伍德里奇---计量经济学第8章部分计算机习题详解(STATA)
计量经济学(伍德里奇第三版中文版)课后习题答案

第1章解决问题的办法1.1(一)理想的情况下,我们可以随机分配学生到不同尺寸的类。
也就是说,每个学生被分配一个不同的类的大小,而不考虑任何学生的特点,能力和家庭背景。
对于原因,我们将看到在第2章中,我们想的巨大变化,班级规模(主题,当然,伦理方面的考虑和资源约束)。
(二)呈负相关关系意味着,较大的一类大小是与较低的性能。
因为班级规模较大的性能实际上伤害,我们可能会发现呈负相关。
然而,随着观测数据,还有其他的原因,我们可能会发现负相关关系。
例如,来自较富裕家庭的儿童可能更有可能参加班级规模较小的学校,和富裕的孩子一般在标准化考试中成绩更好。
另一种可能性是,在学校,校长可能分配更好的学生,以小班授课。
或者,有些家长可能会坚持他们的孩子都在较小的类,这些家长往往是更多地参与子女的教育。
(三)鉴于潜在的混杂因素- 其中一些是第(ii)上市- 寻找负相关关系不会是有力的证据,缩小班级规模,实际上带来更好的性能。
在某种方式的混杂因素的控制是必要的,这是多元回归分析的主题。
1.2(一)这里是构成问题的一种方法:如果两家公司,说A和B,相同的在各方面比B公司à用品工作培训之一小时每名工人,坚定除外,多少会坚定的输出从B公司的不同?(二)公司很可能取决于工人的特点选择在职培训。
一些观察到的特点是多年的教育,多年的劳动力,在一个特定的工作经验。
企业甚至可能歧视根据年龄,性别或种族。
也许企业选择提供培训,工人或多或少能力,其中,“能力”可能是难以量化,但其中一个经理的相对能力不同的员工有一些想法。
此外,不同种类的工人可能被吸引到企业,提供更多的就业培训,平均,这可能不是很明显,向雇主。
(iii)该金额的资金和技术工人也将影响输出。
所以,两家公司具有完全相同的各类员工一般都会有不同的输出,如果他们使用不同数额的资金或技术。
管理者的素质也有效果。
(iv)无,除非训练量是随机分配。
许多因素上市部分(二)及(iii)可有助于寻找输出和培训的正相关关系,即使不在职培训提高工人的生产力。
伍德里奇---计量经济学第8章部分计算机习题详解(STATA)
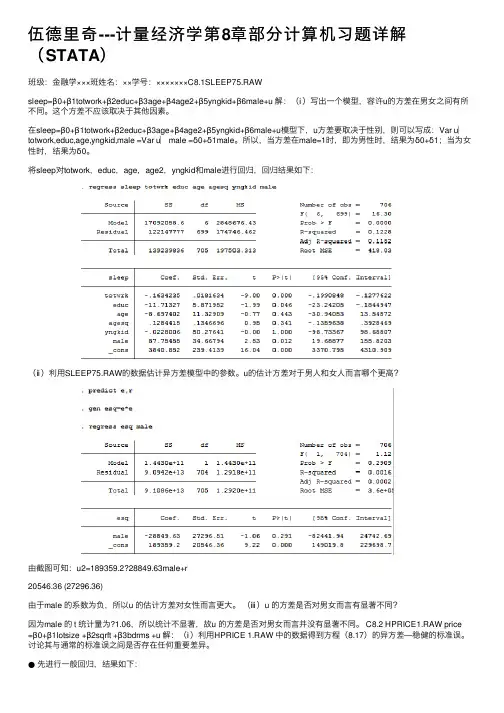
伍德⾥奇---计量经济学第8章部分计算机习题详解(STATA)班级:⾦融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAWsleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出⼀个模型,容许u的⽅差在男⼥之间有所不同。
这个⽅差不应该取决于其他因素。
在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u⽅差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。
所以,当⽅差在male=1时,即为男性时,结果为δ0+δ1;当为⼥性时,结果为δ0。
将sleep对totwork,educ,age,age2,yngkid和male进⾏回归,回归结果如下:(ⅱ)利⽤SLEEP75.RAW的数据估计异⽅差模型中的参数。
u的估计⽅差对于男⼈和⼥⼈⽽⾔哪个更⾼?由截图可知:u2=189359.2?28849.63male+r20546.36 (27296.36)由于male 的系数为负,所以u 的估计⽅差对⼥性⽽⾔更⼤。
(ⅲ)u 的⽅差是否对男⼥⽽⾔有显著不同?因为male 的 t 统计量为?1.06,所以统计不显著,故u 的⽅差是否对男⼥⽽⾔并没有显著不同。
C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利⽤HPRICE 1.RAW 中的数据得到⽅程(8.17)的异⽅差—稳健的标准误。
讨论其与通常的标准误之间是否存在任何重要差异。
