数据结构课程设计汇本:拓扑排序和关键路径
数据结构的应用的拓扑排序与关键路径算法

数据结构的应用的拓扑排序与关键路径算法拓扑排序与关键路径算法是数据结构中重要的应用之一。
拓扑排序通过对有向图的节点进行排序,使得对于任意一条有向边(u,v),节点 u 在排序中都出现在节点 v 之前。
关键路径算法则是用来确定一个项目的关键活动和最短完成时间。
拓扑排序的实现可以通过深度优先搜索或者广度优先搜索来完成。
深度优先搜索是递归地访问节点的所有未访问过的邻居节点,直到没有未访问过的邻居节点为止,然后将该节点添加到拓扑排序的结果中。
广度优先搜索则是通过使用队列来实现的,将节点的邻居节点逐个入队并进行访问,直到队列为空为止。
无论使用哪种方法,拓扑排序都可以通过判断节点的入度来进行。
拓扑排序在很多实际问题中都有广泛应用。
比如在任务调度中,拓扑排序可以用来确定任务间的依赖关系和执行顺序;在编译原理中,拓扑排序可以用来确定程序中变量的定义和使用顺序。
关键路径算法用于确定项目中的关键活动和最短完成时间。
它通过计算每个活动的最早开始时间和最晚开始时间,以及每个活动的最早完成时间和最晚完成时间来实现。
具体步骤如下:1. 构建有向加权图,其中节点表示项目的活动,有向边表示活动间的先后关系,边的权重表示活动的持续时间。
2. 进行拓扑排序,确定活动的执行顺序。
3. 计算每个活动的最早开始时间,即从起始节点到该节点的最长路径。
4. 计算每个活动的最晚开始时间,即从终止节点到该节点的最长路径。
5. 根据每个活动的最早开始时间和最晚开始时间,可以确定关键活动,即最早开始时间与最晚开始时间相等的活动。
6. 计算整个项目的最短完成时间,即从起始节点到终止节点的最长路径。
拓扑排序与关键路径算法在工程管理、任务调度、生产流程优化等领域都有重要应用。
它们能够帮助我们有效地组织和管理复杂的项目,提高工作效率和资源利用率。
在实际应用中,我们可以借助计算机编程以及各种图算法库来实现这些算法,从而更快速、准确地解决实际问题。
综上所述,拓扑排序与关键路径算法是数据结构的重要应用之一。
数据结构课设——有向图的深度、广度优先遍历及拓扑排序
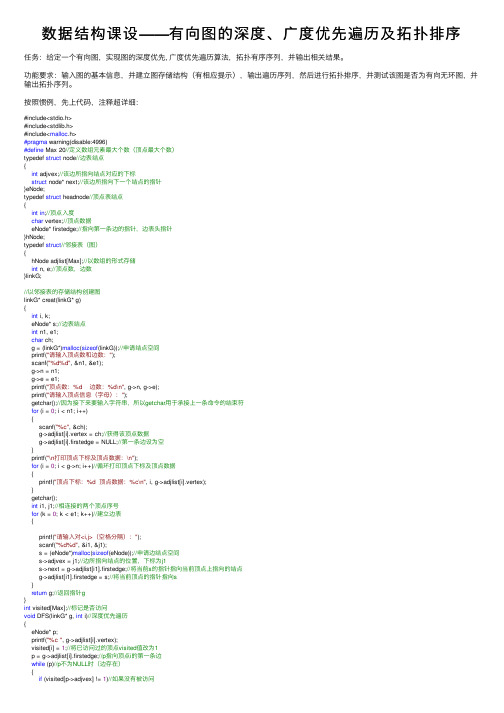
数据结构课设——有向图的深度、⼴度优先遍历及拓扑排序任务:给定⼀个有向图,实现图的深度优先, ⼴度优先遍历算法,拓扑有序序列,并输出相关结果。
功能要求:输⼊图的基本信息,并建⽴图存储结构(有相应提⽰),输出遍历序列,然后进⾏拓扑排序,并测试该图是否为有向⽆环图,并输出拓扑序列。
按照惯例,先上代码,注释超详细:#include<stdio.h>#include<stdlib.h>#include<malloc.h>#pragma warning(disable:4996)#define Max 20//定义数组元素最⼤个数(顶点最⼤个数)typedef struct node//边表结点{int adjvex;//该边所指向结点对应的下标struct node* next;//该边所指向下⼀个结点的指针}eNode;typedef struct headnode//顶点表结点{int in;//顶点⼊度char vertex;//顶点数据eNode* firstedge;//指向第⼀条边的指针,边表头指针}hNode;typedef struct//邻接表(图){hNode adjlist[Max];//以数组的形式存储int n, e;//顶点数,边数}linkG;//以邻接表的存储结构创建图linkG* creat(linkG* g){int i, k;eNode* s;//边表结点int n1, e1;char ch;g = (linkG*)malloc(sizeof(linkG));//申请结点空间printf("请输⼊顶点数和边数:");scanf("%d%d", &n1, &e1);g->n = n1;g->e = e1;printf("顶点数:%d 边数:%d\n", g->n, g->e);printf("请输⼊顶点信息(字母):");getchar();//因为接下来要输⼊字符串,所以getchar⽤于承接上⼀条命令的结束符for (i = 0; i < n1; i++){scanf("%c", &ch);g->adjlist[i].vertex = ch;//获得该顶点数据g->adjlist[i].firstedge = NULL;//第⼀条边设为空}printf("\n打印顶点下标及顶点数据:\n");for (i = 0; i < g->n; i++)//循环打印顶点下标及顶点数据{printf("顶点下标:%d 顶点数据:%c\n", i, g->adjlist[i].vertex);}getchar();int i1, j1;//相连接的两个顶点序号for (k = 0; k < e1; k++)//建⽴边表{printf("请输⼊对<i,j>(空格分隔):");scanf("%d%d", &i1, &j1);s = (eNode*)malloc(sizeof(eNode));//申请边结点空间s->adjvex = j1;//边所指向结点的位置,下标为j1s->next = g->adjlist[i1].firstedge;//将当前s的指针指向当前顶点上指向的结点g->adjlist[i1].firstedge = s;//将当前顶点的指针指向s}return g;//返回指针g}int visited[Max];//标记是否访问void DFS(linkG* g, int i)//深度优先遍历{eNode* p;printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已访问过的顶点visited值改为1p = g->adjlist[i].firstedge;//p指向顶点i的第⼀条边while (p)//p不为NULL时(边存在){if (visited[p->adjvex] != 1)//如果没有被访问DFS(g, p->adjvex);//递归}p = p->next;//p指向下⼀个结点}}void DFSTravel(linkG* g)//遍历⾮连通图{int i;printf("深度优先遍历;\n");//printf("%d\n",g->n);for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问{DFS(g, i);//调⽤DFS函数}}}void BFS(linkG* g, int i)//⼴度优先遍历{int j;eNode* p;int q[Max], front = 0, rear = 0;//建⽴顺序队列⽤来存储,并初始化printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已经访问过的改成1rear = (rear + 1) % Max;//普通顺序队列的话,这⾥是rear++q[rear] = i;//当前顶点(下标)队尾进队while (front != rear)//队列⾮空{front = (front + 1) % Max;//循环队列,顶点出队j = q[front];p = g->adjlist[j].firstedge;//p指向出队顶点j的第⼀条边while (p != NULL){if (visited[p->adjvex] == 0)//如果未被访问{printf("%c ", g->adjlist[p->adjvex].vertex);visited[p->adjvex] = 1;//将该顶点标记数组值改为1rear = (rear + 1) % Max;//循环队列q[rear] = p->adjvex;//该顶点进队}p = p->next;//指向下⼀个结点}}}void BFSTravel(linkG* g)//遍历⾮连通图{int i;printf("⼴度优先遍历:\n");for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问过{BFS(g, i);//调⽤BFS函数}}}//因为拓扑排序要求⼊度为0,所以需要先求出每个顶点的⼊度void inDegree(linkG* g)//求图顶点⼊度{eNode* p;int i;for (i = 0; i < g->n; i++)//循环将顶点⼊度初始化为0{g->adjlist[i].in = 0;}for (i = 0; i < g->n; i++)//循环每个顶点{p = g->adjlist[i].firstedge;//获取第i个链表第1个边结点指针while (p != NULL)///当p不为空(边存在){g->adjlist[p->adjvex].in++;//该边终点结点⼊度+1p = p->next;//p指向下⼀个边结点}printf("顶点%c的⼊度为:%d\n", g->adjlist[i].vertex, g->adjlist[i].in);}void topo_sort(linkG *g)//拓扑排序{eNode* p;int i, k, gettop;int top = 0;//⽤于栈指针的下标索引int count = 0;//⽤于统计输出顶点的个数int* stack=(int *)malloc(g->n*sizeof(int));//⽤于存储⼊度为0的顶点for (i=0;i<g->n;i++)//第⼀次搜索⼊度为0的顶点{if (g->adjlist[i].in==0){stack[++top] = i;//将⼊度为0的顶点进栈}}while (top!