汉语词性标注
词性标注的名词解释

词性标注的名词解释词性标注是自然语言处理中的一项重要任务,其主要目的是确定文本中每个单词的词性。
在计算机领域中,词性标注通常被称为词性标签或词类标签。
它是自然语言处理技术的基础,对于诸如机器翻译、文本分类、信息检索等任务具有重要的影响。
词性是语法学中的一个概念,用于描述一个单词在句子中的语法属性和词义特征。
在英语中,常用的词性包括名词、动词、形容词、副词、代词、冠词、连词、介词和感叹词等。
而在中文中,常见的词性有名词、动词、形容词、副词、量词、代词、连词、介词、助词、语气词和标点符号等。
词性标注的目标是为每个词汇选择正确的词性。
这个过程通常涉及到构建一个标注模型,在已知的语料库中学习每个词汇的词性,并根据上下文的语法规则判断未知词汇的词性。
词性标记常用的方法有规则匹配、基于统计的方法和机器学习方法。
规则匹配是最简单的词性标注方法之一,它基于事先定义好的语法规则。
通过匹配文本中的规则模式,为每个单词分配一个预设的词性。
尽管规则匹配的方法简单易行,但它的局限性在于无法充分利用上下文信息,难以处理歧义问题。
基于统计的方法则通过统计大规模语料库中词汇在不同上下文环境中出现的概率,来预测词性。
这种方法基于频率统计的结果,假设一个单词在给定上下文中具有最大概率的词性,从而进行标注。
其中,隐马尔可夫模型(HMM)是最常用的统计方法之一。
HMM模型通过学习词性之间的转移概率和词性与单词之间的发射概率,来进行词性标注。
与基于统计的方法相比,机器学习方法更加灵活。
机器学习方法通过训练样本学习词汇和其对应的词性之间的潜在关系,并根据这种关系对未知词汇进行标注。
常见的机器学习方法包括最大熵模型、条件随机场(CRF)等。
这些方法通过结合上下文信息和词汇特征,提高了标注的准确性和泛化能力。
词性标注在自然语言处理中具有广泛的应用。
在机器翻译中,词性标注的结果能帮助翻译系统区分单词的不同含义,提高翻译质量。
在文本分类中,词性标注可以辅助判断文本的属性或情感倾向。
浅谈《现代汉语词典》(第五版)词性标注的几个问题

浅谈《现代汉语词典》(第五版)词性标注的几个问题摘要:本文主要从功能的角度对《现代汉语词典》(第五版)的词性标注进行了初步的探索,主要涉及词性标注及其与释义和配例相一致、兼类词的释义等几个方面的问题,对《现汉》(五)的成功和不足之处作了一定说明。
关键词:《现代汉语词典》(第五版)词性标注释义《现代汉语词典》是目前国内最有影响的语文辞书之一。
对现代汉语词典质量产生影响的根本性因素,是词典的释义问题。
一、《现代汉语词典》(第五版)词性标注现代汉语词典标注词性,给汉语教学、用户的学习和使用和中文信息处理等带来了很大的方便。
标注词性必须要对词类系统和词与非词进行界定。
科学的给词归类,主要根据词的语法功能。
陆俭明提出的词类划分标准是:1、词充当句法成分的功能,2、词跟词结合的功能,3、词表示类别的功能,即语法意义。
《现代汉语词典》(第5版)依据的词类是中学语文课本的教学词类系统,是比较科学的。
如:集成:【动】同类著作汇集在一起(多用做书名):《丛书~》|《中国古典戏曲论著~》。
(《现汉》(五)p592)集锦:【名】编辑在一起的精彩的图画、诗文等(多用做标题):图片~|邮票~。
(《现汉》(五)p593)《现代汉语词典》(第5版)中的“集成”与“集锦”根据配例来看,“丛书集成”、“图片集锦”、“邮票集锦”,二者看似相同,但是语法意义不同。
根据“语料库在线”的检索结果,“集成”66条例句中,17个做谓语例句,13个做定语例句,且能带宾语;“集锦”6条例句中5个做中心语。
前者语法意义表示事物的动作、行为或变化、存在,后者的语法意义表示事物名称。
所以二者词性标注不同。
另外,在根据功能判断词性的基础上,也不能完全脱离意义。
