大数据生态圈组件思维导图
大数据与人工智能(思维导图)
创建一个等距的一维数组
numpy.logspace()
创建一个等比数列
np.random.rand(10,10)
创建10行10列的数组(范围在0-1之间)
切片
均匀分布
np.random.uniform(0,100)
创建指定范围内的一个数
生成均匀分布随机数,指定随机数取值范围和数组形状
np.random.randint(0,100)
获取到具体的每个键和值
遍历字典
单独获取键和值
字典函数
len(dict),str(dict),type(dict)
字典方法
Set 集合
set是一组key的集合 集合间的运算
总结
变量
全局变量 变量名
函数外定义的变量
要在函数内给一个全局变量赋值时,需要先用global关键字声明变量,否则编译 器会尝试新建一个同名的局部变量
有标签样本{特征,标签} 无标签样本{特征,?}
数据的特定实例x
样本
检查多个样本并尝试找出可最大限度地减少损失的模型,这一过程称为经验风险 最小化
首先对权重w和偏差b进行初始猜测
构建模型
可将样本映射到预测标签
然后反复调整这些猜测 直到获得损失可能最低的权重和偏差为止
模型训练要点
模型
不断迭代,直到总体损失不再变化或至少变化极其缓 慢为止
《“数字化”背景下经济社会发展的新特征、新趋势》思维导图
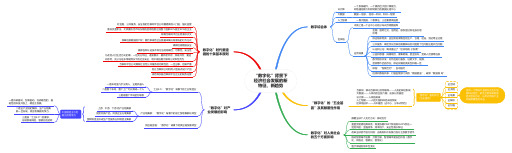
“数字化”背景下经济社会发展的新特征、新趋势数字综合体“数字化”的“五全基因”及其颠覆性作用数字化”对人类社会的五个方面影响云计算大数据人工智能区块链数据—信息, 信息—知识,知识—智慧本质上是一个去中心化的分布式存储数据库一个系统硬件,一个具有巨大的计算能力、网络通信能力和存储能力的数据处理中心一靠大数据,二靠算法,三还要靠高速度应用场景金融:国际汇兑、信用证、股权登记和证券交易所等供应链和物流:监控和追溯物品的生产、仓储、运送、到达等全过程公共服务:确定民众反映的需要解决的问题是个性问题还是共性问题认证和公证:腾讯推出了“区块链电 子发票”公益和慈善:捐赠项目、募集明细、资金流向、受助人反馈等信息数字版权开发:对作品进行鉴权,证明文字、视频、音频等作品的存在,保证权属的真实性和唯一性保险:“智能合约”,自动赔付信息和数据共享:打通监管部门间的“数据壁垒”,破除“数据孤 岛”互联网、移动互联网以及物联网——人类的神经系统大数据——人体内的五脏六腑、皮肤以及器官云计算——人体的脊梁人工智能——人的大脑和神经末梢系统区块链技术——人体基因(去中心、分布式特性)颠覆全球个人支付方式:移动支付重塑贸易清结算体系:高度依赖SWIFT系统和CHIPS存在一定的风险:金融战争、效率低下、安全性难以保证改革全球货币发行机制:由政府和中央银行发行主权数字货币推动智慧城市发展:万物互联、智慧城市建设四阶段(数字化、网络化、智能化、智慧化)医疗保健的根本性变化“数字化”对产业发展的影响工业4.0:“数字化”背景下的工业制造业产业链集群:“数字化”背景下的加工贸易集群化转型供应链金融:“数字化”背景下的供应链发展转型一是车间里几乎没有人,全是机器人二是整个车间、整个工厂可以算成一个人三是跟整个市场密切联系上游、中游、下游 的产业链集群促使同类产品、同类企业扎堆集群围绕制造业形成生产性服务业和制造业集群一是科研驱动、创新驱动。
万字长文解读最新最全的大数据技术体系图谱!

