课程设计题目九:图的广度优先遍历
数据结构的课程设计

数据结构的课程设计一、课程目标知识目标:1. 理解数据结构的基本概念,掌握线性表、树、图等常见数据结构的特点与应用场景。
2. 学会分析不同数据结构的存储方式和操作方法,并能运用到实际问题的解决中。
3. 掌握排序和查找算法的基本原理,了解其时间复杂度和空间复杂度。
技能目标:1. 能够运用所学数据结构知识,解决实际问题,提高编程能力。
2. 能够运用排序和查找算法,优化程序性能,提高解决问题的效率。
3. 能够运用数据结构知识,分析并解决复杂问题,培养逻辑思维能力和创新意识。
情感态度价值观目标:1. 培养学生对数据结构学科的兴趣,激发学习热情,形成主动探索和积极进取的学习态度。
2. 增强学生的团队协作意识,培养合作解决问题的能力,提高沟通表达能力。
3. 培养学生的抽象思维能力,使其认识到数据结构在计算机科学中的重要性,激发对计算机科学的热爱。
本课程针对高中年级学生,结合学科特点和教学要求,注重理论与实践相结合,培养学生的编程能力和逻辑思维能力。
通过本课程的学习,使学生能够掌握数据结构的基本知识,提高解决实际问题的能力,同时培养良好的学习态度和价值观。
在教学过程中,将目标分解为具体的学习成果,以便进行后续的教学设计和评估。
二、教学内容1. 数据结构基本概念:介绍数据结构的概念、作用和分类,重点讲解线性结构(线性表、栈、队列)和非线性结构(树、图)的特点。
2. 线性表:讲解线性表的顺序存储和链式存储结构,以及相关操作(插入、删除、查找等)。
3. 栈和队列:介绍栈和队列的应用场景、存储结构及相关操作。
4. 树和二叉树:讲解树的定义、性质、存储结构,二叉树的遍历算法及线索二叉树。
5. 图:介绍图的定义、存储结构(邻接矩阵和邻接表)、图的遍历算法(深度优先搜索和广度优先搜索)。
6. 排序算法:讲解常见排序算法(冒泡排序、选择排序、插入排序、快速排序等)的原理、实现及性能分析。
7. 查找算法:介绍线性查找、二分查找等查找算法的原理及实现。
数据结构课程设计题目

题目1:图的遍历功能:实现图的深度优先, 广度优先遍历算法,并输出原图结构及遍历结果。
分步实施:1) 初步完成总体设计,搭好框架;2)完成最低要求:两种必须都要实现,写出画图的思路;3)进一步要求:画出图的结构,有兴趣的同学可以进一步改进图的效果。
要求:1)界面友好,函数功能要划分好2)总体设计应画一流程图3)程序要加必要的注释4)要提供程序测试方案5)程序一定要经得起测试,宁可功能少一些,也要能运行起来,不能运行的程序是没有价值的。
题目2:n维矩阵乘法:A B-1功能:设计一个矩阵相乘的程序,首先从键盘输入两个矩阵a,b的内容,并输出两个矩阵,输出ab-1结果。
分步实施:1)初步完成总体设计,搭好框架,确定人机对话的界面,确定函数个数;2)完成最低要求:建立一个文件,可完成2维矩阵的情况;3)一步要求:通过键盘输入维数n。
有兴趣的同学可以自己扩充系统功能。
要求:1)界面友好,函数功能要划分好2)总体设计应画一流程图3)程序要加必要的注释4)要提供程序测试方案5)程序一定要经得起测试,宁可功能少一些,也要能运行起来,不能运行的程序是没有价值的。
题目3:数组应用功能:按照行优先顺序将输入的数据建成4维数组,再按照列优先顺序输出结果,给出任意处的元素值,并给出对应的一维数组中的序号。
分步实施:1.初步完成总体设计,搭好框架,确定人机对话的界面,确定函数个数;2.完成最低要求:完成第一个功能;3.进一步要求:进一步完成后续功能。
有兴趣的同学可以自己扩充系统功能。
要求:1)界面友好,函数功能要划分好2)总体设计应画一流程图3)程序要加必要的注释4)要提供程序测试方案5)程序一定要经得起测试,宁可功能少一些,也要能运行起来,不能运行的程序是没有价值的。
题目4:数组应用2功能:读入数组下标,求出数组A靠边元素之和;求从A[0][0]开始的互不相邻的各元素之和;当m=n时,分别求两条对角线上的元素之和,否则打印出m!=n的信息。
采用邻接表存储结构实现图的广度优先遍历。

精心整理课程设计题目九:图的广度优先遍历基本要求:采用邻接表存储结构实现图的广度优先遍历。
(2)对任意给定的图(顶点数和边数自定),建立它的邻接表并输出;(3)实现图的广度优先遍历*/#include<iostream.h>#include<stdio.h>#include<malloc.h>#defineMAX_NUM20intvisited[MAX_NUM]={0};typedefintVertexType;typedefenum{DG=1,UDG}GraphKind;typedefstructArcNode{intadjvex;intweight;structArcNode*nextarc;ArcNode*info;}ArcNode;typedefstructVNode{VertexTypedata;ArcNode*firstarc;}VNode,AdjList