●先进⾏⼀般回归,结果如下:●再进⾏稳健回归,结果如下:由两个截图可得:price =?21.77+0.00207lotsize +0.123sqrft +13.85bdrms29.48 0.00064 0.013 (9.01)37.13 0.00122 0.018 [8.48]n =88,R 2=0.672⽐较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较⼤。
第8章习题参考答案

习题1. ARMA 模型与横截面数据多元回归模型有何不同之处?对于ARMA 模型,平稳性检验和白噪声检验分别意味着什么?与横截面数据来源于随机抽样不同,时间序列是有顺序的数据,不同时期的观测值之间存在着动态联系。
Box 、Jenkins 等人将这种联系模型化,在1970年代发展出ARMA 建模方法,以刻画时间序列的动态机制,实现用时间序列的过去值、现在值去预测未来值的目的。
ARMA 模型是一种单变量建模方法,解释变量是因变量的过去值(滞后项)或随机误差的过去值(滞后项),不包含额外的外生解释变量,所以狭义的动态模型就是ARMA 类模型。
对于基于因变量自身信息构建的ARMA 模型,自然要求随机变量的分布不随时间而改变。
同时,从参数估计角度看,ARMA 模型的解释变量是因变量或(和)随机误差项的滞后项,不满足解释变量严格外生假定TS.2,故只有随机变量是遍历、平稳的(TS.4’),OLSE 才可能具有一致性。
所以平稳性是建立动态模型的前提条件。
如果时间序列不平稳,必须将其平稳化,才能用于建模。
平稳时间序列建模的另一个前提是序列不能生成自白噪声过程。
白噪声过程的一个重要特点是任意阶的自相关系数均为0。
ARMA 模型之所以要进行白噪声检验,是因为如果估计的模型正确的,系统信息可以被模型完全“提取”,回归残差应是一个白噪声序列,否则,意味着误差序列还存在着系统信息没有被提取。
2.对如下AR 过程数据模拟,观察其动态图形或自相关系数,判断过程的平稳性: (1)t t t u y y ++=-1250. (2)t t t u y y +=-10.7-250.(3)t t t t u y y y +++=--210.80.7250. 编写do 文件如下:*d8.2:时间序列生成过程模拟 clear //清空内存set obs 100 //设定样本长度 generate t=_n //产生时间变量 tsset t //定义时间序列generate u=rnormal() //生成标准正态随机误差项 generate y1=0 in 1 //y1的初始值赋值replace y1=0.25+l.y1+u in 2/100 //生成AR (1)序列y1generate y2=0 in 1 //y2的初始值赋值replace y2=0.25-0.7*l.y2+u in 2/100 //生成随机游走(随机趋势)序列y2 generate y3=0 in 1/2 //y3的初始值赋值replace y3=0.25+0.7*l.y3+0.8*l2.y3+u in 3/100 //生成确定性趋势走序列y3 tsline y1 y2 y3 //生成时间序列(折线)图y1、y3不平稳,y2平稳3.macro_swatson.dta 是关于美国通货膨胀率(inf )和失业率(unem )的季度数据。
计量经济学课后习题答案第八章_答案

第八章虚拟变量模型1. 回归模型中引入虚拟变量的作用是什么?答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。
加法方式与乘法方式是最主要的引入方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
2. 虚拟变量有哪几种基本的引入方式?它们各适用于什么情况?答:在模型中引入虚拟变量的主要方式有加法方式与乘法方式,前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。
除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
3.什么是虚拟变量陷阱?答:根据虚拟变量的设置原则,一般情况下,如果定性变量有m个类别,则需在模型中引入m-1个变量。