万字长文解读最新最全的大数据技术体系图谱!正文开始大数据技术发展20年,已经形成覆盖面非常庞大的技术体系,最近信通院发布了《大数据白皮书2020》(关注本公众号后,后台回复“big2020”获得PDF),提供了一张非常全面的大数据技术体系图谱,如下图所示:从这张图谱可以看到,大数据技术体系可以归纳总结为数据分析应用技术、数据管理技术、基础技术、数据安全流通技术四大方向,每个方向大数据技术的产生都有其独特的背景。
1、基础技术:主要为应对大数据时代的多种数据特征而产生大数据时代数据量大,数据源异构、数据时效性高等特征催生了高效完成海量异构数据存储与计算的技术需求。
面对迅速而庞大的数据量,传统集中式计算架构出现难以逾越的瓶颈,传统关系型数据库单机的存储及计算性能有限,出现了规模并行化处理(MPP)的分布式计算架构,如分析型数据库GreenGreenplum。
面对分布式架构带来的海量分布式系统间信息协同的问题,出现了以Zoomkeeper为代表的分布式协调系统;为了将分布式集群中的硬件资源以一定的策略分配给不同的计算引擎和计算任务,出现了Yarn等集群管理及调度引擎;面对海量计算任务带来的管理复杂度大幅提升问题,出现了面向数据任务的灵活调度工作流平台。
面向海量网页内容及日志等非结构化数据,出现了基于Apache Hadoop和Spark生态体系的分布式批处理计算框架;面向对于时效性数据进行实时计算反馈的需求,出现了Apache Storm、Flink等分布式流处理计算框架。
面对大型社交网络、知识图谱的应用要求出现了以对象+关系存储和处理为核心的分布式图计算引擎和图数据库,如GraphX、neo4j等;面对海量网页、视频等非结构化的文件存储需求,出现了mongoDB 等分布式文档数据库;面向海量设备、系统和数据运行产生的海量日志进行高效分析的需求,出现了influxdb等时序数据库;面对海量的大数据高效开放查询的要求,出现了以Redis为代表的K-V数据库。
实战大数据(Hadoop Spark Flink):从平台构

读书笔记
对想了解大数据的小白来讲还是非常不错的,不过里面的安装步骤太多了[emm]。 快速入门,每个框架讲了怎么安装和简单的使用,对于大体了解很有帮助。 前阶段概念性的东西比较多,可以提供参考。 只能说算是知识普及和实验环境搭建,内容一般,实操的话也没多大意义。 框架搭建流程介绍的很清晰了,而且还附有配置参数相关的代码,很棒哦。 比较快速的过了一遍这本书对于大数据类的项目入门比较好,比较基础的介绍了数据中台以及上层应用层实 际技术框架的常见技术以及概念比如hadoop、flume、spark、sevlet等。 各种框架的安装和word count。 入门读物,很好理清技能树可以用来当作入门读物,能够很好的理清一些技术之间的区别与联系,之后再找 相关技术书籍深入学习。 能够帮助入门大数据常用的框架,对大数据技术有个概貌认知,也能快速入门上手,感知各组件的关系。 六个小时,大体看完,想快速入门的推荐阅读。
资源管理的本质是集群、数据中心级别资源的统一管理和分配。其中多租户、弹性伸缩、动态分配是资源管 理系统要解决的核心问题。
大数据工程师需要掌握Spark Streaming、Flink DataStream等大数据实时计算技术。
大数据工程师需要掌握MapReduce、Hive、Spark Core、Spark SQL、FlinkDataSet等大数据离线计算技术。
3.4 Hadoop分布式 集群的构建
3.5 MapReduce 分布式计算
框架
3.6本章小结
4.2搭建Kafka分布 式消息系统
4.1构建HBase分布 式实时数据库
4.3本章小结
5.1搭建Flume 1
日志采集系统
5.2使用Flume 2
采集用户行为 数据
大数据技术原理与应用(第2版)

作者介绍
这是《大数据技术原理与应用(第2版)》的读书笔记模板,暂无该书作者的介绍。
谢谢观看
读书笔记
天呐,我居然看完了。
