高级计算机系统结构第三章
第三章 计算机网络体系结构ppt课件

图1 OSI参考模型
最顶层
最底层
.
应用层 表示层 会话层 传输层 网络层 数据链路层 物理层
(A)
(P) (S) (T) (N)
(DL) (PH)
通信子网
.
OSI中数据流动过程
用户看到的据流向
向实 际 数 据 流
向实 际 数 据 流
实际数据流向
.
2.3 OSI-RM 各层主要功能概述
1、物理层
2.1 网络体系结构及协议概念
2.1.1 网络体系结构的概念
计算机网络体系结构与网络协议是计算机网络技术 中的关键。
计算机网络的实现需要解决很多复杂的技术问题。 例如:①支持多种通信介质;②支持多厂商和异种机互 联,其中包括软件的通信规定及硬件接口的规范;③支 持多种业务,如远程登录、数据库、分布式计算等;④ 支持高级人机接口。
服务数据单元是指(N)实体为完成(N) 服务用户请求的功能所设置的数据单元
.
2.4.3 、服务原语: 在OSI-RM中,上层使用下层的服务,必须通过下
层交换一些命令,这些命令称为服务原语。
请求:用户要求服务做某项工作
服务原语
指示:用户被告知某事件发生了 响应:用户表示对某事件的响应
确认:用户实体收到关于它的请求答复
● 数据链路层协议分为两类:
● 面向字符型的主要特点是利用已定义好的一组 控制字符完成数据链路控制功能。
● 面向比特型的数据链路层,其规程传送信息的单 位称为帧。帧分为控制帧和信息帧。
.
1、数据链路层的功能
传输链路 传输链路是用于传输数据的通信信道,由双绞线、
光纤、 同轴电缆、微波、卫星通信等构成。 信道分为链路与通路两种:
第三章 计算机系统分层结构
PF
CF
奇偶(偶/奇)
进位(是/否)
PE
CY
PO
NC
3.总线
所谓总线是一组能为多个部件分时共享的公共信息传送线路, 它分时接收各部件送来的信息,并发送信息到有关部件。
由于多个部件连接在一组公共总线上,可能会出现多个部件争 用总线,因此需设置总线控制逻辑以解决总线控制权的有关问题。
总线分类:
CPU内部总线用来连接CPU内的各寄存器与ALU ; 系统总线用来连接CPU、主存储器与I/O接口,它通常包括 三组:数据总线、地址总线和控制总线。 按总线传送的方向可将总线分为单向总线和双向总线。
CPU是计算机的核心组成部分
3.1.1
CPU的组成
• 由算术逻辑部件ALU 、控制器、各种寄存器(寄 存器群)和CPU内部总线(连接部件) • 另:Cache
•
1.ALU部件
ALU的功能是实现数据的算术与逻辑运算 两个输入端口,参加运算的两个操作数,通常 来自CPU中的通用寄存器或ALU总线。 控制信号:ADD,SUB,OR,AND等 输出:运算结果
时序控制方式就是指微操作与时序信号之间采取何种关系,
它不仅直接决定时序信号的产生,也影响到控制器及其他部件的组 成,以及指令的执行速度。
1.同步控制方式
