CCNP生成树经典笔记
CCNP学习笔记

CCNP学习笔记目录基础知识 (2)VLAN&TRUNK (3)路由器存储硬件 (4)CDP (5)交换机安全 (5)STP:802.1d (8)RSTP:802.1w (10)MST:802.1s (10)链路聚合 (10)多层交换 (11)VTP (12)HSRP/VRRP/GLBP (14)路由技术 (14)访问控制列表 (15)NA T (16)广域网 (16)IPv6 (17)VPN (18)WLAN (18)EIGRP (21)OSPF (23)IS-IS (24)路由重发布 (26)BGP (26)组播 (27)QoS(BCMSN) (28)DSL (29)PPPoE (29)MPLS (30)VPN (32)IPsec (32)GRE (33)Easy VPN (34)路由器安全 (34)Firewall (36)V oIP (37)QoS(ONT) (38)基础知识ctrl+C由setup模式退出到CLI模式,在CLI特权模式用setup命令进入setup模式由配置模式退到用户模式用disable,exit等同于logout注销交换机system红色或琥珀色灯闪烁:操作系统丢失,红色或琥珀色常亮,设备无法工作RPS灯绿色意为连接了冗余电源且冗余电源在工作,不亮意为没连接冗余电源STA T/UTL/FDUP灯用MODE按钮切换,与端口状态指示灯结合查看,端口状态灯为桔色为阻塞状态,红色为接口坏UTL用于查看设备背板的利用率,基本不用FDUP用于查看接口的双工模式,绿色为全双工,无色为半双工以太网:802.3快速以太网:802.3u千兆以太网:802.3z (光缆/屏蔽双绞线)、802.3ab (非屏蔽双绞线)交换机槽位顺序:从右向左,从下向上,从1开始(固化的接口其槽位为0,路由器从0开始,固化接口不用写槽位号,如e0、s0)接口顺序:从左向右,同样,交换机从1开始,路由器从0开始交换机MAC地址池,最小的分配给主板,其次按接口从小到大顺序分配给每个接口show version可以看到主板的MAC2960交换机可在接口上配置二三层访问列表,目前的二层交换机在部分功能上已达到了三层甚至四层。
18 CCNP讲解笔记-PIM 2分析

PIM 2研究三层架构中的第二层架构如何让路由器来转发组播流量,此时涉及到组播路由选择协议(PIM)。
一、Multicast Forwarding先研究路由器在收到组播流量,转发组播流量和转发单播流量的一个转发原则。
这个原则正好是相反的。
举例:比如单播使用的是OSPF协议:在一个AS内部署了一个OSPF域,所有路由器建立起OSPF邻居,传递LSA生成路由表,达到全网可达。
a.每台路由器形成的路由表,是基于什么的表项?答:是一张基于目的网段可达性的表项。
我们可以这样理解,在单播路由选择中,路由器收到报文之后,我虽然查看的是三层报头,但我重点查看的是三层报头中的目的IP。
组播:正好与单播相反,一台路由器收到一个组播流量,在我关心通过哪个接口把这个报文发走之前,我更关心这个报文是从哪里发送来的。
为什么会这样呢?举个例子:有个组播组信源Server,它不停的发送组播流量,连接着路由器R1和R2。
如图,假定R1和R2已经运行了正确的组播路由选择协议。
Server开始发送组播流量,正常发应该是同时发送给R1和R2,并且报文是相同的。
此时如果R1和R2都把报文转发给R3。
R3收到R1和R2过来的组播流量,会把这两股流量都发给下游PC群。
如果是单播的话,这样发送是没有问题的。
但是,如果是组播报文就不行了吧。
这产生了重复报文。
重复报文,会导致组播传递出现很多问题。
这也就是说,在这种情况下,我一台路由器对于一个组播组的Server而言,我能接收你的组播流量,但并不是我通过每个接口收到你的流量,都要帮你转发。
总结:在运行组播路由选择协议的时候,路由器收到了组播流量,更加关注报文从哪里来,目的就是为了解决重复报文问题。
注意:组播路由器对于一个组播组信源,你只有通过一个接口接收该Server报文的时候我可以帮你转发下去,但这个接口该怎么判断呢?我怎么知道对于这个Server,我通过哪个接口收到你的报文,该帮你转发下去呢?这是需要一套原则的,这个原则如下。
最小斯坦纳树学习笔记
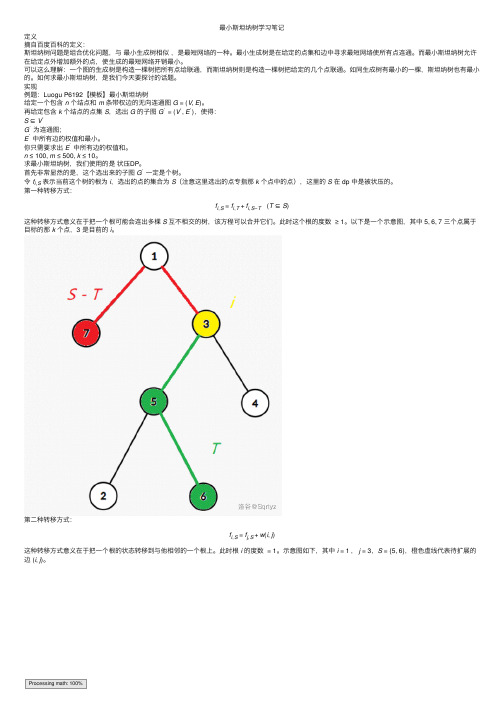
最⼩斯坦纳树学习笔记定义摘⾃百度百科的定义:斯坦纳树问题是组合优化问题,与最⼩⽣成树相似,是最短⽹络的⼀种。
最⼩⽣成树是在给定的点集和边中寻求最短⽹络使所有点连通。
⽽最⼩斯坦纳树允许在给定点外增加额外的点,使⽣成的最短⽹络开销最⼩。
可以这么理解:⼀个图的⽣成树是构造⼀棵树把所有点给联通,⽽斯坦纳树则是构造⼀棵树把给定的⼏个点联通。
如同⽣成树有最⼩的⼀棵,斯坦纳树也有最⼩的。
如何求最⼩斯坦纳树,是我们今天要探讨的话题。
实现例题:Luogu P6192【模板】最⼩斯坦纳树给定⼀个包含n个结点和m条带权边的⽆向连通图G=(V,E)。
再给定包含k个结点的点集S,选出G的⼦图G′=(V′,E′),使得:S⊆V′G′为连通图;E′中所有边的权值和最⼩。
你只需要求出E′中所有边的权值和。
n≤100,m≤500,k≤10。
求最⼩斯坦纳树,我们使⽤的是状压DP。
⾸先⾮常显然的是,这个选出来的⼦图G′⼀定是个树。
令f i,S表⽰当前这个树的根为i,选出的点的集合为S(注意这⾥选出的点专指那k个点中的点),这⾥的S在 dp 中是被状压的。
第⼀种转移⽅式:f i,S=f i,T+f i,S−T (T⊆S)这种转移⽅式意义在于把⼀个根可能会连出多棵S互不相交的树,该⽅程可以合并它们。
此时这个根的度数≥1。
以下是⼀个⽰意图,其中 5,6,7 三个点属于⽬标的那k个点,3 是⽬前的i。
第⼆种转移⽅式:f i,S=f j,S+w(i,j)这种转移⽅式意义在于把⼀个根的状态转移到与他相邻的⼀个根上。
此时根i的度数=1。
⽰意图如下,其中i=1,j=3,S={5,6},橙⾊虚线代表待扩展的边 (i,j)。
Processing math: 100%考虑 dp 顺序,显然S从⼩到⼤枚举即可。
对于第⼀种转移⽅式,只需枚举S的⼦集T。
对于第⼆种转移⽅式,注意到这玩意⼉是个三⾓不等式,联想到最短路也是如此——没错,⽤最短路跑⼀遍就⾏了。
