社会统计学公式总结及要点
统计学公式汇总

统计学公式汇总统计学是研究数据收集、分析、解释和预测的一门学科。
在统计学中,有许多重要的公式被广泛应用于数据的处理和分析过程中。
本文将汇总一些常见的统计学公式,并简要介绍其应用场景和使用方法。
1. 均值(Mean)均值是统计学中最常用的概念之一,用于衡量一组数据的集中趋势。
对于一个样本集合,均值可以通过将所有观测值相加,然后除以样本容量来计算。
其数学公式如下:均值= ∑(观测值) / 样本容量2. 方差(Variance)方差是用于衡量一组数据的离散程度的指标。
方差越大,表示数据的离散程度越高;方差越小,表示数据的离散程度越低。
方差的计算公式如下:方差= ∑((观测值-均值)^2) / 样本容量3. 标准差(Standard Deviation)标准差是方差的平方根,用于衡量数据的离散程度,并且具有和原始数据相同的单位。
标准差的计算公式如下:标准差 = 方差的平方根4. 相关系数(Correlation Coefficient)相关系数用于衡量两组变量之间的线性关系强度和方向。
相关系数的取值范围在-1到1之间,其中-1表示完全的负相关,1表示完全的正相关,0表示无相关。
相关系数的计算公式如下:r = Cov(X,Y) / (σX * σY)5. 回归方程(Regression Equation)回归方程用于建立一个或多个自变量与因变量之间的线性关系。
回归方程的一般形式为:Y = β0 + β1X1 + β2X2 + ... + βnXn + ε其中,Y表示因变量,X1、X2、...、Xn表示自变量,β0、β1、β2、...、βn表示回归系数,ε表示模型的误差项。
6. 样本容量和置信水平(Sample Size and Confidence Level)在统计学中,样本容量和置信水平是决定实验或调查结果可靠性的重要因素。
样本容量是指从总体中抽取的样本大小,而置信水平是指对总体参数的估计值的信任程度。
社会统计学重点知识梳理

《社会统计学》重点知识梳理第一章绪论[教学目的]:本章是对社会统计学这门课程对概要性介绍。
通过本章对学习,首先使学生熟悉到学习这门课程对重要意义和作用,激发其学习对踊跃性和主动性。
其次使学生对该课程有一个大体对了解,并掌握其中的一些基础性的知识,为后面对学习打下基础。
[教学重点]:变量及变量层次[教学难点]:统计和统计学对含义[教学方法和手段]:讲授法[学时分配]:4学时[教学内容]:统计和统计学的含义,统计学的产生和发展,变量及变量层次第一节统计和统计学的含义一统计的含义统计作为一种社会实践活动已有悠长的历史。
在外语中,统计一词与国家一词来自同一词源。
因此,可以说,自从有了国家就有了统计实践活动。
最初,统计只是为统治者管理国家对需要而搜集资料,弄清国家对人力、物力、财力,作为国家管理的依据。
(如早在古代奴隶制的国家,由于赋税、徭役、征兵对需要,就开始了人口、土地等的记录和简单的统计工作。
今天,统计一词已被人们赋予多种含义,在不同场合,其可以具有不同含义。
一般来说,统计一词包括以下三种含义:一指统计工作,即调查研究,包括资料的收集、整理和分析;二指统计资料,包括统计数据和分析报告;三指统计学这门学科,研究如何搜集、整理和分析数据资料。
其中,前两种含义统计工作和统计资料指的是统计的实践活动,统计学则指理论研究。
二统计学的含义一、概念统计学是一门收集、整理和分析统计数据的方法科学,其目的是探索数据的内在规律性,以达到对客观事物的科学认识。
统计数据的收集是取得统计数据的过程,它是进行统计分析对基础。
离开了统计数据,统计方法就失去了用武之地。
如何取得所需的统计数据是统计学研究的内容之一。
统计数据的整理是对统计数据的加工处理过程,目的是使统计数据系统化、条理化,符合统计分析的需要。
数据整理是介于数据收集与数据分析之间的一个必要环节。
统计数据的分析是统计学的核心内容,它是通过统计描述和统计推断的方法探索数据内在规律对过程。
社会统计学常用公式及说明
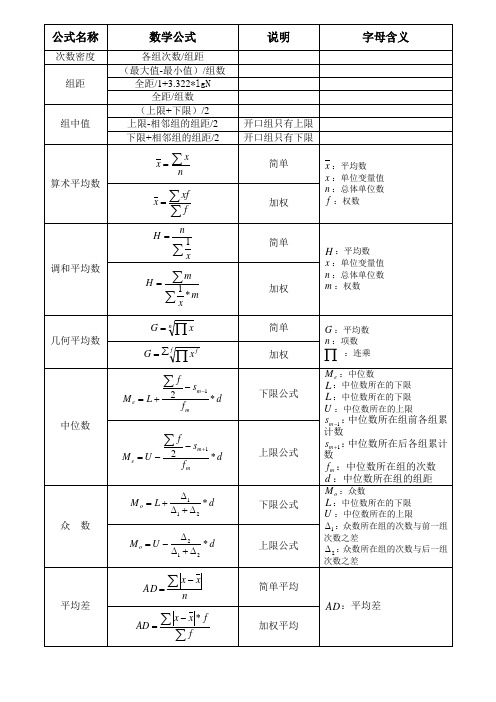
b
b
i 1
n
i
n
yn y0
平均发展速度-1
回归方程
公式名称
数学公式
yt a bt (方程式)
说明
说明
当 t 0 时:
b
N tY t Y N t 2 ( t ) 2
