SPSS线性回归分析案例
SPSS多元线性回归分析实例操作步骤
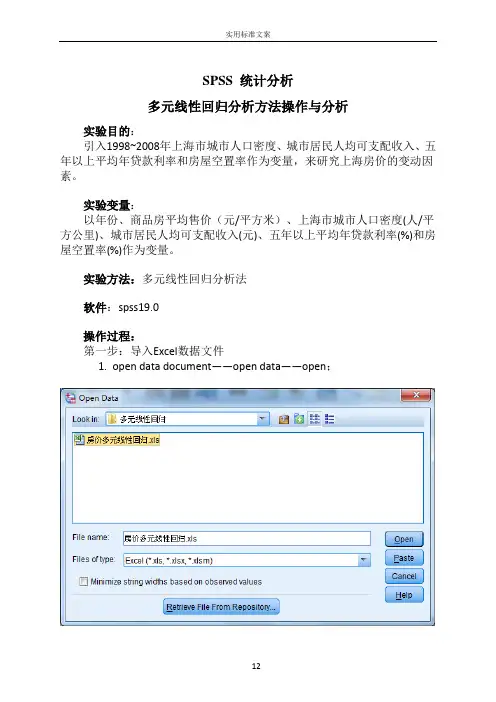
SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析:1.引入/剔除变量表Variables Entered/Removed aModel Variables Entered Variables Removed Method1 城市人口密度(人/平方公里) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).2 城市居民人均可支配收入(元) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).a. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
SPSS多元线性回归分析报告实例操作步骤
SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析:1.引入/剔除变量表Variables Entered/Removed aModel Variables Entered Variables Removed Method1 城市人口密度(人/平方公里) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).2 城市居民人均可支配收入(元) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).a. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
《SPSS统计分析》第11章 回归分析

返回目录
多元逻辑斯谛回归
返回目录
多元逻辑斯谛回归的概念
回归模型
log( P(event) ) 1 P(event)
b0
b1 x1
b2 x2
bp xp
返回目录
多元逻辑斯谛回归过程
主对话框
返回目录
多元逻辑斯谛回归过程
参考类别对话框
保存对话框
返回目录
多元逻辑斯谛回归过程
收敛条件选择对话框
创建和选择模型对话框
返回目录
曲线估计
返回目录
曲线回归概述
1. 一般概念 线性回归不能解决所有的问题。尽管有可能通过一些函数
的转换,在一定范围内将因、自变量之间的关系转换为线性关 系,但这种转换有可能导致更为复杂的计算或失真。 SPSS提供了11种不同的曲线回归模型中。如果线性模型不能确 定哪一种为最佳模型,可以试试选择曲线拟合的方法建立一个 简单而又比较合适的模型。 2. 数据要求
线性回归分析实例1输出结果2
方差分析
返回目录
线性回归分析实例1输出结果3
逐步回归过程中不在方程中的变量
返回目录
线性回归分析实例1输出结果4
各步回归过程中的统计量
返回目录
线性回归分析实例1输出结果5
当前工资变量的异常值表
返回目录
线性回归分析实例1输出结果6
残差统计量
返回目录
线性回归分析实例1输出结果7
返回目录
习题2答案
使用线性回归中的逐步法,可得下面的预测商品流通费用率的回归系数表:
将1999年该商场商品零售额为36.33亿元代入回归方程可得1999年该商场 商品流通费用为:1574.117-7.89*1999+0.2*36.33=4.17亿元。