参考代码int n, m, k, f[Maxn][1 << Maxk];struct Edge {int next, to, dis;}edge[Maxm * 2];int head[Maxn], edge_num;void add_edge(int from, int to, int dis) {edge[++edge_num].next = head[from];edge[edge_num].to = to;edge[edge_num].dis = dis;head[from] = edge_num;}queue <int> Q; int dist[Maxn]; bool inq[Maxn];void SPFA(int S) {memset(inq, 0, sizeof(inq));for(int i = 1; i <= n; ++i) {dist[i] = f[i][S];if(dist[i] != 1061109567) Q.push(i), inq[i] = 1;}while(Q.size()) {int u = Q.front();Q.pop();inq[u] = 0;for(int i = head[u]; i; i = edge[i].next) {int v = edge[i].to;if(dist[v] > dist[u] + edge[i].dis) {dist[v] = dist[u] + edge[i].dis;if(!inq[v]) {inq[v] = 1;Q.push(v);}}}}for(int i = 1; i <= n; ++i) f[i][S] = dist[i];}int main() {n = read(); m = read(); k = read();int u, v, w;for(int i = 1; i <= m; ++i) {u = read(); v = read(); w = read();add_edge(u, v, w);add_edge(v, u, w);}memset(f, 63, sizeof(f));for(int i = 1; i <= k; ++i) {u = read();f[u][1 << (i - 1)] = 0;}for(int i = 1; i <= n; ++i) f[i][0] = 0;for(int S = 0; S < (1 << k); ++S) {for(int i = 1; i <= n; ++i)for(int T = S & (S - 1); T; T = S & (T - 1))f[i][S] = min(f[i][S], f[i][T] + f[i][T ^ S]);SPFA(S);}int ans = 2e9;for(int i = 1; i <= n; ++i) ans = min(ans, f[i][(1 << k) - 1]);cout << ans << endl;return 0;}例题[WC2008] 游览计划考虑把每个⽅格当成⼀个点,最⼩斯坦纳树搞它就完了。
华为stp生成树协议笔记
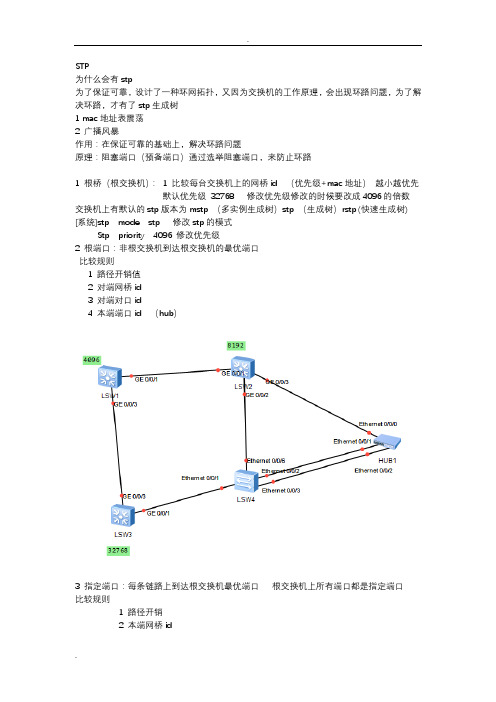
STP为什么会有stp为了保证可靠,设计了一种环网拓扑,又因为交换机的工作原理,会出现环路问题,为了解决环路,才有了stp生成树1 mac地址表震荡2 广播风暴作用:在保证可靠的基础上,解决环路问题原理:阻塞端口(预备端口)通过选举阻塞端口,来防止环路1 根桥(根交换机): 1 比较每台交换机上的网桥id (优先级+mac地址)越小越优先默认优先级 32768 修改优先级修改的时候要改成4096的倍数交换机上有默认的stp版本为mstp (多实例生成树)stp (生成树)rstp (快速生成树) [系统]stp mode stp 修改stp的模式Stp priority 4096 修改优先级2 根端口:非根交换机到达根交换机的最优端口比较规则1 路径开销值2 对端网桥id3 对端对口id4 本端端口id (hub)3 指定端口:每条链路上到达根交换机最优端口根交换机上所有端口都是指定端口比较规则1 路径开销2 本端网桥id3 本端端口id (端口优先级和端口编号)端口优先级默认是1284 剩下的端口就叫做阻塞端口Stp中的报文交互BPDU 桥协议数据单元两种bpdu 1 配置bpdu作用:用于角色(端口)选举维护网络拓扑 2秒1次最多20秒20 秒没有根的回应,则认为根down掉 2 tcn bpdu 拓扑变化bpdu作用:当拓扑发生变化时,会发tcn bpduBpdu 字段1 bpdu flsges标识字段Tca 位拓扑变化确认位Tc 位拓扑变化位发生变化时置12 root identifier 根网桥id3 root path cost 到达根的开销值4 bridge id 本交换机的网桥id5 port id 端口id0x8001 前面的80 代表优先级128 , 01代表端口号6 message age 消息寿命每经过一台交换机message age +17 max age 最大寿命 20 秒8 hello time 2秒9 forward delay 转发延迟 15秒端口的状态变化1 disable 开启stp时特点:不进行stp计算2 blocking 阻塞端口直接进入blocking 状态3 listening 非阻塞端口才进入侦听状态特点:加速mac地址表老化中间有15秒的间隔时间,目的是为了加速mac地址表老化,mac地址表老化时间300秒4 learning 学习状态中间有相隔15秒的时间,加速mac地址表的学习5 forwarding 转发状态当网络发生变化时,阻塞端口如何从discove 到forwarding状态的??主根备根都在汇聚层交换机设置为主根Stp root primary或者修改set primary 4096设置备份根Stp root secondary在交换机上出现的故障叫做直接故障根端口断掉后,预备端口直接变成根端口,需要30s到达forwarding状态当阻塞端口感觉到拓扑发生变化,发送tcn BPDU对端会回复一条tca=1拓扑变化确认当交换机收到根交换机范洪的网络变化tc=1的配置BPDU才能老化原来的路径,学习新的路径中间链路出现故障叫做间接故障至少需要50s的时间变为forwarding状态由于线路故障,Sw2 20s后老化了源路径,认为自己是根,向sw3发送bpdu,sw3收到两条bpdu,因此会检测到链路变化,由于链接s1的路径最优,所以向s1发送tcnBPDU,s1回复一挑tc=1的配置bpdu,交换机将原来的路径老化,并学习新的路径Stp的缺点:收敛过慢原因:stp中1.learning到forwarding需要15s学习mac地址Listening到learning需要15s 加速老化时间2.无论上述用了多少秒,最大等待时间总是15s3.发送tcnBPDU的时间过长RSTP快速生成树为什么会有RSTP?备份端口备份成为指定端口预备端口将来预备成为根端口预备端口和备份端口的相同点,正常情况下都不进行数据转发RSTP中端口状态变成了三种,将stp状态前三种合成一种,因为不学习mac也不转发数据三种状态:1.discarding 不学习mac也不转发数据2.learning 不转发数据但是学习mac3.forwarding 即学习mac也转发数据BPDU stp和rstp的区别配置BPDU RST BPDU(快速生成树bpdu)TCN BPDU标志位1.Tca 位(topology change acknowledgement)拓扑变化确认位2.同意位(agreement)3.转发位(Forwarding)4.学习状态(learning )中间有相隔15秒的时间,加速mac地址表的学习5.端口角色(port role)端口角色是11,证明这个端口是指定端口,如果是10则代表是根端口,01代表预备端口或者备份端口,00代表保留6.提议位(proposal)7.拓扑变化位(topology change)收敛速度快1.