“集成”与“集锦”词汇意义也不同,“集:1.集合;聚集”(《现汉》(五)p639),“成:3.【动】成为;变为”(《现汉》(五)p171),“集成”有“汇集成为”的意思,释义行文体现为动词性。
“锦:有彩色花纹的丝织品”(《古汉语常用字字》p150),这里应为比喻义,指美好的东西,所以“集锦”释义行文应体现为名词性。
汉语词典词性标注的基本经验

、
汉语 书 面词 是 形 音 性Fra bibliotek义 的 统一 体
1 .从 音义 结合 到形 音性 义统 一
音 和义是 口语 词 的两 个 要 素 , 而传 统 的汉 字 学认 为 , 字是 形 、
音、 义的统一体 , 、 、 形 音 义是汉字的三要素 。但是 , 汉语语法 的研
究 已经有 了一百 年 的历史 , 们 已经认 识到 , 是汉语 语 音 、 汇 、 人 词 词 语法研 究 的基 本 单 位 , 个 词 还 有 一 个 要 素是 语 法 功 能 即词 性 。 一 按照 全面 标注 词性 的 词典 中的 排 列顺 序 , 面 词有 四个 要 素 : 、 书 形 音 、 、 。因此 , 性 义 准确 地说 , 汉语 书 面词 是形 音性 义 的统 一体 。词 典 全面标 注 词性 , 将把 这个 观 点普及 于一 般群 众 , 功在 千秋 。这恐
统 一体 ; 汉语词典词性标 注的对 象是词 , 非词 单位不能标注词性 ; 单义词或
多义 词 的 义 项 的 语 法 功 能 是 一 个 统 一 体 , 词 性 标 注 要 遵 循 唯 一 性 的 原 其
则; 含有“ 义异性异” 义项的 多义词是 汉语词 兼类 现 象的存 在形 式 ; 词典 在
怕 是汉 语词 典词性 标 注最 重要 的基 本经 验 。 2 .词性 是什 么
词性标 注的实 践说 明 : 语词 的词 性是 其语 法位 置 的总 和 。 汉 在形 态语 言 中 , 个意 义单 纯 的词根 充 当不 同句子 成分 时 , 一 一 般分 化 为几个 词 , 它们 “ 同性 异 ” 义 。例 如 , 汉 语 中 ,很 容 易/ 在 “ 容 易解 决/ 容易 不见得 是 好 事 ” 个说 法 中 ,容 易 ” 同一 个 词 用 了 “ 是 三次 ; 是 , 果用英 语来 表 达 ( 语 的形 态 并不 丰 富 )其 中的“ 但 如 英 , 容 易” 得分 别变 成 es( )esyav/ai s()它们 成 了 三个 就 ay /ai (d )es esn , l n 不 同的词 , 然词根 相 同 , 义一 样 。 由于汉 语 没 有形 态 , 虽 意 不存 在 “ 同性 异 ” 义 的词 , 以西方 著名 语 言学家 洪堡 特等 把汉 语 叫做 “ 所 词 根 语 ”我 国理论 语言 学家 徐通锵 则 称之 为 “ , 语义 型语 言 ” 。 显然 , 我们 不能 用形 态 语 言 的 眼光 来分 析 汉 语 词 的词性 。如 果用 西语 的眼 光来 分 析汉 语 的 “ 易 ”可 能 出现 三种 结 果 : “ 容 , ① 容
民国时期汉语语文辞书词性标注研究

民国时期汉语语文辞书词性标注研究1. 引言1.1 研究背景民国时期是中国历史上一个重要的时期,同时也是中国语言文字发展的重要阶段。
在这个时期,汉语语文辞书开始逐渐规范化,成为人们学习和理解汉语的重要工具之一。
在这个时期的辞书中,词性标注并不是很完善,这给人们的使用带来了一定的困难。
随着现代计算机技术的发展,词性标注技术已经得到了很大的进步。
通过对民国时期汉语语文辞书进行词性标注研究,不仅可以更好地理解这一时期的语言特点,还能够为现代汉语语言文字研究提供参考和借鉴。
对民国时期汉语语文辞书词性标注的研究具有重要的意义。
本文将从民国时期汉语语文辞书的特点、词性标注方法、技术应用、研究方法和步骤以及实验结果分析等方面进行探讨,希望通过这些研究,可以深入挖掘民国时期汉语语文辞书的内容,为进一步的研究工作提供支持和帮助。
