语料库的词性标注
词法分析:词性标注

词法分析:词性标注词法分析(lexical analysis):将字符序列转换为单词(Token)序列的过程分词,命名实体识别,词性标注并称汉语词法分析“三姐妹”。
在线演⽰平台:词性标注(Part-Of-Speech tagging, POS tagging)也被称为语法标注(grammatical tagging)或词类消疑(word-category disambiguation)是语料库语⾔学(corpus linguistics)中将语料库内单词的词性按其含义和上下⽂内容进⾏标记的⽂本数据处理技术。
语料库(corpus,复数corpora)指经科学取样和加⼯的⼤规模电⼦⽂本库。
所谓词性标注就是根据句⼦的上下⽂信息给句中的每个词确定⼀个最为合适的词性标记。
⽐如,给定⼀个句⼦:“我中了⼀张彩票”。
对其的标注结果可以是:“我/代词中/动词了/助词/ ⼀/数词/ 张/量词/ 彩票/名词。
/标点”词性标注的难点主要是由词性兼类所引起的。
词性兼类是指⾃然语⾔中⼀个词语的词性多余⼀个的语⾔现象。
(⼀词多性)常⽤的词性标注模型有 N 元模型、隐马尔科夫模型、最⼤熵模型、基于决策树的模型等。
其中,隐马尔科夫模型是应⽤较⼴泛且效果较好的模型之⼀。
【jieba】import jieba.posseg as psegwords = pseg.cut("⽼师说⾐服上除了校徽别别别的")for word, flag in words:print('%s %s' % (word, flag))⽼师 n 说 v ⾐服 n 上 f 除了 p 校徽 n 别 d 别 d 别的 r【hanLP】from pyhanlp import *content = "⽼师说⾐服上除了校徽别别别的"print(HanLP.segment(content))⽼师/nnt, 说/v, ⾐服/n, 上/f, 除了/p, 校徽/n, 别/d, 别/d, 别的/rzv ref:。
美国当代英语语料库(COCA)使用介绍

• 2.3 搜索在子语料库内(或之间)出现的频率 (或比较)(不同语域中的用法)
• 如在Fiction和Newspaper子语料库中passionate 后面可以跟任何名词的词及频率,分别如两图 (2.3-1和2.3-2)。
图2.3-1
图2.3-2
COCA主要功能(三)
• 但是也可以之间对两者子语料库中它们出现频率 的对比,操作:分别选择section 1&2,如下图(图 2.3-3):
• 例1. 输入单词“mysterious” (图2.1.1-1):得 到相关结果(图2.1.1-2):在各子库中的频率,每 百万词使用的频率。 • 若对图2中的相应条块进行点击,那么就可以看到 KWIC,如图2.1.1-3 (以点Fiction的条块为例):
图2.1.1-1
图2.1.1-2
使用CHART显示
COCA主要功能(二)
• 如:跟在 “smile前面的形容词” (图2.2-2)
规则:在words里输入: smile.[n*],表示作为名词的smile; 在collocates里输 入: [aj*]表示其前后出现形容词的语境。
Confidence前使用的形容词 图2.2-3
COCA主要功能(三)
COCA主要功能(四)
• 2.4 进行语义倾向比较 • 2.4.1 比较近义词 • 如:近义形容词hot和warm后面所跟名词的 区别(如图2.4.1):
图2.4.1
规则:在words的方格里分别输入hot和warm,再在collocates 方框里输入[nn*],表示后面所跟任何名词。当然也可以比较在 某个子语料库中出现的频率比较。
POS LIST
verb base=动词原形 verb.INF=动词不定式 verb MODAL=情态动词 verb 3SG=动词第三人称单数 verb ED=过去式 verb EN=过去分词 verb ING=现在分词 verb.LEX=lexical verb实意动词 verb.[BE]=系动词 verb.[DO]=do verb.[HAVE]=have
语料库标注说明

