编解码流程
射频解码433流程

射频解码433流程步骤和流程射频解码433是指通过接收和解码433MHz射频信号,将其转换为可读取的数据。
这种技术广泛应用于无线遥控器、智能家居系统等场景中。
本文将详细描述射频解码433的步骤和流程,确保流程清晰且实用。
1. 硬件准备首先,我们需要准备一些硬件设备来进行射频解码433。
一般需要以下设备:•射频接收器模块:用于接收433MHz射频信号。
•微控制器或单片机:用于控制射频接收器模块和处理解码后的数据。
•电源:为射频接收器模块和微控制器供电。
•连接线和电路板:用于连接各个硬件设备。
2. 硬件连接接下来,我们需要将硬件设备连接起来,以便进行射频解码433的操作。
具体的连接方式取决于所使用的硬件设备,一般需要按照以下步骤进行连接:1.将射频接收器模块的信号引脚连接到微控制器或单片机的输入引脚。
2.将射频接收器模块的电源引脚连接到电源。
3.将微控制器或单片机的电源引脚连接到电源。
4.连接其他必要的引脚,如地线等。
确保连接正确无误后,我们可以开始进行射频解码433的操作。
3. 射频信号接收在进行射频解码433之前,我们首先需要接收到射频信号。
射频信号一般由遥控器等设备发出,包含了一些特定的编码信息。
为了接收射频信号,我们需要进行以下步骤:1.配置射频接收器模块:根据所使用的射频接收器模块的规格和说明,配置接收器的参数,如接收频率、解码方式等。
2.监听射频信号:通过微控制器或单片机的程序,监听射频接收器模块的输入引脚,以判断是否接收到射频信号。
3.接收射频信号:一旦接收到射频信号,将其存储到微控制器或单片机的内存中,以便后续的解码操作。
4. 射频信号解码接收到射频信号后,我们需要对其进行解码,以获取其中的编码信息。
解码的过程一般包括以下步骤:1.数据预处理:对接收到的射频信号进行预处理,如滤波、放大等。
这一步骤可以根据具体的需求进行调整。
2.解码算法选择:根据接收到的射频信号的特点,选择合适的解码算法。
Base64编解码

Base64编解码一、编码原理Base64是一种基于64个可打印字符来表示二进制数据的表示方法。
由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。
三个字节有24个比特,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。
编码后的数据比原来的数据略长,是原来的4/3倍。
它可用来作为电子邮件的传输编码。
在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中而不同(Base64de 编码表如下所示)。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。
包括MIME的email,email via MIME, 在XML中存储复杂数据.Base64编码表二、编码流程步骤1:将要编码的所有字符都转化成对应的ASCII码。
步骤2:将所有的ASCII码转换成对应的8位长的二进制数。
步骤3:将所得的二进制数从高位到低位开始分成6位一组,最后一组不足六的则补充0步骤4:将每组二进制数转换成十进制数,然后对照base64的编码表查找得到相应的编码。
注意:1、要求被编码字符是8bit的,所以须在ASCII编码范围内,\u0000-\u00ff,中文就不行。
2、如果被编码的字符串中字符的个数为3的倍数,按照上面的步骤即可得到正确的base64编码。
但是如果不是3的倍数则要分情况讨论。
如果是3的倍数余1,则要在编好的码字后面加上两个“=”,如果是3的倍数余2,这要在编好的码字后面加上一个“=”。
(例如w的base64编码为dw==,w1的base64编码为dzE=)下面我们来对具体的字符串进行编码举例,以便更好的理解编码流程:编码「Man」在此例中,Base64算法将三个字符编码为4个字符特殊情况A的编码为QQ= =BC的编码为QkM=三、核心算法程序算法的基本原理如下:由于每次转换都需要6个bit,而这6个bit可能都来自一个字节,也可以来自前后相临的两个字节。
