任务1 区分数据的类型
第22届全国青少年信息学奥林匹克联赛NOIP2016提高组试题day1
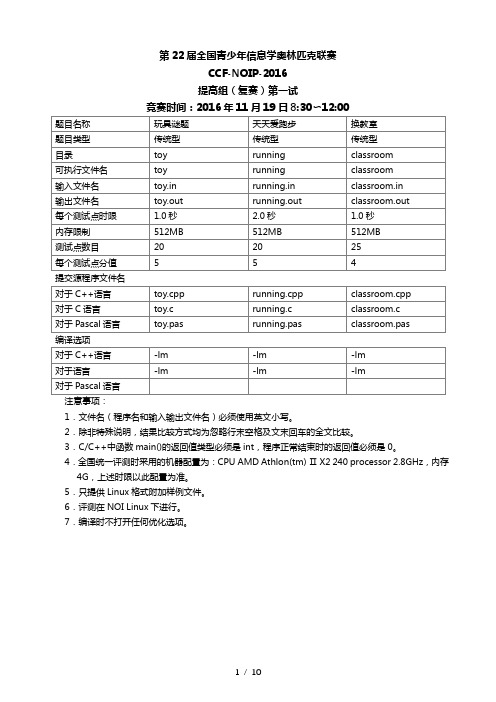
第22届全国青少年信息学奥林匹克联赛CCF-NOIP-2016提高组(复赛)第一试竞赛时间:2016年11月19日8:30〜12:001.文件名(程序名和输入输出文件名)必须使用英文小写。
2.除非特殊说明,结果比较方式均为忽略行末空格及文末回车的全文比较。
3.C/C++中函数main()的返回值类型必须是int,程序正常结束时的返回值必须是0。
4.全国统一评测时采用的机器配置为:CPU AMD Athlon(tm) Ⅱ X2 240 processor 2.8GHz,内存4G,上述时限以此配置为准。
5.只提供Linux格式附加样例文件。
6.评测在NOI Linux下进行。
7.编译时不打开任何优化选项。
玩具谜题(toy)【问题描述】小南有一套可爱的玩具小人,它们各有不同的职业。
有一天,这些玩具小人把小南的眼镜藏了起来。
小南发现玩具小人们围成了一个圈,它们有的面朝圈内,有的面朝圈外。
如下图:这时singer告诉小南一个谜题:“眼镜藏在我左数第3个玩具小人的右数第1个玩具小人的左数第2个玩具小人那里。
”小南发现,这个谜题中玩具小人的朝向非常关键,因为朝内和朝外的玩具小人的左右方向是相反的:面朝圈内的玩具小人,它的左边是顺时针方向,右边是逆时针方向;而面向圈外的玩具小人,它的左边是逆时针方向,右边是顺时针方向。
小南一边艰难地辨认着玩具小人,一边数着:“singer”朝内,左数第3个是archer。
“archer”朝外,右数第1个是thinker。
“thinker”朝外,左数第2个是writer。
“所以眼镜藏在writer这里!”虽然成功找回了眼镜,但小南并没有放心。
如果下次有更多的玩具小人藏他的眼镜,或是谜题的长度更长,他可能就无法找到眼镜了。
所以小南希望你写程序帮他解决类似的谜题。
这样的谜题具体可以描述为:有n个玩具小人围成一圈,已知它们的职业和朝向。
现在第1个玩具小人告诉小南一个包含m条指令的谜题,其中第i条指令形如“左数/右数第s i个玩具小人”。
参考答案of数据挖掘

笫一章卜列JS于数据挖掘任务的是<)根据性别划分公司的顾客计斃公司的总销傅额预測一对股子的结果利用历史记录预测公司的未來股价吋以在不同维度合并数据.从而形成数据立方体的足()数据库数据祿数据仓库数据库系统目的足缩小数据的取值范用•使其更适合于数据挖掘以浓的需要.井且能够得到和原始数据相同的分析结果的足()数据清洗数据集成数据变换数据归約卜谜四种方法嘛一种不足雷见的分类方法(〉决第树支持向fitK-Xeans (聚类)朴素贝叶斯分类卜列任务中.朋于数据挖掘技术在商务智能方面应用的足()欺诈检测垃圾邮件识别根据因特网的捜索引擎伍找特定的Web页面定向营销舁常检测的应用包括()网络攻击预测某股票的未来价格计算公司的总带會额根据性别划分公司顾客将原始数据进行集成.变换.维度规约、数值规约足哪个步驟的任务(〉猿繁模式挖掘分类和预测数据预处理数据流挖掘KDD是(数据挖掘9知识发现)卜列有关离群点的分析错谦的足(〉-纓宿况卜离群点会被肖作唤声而去弃离群点即足噪声数据在荣些待殊应用中离群点有特殊的总义信用卡在不常消费地区突然消费人壇金额的现盘属于离群点分析范畸卜列关于模式识别的相关说法中错谓的足(〉模式识别的本质足抽象出不同爭物中的模式并由此对爭物进行分类医疗诊断属干模式讲别的研宛内容之一F机的描纹解镇技术不属r模式识别的应用门然语育理解也包含模式识别何题()不属干数据挖抿的应用领域。