语料库标注说明“HSK动态作⽂语料库”语料标注及代码说明“HSK动态作⽂语料库”从字、词、句、篇、标点符号等⾓度,对所收⼊的作⽂语料中存在的外国⼈使⽤汉语的中介语偏误进⾏全⾯标注。
1 、字处理(包括标点符号)[C]:错字标记,⽤于标⽰考⽣写的不成字的字。
⽤[C]代表错字,在[C]前填写正确的字。
例如:地球[C](“球”是错字)、这[C]。
[B]:别字标记,⽤于标⽰把甲字写成⼄字的情况。
别字包括同⾳的、不同⾳⽽只是形似的、既不同⾳也不形似但成字的等等。
把别字移⾄[B]中B的后⾯,并在[B]前填写正确的字。
例如:提[B题]⾼、考虑[B虎]。
[L]:漏字标记,⽤于标⽰作⽂中应有⽽没有的字。
⽤[L]表⽰漏掉的字,并在[L]前填写所漏掉的字。
例如:后悔[L],表⽰“悔”在原⽂中是漏掉的字。
农[L]药,表⽰“农”在原⽂中是漏掉的字。
[D]:多字标记,⽤于标⽰作⽂中不应出现⽽出现的字。
把多余的字移⾄[D]中D的后⾯。
例如:我的[D的],表⽰括号中的“的”是多余的字(原⽂中写了两个“的”)。
[F]:繁体字标记,⽤于标⽰繁体字。
把繁体字移⾄[F]中F的后⾯,并在[F]前填写简体字。
例如:记忆[F憶]、单{F單}纯、养{F養}分{F份}。
注意:1)繁体字标记标⽰的是使⽤正确的繁体字,如果该繁体字同时⼜是别字,则先标繁体字标记,再标别字标记。
例如:俭朴[F樸[B僕]]。
2)繁体字写错了,标为:后[F後[C]]。
[Y]:异体字标记,⽤于标⽰异体字。
把异体字移⾄[Y]中Y的后⾯,并在[Y]前填写简体字。
例如:偏[Y徧]、沉[Y沈]。
[P]:拼⾳字标记,⽤于标⽰以汉语拼⾳代替汉字的情况。
把拼⾳字移⾄[P]中P的后⾯,并在[P]前填写简体字。
例如:缘[Pyúan]分、保护[Phù]。
[#]:⽆法识别的字的标记,⽤于标⽰⽆法识别的字。
每个不可识别的字⽤⼀个[#]表⽰。
例如:更[#][#]保存⾃⼰的⽣命,……[BC]:错误标点标记,⽤于标⽰使⽤错误的标点符号。
语料库语言学简介

