机器学习之Mean Shift概述
mean-shift图像分割

由式 (4) 获得 :
������ = . ������+1
∑������������=1 ������������������������������(||������������������ℎ−������������������������||2)������(||������������������ℎ−������������������������||2) ∑������������=1 ������������������(||������������������ℎ−������������������������||2)������(||������������������ℎ−������������������������||2)
图4 3. 图像分割的细节图片如图 5 所示:
图5
实验小结
根据 mean-shift 算法原理,通过对聚类中心的不断迭代,从而找到相近的类,达到分割 的目的。通过这次实验,进一步理解了图像分割的含义,也充分体现了 mean-shift 算法在图 像分割中的应用。
参考文献
【1】 【2】 【3】
Mean-shift 跟踪算法中核函数窗宽的自动选取——彭宁嵩 杨杰 刘志 张凤超——软 件学报——2005,16(9) Mean-shift 算法的收敛性分析——刘志强 蔡自兴——《《软件学报》》——2007,18 (2) 基于分级 mean-shift 的图像分割算法——汤杨 潘志庚 汤敏 王平安 夏德深
计算机视觉实验三
——利用 mean-shift 进行图像分割
算法简介
mean-shift 是一种非参数概率密度估计的方法。通过有限次的迭代过程,Parzen 窗定义 的概率密度函数能够快速找到数据分布的模式。由于具有原理简单、无需预处理、参数少等 诸多优点,mean-shift 方法在滤波、目标跟踪、图像分割等领域得到了广泛的应用。
无监督算法有哪些

无监督算法有哪些无监督学习(Unsupervised Learning)是和监督学习相对的另一种主流机器学习的方法,无监督学习是没有任何的数据标注只有数据本身。
无监督学习算法有几种类型,以下是其中最重要的12种:1、聚类算法根据相似性将数据点分组成簇k-means聚类是一种流行的聚类算法,它将数据划分为k组。
2、降维算法降低了数据的维数,使其更容易可视化和处理主成分分析(PCA)是一种降维算法,将数据投影到低维空间,PCA可以用来将数据降维到其最重要的特征。
3.异常检测算法识别异常值或异常数据点支持向量机是可以用于异常检测。
异常检测算法用于检测数据集中的异常点,异常检测的方法有很多,但大多数可以分为有监督和无监督两种。
监督方法需要标记数据集,而无监督方法不需要。
无监督异常检测算法通常基于密度估计,试图找到数据空间中密集的区域外的点。
一个简单的方法是计算每个点到k个最近邻居的平均距离。
距离相邻点非常远的点很可能是异常点。
还有很多基于密度的异常检测算法,包括局部离群因子(Local Outlier Factor,LOF)和支持向量数据描述(Support Vector Domain Description,SVDD)。
这些算法比简单的k近邻方法更复杂,通常可以检测到更细微的异常[21]。
大多数异常检测算法都需要进行调整,例如指定一个参数来控制算法对异常的敏感程度。
如果参数过低,算法可能会漏掉一些异常。
如果设置过高,算法可能会产生误报(将正常点识别为异常点)。
4、分割算法将数据分成段或组分割算法可以将图像分割为前景和背景。
这些算法可以在不需要人工监督的情况下自动将数据集分割成有意义的组。
这个领域中比较知名的一个算法是k-means算法。
该算法通过最小化组内距离平方和将数据点分成k组。
另一种流行的分割算法是mean shift算法。
该算法通过迭代地将每个数据点移向其局部邻域的中心来实现。
mean shift对异常值具有较强的鲁棒性,可以处理密度不均匀的数据集。
自动聚类算法

自动聚类算法自动聚类算法是一种机器学习算法,它可以将数据集中的对象自动分类,以形成新的集合。
这些对象可以是文本、图像、音频、视频或其他类型的数据。
