数据结构与算法基础(第三版)第四章图精品PPT课件
合集下载
《数据结构与算法 》课件

人工智能领域中,数据结构对于机器学习、深度学习等算法的效率至关重要。例如,使用决策树、神经网络等数据结构进行分类、预测等任务。
数据结构在人工智能中的优化可以提升算法的效率和准确性,例如通过使用哈希表实现快速特征匹配,提高图像识别速度。
THANK YOU
定义与分类
添加边、删除边、查找路径等。
基本操作
图中的边可以是有方向的,也可以是无方向的。节点之间可以有多种关系,如邻接、相连等。
特性
社交网络、交通网络、路由协议等。
应用场景
05
排序与查找算法
冒泡排序:通过重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
详细描述
链表的优势在于可以动态调整大小,插入和删除操作仅需修改指针,时间复杂度为O(1)。但链表访问特定元素需要从头部遍历,效率较低。
VS
栈和队列是特殊的线性数据结构,它们遵循特定的操作规则。栈遵循后进先出(LIFO)原则,队列遵循先进先出(FIFO)原则。
详细描述
栈用于保存按照后进先出顺序访问的数据元素,常见的操作有压栈、弹栈和查看栈顶元素。队列用于保存按照先进先出顺序访问的数据元素,常见的操作有入队、出队和查看队首元素。
03
线性数据结构
数组是线性数据结构中的基本形式,它以连续的内存空间为基础,用于存储固定长度的同类型元素。
数组具有固定的长度,可以通过索引直接访问任意元素。它适合于需要快速访问数据的场景,但插入和删除操作需要移动大量元素,效率较低。
详细描述
总结词
总结词
链表是一种线性数据结构,它通过指针链接各个节点,节点包含数据和指向下一个节点的指针。
数据结构在人工智能中的优化可以提升算法的效率和准确性,例如通过使用哈希表实现快速特征匹配,提高图像识别速度。
THANK YOU
定义与分类
添加边、删除边、查找路径等。
基本操作
图中的边可以是有方向的,也可以是无方向的。节点之间可以有多种关系,如邻接、相连等。
特性
社交网络、交通网络、路由协议等。
应用场景
05
排序与查找算法
冒泡排序:通过重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
详细描述
链表的优势在于可以动态调整大小,插入和删除操作仅需修改指针,时间复杂度为O(1)。但链表访问特定元素需要从头部遍历,效率较低。
VS
栈和队列是特殊的线性数据结构,它们遵循特定的操作规则。栈遵循后进先出(LIFO)原则,队列遵循先进先出(FIFO)原则。
详细描述
栈用于保存按照后进先出顺序访问的数据元素,常见的操作有压栈、弹栈和查看栈顶元素。队列用于保存按照先进先出顺序访问的数据元素,常见的操作有入队、出队和查看队首元素。
03
线性数据结构
数组是线性数据结构中的基本形式,它以连续的内存空间为基础,用于存储固定长度的同类型元素。
数组具有固定的长度,可以通过索引直接访问任意元素。它适合于需要快速访问数据的场景,但插入和删除操作需要移动大量元素,效率较低。
详细描述
总结词
总结词
链表是一种线性数据结构,它通过指针链接各个节点,节点包含数据和指向下一个节点的指针。
数据结构与算法基础PPT课件

组成,数据元素包含数据项(Data Item)
• 在学生档案管理系统中,每位学生信息是数据的基本单位,称之为数据元素,也称为元素 (Element)、节点(Node)或者记录(Record)
• 组成数据元素的项称之为数据项,数据项是数据的最小标识单位,又称为字段(Field )或者域(Field)
• 例如,学生信息由学号、姓名、性别、出生年月、专业等组成
• 数据结构可以表示为DS=(D, R),其中DS表示数据结构,D表示数据集合,R表示关系( Relation)集合
• 三口之家的成员的数据逻辑结构可以表示如下: • DS=(D, R) • D={父亲, 母亲, 孩子} • R={(父亲, 母亲), (父亲, 孩子), (母亲, 孩子)}
• 数据的逻辑结构可以分为线性结构和非线性结构