语料库语言学简介语料库语言学是指利用语料库(一种大规模的文本数据集合)进行语言学研究的方法和理论。
通过构建、标注和分析语料库,可以揭示语言在不同层面上的特征和规律,为自然语言处理、机器翻译等领域提供基础和支持。
语料库语言学的研究内容包括:语言的音系、形态、句法以及语义等方面;语言的变异、演化和变化;语言使用者的使用习惯、语言背景和社会属性等。
语料库语言学的主要方法包括:语料库的构建和管理、语料库的标注和注释、语料库的查询和分析、语料库的应用和评估等。
语料库语言学的应用领域包括:机器翻译、信息检索、语音识别、文本分类、自然语言生成等。
此外,语料库语言学还被广泛应用于各种语言教学、语言规划和语言政策制定等领域。
总的来说,语料库语言学已经成为现代语言学和自然语言处理领域不可或缺的一部分,对于研究和应用语言都有着重要的意义。
一、语料库语言学的意义(一)定义和概述语料库语言学是指利用计算机对大规模语料库进行统计学分析、计算和比较,从而研究语言规律和现象的语言学方法。
语料库是指收集、整理、储存在计算机中的自然语言文本,包括书面文本和口语文本。
语料库语言学旨在通过对语言数据的分析,揭示语言的内在规律和现象,为语言学、语言教学、翻译等领域提供科学依据。
(二)语料库语言学的历史语料库语言学起源于20世纪50年代的美国,当时ChomSky等人提出了生成文法理论,但是这个理论无法解释自然语言的很多现象。
50年代后期,美国普林斯顿大学的SinClair教授提出了使用实际语言数据进行语言研究的观点,并开始编制语料库,由此开启了语料库语言学的先河。
之后,随着计算机技术的发展,语料库语言学得以快速发展,成为现代语言学研究和应用的重要领域。
二、语料库语言学的重要性(一)提供真实语言数据语料库收集大量的自然语言文本,包括书面语和口语,具有代表性和真实性。
这些数据包含了语言使用中的各种现象和规律,是研究语言的最基本素材。
(二)揭示语言规律和现象语料库语言学可以对语言数据进行分析、计算和比较,从而揭示语言的内在规律和现象。
现代汉语语料库加工规范词语切分和词性标注词...
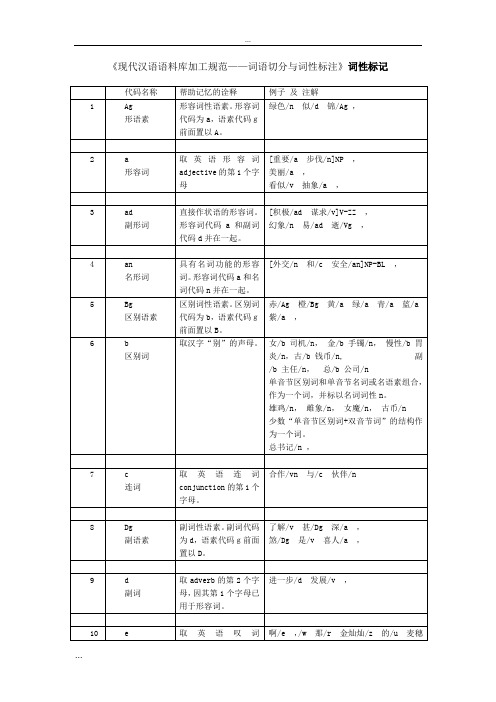
[芜湖/ns专区/n] NS,
[宣城/ns地区/n]ns,
[内蒙古/ns自治区/n]NS,
[深圳/ns特区/n]NS,
[厦门/ns经济/n特区/n]NS,
[香港/ns特别/a行政区/n]NS,
甲/Mg减下/v的/u人/n让/v乙/Mg背上/v ,
凡/d“/w寅/Mg年/n”/w中/f出生/v的/u人/n生肖/n都/d属/v虎/n ,
18
m数词
取英语numeral的第3个字母,n,u已有他用。
1.数量词组应切分为数词和量词。三/m个/q, 10/m公斤/q,一/m盒/q点心/n ,
但少数数量词已是词典的登录单位,则不再切分。
合作/vn与/c伙伴/n
8
Dg
副语素
副词性语素。副词代码为d,语素代码g前面置以D。
了解/v甚/Dg深/a,
煞/Dg是/v喜人/a,
9
d
副词
取adverb的第2个字母,因其第1个字母已用于形容词。
进一步/d发展/v,
10
e
叹词
取英语叹词exclamation的第1个字母。
啊/e,/w那/r金灿灿/z的/u麦穗/n,
约/d一百/m多/m万/m,仅/d一百/m个/q,四十/m来/m个/q,二十/m余/m只/q,十几/m个/q,三十/m左右/m,
两个数词相连的及“成百”、“上千”等则不予切分。
五六/m年/q,七八/m天/q,十七八/m岁/q,成百/m学生/n,上千/m人/n,
4.表序关系的“数+名”结构,应予切分。
[宝山/ns钢铁/n总/b公司/n]NT,(/w宝钢/j)/w
语料库中语料的标注

语料库中语料的标注董爱华【摘要】In the application of corpora, annotation is a must to ESP text analysis, learner’s language analysis and bilingual translation study. To guarantee the validity of the research results based on corpora, annotation of the corpora must be accurate. This paper starts from introducing the principles, methods and patterns of annotation, then it tries to analyzehow to control the quality of annotation from several aspects, and it also aims to help the corpora users to test the quality of a certain corpus.%在语料库应用过程中,ESP文本分析、学习者语言分析及双语翻译研究等都要用到标注。
语料库语料标注的准确性是基于语料库的学术研究结果可靠性的前提。
文章介绍了语料库标注的原则、方法模式,并分析了控制标注质量的相关因素,目的是为标注语料库的使用者检验标注质量提供帮助。
【期刊名称】《北京印刷学院学报》【年(卷),期】2016(024)005【总页数】4页(P67-70)【关键词】语料库标注;原则;方法;模式;质量【作者】董爱华【作者单位】北京印刷学院外语部,北京102600【正文语种】中文【中图分类】H0从现代语料库语言学的角度来看,语料库应该具备三个方面的基本条件,即样本的代表性、规模的有限性和语料的机读化[1]。
3-词性标注

