计量经济学实验报告54995
计量经济学实验报告

计量经济学实验报告1. 引言计量经济学是应用数学和统计学方法来研究经济现象的一门学科。
实验是计量经济学研究中常用的方法之一,通过设计和实施实验,可以帮助我们理解经济现象背后的因果关系。
本文将对一项计量经济学实验进行详细描述和分析,以展示实验的设计、数据分析和结论。
2. 实验设计2.1 实验目的本次实验的目的是研究市场供需关系对商品价格的影响。
具体而言,我们希望通过改变商品的市场供给量,观察商品价格如何变化,并分析供给弹性的大小。
2.2 实验假设在实验设计阶段,我们需要制定实验假设来指导实验的进行。
在本次实验中,我们假设市场供给量的变动会对商品价格产生影响,而且供给弹性的大小会决定价格的变动幅度。
2.3 实验步骤本次实验包括以下几个步骤:1.设定实验组和对照组:我们将随机选择一些参与者,并将其分为两组,一组作为实验组,一组作为对照组。
实验组将面临市场供给量变动的情况,而对照组则不受干扰。
2.确定商品和市场:我们选择一个特定的商品,并确定一个特定的市场来进行实验。
这样可以使实验更加具体和可控。
3.设定实验条件:在实验组中,我们逐步调整市场供给量,并记录下不同供给量下的商品价格。
对照组则保持市场供给量不变。
4.数据收集:在每次实验条件设定完毕后,我们将记录实验组和对照组的商品价格,并对数据进行整理和存储。
2.4 实验风险和伦理考虑在设计实验时,我们需要考虑实验可能存在的风险,并确保实验过程符合伦理要求。
具体而言,我们需要确保参与者的权益得到保护,并在可能对参与者造成负面影响的情况下停止实验。
3. 数据分析在实验进行完毕后,我们对数据进行分析,以验证实验假设并得出结论。
3.1 数据整理首先,我们将实验组和对照组的数据整理成表格形式,方便后续分析。
由于文档要求不能包含表格,这里无法展示具体的数据。
3.2 数据分析方法我们采用的数据分析方法主要包括描述统计分析和回归分析。
描述统计分析用于描述数据的基本特征,包括平均值、标准差、最小值和最大值等。
计量经济学实训报告

计量经济学实训报告一、实验设计:本次实验是基于计量经济学的理论知识和方法,通过对已有的数据进行回归分析,验证理论假设的可行性。
实验的目的是了解计量经济学在实际应用中的重要性,以及掌握回归分析等基本方法。
二、实验过程:1.数据收集:我们选择了一个包含多个变量的数据集,包括自变量和因变量,旨在通过回归模型来预测因变量的取值。
2.数据清洗:对收集到的数据进行清洗和预处理,包括处理缺失值、异常值等。
3.变量选择:根据计量经济学的原理和假设,选择适合的自变量和因变量,并对其进行初步的分析。
4.模型建立:根据选择的自变量和因变量,建立回归模型,并假设一些条件。
5.模型估计:利用统计软件对建立的回归模型进行估计和拟合,获得回归系数和拟合度等相关参数。
6.模型诊断与检验:对建立的回归模型进行诊断和检验,检查模型的拟合度和有效性。
7.结果分析:根据模型估计和检验结果,分析自变量对因变量的影响程度和显著性等,并解读模型。
三、实验结果:经过以上的实验过程和分析,我们得到了以下结论:1.自变量X对因变量Y的影响具有统计显著性;2.自变量X1对因变量Y的影响程度较大,而自变量X2的影响相对较小;3.拟合度较高,模型的解释能力较强。
四、实验感想:通过本次实验,我们深刻认识到计量经济学在实际问题中的重要性。
通过建立回归模型,我们可以对研究对象的变量关系进行实证分析,从而对问题进行解释和预测。
同时,我们也了解到了回归分析中的一些注意事项,如数据的选择和处理、模型的建立和检验等。
在今后的学习中,我们将进一步掌握和应用计量经济学的方法,提高对实际问题的分析和解决能力。
同时,我们也意识到计量经济学的方法和理论需要结合实际问题来进行应用,只有在实际问题中进行实践和应用,才能更好地理解和掌握计量经济学的知识。
计量经济学实验报告