JPEG编码解码流程

JPEG图片压缩算法流程详解薛晓利JPEG是Joint Photographic Exports Group的英文缩写,中文称之为联合图像专家小组。
该小组隶属于ISO国际标准化组织,主要负责定制静态数字图像的编码方法,即所谓的JPEG 算法。
JPEG专家组开发了两种基本的压缩算法、两种熵编码方法、四种编码模式。
如下所示:压缩算法:(1)有损的离散余弦变换DCT(Discrete Cosine Transform)(2)无损的预测压缩技术;熵编码方法:(1)Huffman编码;(2)算术编码;编码模式:(1)基于DCT的顺序模式:编码、解码通过一次扫描完成;(2)基于DCT的渐进模式:编码、解码需要多次扫描完成,扫描效果由粗到精,逐级递增;(3)无损模式:基于DPCM,保证解码后完全精确恢复到原图像采样值;(4)层次模式:图像在多个空间分辨率中进行编码,可以根据需要只对低分辨率数据做解码,放弃高分辨率信息;在实际应用中,JPEG图像编码算法使用的大多是离散余弦变换、Huffman编码、顺序编码模式。
这样的方式,被人们称为JPEG的基本系统。
这里介绍的JPEG编码算法的流程,也是针对基本系统而言。
基本系统的JPEG压缩编码算法一共分为11个步骤:颜色模式转换、采样、分块、离散余弦变换(DCT)、Zigzag 扫描排序、量化、DC系数的差分脉冲调制编码、DC系数的中间格式计算、AC系数的游程长度编码、AC系数的中间格式计算、熵编码。
下面,将一一介绍这11个步骤的详细原理和计算过程。
(1)颜色模式转换JPEG采用的是YCrCb颜色空间,而BMP采用的是RGB颜色空间,要想对BMP图片进行压缩,首先需要进行颜色空间的转换。
YCrCb颜色空间中,Y代表亮度,Cr,Cb则代表色度和饱和度(也有人将Cb,Cr两者统称为色度),三者通常以Y,U,V来表示,即用U代表Cb,用V代表Cr。
RGB和YCrCb之间的转换关系如下所示:Y = 0.299R+0.587G+0.114BCb = -0.1687R-0.3313G+0.5B+128Cr = 0.5R=0.418G-0.0813B+128一般来说,C 值(包括Cb Cr) 应该是一个有符号的数字, 但这里通过加上128,使其变为8位的无符号整数,从而方便数据的存储和计算。
bch编译码原理

bch编译码原理BCH编译码原理BCH(Bose-Chaudhuri-Hocquenghem)编码是一种在数据传输和存储中常用的纠错编码技术。
它能够检测和纠正数据传输过程中的错误,提高数据传输的可靠性。
本文将围绕BCH编码的原理展开,介绍其基本概念、编码过程和解码流程。
一、基本概念BCH编码是一种重要的纠错编码技术,其基本原理是通过添加冗余信息来纠正数据传输中的错误。
在BCH编码中,原始数据被分成若干个数据块,每个数据块由数据位和冗余校验位组成。
冗余校验位的数量根据所需的纠错能力而定,通常冗余校验位越多,纠错能力越强。
二、编码过程BCH编码的核心是生成多项式。
在编码过程中,首先需要选择一个生成多项式,该多项式的次数决定了纠错能力。
然后,利用生成多项式将原始数据进行编码。
具体步骤如下:1. 将原始数据块表示为一个多项式,其中每一位的值为多项式的系数。
2. 选择一个生成多项式,将原始数据多项式与生成多项式进行取模运算。
3. 将取模运算的结果作为冗余校验位添加到原始数据多项式的末尾,形成编码后的数据多项式。
三、解码流程BCH编码的解码过程是纠正码字中的错误位以恢复原始数据。
解码过程的关键是计算错误定位多项式和错误值多项式。
具体步骤如下:1. 接收到编码后的数据多项式,并计算接收到的数据多项式与生成多项式的除法结果。
2. 通过除法结果判断是否存在错误位,并计算错误定位多项式。
3. 利用错误定位多项式计算错误值多项式,进而恢复原始数据多项式。