• 线性链表的优点在于插入和删除效率高。其缺点是访问元素时需要遍历链表的所有元素,因而效率 欠佳
队列和栈
• 队列(Queue)是先进先出的系列(FIFO,First In First Out),即最先添加的元 素,是最先弹出的元素
• 列表可以实现队列,但并不适合。因为从列表的头部移除一个元素,列表中的所有 元素都需要移动位置,所以效率不高。用户可以使用collections模块中的deque 对象来删除列表头部的元素
• 栈(Stack)是后进先出的队列(LIFO,Last In First Out),即最后添加(push) 的元素,是最先弹出(pop)的元素
• 向列表最后位置添加元素和从最后位置移除元素非常方便和高效,故使用列表可以 快捷高效地ቤተ መጻሕፍቲ ባይዱ现栈
常用算法
• 数据的算法基于数据的逻辑结构,但具体实现要在物理存储结构上进行 • 基于数据结构的常用算法包括以下几种。 • (1)检索:在数据结构中查找满足给定条件的节点。 • (2)插入:在数据结构中增加新的节点。 • (3)删除:从数据结构中删除指定节点。 • (4)更新:改变指定节点的一个或者多个字段的值。 • (5)排序:按某种指定的顺序重新排列节点(从而可以提高其他算法的
• 在学生档案管理系统中,每位学生信息是数据的基本单位,称之为数据元素,也称为元素 (Element)、节点(Node)或者记录(Record)
• 组成数据元素的项称之为数据项,数据项是数据的最小标识单位,又称为字段(Field )或者域(Field)
• 例如,学生信息由学号、姓名、性别、出生年月、专业等组成
• 数据结构可以表示为DS=(D, R),其中DS表示数据结构,D表示数据集合,R表示关系( Relation)集合
• 三口之家的成员的数据逻辑结构可以表示如下: • DS=(D, R) • D={父亲, 母亲, 孩子} • R={(父亲, 母亲), (父亲, 孩子), (母亲, 孩子)}
• 数据的逻辑结构可以分为线性结构和非线性结构
• 线性链表的优点在于插入和删除效率高。其缺点是访问元素时需要遍历链表的所有元素,因而效率 欠佳
队列和栈
• 队列(Queue)是先进先出的系列(FIFO,First In First Out),即最先添加的元 素,是最先弹出的元素
• 列表可以实现队列,但并不适合。因为从列表的头部移除一个元素,列表中的所有 元素都需要移动位置,所以效率不高。用户可以使用collections模块中的deque 对象来删除列表头部的元素
• 栈(Stack)是后进先出的队列(LIFO,Last In First Out),即最后添加(push) 的元素,是最先弹出(pop)的元素
• 向列表最后位置添加元素和从最后位置移除元素非常方便和高效,故使用列表可以 快捷高效地ቤተ መጻሕፍቲ ባይዱ现栈
常用算法
• 数据的算法基于数据的逻辑结构,但具体实现要在物理存储结构上进行 • 基于数据结构的常用算法包括以下几种。 • (1)检索:在数据结构中查找满足给定条件的节点。 • (2)插入:在数据结构中增加新的节点。 • (3)删除:从数据结构中删除指定节点。 • (4)更新:改变指定节点的一个或者多个字段的值。 • (5)排序:按某种指定的顺序重新排列节点(从而可以提高其他算法的
《算法与数据结构》PPT课件

描 述
•类语言 类似高级语言的表示,例如类 PASCAL、 类C语言
软件
技术
插入排序
基础
软件
技术
基础
Insertion-Sort(A)
1 for j = 1 to n-1
2
key = A[j]
3
i = j-1
4
while i >= 0 and A[i] > key
5
A[i+1] =性 算法中的每一个指令比须有明确的含义, 不能有二义性;
可行性 算法中描述的操作都是可通过已经实现的 基本运算、执行有限次实现的;
输入 一个算法应有0个或多个输入;
输出 一个算法应有1个或多个输出。
软件
技术
基础
算法的表示
•自然语言
算 法 的
•流程图 特定的表示算法的图形符号
