贝叶斯实验报告
戴维宁定理和诺顿定理实验报告

戴维宁定理和诺顿定理实验报告【贝叶斯定理实验报告】实验背景:贝叶斯定理(Bayesian theorem)是一种概率论的原理,由英国数学家Thomas Bayes 在18世纪发明。
它断言,在已知一系列给定事实的情况下,可以用概率的方式推测出未知事件。
此定理又称为诺顿胡普曼定理,是一种关于概率的基本概念,在数据科学中应用广泛。
实验目的:在实验中试用贝叶斯定理推断未知事件。
实验原理:贝叶斯公式是用来计算相关事件发生概率的模型,它可以应用于各种情况。
换句话说,贝叶斯公式是一个根据特定事件及其可能结果决定其后果的模型。
实验原理:1.定义一系列发生可能性:首先定义一系列可能发生的事件(假设A、B、C三种发生可能),然后对这些事件的可能结果的概率做出定义(假使A和B之间有80%的相关性,A 和C之间有60%的相关性,B和C之间有50%的相关性),最后根据该模型计算目标事件的发生概率(如计算A和C共同发生的概率)。
2.定义事件交互权重:为了计算目标事件的概率,需要将三个事件组合起来,得出它们共同发生的概率。
这需要计算每个事件与其他事件的相关性(或者说权重),然后根据这些权重再结合各自的概率,得出最终的概率结果。
实验方法:以上面的例子为例,A和B之间有80%的相关性,A和C之间有60%的相关性,B和C之间有50%的相关性。
计算A和C共同发生概率用贝叶斯公式:P(A∩C)=P(A)×P(C|A)×P(C),所以P(A∩C) = 0.8×0.6×0.5 = 0.2,即A和C共同发生的概率为20%。
实验结果:通过实验,我们发现贝叶斯定理能够实现根据给定事件及其可能结果推断未知事件及其发生概率的功能,证实了贝叶斯定理的正确性。
此外,我们也发现贝叶斯定理可以用来计算事件间的关联,从而使得计算宏观现象的可能性变得更加容易。
总结:本次实验证实了贝叶斯定理的正确性,为利用贝叶斯定理推理未知事件作出了重要贡献,有助于相关领域更加深入地研究、推断及分析。
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告---最小错误率贝叶斯决策分类一、实验原理对于具有多个特征参数的样本(如本实验的iris 数据样本有4d =个参数),其正态分布的概率密度函数可定义为112211()exp ()()2(2)T d p π-⎧⎫=--∑-⎨⎬⎩⎭∑x x μx μ 式中,12,,,d x x x ⎡⎤⎣⎦=x 是d 维行向量,12,,,d μμμ⎡⎤⎣⎦=μ是d 维行向量,∑是d d ⨯维协方差矩阵,1-∑是∑的逆矩阵,∑是∑的行列式。
本实验我们采用最小错误率的贝叶斯决策,使用如下的函数作为判别函数()(|)(),1,2,3i i i g p P i ωω==x x (3个类别)其中()i P ω为类别i ω发生的先验概率,(|)i p ωx 为类别i ω的类条件概率密度函数。
由其判决规则,如果使()()i j g g >x x 对一切j i ≠成立,则将x 归为i ω类。
我们根据假设:类别i ω,i=1,2,……,N 的类条件概率密度函数(|)i p ωx ,i=1,2,……,N 服从正态分布,即有(|)i p ωx ~(,)i i N ∑μ,那么上式就可以写为1122()1()exp ()(),1,2,32(2)T i i dP g i ωπ-⎧⎫=-∑=⎨⎬⎩⎭∑x x -μx -μ对上式右端取对数,可得111()()()ln ()ln ln(2)222T i i i i dg P ωπ-=-∑+-∑-i i x x -μx -μ上式中的第二项与样本所属类别无关,将其从判别函数中消去,不会改变分类结果。
则判别函数()i g x 可简化为以下形式111()()()ln ()ln 22T i i i i g P ω-=-∑+-∑i i x x -μx -μ二、实验步骤(1)从Iris.txt 文件中读取估计参数用的样本,每一类样本抽出前40个,分别求其均值,公式如下11,2,3ii iii N ωωω∈==∑x μxclear% 原始数据导入iris = load('C:\MATLAB7\work\模式识别\iris.txt'); N=40;%每组取N=40个样本%求第一类样本均值 for i = 1:N for j = 1:4w1(i,j) = iris(i,j+1); end endsumx1 = sum(w1,1); for i=1:4meanx1(1,i)=sumx1(1,i)/N; end%求第二类样本均值 for i = 1:N