1.2 研究意义对于民国时期汉语语文辞书词性标注研究的意义,可以从以下几个方面进行分析:研究民国时期汉语语文辞书的词性标注有助于我们更深入地了解那个时期的汉语语言特点和发展历程。
词性标注是对词汇进行分类和注释的过程,通过对辞书中词语的词性进行标注,可以揭示出当时的语言使用规范和特点,有助于我们了解民国时期的语言风貌和特征。
研究民国时期汉语语文辞书的词性标注方法可以为现代汉语语言学研究提供借鉴和启示。
通过对民国时期辞书中词语的词性标注方法进行探讨和比较,可以发现其在词性分类和标注技术方面的一些优点和不足,从而为现代汉语语言学研究提供经验和启示,有助于完善和发展现代汉语词性标注技术。
2. 正文2.1 民国时期汉语语文辞书的特点1. 语文规范性:民国时期的汉语语文辞书在规范汉语的使用方面起到了重要作用,对于词语、句法结构等进行了较为细致的规范,使人们能够更加准确地理解和运用汉语。
2. 文字注音和释义:民国时期的辞书在注音和释义方面较为全面和准确,为人们提供了丰富的语言资料和参考工具。
辞书中的语词解释也较为详细和权威,有助于人们更好地理解汉语词汇的含义。
中文分词与词性标注技术研究与应用

中文分词与词性标注技术研究与应用中文分词和词性标注是自然语言处理中常用的技术方法,它们对于理解和处理中文文本具有重要的作用。
本文将对中文分词和词性标注的技术原理、研究进展以及在实际应用中的应用场景进行综述。
一、中文分词技术研究与应用中文分词是将连续的中文文本切割成具有一定语义的词语序列的过程。
中文具有词汇没有明确的边界,因此分词是中文自然语言处理的基础工作。
中文分词技术主要有基于规则的方法、基于词典的方法和基于机器学习的方法。
1.基于规则的方法基于规则的中文分词方法是根据语法规则和语言学知识设计规则,进行分词操作。
例如,按照《现代汉语词典》等标准词典进行分词,但这种方法无法处理新词、歧义和未登录词的问题,因此应用受到一定的限制。
2.基于词典的方法基于词典的中文分词方法是利用已有的大规模词典进行切分,通过查找词典中的词语来确定分词的边界。
这种方法可以处理新词的问题,但对未登录词的处理能力有所限制。
3.基于机器学习的方法基于机器学习的中文分词方法是利用机器学习算法来自动学习分词模型,将分词任务转化为一个分类问题。
常用的机器学习算法有最大熵模型、条件随机场和神经网络等。
这种方法具有较好的泛化能力,能够处理未登录词和歧义问题。
中文分词技术在很多自然语言处理任务中都起到了重要的作用。
例如,在机器翻译中,分词可以提高对齐和翻译的质量;在文本挖掘中,分词可以提取关键词和构建文本特征;在信息检索中,分词可以改善检索效果。
二、词性标注技术研究与应用词性标注是给分好词的文本中的每个词语确定一个词性的过程。
中文的词性标注涉及到名词、动词、形容词、副词等多个词性类别。
词性标注的目标是为后续的自然语言处理任务提供更精确的上下文信息。
1.基于规则的方法基于规则的词性标注方法是根据语法规则和语境信息,确定每个词语的词性。
例如,根据词语周围的上下文信息和词语的词义来判断词性。
这种方法需要大量的人工制定规则,并且对于新词的处理能力较差。
汉语自动分词与词性标注

– :主词位 – 对于任意一个字,如果它在某个词位上的能产度高于0.5,称这个词 位是它的主词位。
– MSRA2005语料中具有主词位的字量分布:
33
由字构词方法的构词法基础(2)
• 自由字
– 并不是每个字都有主词位,没有主词位的字叫做自由字。
– 除去76.16%拥有主词位的字,仅有大约23.84%的字是自 由的。这是基于词位分类的分词操作得以有效进行的基 础之一。
• 随着n和N的增加,计算复杂度增加太快, 张华平给出了一种基于统计信息的粗分模 型。 • 粗分的目标就是确定P(W)最大的N种切分结 果
P(W ) = P (w )
i i =1 m
7.2.3 基于HMM的分词方法