同步控制方式是指各项操作由统一的时序信号进行同步控制。 同步控制的基本特征是将操作时间分为若干长度相同的时钟 周期(也称为节拍),要求在一个或几个时钟周期内完成各个微 操作。在CPU内部通常是采用同步控制方式 。 同步控制方式的优点是时序关系简单,结构上易于集中,相应 的设计和实现比较方便。
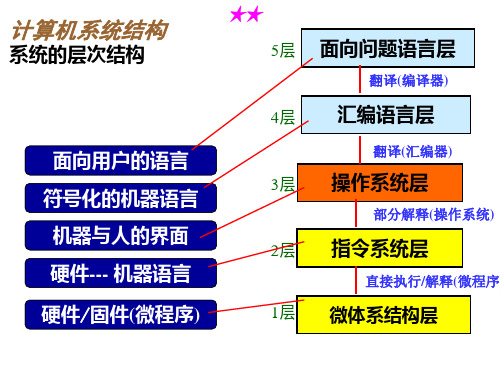
计算机系统结构
系统的层次结构
★★
5层
翻译(编译器)
计算机硬件体系结构

3.2 微型计算机主机结构
1) 计算机指令系统
指令:是指计算机执行特定操作的命令。是程 序设计的最小语言单位。
指令构成:操作码+地址码 指令系统:是指一台计算机所能执行的全部指 令的集合。不同型号的计算机有不同的指令系统。 它反映了计算机的处理能力。
指令
分 类
操作码
操作数
结构
操作码 要完成的操作类型或性质
5.双核心CPU的二级缓存 双核心CPU的二级缓存比较特殊,和以前的单 核心CPU相比,最重要的就是两个内核的缓存所保 存的数据要保持一致。
3.2 微型计算机主机结构
3.2.3 总线 总线:是一组连接各个部件的公共通信线路,是计 算机内部传输指令、数据和各种控制信息的高速通 道,是计算机硬件的一个重要组成部分。 总线按所传输信号不同可分为: 数据总线 地址总线 控制总线。
(1) 掩膜式 ROM(Mask ROM) (2) 可编程 PROM(Programmable ROM) (3) 可擦除 EPROM (Erasable PROM) (4) 电可擦 EEPROM(Electrically EPROM) (5) 快擦写 ROM(Flash ROM)
3.2 微型计算机主机结构
操作数 操作的内容或所在的地址
数据传送指令 数据处理指令 •程序控制指令 输入输出指令 其它指令
内存
CPU
+ - ×÷ And Or……
If Goto……
主机
I/O设备
对计算机的硬件进行管理等
3.5 计算机指令及执行
2 )指令的执行过程
取指令 分析指令 取操作数 执行 回送结果
通常把CPU从内存 并中取出一条指令 并执行这条指令的 时间总和称为指令 周期。
第3章--计算机体系结构

1.则中断级屏蔽位如何设置? 2.假设在用户程序执行过程中同时出现1,2,3, 4四个中断请求,请画出程序运行过程示意图?
第3章作业2
假设系统有4个中断级,则中断响应次序是 1 2 3 4,如果中断处理次序是4 2 3 1
1.则中断级屏蔽位如何设置? 2.假设在用户程序执行过程中同时出现1,2,3, 4四个中断请求,请画出程序运行过程示意图?
0
习题3-5
(1)当中断响应次序为1 2 3 4时,其中断处 理次序是?
(2)如果所有的中断处理都各需3个单位时间,中断 响应和中断返回时间相对中断处理时间少得多。 当机器正在运行用户程序时,同时发生第2、3级 中断请求,过两个单位时间后,又同时发生第1、 4级中断请求,请画出程序运行过程示意图?
