北京邮电大学2017年《软件工程专业综合》考研大纲_北邮考研论坛
北邮 电子商务 J2EE重点 软件工程 研究生

1.1. What is J2EE architecture?Distributed (Clustered) àApp serversMulti-tiered àdifferent container in one App server Component & Container based1.2. Why we use APP server?web server/app server:∙web server: presentation logic only (can be changed to support business logic layer with plugin) ∙app server/middleware/platform: presentation logic && business logicAPP server:∙It is J2EE compatible middleware∙It is pure java-based, so it can run on top of Unix OS, and it is more stable and secure.∙J2EE App is app which is running on top of J2EE App serverBenefit of using J2EE app server/platform:∙Do not reinvent the wheel/do not start from the scratch∙Reuse all of the app server’s services1.3. Why the Sun’s java & j2ee become morecompetitive?第二章1.1. What is presentation logic?∙the server/waiter is the presentation layer(view, and control in MVC),∙the server can act as a view and control in the MVC(pass to different roles, cook or bartender).∙In J2EE app, the JSP as view, and the servlet as control1.2. Why to use Java Bean and Taglib in the JSP? Use a JavaBean when:∙to be primarily encapsulating data(data from the form), rather than business logic.∙to modularize your Java code for reuse in something other than JSP.∙to minimize the chance of having the Web/HTML designers inadvertently modify your Java code.Use custom tag libraries when:∙You have relatively simple business logic that you do want to make available for use by Webdevelopers. For example, you can create a login module for your Web application that the HTML designers can include in every page requiring a user login.??∙You want to do pre- and post-processing of content for tasks such as personalization or content management. Personalization might include special tags that look up a user's information. Content management would enable you to create special tags to load data from your content repository.Or(总结)∙In the final analysis, much of what you can do with JavaBeans you can also do with custom tag libraries.∙the deciding factor is the preference of the developer. 第三章1.1. What is business logic?