[MAX_NUM];typedefstruct{AdjListvertices;intvexnum,arcnum;GraphKindkind;}ALGraph;voidPRIN(ALGraph&G);voidCreat_adjgraph(ALGraph&G);voidbfs(ALGraph&G,intv);voidCreat_adjgraphDG(ALGraph&G);voidCreat_adjgraphUDG(ALGraph&G);voidCreat_adjgraph(ALGraph&G);voidCreat_adjgraphDG(ALGraph&G){inti,s,d;ArcNode*p=NULL,*q=NULL;G.kind=DG;printf("请输入顶点数和边数:");scanf("%d%d",&G.vexnum,&G.arcnum);for(i=0;i<G.vexnum;++i){printf("第%d个顶点信息:",i+1);scanf("%d",&G.vertices[i].data);G.vertices[i].firstarc=NULL;}for(i=0;i<G.arcnum;++i){printf("第%d条边的起始顶点编号和终止顶点编号:",i+1);scanf("%d%d",&s,&d);while(s<1||s>G.vexnum||d<1||d>G.vexnum){printf("编号超出范围,重新输入");scanf("%d%d",&s,&d);}s--;d--;p=new(ArcNode);p->adjvex=d;p->nextarc=G.vertices[s].firstarc;G.vertices[s].firstarc=p;}}voidCreat_adjgraphUDG(ALGraph&G){inti,s,d;ArcNode*p,*q;G.kind=UDG;printf("请输入顶点数和边数:");scanf("%d%d",&G.vexnum,&G.arcnum);for(i=0;i<G.vexnum;++i){printf("第%d个顶点信息:",i+1);scanf("%d",&G.vertices[i].data);G.vertices[i].firstarc=NULL;}for(i=0;i<G.arcnum;++i){printf("第%d条边的起始顶点编号和终止顶点编号:",i+1);scanf("%d%d",&s,&d);while(s<1||s>G.vexnum||d<1||d>G.vexnum){printf("编号超出范围,重新输入");scanf("%d%d",&s,&d);}s--;d--;p=new(ArcNode);p->adjvex=d;p->nextarc=G.vertices[s].firstarc;G.vertices[s].firstarc=p;q=new(ArcNode);q->adjvex=s;q->nextarc=G.vertices[d].firstarc;G.vertices[d].firstarc=q;}}voidPRIN(ALGraph&G){inti;ArcNode*p;if(G.kind==DG||G.kind==UDG){for(i=0;i<G.vexnum;++i){printf("V%d:",G.vertices[i].data);p=G.vertices[i].firstarc;while(p!=NULL){printf("%d\t",p->adjvex+1);p=p->nextarc;}printf("\n");}}}voidbfs(ALGraph&G,intv){v--;ArcNode*p;intqueue[MAX_NUM],front=0,rear=0;intw,i;for(i=0;i<G.vexnum;i++)visited[i]=0;printf("%4d",v+1);visited[v]=1;rear=(rear+1)%MAX_NUM;queue[rear]=v;while(front!=rear){front=(front+1)%MAX_NUM;w=queue[front];p=G.vertices[w].firstarc;while(p!=NULL){if(visited[p->adjvex]==0){printf("%3d",p->adjvex+1);visited[p->adjvex]=1;rear=(rear+1)%MAX_NUM;queue[rear]=p->adjvex;}p=p->nextarc;}}printf("\n");}voidCreat_adjgraph(ALGraph&G){printf("1:有向图2:无向图\n");printf("请根据上述提示输入图的类型:");scanf("%d",&G.kind);switch(G.kind){caseDG:Creat_adjgraphDG(G);PRIN(G);break;caseUDG:Creat_adjgraphUDG(G);PRIN(G);break;default:printf("ERROR");break;}}voidmain(){ALGraphG;Creat_adjgraph(G);printf("\n");printf("广度优先搜索遍历序列为:\n");bfs(G,1);printf("\n");}。
