多元统计分析实验报告
多元统计数据分析报告(3篇)

第1篇一、引言随着大数据时代的到来,数据量急剧增加,传统的统计分析方法已无法满足复杂数据关系的挖掘需求。
多元统计分析作为一种处理多个变量之间关系的方法,在社会科学、自然科学、工程技术等领域得到了广泛应用。
本报告旨在通过对某研究项目的多元统计分析,揭示变量之间的关系,为决策提供科学依据。
二、研究背景与目的本研究以某企业员工绩效评估数据为研究对象,旨在通过多元统计分析方法,探究员工绩效与个人特质、工作环境等因素之间的关系,为企业人力资源管理部门提供决策支持。
三、数据与方法1. 数据来源本研究数据来源于某企业员工绩效评估系统,包括员工的基本信息、个人特质、工作环境、绩效评分等。
2. 研究方法本研究采用以下多元统计分析方法:(1)描述性统计分析:对员工绩效、个人特质、工作环境等变量进行描述性统计分析,了解数据的分布情况。
(2)相关分析:分析变量之间的线性关系,找出相关系数较大的变量对。
(3)因子分析:将多个变量归纳为少数几个因子,揭示变量之间的内在关系。
(4)聚类分析:将员工根据绩效、个人特质、工作环境等因素进行分类,分析不同类别员工的特点。
(5)回归分析:建立员工绩效与个人特质、工作环境等因素之间的回归模型,分析各因素对绩效的影响程度。
四、数据分析结果1. 描述性统计分析通过对员工绩效、个人特质、工作环境等变量的描述性统计分析,得出以下结论:(1)员工绩效评分呈正态分布,平均绩效评分为75分。
(2)个人特质得分集中在中等水平,其中创新能力得分最高,稳定性得分最低。
(3)工作环境得分普遍较高,其中工作压力得分最低。
2. 相关分析通过对员工绩效、个人特质、工作环境等变量进行相关分析,得出以下结论:(1)绩效与创新能力、稳定性、工作环境等因素呈正相关。
(2)创新能力与稳定性呈负相关。
3. 因子分析通过对员工绩效、个人特质、工作环境等变量进行因子分析,得出以下结论:(1)提取了3个因子,分别对应创新能力、稳定性、工作环境。
多元统计分析实验报告_聚类分析

武汉理工大学
实验(实训)报告项目名称实验2―聚类分析
实验报告2
聚类分析(设计性实验)
实验原理:聚类分析的目的是将分类对象按一定规则分为若干类,这些类不是事先给定的,而是根据数据的特征确定的。
在同一类里的这些对象在某种意义上倾向于彼此相似,而在不同的类里的对象倾向于不相似。
系统聚类法是聚类分析中用的最多的一种,其基本思想是:开始将n个对象各自作为一类,并规定对象之间的距离和类与类之间的距离,然后将距离最近的两类合并成一个新类,
E0
N20
(1
(2
(3
(4)用最大距离法将11种语言聚为3类,并将聚类结果存储在一个SPSS数据文件中。
实验题目二:
下表给出了2010年湖北省省各地区的人均各项消费支出情况。
表-1:2010年湖北省各地区人均各项消费支出
(1((2(3
(4
实验题目一分析报告:1.实验(实训)过程(步骤、记录、数据、程序等)
2.结论(结果、分析)
实验题目二分析报告:1.实验(实训)过程(步骤、记录、数据、程序等)
2.结论(结果、分析)。
多元统计分析 实验报告

多元统计分析实验报告1. 引言多元统计分析是一种用于研究多个变量之间关系的统计方法。
在实验中,我们使用了多元统计分析方法来探索一组数据中的变量之间的关系。
本报告将介绍我们的实验设计、数据收集和分析方法以及结果和讨论。
2. 实验设计为了进行多元统计分析,我们设计了一个实验,收集了一组相关变量的数据。
我们选择了X、Y和Z这三个变量作为我们的研究对象。
为了获得准确的结果,我们采用了以下实验设计:1.确定研究目的:我们的目标是探索X、Y和Z之间的关系,并确定它们之间是否存在任何相关性。
2.数据收集:我们通过调查问卷的方式收集了一组数据。
我们请参与者回答与X、Y和Z相关的问题,以获得关于这些变量的定量数据。
3.数据整理:在收集完数据后,我们将数据进行整理,将其转化为适合多元统计分析的格式。