Y b t N
直线回归
b
N tY t Y N t 2 ( t ) 2
H
调和平均数
H
x
1
简单
H :平均数
m 1 x *m
x x
f
加权
x :单位变量值 n :总体单位数 m :权数
Gn
简单 加权
G :平均数
几何平均数
f G
n :项数
:连乘
f
Me L 2
sm 1 fm
*d
下限公式
中位数
Me U
f
2
sm 1 fm
*d
上限公式
环比
Ai
增长速度
Bi
yi y0 (i 1,2,....n) y0
yi yi 1 (i 1,2,....n) yi 1
n
定基
环比
环比发展速度-1 1、等 于 各 环 比 发 展 速度连乘开 n 次方 根 2、等于 n 次方根下报 告期水平 / 基期水 平
平均发展 速度 平均增长 速度
a
a
Y
N
回归方程
a
yt a bt ct 2 (方程式)
t Y t t Y N t ( t )
4 2 2 4 2 2
b
社会统计学公式总结LIJUN

社会统计学考试必备公式
学院:人文学院
姓名:李军
学号:2011014737
专业:社会学
班级:社会111
时间:2013年6月20日
社会统计学考试必备公式
第二章单变量统计描述分析
直方图:频次密度=频次/组距(条宽)
相对频次密度(频率密度)=相对频次(频率)/组距(条宽)
频次=频率密度*组距
A、集中趋势测量法
众值:m0
B、离散趋势测量法
极值R:观察的最大值-观察的最小值
四分互差Q=Q75-Q25
第三章概率
一、概率的运算
1.当事件A与事件B互不相容时,
P(A+B)=P(A)+P(B)
2. 当事件A与事件B不满足互不相容时,
P(A+B)=P(A)+P(B)-P(AB)
3.A、B相互独立
P(AB)=P(A)P(B)
4. A、B不相互独立
P(AB)=P(A)P(B/A)或P(B)(A/B)
第五章正态分布
第六章参数估计
第七章假设检验的基本概念
1.统计假设
2.原假设与备择假设
3.假设检验的基本原理
4.双边检验与单边检验
第十四章非参数检验。
社会统计学重点

1.社会调查研究的步骤:1.确定课题。
2.了解情况。
3.建立假设。
4.确定概念和测量方法。
5.涉及问卷。
6.试填问卷。
7.调查实施。
8.校核与登录。
9.统计分析与命题的检验。
资料的整理归纳分析以及如何收集资料正是统计分析所要谈论的内容。
2.社会调查资料的特点:随机性和统计规律性。
3.怎样选用统计分析方法:1.全面调查和非全面调查。
2.单变量和多变量。
3.变量层次.4.分布概念:指一个概念或变量,它的各个情况出现的次数或频次,又称频次分布。
表现形式:数对的集合.5.变量取值的要求—⑴变量取值必须完备;⑵变量取值必须互斥。
6.统计表:是用表格形式来标识前面所说变量的分布。
它不需要文字表达,就能反响出资料的特性以及资料之间的关系,在编印,传递方面有很大优点,比统计表更精确,但不及统计图直观。
7.统计表必须具备的内容:1.表号。
2.表头。
3.标识行。
4.主体行。
5.表尾。
8.根据变量的层次,可以选择以下不同的统计图形:定类变量:圆瓣图、条形图。
定序变量:条形图。
定距变量:直方图、折线图。
9.圆瓣图:是将资料展示在一个圆的平面上,通常用圆形代表现象的总体,用圆瓣代表现象中一种情况,其大小代表变量取值在总体中所占的百分数。
10.条形图:是用长条的高度来表示资料类别的次数或百分数。
定类:离散。
定序:离散或紧挨着的。
11.直方图:直方图从图形来看,也是紧挨着的长条形所组成,它与条形图不同,宽度有意义,一般来说,直方图是以长条的面积来表示频次或相对频次,而条形的长度。
即纵轴高度表示是频次密度或相对频次密度。
频次密度=频次/组距。
12.折线图:如果用直线连接直方图中条形顶端的中点,就是折线图。
折线图可使资料的频次分布趋势更一目了然。
13.累计图和累计表:表示的是大于某个变量值的频次是多少或小于某个变量值的频次是多少。
14.众值:就是用具有频数最多的变量值来表示变量的集中值。
15.中位值:是数据序列之中央位置之变量值。
电大社会统计学

一、基本概念1、众数众数是一组数据中出现频数最多的数值,用Mo表示。
例如,一个城市有多种产业,但如果以旅游业为最多,那么旅游业就是众数,这个城市也被称为旅游城市。