一元线性回归案例spss
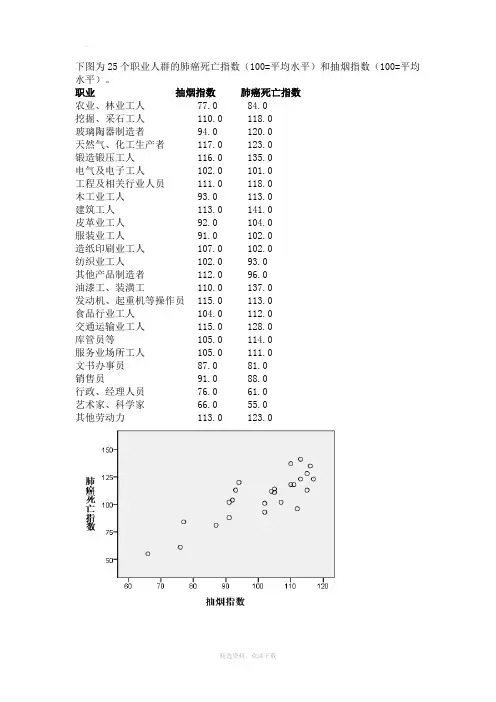
下图为25个职业人群的肺癌死亡指数(100=平均水平)和抽烟指数(100=平均水平)。
职业抽烟指数肺癌死亡指数农业、林业工人77.0 84.0挖掘、采石工人110.0 118.0玻璃陶器制造者94.0 120.0天然气、化工生产者117.0 123.0锻造锻压工人116.0 135.0电气及电子工人102.0 101.0工程及相关行业人员111.0 118.0木工业工人93.0 113.0建筑工人113.0 141.0皮革业工人92.0 104.0服装业工人91.0 102.0造纸印刷业工人107.0 102.0纺织业工人102.0 93.0其他产品制造者112.0 96.0油漆工、装潢工110.0 137.0发动机、起重机等操作员115.0 113.0食品行业工人104.0 112.0交通运输业工人115.0 128.0库管员等105.0 114.0服务业场所工人105.0 111.0文书办事员87.0 81.0销售员91.0 88.0行政、经理人员76.0 61.0艺术家、科学家66.0 55.0其他劳动力113.0 123.0散点图呈线性关系令Y=肺癌死亡指数,X=抽烟指数,做线性回归分析如下:表2中R=0.839 表示两变量高度相关R方=0.703 表示拟合较好,散点相对集中于回归线表3中sig.<0.05 则自变量与因变量具有显著的线性关系,即可以用回归模型表示表4中自变量sig.<0.05 则自变量对因变量的线性影响是显著的由此得到抽烟指数及肺癌死亡指数的一元回归方程:Y=-24.421+1.301X即抽烟指数每变动一个单位则肺癌死亡指数平均变动1.301个单位Welcome !!! 欢迎您的下载,资料仅供参考!。
SPSS实验多元线性回归分析12
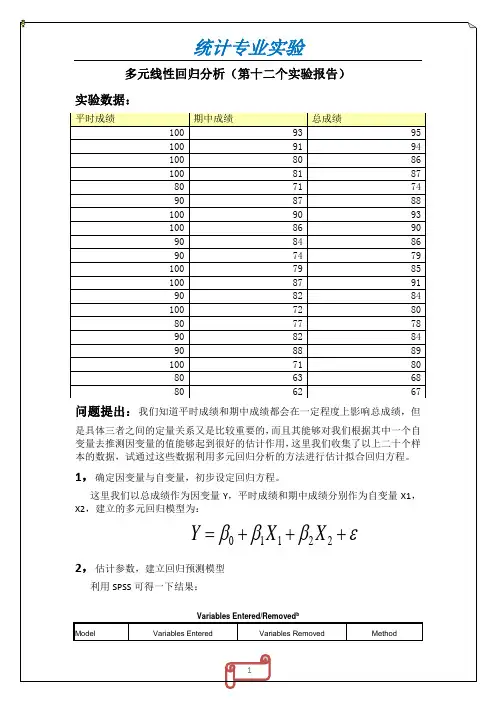
这里我们以总成绩作为因变量Y,平时成绩和期中成绩分别作为自变量X1,X2,建立的多元回归模型为:
Байду номын сангаас2,估计参数,建立回归预测模型
利用SPSS可得一下结果:
Variables Entered/Removedb
Model
Variables Entered
Variables Removed
1183.800
19
a. Predictors: (Constant),期中成绩,平时成绩
b. Dependent Variable:总成绩
注释:从表中可得拟合方程的F统计量值为7.586,相应的P值为0.000说明,拟合方程是显著的。是具有统计意义的。
Coefficientsa
Model
Unstandardized Coefficients
Method
1
期中成绩,平时成绩a
.
Enter
a. All requested variables entered.
b. Dependent Variable:总成绩
注释:根据这个表的结果我们可以初步的知道,经过检验自变量X1,X2是可以加入到准备估计的回归方程中作为变量的。
Model Summaryb
Standardized Coefficients
t
Sig.