• 我们可以将汉语自动分词与词性标注统一 考虑,建立基于HMM的分词与词性标注一 体化处理系统。 • 详见第六章举例。 • 有了HMM参数以后,对于任何一个给定的 观察值序列(单词串),总可以通过viterbi算 法很快地可以得到一个可能性最大的状态 值序列(词性串)。算法的复杂度与观察值序 列的长度(句子中的单词个数)成正比。
歧义切分问题 交集型切分歧义 组合型切分歧义 多义组合型切分歧义
• 交集型歧义切分
中国人为了实现自己的梦想 中国/ 人为/ 了/ 实现/ 自己/ 的/ 梦想 中国人/ 为了/ 实现/ 自己/ 的/ 梦想
中/ 国人/ 为了/ 实现/ 自己/ 的/ 梦想 例如:中国产品质量、部分居民生活水 平
• 新的探索: A.Wu尝试将分词与句法分析融合为一体的 方法,用整个句子的句法结构来消除不正 确的歧义,对组合型歧义释放有效(组合型 歧义少数,交集型歧义较多)。 同时,句法分析本身就有很多歧义,对于 某些句子,反而产生误导。(王爱民)
词性标注对照表
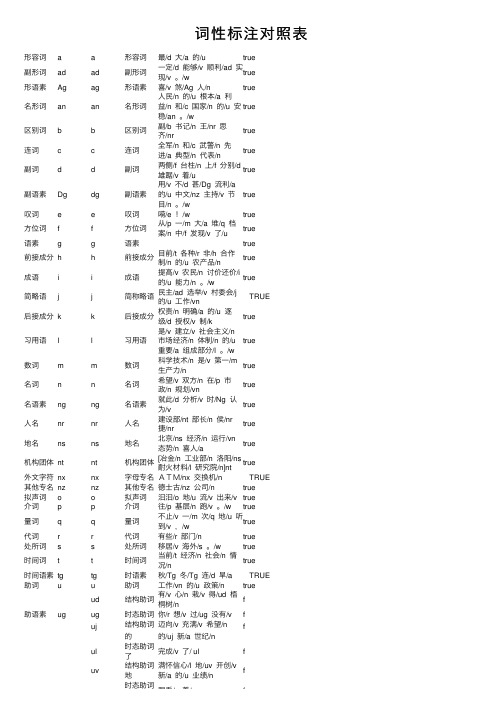
词性标注对照表形容词a a形容词最/d ⼤/a 的/u true副形词ad ad副形词⼀定/d 能够/v 顺利/ad 实现/v 。
/wtrue形语素Ag ag形语素喜/v 煞/Ag ⼈/n true名形词an an名形词⼈民/n 的/u 根本/a 利益/n 和/c 国家/n 的/u 安稳/an 。
/wtrue区别词b b区别词副/b 书记/n 王/nr 思齐/nrtrue连词c c连词全军/n 和/c 武警/n 先进/a 典型/n 代表/ntrue副词d d副词两侧/f 台柱/n 上/f 分别/d雄踞/v 着/utrue副语素Dg dg副语素⽤/v 不/d 甚/Dg 流利/a的/u 中⽂/nz 主持/v 节⽬/n 。
/wtrue叹词e e叹词嗬/e !/w true⽅位词f f⽅位词从/p ⼀/m ⼤/a 堆/q 档案/n 中/f 发现/v 了/utrue语素g g语素 true前接成分h h前接成分⽬前/t 各种/r ⾮/h 合作制/n 的/u 农产品/ntrue成语i i成语提⾼/v 农民/n 讨价还价/i的/u 能⼒/n 。
/wtrue简略语j j简称略语民主/ad 选举/v 村委会/j的/u ⼯作/vnTRUE后接成分k k后接成分权责/n 明确/a 的/u 逐级/d 授权/v 制/ktrue习⽤语l l习⽤语是/v 建⽴/v 社会主义/n市场经济/n 体制/n 的/u重要/a 组成部分/l 。
/wtrue数词m m数词科学技术/n 是/v 第⼀/m⽣产⼒/ntrue名词n n名词希望/v 双⽅/n 在/p 市政/n 规划/vntrue名语素ng ng名语素就此/d 分析/v 时/Ng 认为/vtrue⼈名nr nr⼈名建设部/nt 部长/n 侯/nr捷/nrtrue地名ns ns地名北京/ns 经济/n 运⾏/vn态势/n 喜⼈/atrue机构团体nt nt机构团体[冶⾦/n ⼯业部/n 洛阳/ns耐⽕材料/l 研究院/n]nttrue外⽂字符nx nx字母专名ATM/nx 交换机/n TRUE 其他专名nz nz其他专名德⼠古/nz 公司/n true拟声词o o拟声词汩汩/o 地/u 流/v 出来/v true介词p p介词往/p 基层/n 跑/v 。
现代汉语语料库加工规范词语切分和词性标注词...
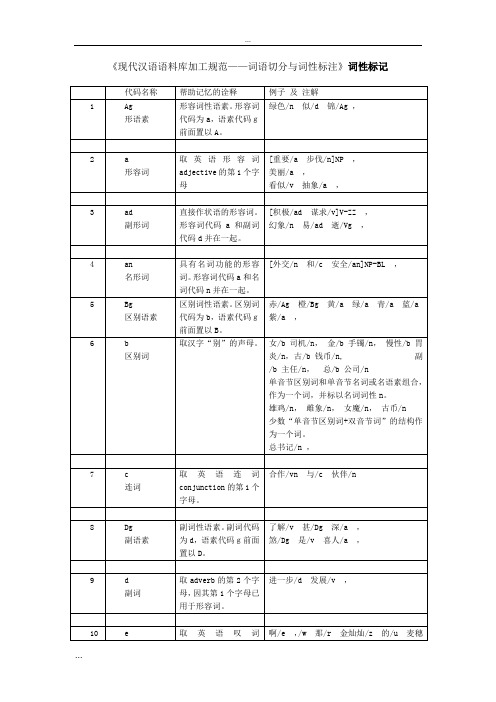
[芜湖/ns专区/n] NS,
[宣城/ns地区/n]ns,
[内蒙古/ns自治区/n]NS,
[深圳/ns特区/n]NS,
[厦门/ns经济/n特区/n]NS,
[香港/ns特别/a行政区/n]NS,
甲/Mg减下/v的/u人/n让/v乙/Mg背上/v ,
凡/d“/w寅/Mg年/n”/w中/f出生/v的/u人/n生肖/n都/d属/v虎/n ,