2、中位数中位数是中心趋势的一种测量,是将一组数据排序后,处于中间位置的变量值,用Me表示。
中位数处于中间位置,前后每部分均包括50%的数据,而且前面部分小于中位数、后面部分大于中位数。
例如,在职工收入水平差异比较大的单位,要了解职工收入的一般水平,用职工收入分布的中位数作为收入水平的代表值要比用算术平均数更恰当,因为它排除了极端数据的影响。
3、四分位数四分位数是将一组数据排序后,找出将该组数据等分为四等份的三个点,每份包括25%的数据,这三个点上的数据就是四分位数。
第二个四分位数就是中位数,它前面包括50%数据,后面也包括50%数据,因而,平时所说的四分位数主要是指第一个四分位数和第三个四分位数。
通常,我们将第一个四分位数称为下四分位数(QL),将第三个四分位数称为上四分位数(QU)。
4、均值均值是集中趋势最主要的测量值,它是将全部数据进行加总然后除以数据总个数,也称为算数平均数。
均值包含一组数据中所有数值,它是先将所有数值进行加总,然后进行平均,在均值中所有数值都有所体现。
因而,我们说均值是集中趋势最主要的测量值。
二、基本方法1、众数的计算(1)众数的计算比较简单,就是找出频数最大的即可。
例如“甲城居民对交通满意度调查”,调查者在甲城市随机抽取统计500人调查,调查结果发现,选择“非常不满意”的有50人,“不满意”的有98人,选择“一般”的有204人,选择“满意”的有110人,选择“非常满意”的有38人。
从调查结果可以看出,选择“一般”的居民最多,为204人,占总数的40.8%,因而众数为“一般”这一变量值,即Mo=“一般”。
对于数值型数据,计算众数时,最好先对数据进行排序,有利于计算各变量值频数,避免出错。
(2)对于分组数据,计算具体数值时,根据公式:对于任意一组数据,基本都存在频数最多的数值,这个数值可能有一个,也可能是两个,或者三个甚至更多,不管存在几个,它们均是该组数据的众数。
社会统计学报告(一)2024

社会统计学报告(一)引言概述:社会统计学是一门研究人类社会现象的学科,通过对人口、就业、教育、健康、犯罪等各个方面的数据进行收集、分析和解释,旨在揭示社会规律和趋势,为社会问题的解决提供科学依据。
本报告旨在总结社会统计学的研究成果,探讨社会统计学在现代社会的重要性和应用。
正文:一、人口统计1. 人口数量的测算与预测- 通过普查和抽样调查等方法,获取人口的真实数量。
- 运用人口统计学模型,预测未来的人口趋势和构成。
2. 人口结构的分析- 研究人口在不同地区、不同年龄、不同性别的分布情况。
- 分析人口结构对社会福利、经济发展等方面的影响。
3. 人口流动与迁徙- 调查人口迁徙的原因和目的,揭示人口流动对社会发展的影响。
- 分析人口迁徙对社会结构、就业市场等的影响。
4. 人口特征的研究- 研究人口的种族、民族、宗教等特征对社会生活的影响。
- 分析人口特征与教育、健康、就业等方面的关联性。
5. 人口政策与规划- 研究人口政策的制定和实施,促进人口合理发展。
- 运用人口统计学方法,制定人口规划,解决人口问题。
二、就业统计1. 就业率与失业率的测算- 统计劳动力市场的就业人数和失业人数,计算就业率和失业率。
- 分析就业率和失业率对经济发展的影响。
2. 就业结构的变化- 调查不同行业和职业的就业人数和比例,分析就业结构的演变。
- 研究科技进步、产业结构调整等因素对就业结构的影响。
3. 工资水平的分析- 收集不同行业和职业的工资数据,比较工资水平的差异。
- 研究工资水平与人力资本、社会地位等因素的关系。
4. 劳动力市场的需求和供给- 调查企业用工需求和劳动力供给的情况,分析供需关系。
- 研究劳动力市场的匹配问题和职业转移现象。
5. 就业政策的研究- 分析就业政策的效果和实施情况,提出改进建议。
- 探讨技能培训、就业援助等政策的作用和影响。
三、教育统计1. 教育水平的测算- 统计人口中受教育程度不同的人数和比例。
- 比较不同地区和不同社会群体之间的教育水平差异。
社会统计学的基本知识

▪ 中国:白威廉的研究,白氏通过对中国大陆1972-1978年间迁 居香港的132位移民的访谈,得到了他们2865位邻居的数据, 发现:对于那些在“文革”前(1966年前)就年满20岁的同期群 案例来说,父亲的“受教育水平”与“职业地位”对子女的受 教育水平,父亲的“职业地位”与“阶级出身”对子女的“职 业地位”获得等,具有显著影响作用。但对于那些在“文革” 时期才年满20岁的同期群案例来说,作用却并不显著。