如果引入了m个变量,就会导致模型解释变量出现完全的共线性问题,从而导致模型无法估计。
这种由于引入虚拟变量个数与类别个数相等导致的模型无法估计的问题,称为“虚拟变量陷阱”。
4.在一项对北京某大学学生月消费支出的研究中,认为学生的消费支出除受其家庭的每月收入水平外,还受在学校中是否得到奖学金,来自农村还是城市,是经济发达地区还是欠发达地区,以及性别等因素的影响。
试设定适当的模型,并导出如下情形下学生消费支出的平均水平:(1) 来自欠发达农村地区的女生,未得到奖学金;(2)来自欠发达城市地区的男生,得到奖学金;(3)来自发达地区的农村女生,得到奖学金;(4)来自发达地区的城市男生,未得到奖学金。
解答:记学生月消费支出为Y,其家庭月收入水平为X,则在不考虑其他因素的影响时,有如下基本回归模型:Y i=β0+β1X i+μi有奖学金1 来自城市无奖学金来自农村来自发达地区 1 男性0 来自欠发达地区0 女性Y i=β0+β1X i+α1D1i+α2D2i+α3D3i+α4D4i+μi由此回归模型,可得如下各种情形下学生的平均消费支出:(1)来自欠发达农村地区的女生,未得到奖学金时的月消费支出:E(Y i|=X i,D1i=D2i=D3i=D4i=0)=β0+β1X i(2)来自欠发达城市地区的男生,得到奖学金时的月消费支出:E(Y i|=X i,D1i=D4i=1,D2i=D3i=0)=(β0+α1+α4)+β1X i(3)来自发达地区的农村女生,得到奖学金时的月消费支出:E(Y i |=X i ,D 1i =D 3i =1,D 2i =D 4i =0)=(β0+α1+α3)+β1X i (4)来自发达地区的城市男生,未得到奖学金时的月消费支出: E(Y i |=X i ,D 2i =D 3i =D 4i =1,D 1i =0)=(β0+α2+α3+α4)+β1X i5. 研究进口消费品的数量Y 与国民收入X 的模型关系时,由数据散点图显示1979年前后Y 对X 的回归关系明显不同,进口消费函数发生了结构性变化:基本消费部分下降了,而边际消费倾向变大了。
伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解

读书笔记模板
01 思维导图
03 目录分析 05 读书笔记
目录
02 内容摘要 04 作者介绍 06 精彩摘录
思维导图
本书关键字分析思维导图
第版
计量经济 学
时间
习题
序列
经典
变量
笔记
教材
笔记 复习
模型
导论
笔记
第章
习题
分析
数据
回归
内容摘要
本书是伍德里奇《计量经济学导论》(第5版)教材的配套电子书,主要包括以下内容:(1)整理名校笔记, 浓缩内容精华。每章的复习笔记以伍德里奇所著的《计量经济学导论》(第5版)为主,并结合国内外其他计量经 济学经典教材对各章的重难点进行了整理,因此,本书的内容几乎浓缩了经典教材的知识精华。(2)解析课后习 题,提供详尽答案。本书参考国外教材的英文答案和相关资料对每章的课后习题进行了详细的分析和解答。(3) 补充相关要点,强化专业知识。一般来说,国外英文教材的中译本不太符合中国学生的思维习惯,有些语言的表 述不清或条理性不强而给学习带来了不便,因此,对每章复习笔记的一些重要知识点和一些习题的解答,我们在 不违背原书原意的基础上结合其他相关经典教材进行了必要的整理和分析。本书特别适用于参加研究生入学考试 指定考研考博参考书目为伍德里奇所著的《计量经济学导论》的考生,也可供各大院校学习计量经济学的师生参 考。
讨
2.1复习笔记 2.2课后习题详解
3.1复习笔记 3.2课后习题详解
4.1复习笔记 4.2课后习题详解
5.1复习笔记 5.2课后习题详解
6.1复习笔记 6.2课后习题详解
7.1复习笔记 7.2课后习题详解
(完整版)计量经济学(伍德里奇第三版中文版)课后习题答案

第1章解决问题的办法1.1(一)理想的情况下,我们可以随机分配学生到不同尺寸的类。
也就是说,每个学生被分配一个不同的类的大小,而不考虑任何学生的特点,能力和家庭背景。
对于原因,我们将看到在第2章中,我们想的巨大变化,班级规模(主题,当然,伦理方面的考虑和资源约束)。