聚类是一种无监督学习技术,它不需要标记或先验信息,但仍然可以从数据中发现模式和结构。
在本文中,我们将介绍一些常用的自动聚类算法,并讨论它们的优点和缺点。
1. k-均值聚类算法k-均值聚类算法是一种基于迭代的算法,它将数据集分成k个不同的簇,使得每个簇中的数据点与该簇的质心之间的距离最小。
该算法需要指定k的值,即要分成的簇的数量。
一般来说,k的值通过试验和误差来确定。
该算法的优点在于计算简单、易于实现、速度快。
但它的缺点在于对异常值和噪声的鲁棒性较差,在数据分布不均匀的情况下效果不佳。
2. 层次聚类算法层次聚类算法是一种逐步加密数据点的算法,它将数据点逐步组合成簇并形成树状结构,称为“聚类树”。
该算法有两个主要类型:聚合层次聚类和分裂层次聚类。
聚合层次聚类从底向上构建聚类树,每个簇开始只有一个数据点,逐步合并到更大的簇,直到形成一个大的簇。
分裂层次聚类从顶向下构建聚类树,开始为一个包含所有数据点的大簇,逐步分裂成较小的簇。
该算法的优点在于不需要预先指定簇的数量,易于可视化以及能够处理异常值和噪声。
但其缺点在于计算复杂度高,速度较慢,对大型数据集不适用。
3. DBSCAN聚类算法DBSCAN聚类算法是一种基于密度的算法,可以对任意形状的簇进行聚类。
该算法通过寻找数据点的“核心点”以及它们周围的数据点来定义簇。
其中,“核心点”是指一个密度大于某一阈值的数据点,在其附近半径内的所有数据点都被认为是同一簇。
该算法的优点在于能够处理任意形状的簇,对噪声和异常值有较好的鲁棒性。
但其缺点在于对参数的依赖性较大,需要人为设定阈值,并且对数据分布不均匀的情况下效果不佳。
4. GMM聚类算法GMM聚类算法是一种基于概率模型的算法,它可以对数据分布于高斯分布的数据进行聚类。
GMM模型假设每个簇是一个高斯分布,并寻找最优参数来拟合数据集。
meanshift算法简介

基于核函数G(x)的 概率密度估计
•
用核函数G在 x点计算得到的Mean Shift 向量 正比于归一化的用核函数K估计的概率 密度的函数 的梯度,归一化因子为用核函数 G估计的x点的概率密度.因此Mean Shift向量 总是指向概率密度增加最大的方向.
Mean shift向量的物理意义的什么呢?
2ck ,d
n
2
2ck ,d cg ,d 2 d h cg ,d nh
g i 1
n
n x xi 2 xi g 2 h x xi i 1 x n x x 2 h i g h i 1
为了更好地理解这个式子的物理意义,假设上式中g(x)=1
平均的偏移量会指向样本点最密的方向,也 就是概率密度函数梯度方向
下面我们看一下mean shift算法的步骤
mh x
给定一个初始点x,核函数G(x), 容许误差 ,Mean Shift算法 循环的执行下面三步,直至结束条件满足, •计算mh ( x) •把 mh ( x)赋给 x. •如果 mh ( x) x ,结束循环;若不然,继续执行(1)
0 =1,2…..m i=1,2…..m
(5)若
,则停止;否则y ←y1转步骤②。
0
限制条件:新目标中心需位于原目标中 心附近。
Meanshift跟踪结果
• 转word文档。
• Meanshift优缺点: 优点 ①算法复杂度小; ②是无参数算法,易于与其它算法集 成; ③采用加权直方图建模,对目标小角 度旋转、轻微变形和部分遮挡不敏感等。
k-平均算法

k-均值起源于信号处理领域,并且现在也能在这一领域找到应用。
例如在计算机图形学中,色彩量化的任务,就是要把一张图像的色彩范围减少到一个固定的数目k上来。
k-均值算法就能很容易地被用来处理这一任务,并得到不错的结果。
其它得向量量化的例子有非随机抽样,在这里,为了进一步的分析,使用k-均值算法能很容易的从大规模数据集中选出k个合适的不同观测。
聚类分析在聚类分析中,k-均值算法被用来将输入数据划分到k个部分(聚类)中。
然而,纯粹的k-均值算法并不是非常灵活,同样地,在使用上有一定局限(不过上面说到得向量量化,确实是一个理想的应用场景)。
特别是,当没有额外的限制条件时,参数k是很难选择的(真如上面讨论过的一样)。
算法的另一个限制就是它不能和任意的距离函数一起使用、不能处理非数值数据。
而正是为了满足这些使用条件,许多其他的算法才被发展起来。
