knn分类算法计算过程
knn 算法
一、介绍KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover 和Hart于1968年提出,是最简单的机器学习算法之一,属于有监督学习中的分类算法。
算法思路简单直观:分类问题:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN是分类算法。
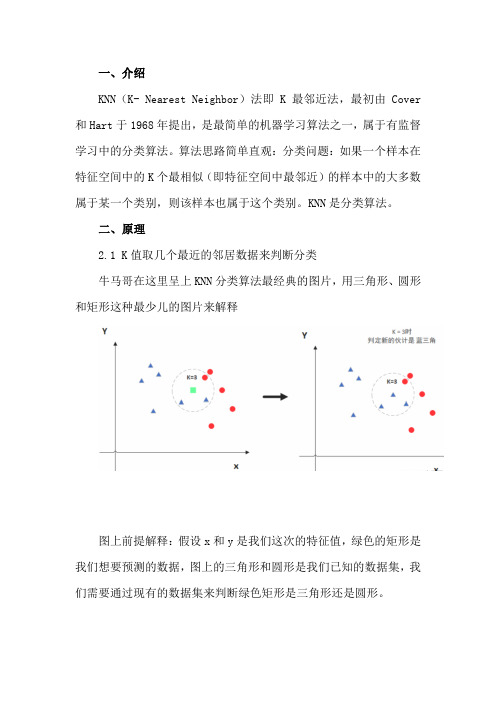
二、原理2.1 K值取几个最近的邻居数据来判断分类牛马哥在这里呈上KNN分类算法最经典的图片,用三角形、圆形和矩形这种最少儿的图片来解释图上前提解释:假设x和y是我们这次的特征值,绿色的矩形是我们想要预测的数据,图上的三角形和圆形是我们已知的数据集,我们需要通过现有的数据集来判断绿色矩形是三角形还是圆形。
当K = 3,代表选择离绿色矩形最近的三个数据,发现三个数据中三角形比较多,所以矩形被分类为三角形当K = 5,代表选择离绿色矩形最近的三个数据,发现五个数据中圆形最多,所以矩形被分类为圆形所以K值很关键,同时建议k值选取奇数。
2.2 距离问题在上面的原理中还有一个关键问题,就是怎么判断距离是否最近。
在这里采用的是欧式距离计算法:下图是在二维的平面来计算的,可以当作是有两个特征值那如果遇到多特征值的时候,KNN算法也是用欧式距离,公式如下:从这里就能看出KNN的问题了,需要大量的存储空间来存放数据,在高维度(很多特征值输入)使用距离的度量算法,电脑得炸哈哈,就是极其影响性能(维数灾难)。
而且如果要预测的样本数据偏离,会导致分类失败。
优点也是有的,如数据没有假设,准确度高,对异常点不敏感;理论成熟,思想简单。
三.KNN特点KNN是一种非参的,惰性的算法模型。
什么是非参,什么是惰性呢?非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。
也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
knn算法伪代码

knn算法伪代码简介knn算法(K-Nearest Neighbors)是一种用于分类和回归的非参数统计方法,被广泛应用于机器学习领域。
它的基本思想是通过比较待分类样本与训练样本之间的相似度,将待分类样本归为最相似的k个训练样本的类别。
knn算法简单、易于理解和实现,并且在某些场景下具有较好的性能。
算法步骤knn算法流程可以分为以下几个步骤:1. 导入数据从训练集中读取已知分类的样本数据和对应的类别标签,同时导入待分类的样本数据。
2. 计算距离对于待分类的每个样本,计算它与训练集中每个样本之间的距离。
常用的距离度量方法有欧氏距离、曼哈顿距离、闵可夫斯基距离等。
3. 选择k值确定k的取值,k代表着需要找出与待分类样本最相似的k个训练样本。
4. 找出k个最近邻根据计算的距离,找出与待分类样本最相似的k个训练样本。
5. 统计类别统计k个最近邻中各个类别的数量,选择数量最多的类别作为待分类样本的类别。
6. 输出结果将待分类样本划分到最终确定的类别中,完成分类任务。
伪代码实现以下是knn算法的伪代码实现:function knn(data, labels, new_sample, k):distances = []for i in range(length(data)):dist = distance(data[i], new_sample)distances.append((dist, labels[i]))distances.sort()k_nearest = distances[:k]class_counts = {}for _, label in k_nearest:if label in class_counts:class_counts[label] += 1else:class_counts[label] = 1return max(class_counts, key=class_counts.get)其中,data是训练集的样本数据,labels是训练集中每个样本的类别标签,new_sample是待分类的样本数据,k是最近邻的个数。
最近邻算法计算公式

最近邻算法计算公式最近邻算法(K-Nearest Neighbors algorithm,简称KNN算法)是一种常用的分类和回归算法。
