机器学习十大算法:kNN
knn近邻法

K最近邻(K-Nearest Neighbors,KNN)是一种简单而常用的机器学习算法,用于
分类和回归问题。
它基于实例的学习,即通过训练集中的数据进行学习,并在预测时根据距离度量从训练集中选择最近的K个数据点。
KNN算法步骤:
1.选择K值:确定K的值,即要考虑的最近邻居的数量。
2.计算距离:对于要预测的数据点,计算其与训练集中所有数据点的距离。
常用的距离度量包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
3.找到最近的K个邻居:根据计算的距离,找到距离最近的K个训练集数据
点。
4.投票或平均:对于分类问题,使用这K个邻居的类别标签进行投票,选择
票数最多的类别作为预测结果。
对于回归问题,取这K个邻居的平均值作
为预测结果。
KNN的特点和注意事项:
•非参数性:KNN是一种非参数方法,因为它不对数据的分布做出任何假设。
•计算复杂度高:在大型数据集上,KNN的计算复杂度较高,因为要计算每个预测点与所有训练点的距离。
•对异常值敏感:KNN对异常值敏感,因为预测结果取决于最近邻居的距离。
•特征缩放:特征缩放对KNN的性能很重要,因为距离度量对于不同尺度的特征可能会产生偏见。
•适用于小型数据集: KNN在小型数据集上效果较好,但在大型高维数据集上可能不如其他算法。
示例(使用Python的scikit-learn库):
在这个示例中,我们使用 scikit-learn 库中的KNeighborsClassifier来创建一个KNN分类器,并在模拟的二维数据集上进行训练和测试。
大数据十大经典算法kNN讲解

可解释性差
KNN算法的分类结果只依赖于最近 邻的样本,缺乏可解释性。
无法处理高维数据
随着维度的增加,数据点之间的距离 计算变得复杂,KNN算法在高维空 间中的性能会受到影响。
对参数选择敏感
KNN算法中需要选择合适的K值,不 同的K值可能会影响分类结果。
04
KNN算法的改进与优化
基于距离度量的优化
与神经网络算法的比较
神经网络算法
神经网络算法是一种监督学习算法,通过训练神经元之间的权重来学习数据的内 在规律。神经网络算法在处理大数据集时需要大量的计算资源和时间,因为它的 训练过程涉及到复杂的迭代和优化。
KNN算法
KNN算法的训练过程相对简单,不需要进行复杂的迭代和优化。此外,KNN算 法对于数据的分布和规模不敏感,因此在处理不同规模和分布的数据集时具有较 好的鲁棒性。
对数据分布不敏感
KNN算法对数据的分布不敏感, 因此对于非线性问题也有较好 的分类效果。
简单直观
KNN算法原理简单,实现直观, 易于理解。
分类准确度高
基于实例的学习通常比基于规 则或判别式的学习更为准确。
对异常值不敏感
由于KNN基于实例的学习方式, 异常值对分类结果影响较小。
缺点
计算量大
KNN算法需要计算样本与所有数据 点之间的距离,因此在大规模数据集 上计算量较大。
欧氏距离
适用于数据特征呈正态分布的情况,但在非 线性可分数据上表现不佳。
余弦相似度
适用于高维稀疏数据,能够处理非线性可分 问题。
曼哈顿距离
适用于网格结构的数据,但在高维数据上计 算量大。
皮尔逊相关系数
适用于衡量两组数据之间的线性关系。
K值选择策略的优化
KNN(k近邻)机器学习算法详解

KNN(k近邻)机器学习算法详解KNN算法详解一、算法概述1、kNN算法又称为k近邻分类(k-nearest neighbor classification)算法。
最简单平凡的分类器也许是那种死记硬背式的分类器,记住所有的训练数据,对于新的数据则直接和训练数据匹配,如果存在相同属性的训练数据,则直接用它的分类来作为新数据的分类。
这种方式有一个明显的缺点,那就是很可能无法找到完全匹配的训练记录。
kNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。
该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
2、代表论文Discriminant Adaptive Nearest Neighbor ClassificationTrevor Hastie and Rolbert Tibshirani3、行业应用客户流失预测、欺诈侦测等(更适合于稀有事件的分类问题)二、算法要点1、指导思想kNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
计算步骤如下:1)算距离:给定测试对象,计算它与训练集中的每个对象的距离?2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻?3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类2、距离或相似度的衡量什么是合适的距离衡量?距离越近应该意味着这两个点属于一个分类的可能性越大。
觉的距离衡量包括欧式距离、夹角余弦等。
对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适。
3、类别的判定投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)三、优缺点简单,易于理解,易于实现,无需估计参数,无需训练适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢可解释性较差,无法给出决策树那样的规则。