中断级屏蔽位的设置
中断 处理 程序 级别 第1级 第2级 第3级 第4级 第5级 中断级屏蔽位
1级 1
0 0 0 0
2级 1
1 0 1 1
3级 1
1 1 1 1
4级 1
0 0 1 0
5级 1
0 0 1 1
具体执行 过程如图:
第3章作业1
假设系统有4个中断级,则中断响应次序是 1 2 3 4,如果中断处理次序是1 4 2 3
中断的响应次序和处理次序
中断的响应次序
中断的响应次序是同时发生多个不同中断类的中断 请求时,中断响应硬件中排队器所决定的响应次序 中断响应的次序是用硬件---排队器---来实现的。
排队器重的次序是由高到低固定死的。
中断处理次序:
中断的处理要由中断处理程序来完成,而中断处理 程序在执行前或执行中是可以被中断的,这样,中 断处理完的次序(简称中断处理次序)就可以不同 于中断响应次序。
计算机网络技术 第三章 计算机网络体系结构及协议

第三章 计算机网络体系结构及协议
3)常见的流量控制方案有:XON/XOFF方案和窗口机制。 ①XON/XOFF方案使用一对控制字符来实现流量控制,当接收方过载时, 可向发送方发送字符XOFF(DC3)暂停,待接收方处理完数据后,再向发送方发送 字符XON(DC1),使之恢复发送数据; ②窗口机制:其本质是在收到一个确定帧之前,对发送方可发送帧的数目加 以限制,这是由发送方调整保留在重发表中的待确认帧来实现的,如接收方来不及 处理,则接收方停止发送确认信息,发送表的重发表就增长,当达到重发表的限度 时,发送方就不再发送新帧直到收到确认信息为止。 发送窗口和接收窗口的大小可以不同,但接收窗口的尺寸不能大于发送窗口, 发送方和接收方的窗口尺寸不得大于信号范围的一半。发送窗口指发送方已发送但 尚未确认的帧序号队列的界,上下界分别称上下沿,上沿、下沿的间距称为窗口尺 寸。发送方每发一帧,待确认帧的数目加1,收到一个确认帧时,待确认帧的数目减 1.当重发表的计数值(待确认帧的数目)等于发送窗口尺寸时,停止发送新帧。 以滑动窗口的观点来统一看待空闲的RQ、Go-Back-N和选择重发,则①空闲 RQ:发送窗口=1,接收窗口=1;②Go-Back-N:发送窗口>1,接收窗口=1;③选择 重发:发送窗口>1,接收窗口>1.
第三章 计算机网络体系结构及协议
七、发送进程发送给接收进程中的数据, 实际上是经过发送方各层从上到下传送 到物理媒体,通过物理媒体传输到接收 方后,再经过从下到上各层的传递,最 后到达接收进程。
第三章 计算机网络体系结构及协议
八、物理层的传输单位是比特,它是指 在物理媒体之上为数据链路层提供一个 原始比特流的物理连接,它不是指具体 的物理设备,也不是指信号传输的物理 媒体,物理层的1建议是于1976年制定的DTE 如何与数字化的DCE交换信号的数字接 口标准。机械特性:采用15芯标准连接 器,定义了八条接口线;电气特性:类 似于RS-422的平衡接口;功能特性:按 同步传输的全双工或半双工方式运行。
吉林大学计算机系统结构题库第三章

第三章流水线技术知识点汇总先行控制、流水线、单功能流水线、多功能流水线、静态流水线、动态流水线、部件级流水线、处理机级流水线、处理机间流水线、线性流水线、非线性流水线、顺序流水线、乱序流水线、时空图、流水线性能评价(吞吐率、加速比、效率)、解决流水线瓶颈问题方法、相关(数据相关、名相关、控制相关)、换名技术、流水线冲突(结构冲突、数据冲突、控制冲突)、流水线互锁机制、定向技术、指令调度、预测分支失败、预测分支成功、延迟分支(从前调度、从失败处调度、从成功处调度)、流水寄存器、3种向量处理方式(横向、纵向、纵横)、链接技术。
简答题1.流水技术有哪些特点?(答出4个即可)(知识点:流水线)答:1.将处理过程分解为若干子过程,由专门的功能部件来实现,2各段的时间尽可能相等,3各部件间都有一个缓冲寄存器,4适用于大量重复的时序过程,5需要通过时间和排空时间。
2.什么是静态流水线?什么是动态流水线?(知识点:静态流水线、动态流水线)答:同一时间段内,多功能流水线中的各段只能按同一种功能的连接方式工作;同一时间段内,多功能流水线中的各段可以按照不同的方式连接同时执行多种功能。
3.什么是单功能流水线?什么是多功能流水线?(知识点:单功能流水线、多功能流水线)答:只能完成一种固定功能的流水线。
流水线的各段可以进行不同的连接,以实现不同的功能。
4.什么是线性流水线?什么是非线性流水线?(知识点:线性流水线、非线性流水线)答:流水线的各段串行连接,没有反馈回路。
流水线中除了有串行的连接外,还有反馈回路。
5.列举3种相关。
(知识点:相关)答:数据相关,名相关,控制相关。
6.流水线中有哪三种冲突?各是什么原因造成的?(知识点:流水线冲突)答:结构冲突,硬件资源满足不了指令重叠执行的要求;数据冲突,指令在流水线中重叠执行时需要用到前面指令的执行结果;控制冲突,流水线遇到分支指令和其他会改变PC值的指令。
7.选择至少2种解决流水线结构冲突的方法简述。
计算机体系结构精选ppt
• 于是,计算机又被看成是由主机和外设两 大部分组成。但无论怎样划分,计算机的5大 部件始终是相对独立的子系统,缺一不可。
3.1.2 计算机硬件的典型结构
• 计算机系统的硬件结构包括各种形式的总线结构和通 道结构,它们是各种大、中、小、微型计算机的典型 结构体系。
第三章 计算机体系结构
• 硬件和软件是学习计算机知识经常遇到的术语。 硬件是指计算机系统中实际设备的总称。它可
以是电子的、电的、磁的、机械的、光的元件