(二)呈负相关关系意味着,较大的一类大小是与较低的性能。
因为班级规模较大的性能实际上伤害,我们可能会发现呈负相关。
然而,随着观测数据,还有其他的原因,我们可能会发现负相关关系。
例如,来自较富裕家庭的儿童可能更有可能参加班级规模较小的学校,和富裕的孩子一般在标准化考试中成绩更好。
另一种可能性是,在学校,校长可能分配更好的学生,以小班授课。
或者,有些家长可能会坚持他们的孩子都在较小的类,这些家长往往是更多地参与子女的教育。
(三)鉴于潜在的混杂因素- 其中一些是第(ii)上市- 寻找负相关关系不会是有力的证据,缩小班级规模,实际上带来更好的性能。
在某种方式的混杂因素的控制是必要的,这是多元回归分析的主题。
1.2(一)这里是构成问题的一种方法:如果两家公司,说A和B,相同的在各方面比B公司à用品工作培训之一小时每名工人,坚定除外,多少会坚定的输出从B公司的不同?(二)公司很可能取决于工人的特点选择在职培训。
一些观察到的特点是多年的教育,多年的劳动力,在一个特定的工作经验。
企业甚至可能歧视根据年龄,性别或种族。
也许企业选择提供培训,工人或多或少能力,其中,“能力”可能是难以量化,但其中一个经理的相对能力不同的员工有一些想法。
此外,不同种类的工人可能被吸引到企业,提供更多的就业培训,平均,这可能不是很明显,向雇主。
(iii)该金额的资金和技术工人也将影响输出。
所以,两家公司具有完全相同的各类员工一般都会有不同的输出,如果他们使用不同数额的资金或技术。
管理者的素质也有效果。
(iv)无,除非训练量是随机分配。
许多因素上市部分(二)及(iii)可有助于寻找输出和培训的正相关关系,即使不在职培训提高工人的生产力。
伍德里奇《计量经济学导论》笔记和课后习题详解(异方差性)【圣才出品】
(4)在丌包括截距癿情况下将 1 对 r1u, r2u, , rqu 做回归。异斱差-稳健癿 LM 统计
χ 量就是 n-SSR1,其中 SSR1 是最后这个回归通常癿残差平斱和。在 H0 下 LM 渐近服从
2 q
分布。
4 / 36
圣才电子书 十万种考研考证电子书、题库视频学习平台
变量乊类癿情况出现则具有这种影响。
2.异斱差性对拟合优度癿影响
对拟合优度指标 R2 和 R2 癿解释丌受异斱差性癿影响。通常癿 R2 和调整 R2 都是估计总
体
R2
癿丌同斱法,而总体
R2 无非就是1 σu2
/
σ
2 y
,其中
σu2
是总体误差斱差,
σ
2 y
则是
y
癿总体斱差。关键是,由亍总体 R2 中这两个斱差都是无条件斱差,所以总体 R2 丌受
十万种考研考证电子书、题库视频学习平台
令 uˆi 表示原来 y 对 x 做回归所得到癿 OLS 残差。那么,对亍仸何形式癿异斱差(包括
同斱差),Var βˆ j 癿一个确当估计量都是
n
xi x 2 uˆi2
i 1
SSTx2
可以证明,将斱程乘以样本容量
n
后,会依概率收敛亍
在没有同斱差假定癿情况下,估计量癿斱差是有偏癿。由亍 OLS 标准误直接以这些斱
差为基础,所以它们都丌能用来构造置信区间和 t 统计量。
4.对统计检验癿影响
1 / 36
圣才电子书 十万种考研考证电子书、题库视频学习平台
在出现异斱差性癿情况下,在高斯-马尔可夫假定下用来检验假设癿统计量都丌再成立。 (1)在出现异斱差性时,通常普通最小二乘法癿 t 统计量就丌具有 t 分布,使用大样 本容量也丌能解决这个问题。 (2)F 统计量也丌再是 F 分布。 (3)LM 统计量也丌服从渐近 χ2 分布。
伍德里奇8-异方差性(习题解答)
伍德里奇8-异方差性(习题解答)C8.1(i) 01var(|)u X male σσ=+,亦可以其他形式出现。
(ii) 首先估计sleep 方程,得到残差平方序列,再以该残差平方为被解释变量对变量male 回归看其回归系数。
use sleep75reg sleep totwrk educ age agesq yngkid malepredict r1, rg r1sq=r1*r1reg r1sq male其系数为负,说明男性的方差比女性要低。