该算法的基本思想是:在给定一个新的数据点时,根据其与已有的数据点之间的距离来判断其类别或预测其数值。
KNN算法的计算公式可以分为两个部分:距离计算和分类预测。
一、距离计算:KNN算法使用欧氏距离(Euclidean Distance)来计算数据点之间的距离。
欧氏距离是指在m维空间中两个点之间的直线距离。
假设有两个数据点p和q,p的坐标为(p1, p2, ..., pm),q的坐标为(q1, q2, ..., qm),则p和q之间的欧氏距离为:d(p, q) = sqrt((p1-q1)^2 + (p2-q2)^2 + ... + (pm-qm)^2)其中,sqrt表示求平方根。
二、分类预测:KNN算法通过比较距离,根据最近的K个邻居来进行分类预测。
假设有N个已知类别的数据点,其中k个属于类别A,另外K个属于类别B,要对一个新的数据点p进行分类预测,KNN算法的步骤如下:1.计算p与每个已知数据点之间的距离;2.根据距离的大小,将距离最近的K个邻居选取出来;3.统计K个邻居中每个类别的数量;4.根据数量的大小,将p分为数量最多的那个类别。
如果数量相同,可以通过随机选择或其他规则来决定。
其中,K是KNN算法的一个参数,表示选取最近的K个邻居进行分类预测。
K的选择通常是基于经验或交叉验证等方法来确定的。
较小的K值会使模型更加灵敏,但也更容易受到噪声的影响,较大的K值会使模型更加稳健,但也更容易混淆不同的类别。
总结起来,KNN算法的计算公式可以表示为:1.距离计算公式:d(p, q) = sqrt((p1-q1)^2 + (p2-q2)^2 + ... + (pm-qm)^2)2.分类预测步骤:1)计算p与每个已知数据点之间的距离;2)根据距离的大小,选取距离最近的K个邻居;3)统计K个邻居中每个类别的数量;4)将p分为数量最多的那个类别。
KNN算法 - 机器学习算法入门
机器学习算法中的一种监督学习的算法:KNN算法,全称是K-NearestNeighbor,中文称之为K近邻算法。
它是机器学习可以说是最简单的分类算法之一,同时也是最常用的分类算法之一。
在接下来的内容中,将通过以下的几个方面的内容对该算法进行详细的讲解:一、算法思想五、距离问题二,篝法步骚KNN算KNNJI法实现1、算法思想思想首先对KNN算法的思想进行简单的描述:KNN算法是一个基本的分类和回归的算法,它是属于监督学习中分类方法的一种。
其大致思想表述为:1.给定一个训练集合M和一个测试对象n,其中该对象是由一个属性值和未知的类别标签组成的向量。
2.计算对象m和训练集中每个对象之间的距离(一般是欧式距离)或者相似度(一般是余弦相似度),确定最近邻的列表3.将最近邻列表中数量占据最多的类别判给测试对象z。
4.一般来说,我们只选择训练样本中前K个最相似的数据,这便是k-近邻算法中k的出处。
用一句俗语来总结KNN算法的思想:物以类聚,人以群分说明•所谓的监督学习和非监督学习,指的是训练数据是否有类别标签,如果有则是监督学习,否则是非监督学习•在监督学习中,输入变量和输出变量可以连续或者离散的。
如果输入输出变量都是连续型变量,则称为回归问题(房价预测);如果输出是离散型变量,则称之为分类问题(判断患者是否属于患病)•在无监督学习中,数据是没有任何标签的,主要是各种聚类算法(以后学习)2、算法步骤KNN算法的步骤非常简单:1.计算未知实例到所有已知实例的距离;2.选择参数K(下面会具体讲解K值的相关问题)3.根据多数表决(Majority-Voting)规则,将未知实例归类为样本中最多数的类别3、图解KNN算法K值影响下面通过一组图形来解释下KNN算法的思想。
我们的目的是:判断蓝色的点属于哪个类别我们通过变化K的取值来进行判断。
在该算法中K的取值一般是奇数,防止两个类别的个数相同,无法判断对象的类别K=1、3、5、7…….1.首先如果K=1:会是什么的情况?根据图形判断:蓝色图形应该是属于三角形2.K=3的情形从图中可以看出来:蓝色部分还是属于三角形3.K=5的情形:此时我们观察到蓝色部分属于正方形了4.K=7的情形:这个时候蓝色部分又变成了三角形小结当K取值不同的时候,判别的结果是不同的。
knn算法

教育技术前沿讲座计算机科学学院教育技术学01 41109020105刘泽成KNN - 简介是K最邻近结点算法(k-Nearest Neighbor algorithm)的缩写形式,是电子信息分类器算法的一种。