•伪语言 包括程序设计语言的三大基本结构及 自然语言的一种语言
for(j =1; j<=i; j++) d[i][j]=data[i][j]+1;
软件
技术
基础
问题规模与时间复杂度的关系
• 一般来说,计算机算法是问题规模n 的函数 f(n),算法的时间复杂度也因此记做
<math>T(n)= \mathcal{O}(f(n))</math>
• 因此,问题的规模n 越大,算法执行的时间 的增长率与f(n) 的增长率正相关,称作渐进 时间复杂度(Asymptotic Time Complexity )。
结信构息模管型理结—点—和二边维代数表据运表算处理和输入/输出状态。
下 棋—— 人工智能(树型结构) 交通管理—— 最佳道路选择(图型结构)
全套电子课件:数据结构(C语言版)(第三版)

例 计算f=1!+2!+3!+…+n!, 用C语言描述。
void factorsum(n) int n;{int i,j;int f,w; f=0; for (i=1,i〈=n;i++) {w=1; for (j=1,j〈=i;j++) w=w*j; f=f+w;} return;
1.2 数据结构的发展简史及其 在计算机科学中所处的地位
• 发展史: 1、 “数据结构”作为一门独立的课程在国外是从1968年才开始设
立的。 2、 1968年美国唐·欧·克努特教授开创了数据结构的最初体系,他所
著的《计算机程序设计技巧》第一卷《基本算法》是第一本较 系统地阐述数据的逻辑结构和存储结构及其操作的著作。
⑵ while语句
while (〈条件表达式〉) { 循环体语句; }
• while循环首先计算条件表达式的值,若条件表达式的值非零, 则执行循环体语句,然后再次计算条件表达式,重复执行,直 到条件表达式的值为假时退出循环,执行该循环之后的语句。
⑶ do-while语句
do { 循环体语句 } while(〈条件表达式〉)
• 地位: 1、“数据结构”在计算机科学中是一门综合性的专业基础课。
2、数据结构是介于数学、计算机硬件和计算机软件三者之间 的一门核心课程。
3、数据结构这一门课的内容不仅是一般程序设计(特别是非 数值性程序设计)的基础,而且是设计和实
1.3 什么是数据结构
• 解决非数值问题的算法叫做非数值算法,数据处理方面的算法都 属于非数值算法。例如各种排序算法、查找算法、插入算法、删 除算法、遍历算法等。
• 数值算法和非数值算法并没有严格的区别。
数据结构和算法PPT教学课件

(1)有且只有一个根结点
(2) 每个节点最多有一个前件,也最多有一个后件.
B 、线形表的顺序存储结构
是计算机中存储线形表的最简单的方法.
两个基本特点:
(1)线形表中所有元素所占的空间都是连续的
(2)线形表中各数据元素在存储空间中是按逻辑顺序
2020/12/10 依次存放的
5
3 、栈及基本运算
(1)栈的概念:
2、二叉树的特点 (1)在第K层上,最多有2k-1(K>=1)个结点
(2)深度为M的二叉树,最多有2M-1个结点(深度指层数)
(3)任何二叉树中,度为0的结点(叶子)总比度为2的结 点多一个
2(020/412)/10 具有n个结点的二叉树,深度至少为[lon2n]+1
9
3、完全二叉树和满二叉树 完全二叉树 是指最后一层外,每一层上的结点数均达到最大值, 在最后一层上只缺少右边的若干结点。 满二叉树 满二叉树是指除最后一层外,每一层上的所有结点有 两个子结点,则在第K层上有2k-1个结点,深度为m的 满二叉树有2m-1个结点。
特点: “先进先出” FIFO 或”后进后出” LILO
队列运算: 入队:从队尾插入 退队:从队头删除
2020/12/10
7
5 、线性链表
(1)概念: 线性表的链式存储结构称为线形链表.
(2)存储原理:
把存储结点分成两部分,第一部分存储数据元素,第二
部分存储下一元素的序号(即存储结点的地址).
(3)特点:
时间复杂度:是指执行算法所需要的计算工作量.
空间复杂度:是指执行算法所需要的内存空间.
存储空间包括:算法程序所占空间,输入原始数据所占空间
执行算法时需要的额外空间.