机器学习:K-近邻算法(KNN)

机器学习:K-近邻算法(KNN)机器学习:K-近邻算法(KNN)⼀、KNN算法概述KNN作为⼀种有监督分类算法,是最简单的机器学习算法之⼀,顾名思义,其算法主体思想就是根据距离相近的邻居类别,来判定⾃⼰的所属类别。
算法的前提是需要有⼀个已被标记类别的训练数据集,具体的计算步骤分为⼀下三步:1、计算测试对象与训练集中所有对象的距离,可以是欧式距离、余弦距离等,⽐较常⽤的是较为简单的欧式距离;2、找出上步计算的距离中最近的K个对象,作为测试对象的邻居;3、找出K个对象中出现频率最⾼的对象,其所属的类别就是该测试对象所属的类别。
⼆、算法优缺点1、优点思想简单,易于理解,易于实现,⽆需估计参数,⽆需训练;适合对稀有事物进⾏分类;特别适合于多分类问题。
2、缺点懒惰算法,进⾏分类时计算量⼤,要扫描全部训练样本计算距离,内存开销⼤,评分慢;当样本不平衡时,如其中⼀个类别的样本较⼤,可能会导致对新样本计算近邻时,⼤容量样本占⼤多数,影响分类效果;可解释性较差,⽆法给出决策树那样的规则。
三、注意问题1、K值的设定K值设置过⼩会降低分类精度;若设置过⼤,且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。
通常,K值的设定采⽤交叉检验的⽅式(以K=1为基准)经验规则:K⼀般低于训练样本数的平⽅根。
2、优化问题压缩训练样本;确定最终的类别时,不是简单的采⽤投票法,⽽是进⾏加权投票,距离越近权重越⾼。
四、python中scikit-learn对KNN算法的应⽤#KNN调⽤import numpy as npfrom sklearn import datasetsiris = datasets.load_iris()iris_X = iris.datairis_y = iris.targetnp.unique(iris_y)# Split iris data in train and test data# A random permutation, to split the data randomlynp.random.seed(0)# permutation随机⽣成⼀个范围内的序列indices = np.random.permutation(len(iris_X))# 通过随机序列将数据随机进⾏测试集和训练集的划分iris_X_train = iris_X[indices[:-10]]iris_y_train = iris_y[indices[:-10]]iris_X_test = iris_X[indices[-10:]]iris_y_test = iris_y[indices[-10:]]# Create and fit a nearest-neighbor classifierfrom sklearn.neighbors import KNeighborsClassifierknn = KNeighborsClassifier()knn.fit(iris_X_train, iris_y_train)KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=1, n_neighbors=5, p=2,weights='uniform')knn.predict(iris_X_test)print iris_y_testKNeighborsClassifier⽅法中含有8个参数(以下前两个常⽤):n_neighbors : int, optional (default = 5):K的取值,默认的邻居数量是5;weights:确定近邻的权重,“uniform”权重⼀样,“distance”指权重为距离的倒数,默认情况下是权重相等。
knn 算法
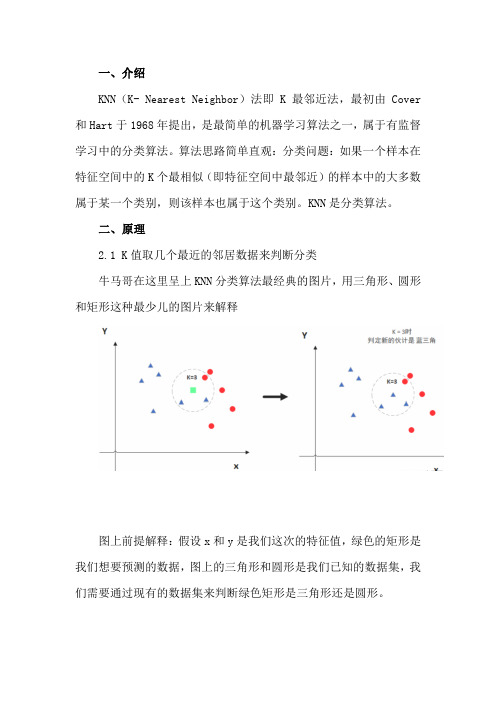
一、介绍KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover 和Hart于1968年提出,是最简单的机器学习算法之一,属于有监督学习中的分类算法。
算法思路简单直观:分类问题:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN是分类算法。
二、原理2.1 K值取几个最近的邻居数据来判断分类牛马哥在这里呈上KNN分类算法最经典的图片,用三角形、圆形和矩形这种最少儿的图片来解释图上前提解释:假设x和y是我们这次的特征值,绿色的矩形是我们想要预测的数据,图上的三角形和圆形是我们已知的数据集,我们需要通过现有的数据集来判断绿色矩形是三角形还是圆形。
当K = 3,代表选择离绿色矩形最近的三个数据,发现三个数据中三角形比较多,所以矩形被分类为三角形当K = 5,代表选择离绿色矩形最近的三个数据,发现五个数据中圆形最多,所以矩形被分类为圆形所以K值很关键,同时建议k值选取奇数。
2.2 距离问题在上面的原理中还有一个关键问题,就是怎么判断距离是否最近。
在这里采用的是欧式距离计算法:下图是在二维的平面来计算的,可以当作是有两个特征值那如果遇到多特征值的时候,KNN算法也是用欧式距离,公式如下:从这里就能看出KNN的问题了,需要大量的存储空间来存放数据,在高维度(很多特征值输入)使用距离的度量算法,电脑得炸哈哈,就是极其影响性能(维数灾难)。
而且如果要预测的样本数据偏离,会导致分类失败。