商务智能信息识别I搜童引鼻医疗诊斷目前数据分析和数据挖掘而临的挑战性何题不包括(〉数据类型的多样化高维度数据离群点数据分析与挖掘结果对视化常见的机器学习方法有监悴学习.无监怦学r监悴学习数据挖掘足从人规模的数据中抽1R或挖掘出感兴趣的知识或模式的过程或方法&施紫模式足描数据集中频緊出现的蟆式X肉群点足描全局或者局部范用内偏离一履水平的观测对盘联机分析处理足数据仓库的主要应用分类是措通过建立模型预测离散标签.I叩丿I足通过建立连续值模型推断新的数据的某个数值型属性。
国开电大《财务大数据分析与决策》形考任务一客观题答案

题目1.下列哪个选项不属于大数据的特点?()A. 海量化的数据B. 大数据都是有价值的数据C. 数据类型的多样化D. 大数据的价值密度相对较低答案:大数据都是有价值的数据题目2.下列哪个选项不属于大数据处理的环节?()A. 数据模型B. 数据预处理C. 数据分析D. 数据可视化答案:数据模型题目3.下列不属于大数据思维的是()。
A. 全样思维B. 容错思维C. 抽样思维D. 相关思维答案:抽样思维题目4.下列关于Jupyter Notebook,说法不正确的是()A. Jupyter Notebook是Anaconda集成环境中自带的代码编辑器B. Jupyter Notebook是一个网页程序C. Jupyter Notebook页面单元格中不仅可以输入代码还可以输入文字D. Jupyter Notebook的Markdown单元中只能输入文字答案:Jupyter Notebook的Markdown单元中只能输入文字题目5.下列print语句使用正确的是()。
A. print(“你好,大数据”)B. print(你好,大数据)C. print([你好,大数据])D. print'你好,大数据'答案:print(“你好,大数据”)题目6.Jupyter Notebook中每个代码单元可书写()行代码。
A. 一至多B. 一C. 十D. 至多一答案:一至多题目7.大数据产生的原因包括()。
A. 全球所有人都是信息的接收者和产生者B. 各类传感器24小时不停地产生数据C. 人类活动的进一步扩展使数据规模急剧膨胀D. 大数据以每年50%的速度增长答案:全球所有人都是信息的接收者和产生者;各类传感器24小时不停地产生数据;人类活动的进一步扩展使数据规模急剧膨胀题目8.大数据的“4V”特点具体指()。
A. VolumeB. VarietyC. VelocityD. Value答案:Volume;Variety;Velocity;Value题目9.Value是指大数据的价值密度。
样本量估算的统计学方法

3、估计样本含量的目的
在保证某个临床试验/临床研究的结论具 有一定科学性、真实性和可靠性前提 下,确定某研究所需的最小观察例数。
Ø
二、估计样本含量 的方法
两大类方法
Ø
1、公式法,可满足多种设计的要求,目 前应用广泛。
Ø
2、查表法,简单、方便,但受条件限 制,有时不一定完全适应。
三、估计样本含 量的步骤
任务1—描述样本数据特性
例:某样本个体分布的集中趋势与离散趋势怎样 ? (1v点,2v线,3v影子_线)
Ø Ø
数据:计数(%),定量(Average),等级(M, Ridit) 分布:正态 (Mean±SD,95%CR),对数正态(G),偏 态 (M, Q/R,P ~ P ) ,相关回归 (r, b) 2.5 97.5 对比:两组对比 (各组Mean±SD ),配对比较 (差值 的Mean±SD)
(4)确定总体标准差σ总体率π
Ø
若研究的终点指标为数值变量时,总体标准 差σ为估计样本含量所必须的条件。 若研究的终点指标为分类变量时,有时,总 体率π为估计样本含量条件。
Ø
Ø
若总体标准差σ和总体率π,常常通过文献检 索、预试验或对研究作出合理的假设来获得。