我们使用Excel等工具进行数据整理和清洗。
4.数据验证:为了确保数据的准确性,我们对数据进行验证。
我们检查数据的有效性,比较数据之间的一致性,并排除任何异常值。
3. 数据分析在数据收集和整理完毕后,我们使用了一些常见的多元统计分析方法来分析我们的数据。
以下是我们使用的方法和步骤:1.描述统计分析:我们首先对数据进行了描述性统计分析。
我们计算了X、Y和Z的均值、标准差、最大值和最小值等。
这些统计量帮助我们了解数据的基本特征。
2.相关性分析:接下来,我们进行了相关性分析,以确定X、Y和Z之间是否存在相关关系。
我们计算了变量之间的相关系数,并绘制了相关系数矩阵。
这帮助我们确定变量之间的线性关系。
3.回归分析:为了更进一步地研究X、Y和Z之间的关系,我们进行了回归分析。
我们建立了一个多元回归模型,通过回归方程来预测因变量。
同时,我们还计算了回归系数和R方值,以评估模型的拟合度和预测能力。
4. 结果和讨论根据我们的实验设计和数据分析,我们得出了以下结果和讨论:1.描述统计分析结果显示,X的平均值为x,标准差为s;Y的平均值为y,标准差为s;Z的平均值为z,标准差为s。
多元统计实验报告

多元统计实验报告一、实验目的多元统计分析是统计学的一个重要分支,它能够处理多个变量之间的复杂关系。
本次实验的主要目的是通过实际操作和数据分析,深入理解多元统计分析的基本原理和方法,并掌握其在实际问题中的应用。
二、实验数据本次实验使用了一组来自某市场调研公司的数据集,包含了消费者的年龄、性别、收入、消费习惯等多个变量,共计_____个样本。
三、实验方法1、主成分分析(PCA)主成分分析是一种降维方法,它通过将多个相关变量转换为一组较少的不相关变量(即主成分),来简化数据结构并提取主要信息。
2、因子分析因子分析用于发现潜在的公共因子,这些因子能够解释多个观测变量之间的相关性。
3、聚类分析聚类分析将数据对象分组,使得同一组内的对象具有较高的相似性,而不同组之间的对象具有较大的差异性。
四、实验过程1、数据预处理首先,对原始数据进行了清洗和预处理,包括处理缺失值、异常值和数据标准化等操作,以确保数据的质量和可用性。
2、主成分分析使用统计软件进行主成分分析,计算出特征值、贡献率和累计贡献率。
根据特征值大于 1 的原则,确定了保留的主成分个数。
通过主成分载荷矩阵,解释了主成分的实际意义。
3、因子分析运用因子分析方法,提取公共因子,并通过旋转因子载荷矩阵,使得因子的解释更加清晰和具有实际意义。
计算因子得分,用于进一步的分析和应用。
4、聚类分析采用 KMeans 聚类算法,根据选定的变量对样本进行聚类。
通过不断调整聚类中心和重新分配样本,最终得到了较为合理的聚类结果。
五、实验结果与分析1、主成分分析结果提取了_____个主成分,它们累计解释了_____%的方差。
第一个主成分主要反映了_____,第二个主成分主要与_____相关,以此类推。
这为我们理解数据的主要结构提供了重要的线索。
2、因子分析结果成功提取了_____个公共因子,它们能够较好地解释原始变量之间的相关性。
每个因子所代表的潜在因素也得到了清晰的解释,有助于深入了解消费者的行为特征和市场结构。
《多元统计实验》主成分分析实验报告二

《多元统计实验》主成分分析实验报告三、实验结果分析6.5人均粮食产量x5,经济作物占农作物播种面积x6,耕地占土地面积比x7,果园与林地面积之比x8,灌溉田占1耕地面积比例x9等五个指标有较强的相关性, 人口密度x1,人均耕地面积x2,森林覆盖率x3,农民人均收入x4相关性也很强,再作主成分分析,求样本相关矩阵的特征值和主成分载荷。
λ11/2=2.158962,λ21/2=1.4455076,λ31/2 =1.0212708,λ41/2 =0.71233588,λ51/2 =0.5614001,λ61/2 =0.43887788,λ71/2 =0.33821497,λ81/2 =0.212900230,λ91/2=0.177406876。