边缘端口:连接终端设备的端口优点:不会进行端口角色计算,直接变成forwarding状态配置边缘端口Interface g0/0/3Stp edged-port enable2.P/A机制提议/同意机制前提条件:点到点链路(全双工链路)交换机先发送一个RST BPDU给根,根收到后作比较,将自己的发给交换机,交换机发现网桥id比自己小比自己优先,就会发一个同意位给根交换机,根交换机上的接口变为指定接口,并直接变为forwarding状态Sw3当网络发生变化,马上启动一个 TC while 计时器:2倍的hellp时间,直接发送tcBPDU 给s2,四秒内,老化原来的mac地址,形成新的地址,s2收到后重复上述动作直到发给根交换机MSTP多实例生成树多个rstp的集合就是mstpInstance 实例:rstp单个实例树的弊端:1.一部分vlan路径不同2.无法使用流量分担3.会产生次优的二层路径建立两棵树,pc1发数据时,lsw4是根,pc2发数据时,lsw5是根从而解决单个实例树的弊端配置步骤1.创建vlan基本操作2.修改stp版本3.Stp region-configuration 创建域的范围4.Region-name Huawei 域的名字5.Revision-level 1(保证都相同)6.Instance 1 vlan 107.Instance 2 vlan 208.Active region-configuration激活mstp的配置9.每台交换机上都要配置10.只要修改就要重新激活11.设置实例的根Stp instance 1 root primary/secondary(主根/备份根)默认交换机上有实例0Mstp和arrp做联动时,mstp的主根一定是arrp的主当网络中有mstp,stp rstp时,最后会以stp运行,他们的模式依旧是mstp和rstp,但是发的bpdu报文是stp当mstp的交换机和stp的交换机相连时,发送的是stp的报文,当stp迁移走了,换了一个mstp的交换机时,不会自动回到mstp【swb】stp mcheck手动迁移回mstp配置mstp最大跳数默认最大跳数20跳Stu max-hops 30 修改最大跳数四个保护1.边缘端口保护(BPDU保护)为什么会有BPDU保护从边缘端口收到bpdu,会直接将边缘端口阻塞掉【系统】Stp bpdu-protection(stp,bpdu保护开启)2.指定端口保护(根的保护)从指定接口收到一个优先级比指定端口还低的端口pbdu,则交换机进入阻塞状态,保护自己永远为跟【指定接口】Stp root-portection 在指定端口下开启根的保护3.环路保护三个交换机之间使用光钎连接,由于光纤是由两条线路构成,一条收一条发,一旦收的根端口down掉,发的线路没有问题,此时阻塞端口启用,会形成环路解决方法,长时间收不到bpdu ,就把该端口阻塞掉接口下 stp loop-protection 开启环路保护4.TC-BPDU保护 TC如果恶意用户一直发送tc-bpdu,那么链路中的路径就会一直老化,此时设置一个阈值,超过上限就会丢弃该bpdu默认接受tc上限为1修改命令:stp tc-portection threshold 2。
ccnp交换学习笔记最终整理版2010910

第一天vlan_trunk_vtpVLAN优点:隔离广播域,提高了安全性,便于管理。
一个VLAN对应一个广播域,对应一个逻辑子网。
End-to-End VLAN(端到端的VLAN):在VLAN中的用户,与实际物理位置无关,如果用户移动到另一个区域,VLAN信息不会变。
Local VLAN(本地VLAN):Local VLAN建议把相同的VLAN信息放在相同的机架上。
ECNM(企业组件网络模型)----一个高性能的网络包括4大组件:安全性、实用性、可升级性、易管理。
安全性:一般双冗余可升级性:每个VLAN在不同的子网划分VLAN的两种方式:(1)Port-based基于端口的----静态VLAN(重点)移动性差(2)MAC-based基于MAC地址的----动态VLAN实验:需求R4与R6都划到VLAN10中,在交换机配置如下:SW1:vlan 10 //新建VLAN10nam e HR //给VLAN10起个名字int f0/4switchport access vlan 10 //把这个接口划到VLAN10中switchport m ode access //把这个接口设为接入端口。
一般用在这个接口接的是非交换设备。
int f0/6switchport access vlan 10switchport m ode accessshow vlan brief 查看VLAN信息低端交换机,如2900上配置:特权模式下:SW3#vlan databaseSW3(vlan)#vlan 10 name WOLFSW3(vlan)#exit//它有双重意义:先应用创建的VLAN10,然后退出int f0/6switchport access vlan 10switchport m ode accessint f0/4switchport access vlan 10switchport m ode access以上都是基于端口的VLAN动态VLAN简单介绍VLAN Management Policy Server(VMPS)---VLAN管理策略服务器,其实是一台交换机(如:Catalyst 4000/5000)这个报文叫VQP----VLAN查询协议,这种报文封装UDP端口号1589SVI交换虚拟接口,每个VLAN都有一个SVI。
CCNP笔记

EIGRP高级距离矢量型协议,管理距离值90 协议号是88 组播224.0.0.10FD:可行路由,是指自己到达目的地的距离AD:通告路由,是指邻居到达目的地的距离K1=带宽,K2=负载,K3=延迟。
K4=可靠性,K5=MTU最大传输单元K1=1, K2=0, K3=1, K4=0, K5=0 延迟(delay) 可靠性(reliability) 负载(loading)MTU 1500 bytes, BW 1544 Kbit, DLY 20000 usec, reliability 255/255, txload 1/255, rxload 1/255 Metric值=256乘以(10的7次方除以最小带宽(bps)+总延迟除以10)一、静态重发布:1、保证有静态路由。
2、发布静态到EIGRPr3(config)#router eigrp 100r3(config-router)#redistribute static二EIGRP宣告r1(config)#netword 0.0.0.0EIGRP负载必须是successor或者是fedsible successorV ariance 2 V值Successor(fd)*2(v值)>fedsible successor 可以做负载r1(config-if)#bandwidth 定义接口带宽show eigrp tppo查看FD all-lin查看多有接口FDOSPFLs:链路状态封装在IP不可靠传输协议号89 LSA:链路状态通告通过224.0.0.5全网组播ABRS:区域边界路由器ASBR:自治系统边界路由DR指定路由BDR:备份指定路由报文:hell建立邻居关系DBD:数据库摘要LSK:链路数据请求LSU:链路状态更新LSACK确认(显式确认针对LSU)DBD---LSK隐式确认:发送router ID 来确认谁先发送OSPF的LSA都是有3个特点第一种是:谁产生,第二种:范围,第三种:所携带的内容第一种LSA:router LSA:产生者是OSPF里的每一个路由器本身,范围是:只在本区域内第二种LSA:network LSA:只在MA网络中出现,点到点PPP是没有的,产生者:DR,范围:仅在本区域内,内容:描述多有和DR相连的路由,包括链路的子网掩码第三种LSA:network summary LSA。