四、应用举例BCH编码在现实生活中有广泛的应用。
例如,在光纤通信中,BCH编码能够提高数据传输的可靠性,减少数据传输错误率。
在存储介质中,如硬盘、光盘等,BCH编码也被广泛应用,保证数据的可靠性和完整性。
总结:BCH编码是一种常用的纠错编码技术,通过添加冗余校验位来纠正数据传输中的错误。
它的编码过程涉及生成多项式的选择和取模运算,解码过程则是通过计算错误定位多项式和错误值多项式来恢复原始数据。
H.264的编解码流程

H.264的编解码流程H.264是在MPEG-4技术的基础之上建⽴起来的,其编解码流程主要包括5个部分:帧间和帧内预测(Estimation)、变换(Transform)和反变换、量化(Quantization)和反量化、环路滤波(Loop Filter)、熵编码(Entropy Coding).1)帧内预测编码帧内编码⽤来缩减图像的空间冗余.为了提⾼H.264帧内编码的效率,在给定帧中充分利⽤相邻宏块的空间相关性,相邻的宏块通常含有相似的属性.因此,在对⼀给定宏块编码时,⾸先可以根据周围的宏块预测(典型的是根据左上⾓的宏块,因为此宏块已经被编码处理),然后对预测值与实际值的差值进⾏编码,这样,相对于直接对该帧编码⽽⾔,可以⼤⼤减⼩码率.2)帧间预测编码帧间预测编码利⽤连续帧中的时间冗余来进⾏运动估计和补偿.H.264的运动补偿⽀持以往的视频编码标准中的⼤部分关键特性,⽽且灵活地添加了更多的功能,除了⽀持P帧、B帧外,H.264还⽀持⼀种新的流间传送帧———SP帧.码流中包含SP帧后,能在有类似内容但有不同码率的码流之间快速切换,同时⽀持随机接⼊和快速回放模式.3)整数变换在变换⽅⾯,H.264使⽤了基于4×4像素块的类似于DCT的变换,但使⽤的是以整数为基础的空间变换,不存在反变换.与浮点运算相⽐,整数DCT变换会引起⼀些额外的误差,但因为DCT变换后的量化也存在量化误差,与之相⽐,整数DCT变换引起的量化误差影响并不⼤.此外,整数DCT变换还具有减少运算量和复杂度,有利于向定点DSP移植的优点.4)量化H.264中可选32种不同的量化步长,这与H.263中有31个量化步长很相似,但是在H.264中,步长是以12.5%的复合率递进的,⽽不是⼀个固定常数.在H.264中,变换系数的读出⽅式也有2种:之字形(Zigzag)扫描和双扫描.⼤多数情况下使⽤简单的之字形扫描;双扫描仅⽤于使⽤较⼩量化级的块内,有助于提⾼编码效率.5)熵编码视频编码处理的最后⼀步就是熵编码,在H.264中采⽤了2种不同的熵编码⽅法:通⽤可变长编码(UVLC)和基于⽂本的⾃适应⼆进制算术编码(CABAC).。
452-通信系统编码流程
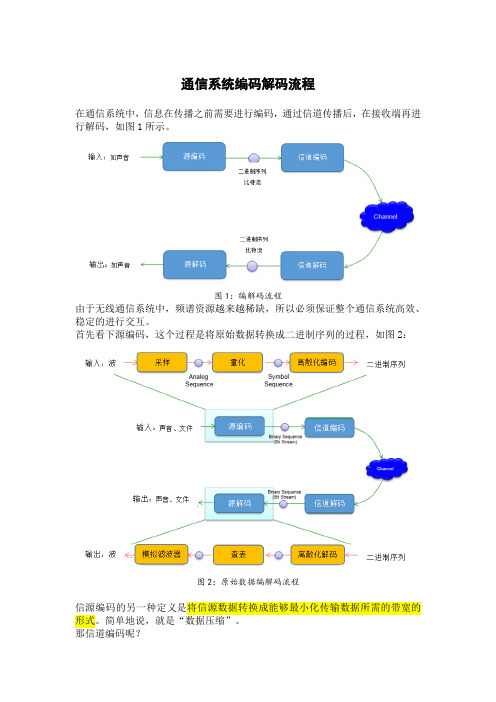
通信系统编码解码流程在通信系统中,信息在传播之前需要进行编码,通过信道传播后,在接收端再进行解码,如图1所示。
图1:编解码流程由于无线通信系统中,频谱资源越来越稀缺,所以必须保证整个通信系统高效、稳定的进行交互。
首先看下源编码,这个过程是将原始数据转换成二进制序列的过程,如图2:图2:原始数据编解码流程信源编码的另一种定义是将信源数据转换成能够最小化传输数据所需的带宽的形式。
简单地说,就是“数据压缩”。
那信道编码呢?信道编码是一种将“原始数据位”替换为“一些其他位(通常比原始位长)”的方法。
例如,最简单的编码如下:0 --> 0000 :将原始数据中的所有“1”替换为“0000‘1 --> 1111 : 将原始数据中的所有“1”替换为“1111‘编码的另一个例子是在通信中添加奇偶校验位,原始七位数据-->原始七位数据+一个奇偶校验位。
在通信系统中,通常把“原始数据”称为“消息(message)”,把编码后的数据称为“码字(Codeword)”。
在所有的编码过程中,“码字”的长度大于“消息”的长度,这意味着在编码过程中,在原始数据(消息)中增加了一些额外的位,这些额外的位被称为“冗余位”。