或设备,或由它们组成的计算机部件或整个计 算机硬件系统。
• 计算机系统包括大型机、中小型机以及微机等 多种结构形式,其硬件主要包括: 运算器、控 制器、存储器、输入设备和输出设备等部件。
息的通路叫输入/输出总线(I/O总线),各种I/O设备通过
I/O接口连接在I/O总线上。
这种结构的优点是控
制线路简单,对I/O
总线的传输速率相对
地可降低一些要求。
缺点是I/O设备与主
存储器之间交换信息
一律要经过CPU,将
耗费CPU大量时间,
降低了CPU的工作效
率。
3.小型机的总线型结构
(3)以存储器为中心的双总线结构
备之间均可以通过系统总线交换信息。
备与主存储器交换信息时,
CPU还可以继续处理默认的不
需要访问主存储器或I/O设备
的工作。缺点是同一时刻只允
许连接到单总线上的某一对设
备之间相互传递信息,限制了
信息传送的吞吐量(或称速率)。
此外,单总线控制逻辑比专用
的存储总线控制逻辑更为复杂,
计算机系统结构
加速比可以表示如下:
Ws + G(n)Wp S = * = * Ws +Wp / n Ws + G(n)Wp / n
* n * s * p
W +W
其中:
在单个处理机上顺序执行的工作负载与问题的规模 或系统的规模无关,即:
Ws = Ws' = W
* s
而G(n)反映的是存储容量增加n倍时并行工作负载增 加的倍数。
增大问题规模的办法使所有处理机保持忙碌状态,在问题扩大到 与可用的计算能力匹配时,程序中的顺序部分就不再是瓶颈了。 当处理器数目n=1024,加速比Sn随α变化的情况如下:
S1024' = n −α(n −1 =1024 −1023 ) α
Sn’
1100
1050
1024
1000
1014 1004
993 983
W +W s p Sn = W +W / n s p
设串行因子α为串行部分所占的比例。即
W s W p α= 或 −α = 1 W +W s p W +W s p
代入即得Amdahl’law:
W +W s p 1 W +W s p ∴Sn = = W s W /n p α + (1−α) / n + W +W s p W +W s p
2.1.3 三种加速比性能模型
1.固定负载加速比性能模型—Amdahl定律
在许多实时应用领域,计算负载的大小常固 定。在并行机中,此负载可分布至多台并行执行, 获得的加速比称为fixed-load speedup。一个问题的 负载可表示如下: W = Ws + Wp 其中,Ws代表问题中不可并行化的串行部分负载, Wp表示可并行化的部分负载。 则n个节点情况下,加速比可以表示如下:
第三章_计算机网络体系结构要点
源进程传送消息到目 标进程的过程: 消息送到源系统的 最高层; 从最高层开始,自 上而下逐层封装; 经物理线路传输到 目标系统; 目标系统将收到的 信息自下而上逐层 处理并拆封; 由最高层将消息提 交给目标进程。
源进程 消息
逻辑通信
目标进程 消息
N+1 N N-1
Pn+1
Pn Pn-1
第三章 计算机网络体系结构
本章学习要点:
网络体系结构与协议的概念
OSI参考模型
TCP/IP参考模型 OSI与TCP/IP两种模型的比较
3.1 网络体系结构与协议的概念
3.1.1 什么是网络体系结构
计算机网络体系结构是指整个网络系统的 逻辑组成和功能分配,它定义和描述了一 组用于计算机及其通信设施之间互连的标 准和规范的集合。 也就是说:为了完成计算机间的通信合作, 把计算机互连的功能划分成有明确定义的 层次,规定了同层次实体通信的协议及相 邻层之间的接口服务。网络体系结构就是 这些同层次实体通信的协议及相邻层接口 的统称,即层和协议的集合。
3.1.2 什么是网络协议 从最根本的角度上讲,协议就是规则。 网络协议,就是为进行网络中的数据交 换而建立的规则、标准或约定。连网的 计算机以及网络设备之间要进行数据与 控制信息的成功传递就必须共同遵守网 络协议。
网络协议主要由以下三要素组成: 语法 语法是以二进制形式表示的命令和相应的结 构,确定协议元素的格式(规定数据与控制 信息的结构和格式)如何讲 语义 语义是由发出请求、完成的动作和返回的响 应组成的集合,确定协议元素的类型,即规 定通信双方要发出何种控制信息、完成何种 动作以及做出何种应答 。讲什么 交换规则 交换规则规定事件实现顺序的详细说明,即 确定通信状态的变化和过程, 。应答关系
计算机系统结构-第三章(习题解答)
计算机系统结构-第三章(习题解答)1. 什么是存储系统?对于一个由两个存储器M 1和M 2构成的存储系统,假设M1的命中率为h ,两个存储器的存储容量分别为s 1和s 2,存取时间分别为t 1和t 2,每千字节的成本分别为c 1和c 2。
⑴ 在什么条件下,整个存储系统的每千字节平均成本会接近于c 2? ⑵ 该存储系统的等效存取时间t a 是多少?⑶ 假设两层存储器的速度比r=t 2/t 1,并令e=t 1/t a 为存储系统的访问效率。
试以r 和命中率h 来表示访问效率e 。
⑷ 如果r=100,为使访问效率e>0.95,要求命中率h 是多少?⑸ 对于⑷中的命中率实际上很难达到,假设实际的命中率只能达到0.96。
现在采用一种缓冲技术来解决这个问题。
当访问M 1不命中时,把包括被访问数据在内的一个数据块都从M 2取到M 1中,并假设被取到M 1中的每个数据平均可以被重复访问5次。
请设计缓冲深度(即每次从M 2取到M 1中的数据块的大小)。