这是一本偏专业的书籍。
值得一看,个中内容,源代码及实践部门太专业而!作为半业务半技术的数据分析师,值得好好了解,体会开发和大数据同行的处理思 维!。
四颗星。
大数据技术发展日新月异,这本书中的一些内容已经有点过时了,不过通篇读下来还是能对大数据领域有一 个整体认识。
15.1大数据在物流领域中的应用 15.2大数据在城市管理中的应用 15.3大数据在金融行业中的应用 15.4大数据在汽车行业中的应用 15.5大数据在零售行业中的应用 15.6大数据在餐饮行业中的应用 15.7大数据在电信行业中的应用 15.8大数据在能源行业中的应用 15.9大数据在体育和娱乐领域中的应用
第3章分布式文件系 统HDFS
第4章分布式数据库 HBase
第5章 NoSQL数据库 第6章云数据库
3.1分布式文件系统 3.2 HDFS简介 3.3 HDFS的相关概念 3.4 HDFS体系结构 3.5 HDFS的存储原理 3.6 HDFS的数据读写过程 3.7 HDFS编程实践 3.8本章小结 3.9习题
4.1概述 4.2 HBase访问接口 4.3 HBase数据模型 4.4 HBase的实现原理 4.5 HBase运行机制 4.6 HBase编程实践 4.7本章小结 4.8习题 实验3熟悉常用的HBase操作
5.1 NoSQL简介 5.2 NoSQL兴起的原因 5.3 NoSQL与关系数据库的比较 5.4 NoSQL的四大类型 5.5 NoSQL的三大基石 5.6从NoSQL到NewSQL数据库 5.7本章小结 5.8习题
《从程序员到架构师 大数据量 缓存 高并发 微服务 多团队协同》读书笔记PPT模板思维导图下载

11.2 限流算 2
法
3 11.3 方案实
现
4 11.4 限流方
案的注意事项
5
11.5 小结
第4部分 微服务进阶场景实战
第12章 微服务的 痛:用实际经历 告诉你它...
第13章 数据一致 性
第14章 数据同步 第15章 BFF
12.1 单体式架构 VS微服务架构
12.2 微服务的好 处
12.3 微服务的痛 点
《从程序员到架构师 大 数据量 缓存 高并发 微
服务 多团队协同》
最新版读书笔记,下载可以直接修改
思维导图PPT模板
01 序
目录
02
第1部分 数据持久化 层场景实战
03
第2部分 缓存层场景 实战
04 第3部分 基于常见组 件的微服务场景实战
05
第4部分 微服务进阶 场景实战
06
第5部分 开发运维场 景实战
12.4 小结
13.1 业务场景: 下游服务失败后 上游服...
13.2 最终一致性 方案
13.3 实时一致性 方案
13.4 TCC模式
13.6 尝试Seata
13.5 Seata中 AT模式的自动
回滚
13.7 小结
14.1 业务场 景:如何解决
1
微服务之间
的...
14.2 数据冗 2
余方案
3 14.3 解耦业
06
1.6 小结
2 . 1 业 务 场 景 :1
千万工单表如 何实现快速...
2.2 查询分离 2
简介
3 2.3 查询分离
实现思路
4 2.4
Elasticsear ch注意事...
5
《ECharts数据可视化 入门 实战与进阶》读书笔记思维导图PPT模板下载

11.3 响 应式自适 应
04
11.4 事 件与行为
06
11.6 本 章小结
05
11.5 三 维可视化 制作
第12章 可视化经验分享
Байду номын сангаас
12.1 如何选择合 适的可视化类型
12.2 可视化配色 需注意什么
12.3 追求动态和 酷炫效果有错吗
12.4 本章小结
读书笔记
谢谢观看
图
4
4.16 关系图
5 4.17 本章小
结
第5章 色彩搭配
5.2 色彩设置
5.1 色彩主题
5.3 本章小结
第6章 带有时间轴的复杂动态 可视化案例
6.2 可视化制作 全流程
6.1 带时间轴的 可视化图
6.3 本章小结
第7章 ECharts不同场景 Dashb...