深广度优先搜索课程设计

深广度优先搜索课程设计一、课程目标知识目标:1. 学生能够理解深广度优先搜索的概念,掌握其基本原理和应用场景。
2. 学生能够描述深广度优先搜索算法的步骤,并解释其在解决特定问题中的优势。
3. 学生能够掌握深广度优先搜索算法在图和树结构中的应用,并能运用到相关实际问题中。
技能目标:1. 学生能够运用深广度优先搜索算法解决迷宫问题,设计并实现简单的路径寻找算法。
2. 学生能够运用深广度优先搜索算法分析社交网络中的关系,提出合理的推荐策略。
3. 学生能够结合实际案例,运用深广度优先搜索算法进行问题分析,提出解决方案。
情感态度价值观目标:1. 学生通过学习深广度优先搜索,培养对算法思维的兴趣,提高解决问题的自信心。
2. 学生在学习过程中,学会与他人合作,培养团队精神和沟通能力。
3. 学生能够认识到深广度优先搜索在实际生活中的应用价值,激发对计算机科学的热爱。
本课程针对高中年级学生,结合学科特点和知识深度,旨在通过深广度优先搜索算法的学习,提高学生的逻辑思维能力、问题解决能力和团队协作能力。
课程内容紧密联系教材,注重实用性和操作性,使学生在掌握算法原理的基础上,能够将其应用于实际问题的解决。
在教学过程中,教师需关注学生的学习反馈,及时调整教学策略,确保课程目标的实现。
二、教学内容本章节教学内容围绕深广度优先搜索算法,结合教材以下章节进行组织:1. 图的基本概念(教材第3章):介绍图的结构、相关术语以及图的表示方法,为深广度优先搜索算法的学习奠定基础。
2. 深度优先搜索(教材第4章):详细讲解深度优先搜索的原理、算法步骤及实现方法,结合实例进行分析。
3. 广度优先搜索(教材第5章):介绍广度优先搜索的原理、算法步骤及实现方法,对比深度优先搜索,分析其优缺点及适用场景。
4. 深广度优先搜索的应用(教材第6章):通过实例讲解深广度优先搜索在路径寻找、社交网络分析等领域的应用。
具体教学内容安排如下:1. 引言:引入图的概念,介绍图的表示方法,分析图在现实生活中的应用。
广度优先遍历序列例题

广度优先遍历序列例题
广度优先遍历序列是一种常见的二叉树遍历方式,也称为层次优先遍历。
下面是一个简单的例题:
上图为一棵二叉树,广度优先遍历的顺序为:A-B-C-D-E-D-F-G。
广度优先遍历通常会借助一个队列来实现,思路为:将根节点放入队列,当队列不为空时循环,在循环中取出队首元素做一些处理,如输出、求和、存储等,然后在存在左节点时,将左节点放入队列,在存在右节点时,将右节点放入队列。
通用的代码模板为:
```java
bfs(Node root) {
if (root == null) return;
Queue<Node> queue = new LinkedList<>(); // 增加root节点到队列中
queue.add(root);
while (queue.size() > 0) {
// 取出队头的元素
Node current = queue.poll();
// 做节点值输出
doSomething();
// 依次处理左右节点
if (current.left != null) queue.add(current.left);
if (current.right != null) queue.add(current.right);
}
}
```
其中,`Node`类表示二叉树节点,包含`left`和`right`两个子节点,以及一个存储节点值的`value`属性。
在`BFS`类的`main`方法中,构建了一棵二叉树,并调用`bfs`方法进行广度优先遍历。
二叉树遍历(前序、中序、后序、层次、广度优先、深度优先遍历)

⼆叉树遍历(前序、中序、后序、层次、⼴度优先、深度优先遍历)⽬录转载:⼆叉树概念⼆叉树是⼀种⾮常重要的数据结构,⾮常多其他数据结构都是基于⼆叉树的基础演变⽽来的。
对于⼆叉树,有深度遍历和⼴度遍历,深度遍历有前序、中序以及后序三种遍历⽅法,⼴度遍历即我们寻常所说的层次遍历。
由于树的定义本⾝就是递归定义,因此採⽤递归的⽅法去实现树的三种遍历不仅easy理解并且代码⾮常简洁,⽽对于⼴度遍历来说,须要其他数据结构的⽀撑。
⽐⽅堆了。
所以。
对于⼀段代码来说,可读性有时候要⽐代码本⾝的效率要重要的多。
四种基本的遍历思想前序遍历:根结点 ---> 左⼦树 ---> 右⼦树中序遍历:左⼦树---> 根结点 ---> 右⼦树后序遍历:左⼦树 ---> 右⼦树 ---> 根结点层次遍历:仅仅需按层次遍历就可以⽐如。