答:⑴ 整个存储系统的每千字节平均成本为:12s 1s 2c 2s 1s 1c 2s 1s 2s 2c 1s 1c c ++⨯=+⨯+⨯=不难看出:当s1/s2非常小的时候,上式的值约等于c2。
即:s2>>s1时,整个存储器系统的每千字节平均成本会接近于c2。
⑵ 存储系统的等效存取时间t a 为:2t )h 1(1t h t a ⨯-+⨯=⑶r)h 1(h 1t )h 1(t h t t t e 211a 1⨯-+=⨯-+⨯==⑷ 将数值代入上式可以算得:h>99.95% ⑸通过缓冲的方法,我们需要将命中率从0.96提高到0.9995。
假设对存储器的访问次数为5,缓冲块的大小为m 。
那么,不命中率减小到原来的1/5m ,列出等式有:m596.0119995.0--= 解这个方程得:m=16,即要达到⑷中的访问效率,缓冲的深度应该至少是16(个数据单位)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
17
4) Utilization
It is the ratio of the achieved speed to the peak speed of a given computer A sequential application executing on a single MPP processor has a utilization ranging from 5%-40%, typical 8%-35% A parallel application executing on multiple processors has a utilization ranging from 1%35%, typical 4%-20% Some benchmark can reach higher utilization, for example : ASCI White Pacific IBM SP POWER3(375MHz) U = 7.226/12.3 = 58.7 %, NEC Earth Simulator can reach U = 35.8/40.96 = 87.4%
4
(2) According to macro or micro:
– Macro benchmark → measure the performance as a whole – Micro benchmark → measure the performance from a specific aspect, such as, CPU speed, memory access time, I/O speed, OS performance , networking
5
§3.1.1 Micro Benchmarks
Name LINPARK (Top 500) LMBENCH STREAM Measuring Numerical computing (Linear algebra) System calls and data movement operations in Unix Memory bandwidth
11
SPEC89 SPEC92 SPEC95: (CPU-intensive applications)
– SPEC95 CPU benchmarks are most famous SPEC benchmarks widely used by vendors and users – they measure the CPU speed, the cache/memory system, and the compiler as a whole
Chapter 3. Performance Metrics and Benchmarks
§3.1 System and Application
Benchmarks
1.Definition of Benchmark: A benchmark is a performance testing program that supposedly captures processing and data movement characteristics of a class of applications
2
A benchmark suite = A set of benchmark programs + a set of specific rules governing the test conditions and procedures, including the
– – – – tested platform environment, the input data, the output results, and the performance metrics
9
§3.1.3 Business and TPC Benchmarks
TPC - Transaction Processing Performance Council The most popular benchmark for commercial applications is TPC-C Benchmark
3. Classification of benchmarks
(1)According to application classes – scientific computing – commercial applications – network services – multimedia applications – signal processing