这不是降低了效率吗?为什么需要编码呢?答案是在“信道”上有“噪声”。
接收端不能准确的接收到正确的原始数据。
为了解决这个问题,可以考虑两种可能的选择。
●使信道无噪音。
(以无噪音的方式建造信道)●使用某种方法检测并纠正错误第一种选择几乎是不可能的,尤其是在无线通信中。
如果是有线通信,至少你可以尝试降低信道中的噪声,但在无线通信中,几乎不可能直接从信道中去除噪声。
这意味着唯一的选择是开发一些方法(算法)来检测和纠正由噪声信道引起的错误。
这是“编码”的主要动机。
图3:计算噪声产生的误码编码的主要思想是以一种非常特殊的方式(不是以随机/任意的方式)向原始数据中添加一些额外的位(称之为冗余位),以便它们可以用来检测错误的确切位置并进行纠正。
解码器流程图 Visuo H.264(JM12.2)

H.264(JM12.2)解码流程理解版本: 1时间:2010.2-2010.3邮件:zjhzchen@主要包括以下两个方面:1.解码标准原理2.JM代码中的解码流程一、H.264解码标准解码器功能框图如下:解码器功能框图详细的解码流程如下:详细的解码流程二、JM12.2的解码主控流程解码总流程帧解码流程(decode one frame)解码一帧的流程读一个片(read_new_slice)解码IDR包括图像的帧号,计算POC,为存储图像分配空间,错误恢复的重设置解码IDR灵活移动宏块的初始化(FmoInit)1. mapUnitToSliceGroupMap变量mapUnitToSliceGroupMap的计算流程2. MbToSliceGroupMap函数NextMbAddress( n )的流程图像序列号的计算(decode_poc)参考帧列表的重排序(reorder_lists)解码一个片(decode_one_slice )为直接预测模式做一些准备工作:获取co_located 图像、计算mv_scale解码一个片熵解码:包括解出宏块类型、预测模式、MVD 、CBP 、残差(包括反量化操作)等反变换及运动补偿:反量化反变换、运动补偿、像素重构等写入各个8*8块的预测模式及运动向量到错误隐藏变量中保存相关的片参数计算宏块,块,像素的坐标;宏块结构语法元素的初始化;相邻块的可用性;以及滤波参数开始一个宏块(start_macroblock)开始一个宏块读一个宏块(read_one_macroblock)// intra frame将亮度块中的16个4*4块的预测模式设置为2(直接预测),运动向量置0宏块(也即P_Skip类型宏块)。
无残MVD。
直接利用预测MV得到像素预=像素预测值从NAL中读取运动矢量信息(readMotionInfoFromNAL)从NAL中读运动矢量信息从NAL中读取CBP以及残差信息(readCBPandCoeffsFromNAL)如果当前宏块不是帧内16*16或者I_PCM类型宏块则从码流中读取CBP从NAL中读取CBP和残差信息解码一个宏块(decode_one_macroblock)解码一个宏块的流程注:此处的解码包括预测信息,残差的反变换以及图像的重建将宏块的预测模式以及运动信息写入错误隐藏变量中(ercWriteMBMODEandMV)将预测模式和运动信息写到错误隐藏变量中退出图像(exit_picture)退出图像图像的去块滤波(DeblockPicture)图像的去块滤波图像的错误检测以及处理图像的错误检测以及处理store_picture到解码缓冲区(store_picture_in_dpb)IDR内存管理(idr_memory_management)IDR内存管理adaptive-内存管理控制(adaptive_memory_management)参考图像的自适应内存控制标记过程分配LongTermFrameIdx给一个短期参考图像插入图像到DPB(insert_picture_in_dpb)插入图像到DPBflush-DPB(flush_dpb)将DPBB.fs的参考标记置为0Flush-DPB。