CCNP-BSCI课堂笔记
NP BSCI 课程 (3)1.1.EIGRP 增强型内部网关路由协议 (3)1.1.1.EIGRP的特性: (3)1.1.2.EIGRP的关键技术 (3)1.1.3.EIGRP的术语 (3)1.1.4.EIGRP的包的类型 (3)1.1.5.EIGRP metric值的计算 (4)1.1.6.EIGRP的配置 (4)1.1.7.路由汇总 (6)1.1.8.非等价负载均衡 (6)1.1.9.基于MD5的认证加密 (7)1.2.OSPF 开放式最短路径优先协议 (8)1.2.1.工作的过程 (8)1.2.2.OSPF的区域划分 (8)1.2.3.关于OSPF的邻居关系与邻接关系 (9)1.2.4.OSPF包的类型 (9)1.2.5.DR和BDR的选举 (9)1.2.6.OSPF的实验配置 (10)1.2.7.Router-id 的选举 (11)1.2.8.OSPF网络类型 (11)1.2.9.Virtual-Link 虚链路 (12)1.2.10.LSA(链路状态通知) 的类型 (14)1.2.11.路由的类型 (16)1.2.12.修改OSPF接口COST值和路由器的带宽值 (16)1.2.13.OSPF的特殊区域 (17)1.2.14.OSPF的邻居认证 (19)1.2.15.OSPF的路由汇总 (20)1.3.IS-IS(中间系统) 路由协议 (21)1.3.1.基本概念 (21)1.3.2.相关术语 (21)1.3.3.相关特性 (21)1.3.4.Level-1 和Level-2 以及Level-1-2 (21)1.3.5.NSAP地址 (21)1.3.6.IS-IS的邻居建立条件 (22)1.3.7.纯IS-IS的实验配置 (22)1.3.8.集成IS-IS的实验配置 (24)1.4.BGP 边界网关协议 (26)1.4.1.何时使用BGP (26)1.4.2.满足以下条件之一时,不要使用BGP (26)1.4.3.BGP的特性 (27)1.4.4.BGP的数据库 (27)1.4.5.BGP的消息类型 (27)1.4.6.关于IBGP与EBGP之间的关系 (27)1.4.7.基本BGP邻居建立的实验 (29)1.4.8.高级的BGP(属性)实验 (30)1.4.9.BGP的路径属性 (33)1.4.10.BGP路由选择决策过程 (33)1.4.11.使用Route-map操纵BGP路径实验(Local_prefence As-path) (33)1.5.过滤路由的更新 (36)1.6.路由重分发(Redistribution) (37)1.6.1.将RIPv2路由重分发进OSPF 中 (37)1.6.2.将OSPF路由重分发进RIPv2中 (38)1.6.3.将EIGRP 100 重分发进OSPF 中 (38)1.6.4.将OSPF重分发进EIGRP 100中 (39)1.6.5.将RIP v2重分发进EIGRP 100 中 (39)1.6.6.将EIGRP 100 重分发进RIPv2中 (39)1.6.7.将EIGRP 100 重分发进EIGRP 10 (40)1.6.8.将EIGRP 100重分发进集成ISIS中 (40)1.6.9.将ISIS 重分发进EIGRP 100 (41)1.6.10.将ISIS重发分进OSPF中 (41)1.6.11.将OSPF 重分发进ISIS中 (42)1.7.各种路由协议的管理距离值 (42)1.8.(MultiCast)组播 (43)1.8.1.单播数据流 (43)1.8.2.广播数据流 (43)1.8.3.组播数据流 (44)1.8.4.组播的缺点: (44)1.8.5.IP的组播地址(3层地址) (45)1.8.6.数据链路层的2层组播地址 (45)1.8.7.IGMP互联网组管理协议 (46)1.8.8.第2层组播帧交换 (47)1.8.9.组播路由协议 (47)1.8.10.带有RP的稀疏密集的实验配置 (48)1.9.IPV6 (48)1.9.1.IPV6的特性 (48)1.9.2.地址空间 (49)1.9.3.IPv6的地址格式 (49)1.9.4.IPv6地址类型 (49)1.9.5.组播地址Multicast (50)1.9.6.任意播地址Anycast (51)1.9.7.EUI(扩展全局标识)地址格式 (51)1.9.8.IPv6与OSPFv3的实验配置 (52)NP BSCI 课程1.1.EIGRP 增强型内部网关路由协议1.1.1.EIGRP的特性:属CISCO私有协议高级的距离矢量路由协议实现网络的快速收敛支持变长子网掩码和不连续的子网路由更新时发送变化部分的更新内容路由更新采用触发更新机制,只当网络发生变化的时候,才会发送路由更新支持多个网络层的协议(IP、IPX、Novell协议)使用组播和单播技术代替了广播(组播地址:224.0.0.10)在网络的任意点可方便的创建手动路由汇总实现100%无环路(基于DUAL(弥散更新算法))支持等价的和非等价的负载均衡1.1.2.EIGRP的关键技术邻居的发现和恢复使用Hello包来建立,高速链路5秒发送Hello包,低速链路是60秒发送Hello包是一个RTP(可靠的传输协议)协议,能够保证所有的更新数据包能被邻居路由器接受到使用DUAL算法机制,选择一个低代价、无环路的路径到达每一个目标段1.1.3.EIGRP的术语1、Successor 后继路由\\ 主路由2、Feasible Successor (FS)可行后继路由\\备用路由3、Feasible Distance (FD)可行距离\\指从源到达目标段的路径距离值4、Advertised Distance (AD)通告距离\\是指通告路由器到达目标段的距离值1.1.4.EIGRP的包的类型HelloUpdate 更新包Query 查询包Reply 应答包ACK 确认包Router# debug eigrp packet //关闭debug使用undebug all1.1.5.EIGRP metric值的计算K1= 带宽1 BWK2= 负载0 txload(发送) 1/255 rxload(接收) 1/255 255代表固定参考值 K3= 延迟1 DLY 100M=100 10M=1000 1.544M=20000K4= 可靠性0 Reliability 255/255 (最可靠)K5= 最大传输单元0 MTU 1500注:1代表使用, 0代表未被使用Router# show interface E0/0计算公式Metric= [ 107/最小带宽(k) + (延迟)/10]×256说明:最小带宽:指从源到达目的网段链路中的最小带宽延迟:指每段链路的延迟总和1.1.6.EIGRP的配置R1(config)# router eigrp 100R1(config-router)# no auto-summaryR1(config-router)# network 12.0.0.0 0.0.0.3R1(config-router)# network 