for j = 1:4 w2(i,j) = iris(i+50,j+1);end endsumx2 = sum(w2,1); for i=1:4meanx2(1,i)=sumx2(1,i)/N; end%求第三类样本均值 for i = 1:N for j = 1:4w3(i,j) = iris(i+100,j+1); end endsumx3 = sum(w3,1); for i=1:4meanx3(1,i)=sumx3(1,i)/N; end(2)求每一类样本的协方差矩阵、逆矩阵1i -∑以及协方差矩阵的行列式i ∑, 协方差矩阵计算公式如下11()(),1,2,3,41i ii N i jklj j lk k l i x x j k N ωωσμμ==--=-∑其中lj x 代表i ω类的第l 个样本,第j 个特征值;ij ωμ代表i ω类的i N 个样品第j 个特征的平均值lk x 代表i ω类的第l 个样品,第k 个特征值;iw k μ代表i ω类的i N 个样品第k 个特征的平均值。
朴素贝叶斯最优性实验

朴素贝叶斯的最优性1报告目的:1) 学习朴素贝叶斯和贝叶斯网络相关知识。
2) 验证属性间依赖分布对朴素贝叶斯分类器分类效果的影响。
3) 在二变量高斯分布下验证朴素贝叶斯最优条件r 系数。
2实验过程本实验通过贝叶斯网络模型构造二属性值的分类样本数据集,并在该数据集上分别用贝叶斯网络和朴素贝叶斯的方法分类,比较其分类准确性,并分析两种分类器准确性与该数据集的r 指标和D(fb,fnb)的关系,验证文章的结论。
并使用泊松分布的数据集来验证文章的结论。
2.1实验模型构造一个如下图所示的贝叶斯网络模型,根据该模型生成一组含有4000个样本的数据集。
设X 为属性集{12,X X }1X 表示属性Rain ,2X 表示属性Sprinkle; 设E 为属性值{12,x x };设C 代表类变量取值为+,-,+表示wet 类,-表示non-wet 类; 则根据属性值E 分类为c 的概率为P(c|E)=p(E|c)p(c)/p(E);贝叶斯网络分类器:121121(|)(|,)(|)()()(|)()(|)(|,)p x p x x p C E p C f E p C E p C p x p x x ++=+=+===-=---朴素贝叶斯分类器:21(|)(|)()()(|)()(|)i n i i p x C p C E p C f E p C E p C p x C ==+=+=+===-=-=-∏2.2实验结果1)变化R 的概率,S 取W 取通过改变P(R),得到不同的属性依赖关系,并产生不同的数据集,分别计算贝叶斯网络和朴素贝叶斯分类器在这些数据集上的分类准确性和r 值。
表1为部分实验结果;图1,图2分别为r 值和D 值与两种分类准确性的散点分布图。
表1 变化R 的概率时贝叶斯网络和朴素贝叶斯分类准确率比较图1 贝叶斯网络和朴素贝叶斯分类性能随r的变化情况从图1中看出,当r足够小时,朴素贝叶斯的分类效果接近甚至等同于贝叶斯网络,随着r增大,朴素贝叶斯分类性能逐渐下降。
4贝叶斯网络实验

实验四贝叶斯网络实验
一、实验目的:
了解不确定性推理的原理和特点,理解贝叶斯网络的推理原理。
二、实验原理:
贝叶斯网络是一种模拟人类推过程中因果关系的不确定性处理模型,其网络拓扑结构是一个有向无环图(DAG),它的节点用随机变量或命题来标识,认为有直接关系的命题或变量则用弧来连接。
通过建立推理规则知识库,设置前提条件和证据可信度,经过贝叶斯推理,得到结论及其可信度。
三、实验条件
1贝叶斯推理网络演示程序界面。
四、实验内容:
1建立贝叶斯网络,包括建立推理规则知识库和前提条件的可信度。
2实际演示贝叶斯推理过程。
五、实验步骤:
1建立推理规则知识库。
规则知识是通过点击“下条知识”按钮,将规则知识逐条加入规则知识库列表框中。
2当规则知识库建立完成后,点击“建库完毕”按钮,表示用户所建立的规则知识库的大小已确定下来。
规则知识库的最大规模不能超过100条。
3建立规则知识前提条件的可信度,用户可以从“证据可信度”的下拉列表框中挑选规则知识前提条件,输入相应的可信度。
4通过点击“下条证据可信度”按钮,将规则知识逐条加入前提条件可信度列表框。
当规则知识前提条件的可信度建立完成后,点击“证据完毕”按钮。
此时用户可以看到“开始推理”按钮被激活,则表示用户可以进行推理。
5用户点击“开始推理”按钮后,可以看到生成的贝叶斯网络推理示意图以及在“推理结果如下”文本框中最后结论的后验概率值。
六、实验报告要求:
1建立的知识库和规则库内容。
2贝叶斯推理网络的推理结果。
3试论述贝叶斯推理网络的推理机制及特点。
贝叶斯实验报告范文

贝叶斯实验报告范文一、实验目的掌握贝叶斯推断的基本原理和方法,通过实验研究贝叶斯公式在实际问题中的应用。
二、实验原理贝叶斯推断是一种通过先验概率和观测数据来推断未知变量的方法。
根据贝叶斯公式,我们可以通过已知的先验概率和条件概率来推导后验概率,从而对未知变量进行推断。
三、实验过程1.实验准备:准备一个贝叶斯实验案例,例如:假设有一个盒子里有红球和蓝球,我们不知道红球和蓝球的比例。
先验概率分别是P(R)=0.5和P(B)=0.52.实验步骤:a)假设我们从盒子里随机取了一个球,结果是红色,我们要计算取到红色球的概率。
根据贝叶斯公式:P(R,D)=P(D,R)*P(R)/P(D)其中,P(R,D)代表在已知取到红色球的条件下,取到红色球的概率;P(D,R)代表在已知取到红色球的条件下,取到红色球的概率;P(R)代表取到红色球的概率;P(D)代表取到红色球的概率。
根据已知条件,P(D,R)=1,P(D)=P(D,R)*P(R)+P(D,B)*P(B),P(B)=1-P(R)。
将上述条件代入贝叶斯公式,计算P(R,D)的值。
b)假设我们从盒子里随机取了一个球,结果是红色,然后再从盒子里取了一个球,结果也是红色,我们要计算从盒子里取到的两个球都是红色球的概率。
根据贝叶斯公式:P(R2,R1)=P(R1,R2)*P(R2)/P(R1)其中,P(R2,R1)代表在已知第一个球是红色球的条件下,第二个球是红色球的概率;P(R1,R2)代表在已知第二个球是红色球的条件下,第一个球是红色球的概率;P(R2)代表第二个球是红色球的概率;P(R1)代表第一个球是红色球的概率。
根据已知条件,P(R1,R2)=1,P(R1)=P(R1,R2)*P(R2)+P(R1,B2)*P(B2),P(B2)=1-P(R2)。
将上述条件代入贝叶斯公式,计算P(R2,R1)的值。
四、实验结果根据贝叶斯公式的计算,可以得到实验结果。
五、实验分析通过实验研究,我们可以发现贝叶斯推断在解决实际问题时能够有效地利用已知的先验概率和观测数据,从而对未知变量进行推断。
山东大学计算机学院机器学习实验一贝叶斯分类
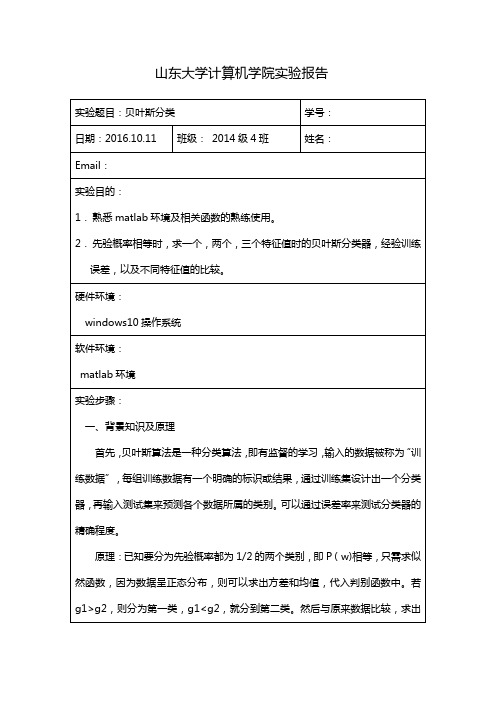
公式:
二、实验步骤
1.因为以前经常使用微软的Azure平台,这次仍然想用这个平台实验一下。分别测试使用一个,两个,三个特征值时用贝叶斯算法求出的准确率和召回率等。
1.熟悉matlab环境及相关函数的熟练使用。
2.先验概率相等时,求一个,两个,三个特征值时的贝叶斯分类器,经验训练误差,以及不同特征值的比较。
硬件环境:
windows10操作系统
软件环境:
matlab环境
实验步骤:
一、背景知识及原理
首先,贝叶斯算法是一种分类算法,即有监督的学习,输入的数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,通过训练集属的类别。可以通过误差率来测试分类器的精确程度。
三、实验结果
1.一个特征值:分类错误率为0.3,界定误差0.473999
2.两个特征值:分类误差率0.45,界定误差为0.460466
3.三个特征值:分类误差率0.15,界定误差为0.411926
4.讨论:对于一有限的数据集,是否有可能在更高的数据维数下经验误差会增加
——我觉得如果数据维数高的话,误差是有可能相对于低维数的反而增加的。因为可能会产生比如这次实验的情况,两维数据的时候第二个特征值特别乱,误差很大,结果误差率比一个特征值的时候还要高了。
结论分析与体会:
刚开始感觉这个题无从下手,不知道要做出来的分类器是个什么样子,虽然知道该怎么在纸上计算后验概率,但是拿到matlab上面编写程序就不会了。
《模式识别》实验报告-贝叶斯分类

《模式识别》实验报告-贝叶斯分类一、实验目的通过使用贝叶斯分类算法,实现对数据集中的样本进行分类的准确率评估,熟悉并掌握贝叶斯分类算法的实现过程,以及对结果的解释。
二、实验原理1.先验概率先验概率指在不考虑其他变量的情况下,某个事件的概率分布。
在贝叶斯分类中,需要先知道每个类别的先验概率,例如:A类占总样本的40%,B类占总样本的60%。
2.条件概率后验概率指在已知先验概率和条件概率下,某个事件发生的概率分布。
在贝叶斯分类中,需要计算每个样本在各特征值下的后验概率,即属于某个类别的概率。
4.贝叶斯公式贝叶斯公式就是计算后验概率的公式,它是由条件概率和先验概率推导而来的。