确定主成分分析,前两个主成分的累积方差贡献率为75.01%,前三个主成分的累积方差贡献率为86.59%,按照累积方差贡献率大于80%的原则,主成分的个数取为3,前三个主成分分别为:Z*1=0.3432x*1-0.446x*3+0.376x*5+0.379x*6+0.432x*7+0.446x*9Z*2=0.368x*1-0.614x*2-0.61x*4-0.307x*5-0.1224x*6Z*3=-0.122x*6+0.246x*7-0.950x*8第一主成分在x*7,x*9两个指标上取值为正且载荷较大,可视为反映耕地占比和灌溉田占耕地面积比例的主成分,第二主成分在x*2和x*4这两个指标的取值为负,绝对值载荷最大,不能作为人均耕地和人均收入的主成分。
第三主成分,x*8这个指标取值为负且,载荷绝对值最大,不能反映果园与林地面积之比的主成分。
根据该图结果可以认为选取前两个指标作为主成分分析的选择是正确的。
将八个指标按前两个主成分进行分类:由结果可以得出森林覆盖率为一类,人口密度、果园与林地面积之比、耕地占土地面积比、灌溉田占耕地面积比为一类,经济作物占农作物播种面积比例、人均粮食产量、农民人均收入、人均耕地面积为一类。
计量经济实验报告多元(3篇)

第1篇一、实验目的本次实验旨在通过多元线性回归模型,分析多个自变量与因变量之间的关系,掌握多元线性回归模型的基本原理、建模方法、参数估计以及模型检验等技能,提高运用计量经济学方法解决实际问题的能力。
二、实验背景随着经济的发展和社会的进步,影响一个变量的因素越来越多。
在经济学、管理学等领域,多元线性回归模型被广泛应用于分析多个变量之间的关系。
本实验以某地区居民消费支出为例,探讨影响居民消费支出的因素。
三、实验数据本实验数据来源于某地区统计局,包括以下变量:1. 消费支出(Y):表示居民年消费支出,单位为元;2. 家庭收入(X1):表示居民家庭年收入,单位为元;3. 房产价值(X2):表示居民家庭房产价值,单位为万元;4. 教育水平(X3):表示居民受教育程度,分为小学、初中、高中、大专及以上四个等级;5. 通货膨胀率(X4):表示居民消费价格指数,单位为百分比。
四、实验步骤1. 数据预处理:对数据进行清洗、缺失值处理和异常值处理,确保数据质量。
2. 模型设定:根据理论知识和实际情况,建立多元线性回归模型:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为因变量,X1、X2、X3、X4为自变量,β0为截距项,β1、β2、β3、β4为回归系数,ε为误差项。
3. 模型估计:利用统计软件(如SPSS、R等)对模型进行参数估计,得到回归系数的估计值。
4. 模型检验:对估计得到的模型进行检验,包括以下内容:(1)拟合优度检验:通过计算R²、F统计量等指标,判断模型的整体拟合效果;(2)t检验:对回归系数进行显著性检验,判断各变量对因变量的影响是否显著;(3)方差膨胀因子(VIF)检验:检验模型是否存在多重共线性问题。
5. 结果分析:根据模型检验结果,分析各变量对因变量的影响程度和显著性,得出结论。
五、实验结果与分析1. 拟合优度检验:根据计算结果,R²为0.812,F统计量为30.456,P值为0.000,说明模型整体拟合效果较好。
多元统计课程实验报告

一、实验背景随着社会经济的发展和科学技术的进步,数据量日益庞大,如何从大量数据中提取有价值的信息,成为统计学研究的热点问题。
多元统计分析作为统计学的一个重要分支,通过对多个变量之间的关系进行分析,为决策者提供有力的数据支持。
本实验旨在通过实际操作,让学生熟练掌握多元统计分析方法,提高数据分析能力。
二、实验目的1. 掌握多元统计分析的基本概念和方法;2. 学会运用多元统计分析方法解决实际问题;3. 提高数据分析能力,为后续课程打下坚实基础。
三、实验内容本次实验以某城市居民消费数据为例,运用多元统计分析方法对其进行分析。