《数据结构与算法 》课件

自然语言处理
自然语言处理中,数据结构用于表示句子、单词之间的关系,如依 存句法树。
计算机视觉
计算机视觉中的图像处理和识别使用数据结构来存储和操作图像信 息,如链表和二叉树。
算法在计算机科学中的应用
加密算法
加密算法用于保护数据的机密性和完整性,如 RSA算法用于公钥加密。
排序算法
排序算法用于对数据进行排序,如快速排序和归 并排序广泛应用于数据库和搜索引擎中。
归并排序
将两个或两个以上的有序表组合成一个新的有序表。
查找算法
线性查找:从数据结构的一端开始逐 个检查每个元素,直到找到所查找的 元素或检查完所有元素为止。
二分查找:在有序数据结构中查找某 一特定元素,从中间开始比较,如果 中间元素正好是要查找的元素,则搜 索过程结束;如果某一特定元素大于 或者小于中间元素,则在数组大于或 小于中间元素的那一半中查找,而且 跟开始一样从中间元素开始比较。如 果在某一步骤数组为空,则代表找不 到。这种搜索算法每一次比较都使搜 索范围缩小一半。
04
常见算法实现
排序算法
冒泡排序
通过重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复 地进行直到没有再需要交换,也就是说该数列已经排序完成。
快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据要小,然后再按 此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
数据结构在计算机科学中的应用
1 2
数据库系统
数据结构是数据库系统的基础,用于存储、检索 和管理大量数据。例如,B树和哈希表在数据库 索引中广泛应用。
自然语言处理中,数据结构用于表示句子、单词之间的关系,如依 存句法树。
计算机视觉
计算机视觉中的图像处理和识别使用数据结构来存储和操作图像信 息,如链表和二叉树。
算法在计算机科学中的应用
加密算法
加密算法用于保护数据的机密性和完整性,如 RSA算法用于公钥加密。
排序算法
排序算法用于对数据进行排序,如快速排序和归 并排序广泛应用于数据库和搜索引擎中。
归并排序
将两个或两个以上的有序表组合成一个新的有序表。
查找算法
线性查找:从数据结构的一端开始逐 个检查每个元素,直到找到所查找的 元素或检查完所有元素为止。
二分查找:在有序数据结构中查找某 一特定元素,从中间开始比较,如果 中间元素正好是要查找的元素,则搜 索过程结束;如果某一特定元素大于 或者小于中间元素,则在数组大于或 小于中间元素的那一半中查找,而且 跟开始一样从中间元素开始比较。如 果在某一步骤数组为空,则代表找不 到。这种搜索算法每一次比较都使搜 索范围缩小一半。
04
常见算法实现
排序算法
冒泡排序
通过重复地遍历待排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复 地进行直到没有再需要交换,也就是说该数列已经排序完成。
快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据要小,然后再按 此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
数据结构在计算机科学中的应用
1 2
数据库系统
数据结构是数据库系统的基础,用于存储、检索 和管理大量数据。例如,B树和哈希表在数据库 索引中广泛应用。
数据结构与算法(共11张PPT)

(b)入队3个元素(c)出队3个元素
(b) d, e, b, g入队
利用一组连续的存储单元(一维数组)依次存放从队 在循环队列中进行出队、入队操作时,队首、队尾指
队列示意图
在非空队列里,队首指针始终指向队头元素,而队
(b) d, e, b, g入队
8
Q.rear
a5
a4
Q.front
(d)入队2个元素
a1, a2, … , an
的指修针改 和是队依列先中进元先素出的Q的变.re原化a则情r 进况行。的,如图所示。
a3
Q.front
a2
a1
首到队尾的各个元素,称为顺序队列。
(c)
d, e出队Q.front
Q.front
◆出队:首先删去front所指的元素,然后将队首指针front+1,并
◆rear所指的单元始终为空(a。)空队列
i
