语音质量评估
语音识别评价指标

语音识别评价指标全文共四篇示例,供读者参考第一篇示例:随着信息技术的不断发展和普及,语音识别技术也逐渐成为人们生活和工作中不可或缺的一部分。
语音识别评价指标在评估和优化语音识别系统的性能方面发挥着至关重要的作用。
本文将对语音识别评价指标进行详细介绍和分析,希望能够帮助读者更好地了解和应用这些指标。
一、语音识别评价指标的定义语音识别评价指标是用于评估语音识别系统性能的一组指标,通常包括识别准确率、识别速度、鲁棒性、实时性等方面的指标。
这些指标通过对语音识别系统在不同场景和条件下的表现进行综合评估,帮助评估人们对语音识别系统的满意程度和认可度。
1. 识别准确率:识别准确率是衡量语音识别系统在识别语音内容方面的准确性的重要指标。
通常用WER(Word Error Rate)或PER (Phone Error Rate)等指标来衡量,值越小表示系统在识别语音内容上的准确性越高。
2. 识别速度:识别速度是指语音识别系统完成一次识别任务的时间消耗,通常以每秒识别字数(WPS)或每秒识别帧数(FPS)来衡量。
识别速度越快表示系统处理能力越强,用户体验也会更好。
3. 鲁棒性:鲁棒性是指语音识别系统在面对各种噪声环境、不同说话人和口音等情况下的稳定性和可靠性。
在评估语音识别系统性能时,鲁棃性是一个非常重要的指标,因为现实生活中的语音输入往往会受到多种干扰。
4. 实时性:实时性是指语音识别系统完成一次识别任务的响应时间,通常以响应时间或延迟时间来衡量。
实时性对于一些需要快速响应的应用场景(如语音识别助手、电话客服等)来说非常重要。
5. 用户体验:用户体验是评价语音识别系统是否符合用户期望和需求的重要指标。
包括系统的易用性、用户界面设计、交互体验等方面,对于提升用户满意度和使用率具有重要意义。
1. 优化系统性能:通过对语音识别评价指标的监测和分析,可以帮助研究者和开发者了解系统存在的问题和不足之处,并进行针对性的优化和改进,以提升系统整体性能。
语音识别中的语音合成质量评估与优化

语音合成是语音识别中的一项重要应用,其质量评估与优化对于提高语音交互系统的整体性能具有重要意义。
下面将分别介绍语音合成质量评估与优化的方法、当前面临的挑战以及未来的研究方向。
一、语音合成质量评估1. 评价指标语音合成质量的评估通常采用以下几种评价指标:(1)清晰度指数(Clarity Index,CI):用于衡量语音的清晰度,数值越高,说明语音质量越好。
(2)自然度指数(Naturalness Index,NI):用于衡量语音的自然程度,数值越高,说明语音越接近人类发音。
(3)信噪比(Signal-to-Noise Ratio,SNR):用于衡量语音信号的质量,数值越高,说明语音信号的纯净度越高。
2. 评估方法常见的语音合成质量评估方法包括主观评估和客观评估。
主观评估是通过人类听觉对语音质量进行评分,但评估结果易受评估人员的主观因素影响。
客观评估则是通过分析语音信号的特征来进行评估,如使用声学模型对语音信号进行建模,再利用机器学习算法对模型输出进行评分。
二、语音合成优化1. 技术手段为了提高语音合成质量,可以采用以下技术手段:(1)使用高质量的语音数据集进行训练,提高声学模型的性能。
(2)采用先进的信号处理技术,如噪声抑制、回声消除等,提高语音信号的纯净度。
(3)利用深度学习技术,如循环神经网络(RNN)、长短期记忆网络(LSTM)等,提高声学模型的自适应学习能力。
2. 优化策略在优化过程中,可以采用以下策略:(1)针对不同的应用场景,选择合适的声学模型和优化算法,以提高语音合成的性能。
(2)采用多模态数据集进行训练,提高声学模型的泛化能力。
(3)对语音合成结果进行反馈,不断优化声学模型和语言模型,提高语音合成的自然度和清晰度。
三、挑战与未来研究方向当前,语音合成质量评估与优化仍面临一些挑战,如评估标准的制定、多语言场景下的适应性、情感表达的准确性等。
未来研究方向包括:1. 开发更加客观、准确的评估方法,以减少主观因素的影响。
语音质量评估

语⾳质量评估语⾳质量评估,就是通过⼈类或⾃动化的⽅法评价语⾳质量。
在实践中,有很多主观和客观的⽅法评价语⾳质量。