mpeg1、mpeg2和mpeg4标准对比分析和总结

mpeg1、mpeg2和mpeg4标准对⽐分析和总结mpeg1、mpeg2和mpeg4标准对⽐分析和总结mpeg1、mpeg2和mpeg4标准对⽐0、参考(1).(2).(3).(4).(5).1、编解码流程详细mpeg1,mpeg2和mpeg4的编解码流程可以参考: MPEG-1标准主要采⽤基于插值的运动补偿预测+DCT+量化+VLC熵编码的技术;MPEG-2标准在MPEG-1的基础上增加了Scan过程并且码流语法中增加了多种extension,以⽀持更⾼分辨率和更多码率的编码。
MPEG-4标准主要是⾯向对象的编码以⽀持应⽤的交互性操作。
MPEG-4解码器分成了纹理解码、运动解码、形状解码、⼈脸解码等模块,MPEG-4标准中纹理解码模块,在MPEG-2标准基础上在Quant之后增加了对残差系数进⾏DC/AC预测过程,进⼀步降低编码冗余。
2、编码码流结构编码码流结构可以参考: 从三种标准的码流分层结构可以看出,MPEG-1和MPEG-2的码流结构⾮常相似,唯⼀区别是MPEG-2码流中的Sequence_header后⾯必须紧跟sequence_extension,否则就是MPEG-1的码流。
两者都具有相似的分层结构,从上到下分别包括Sequence、GOP、Picture、Slice、Macroblock和Block,每⼀层开头都包含⼀个header,后⾯紧跟相关数据,每个header的识别都是根据起始码进⾏判断的。
MPEG-4标准是⾯向对象的,因⽽分层结构也是对象相关的,从上到下分别是Visual Object Sequence(VS)、Video Object(VO)、Video Object Layer (VOL)、Group of Video Object Planes (GOV)和 Video Object Plane (VOP),每⼀层开头都包含⼀个header,后⾯紧跟相关数据,每个header的识别都是根据起始码进⾏判断的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录1 编解码流程 (2)1.1 编码流程 (2)1.2 PES、TS结构 (3)PES结构分析(ES打包成PES) (3)TS结构:(PES经复用器打包成TS): (4)2 解码流程 (5)2.1 获取TS中的PAT (5)2.2 获取TS中的PMT (6)2.3 分流过滤 (6)2.4 解码 (7)3 DVB和ATSC制式 (7)3.1 DVB和ATSC的区别 (7)3.2 DVB和ATSC的SI (8)1编解码流程1.1编码流程图1-1ES:原始码流,包含视频、音频或数据的连续码流。
PES:打包生成的基本码流,是将基本的码流ES流根据需要分成长度不等的数据包,并加上包头就形成了打包的基本码流PES流,可以是不连续的。
TS:传输流,是由固定长度为188字节的包组成,含有独立时基的一个或多个节目,适用于误码较多的环境。
PS:节目流.TS流与PS流的区别在于TS流的包结构是固定长度的,而PS 流的包结构是可变长度的。
在信道环境较为恶劣,传输误码较高时,一般采用TS码流;而在信道环境较好,传输误码较低时,一般采用PS码流。
TS码流具有较强的抵抗传输误码的能力。
最后经过64QAM调制及上变频形成射频信号在HFC网中传输,在用户终端经解码恢复模拟音视频信号。
1.2PES、TS结构PES结构分析(ES打包成PES)ES是直接从编码器出来的数据流,可以是编码过的视频数据流,音频数据流,或其他编码数据流的统称。
每个ES都由若干个存取单元(AU)组成,每个AU实际上是编码数据流的显示单元,即相当于解码的1幅视频图像或1个音频帧的取样。
ES流经过PES打包器之后,被转换成PES包。
PES包由包头和payload组成。
打包时,加入显示时间标签(Presentation Time-Stamp,PTS),解码时间标签(Decoding Time-Stamp,DTS)及段内信息类型等标志信息。