5、计算样本含量
Ø
用按设计方案、资料类型及可能涉及的 统计分析方法来选择样本含量的计算方 法(查书),也可以利用统计软件帮助 完成样本含量的计算。
六、分类变量的样本 含量估计简介
两个率比较的估算
实例分析(例数相等)
Ø
用旧的治疗方案治疗慢性肾炎的控制率为 30%,现用新的治疗方案治疗慢性肾炎,其控 制率应大于50%才有临床意义,若取两组例数 相等,且α=0.05、 β=0.10(power=0.9),问 每组需多少例数?
数据挖掘导论第一二章_924

2.3.4特征创建
常常可以由原来的属性创建新的属性集,更有效地捕获数据集中的重要信息。三种创建新属性的相关方法:特征提取、映射数据到新的空间和特征构造。
特征提取(feature extraction):由原始数据数据创建新的特征集称作特征提取。最常用的特征提取技术都是高度针对具体领域的。因此,一旦数据挖掘用于一个相对较新的领域,一个关键任务就是开发新的特征和特征提取方法。
首先定义测量误差和数据收集错误,然后进一步考虑涉及测量误差的各种问题:噪声、伪像、偏倚、精度和准确度。最后讨论可能同时涉及测量和数据收集的数据质量问题:离群点、遗漏和不一致值、重复数据。
测量误差(measurement error)指测量过程中导致的问题。
数据收集错误(data collection error)指诸如遗漏数据对象或属性值,或不当的包含了其他数据对象等错误。
过滤方法(filter approach):使用某种独立于数据挖掘任务的方法,在数据挖掘算法运行前进行特征选择。
包装方法(wrapper approach):这些方法将目标数据挖掘算法作为黑盒,使用类似于前面介绍的理想算法,但通常不枚举所有可能的子集来找出最佳属性子集。
过滤方法和包装方法唯一的不同是它们使用了不同的特征子集评估方法。对于包装方法,子集评估使用目标数据挖掘算法;对于过滤方法,子集评估技术不同于目标数据挖掘算法。搜索策略可以不同,但是计算花费应当较低,并且应当找到最优或近似最优的特征子集。通常不可能同时满足这两个要求,因此需要这种权衡。搜索的一个不可缺少的组成部分是评估步骤,根据已经考虑的子集评价当前的特征子集。这需要一种评估度量,针对诸如分类或聚类等数据挖掘任务,确定属性特征子集的质量。对于过滤方法,这种度量试图预测实际的数据挖掘算法在给定的属性集上执行的效果如何;对于包装方法,评估包括实际运行目标数据挖掘应用,子集评估函数就是通常用于度量数据挖掘结果的判断标准。
【炼数成金RapidMiner一】数据挖掘概念与技术原书第三版(第一章)1.9节的习题解

【炼数成⾦RapidMiner⼀】数据挖掘概念与技术原书第三版(第⼀章)1.9节的习题解1.数据挖掘是指从⼤量的数据中提取有⽤的知识信息的⼀种模式。
(1)因为现在的⽣活⼯作中随时随刻都在产⽣⼤量的数据和都需要将这些数据转变为有⽤的信息和知识,是因为需求的不断增加才会突显出数据挖掘技术的重要性,所以数据挖掘应该是信息技术发展带来的结果。
(2)数据挖掘应该是这些技术融合⽽不是简单的变⾰。
(3)数据库技术带动了数据收集技术的发展和数据库建⽴的机制,有了有效的数据管理,包括数据存储、检索、查询和事务处理机制。
⼤量的数据库系统提供的查询和事务处理,⾃然地产⽣了对数据分析和理解的必要性,是数据挖掘产⽣的驱动⼒量。
(4)数据清理、数据集成、数据选择、数据变换、数据挖掘、模式评估、知识表达2.数据库与数据仓库的相同与不同点不同: (1)数据库是⾯向事务的设计,数据仓库是⾯向主题设计的。
(2)数据库⼀般存储在线交易数据,数据仓库存储的⼀般是历史数据。
数据库设计是尽量避免冗余,⼀般采⽤符合范式的规则来设计,数据仓库在设计是有意引⼊冗余,采⽤反范式的⽅式来设计。