• 上海_NR 浦东_NR 开发_NN 与_CC 法 制_NN 建设_NN 同步_VV
中科院计算所分词系统
• 字标注的分词本质是一个词性标注问题。
上/B 海/E 计/B 划/E 到/S 本/S 世/B 纪/E 末/S 实/B 现/E 人/B 均/E 国/B 内/E 生/B 产/E 总/B 值/E 五/B 千/M 美/M 元/E。/ S
把 这 篇 报道 编辑 一 下 把/q-p-v-n 这/r 篇/q 报道/v-n 编辑/v-n 一 /m-c 下/f-q-v
英语词的兼类现象
• 对Brown语料库进行统计, DeRose(1988) 给出了如
下表:
无歧义(Unambiguous)只有1个标记: 35,340 歧义(Ambiguous) 有2-7个标记: 4,100 2个标记:3,764 3个标记:264 4个标记:61 5个标记:12 6个标记:2 7个标记:1
• 不是俄罗斯数学家Markov提出。但HMM与
Markov链有关。 • 美国数学家鲍姆(Leonard E. Baum)六、 七十年代提出。 • 这个模型的训练方法由他的名字命名。 • NLP中,HMM最早应用在语音识别中,后 来成功地应用到了机器翻译、拼写纠错、图 像处理、基因序列分析等很多IT领域。
Markov模型
• 现实中经常会出现:一个由并不互相独立的
随机变量组成的序列,序列中每个变量的值 依赖于它前面的元素。 • 如:词串,每天的气温。 • 但是实际情况为:预测的将来的随机变量的 依据就是现在的随机变量的值,也就是,我 们并不需要了解序列中所有过去的随机变量 值。即,序列中未来的元素在给定的当前元 素下与过去的元素是条件独立的。—— Markov假设。
• 名实体识别也可看做是标注问题。
词性标注算法之CLAWS算法和VOLSUNGA算法

词性标注算法之CLAWS算法和VOLSUNGA算法背景知识词性标注:将句⼦中兼类词的词性根据上下⽂唯⼀地确定下来。
⼀、基于规则的词性标注⽅法1.原理 利⽤事先制定好的规则对具有多个词性的词进⾏消歧,最后保留⼀个正确的词性。
2.步骤 ①对词性歧义建⽴单独的标注规则库 ②标注时,查词典,如果某个词具有多个词性,则查找规则库,对具有相同模式的歧义进⾏排歧,否则保留。
③程序和规则库是独⽴的两部分。
3.例⼦ TAGGIT系统⼆、基于统计的词性标注⽅法1、原理 先对部分进⾏⼿⼯标注,然后对新的语料使⽤统计⽅法进⾏⾃动标注。
2、语⾔模型 (1)⼀个语⾔句⼦的信息量 ⼀个句⼦s = w1w2……w n的信息量量可以⽤熵来表⽰:H = - ∑p(w1,w2,…,w n) log p(w1,w2,…,w n),概率p(s)的⼤⼩反映了这个词串在该语⾔中的使⽤情况。
(2)n元语法模型①⼀元语法,w i的出现独⽴于历史 p(w1,w2,…,w n) = p(w1)*p(w2)*p(w3)…p(w n)②⼆元语法,w i的出现决定于w i-1 p(w1,w2,…,w n) = p(w1)*p(w2|w1)*p(w3|w2)…p(w n|w n-1)③三元语法,w i的出现决定于w i-1,w i-2 p(w1,w2,…,w n) =p(w1)*p(w2|w1)*p(w3|w2,w1)…p(w n|w n-1,w n-2) (3)数据平滑——Laplace法则3、词性标注模型①另W=w1w2….w n是由n个词组成的词串,T=t1t2…t n是词串W对应的标注串,其中t k是w k的词性标注。
②根据HMM模型,计算使得条件概率p(T|W)值最⼤的那个T’= argmaxp(T|W)③根据贝叶斯公式:p(T|W) = P(T)*P(W|T)/P(W)。
由于词串不变,p(W)不影响总的概率值,因此继续简化为: p(T|W) = P(T)*P(W|T),其中p(T) = p(t1|t0)*p(t2|t1,t0)…p(ti|ti-1),根据⼀阶HMM独⽴性假设,可得:p(T) = p(t1|t0)*p(t2|t1)…p(t i|t i-1),即P(t i|t i-1) = 训练语料中t i出现在t i-1之后的次数/训练语料中t i-1出现的总次数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
中国外语教育研究中心 梁茂成
主要内容
词性标注的意义
词性标注方法
词性标注集 词性标注语料的检索
词性标注的意义
又称词性赋码(POS, Part-of-Speech Tagging),指对文本中的所有词进行分 析,确定其语法属性,并将该属性添加 到文本中的对应位置。
对经过词性标注后的语料库可以进行更 有效的检索和分析,可以方便从语料库 中提取语法相关信息,即Leech所说的 added value。
词性Байду номын сангаас注方法
词性标注原理
TreeTagger (Multilingual Version 2.0)的操
作方法
词性标注集
词性标注集(tagset)即一整套符号,代
表各类词性。
词性标注集具有内在规律。
词性标注语料的检索
安装EditPad Pro
以赋码为线索,借助正则表达式检
索 AntConc支持正则表达式
谢谢