13.0.0.0 0.0.0.3R1(config-router)# endR2(config)# router eigrp 100R2(config-router)# no auto-summaryR2(config-router)# network 12.0.0.0 0.0.0.3R2(config-router)# network 23.0.0.0 0.0.0.3R2(config-router)# endR3(config)# router eigrp 100R3(config-router)# no auto-summaryR3(config-router)# network 13.0.0.0 0.0.0.3R3(config-router)# network 23.0.0.0 0.0.0.3R3(config-router)# endR1#show ip routeCodes: C - connected, S - static, R - RIP, M - mobile, B - BGPD - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter areaN1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2E1 - OSPF external type 1, E2 - OSPF external type 2i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2ia - IS-IS inter area, * - candidate default, U - per-user static routeo - ODR, P - periodic downloaded static routeGateway of last resort is not set23.0.0.0/30 is subnetted, 1 subnetsD 23.0.0.0 [90/2681856] via 13.0.0.2, 00:00:12, Serial0/1[90/2681856] via 12.0.0.2, 00:00:12, Serial0/012.0.0.0/30 is subnetted, 1 subnetsC 12.0.0.0 is directly connected, Serial0/013.0.0.0/30 is subnetted, 1 subnetsC 13.0.0.0 is directly connected, Serial0/1说明:[90/2681856] [协议管理距离/Metric度量值]R1#show interfaces s0/0Serial0/0 is up, line protocol is upHardware is M4TInternet address is 12.0.0.1/30MTU 1500 bytes, BW 1544 Kbit, DLY 20000 usec,reliability 255/255, txload 1/255, rxload 1/255Metric= [ 107/最小带宽(k) + (延迟+延迟)/10]×256Metric= [ 107/1544 + 4000] ×256Metric= [ 6476 + 4000] ×256Metric= 2681856说明:当107/1544 时候,会出现小数点,立即取整数位,舍弃小数点。
红头发CCNP学习笔记
1.IGP(EIGRP/OSPF/IS-IS)2.EGP(BGP)3.policy4.IP multicast5.路由表:控制层和数据层(FIB)组成。
接入层:ACCESS LAYER端口密度汇聚层:DISTRIBUTION LAYER接入层流量的聚合点,高可用性(冗余+热备份)核心层:CORE LAYER高可用性+高吞吐量,快速转发数据。
Backbone+MAN层二:交换,(以太网)层三:路由可收敛的网络(可聚合的网络)的流量:--语音+视频流量--语音应用程序(IP电话)--办公性质--路由更新--网络管理流量(监控和日志)关键的需求:性能:带宽,延迟,抖动(jitter,到每个节点延迟的偏移量),语音和视频对延迟和抖动要求高。
Real-time 实时流量对延迟,抖动要求高,不可逆性安全:接入和转发。
SONA----语音,视频和数据的综合数据体系,是AVVID 的扩展。
目的是将网络朝IIN(智能信息网)方向推进,IIN 有三个阶段:集成传输,集成服务,集成应用。
SONA>>IIN网络放大效应效率=IT资产成本/ IT资产成本+运营成本使用率=所使用的资产/总资产(%)效能=效率*使用率网络放大效应=使用SONA的效能/不适用SONA的效能IS-IS用于超大型网络,而EIGRP,OSPF用于大型网络环境。
OSPF在NBMA网络上的运行模式:一.RFC:2328定义的:1.nonbroadcast(NBMA)非广播(不支持广播和组播)---- 默认模式(星型网络)必须在同一个子网内。
特点:1.要选举DR/BDR,所有接口处于同一子网,要确保中心路由器(hub)成为BD/BDR.2.边缘路由器(spoke)相互之间要作DLCI的映射(DLCI的复用)3.必须手动指定邻居(neighbor命令)把组播流量(hello包)已单播的形式传输出去2.point-to-multipoint(P2M)1.要选举DR/BDR,所有接口处于同一子网2.多点FR子接口要修改接口的网络类型3.SPOKE之间无需做DLCI复用二.CISCO定义的标准:1.broadcast1.要选DR/BDR,所有接口处于同一子网要确保中心路由器(hub)成为BD/BDR.2.边缘路由器(spoke)相互之间要作DLCI的映射(DLCI的复用)2.point-to-point(P2P)1.DR/BDR不选举,hello time 为10s2.hub要划分子接口,两个子接口在不同的子网3.point-to-multipoint nonbroadcast(P2M NBMA)1.要选举DR/BDR,所有接口处于同一子网2.多点FR子接口要修改接口的网络类型3.SPOKE之间无需做DLCI复用4.需要手动指定邻居。
ccnp详细笔记-switch总结
ccnp详细笔记-switch总结.docCCNP详细笔记 - SWITCH前言CCNP(Cisco Certified Network Professional)是思科认证网络专业人士的简称,是网络领域内高度认可的专业资格认证。
SWITCH是CCNP认证考试的一部分,主要涉及园区网交换和LAN交换技术。
本文档将提供SWITCH考试的详细笔记,帮助考生全面复习和准备。
第一部分:园区网交换概念VLAN(虚拟局域网)定义:VLAN是一种在交换机上创建不同广播域的技术,用于隔离网络流量。
配置:通过vlan database模式创建VLAN,并使用vlan id命令分配ID。
Trunking定义:Trunking是一种允许多个VLAN通过单个物理链路传输的技术。
配置:使用switchport mode trunk命令在端口上启用Trunking。
EtherChannels定义:EtherChannel允许将多个物理链路捆绑成一个逻辑通道,增加吞吐量和冗余。
