微信公众号内容采集方法详解
微信公众号文章采集详细步骤

微信公众号文章采集详细步骤对于某些用户来说,直接自定义规则可能有难度,所以在这种情况下,我们提供了网页简易模式,网页简易模式下存放了国内一些主流网站爬虫采集规则,在你需要采集相关网站时可以直接调用,节省了制作规则的时间以及精力。
所以本次介绍八爪鱼简易采集模式下“微信文章采集”的使用教程以及注意要点。
微信文章采集下来有很多作用,比如可以将自己行业中最近一个月之内发布的内容采集下来,然后分析文章标题和内容的一个方向与趋势。
微信公众号文章采集使用步骤步骤一、下载八爪鱼软件并登陆1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆步骤二、设置微信文章爬虫规则任务1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集微信公众号内容的,这里选择搜狗即可。
3、找到搜狗公众号这条爬虫规则,点击即可使用。
4、搜狗公众号简易采集模式任务界面介绍查看详情:点开可以看到示例网址任务名:自定义任务名,默认为搜狗公众号任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组公众号URL列表填写注意事项:提供要采集的网页网址,即搜狗微信中相关公众号的链接。
多个公众号输入多个网址即可。
采集数目:输入希望采集的数据条数示例数据:这个规则采集的所有字段信息。
5、微信文章爬虫规则设置示例例如要采集相关旅游、美食的公众号文章在设置里如下图所示:任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行商品评论URL列表:/weixin?type=1&s_from=input&query=电影&ie=utf8&_sug_=n&_sug_type_=/weixin?type=1&s_from=input&query=美食&ie=utf8&_sug_=n&_sug_type_=一行一个,使用回车(Enter)进行换行。
微信公众号内容推送技巧

微信公众号内容推送技巧1、内容定位—内容为王内容的定位应该结合企业的特点,同时又从用户的角度去着想,而不一味的只推送企业自己的内容,记住微信不是为企业服务的,而是为用户服务的,只有从你的微信当中获得用户想要的东西,他们才会更加忠实于你,和你成为朋友,接下来的销售才会理所当然。
要记住,用户是冲着你的内容才来的,推荐也是因为觉得内容有价值,所以内容为王。
对于微信的内容,我们有一个“1+X”的模型,“1”是最能体现账号核心价值的内容,“X”则代表了内容的多样性,迎合和满足用户的需求,增强内容的吸引力。
比如我们运营的“永中Office”的微信公众号,这是一个以office产品为主题的微信公号,核心内容是Office的使用技巧,这部分内容尽管实用,但比较枯燥,用户不容易感兴趣,所以我们就会补充一些小职场沟通、人生励志等上班族比较感兴趣的内容。
2、内容推送—拒绝骚扰现在绝大多数的微信公众账号每天都有1次群发消息的功能,很多人嫌少,我觉得太多了。
现在每个用户都会订阅几个账号,推送的信息一多根本看不过来。
关于内容推送,我主要讲两个方面。
①推送频次:一周不要超过三次,太多了会打扰到用户,最坏的后果可能是用户取消对你的关注;当然,太少了用户也会抱怨,觉的你的微信只是一个摆设,根本不会从你这里获得什么。
所以这个度一定得把握好。
②推送形式:是指内容不一定都是图文专题式的,也可以是一些短文本,文本字数一般一两百字左右,关键在于内容能引发的读者思考,产生思想的火花,形成良好的互动效果。
比如在“新桥公关”的微信中,我们定期会开展一些小调查,以短文本的形式,询问读者对于内容和推送时间的建议等。
这样的效果非常好的,一次小调查,我们通常会收到几百条用户回复,这样我们既实现了互动,也更了解用户,而用户也能看到他们想要的内容,应该说是多赢的结果。
3、人工互动—沟通是魂微信的本质是沟通平台,沟通需要有来有往,所以人工互动必不可少的。
我个人比较反对设置“消息自动回复”,就像QQ里的聊天自动回复,很讨厌,没诚意。
微信公众号常规操作方法及技巧
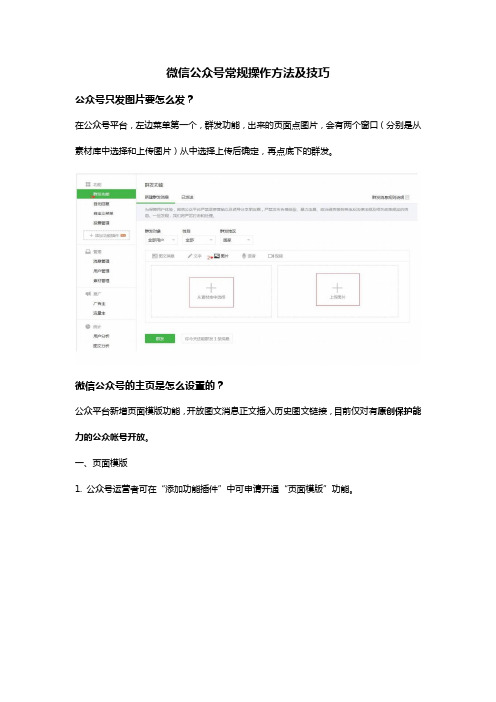
微信公众号常规操作方法及技巧公众号只发图片要怎么发?在公众号平台,左边菜单第一个,群发功能,出来的页面点图片,会有两个窗口(分别是从素材库中选择和上传图片)从中选择上传后确定,再点底下的群发。
微信公众号的主页是怎么设置的?公众平台新增页面模版功能,开放图文消息正文插入历史图文链接,目前仅对有原创保护能力的公众帐号开放。
一、页面模版1. 公众号运营者可在“添加功能插件”中可申请开通“页面模版”功能。
2. 目前可选两种页面模版样式。
3. 选择模版后从素材管理中选择图文消息文章添加到模板中,最后可以把模板链接贴到自定义菜单中。
注意:如果你不是原创保护账号,也可以通过第三方开发平台制作这样的模板,有很多第三方都可以。
实在不想花钱买第三方你还可以用一些微站、3G 页面来实现同样的效果,而且这样的微站都是免费的,制作一个生成链接挂到自定义菜单即可。