=0)//当栈不为空时{gettop = stack[top--];//出栈,并保存栈顶元素(下标)printf("%c ",g->adjlist[gettop].vertex);count++;//统计顶点//接下来是将邻接点的⼊度减⼀,并判断该点⼊度是否为0p = g->adjlist[gettop].firstedge;//p指向该顶点的第⼀条边的指针while (p)//当p不为空时{k = p->adjvex;//相连接的顶点(下标)g->adjlist[k].in--;//该顶点⼊度减⼀if (g->adjlist[k].in==0){stack[++top] = k;//如果⼊度为0,则进栈}p = p->next;//指向下⼀条边}}if (count<g->n)//如果输出的顶点数少于总顶点数,则表⽰有环{printf("\n有回路!\n");}free(stack);//释放空间}void menu()//菜单{system("cls");//清屏函数printf("************************************************\n");printf("* 1.建⽴图 *\n");printf("* 2.深度优先遍历 *\n");printf("* 3.⼴度优先遍历 *\n");printf("* 4.求出顶点⼊度 *\n");printf("* 5.拓扑排序 *\n");printf("* 6.退出 *\n");printf("************************************************\n");}int main(){linkG* g = NULL;int c;while (1){menu();printf("请选择:");scanf("%d", &c);switch (c){case1:g = creat(g); system("pause");break;case2:DFSTravel(g); system("pause");break;case3:BFSTravel(g); system("pause");break;case4:inDegree(g); system("pause");break;case5:topo_sort(g); system("pause");break;case6:exit(0);break;}}return0;}实验⽤图:运⾏结果:关于深度优先遍历 a.从图中某个顶点v 出发,访问v 。
信息学奥赛一本通 第4章 第7节 拓扑排序与关键路径(C++版)

拓扑排序算法
【参考程序】 //gentree #include<cstdio> #include<iostream> using namespace std; int a[101][101],c[101],r[101],ans[101]; int i,j,tot,temp,num,n,m; int main() { freopen("gentree.in","r",stdin); freopen("gentree.out","w",stdout); cin >> n; for (i = 1; i <= n; i++) { do { cin >> j; if (j !=0 ) { c[i]++; //c[i]用来存点i的出度 a[i][c[i]] = j; r[j]++; //r[i]用来存点i的入度。 } } while (j != 0); }
拓扑排序算法
【数据规模】 80%的数据满足n<=1000,m<=2000;100%的数据满足n<=10000,m<=20000。 【算法分析】 首先构图,若存在条件“a的钱比b多”则从b引一条有向指向a;然后拓扑排序, 若无法完成排序则表示问题无解(存在圈);若可以得到完整的拓扑序列,则按序 列顺序进行递推: 设f[i]表示第i个人能拿的最少奖金数; 首先所有f[i]=100(题目中给定的最小值); 然后按照拓扑顺序考察每个点i,若存在有向边(j,i),则表示f[i]必须比f[j] 大,因此我们令f[i] = Max { f[i] , f[j]+1 }即可; 递推完成之后所有f[i]的值也就确定了,而答案就等于f[1]+…+f[n]。