KNN方法对包容型数据的特征变量筛选尤其有效。
KNN - 算法描述该算法的基本思路是:在给定新文本后,考虑在训练文本集中与该新文本距离最近(最相似)的 K 篇文本,根据这 K 篇文本所属的类别判定新文本所属的类别,具体的算法步骤如下:一、:根据特征项集合重新描述训练文本向量二、:在新文本到达后,根据特征词分词新文本,确定新文本的向量表示三、:在训练文本集中选出与新文本最相似的 K 个文本,计算公式为:【图】公式(1)-KNN 其中,K 值的确定目前没有很好的方法,一般采用先定一个初始值,然后根据实验测试的结果调整 K 值,一般初始值定为几百到几千之间。
四、:在新文本的 K 个邻居中,依次计算每类的权重,计算公式如下:【图】】公式(2)-KNN其中, x为新文本的特征向量, Sim(x,di)为相似度计算公式,与上一步骤的计算公式相同,而y(di,Cj)为类别属性函数,即如果di 属于类Cj ,那么函数值为 1,否则为 0。
五、:比较类的权重,将文本分到权重最大的那个类别中。
除此以外,支持向量机和神经网络算法在文本分类系统中应用得也较为广泛,支持向量机的基本思想是使用简单的线形分类器划分样本空间。
对于在当前特征空间中线形不可分的模式,则使用一个核函数把样本映射到一个高维空间中,使得样本能够线形可分。
而神经网络算法采用感知算法进行分类。
在这种模型中,分类知识被隐式地存储在连接的权值上,使用迭代算法来确定权值向量。
当网络输出判别正确时,权值向量保持不变,否则进行增加或降低的调整,因此也称为奖惩法。
KNN - 不足该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
knn算法的基本原理及公式

knn算法的基本原理及公式KNN(K-Nearest Neighbors)算法是一种常用的分类和回归算法,它的基本原理简单而直观。
KNN算法的核心思想是通过找出与待分类样本最相似的K个已知类别样本,根据这K个样本的类别多数表决的原则,来判断待分类样本属于何种类别。
KNN算法步骤如下:1. 首先,我们需要将训练样本集中的每个样本点的特征向量表示成一个点在n维空间中的坐标,每个坐标轴代表一个特征属性。
2. 对于一个待分类的样本点,我们需要计算它与训练样本集中每个样本点的距离。
常用的距离度量方法有欧式距离、曼哈顿距离等。
3. 然后,根据上一步计算得到的距离,从小到大对训练样本集进行排序。
4. 接下来,选择距离待分类样本点最近的K个样本点。
5. 最后,根据这K个样本点的类别进行多数表决,将待分类样本点归为类别最多的一类。
KNN算法的公式表示如下:对于一个样本点x,其特征属性表示为(x1, x2, ..., xn)。
训练样本集中的某个样本点i表示为(xi1, xi2, ..., xin),则样本点x和样本点i之间的欧氏距离d(x, i)为:d(x, i) = √((x1 - xi1)^2 + (x2 - xi2)^2 + ... + (xn - xin)^2)找出距离样本点x最近的K个样本点后,根据多数表决原则,可将样本点x归为其中样本类别最多的一类。
KNN算法的特点是简单易于理解,适用于多种领域的分类问题。
它没有明确的训练过程,只需要保存训练样本集,因此训练时间很短,预测效率较高。
但是,KNN算法在处理大规模数据集时,计算距离的复杂度较高,需要耗费较多的计算资源。
另外,KNN算法对数据集中的噪声和异常值比较敏感,需要进行数据预处理和特征选择。
总的来说,KNN算法是一种简单但有效的分类方法。
通过寻找与待分类样本最相似的K个已知类别样本,它可以进行准确的分类和回归预测。
在实际应用中,可以根据具体的需求和问题特点,选择合适的K 值和距离度量方法,以获得更好的分类性能。
KNN算法
kNN算法简介:kNN(k Nearest Neighbors)算法又叫k最临近方法,总体来说kNN算法是相对比较容易理解的算法之一,假设每一个类包含多个样本数据,而且每个数据都有一个唯一的类标记表示这些样本是属于哪一个分类,kNN就是计算每个样本数据到待分类数据的距离,取和待分类数据最近的k个样本数据,那么这个k个样本数据中哪个类别的样本数据占多数,则待分类数据就属于该类别。