5.贝叶斯分类器贝叶斯分类器是一种基于贝叶斯定理实现的分类器,可以用于在多个类别的情况下分类,是一种常用的分类方法。
具体实现过程为:首先,使用训练数据计算各个类别的先验概率和各特征值下的条件概率。
然后,将测试数据的各特征值代入条件概率公式中,计算出各个类别的后验概率。
最后,取后验概率最大的类别作为测试数据的分类结果。
三、实验步骤1.数据集准备本次实验使用的是Iris数据集,数据包含150个Iris鸢尾花的样本,分为三个类别:Setosa、Versicolour和Virginica,每个样本有四个特征值:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
2.数据集划分将数据集按7:3的比例分为训练集和测试集,其中训练集共105个样本,测试集共45个样本。
计算三个类别的先验概率,即Setosa、Versicolour和Virginica类别在训练集中出现的频率。
对于每个特征值,根据训练集中每个类别所占的样本数量,计算每个类别在该特征值下出现的频率,作为条件概率。
5.测试数据分类将测试集中的每个样本的四个特征值代入条件概率公式中,计算出各个类别的后验概率,最后将后验概率最大的类别作为该测试样本的分类结果。
6.分类结果评估将测试集分类结果与实际类别进行比较,计算分类准确率和混淆矩阵。
贝叶斯分类实验报告doc

贝叶斯分类实验报告篇一:贝叶斯分类实验报告实验报告实验课程名称数据挖掘实验项目名称贝叶斯分类年级XX级专业信息与计算科学学生姓名学号 1207010220理学院实验时间:XX年12月2日学生实验室守则一、按教学安排准时到实验室上实验课,不得迟到、早退和旷课。
二、进入实验室必须遵守实验室的各项规章制度,保持室内安静、整洁,不准在室内打闹、喧哗、吸烟、吃食物、随地吐痰、乱扔杂物,不准做与实验内容无关的事,非实验用品一律不准带进实验室。
三、实验前必须做好预习(或按要求写好预习报告),未做预习者不准参加实验。
四、实验必须服从教师的安排和指导,认真按规程操作,未经教师允许不得擅自动用仪器设备,特别是与本实验无关的仪器设备和设施,如擅自动用或违反操作规程造成损坏,应按规定赔偿,严重者给予纪律处分。
五、实验中要节约水、电、气及其它消耗材料。
六、细心观察、如实记录实验现象和结果,不得抄袭或随意更改原始记录和数据,不得擅离操作岗位和干扰他人实验。
七、使用易燃、易爆、腐蚀性、有毒有害物品或接触带电设备进行实验,应特别注意规范操作,注意防护;若发生意外,要保持冷静,并及时向指导教师和管理人员报告,不得自行处理。
仪器设备发生故障和损坏,应立即停止实验, 并主动向指导教师报告,不得自行拆卸查看和拼装。
八、实验完毕,应清理好实验仪器设备并放回原位,清扫好实验现场,经指导教师检查认可并将实验记录交指导教师检查签字后方可离去。
九、无故不参加实验者,应写出检查,提出申请并缴纳相应的实验费及材料消耗费,经批准后,方可补做。
十、自选实验,应事先预约,拟订出实验方案,经实验室主任同意后,在指导教师或实验技术人员的指导下进行。
H^一、实验室内一切物品未经允许严禁带出室外,确需带出,必须经过批准并办理手续。
学生所在学院:理学院专业:信息与计算科学班级: 信计121篇二:数据挖掘-贝叶斯分类实验报告实验报告实验课程名称数据挖掘实验项目名称贝叶斯的实现年级专业学生姓名学号00学院实验时间:年月曰13篇三:模式识别实验报告贝叶斯分类器模式识别理论与方法课程作业实验报告实验名称:Generating Pattern Classes 实验编号:Proj02-01规定提交日期:XX年3月30日实际提交日期:XX年3 月24日摘要:在熟悉贝叶斯分类器基本原理基础上,通过对比分类特征向量维数差异而导致分类正确率发生的变化,验证了“增加特征向量维数,可以改善分类结果”。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.贝叶斯法则 机器学习的任务:在给定训练数据 D 时,确定假设空间 H 中的最佳假设。 最佳假设:一种方法是把它定义为在给定数据 D 以及 H 中不同假设的先验概率的有关知识下的最可能假设。贝叶斯 理论提供了一种计算假设概率的方法,基于假设的先验概率、给定假设下观察到不同数据的概率以及观察到的数据 本身。 2.先验概率和后验概率 用 P(h)表示在没有训练数据前假设 h 拥有的初始概率。P(h)被称为 h 的先验概率。先验概率反映了关于 h 是一正确 假设的机会的背景知识如果没有这一先验知识,可以简单地将每一候选假设赋予相同的先验概率。