PTS表示显示单元出现在系统目标解码器(STD: system target decoder)的时间,DTS表示将存取单元全部字节从STD的ES解码缓存器移走的时刻。
这两个参数是解决视音频同步显示,防止解码器输入缓存上溢或下溢的关键。
TS结构:(PES经复用器打包成TS):复用器把多路单节目或多节目TS流加入PSI/SI及加密信息合合称成1路多节目TS,再给调制器。
TS流也是由一个或多个PES组合而来的,对具有相同时间基准的多个PES现进行节目复用,然后再对相互有独立时间基准的各个PS进行传输复用,最终产生出TS。
TS包由包头和包数据2部分组成,其中包头还可以包括扩展的自适用区。
包头长度占4bytes,自使用区和包数据共占184bytes。
TS包中净荷缩传送的信息主要包括4种类型:(1)视频、音频的PES包以及辅助数据。
(2)描述单路节目信息的节目映射表(PMT)与描述多路节目复用信息的节目关联表(PAT)以及对CA系统所要求的条件访问表(CAT)。
(3)各种业务信息(SI)表,包括强制性的网络信息表,业务描述表,节目断信息表与实践和日期表,还包括可选的业务组表,运行状态表和时间偏移表。
(4)DVB数据广播信息,包括数据通道,异步数据表、同步、被同步数据流、多协议封装、循环数据、循环对象。
2解码流程接收端接收的数据为TS流,TS 流解码过程:2.1获取TS中的PAT在MPEG-2中专门定义了节目特定信息(PSI),其作用是自动设臵和引导接收机进行解码。
PSI是DVB标准体系中的重要组成部分,它对接收机来说,起着处理码流的入口和引导作用。
PSI由四张表构成:节目关联表(PAT)、条件接收表(CAT)、节目映射表(PMT)和网络信息表(NIT)。
其中NIT是保密网络数据,在PSI 中是可选的,在DVB-SI中规定该表的格式。
从PID为0的TS包里,解析出PAT表,然后从PAT表里找到各个节目源的PID,一般此类节目源都由若干个ES流组成,并描述在PMT表里面,然后通过节目源的PID,就可以在PMT表里检索到各个ES的PID。
2.2获取TS中的PMT根据PMT可以知道当前网络中传输的视频(音频)类型,相应的PID,PCR的PID等信息。
2.3分流过滤设臵demux 模块的视频Filter为相应视频的PID和stream type等。
从视频Demux Filter 后得到的TS数据包中的payload 数据就是one piece of PES,在TS header中有一些关于此payload属于哪个PES 的第多少个数据包。
因此软件中应该将此payload中的数据copy到PES的buffer中,用于拼接一个PES包。
拼接好的PES包的包头会有PTS,DTS信息,去掉PES的header 就是ES。
2.4解码直接将被拔掉PES包头的ES包送给decoder就可以进行解码。
解码出来的数据就是一帧一帧的视频数据,这些数据至少应当与PES 中的PTS关联一下,以便进行视音频同步。
3DVB和ATSC制式数字电视尚无统一的国际标准,有美国的ATSC、欧洲的DVB 和日本的ISDB三种不同的标准.3.1DVB和ATSC的区别1).音频压缩DVB标准采纳了MPEG-2的音频压缩算法;ATSC标准则采纳了AC-3的音频压缩算法。
2)服务信息表DVB和ATSC标准分别定义了各自不同的SI结构,采用不同的机制来产生EPG。
电子节目指南(EPG)是数字电视中非常重要的部分,它相当于传统报纸上的节目表。
3)条件接收系统PES级别加扰、加扰算法、事件加扰控制、可臵换安全接口、4)数据广播数据下载协议、数据预告、数据发现、IP协议封装、对DSM-CC 标准的背离3.2DVB和ATSC的SI1)ATSC-SI业务信息(SI)表和MPEG-2的PSI表,都被分成一个或若干SECTION插入到TS包中。
ATSC包含了层次化的表格来描述系统信息和节目指南数据(参考文献[4])。