18
m数词
取英语numeral的第3个字母,n,u已有他用。
1.数量词组应切分为数词和量词。三/m个/q, 10/m公斤/q,一/m盒/q点心/n ,
但少数数量词已是词典的登录单位,则不再切分。
合作/vn与/c伙伴/n
8
Dg
副语素
副词性语素。副词代码为d,语素代码g前面置以D。
了解/v甚/Dg深/a,
煞/Dg是/v喜人/a,
9
d
副词
取adverb的第2个字母,因其第1个字母已用于形容词。
进一步/d发展/v,
10
e
叹词
取英语叹词exclamation的第1个字母。
啊/e,/w那/r金灿灿/z的/u麦穗/n,
约/d一百/m多/m万/m,仅/d一百/m个/q,四十/m来/m个/q,二十/m余/m只/q,十几/m个/q,三十/m左右/m,
两个数词相连的及“成百”、“上千”等则不予切分。
五六/m年/q,七八/m天/q,十七八/m岁/q,成百/m学生/n,上千/m人/n,
4.表序关系的“数+名”结构,应予切分。
[宝山/ns钢铁/n总/b公司/n]NT,(/w宝钢/j)/w
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
湖南文理学院课程设计报告课程名称:计算机软件技术基础系部:电信系专业班级:通信工程T09103班学生姓名:刘程程指导教师:完成时间:2011.12.28报告成绩:目录中文摘要 (I)ABSTRACT (II)第一章引言 (1)1.1背景和意义 (1)1.2词性标注定义及其困难 (1)1.2.1词性的定义 (2)1.2.2词性标注的难点 (2)第二章基础理论介绍 (3)2.1隐马尔科夫模型(H1DDEN M ARKOV M ODEL,HM) (3)2.2HMM用于词性标注 (4)第三章改进HMM标注模型与参数估计 (4)3.1改进HMM模型词性标注 (4)3.2参数估计 (5)3.2.1训练语料库 (5)3.2.2当用数据库 (5)第四章改进VITERBI算法标注 (7)4.1标注过程 (7)4.2改进后的V ITERBI算法的具体描述 (7)第五章实验结果与分析 (8)5.1评价标准 (8)5.2实验结果 (9)5.3错误分析 (10)参考文献 (11)中文摘要汉语词性标注是中文信息处理技术中的一项基础性课题。
一方面,它的研究成果可以直接融入到信息抽取、信息检索、机器翻译等诸多实际应用系统当中;另一方面,汉语自动词性标注也是汉语语块识别器、汉语句法分析器、汉语语义分析器必不可少的前端处理工具。
因此,研究和实现汉语词性标注器具有重要的理论意义和实用价值。
词性标注的方法主要有基于规则和基于统计的两大类。
由于基于统计的方法具有不需要人工总结语言学规则、正确识别率高等优点,已逐渐成为研究的热点。
在基于统计的方法中,隐马尔科夫模型是最主要的算法模型之一。
在本文中,我们以汉语的词性自动标注为研究对象,提出了一种基于改进的隐马尔科夫模型汉语词性标注方法。
该方法在原有隐马尔科夫模型的基础上,加入了更多的上下文信息,用于汉语词性的自动标注问题,取得了较好的效果。
主要的研究内容有以下几方面: 1.虽然隐马尔科夫模型有很好的标注效果,但是它在对当前词词语出现概率的估计只与其词性有关。
2.获得上下文信息的多少和数据平滑程度是评价统计词性标注模型性能的两个重要参数。
本文详细介绍了现阶段几种平滑算法,针对该模型数据稀疏现象,采用性能稳定指数线性插值方法来平滑HMM的概率参数。
3.对HMM参数估计模型的修改,只是改进模型的第一步,为了更有效的使用训练所得到的参数,需要对Viterbi算法进行修改。
由于传统的Viterbi算法不适合本模型,所以对Viterbi算法进行了拓展。
4.对于自然语言来讲不存在完备的可计算的词性信息,如何确定未登录词的词性是除兼类问题之外词性标注所面临的另一个关键问题。
本文对未登录词处理提出了具体处理方法。