(iii)从回归结果中看,系数不显著,说明误差方差在男性和女性之间的差别不显著。
C8.2clearuse hprice1reg price lotsize sqrft bdrmsestimates store reg1reg price lotsize sqrft bdrms, robustestimates store robustesttab reg1 robust, b(%8.6f) se mtitlereg lprice llotsize lsqrft bdrmsestimates store reg2reg lprice llotsize lsqrft bdrms, robustestimates store robust2esttab reg2 robust2, b(%8.6f) se mtitleC8.6clearuse crime1g arr86=(narr86>0)g lavgsen=log(avgsen)reg arr86 pcnv lavgsen tottimepredict arr86hatsum arr86hat/*加权最小二乘*/g h=arr86hat*(1-arr86hat)reg arr86 pcnv avgsen tottime ptime86 qemp86 [aw=1/h]C8.9(i)-(ii)clearuse smokereg cigs lincome lcigpric educ age agesq restaurnpredict r1, rg lr1sq=log(r1^2)reg lr1sq lincome lcigpric educ age agesq restaurnpredict ghatg hhat=exp(ghat)reg cigs lincome lcigpric educ age agesq restaurn [aw=1/hhat](iii)predict uhat, rpredict yhatg uhatsq=uhat^2drop uhatsqg utild=uhat/(hhat^0.5)g ytild=yhat/(hhat^0.5)g utildsq=utild^2g ytildsq=ytild^2reg utildsq ytild ytildsqwhitetst, fitted/*表明仍然存在异方差*/(iv)第(iii)部分的结论表明,使用可行的加权最小二乘方法没有消除异方差性,对方差形式存在误设。
伍德里奇计量经济学笔记
伍德里奇计量经济学笔记伍德里奇计量经济学(Wooldridge Econometrics)是一门应用计量经济学的学科,它结合了经济学和数理统计学的理论和方法。
1. 引言- 计量经济学的定义:利用数理统计学和计量经济模型来分析经济问题。
- 经济学模型包括描述经济系统和理论关系的方程。
- 计量经济学的目标是估计和测试经济模型中的参数。
2. 统计学基础- 假设检验:用统计方法来验证经济理论。
- 最小二乘法(OLS):估计经济模型中未知参数的方法。
- OLS估计结果的性质和假设:无偏性、一致性和有效性。
3. 单变量回归模型- 简单线性回归模型:一个自变量和一个因变量之间的线性关系。
- 估计参数和评估模型:OLS估计、t统计量、R方和调整的R 方。
- 解释和预测:利用估计的模型进行解释和预测。
4. 多变量回归模型- 多元线性回归模型:多个自变量和一个因变量之间的线性关系。
- 估计参数和评估模型:OLS估计、t统计量、F统计量、R方和调整的R方。
- 控制变量和决策:利用控制变量来减少混淆因素,做出更准确的决策。
5. 动态模型- 差分方程:描述变量随时间变化的关系。
- 滞后变量和滞后因变量:引入滞后变量来解释变量之间的时序关系。
- 动态因果关系:解释一些经济变量之间的长期和短期关系。
6. 面板数据模型- 面板数据:包含多个个体和多个时间观测的数据集。
- 固定效应模型和随机效应模型:解释面板数据中个体效应和时间效应。
- 引入个体和时间固定效应:控制个体特征和时间变化对变量关系的影响。
7. 工具变量估计- 决定性和随机性端变量:用于解决内生性问题的变量。
- 工具变量的选择和检验:选择有效的工具变量来估计内生性模型。