优点也是有的,如数据没有假设,准确度高,对异常点不敏感;理论成熟,思想简单。
三.KNN特点KNN是一种非参的,惰性的算法模型。
什么是非参,什么是惰性呢?非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。
也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
人工智能技术常用算法

人工智能技术常用算法
一、机器学习算法
1、数据类:
(1)K最近邻算法(KNN):KNN算法是机器学习里最简单的分类算法,它将每个样本都当作一个特征,基于空间原理,计算样本与样本之间的距离,从而进行分类。
(2)朴素贝叶斯算法(Naive Bayes):朴素贝叶斯算法是依据贝叶斯定理以及特征条件独立假设来计算各类别概率的,是一种贝叶斯决策理论的经典算法。
(3)决策树(Decision Tree):决策树是一种基于条件概率知识的分类和回归模型,用通俗的话来讲,就是基于给定的数据,通过计算出最优的属性,构建一棵树,从而做出判断的过程。
2、聚类算法:
(1)K-means:K-means算法是机器学习里最经典的聚类算法,它会将相似的样本分到一起,从而实现聚类的目的。
(2)层次聚类(Hierarchical clustering):层次聚类是一种使用组织树(层次结构)来表示数据集和类之间关系的聚类算法。
(3)谱系聚类(Spectral clustering):谱系聚类算法是指,以频谱图(spectral graph)来表示数据点之间的相互关系,然后将数据点聚类的算法。
三、深度学习算法
1、卷积神经网络(Convolutional Neural Network):卷积神经网络是一种深度学习算法。
机器学习--K近邻(KNN)算法的原理及优缺点
机器学习--K近邻(KNN)算法的原理及优缺点⼀、KNN算法原理 K近邻法(k-nearst neighbors,KNN)是⼀种很基本的机器学习⽅法。
它的基本思想是:在训练集中数据和标签已知的情况下,输⼊测试数据,将测试数据的特征与训练集中对应的特征进⾏相互⽐较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类。
由于KNN⽅法主要靠周围有限的邻近的样本,⽽不是靠判别类域的⽅法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN⽅法较其他⽅法更为适合。
KNN算法不仅可以⽤于分类,还可以⽤于回归。
通过找出⼀个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
更有⽤的⽅法是将不同距离的邻居对该样本产⽣的影响给予不同的权值(weight),如权值与距离成反⽐。
KNN算法的描述: (1)计算测试数据与各个训练数据之间的距离; (2)按照距离的递增关系进⾏排序; (3)选取距离最⼩的K个点; (4)确定前K个点所在类别的出现频率 (5)返回前K个点中出现频率最⾼的类别作为测试数据的预测分类。
算法流程: (1)准备数据,对数据进⾏预处理。
(2)选⽤合适的数据结构存储训练数据和测试元组。
(3)设定参数,如k。
(4)维护⼀个⼤⼩为k的的按距离由⼤到⼩的优先级队列,⽤于存储最近邻训练元组。
随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存⼊优先级队列。
(5)遍历训练元组集,计算当前训练元组与测试。
元组的距离,将所得距离L 与优先级队列中的最⼤距离Lmax。
(6)进⾏⽐较。
若L>=Lmax,则舍弃该元组,遍历下⼀个元组。
若L < Lmax,删除优先级队列中最⼤距离的元组,将当前训练元组存⼊优先级队列。
(7)遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
大数据十大经典算法kNN讲解PPT
观察下面的例子,我们看到,对于位置样本X,通过KNN算法,我们显然可以得到X应属于红点,但对于位置样本Y,通过KNN算法我们似乎得到了Y应属于蓝点的结论,而这个结论直观来看并没有说服力。
KNN算法的具体实现
由上面的例子可见:该算法在分类时有个重要的不足是,当样本不平衡时,即:一个类的样本容量很大,而其他类样本数量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。 但是这类样本并不接近目标样本,而数量小的这类样本很靠近目标样本。这个时候,我们有理由认为该位置样本属于数量小的样本所属的一类,但是,KNN却不关心这个问题,它只关心哪类样本的数量最多,而不去把距离远近考虑在内,因此,我们可以采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,由此,将距离远近的因素也考虑在内,避免因一个样本过大导致误判的情况。
KNN算法的缺陷
从算法实现的过程大家可以发现,该算法存两个严重的问题,第一个是需要存储全部的训练样本,第二个是需要进行繁重的距离计算量。对此,提出以下应对策略。
KNN算法的改进:分组快速搜索近邻法
其基本思想是:将样本集按近邻关系分解成组,给出每组质心的位置,以质心作为代表点,和未知样本计算距离,选出距离最近的一个或若干个组,再在组的范围内应用一般的knn算法。由于并不是将未知样本与所有样本计算距离,故该改进算法可以减少计算量,但并不能减少存储量。
问题:有一个未知形状X(图中绿色的圆点),如何判断X是什么形状?