求以下⼆叉树的各种遍历前序遍历:1 2 4 5 7 8 3 6中序遍历:4 2 7 5 8 1 3 6后序遍历:4 7 8 5 2 6 3 1层次遍历:1 2 3 4 5 6 7 8⼀、前序遍历1)依据上⽂提到的遍历思路:根结点 ---> 左⼦树 ---> 右⼦树,⾮常easy写出递归版本号:public void preOrderTraverse1(TreeNode root) {if (root != null) {System.out.print(root.val+" ");preOrderTraverse1(root.left);preOrderTraverse1(root.right);}}2)如今讨论⾮递归的版本号:依据前序遍历的顺序,优先訪问根结点。
然后在訪问左⼦树和右⼦树。
所以。
对于随意结点node。
第⼀部分即直接訪问之,之后在推断左⼦树是否为空,不为空时即反复上⾯的步骤,直到其为空。
若为空。
则须要訪问右⼦树。
注意。
在訪问过左孩⼦之后。
数据结构课设——有向图的深度、广度优先遍历及拓扑排序
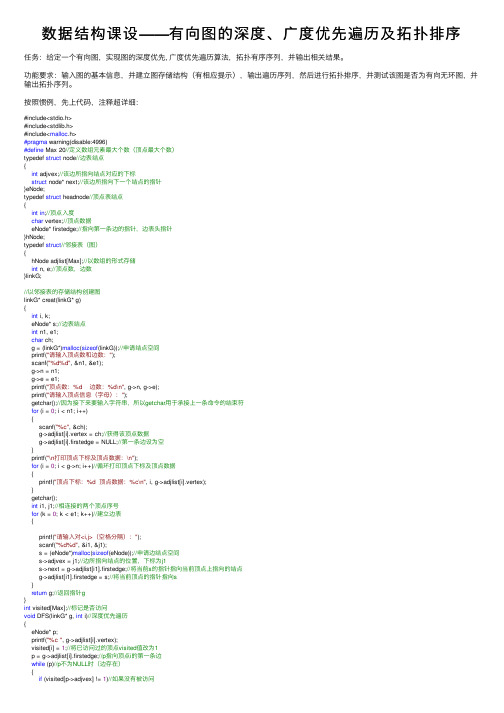
数据结构课设——有向图的深度、⼴度优先遍历及拓扑排序任务:给定⼀个有向图,实现图的深度优先, ⼴度优先遍历算法,拓扑有序序列,并输出相关结果。
功能要求:输⼊图的基本信息,并建⽴图存储结构(有相应提⽰),输出遍历序列,然后进⾏拓扑排序,并测试该图是否为有向⽆环图,并输出拓扑序列。
按照惯例,先上代码,注释超详细:#include<stdio.h>#include<stdlib.h>#include<malloc.h>#pragma warning(disable:4996)#define Max 20//定义数组元素最⼤个数(顶点最⼤个数)typedef struct node//边表结点{int adjvex;//该边所指向结点对应的下标struct node* next;//该边所指向下⼀个结点的指针}eNode;typedef struct headnode//顶点表结点{int in;//顶点⼊度char vertex;//顶点数据eNode* firstedge;//指向第⼀条边的指针,边表头指针}hNode;typedef struct//邻接表(图){hNode adjlist[Max];//以数组的形式存储int n, e;//顶点数,边数}linkG;//以邻接表的存储结构创建图linkG* creat(linkG* g){int i, k;eNode* s;//边表结点int n1, e1;char ch;g = (linkG*)malloc(sizeof(linkG));//申请结点空间printf("请输⼊顶点数和边数:");scanf("%d%d", &n1, &e1);g->n = n1;g->e = e1;printf("顶点数:%d 边数:%d\n", g->n, g->e);printf("请输⼊顶点信息(字母):");getchar();//因为接下来要输⼊字符串,所以getchar⽤于承接上⼀条命令的结束符for (i = 0; i < n1; i++){scanf("%c", &ch);g->adjlist[i].vertex = ch;//获得该顶点数据g->adjlist[i].firstedge = NULL;//第⼀条边设为空}printf("\n打印顶点下标及顶点数据:\n");for (i = 0; i < g->n; i++)//循环打印顶点下标及顶点数据{printf("顶点下标:%d 顶点数据:%c\n", i, g->adjlist[i].vertex);}getchar();int i1, j1;//相连接的两个顶点序号for (k = 0; k < e1; k++)//建⽴边表{printf("请输⼊对<i,j>(空格分隔):");scanf("%d%d", &i1, &j1);s = (eNode*)malloc(sizeof(eNode));//申请边结点空间s->adjvex = j1;//边所指向结点的位置,下标为j1s->next = g->adjlist[i1].firstedge;//将当前s的指针指向当前顶点上指向的结点g->adjlist[i1].firstedge = s;//将当前顶点的指针指向s}return g;//返回指针g}int visited[Max];//标记是否访问void DFS(linkG* g, int i)//深度优先遍历{eNode* p;printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已访问过的顶点visited值改为1p = g->adjlist[i].firstedge;//p指向顶点i的第⼀条边while (p)//p不为NULL时(边存在){if (visited[p->adjvex] != 1)//如果没有被访问DFS(g, p->adjvex);//递归}p = p->next;//p指向下⼀个结点}}void DFSTravel(linkG* g)//遍历⾮连通图{int i;printf("深度优先遍历;\n");//printf("%d\n",g->n);for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问{DFS(g, i);//调⽤DFS函数}}}void BFS(linkG* g, int i)//⼴度优先遍历{int j;eNode* p;int q[Max], front = 0, rear = 0;//建⽴顺序队列⽤来存储,并初始化printf("%c ", g->adjlist[i].vertex);visited[i] = 1;//将已经访问过的改成1rear = (rear + 1) % Max;//普通顺序队列的话,这⾥是rear++q[rear] = i;//当前顶点(下标)队尾进队while (front != rear)//队列⾮空{front = (front + 1) % Max;//循环队列,顶点出队j = q[front];p = g->adjlist[j].firstedge;//p指向出队顶点j的第⼀条边while (p != NULL){if (visited[p->adjvex] == 0)//如果未被访问{printf("%c ", g->adjlist[p->adjvex].vertex);visited[p->adjvex] = 1;//将该顶点标记数组值改为1rear = (rear + 1) % Max;//循环队列q[rear] = p->adjvex;//该顶点进队}p = p->next;//指向下⼀个结点}}}void BFSTravel(linkG* g)//遍历⾮连通图{int i;printf("⼴度优先遍历:\n");for (i = 0; i < g->n; i++)//初始化为0{visited[i] = 0;}for (i = 0; i < g->n; i++)//对每个顶点做循环{if (!visited[i])//如果没有被访问过{BFS(g, i);//调⽤BFS函数}}}//因为拓扑排序要求⼊度为0,所以需要先求出每个顶点的⼊度void inDegree(linkG* g)//求图顶点⼊度{eNode* p;int i;for (i = 0; i < g->n; i++)//循环将顶点⼊度初始化为0{g->adjlist[i].in = 0;}for (i = 0; i < g->n; i++)//循环每个顶点{p = g->adjlist[i].firstedge;//获取第i个链表第1个边结点指针while (p != NULL)///当p不为空(边存在){g->adjlist[p->adjvex].in++;//该边终点结点⼊度+1p = p->next;//p指向下⼀个边结点}printf("顶点%c的⼊度为:%d\n", g->adjlist[i].vertex, g->adjlist[i].in);}void topo_sort(linkG *g)//拓扑排序{eNode* p;int i, k, gettop;int top = 0;//⽤于栈指针的下标索引int count = 0;//⽤于统计输出顶点的个数int* stack=(int *)malloc(g->n*sizeof(int));//⽤于存储⼊度为0的顶点for (i=0;i<g->n;i++)//第⼀次搜索⼊度为0的顶点{if (g->adjlist[i].in==0){stack[++top] = i;//将⼊度为0的顶点进栈}}while (top!=0)//当栈不为空时{gettop = stack[top--];//出栈,并保存栈顶元素(下标)printf("%c ",g->adjlist[gettop].vertex);count++;//统计顶点//接下来是将邻接点的⼊度减⼀,并判断该点⼊度是否为0p = g->adjlist[gettop].firstedge;//p指向该顶点的第⼀条边的指针while (p)//当p不为空时{k = p->adjvex;//相连接的顶点(下标)g->adjlist[k].in--;//该顶点⼊度减⼀if (g->adjlist[k].in==0){stack[++top] = k;//如果⼊度为0,则进栈}p = p->next;//指向下⼀条边}}if (count<g->n)//如果输出的顶点数少于总顶点数,则表⽰有环{printf("\n有回路!\n");}free(stack);//释放空间}void menu()//菜单{system("cls");//清屏函数printf("************************************************\n");printf("* 1.