拓扑排序及关键路径

2.有向图在实际问题中的应用 一个有向图可以表示一个施工流程图,或产品生产流程
图,或数据流图等。设图中每一条有向边表示两个子工程之 间的先后次序关系。
若以有向图中的顶点来表示活动,以有向边来表示活动 之间的先后次序关系,则这样的有向图称为顶点表示活动的 网 (Activity On Vertex Network),简称AOV网。
这样,每个活动允许的时间余量就是l(i) - e(i)。而关键活动 就是l(i) - e(i) = 0的那些活动,即可能的最早开始时间e(i)等于 允许的最晚开始时间l(i)的那些活动就是关键活动。
4.寻找关键活动的算法 求AOE网中关键活动的算法步骤为: (1)建立包含n+1个顶点、e条有向边的AOE网。其中,顶
(4)从汇点vn开始,令汇点vn的最晚发生时间vl[n]=ve[n], 按逆拓扑序列求其余各顶点k(k=n-1,n-2,…,2,1,0)的最晚发生 时间vl[k];
(5)计算每个活动的最早开始时间e[k] (k=1,2,3,…,e); (6)计算每个活动的最晚开始时间l[k] (k=1,2,3,…,e); (7)找出所有e[k]= l[k]的活动k,这些活动即为AOE网的 关键活动。
上述算法仅能得到有向图的一个拓扑序列。改进上述 算法,可以得到有向图的所有拓扑序列。
如果一个有向图存在一个拓扑序列,通常表示该有向 图对应的某个施工流程图的一种施工方案切实可行;而 如果一个有向图不存在一个拓扑序列,则说明该有向图 对应的某个施工流程图存在设计问题,不存在切实可行 的任何一种施工方案。
事件可能的最早开始时间υe(k):对于顶点υk代表的事件, υe(k)是从源点到该顶点的最大路径长度。在一个有n+1个事 件的AOE网中, 源点υ0的最早开始时间υe(0)等于0。事件υk (k=1,2,3,…,n)可能的最早开始时间υe(k)可用递推公式表 示为:
数据结构关键路径

数据结构关键路径 如果在有向⽆环图中⽤有向边表⽰⼀个⼯程中的各项活动(Activity),⽤有向边上的权值表⽰活动的持续时间(duration),⽤顶点表⽰事件(Event),则这种有向图叫做⽤边表⽰活动的⽹络(activity on edges),简称AOE⽹络。
例如: 其中,E i表⽰事件,a k表⽰活动。
E0是源点,E8是汇点。
完成整个⼯程所需的时间等于从源点到汇点的最长路径长度,即该路径中所有活动的持续时间之和最⼤。
这条路径称为关键路径(critical path)。
关键路径上所有活动都是关键活动。
所谓关键活动(critical activity),是不按期完成会影响整个⼯程进度的活动。
只要找到关键活动,就可以找到关键路径。
与计算关键活动有关的量: 1 事件E i的最早可能开始时间:Ee[i]—从源点E0到顶点E i的最长路径长度。
在上图中,Ee[4]=7。
2 事件E i的最迟允许开始时间:El(⼩写L)[i]—在保证汇点E n-1最迟允许开始时间El[n-1]等于整个⼯程所需时间的前提下,等于El[n-1]减去从E i到E n-1的最长路径长度。
3 活动a k的最早可能开始时间:e[k]—设该活动在有向边<E i,E j>上,从源点E0到顶点E i的最长路径长度,即等于Ee[i]。
4 活动a k的最迟允许开始时间:l(⼩写L)[k]—设该活动在有向边<E i,E j>上,在不会引起时间延误的前提下,允许的最迟开始时间。
l[k]=El[j]-dur(<E i,E j>),其中dur(<E i,E j>)是完成该活动所需的时间,即有向边<E i,E j>的权值。
l[k]-e[k]表⽰活动a k的最早可能开始时间和最迟允许开始时间的时间余量,也叫做松弛时间(slack time)。
没有时间余量的活动是关键活动。
算法步骤: 1 输⼊顶点数和边数,再输⼊每条边的起点编号、终点编号和权值。
数据结构-chap7 (4)AOV网与拓扑排序

}//for }//while if (count<G.vexnum) return ERROR; //该有向图有回路 else return OK; }//TopologicalSort
自测题2 AOV-网的拓扑排序
v2 v1 v3 v4 v5 v6 v1 v2
1
3 0 1 0 3 S.top S.base
5 4
1
2 3
3
2 1 4 0 2
C2
1
0
5 0
1
4
5
C3
C4
C5
C3 0 C4
5 0
C5 0