主观⽅法就是通过⼈类对语⾳进⾏打分,⽐如MOS、CMOS和ABX Test。
客观⽅法即是通过算法评测语⾳质量,在实时语⾳通话领域,这⼀问题研究较多,出现了诸如如PESQ和P.563这样的有参考和⽆参考的语⾳质量评价标准。
在语⾳合成领域,研究的⽐较少,论⽂中常常通过展⽰频谱细节,计算MCD(mel cepstral distortion)等⽅法作为客观评价。
所谓有参考和⽆参考质量评估,取决于该⽅法是否需要标准信号。
有参考除了待评测信号,还需要⼀个⾳质优异的,没有损伤的参考信号;⽽⽆参考则不需要,直接根据待评估信号,给出质量评分。
近些年也出现了MOSNet等基于深度⽹络的⾃动语⾳质量评估⽅法。
语⾳质量评测⽅法以下简单总结常⽤的语⾳质量评测⽅法。
主观评价:MOS[1], CMOS, ABX Test客观评价有参考质量评估(intrusive method):ITU-T P.861(MNB), ITU-T P.862(PESQ)[2], ITU-T P.863(POLQA)[3], STOI[4], BSSEval[5]⽆参考质量评估(non-intrusive method)传统⽅法基于信号:ITU-T P.563[6], ANIQUE+[7]基于参数:ITU-T G.107(E-Model)[8]基于深度学习的⽅法:AutoMOS[9], QualityNet[10], NISQA[11], MOSNet[12]此外,有部分的⽅法,其代码已开源::该仓库包括MOSNet, SRMR, BSSEval, PESQ, STOI的开源实现和对应的源仓库地址。
ITU组织已公布⾃⼰实现的P.563: 。
GitHub上⾯的微⼩修改版使其能够在Mac上编译。
在语⾳合成中会⽤到的计算MCD:此外,有⼀本书⽤来具体叙述评价语⾳质量:Quality of Synthetic Speech: Perceptual Dimensions, Influencing Factors, and Instrumental Assessment (T-Labs Series in Telecommunication Services)[13]。
语音识别系统的使用注意事项及语音质量评估

语音识别系统的使用注意事项及语音质量评估语音识别技术已经在各个领域得到广泛应用,并且在生活中的方方面面起到了重要作用。
为了能够更好地使用语音识别系统,我们需要注意一些使用细节,并对语音质量进行评估。
本文将重点介绍语音识别系统的使用注意事项以及语音质量评估的方法。
首先,让我们来了解一下语音识别系统的使用注意事项。
1.清晰明了的发音:要想语音识别系统能够准确识别您的语音,您需要尽量清晰地发音。
有些字母的发音容易混淆,比如 "s" 和 "f",因此在发音时要特别注意细节。
同时,语速也是一个重要的因素,过快或过慢的语速都可能影响系统的识别准确率。
2.背景噪音的控制:语音识别系统对背景噪音非常敏感,因此在使用语音识别系统时需要尽量避免嘈杂的环境。
如果您在嘈杂的环境中使用语音识别系统,建议您使用降噪麦克风或者选择一个相对安静的地方进行操作。
3.适当的麦克风距离:麦克风距离对于语音识别系统的识别效果有一定的影响。
过近或过远的距离都会导致语音质量下降。
建议将麦克风放置于口鼻附近,保持适当的距离,以达到最佳识别效果。
4.避免口头语言和俚语:语音识别系统通常基于标准的书面语言进行训练和识别,对于特定的口头语言和俚语可能无法准确识别。
因此,在使用语音识别系统时,需尽量避免使用口头语言和俚语,使用正式的书面语进行交流。
接下来,让我们来了解一下语音质量评估的方法。
1.准确性评估:语音识别系统的准确性是一个重要的评估指标。
可以使用标注好的语音数据集进行测试,将识别结果与正确答案进行对比,计算出识别准确率。
常见的评估指标包括词错误率(WER)和字符错误率(CER)。
2.鲁棒性评估:鲁棒性是指语音识别系统在不同条件下的表现。
可以使用包含噪音、语音质量差的测试集来评估系统的鲁棒性。
通过计算在不同噪音水平下的识别准确率,可以评估系统对背景噪音的抗干扰能力。
3.速度评估:语音识别系统的速度也是一个重要的考量因素。
语音质量评估及其优化策略