大 含糊
生活用品 家具 桌子
操作化
问卷设 计/ 调查
▪低
小
抽象层次 涵盖面
统计 分析
明确 特征
精选ppt
10
概念的分类
▪ 一类概念仅仅标识某类现象,是唯一的,如“太阳”、 “月亮”;数学上称为“常量”,如л。
▪ 另一类概念则往往包括若干个子范畴、属性或亚概念, 它们反映出概念所指称的现象在类别、规模、数量、程 度等方面的变异情况。如性别,职业,文化程度,意愿, 收入等
经验的人咨询 ▪ 建立研究假设:主要针对解释性研究,探索性和
描述性研究一般没有研究假设 ▪ 确立概念和测量方法 ▪ 设计问卷 ▪ 调查实施 ▪ 校核和登录 ▪ 统计分析与命题检验(研究假设)
精选ppt
15
三、社会调查资料的特点
(一)随机性 ▪ 客观现象分为确定性的关系和非确定性的关系 ▪ 对确定性的关系,则存在“若A,则必有B”的确
精选ppt
13
二、研究的基本过程
▪ 社会调查指的是一种采取自填式问卷或结 构式访问的方法,系统地、直接地从一个 取自总体的样本那里收集量化资料,并通 过对这些资料的统计分析来认识社会现象 及其规律的社会研究方式。
精选ppt
14
具体的研究步骤(P1-7)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3.一个变项,1个样本 :
①(n≥100):
②(n≤30): , df=b-1
4.1个变项,2个样本 1 2
n=n1+n2>100 →
五、归类总结之五:有关消减误差比例
1.
有消减误差比例意义,且对称
、G、Q拉系数、rs2、r2、rxy.12、、Ry.122= Ry.x1x22
2.有无自由度的表达
G、r、F、x2结果解释加上“其显著度水平达到或没有达到……水平”
3.有关r净相关系数
(两个定距变项)
r=rxy.1——引入第三个变项时对X、Y变项产生共同影响。
rx(y-1)——引入第三个变项时,只对Y产生影响,无消减误差意义。
ry(x-1)——引入第三个变项时,只对X产生影响,无消减误差意义。
Q= Q3- Q1
有单个数(n为偶数时会出现偏离)、区间之分。
(有几种Q,就有几种S计算法)
当为区间表格时(n/4)
①计算向上累加数cf;②Q1位置= ,Q3位置= ;
③Q1=L1+ W1,Q3= L3+ W3;④Q= Q3- Q1P57
5.标准差
①单个数:S= ,②区间:S= P60
对S的解释:如以均值来估计各个个案的数值,所犯的错误 平均是S。用均值作估计变项数值时所犯错误的大小。
社会统计学公式汇总及要点2011.09.09-09.10
(仅供参考,如不能显示公式,请安装Microsoft公式3.0)
一、归类总结之一
测量层次
特质
数学特质
单变项:X
定类变项
只分类
Mo、V
比例、比率、对比值、
次数分布、长作图、圆瓣
双变项:
X、Y
定序变项
不仅分类,有大小、高低、程度等
Mo、V、Md、Q
6.定序+定距
因此社会学家常改用相关比率——即将定序变项看做是定类变项。E
参数值的估计:间距估计:均值、百分率、积矩相关
求总体的均值M
①已知:n, (样本的均值),可信度为95%,求M。
(S是样本的标准差)
③已知:n,可信度95%,样本比率p,求总体比率P。
(百分率(或比例)的间距估计)
②已知: ,可信度,M或e,求n。(决定样本的大小)
检定法
①
两个定类
定类
定类
、 、tau-y
x2
②
定类+定序
定类
定序
同上
③
两个定序
定序
定序
G、dy
Z(n≥100)、t(n≤30)
④
两个定距
定距
定距
r、b,即r=rxy,b=bxy
F、r (n≤30)
⑤
定类+定距
定类
定距
E
只能用F检定
⑥
定序+定距
定序
定距
E
只能用F检定
四、归类总结之四:有关计算题
1.第二章、第四或第六章、第七八章
3.两个
定距变项
Y’=bX+a, a= —b = 简单线性回归分析
X是自变项数值,自变项数值,b是回归系数,表示回归张的斜率,a是截距,即回归线与Y轴的交点,Y’是根据回归方程式所预测的Y变项的值。
r=rxy=
积矩相关测量法
r系数与简单线性回归分析都是假定X与Y的关系具有直线的性质。
4.