∙the cook is the business logic layer∙The cook can also classified as Head cook && Helper cook∙The Head cook isàbusiness process controlàcontrol in MVC∙Helper cook à business dataàpersistencelayeràrelated to DB∙In J2EE app, the session bean as control, and the entity bean as ORM∙There is model between the Servlet && Session bean∙Business Logic layer is consisted of Business process control & Business data access∙Similar to the cook in the restaurant example(how to cook KongPao Chicken, what is the rule/business logic to cook KongPao Chicken? )∙Business logic is used for operations such as funds transfers, product orders, and so forth.∙Business logic is a rule that the business follows in a particular situation.1.2. Differentiate between Session bean and Entity bean?∙In the restaurant example,–the Session Beans is similar to the head cook–the Entity Beans is similar to the helper cook ∙For the business logic layer–We divide the business logic layer into 2 separate layers–the Session Beans represent the business process(control) part of business logic–the Entity Beans represent the business data part of business logic∙helper cook’s time should be occupied as short as possible in order to protect the Refrigerator/DB ∙1.3. Differentiate among Session bean, Entity bean and MDB?∙In both entity beans and session beans,a syn programming model is used. Clients makerequests to the EJB and wait for work to be completed on their behalf.∙MDBs introduce an asyn processing paradigm to enterprise Java applications. Tasks can be queued and made available for processing when resources are available.∙Using MDBs, the EJB is not attached to a client.Instead, it is attached to a message queue or topic.When a message arrives, a method on the EJB is executed.∙Use MDBs when your applicationrequires asyn processing for tasks such as sending email responses or tabulating the winners of this month's lottery.1.4. Differentiate between stateful Session bean and stateless Session bean? differentiate from the code?∙Stateless beans receive requests via RMI?? but do not keep any data associated with the client they are serving internally. //all the bean are same ∙Stateful beans, on the other hand, keep data specific to the client they are serving. //all the bean are not sameCode difference:∙In the stateless programming, no info about the client/invoker is included inside the object.∙Every instance is same∙In the stateful programming, info about the client/invoker is included inside the object.∙Every instance is NOT same∙Entity Bean Components?