网规网优责任编辑:左永君*******************玉荣娟中国联通有限公司广东分公司收稿日期:2009年9月25日语音质量评估及其优化策略1 引言语音质量评估可以分为主观评估和客观评估两种。
主观语音评估是以人为主体根据某种预先约定的规则来对失真语音(或参考原始语音)划分质量等级,它反映了评听者对语音质量好坏程度的一种主观印象。
目前,国内外使用较多的语音质量主观评估方法为MOS(Mean Opinion Scores)方法[1],它不仅广泛用于语音编码、通信设备性能测试上,也是衡量语音质量客观评估方法好坏的重要依据之一。
但它把不同种类的失真混为一谈,没有指出失真的原因,不利于算法的改进。
而且,这种方法费时费力,常常受到各种测试条件和测试人员主观因素的影响,使其评估结果的可靠性受到影响。
客观评估采用机器自动判别语音质量,它使用某个特定的参数去表征语音通过编码或传输系统后的失真程度,并以此来评估处理系统的性能优劣。
PESQ(Perceptual Evaluation of Speech Quality,语音质量感知评估)[2]是目前为止,ITU公布的语音质量客观评估算法中与主观评估相关度最高的一个。
其它流行算法还有PSQM(Perceptural Speech Quality Measure)、PAMS(Perceptural AnalysisMeasurement System)和MNB(Measuring Normalizing Blocks)等。
与这些算法相比,PESQ算法既考虑了端到端时延,可以评估不同类型的网络;又采用了改进的听觉模型和认知模型技术,对通信延时、环境噪声等有较好的滤波性,其语音库由在不同的真实或仿真网络中采集而来的九种语言语音构成。
2 PESQ算法模型PESQ的思路是:首先将参考语音信号和失真语音信号的电平调整到标准听觉电平,再用输入滤波器模拟标准电话听筒进行滤波,然后将两个信号做时间对齐,将对齐好的信号做听觉转换。
智能语音业务质量评估保障方案

智能语音业务质量评估保障方案李光宇,梁燕萍,余立,王昆,陈扬铭,刘思佳(中国移动通信有限公司研究院,北京 100053)摘 要:语音通话是电信网络下的主流业务之一,业界主流的语音业务评估方案通过对比收/发端语音音频,计算得到POLQA MOS评估业务质量。
对于电信运营商,在不侵犯用户隐私的前提下感知业务质量,进而进行针对性的业务质量保障是重点工作之一。
提出了通过数理统计及神经网络算法,学习网络侧数据包交互信息与终端侧语音业务质量的映射关系,形成高精度评估模型;在此基础上,结合无线网用户及小区级多维数据信息,分析输出业务质差的原因及解决方案,形成高效准确保障业务质量的系统。
实际应用效果证明,该系统可通过网络侧数据准实时完成语音业务质量评估,并输出质差解决方案,针对网络中的V oLTE语音业务进行质量保障工作。
关键词:V oLTE业务;质量保障;网络智能化中图分类号:TN929.5文献标识码:Adoi: 10.11959/j.issn.1000−0801.2021110AI based scheme on voice service qualityevaluation and assuranceLI Guangyu, LIANG Yanping, YU Li, WANG Kun, CHEN Yangming, LIU SijiaChina Mobile Research Institute, Beijing 100053, ChinaAbstract: The voice service is one of the mainstream services under the telecommunications network. The main-stream voice service quality evaluation method in the industry is to compare the voice and audio of the transceiver and calculate the POLQA MOS, which is the standard benchmark for voice quality analysis. For