配置:使用channel-group命令创建EtherChannel。
STP(生成树协议)定义:STP用于防止网络中的环路,通过选择活动路径和备用路径来管理网络拓扑。
配置:可以通过spanning-tree命令配置STP参数。
第二部分:LAN交换技术端口安全定义:端口安全用于限制连接到特定交换机端口的设备数量,防止MAC 地址泛滥。
配置:使用switchport port-security命令设置端口安全。
QoS(服务质量)定义:QoS用于管理网络流量,确保关键应用的性能。
配置:通过分类、标记、队列和调度等技术实现QoS。
ACL(访问控制列表)定义:ACL用于过滤网络流量,控制对网络资源的访问。
配置:使用ip access-group命令应用ACL。
无线LAN集成定义:无线LAN集成允许将无线接入点与有线网络无缝集成。
配置:涉及WAP(无线接入点)的配置和无线控制器的管理。
CCNA培训课总结笔记
CCNA培训课总结笔记版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章、作者信息和本声明。
否则将追究法律责任。
前记:虽然只有短短的五天CCNA培训,但学习的东西还挺多的,压力也很大.老师课堂上又讲得太快,笔记都记得一塌糊涂.只能回来后慢慢整理一下,在这里写出来和大家分享一下,匆促落笔,难免有错误,不足之处,望大家不吝批评指正.CCNA培训课笔记(一)一. 建议学好Cisco+windows+Linux这方面的知识,将来就会有好前途.考过CCNA之后,因为现在的CCNP太多人考,市场需求也基本饱和,所建议以后学CCSP、CCVP比较有市场.二. 开始课程的学习:学习CCNA主要是学习两大板块的知识,即route+switch.关于教材方面,如果个人自己英文好的话建议买英文的原版教材看.因为中文的教材一般都是直接直译过来的.(1) 首先学习的是OSI参考模型,由上到下分别为七层:应用层(第七层,Application layer):文件、打印、消息、数据库和应用服务表示层(第六层,Presentation layer):数据加密、压缩和转换服务器会话层(第五层,Session layer):会话控制传输层(第四层,Transport layer):端到端连接网络层(第三层,Network layer)路由选择数据链路层(第二层,Data layer):组帧,由MAC、LLC组成物理层(第一层,Physical layer):物理拓扑注意:工作在网络层的路由器为广播域, 每个接口各自为冲突域;工作在数据链路层的交换机为一个广播域,每个接口各自为冲突域工作在物理层的集线器为一个广播域,一个冲突域.(2) 接下来学习的是TCP/IP参考模型(协议书)由上到下分为四层:应用层:用户能够用到的,比如http,https,ftp,telnet,snmp等传输层: TCP(可靠的连接保证),UDP(不可靠的连接)网络层:(host-to-host) IP:RIPv2、EIGRP(思科专有)、OSPF(华为重点掌握,面试常考)接入层:ARP(地址解释协议):IP地址->MAC地址,ICMP(互联控制管理协议)注意:实验时ping命令执行时连通的话会出现这五个感叹号!课余时间老师讲了一下目前比较热门的技术,所谓的融合通信.思科之前提出过统一通信而我车提出的是“三网合一”,即将数据网、电话网、有线电视三个网络合在一条线传输.下一代网络主要是软交换,VG(语音网关).最后推荐学习的书籍:TCP/IP详解卷1 协议(美) stevensCCIE TCP/IP路由协议JeffCCNA笔记(转载)--------------------------------------------------------------------------------2008-03-17 02:37:31标签:CCNA 笔记[推送到技术圈]1ccna中文读书笔记cisco certified network associate 640-801 icnd course notes chapter1 internetworkinginternetworking basics把1个大的网络分成几个小点的网络称之为”网络分段”(network segment),这些工作由routers,switches和bridges来完成引起lan拥塞的可能的原因是:1.太多的主机存在于1个广播域(broadcast domain)2.广播风暴3.多播4.带宽过低在网络中使用routers的优点:1.它们默认是不会转发广播的2.它们可以基于layer-3(network layer)的信息来对网络进行过滤switches的主要目的:提高lan的性能,提供给用户更多的带宽冲突域(collision domain):ehernet术语之1,处于冲突域里的某个设备在某个网段发送数据包,强迫该网段的其他所有设备注意到这个包.而在某1个相同时间里,不同设备尝试同时发送包,那么将在这个网段导致冲突的发生,降低网络性能bridges在某种意义上等同与switches,不同的地方啊bridges只包括2到4个端口(port),而switches可以包括多达上百端口.但是相同的地方是它们都可以分割大的冲突域为数个小冲突域,因为1个端口即为1个冲突域,但是它们仍然处在1个大的广播域中.分割广播域的任务,可以又routers来完成.internetworking models早期各个网络厂商拥有私有网络,不便于同其他厂商的网络进行通讯.于是,在20世纪70年代末期,iso组织创建了osi(open system interconnection)参考模型.osi参考模型,用于帮助不同厂家创建可与对方进行协同工作的网络设备和软件等等,最大的特点是分层.但是它仍然只是个参考模型而非物理模型advantages of refernce modelsosi参考模型分层化的优点:1.允许多厂家共同发展网络标准化组件2.允许不同类型的网络硬件和软件相互通信3.防止其中某层的变化影响到其他层,避免牵制到整个模型the osi reference modelosi参考模型分为7层2组;最高3层定义了端用户如何进行互相通信;底部4层定义了数据是如何端到端的传输.最高3层,也称之为上层(upper layer),它们不关心网络的具体情况,这些工作是又下4层来完成。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