其中,一个公用的基础PID(Base PID)是所有表格的入口,它被显示定义为0x1FFB,根据Base PID可以在地面广播系统和有线电视系统中定位如下表格。
System Time Table (STT)——包含同步所需的时间信息Master Guide Table (MGT)——包含其它相关表格的大小,PID以及版本号Rating Region Table (RRT)——包含不同地区和国家的节目等级信息Virtual Channel Table (VCT)——包含节目导航和转换的虚拟频道表格The optional Directed Channel Change Table (DCCT)——在特定时间特定环境下要求接受者转换到特定的虚拟频道上去The optional Directed Channel Change Selection Code Table (DCCSCT)——基本种类列表和位臵代码表的扩展事件信息表(Event Information Table, EIT)也是SI系统的一部分,它们的PID定义在MGT之中。
每一个EIT都按照VCT里面所定义的虚拟频道列出电视节目(事件)清单,并按照时间先后从EIT-0到EIT-127排序。
ATSC标准规定,每一个EIT必须有3个小时的时间长度,而且所有EIT的开始时间都被限制在0:00(午夜),3:00,&nbs p; 6:00,9:00,12:00(中午),15:00,18:00和21:00(所有的时间都是UTC制)。
这样,EIT-0代表的就是当前3个小时内的所有电视节目,EIT-1代表的是接下来3个小时的信息,而每隔三个小时,原先的EIT-0就被废弃,之前的EIT-1将取代EIT-0的位臵,依此类推。
另外,ATSC还定义了可选的扩展文字表(Extended Text Table,ETT),ETT包含了有关EIT的相对比较长的文字描述,它们的PID也同样包含在MGT中。
形成电子节目指南(EPG)是SI系统最终目的。
参照图1可以得到如下的EPG构造过程:1. 调频到某个特定的RF频道。
2. 过滤Base PID,从Base PID的TS数据包中构造MGT,TVCT 和STT等。
3. 解析MGT,获取EIT以及相关ETT的PID。
4. 把每个虚拟频道和它相关的TV节目列表联系起来。
5. 调频到另一个RF频道,跳转到第2步。
如果没有其它的频道,则跳转到第6步。
6. 把所有的节目列表以及相关信息显示给用户,捕捉用户的输入指令,并根据指令查找对应的service location descriptor,解码显示用户所选择的电视节目。
2)DVB-SI事件信息表(EIT):ATSC和DVB都有各自的EIT,虽然名字相同,但它们的结构有很大的差别。
另外,ATSC中的每个EIT都只有3个小时的有效期,每隔3个小时,EIT-0会被废弃,后继的EIT会取代前继EIT的位臵(可以采用修改MGT中PID来实现)。
另外,ATSC对EIT的开始时间也有限制。
如果一个节目时间跨越了好几个EIT,那么它必须同时出现在这些EIT之中,而且事件ID必须相同。
而在DVB标准中,就不存在上述限制。
DVB的EPG构造:1. DVB和ATSC结构上的不同,导致了EPG的构造过程的不同。
2. 调频到某个RF频道,基于这个频道解析NIT表,获取当前网络的所有TS流信息。
3. 基于当前频道来解析当前SDT和其它TS流的SDT表,或者扫描当前网络中所有的频道,一一获取SDT信息。
4. 基于当前频道获取当前的EIT和其它TS流的EIT,或者扫描当前网络中所有的频道,一一获取EIT信息。
5. 显示用户节目列表。
当用户转换到某个节目,transport id以及相应的各个PID将从PAT和PMT中解析出来,以便解码。
和DVB相比,ATSC-SI的结构试图在不增加网络带宽的前提下,加速事件的处理。
为了达到这个目的,ATSC采用了固定的PID,单独的MGT来缩短PID解析的时间。