特征学习在(半)监督学习或无监督学习中,k-均值聚类被用来进行特征学习(或字典学习)步骤[18]。
基本方法是,首先使用输入数据训练出一个k-均值聚类表示,然后把任意的输入数据投射到这一新的特征空间。
k-均值的这一应用能成功地与自然语言处理和计算机视觉中半监督学习的简单线性分类器结合起来。
在对象识别任务中,它能展现出与其他复杂特征学习方法(如自动编码器、受限Boltzmann机等)相当的效果。
然而,相比复杂方法,它需要更多的数据来达到相同的效果,因为每个数据点都只贡献了一个特征(而不是多重特征)。
与其他统计机器学习方法的关系k-均值聚类,以及它与EM算法的联系,是高斯混合模型的一个特例。
很容易能把k-均值问题一般化为高斯混合模型[19]。
另一个k-均值算法的推广则是k-SVD算法,后者把数据点视为“编码本向量”的稀疏线性组合。
而k-均值对应于使用单编码本向量的特殊情形(其权重为1)[20]。
Mean Shift 聚类基本的Mean Shift聚类要维护一个与输入数据集规模大小相同的数据点集。
MeanShift

§5-1Mean Shift 算法Mean Shift 算法是由Fukunaga 和Hosteler 于1975年提出的一种无监督聚类方法[109],Mean Shift 的含义是均值偏移向量,它使每一个点“漂移”到密度函数的局部极大值点。
但是再提出之初,Mean Shift 算法并没有得到广泛的重视,直到1995年,Cheng 等人对该算法进行了进一步的研究[110],提出了一般的表达形式并定义了一族核函数,从而扩展了该算法的应用领域,此后Mean Shift 算法逐步得到了人们的重视。
目前,Mean Shift 算法已广泛应用于目标跟踪[111~114]、图像分割与平滑[115~118]等领域,同时由于该算法具有简洁、能够处理目标变形等优点,也是目前目标跟踪领域的一个重要研究热点。
5-1-1 Mean Shift 算法原理Mean Shift 算法是一种基于密度梯度的无参数估计方法,从空间任意一点,沿核密度的梯度上升方向,以自适应的步长进行搜索,最终可以收敛于核密度估计函数的局部极大值处。
基本的Mean Shift 算法可以描述为:设{}()1,,i x i n = 为d 维空间R d 中含有n 个样本点的集合,在点x 处的均值偏移向量的基本形式可以由式(5.1)表示:1()()hh ix S M x xx k∈=-∑ (5.1)其中,S h 是R d 中满足式(5.2)的所有y 点集合,其形状为一个半径为h 的高维球区域。
k 为所有n 个样本点中属于高维球区域的点的数目。
(x i -x )为样本点相对于点x 的偏移向量。
根据式(5.1)的定义可知,点x 的均值偏移向量就是所有属于S h 区域中的样本点与点x 的偏移向量均值,而S h 区域中的样本点大多数是沿着概率密度梯度的方向,所以均值漂移向量的方向与概率密度梯度方向一致,图5.1为具体的示意图。
{}2():()()Th S x y y x y x h=--≤ (5.2)图5.1 Mean Shift 示意图 Fig.5.1 Mean Shift sketch map根据式(5.1)和图5.1可以看出,所有属于区域S h 中的样本点对于点x 的均值漂移向量贡献度相同,而与这些点与点x 间的距离无关。
MeanShift算法
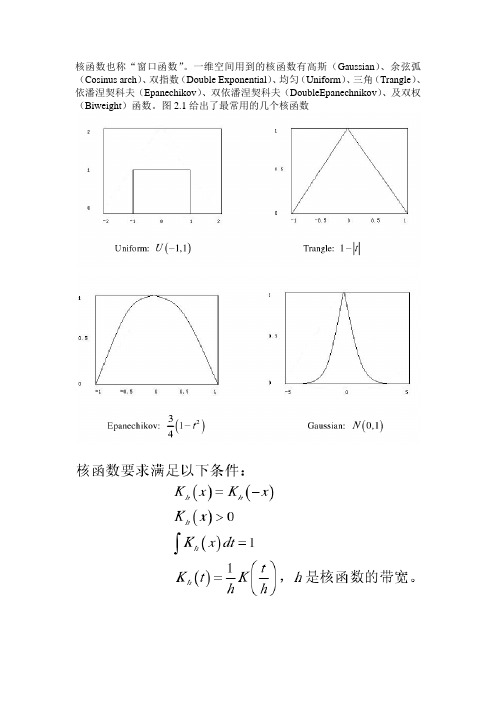
核函数也称“窗口函数”。
一维空间用到的核函数有高斯(Gaussian)、余弦弧(Cosinus arch)、双指数(Double Exponential)、均匀(Uniform)、三角(Trangle)、依潘涅契科夫(Epanechikov)、双依潘涅契科夫(DoubleEpanechnikov)、及双权(Biweight)函数。
图2.1给出了最常用的几个核函数给定一组一维空间的n个数据点集合令该数据集合的概率密度函数假设为f (x),核函数取值为,那么在数据点x处的密度估计可以按下式计算:上式就是核密度估计的定义。
其中,x为核函数要处理的数据的中心点,即数据集合相对于点x几何图形对称。
核密度估计的含义可以理解为:核估计器在被估计点为中心的窗口内计算数据点加权的局部平均。