类似地,P(D)表 示训练数据 D 的先验概率,P(D|h)表示假设 h 成立时 D 的概率。机器学习中,我们关心的是 P(h|D),即给定 D 时 h 的成立的概率,称为 h 的后验概率。 3.贝叶斯公式 贝叶斯公式提供了从先验概率 P(h)、P(D)和 P(D|h)计算后验概率 P(h|D)的方法 p(h|D)=P(D|H)*P(H)/P(D) P(h|D)随着 P(h)和 P(D|h)的增长而增长,随着 P(D)的增长而减少,即如果 D 独立于 h 时被观察到的可能性越大, 那么 D 对 h 的支持度越小。 4.极大后验假设 学习器在候选假设集合 H 中寻找给定数据 D 时可能性最大的假设 h,h 被称为极大后验假设(MAP)确定 MAP 的方法 是用贝叶斯公式计算每个候选假设的后验概率,计算式如下: h_map=argmax P(h|D)=argmax (P(D|h)*P(h))/P(D)=argmax P(D|h)*p(h) (h 属于集合 H)
二、实验的硬件、软件平台
硬件:计算机 软件:操作系统:WINDOWS 10 应用软件:C,Java 或者 Matlab 相关知识点:
贝叶斯定理:
表示事件 B 已经发生的前提下,事件 A 发生的概率,叫做事件 B 发生下事件 A 的条件概 率,其基本求解公式为:
贝叶斯定理打通了从 P(A|B)获得 P(B|A)的道路。
HUNAN UNIVERSITY
人工智能实验报告
题
目
学生姓名
学生学号
专业班级
指导老师
实验三:分类算法实验 匿名
2013080702xx
智能科学与技术 1302 班 袁进
一.实验目的
1.了解朴素贝叶斯算法的基本原理; 2.能够使用朴素贝叶斯算法对数据进行分类 3.了解最小错误概率贝叶斯分类器和最小风险概率贝叶斯分类器 4.学会对于分类器的性能评估方法
C.编写一个贝叶斯分类器。输入为:均指向量、先验概率、协方差矩阵、输入学习数据 X,测 试数据类别 XLABEL,测试数据 Y.输出为 Y 对应的类别。(选做)。
四、实验步骤:
1.仔细阅读并了解实验数据集;
2.使用任何一种熟悉的计算机语言(比如 C,Java 或者 matlab)实现朴素贝叶斯算法;
的,所以有: 整个朴素贝叶斯分类分为三个阶段:
第一阶段: 准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据 具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类, 形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整 个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大 程度上由特征属性、特征属性划分及训练样本质量决定。
直接给出贝叶斯定理:
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很 朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出 现的概率,哪个最大,就认为此待分类项属于哪个类别。
朴素贝叶斯分类的正式定义如下:
1、设
为一个待分类项,而每个 a 为 x 的一个特征属性。
三、实验内容及步骤
实验内容: A.利用贝叶斯算法进行数据分类操作,并统计其预测正确率,数据集:汽车评估数据集(learn 作为学习集,test 作为测试集合) B.随机产生10000组正样本和20000负样本高斯分布的数据集合(维数设为二维),要求正样 本:均值为[1;3],方差为[2 0;0 2];负样本:均值为[10;20],方差为[10 0;0 10].先验概 率按样本量设定为1/3和2/3.分别利用最小错误概率贝叶斯分类器和最小风险概率贝叶斯分 类器对其分类。(假设风险程度正样本分错风险系数为0.6,负样本分错风险为0.4,该设定 仅用于最小风险分析) 相关概念:
3.利用朴素贝叶斯算法在训练数据上学习分类器,训练数据的大小分别设置为:前100个数据,
前200个数据,前500个数据,前700个数据,前1000个数据,前1350个数据;
4.利用测试数据对学习的分类器进行性能评估;
5.统计分析实验结果并上交实验报告;
A 源代码:
package Bayes; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.math.BigDecimal; import java.util.Vector; import Bayes.NaiveBayesTool.Property; public class NaiveBayesTool {