25、微信公众号用户是从哪些渠道添加关注?搜索公众号、扫描二维码及其他、搜索微信号、名片分享、图文右上角等26、用户来源渠道如何分析统计?1、收集数据的表格模板2、梳理出微信公众号用户增长重点渠道3、折线图监控用户在重点渠道的增长趋势公众号图文分析需要关注哪些指标?到达率、阅读量、转发量、收藏量、新增及流失用户数等数据来判断公众号是否上升还是下降的趋势和做出相应的优化或改动。
微信文章打开率取决哪些因素?首先文章标题,其次是文章摘要,再其次是首图为什么要注意微信文章前13 字?微信提醒的时候只能看见13 个字,而这13 个字会直接影响文章的打开率。
如何搜狗微信公众号的内容?通过搜狗搜索引擎,选择微信,就会跳出相应页面,然后选文章按钮就能搜索相对应的文章;选择公众号就能查看相应的公众号,如图所示:进行原创内容需要哪些过程?内容创作过程:采集资料——整理资料——编辑再创作——内容发布微信公众号最多可以关注多少个?目前无上限,越多越好公众号文章什么时间段群发比较合适?如果从总体上要评判微信公众号最佳群发时间,必然是晚上9-10 点,但是每个公众号又都有自己的特色,可根据自己的实际情况进行有效调整,以便阅读效果最大化。
公众号文章中的语音怎么提取

公众号文章中的语音怎么提取
据运营公众号时了解,公众号文章中的语音是可以提取的,想要在公众号文章中提取语音的朋友可以接着往下看,以下是店铺为您带来的关于公众号文章中的语音可以提取,希望对您有所帮助。
公众号文章中的语音可以提取
公众号文章中的语音提取的方法和步骤如下:
1、在微信中把文章打开,打开文章后我们点击右上角三点,然后在出现的页面中选择复制链接;
2、打开浏览器,在网址栏中粘贴刚刚复制的链接并打开;
3、在浏览器中打开链接后,选择自己所需要的语音文件(语音文件一般有个绿色的播放图标);
4、在语音文件上单击鼠标右键,然后在弹出的框框中选择“审查元素”或者是“检查”,两者功能一样;
5、在打开的页面中选择“Resources”-“Frames”,然后点击小黑三角形,打开文件并找到“Media”-“getvoice”,我们再双击它打开新的网页;
6、在打开的新的网页中,会看到中间一行是白色的其他黑色的东西,我们右击中间白的文件链接,然后选择另存为或者是视频、网页另存为并保存好;
7、当我们保存好后,到保存好语音的文件来中去查看文件即可。
通过以上小编的介绍,现在你知道应该怎样提取公众号文章中的语音了吧。
微信文章采集器使用方法详解
微信文章采集器使用方法详解对于某些用户来说,直接自定义规则可能有难度,所以在这种情况下,我们提供了网页简易模式,本文介绍八爪鱼简易采集模式下“微信文章采集”的使用教程以及注意要点。
微信公众号文章采集使用步骤步骤一、下载八爪鱼软件并登陆1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆步骤二、设置微信文章爬虫规则任务1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集微信公众号内容的,这里选择搜狗即可。
3、找到搜狗公众号这条爬虫规则,点击即可使用。
4、搜狗公众号简易采集模式任务界面介绍查看详情:点开可以看到示例网址任务名:自定义任务名,默认为搜狗公众号任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组公众号URL列表填写注意事项:提供要采集的网页网址,即搜狗微信中相关公众号的链接。
多个公众号输入多个网址即可。
采集数目:输入希望采集的数据条数示例数据:这个规则采集的所有字段信息。
5、微信文章爬虫规则设置示例例如要采集相关旅游、美食的公众号文章在设置里如下图所示:任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行商品评论URL列表:/weixin?type=1&s_from=input&query=电影&ie=utf8&_sug_=n&_sug_type_=/weixin?type=1&s_from=input&query=美食&ie=utf8&_sug_=n&_sug_type_=一行一个,使用回车(Enter)进行换行。
采集数目:可根据自身需求选填(当前默认)注意事项:URL列表中建议不超过2万条步骤三、保存并运行微信文章爬虫规则1、设置好爬虫规则之后点击保存。
微信公众号爬虫--历史文章-首页

2.有些公众号没有历史文章,这种公众号不能使用
3.有些公众号历史文章使用的是分类,这种也不能使用(下次分享这种的怎么处理)
好了,我们先来看看首页的链接吧:
+action=getmsg
对比地址,我们可以看到也就是访问的路径都一样,只是action的参数不一样,这次的action值是home,后面的参数都一样
下面开始放代码吧:
# 在之前我们的公众号名字是通过我们手动输入的,这次因为是在首页,可以通过正则表达式直接获取,新增加了获取公众号名的步骤
import requests import re, os import time # 在之前的链接里我们封装的数据库操作,可以直接拿来用 from conn.connect_mysql import insert_wechat_content,select_wechat_content
在之前我们的公众号名字是通过我们手动输入的这次因为是在首页可以通过正则表达式直接获取新增加了获取公众号名的步骤
微信公众号爬虫 --历史文章 -首页
在上次的爬虫中,我们只是爬取了历史文章中加载更多的数据(),这次是历史文章中首页的数据
历史文章首页的数据是返回在html中的,再具体点在JavaScript中
path = os.getcwd() print(path) file_path = path + '//content_file' def get_content_text(url):
""" 请求接口数据 :return: """ wechat_home_url = url headers = {
PHP+fiddler抓包采集微信文章阅读数点赞数的思路详解
PHP+fiddler抓包采集微信⽂章阅读数点赞数的思路详解简介:分析接⼝知道要获取⽂章阅读数和点赞数必须有key和uin这两个关键参数,不同公众号key不⼀样(据说有万能微信key,不懂怎么搞到),同⼀个公众号key⼤概半⼩时会过期提交链接获取⽂章阅读量api思路:1.将客户端请求阅读量接⼝的请求拦截转发到⾃⼰服务器,这样就可以获取到key ,⽤__biz关联缓存半⼩时2.提交⽂章链接进⾏查询时,服务器从⽂章链接⾥获取__biz,查询是否缓存了当前公众号对应的key,有的话进⾏第3步,没有进⾏第4步。
4.key不存在时,通知客户端重定向到该url(通知⽤websocket通知或者客户端ajax轮询,需要⽤抓包⼯具修改⽂章详情页代码让其跳转到中间页⾯待命,打开⽂章页⾯后隔⼏秒跳回中间页)并暂停程序⼏秒等待客户端更新key,此时客户端提交了新的key,⽤其进⾏查询实现1.抓包此接⼝就是获取阅读量的接⼝,参数如下图2.将此接⼝拦截转发到⾃⼰服务器,点击 rules- customize rules 在OnBeforeRequest(正式请求之前执⾏的函数)加上if (oSession.fullUrl.Contains("/mp/getappmsgext")){oSession.oRequest["Host"]= '' ;}效果,可以看到此接⼝已经被转发3.服务端缓存key,代码以PHP为例public function saveKey(Request $request){$__biz = $request->param('__biz',0);$data['uin'] = $request->param('uin',0);$data['key'] = $request->param('key',0);Cache::set($__biz,$data,30 * 60);return 'ok';}4.提交⽂章链接查询API代码public function getReadNum(Request $request){$url = $request->param('url');parse_str(parse_url($url)['query'], $param);$__biz = $param['__biz'];$key_data = Cache::get($__biz);if (empty($key_data))return 'no key';$uin = $key_data['uin'];$key = $key_data['key'];$param['uin'] = $uin;$param['key'] = $key;$param['wxtoken'] = "777";$wechat_url = "https:///mp/getappmsgext?" . http_build_query($param);//dump($wechat_url);$data = array('is_only_read' => 1,'is_temp_url' => 0,'appmsg_type' => 9,);$res = $this->get_url($wechat_url,$data);return $res;}function get_url($url,$data){$ifpost = 1;//是否post请求$datafields = $data;//post数据$cookiefile = '';//cookie⽂件$cookie = '';//cookie变量$v = false;//模拟http请求header头$header = array("Connection: Keep-Alive","Accept: text/html, application/xhtml+xml, */*", "Pragma: no-cache", "Accept-Language: zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3","User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 $ch = curl_init();curl_setopt($ch, CURLOPT_URL, $url);curl_setopt($ch, CURLOPT_HEADER, $v);curl_setopt($ch, CURLOPT_HTTPHEADER, $header);$ifpost && curl_setopt($ch, CURLOPT_POST, $ifpost);$ifpost && curl_setopt($ch, CURLOPT_POSTFIELDS, $datafields);curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);$cookie && curl_setopt($ch, CURLOPT_COOKIE, $cookie);//发送cookie变量$cookiefile && curl_setopt($ch, CURLOPT_COOKIEFILE, $cookiefile);//发送cookie⽂件$cookiefile && curl_setopt($ch, CURLOPT_COOKIEJAR, $cookiefile);//写⼊cookie到⽂件curl_setopt($ch,CURLOPT_TIMEOUT,60); //允许执⾏的最长秒数curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);$ok = curl_exec($ch);curl_close($ch);unset($ch);return $ok;}5.通知客户端重定向页⾯(这部分没写,看参考我的其他关于⽂本socket⽂章)6.⽤fiddler修改微信⽂章也jsj脚本,在OnBeforeResponse(返回给客户端之前执⾏的⽅法),加上跳转到中间页的代码效果总结以上所述是⼩编给⼤家介绍的PHP+fiddler抓包采集微信⽂章阅读数点赞数,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
如何将微信公众号文章里面的图片批量导出
如何将微信公众号文章里面的图片批量导出现在很多人都在运营微信公众号,往微信上推送一些文章,但是有时候有必要的时候会把文章里面的图片导出来。
以下是店铺为您带来的关于将微信公众号文章里面的图片批量导出,希望对您有所帮助。
将微信公众号文章里面的图片批量导出作为公司新媒体运营,经常需要负责在微信、头条号、论坛等不同的渠道,更新同一篇稿子,当然更多的时候,也需要去转载别人的文章。
这个时候,就出现了一个大问题:如何快速地批量导出已发送文章里的图片?显然直接复制粘贴微信文章图片到其他平台,是行不通的,会显示来源于微信的图片不允许使用,微信对支持复制的第三方还是很少的。
在以前我也还是用着老方法:1.要么就是老老实实的另存图片,但有些浏览器(谷歌)是不支持另存的,下载下来的都是640文件,你得添加后缀,你得修改文件属性后才能弄好。
此方法麻烦不高效。
2.像360浏览器现在也还支持另存图片,但命名上还是带有640,如果你上传其他平台,为了方便还得命名下。
此方法也不高效。
3.对于微信文章,我们可以直接复制粘贴别人的格式和图片,但如果要是需要修改某些微信图片,你还得另存。
此方法仅适用于微信复制粘贴。
4.对于很多老司机来说,不管是网页还是文章,直接敲出F12从后台扒图,也是一个不错的选择。
但有些图片较多的,你得一张一张地下载另存,同样方法不高效。
而这个时候,微微风就在想,有没有一些已经存在的软件或者技术能够解决这一痛点?来个一键下载?微微风推荐大家下载微信图片下载器使用方法非常简单:直接从微信页面或者浏览器页面复制已发送文章的链接地址到窗口下载即可。
粘贴文章地址点击下载即可。
下载完后的图片会直接在桌面以单独文件夹存在,并且是按照微信文章里面,所有图片的插入顺序进行排列的。
怎么搜集行业公众号资料
怎么搜集行业公众号资料搜集行业公众号资料是一项对于从业者而言非常重要的任务。
随着移动互联网的快速发展,公众号已经成为了人们获取信息、交流和娱乐的重要渠道之一。
不论是对于企业还是个人来说,了解行业公众号的动态和趋势,对于提高竞争力和谋求发展都具有重要意义。
本文将从两个角度,即通过搜索引擎和通过社交媒体平台,来探讨如何更好地搜集行业公众号资料。
首先,通过搜索引擎是最为常用和直接的方式之一。
搜索引擎如百度、谷歌等提供了强大的检索功能,通过输入关键词即可找到相关的行业公众号。
搜索引擎还会根据搜索者的兴趣和搜索历史,推荐相关的公众号,方便用户快速找到感兴趣的内容。
此外,搜索引擎还提供了“相关搜索”和“人们还搜索”等功能,可以进一步拓展搜索范围,发现更多有价值的行业公众号。
然而,通过搜索引擎搜集行业公众号资料也存在一定的局限性。
首先,搜索结果的排序可能受到搜索引擎算法的影响,有些优质的公众号可能会被遗漏或排在较后面。
其次,由于搜索引擎的广告推广和SEO优化等因素,搜索结果中可能会出现一些与行业公众号无关的内容。