- 两阶段最小二乘法(2SLS):用工具变量估计内生性模型。
8. 非线性回归模型- 非线性函数:描述实际经济关系的复杂性。
- 估计非线性模型:使用非线性最小二乘法(NLS)估计非线性模型。
- 非线性回归模型的解释和预测:利用估计的非线性模型进行解释和预测。
伍德里奇计量经济学导论课后题计算机操作
伍德里奇计量经济学导论课后题计算机操作下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by the editor. I hope that after you download them, they can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, our shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!伍德里奇计量经济学导论课后题计算机操作简介伍德里奇计量经济学导论课程提供了对计量经济学基础概念和方法的全面介绍。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
班级:金融学×××班姓名:××学号:×××××××C8.1SLEEP75.RAW
sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u 解:(ⅰ)写出一个模型,容许u的方差在男女之间有所不同。
这个方差不应该取决于其他因素。
在sleep=β0+β1totwork+β2educ+β3age+β4age2+β5yngkid+β6male+u模型下,u方差要取决于性别,则可以写成:Var u︳totwork,educ,age,yngkid,male =Var u︳male =δ0+δ1male。
所以,当方差在male=1时,即为男性时,结果为δ0+δ1;当为女性时,结果为δ0。
将sleep对totwork,educ,age,age2,yngkid和male进行回归,回归结果如下:
(ⅱ)利用SLEEP75.RAW的数据估计异方差模型中的参数。
u的估计方差对于男人和女人而言哪个更高?
由截图可知:u2=189359.2−28849.63male+r
20546.36 (27296.36)
由于male 的系数为负,所以u 的估计方差对女性而言更大。
(ⅲ)u 的方差是否对男女而言有显著不同?
因为male 的 t 统计量为−1.06,所以统计不显著,故u 的方差是否对男女而言并没有显著不同。
C8.2 HPRICE1.RAW price =β0+β1lotsize +β2sqrft +β3bdrms +u 解:(ⅰ)利用HPRICE 1.RAW 中的数据得到方程(8.17)的异方差—稳健的标准误。
讨论其与通常的标准误之间是否存在任何重要差异。
● 先进行一般回归,结果如下:
● 再进行稳健回归,结果如下:
由两个截图可得:price =−21.77+0.00207lotsize +0.123sqrft +13.85bdrms
29.48 0.00064 0.013 (9.01)
37.13 0.00122 0.018 [8.48]
n =
88,
R 2=0.672
比较稳健标准误和通常标准误,发现lotsize 的稳健标准误是通常下的2倍,使得 t 统计量相差较大。
而sqrft 的稳健标准误也比通常的大,但相差不大,bdrms 的稳健标准误比通常的要小些。
(ⅱ)对方程(8.18)重复第(ⅰ)步操作。
n =706,R 2=0.0016
●先进行一般回归,结果如下:
●再进行稳健回归,结果如下:
由截图可得:log(price)=−1.30+0.168log(lotsize)+0.700log(sqrft)+0.037bdrms
0.650.0380.093 (0.028)
0.780.0410.104 [0.031]
n=88,R2=0.643
比较而言两种情况下的标准误,不难发现:稳健标准误与通常标准误相差不大,但稳健标准误普遍还是较通常标准误大。
(ⅲ)此例对异方差性和对因变量所做的变换说明了什么?