K-最近邻算法
显然,通过上面的例子我们可以明显发现最近邻算法的缺陷——对噪声数据过于敏感,为了解决这个问题,我们可以可以把位置样本周边的多个最近样本计算在内,扩大参与决策的样本量,以避免个别数据直接决定决策结果。由此,我们引进K-最近邻算法。
knn算法及其原理
k-最近邻算法(k-Nearest Neighbors,KNN)1. 简介k-最近邻算法(k-Nearest Neighbors,KNN)是一种基本的分类和回归算法。
它是一种非参数化的、懒惰学习(lazy learning)的方法,它不需要事先对数据进行训练,而是在进行预测时,根据训练数据集中与待预测样本最相似的k个邻居的标签进行决策。
KNN算法的基本思想是“近朱者赤,近墨者黑”,即认为与某个样本最相似的k个样本往往具有相似的标签。
KNN算法的主要优点是简单易懂、易于实现,同时对于非线性的分类问题效果较好。
然而,KNN算法的计算复杂度较高,尤其是在大规模数据集上的应用效率较低。
此外,KNN算法对于样本不平衡的数据集和噪声敏感。
2. 原理KNN算法的核心是样本之间的距离度量和选择最近邻的方法。
2.1 距离度量在KNN算法中,常用的距离度量方法有欧氏距离(Euclidean Distance)、曼哈顿距离(Manhattan Distance)、闵可夫斯基距离(Minkowski Distance)等。
欧氏距离是最常用的距离度量方法,它表示两个样本之间在n维特征空间中的直线距离:d(x,y)=√(x1−y1)2+(x2−y2)2+⋯+(x n−y n)2曼哈顿距离是指两个样本在n维特征空间中沿坐标轴方向的绝对距离总和:d(x,y)=|x1−y1|+|x2−y2|+⋯+|x n−y n|闵可夫斯基距离是欧氏距离和曼哈顿距离的推广,它定义为:d(x,y)=(∑|x i−y i|pni=1) 1 p其中,p为闵可夫斯基距离的阶数。
当p=1时,闵可夫斯基距离等于曼哈顿距离;当p=2时,闵可夫斯基距离等于欧氏距离。
2.2 最近邻选择在KNN算法中,最近邻的选择方法决定了预测结果。
常用的最近邻选择方法有以下几种:•简单投票法:选择k个最近邻中出现最多的类别作为预测结果。
当k=1时,即为最近邻分类。
•加权投票法:根据距离远近为最近邻赋予不同的权重,再根据权重进行投票。
机器学习:k-NN算法(也叫k近邻算法)
机器学习:k-NN算法(也叫k近邻算法)⼀、kNN算法基础# kNN:k-Nearest Neighboors# 多⽤于解决分类问题 1)特点:1. 是机器学习中唯⼀⼀个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集就是模型本⾝;2. 思想极度简单;3. 应⽤数学知识少(近乎为零);4. 效果少;5. 可以解释机械学习算法使⽤过程中的很多细节问题6. 更完整的刻画机械学习应⽤的流程; 2)思想:根本思想:两个样本,如果它们的特征⾜够相似,它们就有更⾼的概率属于同⼀个类别;问题:根据现有训练数据集,判断新的样本属于哪种类型;⽅法/思路:1. 求新样本点在样本空间内与所有训练样本的欧拉距离;2. 对欧拉距离排序,找出最近的k个点;3. 对k个点分类统计,看哪种类型的点数量最多,此类型即为对新样本的预测类型; 3)代码实现过程:⽰例代码:import numpy as npimport matplotlib.pyplot as pltraw_data_x = [[3.3935, 2.3312],[3.1101, 1.7815],[1.3438, 3.3684],[3.5823, 4.6792],[2.2804, 2.8670],[7.4234, 4.6965],[5.7451, 3.5340],[9.1722, 2.5111],[7.7928, 3.4241],[7.9398, 0.7916]]raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]# 训练集样本的datax_train = np.array(raw_data_x)# 训练集样本的labely_train = np.array(raw_data_y)# 1)绘制训练集样本与新样本的散点图# 根据样本类型(0、1两种类型),绘制所有样本的各特征点plt.scatter(x_train[y_train == 0, 0], x_train[y_train == 0, 1], color = 'g')plt.scatter(x_train[y_train == 1, 0], x_train[y_train == 1, 1], color = 'r')# 新样本x = np.array([8.0936, 3.3657])# 将新样本的特征点绘制在训练集的样本空间plt.scatter(x[0], x[1], color = 'b')plt.show()# 2)在特征空间中,计算训练集样本中的所有点与新样本的点的欧拉距离from math import sqrt# math模块下的sqrt函数:对数值开平⽅sqrt(number)distances = []for x_train in x_train:d = sqrt(np.sum((x - x_train) ** 2))distances.append(d)# 也可以⽤list的⽣成表达式实现:# distances = [sqrt(np.sum((x - x_train) ** 2)) for x_train in x_train]# 3)找出距离新样本最近的k个点,并得到对新样本的预测类型nearest = np.argsort(distances)k = 6# 找出距离最近的k个点的类型topK_y = [y_train[i] for i in nearest[:k]]# 根据类别对k个点的数量进⾏统计from collections import Countervotes = Counter(topK_y)# 获取所需的预测类型:predict_ypredict_y = votes.most_common(1)[0][0]封装好的Python代码:import numpy as npfrom math import sqrtfrom collections import Counterdef kNN_classify(k, X_train, y_train, x):assert 1 <= k <= X_train.shape[0],"k must be valid"assert X_train.shape[0] == y_train.shape[0], \"the size of X_train nust equal to the size of y_train"assert X-train.shape[1] == x.shape[0],\"the feature number of x must be equal to X_train"distances = [sprt(np.sum((x_train - x) ** 2)) for x_train in X_train]nearest = np.argsort(distances)topK_y = [y_train[i] for i in nearest[:k]]vates = Counter(topK_y)return votes.most_common(1)[0][0] # assert:表⽰声明;此处对4个参数进⾏限定;代码中的其它Python知识:1. math模块下的sprt()⽅法:对数开平⽅;from math import sqrtprint(sprt(9))# 32. collections模块下的Counter()⽅法:对列表中的数据进⾏分类统计,⽣产⼀个Counter对象;from collections import Countermy_list = [0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3]print(Counter(my_list))# ⼀个Counter对象:Counter({0: 2, 1: 3, 2: 4, 3: 5})3. Counter对象的most_common()⽅法:Counter.most_common(n),返回Counter对象中数量最多的n种数据,返回⼀个list,list的每个元素为⼀个tuple;from collections import Countermy_list = [0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3]votes = Counter(my_list)print(votes.most_common(2))# [(3, 5), (2, 4)]⼆、总结 1)k近邻算法的作⽤ 1、解决分类问题,⽽且天然可以解决多分类问题; 2、也可以解决回归问题,其中scikit-learn库中封装的KNeighborsRegressor,就是解决回归问题; 2)缺点缺点1:效率低下1. 原因:如果训练集有m个样本,n个特征,预测每⼀个新样本,需要计算与m个样本的距离,每计算⼀个距离,要使⽤n个时间复杂度,则计算m个样本的距离,使⽤m * n个时间复杂度;2. 算法的时间复杂度:反映了程序执⾏时间随输⼊规模增长⽽增长的量级,在很⼤程度上能很好反映出算法的优劣与否。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Chapter8k NN:k-Nearest NeighborsMichael Steinbach and Pang-Ning TanContents8.1Introduction (151)8.2Description of the Algorithm (152)8.2.1High-Level Description (152)8.2.2Issues (153)8.2.3Software Implementations (155)8.3Examples (155)8.4Advanced Topics (157)8.5Exercises (158)Acknowledgments (159)References (159)8.1IntroductionOne of the simplest and rather trivial classifiers is the Rote classifier,which memorizes the entire training data and performs classification only if the attributes of the test object exactly match the attributes of one of the training objects.An obvious problem with this approach is that many test records will not be classified because they do not exactly match any of the training records.Another issue arises when two or more training records have the same attributes but different class labels.A more sophisticated approach,k-nearest neighbor(k NN)classification[10,11,21],finds a group of k objects in the training set that are closest to the test object,and bases the assignment of a label on the predominance of a particular class in this neighborhood.This addresses the issue that,in many data sets,it is unlikely that one object will exactly match another,as well as the fact that conflicting information about the class of an object may be provided by the objects closest to