因此,需要用户进行筛选和鉴别,选择真正与行业相关、权威可信的公众号。
除了搜索引擎,社交媒体平台也是搜集行业公众号资料的重要渠道之一。
大多数行业公众号都会在社交媒体平台上进行宣传和推广,通过关注这些平台的官方账号,可以及时了解到公众号的更新和最新动态。
在微博、微信等平台上,有许多专门推荐和推广公众号的账号或专栏,可以通过关注这些账号来获取更多行业公众号的信息。
此外,一些行业博主和专家也会在社交媒体上分享有关公众号的推荐和评价。
他们通常会在自己的账号上推荐一些在某个领域内有影响力和质量较高的公众号,这对于搜集行业公众号资料是非常有帮助的。
然而,由于社交媒体平台的信息泛滥和劣质内容泛滥的问题,需要用户保持警惕,辨别真伪,选择可信赖的来源。
除此之外,一些行业资讯网站和专业论坛也是搜集行业公众号资料的宝贵资源。
微信爬虫如何采集数据
微信爬虫如何采集数据微信公众号已经成为我们日常获取信息的一个非常重要的方式,很多人也希望能把优质的信息抓取出来,却苦于不会使用爬虫软件。
下面教大家一个不用会打代码也能轻松采集数据的软件工具:八爪鱼是如何采集微信文章信息的抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。
采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”微信爬虫采集数据步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” 微信爬虫采集数据步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”微信爬虫采集数据步骤32)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮微信爬虫采集数据步骤43)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮”微信爬虫采集数据步骤54)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”微信爬虫采集数据步骤6步骤3:创建列表循环并提取数据1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”微信爬虫采集数据步骤72)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”微信爬虫采集数据步骤83)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
右侧操作提示框中,出现字段预览表,将鼠标移到表头,点击垃圾桶图标,可删除不需要的字段。
字段选择完成后,选择“采集以下数据”微信爬虫采集数据步骤94)由于我们还想要采集每篇文章的URL,因而还需要提取一个字段。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
微信已成为大多数人每天生活工作的一部分,所以会花不少的时间浏览微信公众号的文章内容,里面的精品以及爆款文章不少,如果想把这些文章都采集下来,怎么办在手机上一篇一篇下载有不方便,这是不得不用一下科学高效的采集方法了。
下面介绍一个微信公众号内容采集的神奇方法。
很多时候,我们有采集网页文章正文的需求。
本文以搜狗微信文章为例,介绍使用八爪鱼采集网页文章正文的方法。
文章正文里一般包括文本和图片两种。
本文仅演示采集正文中本文的方法,图文采集会在另一篇教程中讲到。
本文将采集以下字段:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方式”功能,请大家注意)。
以下为“自定义数据合并方式”详解教程,大家可先了解一下:
/tutorialdetail-1/zdyhb_7.html
采集网站:/
使用功能点:
分页列表信息采集
1)进入主界面,选择“自定义模式”
微信公众号文章正文采集步骤1
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
微信公众号文章正文采集步骤2
步骤2:创建翻页循环
1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“热门”文章。
下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”
微信公众号文章正文采集步骤3
2)选择“循环点击单个元素”,以创建一个翻页循环
微信公众号文章正文采集步骤4
由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。
选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”
微信公众号文章正文采集步骤5
注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