∙ a home interface,∙remote interface,∙bean class,∙primary key class,∙deployment descriptors.1.5. Differentiate between CMP and BMP entity bean ? differentiate from the code?∙CMP(Container-Managed Persistent) Entity Bean–Container offers defined DB’s Operation, like DB’s read/write.∙BMP(Bean-Managed Persistent) Entity Bean–User defined DB’s Operation, like DB’s read/write.CMP Entity Bean Concept∙Instead of writing cumbersome JDBC code, the CMP bean writer provides only the business logic and deployment descriptors.∙CMP can offer the developer faster development time and better performance than BMP entity beans.∙The CMP entity bean class is abstract. This enables the EJB container to implement persistence logic bygenerating a class that extends the bean class.Pro and Con of CMP∙CMP make the bean code independent from the database mapping. Therefore, more reusable.???∙CMP requires vender’s mapping tools to define how the bean’s fields map to the database.∙Legacy System or complicated join is not easy to map ∙More DB-independent, and more DB schema independentPro and Con of BMP∙BMP has flexibility in manage the persistence.(database, table, join, legacy system)∙BMP requires more work, more understanding of EJB theory.∙BMP is more database dependence, and database schema dependence.第四章1.1. Why is it necessary to use JNDI in the J2EE Application?(What is JNDI?)∙JNDI is the Java standard for the “centralregistry” (catalog) of naming and directory services.(registry & retrieval )∙In the case of WebLogic Server clustering, JNDI is also used as the shared naming service across the entire cluster.∙J2EE components can access a wide variety of resources, including databases, Mail sessions, Java Message Service objects, JAXR connection factories, and URLs, and EJBs.∙The J2EE platform provides mechanisms that allow you to access all these resources in a similar manner. (Conclusion)∙RMI and JNDI are core services offered by the WebLogic Server to enable scalable distributed applications.∙While RMI and JNDI make distributed programming much easier, it is important to understand the many failure cases in networked applications.∙Also noted that: distributed is network-dependent, and also time and resource consuming, it should be avoided if possible.