计量经济学作业一、研究内容研究影响GDP增长的因素二、理论模型的设计模型选择国内生产总值GDP作为被解释变量,财政支出FE、城镇就业人口TEP作为被解释变量,由于在中国政府对于经济调控的影响比较大,财政政策对于中国经济具有较强的干预性,特别是在2008年金融风暴席卷下,中国政府采用财政政策来拉动中国经济增长,起到了较明显的作用,因此考虑选取财政支出作为解释变量。
另外,中国城乡二元差异,中国经济的发展是伴随着城镇化的发展,城镇化进程对于中国经济的发展也起着重要作用,因此选取了城镇就业人口作为解释变量。
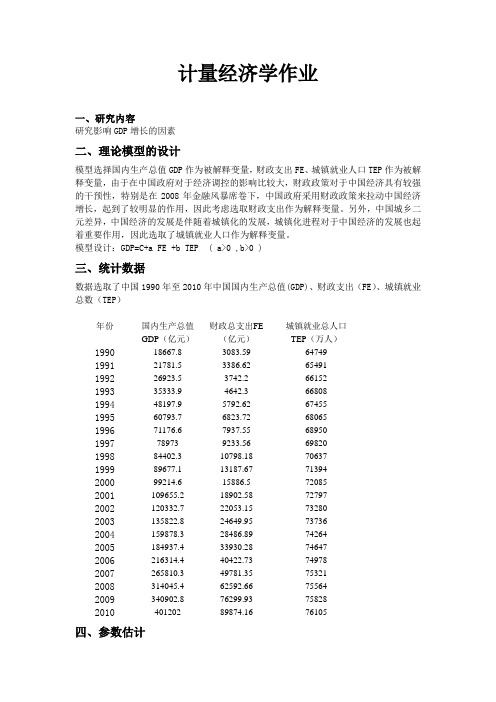
模型设计:GDP=C+a FE +b TEP ( a>0 ,b>0 )三、统计数据数据选取了中国1990年至2010年中国国内生产总值(GDP)、财政支出(FE)、城镇就业总数(TEP)年份国内生产总值GDP(亿元)财政总支出FE(亿元)城镇就业总人口TEP(万人)199018667.8 3083.59 64749 199121781.5 3386.62 65491 199226923.5 3742.2 66152 199335333.9 4642.3 66808 199448197.9 5792.62 67455 199560793.7 6823.72 68065 199671176.6 7937.55 68950 199778973 9233.56 69820 199884402.3 10798.18 70637 199989677.1 13187.67 71394 200099214.6 15886.5 72085 2001109655.2 18902.58 72797 2002120332.7 22053.15 73280 2003135822.8 24649.95 73736 2004159878.3 28486.89 74264 2005184937.4 33930.28 74647 2006216314.4 40422.73 74978 2007265810.3 49781.35 75321 2008314045.4 62592.66 75564 2009340902.8 76299.93 75828 2010401202 89874.16 76105四、参数估计利用Eviews对模型进行普通二乘法估计,输出结果如下:^GDP= —281320.3 + 3.826244FE + 4.511029TEP(—4.292062) (26.83580) (4.701810)R^2=0.993864 R^2=0.993182 F=1457.638 D.W.=0.796234从回归估计的结果来看,可决系数R^2=0.993864,表明模型总体拟合较好,GDP变化的99.3864%可由财政支出和城镇就业人口来解释。
计量经济学实验报告(一)

计量经济学实验报告(一)
一、实验背景
计量经济学实验是一种采用经济理论和方法来设计实验的经济研究方法。
经济实验的主要目的是检验经济理论,比如检验假设和改进预测。
它还可以用于定性评价和定量评价政策方案和市场动态,以及验证行为经济学理论。
二、实验内容
本次实验通过一组独立的在线调查来研究人们对收入分配政策的态度。
调查中,受访者被要求就14种不同的收入分配政策支持、反对和中立做出反应。
这14种收入分配政策包括财政公平政策、税收和补贴政策、劳动力市场政策和参与机会政策等。
以及根据态度的强度来改变互动形式,不同类型的回答有不同的加分,比如更强烈的支持会比中立的有更多分数。
三、实验结果
实验结果显示,在14种收入分配政策中,受访者大部分表示支持或者反对。
最受支持的是劳动力市场政策,而最受反对的是税收和补贴政策。
同时,实验还发现,这14种收入分配政策受实验者支持或反对的原因大部分是经济实惠:如果一个政策能够为普通大众带来经济实惠,这个政策很可能受到受访者的支持。
此外,一些政策因其有助于实现平等收入而受到支持。
四、实验结论
本次实验结论清楚地表明,受访者支持或反对收入分配政策跟经济实惠有关。
当人们普遍受益于收入分配政策时,他们很可能支持这种政策。
另外,实验还发现,有些政策受支持的原因还在于它们有助于实现平等收入的目的。