95% Confidence Interval for B
Correlations
Collinearity Statistics
B
Std. Error
Beta
Lower Bound
Upper Bound
Zero-order
SPSS多元线性回归分析报告实例操作步骤
SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent (因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析: 1.引入/剔除变量表该表显示模型最先引入变量城市人口密度 (人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
SPSS实现一元线性回归分析实例
SPSS实现一元线性回归分析实例2009-12-14 15:311、准备原始数据。
为研究某一大都市报开设周日版的可行性,获得了34种报纸的平日和周日的发行量信息(以千为单位)。
数据如图1所示。
SPSS17.0图12、判断是否存在线性关系。
制作直观散点图:(1)SPSS:菜单Analyze/Regression/linear Regression,如图2所示:图2 (2)打开对话框如图3图3图3中,Dependent是因变量,Independent是自变量,分别将左栏中的sunday选入因变量,daily选入自变量,newspaper作为标识标签选入case labels.(3)点击图3对话框中的plots按钮,如图4所示:图4将因变量DEPENTENT 选入Y:,自变量 ZPRED 选入X: continue 返回上级对话框。
单击主对话框OK.便生成散点图如图5所示:图5从以上散点图可看出,二者变量之间关系趋势呈线性关系。
2、回归方程菜单Analyze/Regression/linear Regression,在图3对话框的右边单击statistics如图6所示:图6regression coefficient回归系数,estimates估计值,confidence intervals level:95%置信区间,model fit拟合模型。
点击continue返回主对话框,单击OK.结果如图7、图8所示:图7图7中第一个图是变量的输入与输出,从图下的提示可知所有变量均输入与输出,没有遗漏。
图7中的第二图是模型总和R值,R平方值,R调整后的平方值,及标准误。
图8图8中第一图为方差统计图,包括回归平方和,自由度,方程检验F值及P值。
图8第二图为回归参数图,从图中可知,constant为回归方程截距,即13.836,回归系数为1.340,标准误分别为:35.804和0.071,及t检验值和95%的置信区间的最大值和最小值。
SPSS回归分析案例
偏度偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。
表征概率分布密度曲线相对于平均值不对称程度的特征数。
直观看来就是密度函数曲线尾部的相对长度。
正偏离(右偏态)、负偏离(左偏态):正态分布的偏度为为0,两侧尾部长度对称。
若以bs表示偏度。
bs<0称分布具有负偏离,也称左偏态,此时数据位于均值左边的比位于右边的少,直观表现为左边的尾部相对于与右边的尾部要长,因为有少数变量值很小,使曲线左侧尾部拖得很长;bs>0称分布具有正偏离,也称右偏态,此时数据位于均值右边的比位于左边的少,直观表现为右边的尾部相对于与左边的尾部要长,因为有少数变量值很大,使曲线右侧尾部拖得很长;而bs接近0则可认为分布是对称的。
若知道分布有可能在偏度上偏离正态分布时,可用偏离来检验分布的正态性。
右偏时一般算术平均数>中位数>众数,左偏时相反,即众数>中位数>平均数。
计算:1.2.其中:而,数学期望所以:举个栗子(见excel表中):Χ2分布,t分布,F分布Χ2分布:t分布:F分布:关于p分为点决定系数(coefficient of determination)有的教材上翻译为判定系数,也称为拟合优度,决定系数是指在x或y的总变异中,可以相互以直线关系说明的部分所占的比率。
即在Y的总平方和中,由X引起的平方和所占的比例,记为R^2(R的平方)。
当R^2越接近1时,表示相关的方程式参考价值越高,越符合回归线。
计算:RSS = (回归平方和)TSS = (总离差平方和)区别:SPSS-线性回归(举个栗子)例1. 某分公司连续6年记录了员工的平均工资,数据如下表,试建立线性回归模型。
操作步骤(1)定义变量:年份定义为x,工资定义为y,点击“变量试图”,定义x,y变量;(2)数据录入:点击“数据视图”,输入x,y对应的数据;(3)线性回归准备:“分析”->“回归”->“线性”,打开“线性回归”的对话框;(4)线性回归:选择因变量y进入“因变量”栏中,选择自变量x进入“自变量”栏中,单击右上角的“statics”统计对话框可以选择要计算的统计数据,最后单击左下角的“确定”按钮;(5)结果分析(α系数默认为0.05):图1图2图3图4图2中R^2是0.995,表明Y的总平方和中,由X引起的平方和所占的比例为99.5%。
SPSS线性回归分析
SPSS线性回归
一、回归的原理
回归(Regression,或Linear Regression)和相关都用来分析两个定距变 量间的关系,但回归有明确的因果关系假设。 即要假设一个变量为自变量,一个为因变量, 自变量对因变量的影响就用回归表示。如年龄 对收入的影响。由于回归构建了变量间因果关 系的数学表达,它具有统计预测功能。
1.000
Age of Respondent
-.002
Highest Year of School Co mp l ete d
.559
Highest Year School Completed, Father
.227
Highest Year School Completed, Mother
.175
Highest Year School Completed, Spouse
.000
Highest Year School Completed, Mother
.001