telecom operators, perceive voice service quality efficiently without any infringement of user privacy, and carry out precise service qual-ity assurance, is one of the key tasks. A system using mathematical statistics and neural network to learn the mapping between voice service feature data from network side and voice quality from user side to generate evaluation model with high accuracy and precision was proposed. On this basis, the system made use of data information from multiple fields including wireless network user level and cell level, to analyze reasons and work out solutions for poor service quality, so as to assure service quality efficiently and accurately. The result shows that the scheme has achieved good practical application results.Key words: V oLTE service, quality assurance, network intelligence收稿日期:2021−04−18;修回日期:2021−05−10·65·电信科学 2021年第5期1 引言长期以来,作为运营商的自营业务,语音业务一直是运营商需要重点保障的核心业务。
语音质量评估系统的实现
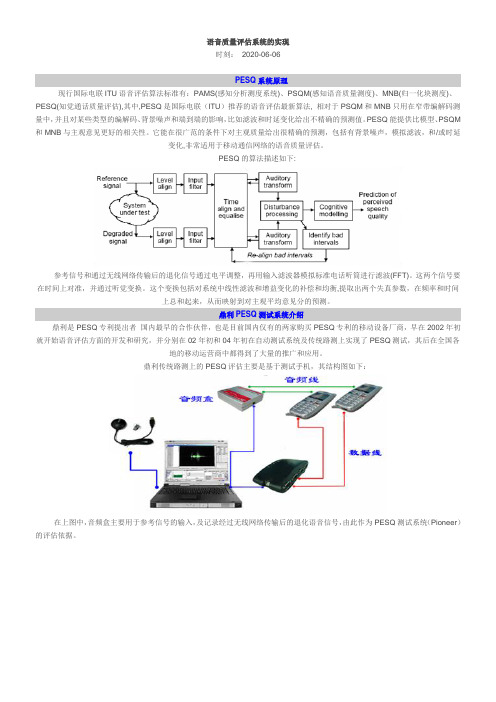
语音质量评估系统的实现时刻:2020-06-06PESQ系统原理现行国际电联ITU语音评估算法标准有:PAMS(感知分析测度系统)、PSQM(感知语音质量测度)、MNB(归一化块测度)、PESQ(知觉通话质量评估),其中,PESQ是国际电联(ITU)推荐的语音评估最新算法, 相对于PSQM和MNB只用在窄带编解码测量中,并且对某些类型的编解码、背景噪声和端到端的影响,比如滤波和时延变化给出不精确的预测值。
PESQ能提供比模型、PSQM 和MNB与主观意见更好的相关性。
它能在很广范的条件下对主观质量给出很精确的预测,包括有背景噪声,模拟滤波,和/或时延变化,非常适用于移动通信网络的语音质量评估。
PESQ的算法描述如下:参考信号和通过无线网络传输后的退化信号通过电平调整,再用输入滤波器模拟标准电话听筒进行滤波(FFT)。
这两个信号要在时间上对准,并通过听觉变换。
这个变换包括对系统中线性滤波和增益变化的补偿和均衡,提取出两个失真参数,在频率和时间上总和起来,从而映射到对主观平均意见分的预测。
鼎利PESQ测试系统介绍鼎利是PESQ专利提出者国内最早的合作伙伴,也是目前国内仅有的两家购买PESQ专利的移动设备厂商,早在2002年初就开始语音评估方面的开发和研究,并分别在02年初和04年初在自动测试系统及传统路测上实现了PESQ测试,其后在全国各地的移动运营商中都得到了大量的推广和应用。
鼎利传统路测上的PESQ评估主要是基于测试手机,其结构图如下:在上图中,音频盒主要用于参考信号的输入,及记录经过无线网络传输后的退化语音信号,由此作为PESQ测试系统(Pioneer)的评估依据。
Pioneer作为测试软件,其作用主要体现在两个方面,一是记录测试时的无线网络质量情况,包括场强、信号质量等,以便用户对影响语音质量的无线因素进行定位;另一方面,Pioneer内置PESQ的算法模块,可以实现对输入的参考语音样本和退化语音信号根据PESQ算法进行比较、运算,给出并记录相应的评估分数(MOS值),同时也可以给出一些其他的相关质量指标,如噪声增益、电平等,还可以实现回放时对记录的语音文件进行同步播放,以便于用户定位问题。