it.There are several key elements of this approach:(i)the set of labeled objects to be used for evaluating a test object’s class,1(ii)a distance or similarity metric that can be used to computeThis need not be the entire training set.151152kNN:k-Nearest Neighborsthe closeness of objects,(iii)the value of k,the number of nearest neighbors,and(iv) the method used to determine the class of the target object based on the classes and distances of the k nearest neighbors.In its simplest form,k NN can involve assigning an object the class of its nearest neighbor or of the majority of its nearest neighbors, but a variety of enhancements are possible and are discussed below.More generally,k NN is a special case of instance-based learning[1].This includes case-based reasoning[3],which deals with symbolic data.The k NN approach is also an example of a lazy learning technique,that is,a technique that waits until the query arrives to generalize beyond the training data.Although k NN classification is a classification technique that is easy to understand and implement,it performs well in many situations.In particular,a well-known result by Cover and Hart[6]shows that the classification error2of the nearest neighbor rule is bounded above by twice the optimal Bayes error3under certain reasonable assump-tions.Furthermore,the error of the general k NN method asymptotically approaches that of the Bayes error and can be used to approximate it.Also,because of its simplicity,k NN is easy to modify for more complicated classifi-cation problems.For instance,k NN is particularly well-suited for multimodal classes4 as well as applications in which an object can have many class labels.To illustrate the last point,for the assignment of functions to genes based on microarray expression profiles,some researchers found that k NN outperformed a support vector machine (SVM)approach,which is a much more sophisticated classification scheme[17]. The remainder of this chapter describes the basic k NN algorithm,including vari-ous issues that affect both classification and computational performance.Pointers are given to implementations of k NN,and examples of using the Weka machine learn-ing package to perform nearest neighbor classification are also provided.Advanced techniques are discussed briefly and this chapter concludes with a few exercises. 8.2Description of the Algorithm8.2.1High-Level DescriptionAlgorithm8.1provides a high-level summary of the nearest-neighbor classification method.Given a training set D and a test object z,which is a vector of attribute values and has an unknown class label,the algorithm computes the distance(or similarity)2The classification error of a classifier is the percentage of instances it incorrectly classifies.3The Bayes error is the classification error of a Bayes classifier,that is,a classifier that knows the underlying probability distribution of the data with respect to class,and assigns each data point to the class with the highest probability density for that point.For more detail,see[9].4With multimodal classes,objects of a particular class label are concentrated in several distinct areas of the data space,not just one.In statistical terms,the probability density function for the class does not have a single“bump”like a Gaussian,but rather,has a number of peaks.8.2Description of the Algorithm 153Algorithm 8.1Basic k NN AlgorithmInput :D ,the set of training objects,the test object,z ,which is a vector ofattribute values,and L ,the set of classes used to label the objectsOutput :c z ∈L ,the class of z foreach object y ∈D do|Compute d (z ,y ),the distance between z and y ;endSelect N ⊆D ,the set (neighborhood)of k closest training objects for z ;c z =argmax v ∈Ly ∈N I (v =class (c y ));where I (·)is an indicator function that returns the value 1if its argument is true and 0otherwise.between z and all the training objects to determine its nearest-neighbor list.It then assigns a class to z by taking the class of the majority of neighboring objects.Ties are broken in an unspecified manner,for example,randomly or by taking the most frequent class in the training set.The storage complexity of the algorithm is O (n ),where n is the number of training objects.The time complexity is also O (n ),since the distance needs to be computed between the target and each training object.However,there is no time taken for the construction of the classification model,for example,a decision tree or sepa-rating hyperplane.Thus,k NN is different from most other classification techniques which have moderately to quite expensive model-building stages,but very inexpensive O (constant )classification steps.8.2.2IssuesThere are several key issues that affect the performance of k NN.One is the choice of k .This is illustrated in Figure 8.1,which shows an unlabeled test object,x ,and training objects that belong to either a “+”or “−”class.If k is too small,then the result can be sensitive to noise points.On the other hand,if k is too large,then the neighborhood may include too many points from other classes.An estimate of the best value for k can be obtained by cross-validation.However,it is important to point out that k =1may be able to perform other values of k ,particularly for small data sets,including those typically used in research or for class exercises.However,given enough samples,larger values of k are more resistant to