7.2 车联网情况 可视化案例
最新版读书笔记,下载可以直接修改
《ECharts数据可 视化 入门 实战与
进阶》
思维导图PPT模板
本书关键字分析思维导图
ECharts
小结
第章
图
文本 流程
官方
数据 时间
化图
经验
Dashboard
可视化
案例
内容
动态
线图
产品
制作
01 第1章 全面认识 ECharts
目录
02 第2章 搭建开发环境
03
5 2.5 本章小
结
第3章 ECharts组件详解
01
3.1 标 题
02
3.2 提 示框
03
3.3 工 具栏
04
3.4 图 例
大数据知识工程

阅读感受
在大数据时代,数据成为了企业竞争的核心资源。在这个背景下,大数据知 识工程应运而生。作为我的搜索伙伴,读完《大数据知识工程》这本书后,我深 受启发,对大数据知识工程有了更深入的认识和理解。
这本书的作者具有极高的专业素养和严谨的学术态度。他们不仅具备扎实的 理论基础,而且拥有丰富的实践经验。在阐述大数据知识工程的概念、技术和应 用时,他们运用了通俗易懂的语言和生动的案例,使得读者能够轻松理解和掌握。
本书主要讨论了大数据知识工程的相关主题和关键问题,包括数据预处理、数据存储、数据处理 和分析、数据挖掘、机器学习和人工智能等方面。本书不仅介绍了这些技术的理论知识,还通过 具体案例和实践经验,阐述了如何将这些技术应用到实际的大数据工程中。本书还强调了大数据 安全和隐私保护的重要性,并提出了一些解决方案。
大数据安全和隐私保护是大数据知识工程中至关重要的一环,需要采取一系列有效的技术和管理 措施来保障数据的安全性和隐私性。
大数据知识工程是一个充满挑战和机遇的领域,需要不断深入研究和实践创新。
通过综合运用多学科知识和先进的技术手段,可以实现大数据的高效处理和深度分析,从而为决 策提供有力支持。
大数据安全和隐私保护是大数据知识工程中至关重要的一环,需要引起足够的重视并采取有效的 措施来保障数据的安全性和隐私性。
本书为读者提供了全面、系统的大数据知识工程方面的知识和技能,可以帮助读者更好地理解和 应用大数据技术,从而为未来的大数据发展做出贡献。
《大数据知识工程》这本书是一本非常全面、系统和深入的大数据知识工程领域的著作。通过阅 读这本书,读者将获得关于大数据知识工程方面的深入理解和实用技能,同时可以了解大数据在 未来的发展趋势和应用前景。这本书不仅适用于计算机科学和数学领域的专业人士,也适合于从 事大数据相关工作的企业家、学者和研究人员阅读。通过阅读这本书,读者将受益匪浅,并为未 来的大数据发展做出贡献。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
01
通过clusterid来判断DataNode是否归NameNode管理
02
心跳机制判断是否存活
若DataNode超过10分30秒未发送心跳,则判定DataNode宕机
03
保持block的副本数量
NameNode
维护目录树
DataNode
01
管理用户的文件 块
02
和NameNode保 持心跳,定期向 NameNode报告 块的存储情况
Zookeeper
是什么
Zookeeper分布式应用程序协调服务是Hadoop的一个子项目,为分布 式应用提供协调服务
Zookeeper
能做什么
分布式
01
共享锁
统一命
02
名服务
集群管
04
理
队列管
05
理
统一配
03
置管理
数据发
06
布订阅
Zookeeper
能做什么
负载均衡
集群管理
选举
服务器动态 上下线
大数据生态圈组件思维导 图
演讲人
2 0 2 5 - 11 - 11
01 Hadoop
Hadoop
是什么
Hadoop是Apache公司旗下的一套开源分布式计算软件
Hadoop
为什么产生
Hadoop
能做什么
它允许使用简单的编程模型去分布式地计算大数据集,用户可以利用 Hadoop服务器集群,编写自己的业务逻辑代码,就可以对海量数据进行 分布式处理
Ya r n
能做什么?
管理内存和CPU等资源
Yarn
怎么做?
结构?
01 ResourceManager
作用?
03 ApplicationMaster
作用?
02 NodeManager
作用?
04 Container
作用?