语音智能质检报告

语音智能质检报告1. 引言语音智能质检是一种通过自动化技术对录音或实时语音通话进行检测、评估和分析的方法。
它可以帮助企业对客户服务、销售呼叫、市场调研等领域的语音内容进行质量评判和改进。
本报告将针对语音智能质检的技术原理、应用场景以及优势进行分析和阐述。
2. 技术原理语音智能质检技术主要基于自然语言处理(NLP)、语音识别和机器学习等技术实现。
其主要步骤包括声音采样、语音转文本、文本匹配、语义分析和结果评估等。
首先,通过麦克风或其他音频设备对人的声音进行采样,得到音频数据。
然后,将音频数据通过语音识别技术转换为文本形式,即将语音转换为可处理的数据。
接下来,通过匹配算法对转换后的文本与预设的标准文本进行匹配,以确定检测的内容。
在语音转文本的基础上,还可以使用NLP技术对文本进行语义分析,以更好地理解和解释语音内容。
最后,通过机器学习算法对语音质量进行评估,并给出相关的评分和建议。
3. 应用场景语音智能质检技术可以应用于各个行业和领域中,尤其是那些需要大量电话沟通和客户服务的企业。
以下是几个主要的应用场景:3.1 客服质检语音智能质检可以帮助客服部门在大量的电话呼叫中对服务质量进行评估。
通过分析与客户的交流内容,识别出问题的关键词、语速、语调等,帮助客服人员改进服务态度和能力,提升客户满意度。
3.2 销售质检在销售呼叫中,语音智能质检可以帮助销售人员提升业务能力和销售技巧。
通过分析销售人员与客户的对话内容,如提问方式、产品介绍的准确性等,帮助销售人员改进销售策略,提高销售效率。
3.3 市场调研语音智能质检技术也可以应用于市场调研领域。
通过分析市场调研人员与被调查对象的对话内容,识别出对调查问题的回答情况,帮助市场调研人员分析调查结果,快速掌握市场需求和客户需求。
4. 优势语音智能质检技术相比传统的手工质检方法具有以下优势:4.1 自动化和高效率语音智能质检技术可以自动对大量录音或实时通话进行质检,极大地提高了工作效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
通常,人既是语音的发送主体,也是语音的接收主体。
语音所具备的自然属性和社会属性决定了人对语音的感知涉及到语音信号的物理特征、听觉器官对语音的听觉表征及听觉心理等诸多方面,因此难以对语音质量这个概念做出全面、精确的定义。
一般说来,语音质量至少包括三个方面内容:清晰度、可懂度和自然度。
清晰度是指语音中语言单元为意义不连贯的(如音素、声母、韵母等)单元的清晰程度;可懂度是指语音中有意义的语言单元(如单词、单句等)内容的可识别程度;自然度则与语音的保真性密切相关。
目前对语音可懂度、清晰度的主观评测己有国际和国内标准,对语音自然度还缺乏公认的评价准则。
语音质量受到个人区别、可理解性、语音特征、周围环境、背景噪声传输、网络状况和人的期望等复杂的因素影响.用于评价输出语音质量的方法分为主观评价和客观评价两种1 主观评价法主观评价方法以人为主体在某种预设原则的基础上对语音的质量作出主观的等级意见或者作出某种比较结果,它反映听评者对语音质量好坏的主观印象。
不同的主观评价方法对语音质量考察的侧重点不同,常见的主观评价方法有平均意见分(Mean Opinion Score,MOS)方法、判断韵字测试(Diagnostic Rhyme Test,DRT)方法、失真平均意见分(Degradation Mean Opinion Score,DMOS)、判断满意度测试(Dignostic Acceptability Measure,DAM)方法和汉语清晰度测试。
ITU-T推荐用于传输性能的主观评价有以下几种[14]:1.绝对等级评价(Absolute Category Rating,ACR)ACR主要通过平均意见分(MOS)对音质进行主观评价。
这种情况下没有参考语音,听音人只听失真语音,然后对该语音作出1-5分的评价。