Highest Year School Completed, Spouse
.000
R's Federal Income Tax
.458
R's Occupational Prestige Score (1980)
Highest Year School
Co mp l ete d , Father
Highest Year School
Co mp l ete d , M oth er
Highest Year School
Co mp l ete d , Spouse
一元线性回归分析例题
SPSS一元线性回归分析例题(体检数据中的体重和肺活量的分析)某单位对12名女工进行体检,体检项目包括体重(kg)和肺活量(L),数据如下:X(体重:kg) 42.00 42.00 46.00 46.00 46.00 50.0050.00 50.00 52.00 52.00 58.00 58.00Y(肺活量:L) 2.55 2.20 2.75 2.40 2.80 2.813.41 3.10 3.46 2.85 3.50 3.00用x表示体重,y表示肺活量,建立数据文件。
利用一元线性回归分析描述其关系。
基本操作提示:Step 1 建立数据文件,并打开该数据文件。
Step 2 选择菜单Analyz e→Regressio n→Linear,打开主对话框。
在“Dependent”(因变量)列表框中选择变量“肺活量”,作为线性回归分析的被解释变量;在“Independent”(自变量)列表框中选择变量“体重”,作为解释变量。
Step 3 单击“Statistics”按钮,在打开的对话框中,依次选择“Estimates”(显示回归系数的估计值)、“Confidence intervals”、“Model fit”(模型拟合)、“Descriptives”、“Casewise diagnostic”(个案诊断)和“All Cases”选项。
选择完毕后,单击“Continue”按钮,返回主对话框。
Step 4 单击“Plots”(图形)按钮,在打开的主对话框中,选择“DEPENDENT”(因变量)作为y轴变量,“*ZPRED”(标准化预测值)作为x轴变量;并在“Standardized Residual Plots”(标准化残差图)中选择“Histogram”(直方图)和“Normal probabilityplot”(正态概率图,即P-P图)选项。
选择完毕后,单击“Continue”按钮,返回主对话框。
Step 5 单击“Save”(保存)按钮,在打开的主对话框中,在“Predicted Values”(预测值)选项区域中选择“Unstandardized”和“S. E. ofmean predictions”(预测值均数的标准误差)选项;“PredictionIntervals”(预测区间)选项区域中选择“Mean”和“Individual”选项;“Residuals”(残差)选项区域中选择“Unstandardized”选项。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
回归分析
实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析
【研究目的】
居民消费在社会经济的持续发展中有着重要的作用。
影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。
【模型设定】
:
我们研究的对象是各地区居民消费的差异。
由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。
模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。
从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。
1、实验数据
表1:
—
2010年中国各地区城市居民人均年消费支出和可支配收入
|
数据来源:《中国统计年鉴》2010年
2、实验过程
作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2
模型汇总b
—
模型
R R方调整R方标准估计的误差
-
1
.965a.932.930
~
a.预测变量:(常量),可支配收入X(元)。
b.因变量:消费性支出Y(元)
表3
相关性
、
消费性支出Y
(元)
可支配收入X(元)
Pearson相关
性消费性支出Y(元)& .965
!
从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
表4
系数a
3、结果分析
表2模型汇总:相关系数为,判定系数为,调整判定系数为,估计值的标准误
表3是相关分析结果。
消费性支出Y与可支配收入X相关系数为,相关性很高。
表4是回归分析中的系数:常数项b=,可支配收入X的回归系数a=。
a的标准误差为,回归系数t的检验值为,P值为0,满足95%的置信区间,可认为回归系数有显著意义。
得线性回归方程Y=+.【实验结论】
(1)结果显示,变量之间具有如下关系式:Y=+.也就是说消费与收入之间存在稳定的函数关系。
随着收入的增加,消费将增加,但消费的增长低于收入的增长。
这与凯尔斯的绝对收入消费理论刚好吻合。
但为了研究方便,这里假设边际消费倾向为常数。
由公式知X每
增长1个单位,Y增加个单位。
(2)居民可支配收入是影响消费支出的最主要因素。
因此,要大力发展经济,增加居民的可支配收入特别是提高低收入居民群体的收入,才能最大限度发挥消费对经济的拉动效应,促进消费的持续。
有效增长。
(3)居民的边际消费倾向数值越大,增加1单位居民可支配收入所引起的居民消费支出也越大。
因此,政府可以实行一定的经济政策来增强居民的消费能力。
(4)在上述分析的基础上,可以进行更深入的分析。
比如整理各地区食物支出总额,算出各地区食物支出总额占个人消费支出总额的比重,也就是恩格尔系数来说明经济发展、收入增加对生活消费的影响程度。
一个地区的恩格尔系数越小,就说明这个地区经济越富裕。