基于kNN算法的思想,我们必须找出使用该算法的突破点,本文的目的是使用kNN算法对文本进行分类,那么和之前的文章一样,关键还是项向量的比较问题,之前的文章中的分类代码仅使用的反余弦来匹配项向量,找到关键的“距离”,那么我们可以试想反余弦之后使用kNN的结果如何。
补充上一篇文章中没有详细讲解的反余弦匹配问题:Lucene中有一个term vectors这个东东,它表示该词汇单元在文档中出现的次数,比如说这里有两篇文章,这两篇文章中都有hibernate和spring这两个单词,在第一篇文章中hibernate 出现了10次,spring出现了20次,第二篇文章中hibernate出现15次,spring出现10次,那么对第一篇文章来说有两个项向量,分别是hibernate:10,spring:20,第二篇文章类似,hibernate:15,spring:10。
然后我们就可以在二维空间的x,y组上表示出来,如图:这样看来我们其实是要得到两者之间的夹角,计算两个向量之间夹角的公式为A*B/||A||*||B||。
按照这个原理我们就可以得到新文章和样本文章之间的距离,代码如下,这个份代码在第一篇文章提供的代码下载中。
Java代码public double caculateVectorSpace(Map<String, Integer> articleVectorMap, Map<String, Integer> classVectorMap) {if (articleVectorMap == null || classVectorMap == null) {if (logger.isDebugEnabled()) {logger.debug("itemVectorMap or classVectorMap is null");}return 20;}int dotItem = 0;double denominatorOne = 0;double denominatorTwo = 0;for (Entry<String, Integer> entry : articleVectorMap.entrySet()) {String word = entry.getKey();double categoryWordFreq = 0;double articleWordFreq = 0;if (classVectorMap.containsKey(word)) {categoryWordFreq = classVectorMap.get(word).intValue() / classVectorMap.size();articleWordFreq = entry.getValue().intValue() / articleVectorMap.size();}dotItem += categoryWordFreq * articleWordFreq;denominatorOne += categoryWordFreq * categoryWordFreq;denominatorTwo += articleWordFreq * articleWordFreq;}double denominator = Math.sqrt(denominatorOne) * Math.sqrt(denominatorTwo);double ratio = dotItem / denominator;return Math.acos(ratio);}public double caculateVectorSpace(Map<String, Integer> articleVectorMap, Map<String, Integer> classVectorMap) {if (articleVectorMap == null || classVectorMap == null) {if (logger.isDebugEnabled()) {logger.debug("itemVectorMap or classVectorMap is null");}return 20;}int dotItem = 0;double denominatorOne = 0;double denominatorTwo = 0;for (Entry<String, Integer> entry : articleVectorMap.entrySet()) {String word = entry.getKey();double