∙Core J2EE services such as EJB and JMS are built ontop of RMI and JNDI.1.2. Why to use the JDBC connection pooling?There are a number of reasons to pool connections to the database:∙Creating a new connection for every individual client that visits your site is very expensive.∙You do not need to hard-code details such as the database management system (DBMS) password in your application. This is particularly beneficial in the case of J2EE services such as JavaServer Pages (JSPs), which typically store the source code with the application .(good for future maintenance) ∙You can change the database system you are using without changing your application code.Databases are most effective when the number of incoming connections is limited. With connection pooling, you can limit the number of connections to your DBMS.1.3. When do you think it is necessary to use JTA? The JTA is similar to the Java Exception Handing in some way?∙JTA–JTA is used when the possible roll back might be happening–In JTA, code that might rollback is put between transaction begin && commit block∙Exception–Exception is used if the possible exception might be happening–In Exception, code that might have exception happening is put between try && catch block1.4. Compare RMI and EJB?∙EJB and its relation with RMI, EJB is built on top of the RMI1.5. Why to use JMS? What is JMS’s relationship with MDB?∙JMS is to asynchronously process the client’s request in order to improve the performance in both client side and server side∙JMS queues messages and can deliver them asynchronously: Messaging need not take place inreal time; and messages can be sent and consumed at different times(Relation)∙In the J2EE app, the msg producer usually originally come from the Servlet, and the asyn consumer usually is a MDB, which is Message Driven Bean.1.6. Compare IMAP and POP3?∙In contrast, IMAP enables users to access their mail from the mail server, but without expectations that they immediately delete those messages. Using IMAP, the user's mail is stored on the mail server and is displayed by an IMAP email client, such as Netscape Communicator or Microsoft Outlook.∙Because IMAP does not store messages on the user's local machine, individuals using IMAP can move from client machine to client machine, with uninterrupted access to new and archived messages.∙POP3 stores mail for the user on the server. The user's mail client connects to the mail server and retrieves messages on behalf of the user.