802.1d,802.1w,802.1s与802.1q一.STP:在谈本主题之前,先简单的对STP(802.1d)做个回顾.STP是用于打破层2环路的协议,但这个协议有个最明显的缺点,就是当层2网络重新收敛的时候,至少要等待50秒的时间(转发延迟+老化时间).50秒的时间对于一个大型的层2网络来说,是一个漫长的过程(何况这只是个理论时间,实际情况还会更长).虽然CISCO对STP的这些缺点开发出了些弥补性的特性,比如Port Fast,Uplink Fast和Backbone Fast,用于加快层2网络的收敛时间.套用王朔的话"看上去很美".虽然这些"新"特性能够改善STP的一些不足,但是,这些特性是CISCO私有的,而非行业标准;此外,这些特性要求我们做额外的配置,如果缺乏对这些技术的理解,还有可能导致环路问题.二.RSTP:RSTP是IEEE 802.1w标准定义的,目的就是为了改进STP的一些不足,并且在某些情况下,RSTP要比之前所提到的那些Port Fast,Uplink Fast和Backbone Fast 技术更为方便.但是在比较古老的交换机型号中比如CATALYST 2900XL/3500XL 里,不支持RSTP与RPVST+(或叫PVRST+),还有些型号比如CATALYST2948G-L3/4908G-L3,CATALYST 5000/5500和CATALYST 8500不支持RSTP.802.1d标准中对端口状态的定义有:1.监听(listening).2.学习(learning).3.堵塞(blocking).4.转发(forwarding).5.禁用(disabled).802.1w标准中对端口状态的定义有:1.丢弃(discarding).2.堵塞(blocking).3.转发(forwarding).丢弃状态,实际上就类似802.1d中监听,学习和禁用状态的集合.在802.1w中,根端口(root port,RP)和指定端口(designated port,DP)仍然得以保留;而堵塞端口被改进为备份端口(backup port,BP)替代端口(alternate port,AP).不过,生成树算法(STA)仍然是依据BPDU决定端口的角色.和802.1d中对RP的定义一样,到达根桥(root bridge)最近的端口即为RP.同样的,每个桥接网段上,通过比较BPDU,决定出谁是DP.一个桥接网段上只能有一个DP(同时出现两个的话就形成了层2环路).在802.1d中,非RP和DP的端口,它的状态就为堵塞状态,这种状态虽然不转发数据,但是仍然需要接收BPDU来保持处于堵塞状态.AP和BP同样也是这样.AP提供了到达根桥的替代路径,因此,一旦RP挂掉后,AP可以取代RP的位置.BP也提供了到达同一桥接网段以及AP所不能保证到根桥连接性的冗余链路.在RSTP里,BPDU的格式稍稍变化了一些,在802.1d里,BPDU只有两个标签选项:1.拓扑改变(TC).2.拓扑改变确认(TCA).而RSTP中的BPDU采用的是版本2的BPDU,换句话说802.1d网桥将丢弃这种新的BPDU.这种新的BPDU,在原先的BPDU基础上增加了6个标签选项:BPDU的处理方式,和802.1d也有些不同,取代原先的BPDU中继方式(非根桥的RP 收到来自根桥的BPDU后,会重新生成一份BPDU朝下游交换机发送出去),802.1w 里的每个网桥,在BPDU hello time(默认2秒)的时间里生成BPDU发送出去(即使没有从根桥那里接收到任何BPDU).如果在连续3个hello time里没有收到任何BPDU,那么BPDU信息将超时不被予以信任.因此,在802.1w里,BPDU更像是一种保活(keepalive)机制.即,如果连续三次未收到BPDU,那么网桥将认识它丢失了到达相邻网桥RP或DP的连接.这种快速老化的方式使得链路故障可以很快的被检测出来.在RSTP里,类似Backbone Fast的下级BPDU(inferior BPDU)也被集成进去.当交换机收到来自RP或DP的下级BPDU时,它立刻替换掉之前的BPDU并进行存储:如上图,由于C知道根桥仍然是可用的,它就立刻向B发送关于根桥的BPDU信息.结果是B停止发送它自己的BPDU,接收来自C的BPDU信息并将连接到C的端口做为新的RP.传统的802.1d标准里,STA是被动的等待层2网络的收敛(由于转发延迟的定义).对STP默认的计时器进行修改,可能又会导致STP的稳定性问题;而RSTP可以主动的将端口立即转变为转发状态,而无需通过调整计时器的方式去缩短收敛时间.为了能够达到这种目的,就出现了两个新的变量:边缘端口(edge port)和链路类型(link type).边缘端口(EP)的概念,和CISCO中Port Fast特性非常相似.由于连接端工作站的端口,是不可能导致层2环路的,因此这类端口就没有必要经过监听和学习状态,从而可以直接转变为转发状态.但是和Port Fast不同的是,一旦EP收到了BPDU,它将立即转变为普通的RSTP端口:RSTP快速转变为转发状态的这一特性,可以在EP和点到点链路上实现的.由于全双工操作的端口被认为是点到点型的链路;半双工端口被认为是共享型链路.因此RSTP会将全双工操作的端口当成是点到点链路,从而达到快速收敛.当STA决定出DP后,对于802.1d,仍然要等待30秒的转发延迟才能进入转发状态;在802.1w里:假设根桥和交换机A之间创建了一条新的链路,链路两端的端口刚开始均处于堵塞状态,直到收到对方的BPDU.当DP处于丢弃或者学习状态,它将在自己将要发送出去的BPDU里设置提议位(proposal bit),如上图的p0和步骤1.由于交换机A收到了上级(superior)信息,它将意识到自己的P1应该立即成为RP.此时交换机A将采取同步(sync)动作,将该上级BPDU信息洪泛到其他的所有端口上并保证这些端口处于同步状态(in-sync).当端口满足下列标准之一时,即处于同步状态:1.端口为EP.2.端口为堵塞状态(即丢弃,或者为稳定拓扑).假设交换机A的P2为AP,P3为DP,P4为EP.P2和P4满足上述标准之一,因此为了处于同步状态,交换机A将堵塞P3,指定它为丢弃状态,其他端口处于同步状态(步骤2).交换机A将解除P1的堵塞状态做为新的RP,并向根桥反馈确认信息(步骤3),这个信息其实是之前步骤1所发的提议BPDU信息的拷贝,只不过是把提议位设置成了认可位(agreement bit).当P2收到这个认可信息后,它立即进入转发状态.由于P3之前被堵塞了,当步骤3完成后,P3也执行之前P0所经过的步骤1,向下游交换机发出提议BPDU信息,尝试快速进入转发状态.依次类推.由于提议机制非常迅速,因此RSTP不需依赖任何计时器.如果一个指定为丢弃状态的端口,在发出提议BPDU信息后没有收到认可信息,该端口会回退到802.1d 标准,从监听到学习,再慢慢进入转发状态.这种情况多发生在不理解RSTP BPDU 的交换机端口上.RSTP里另外一个快速进入转发状态的机制,和CISCO对STP的扩展技术Uplink Fast很相似.当网桥丢失了RP后,它会把自己的AP直接设置为转发状态(新的RP).因此对于RSTP来说,Uplink Fast的特性无需手动配置.还有一点和802.1d 不同的是,当交换机检测到拓扑变化后,产生TC信息,直接洪泛给整个网络,而无需像802.1d那样先报告给根桥:三.MST:MST是由IEEE 802.1s标准制定,来自CISCO私有的MISTP协议(Multiple Instances Spanning Tree Protocol).和RSTP一样,MST在某些CATALYST交换机上也不支持,比如:CATALYST 2900/3500XL,CATALYST2948G-L3/4908G-L3,CATALYST 5000/5500以及CATALYST 8500.在谈MST之前先说说关于trunk的原始版本IEEE 802.1q,该标准制定了CST(Common Spanning Tree).CST假定整个层2网络只有一个STP的实例,也就是说不管整个层2网络划分了多少个VLAN,都只有一个STP的实例.CST的一些优劣:1.