while(! StackEmpty(S)){ Pop(S, i); printf(i, G. vertices[i].data); ++count; for (p=G.vertices[i].firstarc; p; p=p->nextarc) { k = p->adjvex; if ( !(- -indegree[k]) ) Push(S, k); }//for }//while data firstarc C0 1 3 0 栈S C1 5 0
Status TopologicalSort(ALGraph G) { FindInDegree(G, indegree); //求各顶点入度indegree[0..vexnum-1] InitStack(S); for(i=0; i<G. vexnum; ++i) if (! indegree[i]) Push(S, i); //入度为0顶点的编号进栈 count = 0; //对输出顶点计数 count=6 while(! StackEmpty(S)){ Pop(S, i); //从零入度顶点栈S 栈顶,获得一入度为零的顶点i printf(i, G. vertices[i].data); ++count; //输出i号顶点的数据,并计数 for (p=G. vertices[i]. firstarc; p; p=p->nextarc) { k = p->adjvex; if ( !(- -indegree[k]) ) Push(S, k); //对i号顶点邻接到的 每个顶点入度减1
课次21——第七章03拓扑排序和关键路径

对有向图进行如下操作:按照有向图给出的次序关系,将图 中顶点排成一个线性序列,对于有向图中没有限定次序关系的顶 点,则可以人为加上任意的次序关系。由此所得顶点的线性序列 称之为拓扑有序序列。
v3 v5
v9
v8
v4
v6
13 2020/8/4
7.5.2 关键路径(4)
在AOE网络中, 有些活动顺序进行,有些活动并行进行。
从源点到各个顶点,以至从源点到汇点的有向路径可能不止 一条。这些路径的长度也可能不同。完成不同路径的活动所 需的时间虽然不同,但只有各条路径上所有活动都完成了, 整个工程才算完成。
例:
C0
C1
C2
C0
C1
C2
C3
C4
C5
(a) 有向无环图
C0
C1
C2
C3
C4
C5
(b) 输出C4
C1
C2
C3
C5
(c) 输出顶点C0
9 2020/8/4
C3
C5
(d) 输出顶点C3
7.5.1拓扑排序(Topological Sort)(7)
C1
C2
C1
C5 (e) 输出顶点C2
C5 (f) 输出顶点C1
因此,完成整个工程所需的时间取决于从源点到汇点的最长 路径长度,即在这条路径上所有活动的持续时间之和。这条 路径长度最长的路径就叫做关键路径(Critical Path)。
子工程所需时间。 问:哪些子工程是“关键工程”? 即:哪些子工程将影响整个工程的完成期限的。
首先了解一些基本概念:
数据结构-拓扑排序和最短路径

Dijkstra算法
如何找到Vk?
min( D[i] + dur(i,k)) i = 0,1,…k-1
Vk
S
Dijkstra算法
V5
V0
10
30 10
V4
20
V1 V2
V3
S={V0} D[0]=0
S={V0,} D[3] = 50 S={V0,V2,V4,V3,V5}
Dijkstra算法实现
void ShortestPath_DIJ(MGraph G, int v0, PathMatrix &P, ShortestPathTable &D){ for(v=0;v<G.vexnum;++v){ final[v]=FALSE; //S中的顶点 D[v]=G.arcs[v0][v];//v0到v的路径的长度 for(w=0;w<G.vexnum;++w) p[v][w]=FALSE; if(D[v]<INFINITY){//V0的邻接点 p[v][v0]=TRUE; p[v][v]=TRUE; }//if }//for final[v0]=TRUE;
Floyd 算法
首先对顶点进行编号,n个顶点对应1……n个整 数,分别叫做V1,V2,……,Vn 显然,顶点vi和vj之间的最短路径通过了n个 顶点的某些顶点。
Floyd 算法
•偏序就是集合中的部分成员可以比较。 •全序是集合中的任何成员之间都可以比较。 B A C 偏序 D A C 全序 B D
拓扑排序
按照有向图给出的次序关系,将图中顶点排成 一个线性序列,对于有向图中没有限定次序关系 的顶点,则可以人为加上任意的次序关系。