建⽴图 *\n");printf("* 2.深度优先遍历 *\n");printf("* 3.⼴度优先遍历 *\n");printf("* 4.求出顶点⼊度 *\n");printf("* 5.拓扑排序 *\n");printf("* 6.退出 *\n");printf("************************************************\n");}int main(){linkG* g = NULL;int c;while (1){menu();printf("请选择:");scanf("%d", &c);switch (c){case1:g = creat(g); system("pause");break;case2:DFSTravel(g); system("pause");break;case3:BFSTravel(g); system("pause");break;case4:inDegree(g); system("pause");break;case5:topo_sort(g); system("pause");break;case6:exit(0);break;}}return0;}实验⽤图:运⾏结果:关于深度优先遍历 a.从图中某个顶点v 出发,访问v 。
算法设计:深度优先遍历和广度优先遍历

算法设计:深度优先遍历和广度优先遍历实现深度优先遍历过程1、图的遍历和树的遍历类似,图的遍历也是从某个顶点出发,沿着某条搜索路径对图中每个顶点各做一次且仅做一次访问。
它是许多图的算法的基础。
深度优先遍历和广度优先遍历是最为重要的两种遍历图的方法。
它们对无向图和有向图均适用。
注意:以下假定遍历过程中访问顶点的操作是简单地输出顶点。
2、布尔向量visited[0..n-1]的设置图中任一顶点都可能和其它顶点相邻接。
在访问了某顶点之后,又可能顺着某条回路又回到了该顶点。
为了避免重复访问同一个顶点,必须记住每个已访问的顶点。
为此,可设一布尔向量visited[0..n-1],其初值为假,一旦访问了顶点Vi之后,便将visited[i]置为真。
--------------------------深度优先遍历(Depth-First Traversal)1.图的深度优先遍历的递归定义假设给定图G的初态是所有顶点均未曾访问过。
在G中任选一顶点v为初始出发点(源点),则深度优先遍历可定义如下:首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。
若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点(亦称为从源点可达的顶点)均已被访问为止。
若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点作为新的源点重复上述过程,直至图中所有顶点均已被访问为止。
图的深度优先遍历类似于树的前序遍历。
采用的搜索方法的特点是尽可能先对纵深方向进行搜索。
这种搜索方法称为深度优先搜索(Depth-First Search)。
相应地,用此方法遍历图就很自然地称之为图的深度优先遍历。
2、深度优先搜索的过程设x是当前被访问顶点,在对x做过访问标记后,选择一条从x出发的未检测过的边(x,y)。
若发现顶点y已访问过,则重新选择另一条从x出发的未检测过的边,否则沿边(x,y)到达未曾访问过的y,对y访问并将其标记为已访问过;然后从y开始搜索,直到搜索完从y出发的所有路径,即访问完所有从y出发可达的顶点之后,才回溯到顶点x,并且再选择一条从x出发的未检测过的边。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
q=new(ArcNode);
q->adjvex=s;
q->nextarc=G.vertices[d].firstarc;
G.vertices[d].firstarc=q;
}
}
void PRIN(ALGraph &G)
{
int i;
ArcNode *p;
while(p!=NULL)
{
if(visited[p->adjvex]==0)
{
printf("%3d",p->adjvex+1);
visited[p->adjvex]=1;
rear=(rear+1)%MAX_NUM;
queue[rear]=p->adjvex;}
p=p->nextarc;}
}
printf("\n");
ArcNode *info;
}ArcNode;
typedef struct VNode
{
VertexType data;
ArcNode *firstarc;
}VNode,AdjList[MAX_NUM];
typedef struct
{
AdjList vertices;
int vexnum,arcnum;
for(i=0;i<G.vexnum;++i)
{
printf("第%d个顶点信息:",i+1);