验证方式:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或者转圈状态。
观察网页,我们发现,通过5次点击“加载更多内容”,页面加载到最底部,一共显示100篇文章。
因此,我们设置整个“循环翻页”步骤执行5次。
选中“循环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循环次数等于“5次”,点击“确定”
微信公众号文章正文采集步骤6
步骤3:创建列表循环并提取数据
1)移动鼠标,选中页面里第一条文章链接。
系统会自动识别相似链接,在操作提示框中,选择“选中全部”
微信公众号文章正文采集步骤7
2)选择“循环点击每个链接”
微信公众号文章正文采集步骤8
3)系统会自动进入文章详情页。
点击需要采集的字段(这里先点击了文章标题),在操作提示框中,选择“采集该元素的文本”。
文章发布时间、文章来源字段的采集方法同理
微信公众号文章正文采集步骤9
4)接下来开始采集文章正文。
先点击文章正文的第一段,系统会自动识别页面内的同类元素,选择“选中全部”
微信公众号文章正文采集步骤10
5)可以看到,所有的正文段落均被选中,变为绿色。
选择“采集以下元素文本”
微信公众号文章正文采集步骤11
注意:在字段表中,可进行字段的自定义修改
微信公众号文章正文采集步骤12
6)经过如上操作,正文就会被全部采集下来(默认为每一段正文为一个单元格)。
一般而言,我们希望采集的正文,合并为同一个单元格。
点击“自定义数据字段”按钮,选择“自定义数据合并方式”,勾选“同一字段多次提取合并为一行,即追加到同一字段,例如正文分页合并”,再点击“确定”
微信公众号文章正文采集步骤13
“自定义数据字段”按钮
选择“自定义数据合并方式”
微信公众号文章正文采集步骤14
微信公众号文章正文采集步骤15
如图进行勾选
步骤4:修改Xpath
1)选中整个“循环步骤”,打开“高级选项”,可以看到,八爪鱼默认生成的是固定元素列表,定位的是前20篇文章的链接
微信公众号文章正文采集步骤16
2)在火狐浏览器中打开要采集的网页并观察源码。
我们发现,通过此条Xpath://DIV[@class='main-left']/DIV[3]/UL/LI/DIV[2]/H3[1]/A,页面中所需的100篇文章均被定位了
微信公众号文章正文采集步骤17
3)将修改后的Xpath ,复制粘贴到八爪鱼中所示位置,然后点击“确定”
微信公众号文章正文采集步骤18
步骤5:修改流程图结构
我们继续观察,通过5次点击“加载更多内容”后,此网页加载出全部100篇文章。
因而我们配置规则的思路是,先建立翻页循环,加载出全部100篇文章,再建立循环列表,提取数据
1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。
如果不进行此项操作,那么将会出现很多重复数据
微信公众号文章正文采集步骤19
拖动完成后,如下图所示
微信公众号文章正文采集步骤20
步骤6:数据采集及导出
1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”
微信公众号文章正文采集步骤21
2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的数据导出
微信公众号文章正文采集步骤22
3)这里我们选择excel作为导出为格式,数据导出后如下图
微信公众号文章正文采集步骤23
4)如上图,部分文章的正文没有采集到。
那是因为,系统自动生成的文章正文的循环列表的Xpath://[@id="js_content"]/P,定位不到此篇文章的正文。
将Xpath修改为://[@id="js_content"]//P,所有的文章正文均可被定位到
微信公众号文章正文采集步骤23
修改Xpath前
微信公众号文章正文采集步骤24
说明:本文的方法仅适用于采集搜狗微信文章正文的文本内容,不可采集正文中的图片,如需采集图片,则需在流程中加入一个判断条件。
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。
相关采集教程:
微信文章采集:
/tutorial/hottutorial/zimeiti/sogouweixin
如何通过搜索关键词采集搜狗微信公众号文章:
/tutorial/sgwxwzcj-7
搜狗微信公众号热门文章采集方法以及详细教程:
/tutorial/sgwxcj
微信公众号文章正文采集:
/tutorial/wxcjnotimg
微信公众号热门文章采集(文本+图片):
/tutorial/wxcjimg
微信文章爬虫使用教程:
/tutorial/wxarticlecrawl
新浪微博发布内容采集方法:
/tutorial/xlwbcj_7
知乎回答内容采集方法以及详细步骤:
/tutorial/zh-hd-7
使用八爪鱼v7.0简易模式采集百度百科内容:
/tutorial/jxmsbdbk
百度贴吧内容采集:
/tutorial/bdtbtzcj。