ACR评价方法不需要参考音,比较灵活,然而由于人对不同声音的喜好不同,这种灵活性会导致一定的不公平性。
2.失真等级评价(Degradation Category Rating,DCR)DCR主要通过失真平均意见分(DMOS)来实现音质的主观评价。
这种评价方法要求听音人在给失真语音打分前,先熟悉原始语音(参考语音),再将失真语音与原始语音的差异按一定标准来描述。
DCR常用于评价诸如汽车噪声、街道噪声或其他说话人干扰等为背景噪声情况下的音质。
噪声的类型和数量将直接影响评定的失真等级。
3.相对等级评价(Comparison Category Rating,CCR)CCR方法主要采用相对平均意见分(CMOS)对音质进行主观评价。
CCR类似于DCR,不同的是,在CCR方法中,原始语音和失真语音的播放次序是随机的,听音人不知道哪是原始音、哪是失真音。
听音人只是在上一个音的基础上,评定出当前音相对于上一音的好坏。
CCR方法允许对处理后语音(失真语音)的评价高于原始音的评价,因此,它可以用来评价具有噪声抑制和语音增强功能的编码器,也可以用来比较两种未知编码器的性能优劣。
MOS得分方法是由CCITT推荐的主观评价方法,现已广泛作为不同系统之间的MOS评分中质量优表示重建语音和原始语音只有很少的细节差异,且若不进行对照听比就觉察不出这种差异质量良表示重建语音的畸变或失真不明显,不注意听感觉不到;质量一般表示重建语音有比较明显可感知的畸变成失真,但语音自然度和清晰度仍很好,且听起来没有疲劳感;质量差表示重建语音有较强的畸变或失真,听起来已有疲劳感;质量极差表示重建语音的质量极差,听觉无法忍受。
在数字语音通信中,通常认为MOS分为4.04.5为高质量数字化语音,达到长途电话网的质量要求,接近于透明信道编码,也常称之为网络质量。
MOS分为3.5分左右称为通信质量,这时能感到重建话音质量有所下降,但不妨碍正常通话,可以满足多数语音通信系统使用要求。
MOS分3.0以下常称为合成语音质量,指一些声码器合成的语音所能达到的质量。
它虽然有较高的可懂度,但自然度较差MOS得分法的优点是:由于编码系统的质量是按数值大小等级排列,所以不同失真类型的编码系统就可以相互比较;评测者只需实现进行简单训练,就可直接参与评测,因而容易完成.其缺点是:它把不同种类的失真混为一谈,没有指出失真的原因,不利于算法的改进。
另外,测试条件的选择及其他一些因素会影响MOS方法的结果判断韵字测试(DRT)判断韵字测试是反映语音清晰度或可懂度的一种测试方法,它主要用于低速率语音编码的质量测试,因为这时可懂度已成为主要问题。
这种测试方法使用若干对(通常是96对)同韵母进行测试,例如中文的“为”和“费”,英文的’fast’和’vast’等。
让受试者每次听到一对韵字中的某个音,然后让他判断所听到的音是哪一个字,全体实验者判断正确的百分比就是DRT得分,通常认为DRT为95%以上时清晰度为优,85%-94%为良,75%-84%为中,65%-75%为差而65%以下为不可接受。
在实际通话中,清晰度为50%时,整句的可懂度大约为80%,这是因为整句中具有较高的冗余度,即使个别字听不清楚,人们也能理解整句话的意思。
当清晰度为90%时,整句话的可懂度已接近100%,所以对于低速率语音编码,一般要求其清晰度能达到90%或以上诊断满意度测量(Diagnostic Acceptability Measure)DAM是对语音质量的综全评估,它是在多种条件下对话音质量的接受程度的一种度量。
这种评分体系相当全面,也相当复杂主观评价的优点在于直接、易于理解,真实反映语音质量的实际情况。
然而,主观评价不但对听评条件、听评流程有严格要求,为了避免个别听评者的感知偏差,还需要对大量的听评者的评价结果做统计,因此主观评价费时费力,成本高,灵活性差,重复性不好,难以应用于实时性场合。
2 客观评价法音质的客观评价是指用机器自动判别语音质量,按是否需要使用输入语音的角度可分为两类:基于输入—输出方式的客观评价和基于输出方式的客观评价。
基于输入—输出的客观评价比较输出和输入语音之间的差异(失真)程度,将差异量值作为语音质量的衡量依据;基于输出的客观评价则仅由输出语音就可对语音的质量做出评估。
在应用中,输入语音也常称为原始语音或者参考语音,通过系统的输出语音常称为失真语音。
