon/.ssh (注意其中目标机器后面的:与要传到的文件路径之间没有空格,即sc706:与/home/hadoop/之间没有空格)scp ~/.ssh/id_dsa.pub hzau03:/home/garon/.ssh登录到DataNode上,[garon@hzau02 ~]$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys ,其余一台一样,注意:追加完后必须修改NameNode和DataNode上的.ssh和authorized_keys 的权限,chmod命令,参数600,完成后测试下,例如ssh hzau02时不需要密码就可以登录,就可以知道ssh设置成功。
2)关闭防火墙(NameNode和DataNode都必须关闭)[root@hzau01 ~]# service iptables stop注意:每次重新开机启动hadoop前都必须关闭4 安装jdk1.6(集群中机子都一样)下载jdk-6u23-ea-bin-b03-linux-i586-18_oct_2010.bin,之后直接安装,我的安装路径为:/usr/java/jdk1.6.0_23,安装后添加如下语句到/etc/profile中:export JA VA_HOME="/usr/java/jdk1.6.0_23"export JRE_HOME=/usr/java/jdk1.6.0_23/jreexport CLASSPATH=.:$JA V A_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PA TH=$JA V A_HOME/bin:$JRE_HOME/bin:$PATH5 安装hadoop(集群中机子都一样) 在官网//hadoop/core/下载hadoop-0.21.0.tar.gz [garon@hzau01 ~]$ tar xzvf hadoop-0.21.0.tar.gz将hadoop的安装路径添加到/etc/profile中:export HADOOP_HOME=/home/garon/hadoop-0.21.0export PA TH=$HADOOP_HOME/bin:$PATH为了让/etc/profile生效,source一下[garon@hzau01 ~]$ source /etc/profile 6 配置hadoop其配置文件在/conf目录下1)配置JAVA环境[garon@hzau01 ~]$$ vi ~/hadoop/hadoop-0.21.0/conf/hadoop-env.shexport JA VA_HOME=/usr/java/jdk1.6.0_232)配置conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml文件[garon@hzau01 hadoop-0.21.0]$ vi conf/core-site.xml<configuration><property><name>hadoop.tmp.dir</name><value>/home/garon/hadoopgaron</value></property><property><name></name><value>hdfs://hzau01/</value></property></configuration>[garon@hzau01 hadoop-0.21.0]$ vi conf/mapred-site.xml<configuration><property><name>mapred.jobtracker.address</name><value>hzau01:9001</value></property></configuration>[garon@hzau01 hadoop-0.21.0]$ vi conf/hdfs-site.xml<configuration><property><name>.dir</name><value>/home/garon/hadoopname</value> </property><property><name>dfs.data.dir</name><value>/home/garon/hadoopdata</value> </property><property><name>dfs.replication</name><value>1</value></property></configuration>3)将NameNode上完整的hadoop拷贝到DataNode上,可先将其进行压缩后直接scp过去或是用盘拷贝过去4)配置NameNode上的conf/masters和conf/slaves masters:192.168.0.4slaves:192.168.0.17192.168.0.67 运行hadoop1)格式化文件系统[garon@hzau01 bin]$ hdfs namenode -format注意:格式化时要防止NameNode的namespace ID与DataNode的namespace ID的不一致,因为每格式化一次会产生Name、Data、tmp等临时文件记录信息,多次格式化会产生很多,会导致ID的不同,造成hadoop不能运行2)启动hadoop[garon@hzau01 bin]$ start-dfs.sh[garon@hzau01 bin]$ start-mapred.sh3)用jps命令查看进程,NameNode上的结果如下:5334 JobTracker5215 SecondaryNameNode5449 Jps5001 NameNode4)查看集群状态[garon@hzau01 bin]$ hdfs dfsadmin -report确保运行的DataNode个数是正确的,我的是2个,这样可以查看哪个DataNode没有运行8 运行Wordcount.java程序1)先在本地磁盘上建立两个文件f1和f2[garon@hzau01 bin]$ echo ”Hello world Bye world" > ~/input/f1[garon@hzau01 bin]$ echo ”hello hadoop bye hadoop” > ~/input/f22)在hdfs上建立一个input目录[garon@hzau01 bin]$ hadoop fs -mkdir /tmp/input3)将f1和f2拷贝到hdfs的input目录下[garon@hzau01 bin]$ hadoop fs -put /home/garon/input /tmp4)查看hdfs上有没有f1,f2[garon@hzau01 bin]$ hadoop fs -ls /tmp/input5)执行wordcount(确保hdfs上没有output目录)[garon@hzau01 bin]$ hadoop jar ../hadoop-mapred-examples-0.21.0.jar wordcount /tmp/input /output6)运行完成,查看结果[garon@hzau01 bin]$ hadoop fs -cat /output/part-r-00000Bye 1Hello 1bye 1 hadoop 2 hello 1 world 2。