noise.Another issue is the approach to combining the class labels.The simplest method is to take a majority vote,but this can be a problem if the nearest neighbors vary widely in their distance and the closer neighbors more reliably indicate the class of the object.A more sophisticated approach,which is usually much less sensitive to the choice of k ,weights each object’s vote by its distance.Various choices are possible;for example,the weight factor is often taken to be the reciprocal of the squared distance:w i =1/d (y ,z )2.This amounts to replacing the last step of Algorithm 8.1with the154kNN:k-Nearest Neighbors ++‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒+++X ++++++‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒+++++++++++X ‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒‒+++++++++++X (a) Neighborhood toosmall.(b) Neighborhood just right.(c) Neighborhood too large.Figure 8.1k -nearest neighbor classification with small,medium,and large k .following:Distance-Weighted V oting:c z =argmax v ∈L y ∈N w i ×I (v =class (c y ))(8.1)The choice of the distance measure is another important monly,Euclidean or Manhattan distance measures are used [21].For two points,x and y ,with n attributes,these distances are given by the following formulas:d (x ,y )= n k =1(x k −y k )2Euclidean distance (8.2)d (x ,y )= n k =1|x k −y k |Manhattan distance (8.3)where x k and y k are the k th attributes (components)of x and y ,respectively.Although these and various other measures can be used to compute the distance between two points,conceptually,the most desirable distance measure is one for which a smaller distance between two objects implies a greater likelihood of having the same class.Thus,for example,if k NN is being applied to classify documents,then it may be better to use the cosine measure rather than Euclidean distance.Note that k NN can also be used for data with categorical or mixed categorical and numerical attributes as long as a suitable distance measure can be defined [21].Some distance measures can also be affected by the high dimensionality of the data.In particular,it is well known that the Euclidean distance measure becomes less discriminating as the number of attributes increases.Also,attributes may have to be scaled to prevent distance measures from being dominated by one of the attributes.For example,consider a data set where the height of a person varies from 1.5to 1.8m,8.3Examples155 the weight of a person varies from90to300lb,and the income of a person varies from$10,000to$1,000,000.If a distance measure is used without scaling,the income attribute will dominate the computation of distance,and thus the assignment of class labels.8.2.3Software ImplementationsAlgorithm8.1is easy to implement in almost any programming language.However, this section contains a short guide to some readily available implementations of this algorithm and its variants for those who would rather use an existing implementation. One of the most readily available k NN implementations can be found in Weka[26]. The main function of interest is IBk,which is basically Algorithm8.1.However,IBk also allows you to specify a couple of choices of distance weighting and the option to determine a value of k by using cross-validation.Another popular nearest neighbor implementation is PEBLS(Parallel Exemplar-Based Learning System)[5,19]from the CMU Artificial Intelligence repository[20]. According to the site,“PEBLS(Parallel Exemplar-Based Learning System)is a nearest-neighbor learning system designed for applications where the instances have symbolic feature values.”8.3ExamplesIn this section we provide a couple of examples of the use of k NN.For these examples, we will use the Weka package described in the previous section.Specifically,we used Weka3.5.6.To begin,we applied k NN to the Iris data set that is available from the UCI Machine Learning Repository[2]and is also available as a sample datafile with Weka.This data set consists of150flowers split equally among three Iris species:Setosa,Versicolor, and Virginica.Eachflower is characterized by four measurements:petal length,petal width,sepal length,and sepal width.The Iris data set was classified using the IB1algorithm,which corresponds to the IBk algorithm with k=1.In other words,the algorithm looks at the closest neighbor, as computed using Euclidean distance from Equation8.2.The results are quite good, as the reader can see by examining the confusion matrix5given in Table8.1. However,further investigation shows that this is a quite easy data set to classify since the different species are relatively well separated in the data space.To illustrate, we show a plot of the data with respect to petal length and petal width in Figure8.2. There is some mixing between the Versicolor and Virginica species with respect to 5A confusion matrix tabulates how the actual classes of various data instances(rows)compare to their predicted classes(columns).156kNN:k-Nearest NeighborsTABLE 8.1Confusion Matrix for Weka k NNClassifier IB1on the Iris Data SetActual/Predicted Setosa Versicolor Virginica Setosa5000Versicolor0473Virginica 0446their petal lengths and widths,but otherwise the species are well separated.Since the other two variables,sepal width and sepal length,add little if any discriminating information,the performance seen with basic k NN approach is about the best