以往的音质客观评价研究大多集中于输入—输出方式,随着技术发展、对通信服务质量的关注等,基于输出的音质评价技术正得到越来越多的关注。
客观评价不受人为主观因素的影响,成本低廉,灵活性好,效率高,具有可重复性,且可实时使用,例如对VoIP网络中语音传输质量的实时监控和用于指导系统中设备参数调整等。
尽管科学家对人类的感官感知和神经信息处理机制做了大量的研究并取得一定的成果,但人们对人类感知的机理和大脑活动的运作方法仍处在一知半解的初级阶段,因此我们还无法建立一个能完全模仿人类音质感知过程的客观评价系统,只能根据所获得的信息作出尽可能正确的评价,所建立的客观评价系统也与人类所具有的感知评价能力相差甚远。
因此,客观评价并不能完全取代主观评价。
在实际应用中,通常将主观评价和客观评价结合使用。
客观评价常用于系统的设计、调整以及现场实时监控阶段,主观评价作为实际效果的最终检验,两者相辅相成,用于不同的场合。
其次,客观评价系统的优劣取决于由它得到的客观评价结果与主观评价结果是否具有统计意义上高相关性以及小的偏差,因此客观评价系统的设计必须以主观评价为基础,并借鉴主观评价主体的感知功能和智能特性。
合格的客观评价系统可在一定使用范围内中代替主观评价对语音质量做出基本正确的判断。
3 客观评价原理基于输入—输出的客观评价是在信号特征表示的基础上对失真语音和原始语音进行比较。
下图为基于输入—输出的客观评价的模块原理图,从流程上分为预处理、语音信号特征提取、客观失真量计算和质量等级映射四大模块。
原始语音失真语音通信系统预处理预处理特征提取特征提取客观失真量计算映射模块预处理包括输入—输出语音信号的同步处理、电平规整、分帧等处理步骤。
同步处理是为了保证所比较的输入和输出语音单元之间有正确的对应关系,否则将对客观评价结果产生巨大的偏差;为了消除语音信号幅度差异对主观听觉的影响,必须通过电平规整保证输入和输出语音的声压级基本相同;虽然语音是时变的非平稳信号,但是在一个短时间范围内(1Oms-30ms),其特性相对稳定,因此可以将连续语音信号分割为短时间范围的时间片序列以便于后续的特征参数分析。
这样,对于整体的语音信号,通过预处理环节后,语音信号被分割为以帧为单位、加窗处理过的短时信号。
语音信号分析是语音信号处理的前提和基础,分析的目的是提取需要的信息,获取特征表示参数。
曾有语音处理专家在论文中表示:语音信号的表示是人类近代科学研究中很少碰到的难题之一[18]。
虽然语音信号是一维波形信号,但仅从时域上描述其特性是远远不够的,特别是在音质评价中,两个时域波形差别很大的语音信号的主观音质感觉可能基本相同,因此需要使用频域分析及其它信号分析方法表示语音信号的特征。
对于语音帧序列,语音信号特征提取模块使用适当的分析方法,得到表示语音信号的特征参数。
特征参数对音质评价效果有极其重要的影响,音质评价的特殊性对所使用的语音特征参数有着独特的要求。
客观失真量计算模块用于计算失真量。
所谓失真量是指原始语音和输出语音特征参数之间的总体差异量,该量值反映语音通过系统后的质量变化,即输出语音对于原始语音的失真程度。
由于尚不清楚人类听觉系统、感知神经系统以及大脑思维在判断语音质量过程中的相互作用,无法建立人类感知语音失真程度的真,范数形式计算客观失真量。
实数学模型,因此常采用Lp为了与主观评价等级一致,通常将客观评价所得到的失真量映射为主观评价的尺度表示,如MOS的5级表示,映射模块即完成此功能。
映射模块可按二次或者三次多项式函数拟合形式建立客观失真量与主观等级分之间的对应关系。
使用基于输入—输出的客观评价时要求原始语音和失真语音之间做到严格同步,而在实际应用中,严格同步的要求并不容易得到满足,同时在某些应用场合中难以或者不便于采集到原始语音材料,这就要求发展基于输出语音的客观评价方法。
基于输出的客观评价方法仅对输出语音进行处理,因此在预处理中不再需要端点同步处理步骤,其他处理模块的功能等同于基于输入—输出的客观评价方法,但在模块具体实现中,如特征提取等,必须使用适合基于输出评价方式的方法和技术手段。
下图为基于输出方式的客观评价的模块原理图。
原始语音失真语音通信系统预处理特征提取客观失真量计算映射模块。