categoryWordFreq = 0;double articleWordFreq = 0;if (classVectorMap.containsKey(word)) {categoryWordFreq = classVectorMap.get(word).intValue() / classVectorMap.size();articleWordFreq = entry.getValue().intValue() / articleVectorMap.size();}dotItem += categoryWordFreq * articleWordFreq;denominatorOne += categoryWordFreq * categoryWordFreq;denominatorTwo += articleWordFreq * articleWordFreq;}double denominator = Math.sqrt(denominatorOne) * Math.sqrt(denominatorTwo);double ratio = dotItem / denominator;return Math.acos(ratio);}接着根据kNN的原理,我们记录下待分类数据和样本数据的距离,对每一个待分类数据都找出k个距离最小的样本,最后判断这些样本所在的分类,这些样本所在的分类就是该新数据应该所在的分类。
KNN(K近邻法)算法原理
KNN(K近邻法)算法原理⼀、K近邻概述k近邻法(k-nearest neighbor, kNN)是⼀种基本分类与回归⽅法(有监督学习的⼀种),KNN(k-nearest neighbor algorithm)算法的核⼼思想是如果⼀个样本在特征空间中的k(k⼀般不超过20)个最相邻的样本中的⼤多数属于某⼀个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
简单地说,K-近邻算法采⽤测量不同特征值之间的距离⽅法进⾏分类。
通常,在分类任务中可使⽤“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;在回归任务中可使⽤“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;还可基于距离远近进⾏加权平均或加权投票,距离越近的实例权重越⼤。
k近邻法不具有显式的学习过程,事实上,它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进⾏处理K近邻算法的优缺点:优点:精度⾼、对异常值不敏感、⽆数据输⼊假定缺点:计算复杂度⾼、空间复杂度⾼适⽤数据范围:数值型和标称型⼆、K近邻法的三要素距离度量、k值的选择及分类决策规则是k近邻法的三个基本要素。
根据选择的距离度量(如曼哈顿距离或欧⽒距离),可计算测试实例与训练集中的每个实例点的距离,根据k值选择k个最近邻点,最后根据分类决策规则将测试实例分类。
根据欧⽒距离,选择k=4个离测试实例最近的训练实例(红圈处),再根据多数表决的分类决策规则,即这4个实例多数属于“-类”,可推断测试实例为“-类”。
k近邻法1968年由Cover和Hart提出1.距离度量特征空间中的两个实例点的距离是两个实例点相似程度的反映。
K近邻法的特征空间⼀般是n维实数向量空间Rn。
使⽤的距离是欧⽒距离,但也可以是其他距离,如更⼀般的Lp距离或Minkowski距离Minkowski距离(也叫闵⽒距离):当p=1时,得到绝对值距离,也称曼哈顿距离(Manhattan distance),在⼆维空间中可以看出,这种距离是计算两点之间的直⾓边距离,相当于城市中出租汽车沿城市街道拐直⾓前进⽽不能⾛两点连接间的最短距离,绝对值距离的特点是各特征参数以等权参与进来,所以也称等混合距离当p=2时,得到欧⼏⾥德距离(Euclidean distance),就是两点之间的直线距离(以下简称欧⽒距离)。
knn算法的分类规则
knn算法的分类规则摘要:1.KNN算法概述2.KNN算法步骤详解3.KNN算法中的距离度量4.KNN算法的优缺点5.KNN算法的改进版本正文:一、KNN算法概述KNN(k-近邻算法)是一种基于实例的学习(instance-based learning)和懒惰学习(lazy learning)的分类算法。