由此所得顶点的线性序列称之为拓扑有序序 列
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 ABSTRACT1.1图和栈的结构定义struct SqStack////栈部分{SElemType *base;//栈底指针SElemType *top;//栈顶指针int stacksize;//栈的大小int element_count;//栈中元素个素};/////////AOE网的存储结构struct ArcNode //表结点{int lastcompletetime;//活动最晚开始时间int adjvex; //点结点位置int info; //所对应的弧的权值struct ArcNode *next;//指向下一个表结点指针};struct VNode //点结点{VertexType data; //结点标志int indegree; //该结点入度数int ve; //记录结点的最早开始时间int vl; //记录结点的最晚开始时间struct ArcNode *first_out_arc; //存储下一个出度的表结点struct ArcNode *first_in_arc;//存储下一个入度的表结点};struct ALGraph{ VNode *vertices; //结点数组int vexnum; //结点数int arcnum; //弧数int kind; //该图的类型 };2系统总分析2.1关键路径概念分析2.1.1什么是关键路径关键路径法(Critical Path Method, CPM)最早出现于20世纪50年代,它是通过分析项目过程中哪个活动序列进度安排的总时差最少来预测项目工期的网络分析。
这种方法产生的背景是,在当时出现了许多庞大而复杂的科研和工程项目,这些项目常常需要运用大量的人力、物力和财力,因此如何合理而有效地对这些项目进行组织,在有限资源下以最短的时间和最低的成本费用下完成整个项目就成为一个突出的问题,这样CPM就应运而生了。
对于一个项目而言,只有项目网络中最长的或耗时最多的活动完成之后,项目才能结束,这条最长的活动路线就叫关键路径(Critical Path),组成关键路径的活动称为关键活动。
2.1.2关键路径特点关键路径上的活动持续时间决定了项目的工期,关键路径上所有活动的持续时间总和就是项目的工期。
关键路径上的任何一个活动都是关键活动,其中任何一个活动的延迟都会导致整个项目完工时间的延迟。
关键路径上的耗时是可以完工的最短时间量,若缩短关键路径的总耗时,会缩短项目工期;反之,则会延长整个项目的总工期。
但是如果缩短非关键路径上的各个活动所需要的时间,也不至于影响工程的完工时间。
关键路径上活动是总时差最小的活动,改变其中某个活动的耗时,可能使关键路径发生变化。
可以存在多条关键路径,它们各自的时间总量肯定相等,即可完工的总工期。
关键路径是相对的,也可以是变化的。
在采取一定的技术组织措施之后,关键路径有可能变为非关键路径,而非关键路径也有可能变为关键路径。
2.2关键路径实现过程2.2.1结构选取首先要选取建图的一种算法建立图,有邻接矩阵,邻接表,十字链表,邻接多重表等多种方法,要选取一种适当的方法建立图,才能提高算法效率,降低时间复杂度和空间复杂度。
两个相邻顶点与它们之间的边表示活动,边上的数字表示活动延续的时间。
对于给出的事件AOE网络,要求求出从起点到终点的所有路径,经分析、比较后找出长读最大的路径,从而得出求关键路径的算法,并给出计算机上机实现的源程序。
完成不同路径的活动所需的时间虽然不同,但只有各条路径上所有活动都完成了,这个工程才算完成。
2.2.2具体要解决的问题(1)将项目中的各项活动视为有一个时间属性的结点,从项目起点到终点进行排列;(2)用有方向的线段标出各结点的紧前活动和紧后活动的关系,使之成为一个有方向的网络图;(3)用正推法和逆推法计算出各个活动的最早开始时间,最晚开始时间,最早完工时间和最迟完工时间,并计算出各个活动的时差;(4)找出所有时差为零的活动所组成的路线,即为关键路径;(5)识别出准关键路径,为网络优化提供约束条件;2.2.3算法分析(1)求关键路径必须在拓扑排序的前提下进行,有环图不能求关键路径;(2)只有缩短关键活动的工期才有可能缩短工期;(3)若一个关键活动不在所有的关键路径上,减少它并不能减少工期;(4)只有在不改变关键路径的前提下,缩短关键活动才能缩短整个工期。
(5)关键路径:从源点到汇点的路径长度最长的路径叫关键路径。