that can be achieved with a k NN approach or,indeed,any other approach.The second example uses the ionosphere data set from UCI.The data objects in this data set are radar signals sent into the ionosphere and the class value indicates whether or not the signal returned information on the structure of the ionosphere.There are 34attributes that describe the signal and 1class attribute.The IB1algorithm applied on the original data set gives an accuracy of 86.3%evaluated via tenfold cross-validation,while the same algorithm applied to the first nine attributes gives an accuracy of 89.4%.In other words,using fewer attributes gives better results.The confusion matrices are given ing cross-validation to select the number of nearest neighbors gives an accuracy of 90.8%with two nearest neighbors.The confusion matrices for these cases are given below in Tables 8.2,8.3,and 8.4,respectively.Adding weighting for nearest neighbors actually results in a modest drop in accuracy.The biggest improvement is due to reducing the number of attributes.P e t a l w i d t h Petal lengthFigure 8.2Plot of Iris data using petal length and width.8.4Advanced Topics157TABLE8.2Confusion Matrix for Weka k NN ClassifierIB1on the Ionosphere Data Set Using All AttributesActual/Predicted Good Signal Bad SignalGood Signal8541Bad Signal72188.4Advanced TopicsTo address issues related to the distance function,a number of schemes have been developed that try to compute the weights of each individual attribute or in some other way determine a more effective distance metric based upon a training set[13,15]. In addition,weights can be assigned to the training objects themselves.This can give more weight to highly reliable training objects,while reducing the impact of unreliable objects.The PEBLS system by Cost and Salzberg[5]is a well-known example of such an approach.As mentioned,k NN classifiers are lazy learners,that is,models are not built explic-itly unlike eager learners(e.g.,decision trees,SVM,etc.).Thus,building the model is cheap,but classifying unknown objects is relatively expensive since it requires the computation of the k-nearest neighbors of the object to be labeled.This,in general, requires computing the distance of the unlabeled object to all the objects in the la-beled set,which can be expensive particularly for large training sets.A number of techniques,e.g.,multidimensional access methods[12]or fast approximate similar-ity search[16],have been developed for efficient computation of k-nearest neighbor distance that make use of the structure in the data to avoid having to compute distance to all objects in the training set.These techniques,which are particularly applicable for low dimensional data,can help reduce the computational cost without affecting classification accuracy.The Weka package provides a choice of some of the multi-dimensional access methods in its IBk routine.(See Exercise4.)Although the basic k NN algorithm and some of its variations,such as weighted k NN and assigning weights to objects,are relatively well known,some of the more advanced techniques for k NN are much less known.For example,it is typically possible to eliminate many of the stored data objects,but still retain the classification accuracy of the k NN classifier.This is known as“condensing”and can greatly speed up the classification of new objects[14].In addition,data objects can be removed to TABLE8.3Confusion Matrix for Weka k NN ClassifierIB1on the Ionosphere Data Set Using the First Nine AttributesActual/Predicted Good Signal Bad SignalGood Signal10026Bad Signal11214158kNN:k-Nearest NeighborsTABLE8.4Confusion Matrix for Weka k NNClassifier IBk on the Ionosphere Data Set Usingthe First Nine Attributes with k=2Actual/Predicted Good Signal Bad SignalGood Signal1039Bad Signal23216improve classification accuracy,a process known as“editing”[25].There has also been a considerable amount of work on the application of proximity graphs(nearest neighbor graphs,minimum spanning trees,relative neighborhood graphs,Delaunay triangulations,and Gabriel graphs)to the k NN problem.Recent papers by Toussaint [22–24],which emphasize a proximity graph viewpoint,provide an overview of work addressing these three areas and indicate some remaining open problems.Other important resources include the collection of papers by Dasarathy[7]and the book by Devroye,Gyorfi,and Lugosi[8].Also,a fuzzy approach to k NN can be found in the work of Bezdek[4].Finally,an extensive bibliography on this subject is also available online as part of the Annotated Computer Vision Bibliography[18].8.5Exercises1.Download the Weka machine learning package from the Weka project home-page and the Iris and ionosphere data sets from the UCI Machine Learning Repository.Repeat the analyses performed in this chapter.2.Prove that the error of the nearest neighbor rule is bounded above by twice theBayes error under certain reasonable assumptions.3.Prove that the error of the general k NN method asymptotically approaches thatof the Bayes error and can be used to approximate it.4.Various spatial or multidimensional access methods can be used to speed upthe nearest neighbor computation.For the k-d tree,which is one such method, estimate how much the saving would ment:The IBk Weka classification algorithm allows you to specify the method offinding nearest neighbors.Try this on one of the larger UCI data sets,for example,predicting sex on the abalone data set.5.Consider the one-dimensional data set shown in Table8.5.TABLE8.5Data Set for Exercise5x 1.5 2.5 3.5 4.5 5.0 5.5 5.75 6.57.510.5y++−−−++−++References159(a)Given the data points listed in Table8.5,compute the class of x=5.5according to its1-,3-,6-,and9-nearest neighbors(using majority vote).