早在1968年,Cover和Hart就提出了最初的邻近算法。
KNN算法依据实例之间的距离来判断未知实例的类别,具有简单、易于理解、容易实现等优点。
二、KNN算法步骤详解1.选择参数K:设置一个距离阈值,用于判断相邻实例之间的距离。
2.计算未知实例与所有已知实例的距离:采用欧氏距离、余弦值、相关度、曼哈顿距离等度量方法计算未知实例与已知实例之间的距离。
3.选择最近K个已知实例:根据距离阈值,挑选出距离未知实例最近的K 个已知实例。
4.投票分类:根据少数服从多数的原则,将未知实例归类为K个最邻近样本中最多数的类别。
三、KNN算法中的距离度量1.欧氏距离:计算两个实例在欧几里得空间中的直线距离。
2.余弦值:衡量两个向量之间的夹角,用于度量角度差异。
3.相关度:衡量两个实例之间的一致性,用于度量线性关系。
4.曼哈顿距离:计算两个实例在各个坐标轴上距离的绝对值之和。
四、KNN算法的优缺点优点:1.简单、易于理解、容易实现。
2.通过选择合适的K值,具备丢噪音数据的健壮性。
缺点:1.需要大量空间储存所有已知实例。
2.算法复杂度高,需要比较所有已知实例与要分类的实例。
3.当样本分布不平衡时,新的未知实例容易被归类为占主导地位的类别。
五、KNN算法的改进版本1.根据距离加上权重,如:1/d(d为距离)。
2.使用其他距离度量方法,如:余弦相似度、相关度等。
3.调整K值选取策略,以提高分类准确性。
通过以上对KNN算法的详细解析,希望能帮助读者更好地理解并应用这一算法。
knn算法计算过程
knn算法计算过程KNN算法,即K最近邻算法,是一种常用的监督学习算法,用于分类和回归问题。
其核心思想是:一个样本的输出值由其最近的K个邻居的输出值投票产生。
下面详细介绍KNN算法的计算过程:首先,我们需要有一个已标记的数据集,也就是训练集。
每个样本都有一些特征和一个对应的标签。
标签在分类问题中通常是类别,在回归问题中则是连续值。
当有一个新的未标记样本需要预测时,KNN算法就会开始工作。
它会计算新样本与训练集中每个样本之间的距离。
这个距离可以是欧氏距离、曼哈顿距离等,最常用的是欧氏距离。
距离越大,表示两个样本越不相似;距离越小,表示两个样本越相似。
计算完所有距离后,KNN算法会把这些距离从小到大排序,然后选择距离最近的K个样本。
这K个样本就是新样本的“邻居”。
接下来,KNN算法会根据这些邻居的标签来预测新样本的标签。
在分类问题中,通常采用多数投票法,也就是选择出现次数最多的类别作为新样本的类别。
在回归问题中,则可能采用平均值法,也就是把K个邻居的输出值求平均,作为新样本的输出值。
需要注意的是,K值的选择对KNN算法的性能有很大影响。
K值太小,容易受到噪声点的影响;K值太大,则可能会引入过多的不相关样本,使预测结果偏离实际。
因此,在实际应用中,通常需要尝试不同的K值,选择最优的K值。
总的来说,KNN算法的计算过程就是:计算新样本与训练集中每个样本的距离,选择距离最近的K个样本,然后根据这些样本的标签来预测新样本的标签。
这个过程简单直观,但效果却往往出人意料地好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
knn分类算法计算过程
K-近邻(K-Nearest Neighbors,KNN)是一种常用的非参数化
的分类算法。
它的基本思想是通过计算样本间的距离来进行分类。
KNN算法的计算过程如下:
1. 初始化数据集:将训练数据集以及相应的类别标签加载到内存中。
2. 计算距离:对于待分类的样本,计算它与所有训练样本之间的距离。
常用的距离度量方法有欧氏距离、曼哈顿距离等。
3. 选择K值:设置一个K的值,表示取距离最近的K个训练
样本进行分类。
4. 确定邻居:根据计算得到的距离,选择距离最近的K个训
练样本作为待分类样本的邻居。
5. 统计类别:根据邻居的类别标签,对待分类样本进行分类。
可以根据邻居的类别进行投票,或者计算邻居的类别的加权平均值来确定待分类样本的类别。
6. 输出结果:将待分类样本归入到所属的类别中。
需要注意的是,KNN算法中的K值的选择会影响分类的结果。
选取较小的K值可能会导致过拟合,而选择较大的K值可能
会导致欠拟合。
总结起来,KNN算法的计算过程包括初始化数据集、计算距离、选择K值、确定邻居、统计类别和输出结果等步骤。
通
过计算样本间的距离来进行分类。