关键词:中文信息处理;汉语词性标注;隐马尔科夫模型;平滑算法;AbstractChinese Part-of-Speech Tagging is a fundamental problem to many Chinese Information Processing tasks. The task of Part-of-Speech Tagging is to design software that can identify Part-of-Speech in a sentence automatically.One side, the performance of many realistic applications such as information extraction, information retrieval, and machine translation would be improved if the right Part-of-Speech were available. And on the other hand, it is indispensable processing component in Chinese lexical analysis system, Chinese syntax analysis system, and etc. Therefore, its research is of great of theoretical importance as well as practicability.The model of Part-of-Speech Tagging includes both rule and statistics technique. Because of the statistics technique requires no manual rules of natural language and has a high level accuracy, the statistical language model has gradually become a hot research topic. For its better performance, Hidden Makov Model (HMM), one of the statistical models, has been the recent trend in Part-of-Speech Tagging.We propose a method of Chinese Part-of-Speech Tagging based on ameliorated Hidden Makov Model, taking more information of context into the model to describe language phenomena. The result of ameliorated model is satisfying. The main works of this paper includes four parts:1 .Although HMM are high performance, the probability of the word depends on its own tag. 2. Two key factors can be used in evaluating the performance of statistical model of Part-of-Speech Tagging. 3 .For the sake of making effective use of parameters trained from ameliorated Hidden Makov Model; we fit the Viterbi algorithm for the new parameter.4 .For the imperfection of computable information on each word in How to solve new words is anther key problem in statistical language In this paper, we propose a concreted method in new words.Key words: Chinese Information Processing; Chinese Part-of-SpeechTagging; Hidden Makov Model; Smoothing Algorithm第一章引言1.1背景和意义随着Internet上中文网页的急剧膨胀和中文电子出版物、中文数字图书馆的迅速普及,以非受限文本为主要对象的中文自然语言处理研究的重要性日益显著。
分析和处理语言的基本方法,是将语言分为词法、句法、语义等不同层次来加以认识的,在自然语言处理领域,相应建立了词法分析、句法分析、语义分析等课题。
当前汉字编码和输入方法的研究已比较成熟,中文自然语言处理的重点已从“字”层面转移到“词”层面。
汉语的词性标注研究,主要是从词层面进行的研究,这一问题在70年代末就受到了广泛的关注,目前,许多标注方法方法已得到了实现。
在这一长期的研究和实践过程中,尽管有这些难题的长期困扰,汉语的词性标注仍得到很多现实应用。
因此具体如下:a)为更高层次的自然语言文本加工提供素材,例如:利用词性标注结果对部分句法进行对名次短语的识别。
b)为语言学的研究提供翔实的资料,例如:利用词性标注实现信息理解,数据抽取或文本数据挖掘。
c)从加工过的文本中获取词类及频度的词性标注知识。
例如:文本分类等。
一方面,它的研究成果可以直接融入到机器翻译[z1、信息检索、语音识别等诸多实际应用系统当中,另一方面,汉语自动词性标注也是汉语语块识别器、汉语句法分析器、汉语语义分析器必不可少的前端处理工具。
因此,研究和实现汉语词性标注器具有重要的理论意义和实用价值。
1.2词性标注定义及其困难词性也叫词类,是根据一个词的本意及在短语或句子中的作用划分的。
从语言学的角度,汉语词汇可分为实词和虚词两大类。
实词是意义比较具体的词,包括:名词(含方位词)、动词、形容词(含颜色词)、数词、量词、代词六大类。
虚词主要指没有完整的词汇意义,但有文法意义或功能意义的词,包括:副词、介词、连词、助词、象声词六大类。
需要注意的是,上述的分类方法不是唯一的。
一种语言的词汇应该划分为多少类以及每一类都应该包含那些词汇都没有一个统一的标准。
在语言学研究中,这个问题通常是由人们的语一言感觉、应用需求、工程可操作性三个因素共同决定。
1.2.1词性的定义词性也叫词类,是根据一个词的本意及在短语或句子中的作用划分的。
从语言学的角度,汉语词汇可分为实词和虚词两大类。
实词是意义比较具体的词,包括:名词(含方位词)、动词、形容词(含颜色词)、数词、量词、代词六大类。
虚词主要指没有完整的词汇意义,但有文法意义或功能意义的词,包括:副词、介词、连词、助词、象声词六大类。
需要注意的是,上述的分类方法不是唯一的。
一种语言的词汇应该划分为多少类以及每一类都应该包含那些词汇都没有一个统一的标准。
在语言学研究中,这个问题通常是由人们的语一言感觉、应用需求、工程可操作性三个因素共同决定。
1.2.2词性标注的难点所谓词性标注就是根据句子中的上下文信息给句中的每个词确定一个最为合适的词性标记。
比如给定一个句子:“我中了一张彩票。
”对其的标注结果可以是:“我/代词中/动词了/助词一/数词张/量词彩票/名词。
/标点’,。
词性标注的难点主要是由词性兼类[3]所引起的,词性兼类是指自然语言中一个词语的词性多余一个的语言现象。