或者:将在每个采样点为中心的局部函数的平均效果作为该采样点概率密度函数的估计值。
MeanShift实现:1.选择窗的大小和初始位置.2.计算此时窗口内的Mass Center.3.调整窗口的中心到Mass Center.4.重复2和3,直到窗口中心"会聚",即每次窗口移动的距离小于一定的阈值,或者迭代次数达到设定值。
meanshift算法思想其实很简单:利用概率密度的梯度爬升来寻找局部最优。
它要做的就是输入一个在图像的范围,然后一直迭代(朝着重心迭代)直到满足你的要求为止。
但是他是怎么用于做图像跟踪的呢?这是我自从学习meanshift以来,一直的困惑。
而且网上也没有合理的解释。
经过这几天的思考,和对反向投影的理解使得我对它的原理有了大致的认识。
在opencv中,进行meanshift其实很简单,输入一张图像(imgProb),再输入一个开始迭代的方框(windowIn)和一个迭代条件(criteria),输出的是迭代完成的位置(comp )。
这是函数原型:int cvMeanShift( const void* imgProb, CvRect windowIn,CvTermCriteria criteria, CvConnectedComp* comp )但是当它用于跟踪时,这张输入的图像就必须是反向投影图了。
认知计算概论

认知计算概论前段时间的“⼈机⼤战”——⾕歌的Alpha Go战胜⼈类棋⼿的新闻甚嚣尘上,不禁有⼈会想起1997年IBM⾃主研发的深蓝战胜卡斯帕罗夫的事件。
“⼈⼯智能”这个词再次被推上风⼝浪尖,⽽“认知计算”却鲜有⼈听说,同样是⼈类模拟机器思索,让机器具有⾃主思考能⼒,都是具有跨时代意义和⾥程碑式的存在。
认知计算更加强调机器或⼈造⼤脑如何能够主动学习、推理、感知这个世界,并与⼈类、环境进⾏交互的反应。
它会根据环境的变化做出动态的反应,所以认知更加强调它的动态性、⾃适应性、鲁棒性、交互性。
计算机在体系架构上的发展历史主要体现在两个⽅⾯:计算能⼒的增强计算规模的增⼤随着计算机计算能⼒的⼤幅增强,具备了处理海量数据的能⼒;另⼀⽅⾯,⽇常⽣活中所产⽣的数据规模⽇益扩⼤,所拥有的数据源驱动了深层次分析的需求;同时⼤数据、云计算技术的不断完善,都促进了对数据进⾏深度挖掘,提取数据的特征,利⽤特征让机器具有⾃主学习与思考的能⼒。
按照计算⽅式的不同,可以分为三个计算时代:1990s~1940s 打卡阶段(The Tabulating Era)机械式1950s~现在编程阶段(The Programming Era)⾃主输⼊2011~将来认知计算阶段(The Cognitive Era)⾃动思考“⼤脑”项⽬:Think & Learn2006 IBM Watson 利⽤⾃然语⾔分析,让机器⾃动推理事件与回答问题;涵盖医疗、数据分析、“危险游戏”等。
2011 Google ⾕歌⼤脑通过神经⽹络,能够让更多的⽤户拥有完美的、没有错误的使⽤体验;⾕歌⽆⼈驾驶汽车、⾕歌眼镜等。
2012 Baidu 百度⼤脑融合深度学习算法、数据建模、⼤规模GPU并⾏化平台等技术,构造起深度神经⽹络。
⼀、认知计算的概念:1. ⼈⼯智能与认知计算的区别:⼈⼯,以⼈为主导;认知,机器对事物与外界的理解,交互的能⼒编程能⼒;学习与推理的能⼒确定性结果;概率性结果⼈并未参与;⼈、机器、环境之间的交互图灵测试或仿造⼈测量;实际应⽤中的测试2. 认知计算所涉及的技术领域:神经科学:机器模拟⼈脑神经元的思考过程;超计算:超级快速计算和处理能⼒;纳⽶技术:芯⽚、系统等底层架构设计。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
机器学习之Mean Shift 概述一、 前言短短八周,机器学习课就已经离我们而去了。
八周的时间里,我们了解了许多,也收获了许多。
八周其实根本不足以涵盖这门课的知识,来不及领悟,来不及体会,甚至连一些皮毛都不够。
但是其知识背后隐含的奥秘却值得我们去探索。
而其中均值漂移,无疑是值得花时间琢磨的知识之一。