scanf("%d",&G.vertices[i].data);
G.vertices[i].firstarc=NULL;}
for(i=0;i<G.arcnum;++i)
{
printf("第%d条边的起始顶点编号和终止顶点编号:",i+1);
GraphKind kind;
}ALGraph;
void PRIN(ALGraph &G);
void Creat_adjgraph(ALGraph &G);
void bfs(ALGraph &G,int v);
void Creat_adjgraphDG(ALGraph &G);
void Creat_adjgraphUDG(ALGraph &G);
if(G.kind==DG||G.kind==UDG)
{
for(i=0;i<G.vexnum;++i)
{
printf("V%d:",G.vertices[i].data);
p=G.vertices[i].firstarc;
while(p!=NULL)
{
printf("%d\t",p->adjvex+1);
p=p->nextarc;}
printf("\n");}
}
}
void bfs(ALGraph &G,int v)
{
v--;
ArcNode *p;
int queue[MAX_NUM],front=0,rear=0;
int w,i;
for(i=0;i<G.vexnum;i++)visited[i]=0;
int visited[MAX_NUM]={0};
typedef int VertexType;
typedef enum {DG=1,UDG}GraphKind;
typedef struct ArcNode
{
int adjvex;
int weight;
struct ArcNode *nextarc;
课程设计题目九:图的广度优先遍历
基本要求:
采用邻接表存储结构实现图的广度优先遍历。
(Hale Waihona Puke )对任意给定的图(顶点数和边数自定),建立它的邻接表并输出;
(3)实现图的广度优先遍历*/
#include<iostream.h>
#include<stdio.h>
#include<malloc.h>
#define MAX_NUM 20
printf("%4d",v+1);
visited[v]=1;
rear=(rear+1)%MAX_NUM;
queue[rear]=v;
while(front!=rear)
{
front=(front+1)%MAX_NUM;
w=queue[front];
p=G.vertices[w].firstarc;
scanf("%d %d",&s,&d);
while(s<1||s>G.vexnum||d<1||d>G.vexnum)
{
printf("编号超出范围,重新输入");
scanf("%d%d",&s,&d);}
s--;
d--;
p=new(ArcNode);
p->adjvex=d;
p->nextarc=G.vertices[s].firstarc;
scanf("%d %d",&s,&d);
while(s<1||s>G.vexnum||d<1||d>G.vexnum)
{
printf("编号超出范围,重新输入");
scanf("%d %d",&s,&d);}
s--;
d--;
p=new(ArcNode);
p->adjvex=d;
p->nextarc=G.vertices[s].firstarc;
}
void Creat_adjgraph(ALGraph &G)
{
printf("1:有向图2:无向图\n");
printf("请根据上述提示输入图的类型:"
);
scanf("%d",&G.kind);
for(i=0;i<G.vexnum;++i)
{
printf("第%d个顶点信息:",i+1);
scanf("%d",&G.vertices[i].data);
G.vertices[i].firstarc=NULL;}
for(i=0;i<G.arcnum;++i)
{
printf("第%d条边的起始顶点编号和终止顶点编号:",i+1);
void Creat_adjgraph(ALGraph &G);
void Creat_adjgraphDG(ALGraph &G)
{
int i,s,d;
ArcNode *p=NULL,*q=NULL;G.kind=DG;
printf("请输入顶点数和边数:");
scanf("%d %d",&G.vexnum,&G.arcnum);
G.vertices[s].firstarc=p;
}
}
void Creat_adjgraphUDG(ALGraph &G)
{
int i,s,d;
ArcNode *p,*q;
G.kind=UDG;
printf("请输入顶点数和边数:");
scanf("%d %d",&G.vexnum,&G.arcnum);