(3)数据库是为捕获数据⽽设计,数据仓库是为分析数据⽽设计,它的两个基本的元素是维表和事实表。
维是看问题的⾓度,⽐如时间,部门,维表放的就是这些东西的定义,事实表⾥放着要查询的数据,同时有维的ID。
相同:数据仓库和数据库都是数据或信息的存储系统,都存储了⼤量的持久性数据。
3.数据特征化:⽬标类数据的⼀般特性或特征的汇总。
数据区分:将⽬标类数据对象的⼀般特性与⼀个或者多个⽐类对象的⼀般特性进⾏⽐较。
例⼦:通过⼀个⽤户的每个季度的消费⾦额给出⽤户的⼀个消费指数。
关联和相关性分析:如果两个或者多个事物之间存在⼀定的关系,那么其中⼀个事物就可以通过另⼀个事物预测,⽬的是为了挖掘数据之间的相关性。
例⼦:挖掘消费⽹站中不同年龄⽤户对不同商品的需求。
分类:利⽤分类技术可以从数据集中提取描述数据类的⼀个函数或模型(也常称为分类器),并把数据集中的每个对象归结到某个已知的对象类中。
数据挖掘原理与实践 蒋盛益 答案
数据挖掘原理与实践蒋盛益答案习题参考答案第 1 章绪论1.1 数据挖掘处理的对象有哪些?请从实际生活中举出至少三种。
答:数据挖掘处理的对象是某一专业领域中积累的数据,对象既可以来自社会科学,又可以来自自然科学产生的数据,还可以是卫星观测得到的数据。
数据形式和结构也各不相同, 可以是传统的关系数据库,可以是面向对象的高级数据库系统,也可以是面向特殊应用的数据库,如空间数据库、时序数据库、文本数据库和多媒体数据库等,还可以是 Web 数据信息。
实际生活的例子:①电信行业中利用数据挖掘技术进行客户行为分析,包含客户通话记录、通话时间、所开通的服务等,据此进行客户群体划分以及客户流失性分析。
②天文领域中利用决策树等数据挖掘方法对上百万天体数据进行分类与分析,帮助天文学家发现其他未知星体。
③制造业中应用数据挖掘技术进行零部件故障诊断、资源优化、生产过程分析等。
④市场业中应用数据挖掘技术进行市场定位、消费者分析、辅助制定市场营销策略等。
1.2 给出一个例子,说明数据挖掘对商务的成功是至关重要的。
该商务需要什么样的数据挖掘功能?它们能够由数据查询处理或简单的统计分析来实现吗?答:例如,数据挖掘在电子商务中的客户关系管理起到了非常重要的作用。
随着各个电子商务网站的建立,企业纷纷地从“产品导向”转向“客户导向”,如何在保持现有的客户同时吸引更多的客户、如何在客户群中发现潜在价值,一直都是电子商务企业重要任务。
但是,传统的数据分析处理,如数据查询处理或简单的统计分析,只能在数据库中进行一些简单的数据查询和更新以及一些简单的数据计算操作,却无法从现有的大量数据中挖掘潜在的价值。
而数据挖掘技术却能使用如聚类、关联分析、决策树和神经网络等多种方法,对数据库中庞大的数据进行挖掘分析,然后可以进行客户细分而提供个性化服务、可以利用挖掘到的历史流失客户的特征来防止客户流失、可以进行产品捆绑推荐等,从而使电子商务更好地进行客户关系管理,提高客户的忠诚度和满意度。
国家开放大学《社会统计学》网上作业1-5参考答案202011
《社会统计学》形考任务形考任务1(占比20%)表1是某大学二年级135个同学的《社会统计学》课程的期末考试成绩,请将数据输入SPSS软件,并(1)对考试成绩进行排序和分组(40分),(2)制作频数分布表(30分)并绘制频数分析统计图(30分)。
请注意分组时按照下列标准:请注意分组时按照下列标准:表1某专业二年级同学社会统计学期末考试成绩(百分制)22 49 49 86 76 88 103 90 130 5423 80 50 84 77 82 104 82 131 6524 70 51 81 78 83 105 72 132 7425 59 52 90 79 92 106 86 133 7026 80 53 34 80 86 107 80 134 7227 52 54 84 81 86 108 82 135 73 解:形考任务2(占比20%)表1为某大学对100个学生进行了一周的上网时间调查,请用SPSS软件。