(b)Repeat the previous exercise,but use the weighted version of k NN givenin Equation(8.1).ment on the use of k NN when documents are compared with the cosinemeasure,which is a measure of similarity,not distance.7.Discuss kernel density estimation and its relationship to k NN.8.Given an end user who desires not only a classification of unknown cases,butalso an understanding of why cases were classified the way they were,which classification method would you prefer:decision tree or k NN?9.Sampling can be used to reduce the number of data points in many kinds ofdata ment on the use of sampling for k NN.10.Discuss how k NN could be used to perform classification when each class canhave multiple labels and/or classes are organized in a hierarchy.AcknowledgmentsThis work was supported by NSF Grant CNS-0551551,NSF ITR Grant ACI-0325949, NSF Grant IIS-0308264,and NSF Grant IIS-0713227.Access to computing facil-ities was provided by the University of Minnesota Digital Technology Center and Supercomputing Institute.References[1] D.W.Aha,D.Kibler,and M.K.Albert.Instance-based learning algorithms.Mach.Learn.,6(1):37–66,January1991.[2] A.Asuncion and D.Newman.UCI Machine Learning Repository,2007.[3] B.Bartsch-Sp¨o rl,M.Lenz,and A.H¨u bner.Case-based reasoning—surveyand future directions.In F.Puppe,editor,XPS-99:Knowledge-Based Systems—Survey and Future Directions,5th Biannual German Conference on Knowledge-Based Systems,volume1570of Lecture Notes in Computer Sci-ence,W¨u rzburg,Germany,March3-51999.Springer.[4]J.C.Bezdek,S.K.Chuah,and D.Leep.Generalized k-nearest neighbor rules.Fuzzy Sets Syst.,18(3):237–256,1986.[5]S.Cost and S.Salzberg.A weighted nearest neighbor algorithm for learningwith symbolic features.Mach.Learn.,10(1):57–78,1993.160kNN:k-Nearest Neighbors[6]T.Cover and P.Hart.Nearest neighbor pattern classification.IEEE Transactionson Information Theory,13(1):21–27,January1967.[7] B.Dasarathy.Nearest Neighbor(NN)Norms:NN Pattern Classification Tech-puter Society Press,1991.[8]L.Devroye,L.Gyorfi,and G.Lugosi.A Probabilistic Theory of Pattern Recog-nition.Springer-Verlag,1996.[9]R.O.Duda,P.E.Hart,and D.G.Stork.Pattern Classification(2nd Edition).Wiley-Interscience,November2000.[10] E.Fix and J.J.Hodges.Discriminatory analysis:Non-parametric discrimi-nation:Consistency properties.Technical report,USAF School of Aviation Medicine,1951.[11] E.Fix and J.J.Hodges.Discriminatory analysis:Non-parametric discrimina-tion:Small sample performance.Technical report,USAF School of Aviation Medicine,1952.[12]V.Gaede and O.G¨u nther.Multidimensional access methods.ACM Comput.Surv.,30(2):170–231,1998.[13] E.-H.Han,G.Karypis,and V.Kumar.Text categorization using weight adjustedk-nearest neighbor classification.In PAKDD’01:Proceedings of the5th Pacific-Asia Conference on Knowledge Discovery and Data Mining,pages53–65, London,UK,2001.Springer-Verlag.[14]P.Hart.The condensed nearest neighbor rule.IEEE rm.,14(5):515–516,May1968.[15]T.Hastie and R.Tibshirani.Discriminant adaptive nearest neighbor classifica-tion.IEEE Trans.Pattern Anal.Mach.Intell.,18(6):607–616,1996.[16]M.E.Houle and J.Sakuma.Fast approximate similarity search in extremelyhigh-dimensional data sets.In ICDE’05:Proceedings of the21st Interna-tional Conference on Data Engineering,pages619–630,Washington,DC, 2005.IEEE Computer Society.[17]M.Kuramochi and G.Karypis.Gene classification using expression profiles:A feasibility study.In BIBE’01:Proceedings of the2nd IEEE InternationalSymposium on Bioinformatics and Bioengineering,page191,Washington,DC, 2001.IEEE Computer Society.[18]K.Price.Nearest neighbor classification bibliography.http://www.visionbib.com/bibliography/pattern621.html,2008.Part of the Annotated Computer Vision Bibliography.[19]J.Rachlin,S.Kasif,S.Salzberg,and D.W.Aha.Towards a better understandingof memory-based reasoning systems.In International Conference on Machine Learning,pages242–250,1994.References161 [20]S.Salzberg.PEBLS:Parallel exemplar-based learning system.http://www./afs/cs/project/ai-repository/ai/areas/learning/systems/pebls/0.html, 1994.[21]P.-N.Tan,M.Steinbach,and V.Kumar.Introduction to Data Minining.PearsonAddison-Wesley,2006.[22]G.T.Toussaint.Proximity graphs for nearest neighbor decision rules:Recentprogress.In Interface-2002,34th Symposium on Computing and Statistics, Montreal,Canada,April17–20,2002.[23]G.T.Toussaint.Open problems in geometric methods for instance-based learn-ing.In Discrete and Computational Geometry,volume2866of Lecture Notes in Computer Science,pages273–283,December6–9,2003.[24]G.T.Toussaint.Geometric proximity graphs for improving nearest neighbormethods in instance-based learning and data put.Geometry Appl.,15(2):101–150,2005.[25] D.Wilson.Asymptotic properties of nearest neighbor rules using edited data.IEEE Trans.Syst.,Man,and Cybernetics,2:408–421,1972.[26]I.H.Witten and E.Frank.Data Mining:Practical Machine Learning Tools andTechniques,Second Edition(Morgan Kaufmann Series in Data Management Systems).Morgan Kaufmann,June2005.© 2009 by Taylor & Francis Group, LLC。