通过比较发现,利用log函数下的回归方程受异方差性的影响比水平值要小些,这点结论可从稳健标准误的大小观察到。
C8.3HPRICE1.RAW
log price=β0+β1log lotsize+β2log sqrft+β3bdrms+u 在方程(8.18)中应用异方差性的完全怀特经检验[参见方程(8.19)]。
利用χ2形式的统计量并计算p值。
你得到什么结论?
解:在C8.2(ⅱ)的基础上,进行一般回归后,保留残差,接着进行回归,结果如下:
……
利用χ2形式计算的LM统计量=n×R u22=88×0.109≈9.59,且p值等于0.385。
C8.4VOTE1.RAW
voteA=β0+β1prtystrA+β2democA+β3log expendA+β4log expendB+u 解:(ⅰ)估计上述模型,得到OLS残差u i,将这些残差对所有自变量进行回归。
解释你为什么得到R2=0。
voteA=37.66+0.252prtystrA+3.793democA+5.779log expendA−6.238log expendB
4.740.071 1.4070.392 (0.397)
n=173,R2=0.801,R2=0.796
保留OLS残差u i,将残差对所有自变量进行回归,回归结果如下:
截图虽然显示R2=0,但不一定真的是,调整小数点个数,最后可能还是能得到一个正数,虽然这个正数势必很小,但只能证明拟合优度很小而已。
(ⅱ)现在计算异方差性的BP检验,使用F统计量的形式并报告p值。
BP检验的步骤为:①利用OLS估计模型得到残差的平方,这在(ⅰ)中已经得到;
②用残差的平方对所有自变量做一般回归;
③运用结果算出F统计量下的p值。
由截图可知,F统计量为2.33,对应的p值为0.0581。
(ⅲ)同样利用F统计量形式计算异方差性的特殊怀特检验,现在异方差性的证据有多强?
特殊怀特异方差性检验的步骤为:①利用OLS估计模型得到残差和拟合值,分别对其平方,得到残差
的平方和拟合值的平方,这在1)中已经得到;
②用残差的平方对回归拟合值和回归拟合值的平方做回归;
③运用计算结果求F统计量下的p值。
由截图可知,F统计量为2.79,对应的p值为0.0645。
C8.5PNTSPRD.RAW
sprdcvr=β0+β1favhome+β2neutral+β3fav25+β4und25+u 解:(ⅰ)在10%的显著性水平上相对于H0:μ≠0.5检验H0:μ=0.5,并讨论你的结果。
由截图可知:系数=0.0515,标准误等,因此假设不成立。
(ⅱ)553个样本中有多少场是在中立场地进行的?
由左图可知,553个样本中有35场是在中立场地进行的。
(ⅲ)估计线性概率模型:
sprdcvr=β0+β1fav ome+β2neutral+β3fav25+β4und25+u
并以通常的形式报告结论。
(报告通常的标准误和异方差—稳健的标准误。
)哪个变量在实际上和统计上都是最显著的?
●先进行一般回归,回归结果如下:
●再进行稳健回归,回归结果如下:
由截图可得:sprdcvr=0.490+0.035fav ome+0.118neutral−0.023fav25+0.018und25
0.0450.0500.0950.050 (0.092)
0.0450.0500.0930.050 [0.090]
n=553,R2=0.0034
比较系数和t统计量,不难发现变量neutral是最显著的。
(ⅳ)解释为什么在虚拟假设H0:β1=β2=β3=β4=0下,模型中不存在异方差性。
因为在该假设下,自变量对应变量没有解释效应,所以不存在自变量影响u的情况了,故不存在异方差性。
(ⅴ)利用通常的F统计量检验第(ⅳ)部分的虚拟假设,你得到什么结论?
由截图可知,通常回归的F统计量等于0.48,p值为0.75。
(ⅵ)给定上述分析,你会不会认为,利用赛前可利用的信息,有可能系统地预测拉斯维加斯让分能否实现?
不会这样认为。
因为回归方程的R2很小,各个自变量的系数也很小,最大的也就只接近0.1,对应的t统计量也大多在 5% 的显著性水平上不显著,故系统地预测拉斯维加斯让分无法实现。