本次实验不仅对计量经济学的理论和方法提供了有价值的信息,而且还为构建经济实证提供了重要的参考意见。
可以认为,经过本次实验的进一步检验和优化,可以发现更详细、更准确的数据,以便进一步检验和发展计量经济学的理论与方法。
计量经济学实验报告

计量经济学实验报告:马艺菡学号:4班级:9141070302任课教师:静文实验题目简单线性回归模型分析一实验目的与要求目的:影响财政收入的因素可能有很多,比如国生产总值,经济增长,零售物价指数,居民收入,消费等。
为研究国生产总值对财政收入是否有影响,二者有何关系。
要求:为研究国生产总值变动与财政收入关系,需要做具体分析。
二实验容根据1978-1997年中国国生产总值X和财政收入Y数据,运用EV软件,做简单线性回归分析,包括模型设定,模型检验,模型检验,得出回归结果。
三实验过程:(实践过程,实践所有参数与指标,理论依据说明等)简单线性回归分析,包括模型设定,估计参数,模型检验,模型应用。
(一)模型设定为研究中国国生产总值对财政收入是否有影响,根据1978-1997年中国国生产总值X和财政收入Y,如图11978-1997年中国国生产总值和财政收入(单位:亿元)1996 66850.5 7407.991997 73452.5 8651.14根据以上数据作财政收入Y 和国生产总值X的散点图,如图2从散点图可以看出,财政收入Y和国生产总值X大体呈现为线性关系,所以建立的计量经济模型为以下线性模型:(二)估计参数1、双击“Eviews”,进入主页。
输入数据:点击主菜单中的File/Open/EV Workfile—Excel—GDP.xls;2、在EV主页界面点击“Quick”菜单,点击“Estimate Equation”,出现“Equation Specification”对话框,选择OLS估计,输入““y c x”,点击“OK”。
即出现回归结果图3;参数估计结果为:Y=857.8375+0.100036iX(67.12578)(0.002172)t=(12.77955)(46.04910)2r=0.991583F=2120.520S.E.=208.5553DW=0.864 0323、在“Equation”框中,点击“Resids”,出现回归结果的图形(图4):剩余值(Residual)、实际值(actual),拟合值(fitted)4、.(三)模型检验1.经济意义检验回归模型为:Y=857.8375+0.100036*X(其中Y为财政收入,iX为国生产总值;)所估计的参数=0.100036,说明国生产总值每增加1亿元,财政收入平均增加0.100036亿元。
计量经济学综合实验报告

1、用Eviews创建变量LE、NI,输入样本数据,、打开Eviews工作文件,建立新的文件夹,在命令框中输入“data le ni”回车 ,从数据表中粘贴数据到Eviews数据表中即可;
2、估计河南省农村居民消费支出LE依可支配收入NI的一元回归模型
下图就是河南省农村居民消费支出LE和可支配收入NI的一元线性回归结果:
6、对ce为被解释变量,di为解释变量模型输出结果进行经济理论检验,拟合优度检验和t检验;
1经济意义检验:所估计参数β1=,β2=,说明可支配收入增加1元,平均说来可导致城市居民消费支出增加元;
2拟合优度检验:通过以上的回归数据可知,可决系数为,说明所建模型整体上对样本数据拟合度不是太好;
3t检验:针对H1:β1=0和H2:β2=0,由上回归结果可以看出,估计的回归系数B1的标准误差和t值分别为:SEβ1=,tβ1=: β2的标准误差和t值分别为SEβ2= tβ2=. 取a=0,05,查t分布表得自由度为n-2=18-2=16的临界值为= 19,tβ1=<= 19,不拒绝H1, tβ2=>= 19,拒绝H2.这表明,城市居民可支配收入对其消费水平有很大影响;
但两者的之一比例均大于,可见用凯恩斯的绝对收入假说解释现阶段河南省居民消费规律是合理的;
实验二 截面数据一元线性回归模型
异方差性
实验目的和要求
1、掌握一元线性回归估计方程的异方差性检验方法;