四、实验步骤1. 数据导入首先,将实验数据导入统计软件(如SPSS、R等)。
本实验采用SPSS软件,数据集包含以下变量:(1)收入(y):居民年收入;(2)教育程度(x1):居民最高学历;(3)年龄(x2):居民年龄;(4)家庭人口(x3):家庭人口数量;(5)住房面积(x4):家庭住房面积。
2. 描述性统计分析对数据集进行描述性统计分析,包括各变量的均值、标准差、最大值、最小值等。
3. 相关性分析运用皮尔逊相关系数、斯皮尔曼等级相关系数等方法,分析变量之间的相关关系。
4. 主成分分析运用主成分分析方法,提取主要成分,降低数据维度。
5. 聚类分析运用K-means聚类分析方法,将居民划分为不同的消费群体。
6. 随机森林回归分析运用随机森林回归分析方法,预测居民收入。
五、实验结果与分析1. 描述性统计分析根据描述性统计分析结果,可知居民年收入、教育程度、年龄、家庭人口、住房面积的平均值、标准差、最大值、最小值等。
2. 相关性分析通过相关性分析,发现收入与教育程度、年龄、家庭人口、住房面积之间存在显著的正相关关系。
3. 主成分分析根据主成分分析结果,提取出两个主成分,累计方差贡献率为84.95%,可以解释大部分的变量信息。
4. 聚类分析通过K-means聚类分析,将居民划分为3个消费群体。
多元统计分析——典型相关分析实验报告
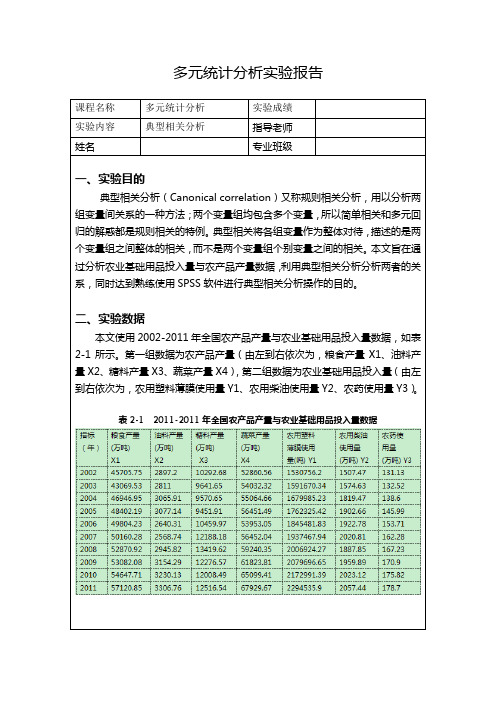
多元统计分析实验报告课程名称多元统计分析实验成绩实验内容典型相关分析指导老师姓名专业班级一、实验目的典型相关分析(Canonical correlation)又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。
典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,而不是两个变量组个别变量之间的相关。
本文旨在通过分析农业基础用品投入量与农产品产量数据,利用典型相关分析分析两者的关系,同时达到熟练使用SPSS软件进行典型相关分析操作的目的。
二、实验数据本文使用2002-2011年全国农产品产量与农业基础用品投入量数据,如表2-1所示。
第一组数据为农产品产量(由左到右依次为,粮食产量X1、油料产量X2、糖料产量X3、蔬菜产量X4),第二组数据为农业基础用品投入量(由左到右依次为,农用塑料薄膜使用量Y1、农用柴油使用量Y2、农药使用量Y3)。
表2-1 2011-2011年全国农产品产量与农业基础用品投入量数据由于cancorr不能读取中文名称,所以变量名均需为英文名。
将表2-1数据转换为能够进行典型相关分析形式的数据,如表2-2所示。
表2-2 典型相关分析数据(农产品产量与农业基础用品投入量数据)三、实验过程SPSS 16.0并未提供典型相关分析的交互窗口,只能直接在syntax editor 窗口呼叫SPSS的CANCORR程序来执行分析。
选择【File】—【New】—【Syntax】,弹出Syntax对话框,在对话框中写入调用Cancorr程序,如图3-1所示。
图3-1 Syntax窗口调用CONCORR函数四、实验结果表4-1为第一组数据,即农产品产量之间的相关关系表。
从表中可以看出,粮食产量(X1)与蔬菜产量(X4)有较高的相关关系,相关系数高达0.9035;粮食产量(X1)与糖料产量(X3)相关关系也较大,相关系数为0.8081;油料产量(X2)与蔬菜产量(X4)的相关关系较大,为0.7442。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多元统计分析实验报告
1、实验内容
根据课本习题3-12做相关分析。
2、实验目的 (1)检验H0:;H1:协方差阵不全相等。
(2)检验H0: U1=U2 ; H1:U1≠U2;
(3)检验H0: U1=U2 =U3 ; H1:U1,U2,U3不全等; (4)检验三种化学成分相互独立。
3、实验方案分析