i, j, k入队
(e)
1
2
3
k
r
01
j5
2
front
43
i
b, g出队
(f )
r, p,
p rear
s, t入队
循环队列操作及指针变化情况
入队时尾指针向前追赶头指针,出队时头指针向前追赶尾指针 ,故队空和队满时头尾指针均相等。因此,无法通过front=rear来 判断队列“空”还是“满”。解决此问题的方法是:约定入队前,
数据结构与算法
1算法基础 2数据结构
3栈
4队列
5链表 6树和二叉树
7查找
4队列
✓队列的基本概念 ✓队列运算
✓循环队列及其运算
4队列
1.队列的基本概念
数据结构第四章
T 插入串
S pos
T 插入后
A
A串部分被舍弃
MAXLEN
(3) 插入后串长(st+st+st≥MAXLEN且pos+st>MAXLEN,则A全部 字符被舍弃(不需后移),并且T在插入时也有部分字符被舍弃
S pos
A 插入前
S pos
T 插入后
MAXLEN 舍弃
T 插入串
S.ch 0 1 2 3 4 5 6 7 8 9 10 … abcde fgh i j k
st
MAXLEN-1 …
串的长度st+1
省级精品课程配套教材 高等学校计算机类“十二五” 规划2教. 在材串尾存储一个特殊字符作为串的终结符
比如C语言中用’\0’来表示串的结束。 char s[MAXLEN];
5 { /*连接后串长小于MAXLEN */
6 for(i=S->last; i<=S->last+st; i++)
7
S->ch[i+1]=T.ch[i-S->last];
8 S->last=S->last+st+1;
省级精品课程配套教材
高等学校计算机类“十二五”
规划教材
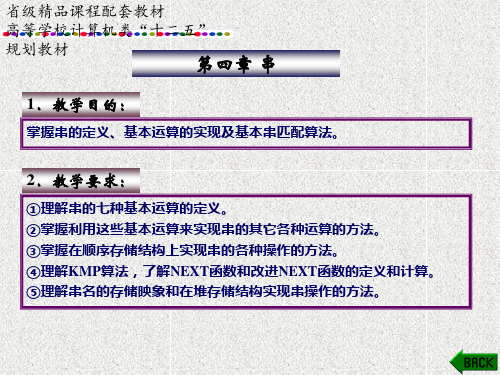
第四章 串
1.教学目的:
掌握串的定义、基本运算的实现及基本串匹配算法。
2.教学要求:
①理解串的七种基本运算的定义。 ②掌握利用这些基本运算来实现串的其它各种运算的方法。 ③掌握在顺序存储结构上实现串的各种操作的方法。 ④理解KMP算法,了解NEXT函数和改进NEXT函数的定义和计算。 ⑤理解串名的存储映象和在堆存储结构实现串操作的方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Slide. 4 - 2
D.S. 数据结构与算法
第四章 图以及与图有关的算法
Slide. 4 - 3
操作: Node NEWNODE ( G ) Void DELNODE ( G, v )
Void SETSUCC ( G, v1, v2 ) Void DELSUCC ( G, v1, v2 ) Listofnode SUCC ( G, v1, v2 ) Lisyofnode PRED ( G, v)
第四章 图以及与图有关的算法
V1
V2
0110
G1
G1.arcs 0 0 0 0 0001
V3
V4
1000
V1
V2
G2
V3
V4
V5
G2.arcs
01010 10101 01011 10100 01100
5
3
32
8
4
3
1
1
6
9 5
4
6
5
5
∞ 3 ∞ ∞∞ 1 ∞∞ 5 ∞ 3 ∞ ∞∞ ∞ 4 ∞∞ 9 8 ∞ ∞∞∞ 6∞∞ 5∞∞ ∞∞ ∞ ∞∞ 5
ADT. Graph G = ( V , R ) 数据对象v:v是具有相同特性的数据元素的集合,称为顶点集。 数据关系R:
R = { VR } VR = { <v , w >|v, w ∈V,且P(v,w),<v, w>表示从v到w的弧,
谓词P(v, w)定义了弧 <v, w>的意义或信息 }
国家示范性软件学院 2005 ·秋
} Vnode, AdjList[MAX_VERTEX_NUM] ;
Typedef struct {
AdjList vertices ;
Int
vexnum ;
Int
kind ;
} ALGraph ;
国家示范性软件学院 2005 ·秋
Slide. 4 - 7
D.S. 数据结构与算法
第四章 图以及与图有关的算法
国家示范性软件学院 2005 ·秋
Slide. 4 - 1
D.S. 数据结构与算法
第四章 图以及与图有关的算法
4.1 基本定义/术语
Slide. 4 - 2