∙In most cases, enterprises using POP3 expect users to download their messages and then delete them from the mail server.1.7. What is JAAS?∙Java authorization & authentication service∙JAAS is a security framework (based on AOP) which the J2EE App server provided to the application component. (compare to Acegi in Spring Framework) ∙With the security framework, the app developer does not have to connect the web layer to the DB backend in order to verify the user’s identification.∙JAAS allow 600 users for each application1.8. Difference between programmatic and declarative security?∙Declarative security is preferred where possible because there is a better separation between the application code and the security constraints.∙Programmatic security is used by security-aware applications when declarative security alone is not sufficient.。
2017年硕士研究生入学考试大纲

2017年硕士研究生入学考试大纲考试科目名称:计算机学科专业基础考试科目代码:895 一、考试要求计算机学科专业基础考试大纲适用于北京工业大学信息学部(0812)计算机科学与技术学科、北京未来网络科技高精尖创新中心(085211)计算机技术(专业学位)的硕士研究生入学考试。
考试内容主要包括两部分:数据结构与C语言程序设计,这两门课程是计算机科学与技术学科的重要基础课程。
数据结构的考试内容主要包括基本数据结构、排序、索引、检索、高级数据结构等内容,从逻辑结构的角度包括线性表、栈、队列、二叉树、树和图等各种基本数据结构;从算法的角度包括各类排序、检索和索引算法。
要求考生对其中的基本概念有很深入的理解,掌握数据结构与算法的基本概念、合理组织数据的基本方法、高效处理数据的基本算法、并具备面对实际问题选择恰当数据结构与相应算法的能力。
C语言程序设计部分的考试内容主要包括C语言程序设计的基础概念、方法和技巧。
要求考生熟练掌握高级语言的基本控制结构、数据组织和程序组织形式。
熟练使用C语言的结构体、指针、文件等。
具有基本的计算思维能力,熟悉简单算法,能够构建实际问题的模块化解决方案。
二、考试内容数据结构部分:1.数据结构的相关概念、算法概念、算法性质及算法分析(时间复杂度与空间复杂度);2.线性表逻辑结构定义、存储结构的表示,以及在特定存储结构下线性表基本运算的算法实现;3.栈与队列的逻辑结构定义、存储结构的表示,基本操作特点,栈与队列的基本应用;4.串的逻辑结构定义,基本操作的含义与实现;5.数组定义及其顺序存储,矩阵的压缩存储,广义表定义及存储结构;6.树的定义与存储结构,二叉树的定义与性质、存储结构,二叉树遍历算法(三序遍历与按层遍历),赫夫曼树与赫夫曼编码以及二叉树基本算法的实现与应用;7.图的定义与术语,图的存储结构,图的遍历(深度优先搜索与广度优先搜索),最小生成树、拓扑排序以及最短路径的求解;8.查找的相关概念,静态查找表(顺序表的查找与有序表的查找),动态查找表(二叉排序树),B-树,A VL树,哈希表的相关概念;9.排序的相关概念,掌握插入排序、冒泡排序、快速排序、简单选择排序、堆排序、归并排序算法的执行过程、时空复杂度、稳定性以及使用场合。
北京邮电大学2017年非全日制硕士专业学位研究生招生简章_北邮考研论坛

北京邮电大学2017年非全日制硕士专业学位研究生招生简章根据《教育部国家发展改革委财政部关于深化研究生教育改革的意见》(教研〔2013〕1号)和《教育部办公厅关于统筹全日制和非全日制研究生管理工作的通知》(教研厅〔2016〕2号)有关要求,2017年在职人员攻读硕士专业学位(双证)招生计划纳入国家硕士生招生计划统筹管理,我校2017年预计招收1085名非全日制硕士专业学位研究生(在职),具体名额以教育部实际下达招生计划为准。
一、报考条件(一)参加全国统考,须符合下列条件:1、中华人民共和国公民。
2、拥护中国共产党的领导,品德良好,遵纪守法。
3、考生的学业水平必须符合下列条件之一:1)国家承认学历的应届本科毕业生(含普通高校、成人高校、普通高校举办的成人高等学历教育应届本科毕业生)及自学考试和网络教育届时可毕业本科生,录取当年9月1日前须取得国家承认的本科毕业证书。
2)具有国家承认的大学本科毕业学历的人员。
3)已获硕士或博士学位的人员。
4)下列两种类型考生须以同等学力身份报考,且符合北京邮电大学根据各专业的培养目标对考生提出的具体业务要求(具体参见《2017年同等学力者报考硕士研究生加试科目及报考条件》)。