(1)这是关于判断三个3元正态总体的协方差阵是否相等的问题; (2)均值是否相等,在两个协方差阵相等的情况下均值是否相等的问题;
(3)比较三组的3项指标是否有差异的问题,就是多总体均值向量是否相等的检验问题;
(4)检验 是否独立相当于检验任意2个子向量的协方差阵是否为零矩阵;
4、实验原理及操作过程,结果如下: (1)SAS 代码实现过程如下:
data d3121;
input y1-y3 group @@; cards;
47.22 5.06 0.10 1
1
23
==∑∑∑
47.45 4.35 0.15 1
47.52 6.85 0.12 1
47.86 4.19 0.17 1
47.31 7.57 0.18 1
54.33 6.22 0.12 2
56.17 3.31 0.15 2
54.40 2.43 0.22 2
52.62 5.92 0.12 2
43.12 10.33 0.05 3
42.05 9.67 0.08 3
42.50 9.62 0.02 3
40.77 9.68 0.04 3
;
proc iml;
n1=5;n2=4;n3=4;
n=n1+n2+n3;k=3; p=3;
use d3121(obs=5);
xa={y1 y2 y3 };
read all var xa into x1; print x1; use d3121(firstobs=6 obs=9);
read all var xa into x2; print x2; use d3121(firstobs=10 obs=13);
read all var xa into x3; print x3; xx=x1//x2//x3;
ln={[5] 1} ;
x10=(ln*x1)/n1; print x10;
mm1=i(n1)-j(n1,n1,1)/n1;
mm=i(n)-j(n,n,1)/n;
a1=x1`*mm1*x1; print a1;
ln={[4] 1} ;
x10=(ln*x2)/n2; print x20;
mm2=i(n2)-j(n2,n2,1)/n2;
a2=x2`*mm2*x2; print a2;
ln={[4] 1} ;
x10=(ln*x3)/n3; print x30;
mm3=i(n3)-j(n3,n3,1)/n3;
a3=x3`*mm3*x3; print a3;
tt=xx`*mm*xx; print tt;
a=a1+a2+a3;
print a;
da=det(a/(n-k));
da1=det(a1/(n1-1));
da2=det(a2/(n2-1));
da3=det(a3/(n3-1));
m=(n-k)*log(da)-(4*log(da1)+3*log(da2)+3*log(da3)); dd=(2*p*p+3*p-1)*(k+1)/(6*(p+1)*(n-k));
df=p*(p+1)*(k-1)/2;
kc=(1-dd)*m;
print da da1 da2 da3;
print m dd df ;
p0=1-probchi(kc,df);
print kc p0;
quit;
(2)代码实现(数据省略(1)相同)
proc iml;
n=5;m=4; p=3;
use d3122(obs=5);
xx={x1 x2 x3};
read all var xx into x; print x;
ln={[5] 1} ;
x0=(ln*x)/n; print x0;
mx=i(n)-j(n,n,1)/n;
a1=x`*mx*x; print a1;
use d3122(firstobs=6);
read all var xx into y; print y;
lm={[4] 1} ;
y0=(lm*y)/m; print y0;
my=i(m)-j(m,m,1)/m;
a2=y`*my*y; print a2;
a=a1+a2; xy=x0-y0;
ai=inv(a); print a ai;