2、掌握一元线性回归估计方程的异方差性纠正方法;
3、在老师的指导下独立完成实验,并得到正确结果;
实验内容
1、估计河南省城市居民消费支出CE依可支配收入DI的一元线性回归模型和农村居民生活消费支出LE与纯收入NI的一元线性回归模型;
城市居民:
计量经济学实验报告
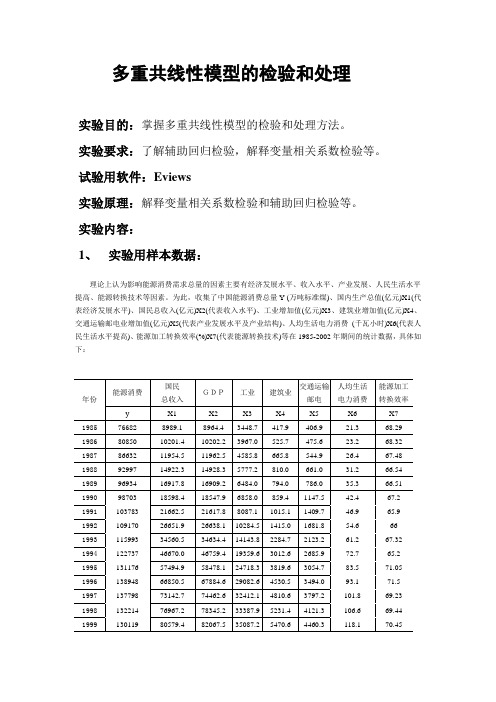
多重共线性模型的检验和处理实验目的:掌握多重共线性模型的检验和处理方法。
实验要求:了解辅助回归检验,解释变量相关系数检验等。
试验用软件:Eviews实验原理:解释变量相关系数检验和辅助回归检验等。
实验内容:1、实验用样本数据:理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。
为此,收集了中国能源消费总量Y (万吨标准煤)、国内生产总值(亿元)X1(代表经济发展水平)、国民总收入(亿元)X2(代表收入水平)、工业增加值(亿元)X3、建筑业增加值(亿元)X4、交通运输邮电业增加值(亿元)X5(代表产业发展水平及产业结构)、人均生活电力消费(千瓦小时)X6(代表人民生活水平提高)、能源加工转换效率(%)X7(代表能源转换技术)等在1985-2002年期间的统计数据,具体如下:资料来源:《中国统计年鉴》2004、2000年版,中国统计出版社。
实验要求:(1)建立对数线性多元回归模型(2)如果决定用表中全部变量作为解释变量,你预料会遇到多重共线性的问题吗?为什么?(3)如果有多重共线性,你准备怎样解决这个问题?明确你的假设并说明全部计算。
2、实验步骤:建立对数线性多元回归模型设模型的函数形式为:Y=β+β1X1+β2X2+β3X3+β4X4+β5X5+β6X6+β7X7+u运用OLS估计方法对上式中的参数进行估计,EViews过程如下1、参数估计:(1)点击“File/New/Workfile”,屏幕上出现Workfile Range对话框,在Start date里键入1985,在End date里键入2002,点击OK后屏幕出现“Workfile对话框(子窗口)”。
(2)方法一:在Objects菜单中点击New objects,在New objects选择Group,并在Name for Objects定义文件名,点击OK出现数据编辑窗口,,按顺序键入数据。
计量经济学实验报告1(共6篇)

篇一:计量经济学实验报告 (1)计量经济学实验基于eviews的中国能源消费影响因素分析学院:班级:学号:姓名:基于e views的中国能源消费影响因素分析一、背景资料能源消费是指生产和生活所消耗的能源。
能源消费按人平均的占有量是衡量一个国家经济发展和人民生活水平的重要标志。
能源是支持经济增长的重要物质基础和生产要素。
能源消费量的不断增长,是现代化建设的重要条件。
我国能源工业的迅速发展和改革开放政策的实施,促使能源产品特别是石油作为一种国际性的特殊商品进入世界能源市场。
随着国民经济的发展和人口的增长,我国能源的供需矛盾日益紧张。
同时,煤炭、石油等常规能源的大量使用和核能的发展,又会造成环境的污染和生态平衡的破坏。
可以看出,它不仅是一个重大的技术、经济问题,而且以成为一个严重的政治问题。
在20世纪的最后二十年里,中国国内生产总值(gdp)翻了两番,但是能源消费仅翻了一番,平均的能源消费弹性仅为0.5左右。
然而自2002年进入新一轮的高速增长周期后,中国能源强度却不断上升,经济发展开始频频受到能源瓶颈问题的困扰。
鉴于此,研究能源问题不仅具有必要性和紧迫性,更具有很大的现实意义。
由于我国目前面临的所谓“能源危机”,主要是由于需求过大引起的,而我国作为世界上最大的发展中国家,人口众多,所需能源不可能完全依赖进口,所以,研究能源的需求显得更加重要。
二、影响因素设定根据西方经济学消费需求理论可知,影响消费需求的因素有:商品的价格、消费者收入水平、相关商品的价格、商品供给、消费者偏好以及消费者对商品价格的预期等。
对于相关商品价格的替代效应,我们认为其只存在能源品种内部之间,而消费者偏好及消费者对商品价格的预期数据差别较大,不容易进行搜集整理在此暂不涉及。