(a)获得国家承认的高职高专毕业学历后满2年(从毕业后到录取当年9月1日)或2年以上,达到与大学本科毕业生同等学力者;(b)国家承认学历的本科结业生。
同等学力复试时需以笔试方式加试两门本科阶段主干课程,复试时还需提供以下材料:①进修所报考专业本科阶段课程的成绩单,或通过自学修完所报考专业本科段课程的自我介绍;②两名副教授以上专家的推荐信各一封。
③相关专业报考的附加条件中的相应材料证明。
4、在校研究生报考需征得所在研究生培养单位同意。
5、身体健康状况符合国家和北京邮电大学规定的研究生入学体检标准。
(二)报考工商管理硕士、工程管理、项目管理硕士专业的考生,须符合下列条件:1、符合(一)中第1、2、4、5各项的要求。
北京邮电大学2017年硕士研究生入学考试复试笔试内容
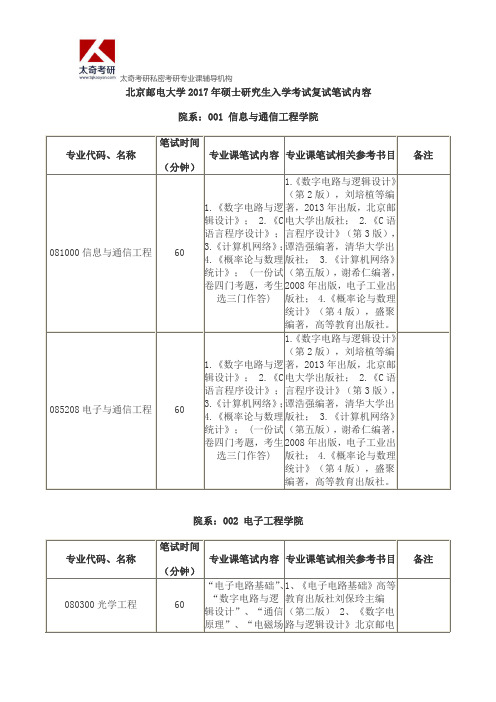
90 究 2.网络传 无
播学
《数字电路与逻 《数字电路与逻辑设计》
辑设计》、《C 语 (第 2 版),刘培植等编
0810Z1★数字媒体技术 60 言程序设计》、《计 著,2013 年出版,北京邮
算机网络》、《概 电大学出版社。《C 语言
率论与数理统计》程序设计》(第 3 版),
备注
太奇考研私密考研专业课辅导机构
60
网络
《计算机网络》第五版,
谢希仁,电子工业出版社
《实用软件工程》郑人杰
软件工程、计算机 等著,清华大学出版社;
60
网络
《计算机网络》第五版,
谢希仁,电子工业出版社
备注
院系:006 数字媒体与设计艺术学院
专业代码、名称
笔试时间 专业课笔试内容 专业课笔试相关参考书目
(分钟)
1.文化研
050300 新闻传播学
080900 电子科学与技术
辑设计”、“通信 周炯槃、庞沁华、续大我、 60
原理”、“电磁场 吴伟陵,北京邮电大学出
理论”、“信号与 版社 4、《电磁场与电磁
系统”五选四 波》,张洪欣, 沈远茂, 韩
宇南著,清华大学出版社
5、《信号与系统引论》郑
君里等,2010 年,高等教
育出版社
1、《电子电路基础》高等
统计》; (一份试 (第五版),谢希仁编著,
卷四门考题,考生 2008 年出版,电子工业出
选三门作答) 版社; 4.《概率论与数理
统计》(第 4 版),盛聚
编著,高等教育出版社。
备注
专业代码、名称 080300 光学工程
院系:002 电子工程学院
笔试时间 专业课笔试内容 专业课笔试相关参考书目
北京邮电大学软件工程答辩须知

北京邮电大学软件工程硕士在京研究生论文答辩须知一、申请答辩流程1. 软件学院工程硕士研究生的学制为2-5年,从修课开始到申请答辩的最短时间为两年。
所学课程应满足软件学院工程硕士培养方案要求。
2. 答辩之前提前半年缴清学费并确认学费缴纳情况,联系电话:,。
3. 答辩之前提前一年选导师。
选导师是双向选择,学生可自行与导师联系,(导师介绍:教学资源--师资队伍)。
下载聘请导师登记表(--快速通道--论文答辩相关文件),填好学生栏、实习企业导师栏、实习单位栏(此三栏不得空白,实习单位栏必须盖章)后,面交或寄给导师,正导师签署意见后,交至软件学院校本部教务办公室(明光楼313室) ,非上班时间(晚11点以前)可放入明光楼313室门旁软件学院信箱,或邮寄中国邮政至:北京市海淀区西土城路10号北京邮电大学软件学院146号信箱XXX(导师姓名)收邮编:100876。
选外院导师的同学应向导师索要邮寄地址寄给导师,正导师签署意见后,交软件学院校本部教务办公室(明光楼313室)。
联系电话:。
4. 论文电子版、开题报告表、阶段报告表、前沿课题报(--快速通道--论文答辩相关文件)告经导师审阅并同意后,打印开题报告表、阶段报告表、前沿课题报告各一份,用A4纸,为便于最终线装装订存档,请在每份左上角横钉一个订书钉即可。
注意开题报告表包括封面4页纸、阶段报告表包括封面3页纸,一定注意不得改变模板表格位置和格式,内容不要超过表格范围;前沿课题报告3000字即可,题目和内容不要与论文题目相同或相近,由导师手签:通过、导师姓名、年月日,学生即可获得一学分。
由导师签好相关栏目后交至软件学院校本部教务办公室。
定稿论文以电子版发给导师,经导师审阅通过后,由导师以电子版发给软件学院教务办公室(Email:)论文文件名称:XXXXXXX(7位学号)北京XXX (姓名)论文200XXXXX(年月日);例如:05R0432北京张三论文20070925.doc。
北京邮电大学软件工程研究生的课程---数据库设计开发-3

–表示层:表示层主要承担人机界面的任务
• 应用系统的性能优化设计是一项系统的工作,三层模型 为系统的开放性扩充和性能优化提供了很大的空间和 灵活性,但单纯的三层结构并不一定是最优的。
客户机在完成某一项任务时,通常要利用 服务器上的共享资源和服务器提供的服务。 在一个客户机/服务器体系结构中可以有多 台客户机、多台服务器。
北京邮电大学软件学院
郭文明 2003.06
《数据库设计与开发》讲义
3.3.2客户机/服务器结构
–软件结构指把一个应用系统按照逻辑功能分 成四个组成部分:用户界面、应用表示逻辑、 事务逻辑、数据管理,按照其相对角色的不 同区分为客户端和服务器端软件。客户软件 能够请求服务器软件的服务。客户软件和服 务器软件可以分布在网络中不同的计算机节 点上,也可以放置在同一台计算机上。
–另一种以服务器为中心,一些重要的应用逻辑放在 服务器上,充分利用服务器的计算能力,通常以存 储过程和触发器出现,减少网络压力,提高系统性 能。 这种方式下,存储程序依赖于特定数据库,不同 数据库间的移植不太容易。