二、 Mean Shift 简介Mean Shift 这个概念最早是由Fukunaga 等人于1975年在一篇关于概率密度梯度函数的估计中提出来的,其最初含义正如其名,就是偏移的均值向量,在这里Mean Shift 是一个名词,它指代的是一个向量,但随着Mean Shift 理论的发展,Mean Shift 的含义也发生了变化,如果我们说Mean Shift 算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束。
然而在以后的很长一段时间内Mean Shift 并没有引起人们的注意,直到20年以后,也就是1995年,另外一篇关于Mean Shift 的重要文献才发表。
在这篇重要的文献中,Yizong Cheng 对基本的Mean Shift 算法在以下两个方面做了推广,首先Yizong Cheng 定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同,其次Yizong Cheng 还设定了一个权重系数,使得不同的样本点重要性不一样,这大大扩大了Mean Shift 的适用范围。
另外Yizong Cheng 指出了Mean Shift 可能应用的领域,并给出了具体的例子。
Comaniciu 等人把Mean Shift 成功的运用的特征空间的分析,在图像平滑和图像分割中Mean Shift 都得到了很好的应用。
Comaniciu 等在文章中证明了,Mean Shift 算法在满足一定条件下,一定可以收敛到最近的一个概率密度函数的稳态点,因此Mean Shift 算法可以用来检测概率密度函数中存在的模态。
Comaniciu 等人还把非刚体的跟踪问题近似为一个Mean Shift 最优化问题,使得跟踪可以实时的进行。
在后面的几节,本文将详细的说明Mean Shift 的基本思想及其扩展,其背后的物理含义,以及算法步骤,并给出理论证明。
最后本文还将给出Mean Shift 在聚类,图像平滑,图像分割,物体实时跟踪这几个方面的具体应用。
三、 基本Mean Shift给定d 维空间dR 中的n 个样本点i x ,i=1,…,n ,在x 点的Mean Shift 向量的基本形式定义为:()()1i hh i x S M x x x k ∈≡-∑其中,h S 是一个半径为h 的高维球区域,满足以下关系的y 点的集合()()(){}2:Th S x y y x y x h ≡--≤ k 表示在这n 个样本点i x 中,有k 个点落入h S 区域中。
我们可以看到()i x x -是样本点i x 相对于点x 的偏移向量, Mean Shift 向量()h M x 就是对落入区域h S 中的k 个样本点相对于点x 的偏移向量求和然后再平均。
从直观上看,如果样本点i x 从一个概率密度函数()f x 中采样得到,由于非零的概率密度梯度指向概率密度增加最大的方向,因此从平均上来说, h S 区域内的样本点更多的落在沿着概率密度梯度的方向。
因此,对应的, Mean Shift 向量()h M x 应该指向概率密度梯度的方向。
图1、Mean Shift 示意图如上图所示, 大圆圈所圈定的范围就是h S ,小圆圈代表落入h S 区域内的样本点i h x S ∈,黑点就是Mean Shift 的基准点x ,箭头表示样本点相对于基准点x 的偏移向量,很明显的,我们可以看出,平均的偏移向量()h M x 会指向样本分布最多的区域,也就是概率密度函数的梯度方向。
四、 扩展的Mean Shift首先我们引进核函数的概念。
定义:X 代表一个d 维的欧氏空间,x 是该空间中的一个点,用一列向量表示。
x 的模2T xx x =。
R 表示实数域。
如果一个函数:K X R →存在一个剖面函数[]:0,k R ∞→,即()2()K x kx=并且满足: 1)k 是非负的。
2)k 是非增的,即如果a b <那么()()k a k b ≥。
3)k 是分段连续的,并且0()k r dr ∞<∞⎰ 。
那么,函数()K x 就被称为核函数。
从Mean Shift 向量的基本形式我们可以看出,只要是落入h S 的采样点,无论其离x 远近,对最终的()h M x 计算的贡献是一样的,然而我们知道,一般的说来,离x 越近的采样点对估计x 周围的统计特性越有效,因此我们引进核函数的概念,在计算()h M x 时可以考虑距离的影响;同时我们也可以认为在这所有的样本点i x 中,重要性并不一样,因此我们对每个样本都引入一个权重系数。