另外,发展经济学认为,来自知识、人力资本的积累水平所体现的技术进步不仅可以带动劳动产出的增长,而且会通过外部效应可以提高劳动力、自然资源、物质资本与生产要素的生产效率,消除其中收益递减的内在联系,带来递增的规模收益。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.背景经济增长是指一个国家生产商品和劳务能力的扩大。
在实际核算中,常以一国生产的商品和劳务总量的增加来表示,即以国民生产总值(GDP )和国内生产总值的的增长来计算。
古典经济增长理论以社会财富的增长为中心,指出生产劳动是财富增长的源泉。
现代经济增长理论认为知识、人力资本、技术进步是经济增长的主要因素。
从古典增长理论到新增长理论,都重视物质资本和劳动的贡献。
物质资本是指经济系统运行中实际投入的资本数量.然而,由于资本服务流量难以测度,在这里我们用全社会固定资产投资总额(亿元)来衡量物质资本。
中国拥有十三亿人口,为经济增长提供了丰富的劳动力资源。
因此本文用总就业人数(万人)来衡量劳动力。
居民消费需求也是经济增长的主要因素。
经济增长问题既受各国政府和居民的关注,也是经济学理论研究的一个重要方面。
在1978—2008年的31年中,我国经济年均增长率高达9.6%,综合国力大大增强,居民收入水平与生活水平不断提高,居民的消费需求的数量和质量有了很大的提高。
但是,我国目前仍然面临消费需求不足问题。
本文将以中国经济增长作为研究对象,选择时间序列数据的计量经济学模型方法,将中国国内生产总值与和其相关的经济变量联系起来,建立多元线性回归模型,研究我国中国经济增长变动趋势,以及重要的影响因素,并根据所得的结论提出相关的建议与意见。
用计量经济学的方法进行数据的分析将得到更加具有说服力和更加具体的指标,可以更好的帮助我们进行预测与决策。
因此,对我国经济增长的计量经济学研究是有意义同时也是很必要的。
2.模型的建立 2.1 假设模型为了具体分析各要素对我国经济增长影响的大小,我们可以用国内生产总值(Y )这个经济指标作为研究对象;用总就业人员数(1X )衡量劳动力;用固定资产投资总额(2X )衡量资本投入:用价格指数(3X )去代表消费需求。
运用这些数据进行回归分析。
这里的被解释变量是,Y :国内生产总值,与Y-国内生产总值密切相关的经济因素作为模型可能的解释变量,共计3个,它们分别为:1X 代表社会就业人数, 2X 代表固定资产投资, 3X 代表消费价格指数,μ代表随机干扰项。
模型的建立大致分为理论模型设置、参数估计、模型检验、模型修正几个步骤。
如果模型符合实际经济理论并且通过各级检验,那么模型就可以作为最终模型,可以进行结构分析和经济预测。
国内生产总值 经济活动人口 全社会固定资产投资 居民消费价格指数 1992年 26,923.48 66,782.00 8,080.10 106.4 1993年 35,333.92 67,468.00 13,072.30 114.7 1994年 48,197.86 68,135.00 17,042.10 124.1 1995年 60,793.73 68,855.00 20,019.30 117.1 1996年 71,176.59 69,765.00 22,913.50 108.3 1997年 78,973.03 70,800.00 24,941.10 102.8 1998年 84,402.28 72,087.00 28,406.20 99.2 1999年 89,677.05 72,791.00 29,854.70 98.6 2000年 99,214.55 73,992.00 32,917.70 100.4 2001年 109,655.17 73,884.00 37,213.50 100.7 2002年 120,332.69 74,492.00 43,499.90 99.2 2003年 135,822.76 74,911.00 55,566.61 101.2 2004年 159,878.34 