定义:一个图G=(V,E)是一个由非空的有限集 V和一个边集 E 所组成的。若E中的每条边都是结点的有序对(v , w),就说 该图是有向图(directed graph,digraph)。若E中的每条边是两 个不同结点有序对,就说该图是无向图,其边仍表示成(v, w)。
D.S. 数据结构与算法
第四章 图以及与图有关的算法
第四章 图以及与图有关的算法
Slide. 4 - 1
4.1 基本术语
4.2 图的表示
4.3 图的搜索算法 4.4 图与树的联系
4.5 无向图的双连通性
*4.6 有向图的搜索
4.7 强连通图
4.8 拓扑分类
*4.9 关键路径
4.10 单源最短路径
*4.11 每一对顶点间的最短路径
Slide. 4 - 8
0 v1 1 v2 2 v3 3 v4
2
1^
3^
+
0^
有向图G1邻接表
0 v1
3^
1 v2
0^
2 v3 3 v4
0^ 2^
G1的逆邻接表
0 v1
1 v2 2 v3 3 v4 4 v5
3
1^
4
2
0^
4
3
1^
2
0^
2
1^
无向图G2邻接表
国家示范性软件学院 2005 ·秋
V1
V2
G1
V3
V4
V1
G2
V4
V2
V3 V5
Slide. 4 - 8
1 若(i, j)∈E A[i][j] = 0 若(i, j)∈E
网的邻接矩阵可定义为: A[i][j] =
wij 若(i, j)∈E ∞ 若(i, j)∈E
n-1
n-1
TD(v
i
)
=
∑A[i][j]
j=0
=
∑A[j][i]
j=0
( n 顶点个数 )
n-1
n-1
TD(vi)=OD(vi)+ID(vi)源自intadjvex ;
struct ArcNode *nextarc ;
表结点
InfoType } ArcNode ;
*info ; Adjvex nextarc info
Typedef struct Vnode { VertexType data ; ArcNode *firstarc ;
头结点 data firstarc
Int ISEDGE ( G, v1, v2 ) Node FirstAdjVex( G , v )
Node NextAdjVex( G, v, w )
术语:顶点 弧 边 邻接 相邻
依附
路径(路) 简单路径 环路
带标号的图(网)
连通
连通图
强连通图 连通分量
完全图 子图 度
完全图 入度
国家示范性软件学院
Typedef enum { DG, DN, AG, AN } GraphKind ;
Typedef struct ArcCell {
VRType adj ;
InfoType *info ;
} ArcCell , AdjMatrix[ MAX_VERTEX_NUM][MAX_VERTEX_NUM] ;
国家示范性软件学院 2005 ·秋
Slide. 4 - 6
有向图G1
无向图G2
有 向 网
Slide. 4 - 6
D.S. 数据结构与算法
第四章 图以及与图有关的算法
Slide. 4 - 7
2、图的链式存储——邻接表(Adjacency List)
#define MAX_VERTEX_NUM 20
Typedef struct ArcNode {
稀疏图 出度
2005 ·秋
稠密图 生成树
Slide. 4 - 3
D.S. 数据结构与算法
第四章 图以及与图有关的算法
4.2 图的表示
Slide. 4 - 4
1、图的顺序存储——邻接矩阵
设图G = ( V, E ) ,V = { 0, 1,…,n-1 }则表示G的邻接 矩阵 A 是其元素按下式定义的nxn矩阵:
Typedef struct {
VertexType vex[MAX_VERTEX_NUM] ;
AdjMatrix arcs ;
int
vexnum , arcnum ;
GraphKind kind;
} Mgraph ;
国家示范性软件学院 2005 ·秋
Slide. 4 - 5
D.S. 数据结构与算法
=
∑A[i][j]
j=0
+
∑A[j][i]
j=0
( n 顶点个数 )
国家示范性软件学院 2005 ·秋
Slide. 4 - 4
D.S. 数据结构与算法
第四章 图以及与图有关的算法
#define INFINITY INT_MAX
Slide. 4 - 5
#define MAX_VERTEX_NUM 20