2、有类别集合。
那么现在的关键就是如何计算第 3 步中的各个条件概率。我们可以这么做: 1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2、统计得到在各类别下各个特征属性的条件概率估计。即
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立
NaiveBayesTool NBayes=new NaiveBayesTool(); NBayes.ReadFile("learn.txt");//获取训练样本
NBayes.Calculated_probability();//计算概率 NBayes.TestData();//导入测试样本数据 NBayes.show();//输出结果 } /*汽车属性类 * */ public class Property{//汽车有6个属性,每个属性都有几种类别,根据这6个属性来判断汽 车的性价比Classvalue如何, public String buying;//vhigh,high,med,low public String maint;//vhigh,high,med,low public String doors;//2,3,4,5more public String persons;//2,4,more public String lug_boot;//small ,med,big public String safety;// low,med,high public String ClassValues;//unacc,acc, good,vgood public String[] PredictResult = new String[5];// 记录预测结果 public Property(String b,String m,String d,String p,String l,String s,String c){
/* * 申明全局变量 // 前面是自己的属性,后面是value的属性 * */ int testTotal = 0;// 训练样本数量 int predictTotal = 0;// 测试样本的数据 int predictSucess = 0;// 预测成功的数量 //存储数量 public int[][] buy=new int[4][4];//vhigh,high,med,low public int[][] maint=new int[4][4];//vhigh,high,med,low public int[][] door=new int[4][4];//2,3,4,5more public int[][] person=new int[3][4];//2,4,more public int[][] lug_boot=new int[3][4];//small ,med,big public int[][] safe=new int[3][4];//low,med,high public int[] ClassValues=new int[4];//unacc,acc, good,vgood String[] ClassValueName = { "unacc", "acc", "good", "vgood" }; //存储概率 float[] ClassValue_gl = new float[4];// unacc-0 acc-1 good-2 vgood-3 float[][] buy_Vlaue_gl = new float[4][4]; //前面是自己的属性,后面是value的属性 float[][] maint_Value_gl = new float[4][4]; float[][] door_Value_gl = new float[4][4]; float[][] person_Value_gl = new float[3][4]; float[][] lugboot_Value_gl = new float[3][4]; float[][] safe_Value_gl = new float[3][4]; /** * 主函数 */ public static void main(String[] args) throws IOException {