75,290.00 70,477.43 103.9 2005年 184,937.37 76,120.00 88,773.61 101.8 2006年 216,314.43 76,315.00 109,998.16 101.5 2007年 265,810.31 76,531.00 137,323.94 104.8 2008年 314,045.43 77,046.00 172,828.40 105.9 2009年 340,902.81 77,510.00 224,598.77 99.3 2010年 401,512.80 78,388.00 251,683.77 103.3 2011年 473,104.05 78,579.00 311,485.13 105.4 2012年519,470.1078,894.00374,694.74102.6假设经济模型为:μββββ++++=3423121X X X y 2.2 建立初始模型——OLS2.2.1 使用OLS 法进行参数估计Dependent Variable: Y Method: Least Squares Date: 05/27/14 Time: 20:46 Sample: 1992 2012Included observations: 21VariableCoefficient Std. Error t-Statistic Prob.C -713618.8 127520.1 -5.596127 0.0000 X1 9.301372 1.252990 7.423339 0.0000 X21.1099320.03693230.053370.0000X3960.6130 455.8173 2.107452 0.0502R-squared0.996644 Mean dependent var 182689.5 Adjusted R-squared 0.996051 S.D. dependent var 147531.4 S.E. of regression 9270.792 Akaike info criterion 21.27677 Sum squared resid 1.46E+09 Schwarz criterion 21.47573 Log likelihood -219.4061 Hannan-Quinn criter. 21.31995 F-statistic 1682.612 Durbin-Watson stat 1.682540 Prob(F-statistic)0.000000得到的初始模型为123713618.89.3013 1.1099960.62Y X X X =-+++2.2.2 对初始模型进行检验要对建立的初始模型进行包括经济意义检验、统计检验、计量经济学检验、预测检验在内的四级检验。
(1)经济意义检验解释变量的系数分别为1β=9.3013、2β=1.1099。
两个解释变量系数均为正,符合被解释变量与解释变量之间的正相关关系,符合解释变量增长带动被解释变量增长的经济实际,3β=960.61,符合被解释变量与解释变量之间的正相关关系。
与现实经济意义相符,所以模型通过经济意义检验。
(2)统计检验①拟合优度检验:R 2检验,R-squared=0.996644;Adjusted R-squared=0.996051;可见拟合优度很高,接近于1,方程拟和得很好。
②变量的显著性检验:t 检验,模型系数显著性检验,t 检验结果VariableCoefficient Std. Error t-Statistic Prob.C -713618.8 127520.1 -5.596127 0.0000 X1 9.301372 1.252990 7.423339 0.0000 X2 1.109932 0.036932 30.05337 0.0000 X3 960.6130 455.8173 2.107452 0.0502从检验结果表中看到,包括常数项在内的所有解释变量系数的t 检验的伴随概率均小于5%,所以,在5%的显著水平下1X 、2X 、3X 的系数显著不为零,通过显著性检验,常数项也通过显著性检验,保留在模型之中。