(1)计算学生上网时间的中心趋势测量各指标(20分)和离散趋势测量各指标(30分)。
(2)计算学生上网时间的标准分(Z值)及其均值和标准差。
(20分)(3)假设学生上网时间服从正态分布,请计算一周上网时间超过20小时的学生所占比例。
(30分)表1某专业一年级同学一周上网时间(小时)15 15 35 17 55 9 75 17 95 1516 8 36 14 56 10 76 19 96 1017 8 37 8 57 12 77 9 97 2018 15 38 12 58 24 78 21 98 819 20 39 15 59 26 79 17 99 1420 22 40 13 60 20 80 16 100 18解:形考任务3(占比20%)学习完7-12章后,你可以完成本次形考任务了,本次任务的题型包含:单项选择题(5道),名词解释(5道),简答题(2道),计算题(2道),本次任务按照百分制计,占形成性考核总成绩的20%。
国家开放大学MySQL数据库应用形考任务1
实验训练1实验训练1 在MySQL中创建数据库和表请到电脑端查看实验目的熟悉MySQL环境的使用,掌握在MySQL中创建数据库和表的方法,理解MySQL支持的数据类型、数据完整性在MySQL下的表现形式,练习MySQL数据库服务器的使用,练习CREATE TABLE,SHOW TABLES,DESCRIBE TABLE,ALTER TABLE,DROP TABLE语句的操作方法。
实验内容:【实验1-1】MySQL的安装与配置。
参见4.1节内容,完成MySQL数据库的安装与配置。
【实验1-2】创建“汽车用品网上商城系统”数据库。
用CREATE DATABASE语句创建Shopping数据库,或者通过MySQL Workbench图形化工具创建Shopping数据库。
【实验1-3】在Shopping数据库下,参见3.5节,创建表3-4~表3-11的八个表。
可以使用CREATE TABLE语句,也可以用MySQL Workbench创建表。
【实验1-4】使用SHOW、DESCRIBE语句查看表。
【实验1-5】使用ALTER TABLE、RENAME TABLE语句管理表。
【实验1-6】使用DROP TABLE语句删除表,也可以使用MySQL Workbench删除表。
(注意:删除前最好对已经创建的表进行复制。
)【实验1-7】连接、断开MySQL服务器,启动、停止MySQL服务器。
【实验1-8】使用SHOW DATABASE、USE DATABASE、DROP DATABASE 语句管理“网上商城系统”Shopping数据库。
实验要求:1.配合第1章第3章的理论讲解,理解数据库系统。
2.掌握MySQL工具的使用,通过MySQL Workbench图形化工具完成。
3.每执行一种创建、删除或修改语句后,均要求通过MySQL Workbench查看执行结果。
4.将操作过程以屏幕抓图的方式复制,形成实验文档。
5.55555。
国开MySQL大数据库应用形考任务1-4
实验训练1 在MySQL中创建数据库和表请到电脑端查看实验目的熟悉MySQL环境的使用,掌握在MySQL中创建数据库和表的方法,理解MySQL支持的数据类型、数据完整性在MySQL下的表现形式,练习MySQL数据库服务器的使用,练习CREATE TABLE,SHOW TABLES,DESCRIBE TABLE,ALTER TABLE,DROP TABLE语句的操作方法。