如此以来我们就可以把基本的Mean Shift 形式扩展为:()11()()()()()nHi i i i nHi i i Gx x w x x x M x Gx x w x ==--≡-∑∑其中:()()1/21/2()H i i G x x HG H x x ---=-()G x 是一个单位核函数,H 是一个正定的对称d d ⨯矩阵,()0i w x ≥是一个赋给采样点i x 的权重在实际应用的过程中,带宽矩阵H 一般被限定为一个对角矩阵221diag ,...,d H h h ⎡⎤=⎣⎦,甚至更简单的被取为正比于单位矩阵,即2H h I =。
由于后一形式只需要确定一个系数h ,在Mean Shift 中常常被采用,在本文的后面部分我们也采用这种形式,因此上式又可以被写为:()11()()()()()ni i i i h ni i i x xG w x x x hM x x x G w x h ==--≡-∑∑我们可以看到,如果对所有的采样点i x 满足1)()1i w x = 2) 1 if 1()0 if 1x G x x ⎧<⎪=⎨≥⎪⎩会发现扩展的Mean Shift 形式退化成了最基本的Mean Shift 形式。
五、 Mean Shift 的物理含义对一个概率密度函数()f x ,已知d 维空间中n 个采样点i x ,i=1,…,n, ()f x 的核函数估计为11()ˆ()()ni i i n di i x x K w x h f x h w x ==-⎛⎫⎪⎝⎭=∑∑ 其中()0i w x ≥是一个赋给采样点i x 的权重,()K x 是一个核函数,并且满足()1k x dx =⎰我们另外定义:核函数()K x 的剖面函数()k x ,使得()2()K x k x =()k x 的负导函数()g x ,即'()()g x k x =-,其对应的核函数()2()G x g x=则概率密度函数()f x 的梯度()f x ∇的估计为:()2'1212()ˆˆ()()()ni i i i nd i i x x x x k w x h f x f x h w x =+=⎛⎫--⎪ ⎪⎝⎭∇=∇=∑∑由上面的定义, '()()g x k x =-,()2()G x gx=,上式可以重写为()()21212112112()ˆ()()()()2 ()()nii i i nd i i n i n i i i i i i n d n i i i i i x xx x G w x h f x h w x x x x x x x G w x G w x h h x x h h w x G w x h =+=====⎛⎫-- ⎪ ⎪⎝⎭∇=⎡⎤⎛⎫-⎡-⎤⎛⎫-⎢⎥ ⎪ ⎪ ⎪⎢⎥⎢⎥⎝⎭⎝⎭⎢⎥=⎢⎥-⎛⎫⎢⎥⎢⎥ ⎪⎢⎥⎝⎭⎢⎥⎣⎦⎣⎦∑∑∑∑∑∑上式右边的第二个中括号内的那一部分就是Mean Shift 向量,第一个中括号内的那一部分是以()G x 为核函数对概率密度函数()f x 的估计,我们记做ˆ()G f x ,而ˆ()f x 我们重新记做ˆ()K f x ,因此ˆ()f x ∇=ˆ()K f x ∇=()22ˆ()G h f x M x h 得()2ˆ()1ˆ2()K h G f x M x h f x ∇=上式表明,用核函数G 在x 点计算得到的Mean Shift 向量()h M x 正比于归一化的用核函数K 估计的概率密度的函数ˆ()Kf x 的梯度,归一化因子为用核函数G 估计的x 点的概率密度。
因此Mean Shift 向量()h M x 总是指向概率密度增加最大的方向。
六、 Mean Shift 算法1、算法:我们把x 提到求和号的外面来,可以得到()11()()()()ni i i i h ni i i x xG w x x h M x x x x G w x h ==-=--∑∑ 我们把上式右边的第一项记为()h m x ,即11()()()()()ni i i i h ni i i x xG w x x h m x x x G w x h ==-=-∑∑ 给定一个初始点x ,核函数()G X , 容许误差ε,Mean Shift 算法循环的执行下面三。