北京邮电大学软件学院
郭文明 2003.06
《数据库设计与开发》讲义
3.3.2客户机/服务器结构
编码协议主要有两种:通信与远程过程调用(Remote Procedure Call,RPC)。通信是指前端应用与DBMS之间的 信息传输采用的报文形式,编码协议有: TABULAR
(Microsoft)、SQL*Net (Oracle)、DRDA(IBM)。远程过程调用 是一种由客户制定而由服务器来执行的函数调用。
北京邮电大学2020年《807软件工程专业综合》考研专业课真题试卷

北京邮电大学2020年硕士研究生招生考试试题考试科目:807软件工程专业综合请考生注意:(1)所有答案(包括选择题和填空题)一律写在答题纸上,否则不计成绩。
(2)允许使用计算器。
(3)本考题包括数据结构,操作系统,数据库三个科目。
其中数据结构为必选。
操作系统与数据库为二选一,考生需选择其中一个科目答题并且注明所选科目的名称。
必选科目数据结构(90分)一、选择题(每小题2分,共20分)1.考虑下面的程序段void running (int n)int j = 0; int k = O;w h ile (j < n) { k = k+ 1; j = j + k;此段代码的时间复杂度为A.O(logn)B.0 (n112)C.0 (n)D.0 (n2)2.设T是高度为h的平衡二叉树(又称A VL树),并且是高度为h的包含节点最少的平衡二叉树,则T包含节点数目的数量级是?A. 1. 41421 hB. 1. 61803hC.2. 71828hD. 3. 14159h3.循环单链表的主要优点是A.不再需要头节点指针B.从表的任一节点出发都能够遍历整个链表C.已知某个节点位置后能够容易找他其前趋D.在进行插入删除操作时能够保证链表不断开4.将n阶对称矩阵A=[a j,k](O<=j, k<n)的上三角元素按行优先压缩存储在数组b[O, N)中,则矩阵元素a j,k(j<=k)在数组中对应的位置是A. b U*n-j* (j—1) /2 + k]B.b U* (j-1) /2 + k]C.b[j*n-j*(j+l)/2 + k-1]D.b[j*(j+l)/2 +k-1]5.对快速排序算法较为不利的情况是A.数据量太大B.数据基本有序C.数据中包含太多的相同键值D.数据量为奇数6.n个节点的二叉树大约有多少个不同的形状?A.3. 14159"B.2"C.2. 71828"D.4"7.在采用线性探测处理冲突的散列表上作查找操作。
北邮考试大纲汇总

801通信原理一、考试要求要求学生熟练把握通信理论的大体概念,把握通信系统的大体工作原理和性能分析方式,具有较强的分析问题和解决问题的能力。
二、考试内容1.预备知识希尔伯特变换、解析信号、频带信号与带通系统、随机信号的功率谱分析、窄带平稳高斯进程。
2.模拟调制DSB-SC、AM、SSB、VSB、FM的大体原理、频谱分析、抗噪声性能分析。
3.数字基带传输数字基带信号,PAM信号的功率谱密度分析;数字基带信号的接收,匹配滤波器,误码率分析;码间干扰的概念,奈奎斯特准那么,升余弦滚降,最正确基带系统,眼图;均衡的大体概念,线路码型的作用和编码规那么,部份响应系统,符号同步的大体概念。
4.数字信号的频带传输信号空间及最正确接收理论,各类数字调制〔包括OOK、2FSK、PSK、2DPSK,QPSK、OQPSK、MASK、MPSK、MQAM〕的大体原理、频谱分析、误码性能分析,载波同步的大体概念。
5.信源及信源编码信息熵、互信息;哈夫曼编码;量化〔量化信噪比、均匀量化〕,A率13折线编码、TDM。
6.信道及信道容量信道模型,信道特性及其对信号传输特性的阻碍;多径衰落方面的概念〔平衰落和频率选择性衰落、时延扩展、相干带宽、多普勒扩展、相干时刻〕;信道容量〔二元无经历对称信道、AWGN信道〕的分析计算;7.信道编码信道编码的大体概念,纠错检错、汉明距离线性分组码,循环码、CRC;卷积码的编码和Viterbi译码;8.扩频通信及多址通信沃尔什码及其性质;m序列的产生及其性质,m序列的自相关特性;扩频通信、扰码三、试卷构造填空题,判定题,计算题,画图题等。
802 电子电路模拟部份一、考试要求要求学生系统地把握模拟电子技术的大体概念、大体电路的工作原理和大体分析方式,并能灵活应用于实际,具有较强的分析问题与解决问题的能力。
二、考试内容一、了解PN结及其特性;把握常常利用二极管、双极型晶体管及场效应管的特性和要紧参数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一部分数据结构(90/150) 一、考试要求 要求考生比较系统地理解数据结构的基本概念和基本理论,掌握各种数据结构的特点和基本方法,着 重考察考生综合运用所学知识分析问题和解决问题的能力。要求考生能够用 C/C++语言描述数据结构中的 算法。 二、考试内容 (一)绪论 数据结构的基本概念,数据的逻辑结构、存储结构; 算法的定义和应具有的特性,算法设计的要求,算法的时间复杂度分析和算法的空间复杂度分析。 (二)线性表 线性结构的特点、线性表的定义,线性表的基本操作; 线性表的顺序存储结构,对其进行检索、插入和删除等操作; 线性表的链式存储结构,单链表、双向链表和循环链表这三种链表形式的存储结构和特点以及基本操 作。 (三)栈和队列,递归算法 栈的定义、结构特点及其存储方式(顺序存储与链接存储)和基本操作的实现算法; 队列的结构、特点及其存储方式(顺序存储与链接存储)和基本操作的实现算法。 