③方程的显著性检验:F 检验,方程总体显著性检验的伴随概率小于0.00000,在5%显著水平下方程显著成立,具有经济意义。
(3)计量经济学检验:方程通过经济意义检验和统计检验,下面进行居于计量经济学模型检验核心的计量经济学检验。
①进行异方差性检验:首先用图示法对模型的异方差性进行一个大致的判断。
令X 轴为方程被解释变量,Y 轴为方程的残差项,做带有回归线的散点图。
40,000,00080,000,000120,000,000160,000,000200,000,000240,000,000280,000,000320,000,000X1E 2040,000,00080,000,000120,000,000160,000,000200,000,000240,000,000280,000,000320,000,000X2E 2040,000,00080,000,000120,000,000160,000,000200,000,000240,000,000280,000,000320,000,000X3E 2通过图形看到,回归线向上倾斜,大致判断存在异方差性,但是,图示法并不准确,下面使用White 异方差检验法进行检验,得到下面的检验结果:Heteroskedasticity Test: WhiteF-statistic 2.616909 Prob. F(9,11)0.0677 Obs*R-squared 14.31446 Prob. Chi-Square(9) 0.1116 Scaled explained SS6.518631 Prob. Chi-Square(9) 0.6871Test Equation:Dependent Variable: RESID^2 Method: Least Squares Date: 05/27/14 Time: 22:12 Sample: 1992 2012Included observations: 21VariableCoefficientStd. Error t-Statistic Prob.C 1.04E+11 5.15E+10 2.017611 0.0687 X1 -1949844. 945581.9 -2.062057 0.0636 X1^2 9.051342 4.890384 1.850845 0.0912 X1*X2 -1.464567 0.648826 -2.257258 0.0453 X1*X3 6331.557 4214.655 1.502272 0.1612 X2 120106.3 44949.37 2.672034 0.0217 X2^2 0.010887 0.005643 1.929190 0.0799 X2*X3 -86.80476 165.7979 -0.523558 0.6110 X3-6.64E+084.05E+08-1.6396150.1293X3^21017845. 635414.2 1.601860 0.1375R-squared0.681641 Mean dependent var 69576621 Adjusted R-squared 0.421165 S.D. dependent var 84049298 S.E. of regression 63945702 Akaike info criterion 39.09072 Sum squared resid 4.50E+16 Schwarz criterion 39.58811 Log likelihood -400.4526 Hannan-Quinn criter. 39.19867 F-statistic 2.616909 Durbin-Watson stat 1.993942 Prob(F-statistic)0.0676562nR =14.3145,对应的卡方检验p 值为0.1116所得的检验伴随概率小于5%,均在5%的显著水平下拒绝方程不存在异方差性的原假设,认为模型具有比较严重的异方差性。