定类+定项
,ni是每个自变项Xi的个案数目。 =每类的平均值, 每个竖列平方的和。E值无负值,因为是定类变项。
累加次数、累加百分率
定距变项
不仅分类,有大小、高低、程度,还可加减
Mo、V、Md、Q、 、S(S2)
同上
定比变项
最高测量层次
加减乘除
二、归类总结之二
①2个定类
、 、tau-y
1.集中趋势测量法:Mo、Md、
2.离散趋势测量法:V、Q、S
2.有下标,表示不对称
3.具有消减误差比例意义的有:r2、E2、G、dy、 、 、tau-y、rs2(rs斯皮尔曼系数)
计算公式表(一)⑥①②③④⑤⑥(红色字体为特别关注的.中位项
Md位置= ,Md=L+ W,Md=L+ W
有三种情况:单个数奇、偶、区间。fm:原始次数;cfm-1:累加次数P48
3.均值
= P49
4.离异比率
V= = P52
5.四分位差
由低到高排列,分四个等分计算Q1、Q3位置,Q1位置= ,Q3位置= ,
S2方差:就是标准的平方值,其意义与标准差相同。
计算公式表(二)二个变项
1.两个
定类变项
①
②
My=Y变项的众值次数,Mx=X变项的众值次数,n=全部个案数目。
my=X变项的每个值(类别)之下Y变项的众值次数,mx=Y变项的每个值之下X变项的众值次数,
③tau-y= (E1= ,E2= )
n=全部个案数目,f=某条件次数,Fy=Y变项的某个边缘次数,Fx=X变项的某个边缘次数。
2.两个
定序变项
G=
Ns是同序对数,Nd是异序对数对G检定,只有两种检定法:Z、t。
dy=
Ns是同序对数,Nd是异序对数,
Ty是只在依变项Y上同分的对数。因为dy系数是以X预测Y,如果两个个案在X上有高低之分,就要预测或估计他们在Y上的相对等级。因上分母要加上Ty。
rs=
斯皮尔曼rho系数。常出现在填空选择,一般不考计算题。
2.
有消减误差比例意义,且不对称
dy、 、tau-y、E2、CR2(特征值)
3.
无消减误差比例意义,且对称
、V系数、C系数、tau-a、tau-b、tau-c、Vs、r
4.
无消减误差比例意义,且不对称
b、E
六、其他细节
1.显著度的表达
①两端检定: ;②一端检定: ;③ ;④F(df1,df2);⑤x2(df)
相关比率与非线性相关
又称为eta平方系数(E2),是以一个定类变项X为自变项,以一个定距变项Y为依变项。是根据自变项的每一个值来预测或估计依变项的均值。
E是假定X是非线性关系。E值从0-1,其E2具有消减误差的意义。
5.定类+定序
=两个定类,大部分的社会学研究都采用Lambda或tau-y系数来测量
④已知:可信度,p,
P or e,求n。
计算公式表(三)假设的检定:两个变项之相关Z(5个)、t(4)、F(2个)
Z检定法(大样本)、t检定法(小样本):定矩变项、随机抽样、总体正态分布。
1、Z检定法
2、t检定法
①(大样本)
n≥100(单均值)
①(小样本)n≤30
4.参数检定:Z、t、F
非参数检定:x2、U、H、K-S、走动检定P201
②2个定序
G、dy
③2个定距
R、b,即r=rxy,b=bxy
④定类+定距
E
⑤定类+定序
同①: 、 、tau-y大多数社会学者将定序看作定类,即2个定类。
三、归类总结之三:理解如下:(红色字体为特别关注的公式)
变项X
变项Y
可计算