缺点:无法实现STP的负载均衡.2.优点:节约CPU资源,整个层2网络只需要维护一个STP的实例.而后续的802.1q增强了对VLAN的支持,出现了PVST+(每1个VLAN有1个STP 的实例).802.1s结合了PVST+和802.1q的优点,将多个VLAN映射到较少的STP实例.之前的PVST+的优点,可以实现STP的负载均衡,对CPU资源是个负担.而MST减少了不必要的STP的实例.如下图,假设D1和D2分别为VLAN 1到500和VLAN 501到1000的根桥,如果用PVST+,就将有1000个STP的实例,但是实际上整个层2网络只有2个逻辑拓扑,所以优化办法是将STP的实例减少到2个,同时保留STP 负载均衡的优点:从技术角度来看,MST的确是最佳解决方案,但是对端用户而言却并不是必需的,因为MST通常要求比802.1d和802.1w更为复杂的配置,并且还可能遇到与802.1d的协同操作问题.之间提到了,多个VLAN可以映射到一个STP的实例上.但是,决定哪个VLAN和哪个STP实例相关联,以及BPDU的标签方式以便交换机可以鉴别出VLAN与STP实例信息,这是个问题.这个时候就出现了一个类似BGP里AS的概念:区域(Region).MST的区域是指处于同一管理范围的交换机组.为了能够成为MST区域里的一部分,交换机必须享有相同的配置属性:1.以26个字母命名的配置名(32字节).2.配置修正号(2字节).3.对应4096个VLAN的元素表.在做VLAN到STP实例映射的时候,要先定义MST的区域,但这个信息不会在BPDU 里传播,因为对于交换机来说,它只需要知道自己和邻居交换机是否处于同一个MST区域.因此,只有一份VLAN到STP实例的映射摘要信息,配置修正号,与配置名随着BPDU被传播出去.当交换机端口收到该BPDU后,它将解读该摘要信息,和自身的摘要信息做个比较,如果结果不同,那么该端口将成为MST区域的边界:根据802.1s的定义,MST网桥必须能够处理至少两种实例:1.一个IST(Internal Spanning Tree).2.一个或多个MSTI(Multiple Spanning Tree Instance).当然到目前为止,802.1s只是个"准标准",这些术语可能随着最终版的802.1s而有不同的叫法.CISCO支持1个IST和15个MSTI.由于MST源自IEEE 802.1s,因此,要必须让802.1s和802.1q(CST)协同操作.IST 实例向CST发送或从CST那里接收BPDU.IST实例其实是RSTP实例的简化,它扩展了MST区域里的CST.IST可以看做CST外部的整个MST区域的代表:如上图,这两种图例职能相同.在典型的802.1d环境里,你可能会看到堵塞M和B 之间的通信;同样的,你可能期望堵塞图中MST区域里的某个端口(而不是堵塞D).但是,由于IST是做为整个MST区域的代表,因此,你看到的就是对B和D的堵塞.MSTI也是RSTP的简化版实例,它只存在于MST区域的内部.MSTI默认自动运行RSTP,而无需额外的配置.和IST不同的是,MSTI永远不会和MST区域外部通信.另外,只有IST会向MST区域外发送BPDU,而MSTI不会.在MST区域内,网桥相互交换MST BPDU,这些MST BPDU对IST来说可以看成是RSTP BPDU.配置MST示例:Switch(config)# spanning-tree mstconfiguration /---进入MST配置模式---/Switch(config-mst)# instance 1 vlan 10-20 /---将VLAN 10到20映射到实例1里,VLAN范围为1-4094,实例范围为0-4094---/Switch(config-mst)# nameregion1 /---命名MST区域,32字节长的字符,大小写敏感---/Switch(config-mst)# revision1 /---配置修正号,范围是0到65535---/Switch(config-mst)# showpending /---显示等待用户确认的配置信息---/Pending MST configurationName [region1]Revision 1Instance Vlans Mapped-------- ---------------------0 1-9,21-40941 10-20-------------------------------Switch(config-mst)#exit /---应用配置并退出MST配置模式---/Switch(config)# spanning-tree mode mst /---启用MST,同时让RSTP生效---/指定MST根桥与配置MST网桥的优先级:Switch(config)# spanning-tree mst {instance-id} root {primary|secondary} [diameter net-diameter [hello-time ses]]对于MST,半径范围只能为0;默认配置信息2秒发送1次,可选修改范围为1-10秒.Switch(config)# spanning-tree mst {instance-id} priority {priority}端口优先级的值范围是0-61440,以4096递增,值越低,优先级越高,默认为32768.配置MST端口优先级与路径开销:Switch(config)#spanning-tree mst {instance-id} port-priority {priority}端口优先级的值范围是0-240,以16递增,值越低,优先级越高.Switch(config)# spanning-tree mst {instance-id} cost {cost}路径开销的值范围是1到200000000,取决于接口带宽.配置MST的相关计时器:Switch(config)# spanning-tree mst hello-time {sec}默认配置信息2秒发送1次,可选修改范围为1-10.Switch(config)# spanning-tree mst forward-time {sec}默认转发延迟为15秒,可选修改范围为4-30.Switch(config)# spanning-tree mst max-age {sec}指定MST实例的最大生存周期,默认为20秒,可选修改范围为6-40.指定BPDU的最大跳数:Switch(config)# spanning-tree mst max-hops {hop-count}默认为20跳,可选修改范围为1-255.定义链路类型为点到点:Switch(config-if)# spanning-tree link-type point-to-point一些验证命令:Switch#show spanning-tree mst configuration验证MST区域信息.Switch#show spanning-tree mst [instance-id]验证MST实例信息.Switch#show spanning-tree mst interface [interface-id]验证特定接口的MST实例信息.。