实验容:【实验1-1】MySQL的安装与配置。
参见4.1节容,完成MySQL数据库的安装与配置。
【实验1-2】创建“汽车用品网上商城系统”数据库。
用CREATE DATABASE语句创建Shopping数据库,或者通过MySQL Workbench图形化工具创建Shopping数据库。
【实验1-3】在Shopping数据库下,参见3.5节,创建表3-4~表3-11的八个表。
可以使用CREATE TABLE语句,也可以用MySQL Workbench创建表。
【实验1-4】使用SHOW、DESCRIBE语句查看表。
【实验1-5】使用ALTER TABLE、RENAME TABLE语句管理表。
【实验1-6】使用DROP TABLE语句删除表,也可以使用MySQL Workbench删除表。
(注意:删除前最好对已经创建的表进行复制。
)【实验1-7】连接、断开MySQL服务器,启动、停止MySQL服务器。
【实验1-8】使用SHOW DATABASE、USE DATABASE、DROP DATABASE语句管理“网上商城系统”Shopping数据库。
实验要求:1.配合第1章第3章的理论讲解,理解数据库系统。
2.掌握MySQL工具的使用,通过MySQL Workbench图形化工具完成。
3.每执行一种创建、删除或修改语句后,均要求通过MySQL Workbench查看执行结果。
4.将操作过程以屏幕抓图的方式复制,形成实验文档。
实验训练2:数据查询操作请到电脑端查看实验目的:基于实验1创建的汽车用品网上商城数据库Shopping,理解MySQL运算符、函数、谓词,练习Select语句的操作方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
任务1 区分数据的类型
【设计步骤】 【程序测试】 1. 基本数据类型
嵩县中等专业学校计算机教研组
Visual Basic 6.0 程序设计
2
任务1 区分数据的类型
2. 常量 (1)一般常量 字符串常量 数值常量 布尔型常量 日期型常量 (2)符号常量 Vsiual Basic 6.0定义了许多符号常量如vbRed(红色)、 vbBlue(蓝色)、vbGreen(绿色)等,在程序设计中可以 直接使用。 用户定义的符号常量可以用Const语句来声明,语法格式如 下。 Const 常量名 [As 类型] = 常量表达式
嵩县中等专业学校计算机教研组 NhomakorabeaVisual Basic 6.0 程序设计
3
任务1 区分数据的类型
3. Print语句 [对象名称.]Print [表达式] [,|;] [表达式] [,|;] … 4. 标识符命名规则 标识符必须以字母开头。最大长度为255。 标识符不能使用Vsiual Basic的保留字(关键字)。不能包含 在Vsiual Basic中有特殊含义的字符如:句号、空格、类型说 明符、运算符等。 Vsiual Basic的标识符不区分大小写。 标识符在标识符的同一范围内必须是唯一的。 在Vsiual Basic中,符号常量名、变量名、过程名、记录类型 名、元素名等名称都必须遵循上述命名规则。
嵩县中等专业学校计算机教研组
Visual Basic 6.0 程序设计
4
任务1 区分数据的类型
任务1 区分数据的类型 【知识点】 基本数据类型 常量 Print语句 标识符命名规则 【任务描述】 在本任务中分别为每种数据类型提供一些常量,并使用Print语 句将常量的值显示在窗体上,运行效果如图2-1所示。
嵩县中等专业学校计算机教研组
Visual Basic 6.0 程序设计