14
1) Execution Time
To run the user’s application on the target machine and measure the wall clock time elapsed. But this approach is sometimes difficult to apply Execution time is critical to some applications, such as in a real-time application Execution time alone does not give much clue to a true performance of the machine
Rmax (Tflops) Rpeak (Tflops)
35.8 40.96
Nmax
1075200
Country
Japan
2
8192
13.88
20.48
633000
USA
3
2304
7.634
11.06
3ห้องสมุดไป่ตู้0000
USA
4
8192
7.304
12.288
518096
USA
4‘
8192 512 (Xeon 2GHz)
16
3) System Throughout
Throughput is defined to be the number of jobs processed in a unit time The throughput is usually used when multiple jobs are executed simultaneously.
20
§3.3 Basic Performance Metrics
Workload Metrics
– Execution time : depending on algorithm , data structure, input data, platform, and language – Instruction count : depending on input data, platform (RISC, CISC), compiler – Floating -point count : normally it is independent
6
Nov. 2006 Top500
7
2003, June,1st four of Top 500
Ran k 1 Computer NEC Earth-Simulator HP SC ES 45 MCR Linux Cluster Xeon 2.4GHz IBM ASCI White SP Power3 神州 IV Alpha 800MHz 联想 深腾1800 深腾 Number of processor 5120
10
§3.1.4 SPEC Benchmark Family
SPEC(Standard Performance Evaluation Corporation) emphasizes developing real applications benchmarks that closely reflect the actual workload SPEC defines a few (2 in many cases) metrics that measure the overall performance of entire system
12
– 8 integer programs → SPECint95 – 10 floating-point programs → SPECfp95 – All SPEC95 results are expressed as ratios compared to a Sun SPARC station 10/40, the reference machine
N.A
13.107
N.A
China
52
1.046
2.048
153600
China
8
§3.1.2 Parallel Computing Benchmarks
1.The NBP Suite - NAS parallel benchmarks 2.The PARKBENCH - PARallel Kernels and BENCHmarks) 3.The Parallel STAP Suite - The Space-Time Adaptive Processing
19
6) Performance/cost
It is defined as the ratio of the speed to the purchasing price Gflop/s per $M Should use sustained performance/cost, not peak performance/cost
Performance : how to measure 1) Execution Time 2) Processing Speed 3) System Throughput 4) Utilization 5) Cost-effectiveness 6) Performance/cost • These performance requirements could lead to quite different conclusions for the same application on the same computer platform