(6)活动的最早开始时间e(i);(7)活动的最晚开始时间l(i);(8)定义e(i)=l(i)的活动叫关键活动;(9)事件的最早开始时间ve(i);(10)事件的最晚开始时间vl(i)。
设活动ai由弧<j,k>(即从顶点j到k)表示,其持续时间记为dut(<j,k>),则:e(i)=ve(j)l(i)=vl(k)-dut(<j,k>)求ve(i)和vl(j)分两步:1.从ve(1)=0开始向前递推ve(j)=Max{ ve(i)+dut(<i,j>) }<i,j>T, 2<=j<=n其中,T是所有以j为弧头的弧的集合。
2.从vl(n)=ve(n)开始向后递推vl(i)=Min{ vl(j)-dut(<i,j>) }<i,j>S, 1<=i<=n-1其中,S是所有以i为弧尾的弧的集合。
两个公式是在拓扑有序和逆拓扑有序的前提下进行。
2.2.4 算法步骤(1)输入e条弧<j,k>,建立AOE网的存储结构。
(2)从源点v1出发,令ve(1)=0,求个点的最早开始时间ve(j)。
(3)从汇点vn出发,令vl(n)=最大值,求个点的最晚开始时间vl(j)。
(4)由于各结点的最早开始时间已求出来,所以各活动的最早开始时间即(每条弧s(活动)的最早开始时间)就等于该结点的最早开始时间,并由上可同时求出该活动的最晚开始时间l(j)。
(5)具体表达式为:e(i)=ve(j)l(i)=vl(k)-dut(<j,k>)(6)当结点的最早开始时间ve(j)=最晚开始时间时vl(j),则该结点为关键结点。
(7)当活动的最早开始时间e(j)=最晚开始时间时l(j),则该结点为关键活动。
3 主要功能模块设计3.1程序模块栈部分模块Status InitStack(SqStack &S) //初始化栈Status DestroyStack(SqStack &S)//销毁栈Status ClearStack(SqStack &S)//清空栈Status StackEmpty(SqStack S)//判断是否为空Status StackEmpty(SqStack S)//判断是否为空Status Pop(SqStack &S,SElemType &e) //弹出元素Status GetElement(SqStack &S,int position,SElemType &e) //取元素,非弹出,i为要去元素位置无向图(AOE网)部分模块void CreateALGraph(ALGraph &graph)//初始化AOE网Status TopologicalSort(ALGraph &graph,SqStack &ToPoReverseSort) //求拓扑排序Status PutInfoToPoSort(SqStack temp,ALGraph graph) //输出拓扑顺序排序(当拓扑序列存在时)Status GetVeAndVl(ALGraph &graph,SqStack OrderSort,SqStack RevSort) //求出结点和活动的最晚开始时间和最早开始时间Status CriticalPath(ALGraph &graph,SqStack RevSort) //求出关键活动和关键事件并输出4 系统详细设计4.1主函数模块main函数首先调用SqStack ToPoSort;SqStack ToPoReverseSort;函数来定义栈,调用InitStack(ToPoSort);来初始化存拓扑排序的栈和InitStack(ToPoReverseSort);来初始化逆拓扑排序的栈。
其次调用CreateALGraph(ALGraph &graph)函数定义和初始化AOE网,调用TopologicalSor t(ALGraph &graph,SqStack &ToPoReverseSort) 函数求拓扑序列和调用PutInfoToPoSort(ToPoSort,graph);函数来输出输出拓扑顺序排序。
然后调用GetVeAndVl(graph,ToPoSort,ToPoReverseSort) 函数求结点和活动的最晚开始时间、最早开始时间并输出。
最后调用Status CriticalPath(ALGraph &graph,SqStack RevSort)函数来求关键活动、关键事件并输出。
4.2初始化模块初始化模块用来初始化图,要求用户自己输入数据,并程序构造AOE网。
本程序是用自己改进的邻接表来构造AOE网。
见图2-4-2图2-4-2图2-4-34.3求拓扑序列模块利用栈来存储入度为零的结点,然后逐个弹出,来进行与该结点的出度结点来比较,是否符合拓扑排序的规则,最后用ToPoReverseSort存放拓扑逆序序列来完成整个拓扑排序。
见图2-4-3。