Ya r n
容错性
ResourceM anager
Application Master
HDFS
是什么
9,300 Million
单击此处添加标题
单击此处输入你的正文,文字是您思想 的提炼,为了最终演示发布的良好效果, 请尽量言简意赅的阐述观点;根据需要 可酌情增减文字,以便观者可以准确理 解您所传达的信息。
来源于谷歌发布的一篇论文GFS,是一 个可扩展的分布式文件系统
提供容错性机制,允许使用廉价的计算 机集群来为用户提供性能不错的文件存 取服务
它是一个文件系统,用来存储文件,通 过目录树来定位文件
HDFS
能做什么
为分布式运算框架提供文件存取服务
01
NameN ode
HDFS
结构
02
DataN ode
03
Second aryNam eNode
NameNode
响应客户端请求
NameN控DataNode状态
HDFS
运作机制
A
启动
B
运行 中
C
运行 异常
启动
NameNode的启动过 程 安全模式
安全模式是什么 安全模式能做什么 如何离开安全模式
运行中
01
check point
是什么 为什么产生
能做什么 怎么做
02
文件上 传到
HDFS
03
从HDFS 下载文件
运行异常
NameNode高可用(HA)
03 MapReduce
MapReduce
是什么
MapReduce
为什么产生
MapReduce
能做什么
结构
01 02 03 04 05
Resouce Manager
MR AppMaster
是什么 作用
NodeMa nager
M a p Ta s k
ReduceT ask
运作机制
运行中 MapReduce工作流程详解
高可靠
失败的任务重新分配
高可靠
其它
01
快照
02
回收站 机制
高扩展
停机增删节点 增加节点
删除节点 动态扩展节点
动态增加节点 动态删除节点
高效
块均匀分布 负载均衡
移动计算而非移动 数据
其它
适合大文件的批处理,不适合小文件存取及低延迟响应
一次写入,多次读取,不支持多用户写入,不支持修改,只支持 append
block副本数目到预期设置的副本数 DataNode会在文件创建后三周验证其校验和
网络和机器失效预防
1 多副本机制
安全模式
3 心跳感知
2 机架感知(副本存放)
同一个节点 不同机架 同第二个副本同机架的不同节点
4 checkpoint机制
NameNo de宕机
主备切换(HA) 是什么
为什么 做什么 怎么做 结构 特点 (多)磁盘存储fsimage和edits
SecondaryNam eNode
帮助NameNode合并日志
HDFS
特点
A
高可 靠
B
高扩 展
C
高效
D
其它
文件完整性
块校验和
文件在建立时,会在每个block上计算校验和,并保存在.meta文件中 客户端在读取block时,会将计算的block校验和与.meta文件中的校验和作比较,
若不匹配,则block损坏 若损坏,客户端可以读取其它副本,NameNode会标记该block已损坏,并复制
(mapTask+shuffle+ReduceTask ) MapReduce中ReadLine读取切片规 则
启动 MapReduce的Job提交
运行流程
04 Yarn
Ya r n
是什么?
Yarn是作业调度和集群资源管理的一个框架
Ya r n
为什么产生?
Ya r n 解 决 了 M R v 1 版 本 中 资 源 管 理 器 扩 展 性 差 , 单 点 故 障 以 及 只 能 局 限 于 MR计算框架等的问题
结构
Hadoop common
支持其他Hadoop模块的 常用工具
Ya r n
1 4
2 3
HDFS MapReduce
Hadoop
怎么做
Hadoop
特点
高可靠 可扩展
Hadoop
运作机制
A
启动
B
C
运行
运行
中
2
异常
D
运行 结束
02 HDFS
HDFS
是什么
结构
为什么 产生
特点
能做什 么
运作机 制
Zookeeper
怎么做?
为用户提交的数据节点提供监听功 能
管理(存储,读取)用户提交的数 据
Zookeeper
结构
A
B
C
D
Lea der
Follo wer
Sess ion
Zno de
Session
01
是什么?
02
Session 的四种
状态
Znode
是什么?
分类
按照存活时间 Persistent
NodeMana ger
Ya r n
运行在Yarn上的计算框 架
01 MapR educe
03 Storm
05 ...
02 Tez 04 Spark
运作机制
运行异常
Yarn的HA
05 Zookeeper
Zookeeper
是什么 怎么做?
为什么 产生?
结构
能做什 么
特点?
Zookeeper
运作机制