dd=xy*ai*xy`; d2=(m+n-2)*dd;
t2=n*m*d2/(n+m) ;
f=(n+m-1-p)*t2/((n+m-2)*p);
print d2 t2 f;
pp=1-probf(f,p,m+n-p-1);
print pp; 7
quit;
(3)代码实现如下:
title ' "应用多元统计分析" p104 312(3)'; proc iml;
n1=5;n2=4; n3=4;
p=3; k=3;
n=n1+n2+n3;
xa={ 47.22 5.060.10 ,
47.45 4.350.15 ,
47.52 6.850.12 ,
47.86 4.190.17 ,
47.317.570.18 };
xb={ 54.33 6.220.12 ,
56.17 3.310.15 ,
54.40 2.430.22 ,
52.62 5.920.12 };
xc={ 43.1210.330.05 ,
42.059.670.08 ,
42.509.620.02 ,
40.779.680.04 };
xx=xa//xb//xc;
ln1={[5] 1} ; ln2={[4] 1};
lnn= {[13] 1};
xa0=(ln1*xa)/n1; print xa0;
xb0=(ln2*xb)/n2; print xb0;
xc0=(ln2*xc)/n3; print xc0;
xx0=(lnn*xx)/n; print xx0;
mm1=i(n1)-j(n1,n1,1)/n1;
mm2=i(n2)-j(n2,n2,1)/n2;
mm=i(n)-j(n,n,1)/n;
a1=xa`*mm1*xa; print a1;
a2=xb`*mm2*xb; print a2;
a3=xc`*mm2*xc; print a3;
tt=xx`*mm*xx; print tt;
a=a1+a2+a3; print a;
da=det(a);
dt=det(tt); a0=da/dt;
print da dt a0;
b=sqrt(a0);
f3=(n-k-p+1)*(1-b)/(b*p);
df1=2*p; df2=2*(n-k-p+1);
print df1 df2;
p3=1-probf(f3,df1,df2);
print f3 p3;
(4)的代码实现如下:
title ' "应用多元统计分析" p104 312(4)';
proc iml;
n=13; p=3;
x={47.22 5.060.10, 47.45 4.350.15, 47.52 6.850.12, 47.86 4.190.17,
47.317.570.18, 54.33 6.220.12, 56.17 3.310.15, 54.40 2.430.22,
52.62 5.920.12, 43.1210.330.05, 42.059.670.08, 42.509.620.02,
40.779.680.04 };
ln={[13] 1} ;
x0=(ln*x)/n; print x0;
mm=i(13)-j(13,13,1)/n;
a=x`*mm*x; print a;
a0=det(a); print a0;
a1=a[1,1]*a[2,2]*a[3,3];
v=a0/a1; print v;
b=n-1.5-(p*p*p-3)/(3*p*p-3*3);
df=0.5*(p*(p+1)-2*3);
kc=-b*log(v);
print b df kc;
p0=1-probchi(kc,df);
print p0;
quit;
5、实验结果
(1)
M=24.52397,d=0.4333,X2=13.8969,p=0.30793>0.05,
故H0相容,
(2)因为P=0,001083<0.05,故否定H0,即A和B地区地区岩石的化学成分有显著差异。
(3)因为p=0.00002345<0.5,故否定H0,即A和B,C三个地区地区
岩石的化学成分有显著差异。