递归的基本概念和实现原理以及用递归的思想描述问题和书写算法的方法; 用栈实现递归问题的非递归解法。 (四)数组和串 串的基本概念、串的存储结构和相关的操作算法; 数组的存储结构,在顺序存储的情况下,数组元素与存储单元的对应关系; 稀疏矩阵的存储结构和特点以及基本操作。 字符串匹配算法(例如 KMP 算法)。 (五)树和森林 树的结构和主要概念,各种二叉树的结构及其特点; 二叉树的三种遍历方法的实现原理和性质,能将二叉树的遍历方法应用于求解二叉树的叶子结点个数、 二叉树计数等问题,遍历的非递归实现方法; 线索化二叉树的结构和基本操作; 森林的定义和存储结构,森林的遍历等方法的实现; 基于霍夫曼树生成霍夫曼编码的方法; AVL 树的定义和特点以及 AVL 树调整操作的实现原理; 最优二叉树的构造原理和相关算法。 (六)图 图的各种基本概念和各种存储方式; 图的两种搜索方法和图连的连通性; 两种最小生成树的生成方法; 各种求最短路径的方法; 用顶点表示活动和用边表示活动的两种网络结构特点和相关操作的实现算法。 (七)排序 插入排序法(含折半插入排序法)、选择排序法、泡排序法、快速排序法、堆积排序法、归并排序、基
限期调度和速率单调调度方法。 (八)设备管理和磁盘调度 操作系统中输入/输出功能的组织; 中断处理; 设备驱动程序、设备无关的软件接口和 spooling 技术; 缓冲策略; 磁盘调度算法; 磁盘阵列。 (九)文件系统 文件系统特点与文件组织方式; 文件系统的数据结构; 目录的基本性质及其实现方法; 磁盘空间的管理。 (十)分布式系统 分布式处理的特点、类型; 多层体系结构、中间件技术; 机群系统; 分布式进程管理相关的操作系统设计问题。 三、试卷结构 考试题型:填空题、选择题、简答题、计算题 第三部分数据库系统原理(60/150)(与第二部分二选一) 一、考试要求 要求考生熟悉数据库系统的基本概念、原理和基础理论,熟悉关系数据模型、关系代数、关系系统、 关系数据库设计方法,以及数据库恢复、并发控制、安全性、完整性等数据库系统技术;能够熟练使用 SQL, 具备使用数据库管理系统和设计数据库的能力。 二、考试内容 (一)概论 数据、数据库、数据库管理系统、数据库系统、数据库系统的特点等基本概念的定义、数据管理的三 个阶段; 数据模型:概念模型、关系模型、面向对象等的构造形式及特点; 数据库系统结构:三级结构、两级映像。 (二)关系数据库 关系模型、关系模式、关系数据库等基本概念以及关系代数理论; 能够运用关系代数(并、交、差、除、笛卡尔积、选择、投影、连接)完成关系运算。 (三)SQL 语言 SQL 特点、SQL 标准; 各类 SQL 语句的语法构成、语义与功能,能够运用标准 SQL 完成数据存取; 视图的概念、视图的定义、视图操纵、视图的更新; 存储过程、触发器。 (四)关系存储和查询优化 表的存储、索引结构、聚簇结构; 关系系统分类; 查询优化概念、查询优化方法。
文章来源:和特点; 各种排序算法的时空复杂度的简单分析。 (八)索引结构与散列 线性索引结构、倒排表、静态搜索树的结构和特点; B 树的结构; 散列的实现原理和各种操作的实现算法。 三、试卷结构 考试题型:填空题、选择题、简答题、编程题 第二部分操作系统(60/150)(与第三部分二选一) 一、考试要求 要求考生比较系统地理解和掌握操作系统的基本概念、主要功能、主要组成部分、各个主要组成部分
(五)数据库设计 数据库设计的步骤,以及每个步骤重点关心的问题; 实体联系分析,ER 模型,ER 模型向关系模型转换规则; (六)关系规范化 数据库设计的冗余和异常问题; 函数依赖、多汁依赖、逻辑蕴涵、阿姆斯特朗公理; 基本依赖闭包、候选码; 无损分解,1NF、2NF、3NF、BCNF、4NF 定义与算法。 (七)安全性和完整性 数据库安全性控制的基本技术:用户、角色、权限、授权; 完整性分类和完整性控制方法。 触发器的使用方法。 (八)事务管理 事务的概念、性质,事务的实现; 数据库故障、日志,数据库恢复原理和方法; 并发问题:数据不一致性; 数据锁、封锁粒度、封锁协议, 死锁检测和死锁处理; 三、试卷结构 考试题型:填空题、选择题、简答题、计算题、设计题
的不同实现方法;从资源管理和应用程序与硬件系统接口的观点掌握操作系统设计的基本思想,掌握现代 计算机系统对其各种软硬资源的管理技术。要求考生具备综合运用所学知识分析问题和解决问题的能力。
二、考试内容 (一)基本概念 计算机基本构成、处理器的内部结构、高速缓冲存储器 CACHE; 操作系统的概念、演变历程、特性、分类、运行环境、功能; 存储器的层次结构。 (二)进程 进程的概念和特点; 进程状态转换。 (三)线程、对称多处理 SMP 和微内核 线程的概念,定义线程的必要性和可能性; 线程的功能特性与实现方式; 对称多处理 SMP 体系结构; 操作系统的体系结构(微内核与单内核)及其性能分析。 (四)并发 并发性问题及相关概念,如临界区、互斥、信号量和管程等; 进程互斥、同步和通信的各种算法; 死锁的概念、死锁的原因和条件; 死锁的预防、避免和检测算法。 (五)存储器管理 分区存储管理、覆盖与交换; 页式管理及段式管理; 段、页式存储管理方法及实现技术; 虚存的原理及相关的各种算法和数据结构。 (六)单处理器调度 处理器的三种调度类型; 进程调度的各种算法及其特点。 (七)多处理器调度和实时调度 多处理器对进程调度的影响; 多处理器环境下的进程和线程调度算法; 实时进程的特点;