第(11)章如何选取样本.
第11章回归分析习题解答

B. 是随机变量,且有 y0 N (β0 + β1x0 ,σ 2 ) .
C. 当 β0 , β1 确知时等于 β0 + β1x0 .
D. 等于 βˆ0 + βˆ1x0 .
6. 在回归分析中,检验线性相关显著性常用的三种检验方法,不包含(
A. 相关系数显著性检验法.
B. t 检验法.
; 若 新 保 单 数 x0 = 1000 , 给 出 Y 的 估 计 值 为
yˆ0 = 0.118129 + 0.003585×1000 = 3.703129 .
16. 下表是 16 只公益股票某年的每股帐面价值 x 和当年红利 y ,利用 Excel 的数据分
析功能得到的统计分析结果如下:
方差分析
过 10 周时间,收集了每周加班工作时间的数据和签发的新保单数目, x 为每周签发的新保
单数目,Y 为每周加班工作时间(小时).利用 Excel 的数据分析功能得到统计分析如下表.
Coefficients
标准误差
Intercept X Variable 1
0.118129 0.003585
0.355148 0.000421
15.1
15.1
228.01
228.01
18
15.1
14.5
228.01
210.25
列和
270.1
265
计算可得:
4149.39
3996.14
∑ Syy =
y2 i
−
ny 2
=94.75
∑ Sxx =
x2 i
−
nx 2
=96.39
∑ Sxy = xi yi − nxy = 95.24
抽样技术-课件全-抽样技术-第11章全文

CPS的样本轮换具有如下主要特征
1.在任何一个月内,都有八分之一的住户单位第一次接受 调查,八分之一的住户单位第二次接受调查,如此下去
2.每个月都有新的样本组代替从样本中永久退出的老样本 组
3.每个月都有一个样本组在8个月的闲置后重新接受调查。 重新接受调查的样本组代替了刚刚退出,进入闲置期的 样本组
4.设计保证了每个样本单元在两个年份的4个相同月份中 接受调查
5.在连续的两个月内,有四分之三的样本是相同的;在连 续的两年中,有二分之一的样本是相同的。
劳动力特征
3. 抽样时以州为总体,因而设计也是以州为总体的设 计
4. 样本量由变异系数CV及可靠性要求所决定 5. 在失业率为6%的自定义下,各州对变异系数的要求 在8%—9%之间。这样就能保证进行全国估计的变异系 数控制在1.8%之内
11.2.2第一阶段的抽样
第一阶段的抽样涉及三个方面的工作。这些工 作是:初级抽样单元(PSU)的界定;将初级抽 样单元PSU分层;PSU的抽选
11.4.5 广义方差(Generalized Variance)
广义方差函数GVF用于产生人口总量x估计值的估计方差。 函数形式为
Var( Xˆ ) aX 2 bX 式中,a和b是用最小二乘法得到的估计参数。该模型的原理是假定x的方差可以表示为简 单随机样本的方差与设计效应(deff)的乘积。设计效应deff是指某一复杂抽样设计相对于
第11章 设计与方法-美国CPS案例
美国人口现状调查(Current Population Survey,简称CPS)被认为是全国性大规模居 民住户抽样调查的典范。
第十一章 t 检验

H0: μ=μ0, 即该山区成年男子的平均脉搏数与一般成年男
子脉搏 数相等 H1: μ>μ0, 即该山区成年男子的平均脉搏数高于一般成年 男子脉 搏数 单侧 α=0.05
(2) 选定检验方法,计算检验统计量t值
X 0 74.2 72 t 1.833 S 6 n 25
v n 1 25 1 24 t0.05 24 1.7109
单位:千克
94.5
101
110
103.5
97
88.5
96.5
101
104
116.5
85
89.5
101.5
96
86
80.5
87
93.5
93
102
首先进行假设:H0 :μ1 - μ2 ≤ 8.5
H1 :μ1 - μ2 > 8.5
即平均体重减少不足 8.5千克
即平均体重减少超过 8.5千克
然后计算参加前后体重变化差值,见下表:
(3) 判断结果 t=1.833 > t0.05(24)=1.7109, 拒绝H0,接受H1,差异有统计学意义。 可认为该山区健康成年男子脉搏数高于 一般成年男子脉搏数。
两配对样本 t 检验
配对样本:是指一个样本中的数据与另一个样本中的数据相对应的两 个样本。 例如,医生对药物治疗效果进行检验时,将病情相似的病人分为两组, 其中一组按时服用药物,另一组则不服用药物;我们将一个班级的同 学(同质性较强)随机分为两组,一组采用新教案授课,另一组按原 教案上课,最后通过比较分析新教案是否有利于提高学生成绩。
取 α= 0.05 。
首先进行假设:H0 :μ1 = μ2
H1 : μ 1 ≠ μ 2
14第十一章修匀法概述

n
n
ar[c0 c1r c2r 2 c3r3 ] x ar[c1 2rc2 3r 2c3 ]
n
n
n
n
x2 ar[c2 3rc3] x3c3 ar
19
n
n
误差分析
如无果偏待估估计参(U数E),tx 则的在估再计生量性U条x ,件是下,txV的x
也估是计量t x
的UE,如何比较估计量
第二步:修匀。我们着手初始数据的系统修订 工作,其目标是产生关于那个未知的,基死亡 模型的一个代表。它与已给的初始估计相比要
好一些。应该注意到,经过一次修匀,死亡数 据将被改变,这可适当地反映我们模型的这种 期望改进。在我们的精算方向中,把修匀看作 一种尝试,去得到通用的有效的死亡率的最佳 代表。
如Whittaker修匀。修匀表达式显含初始
估计值
的u函x 数。
,u而x 不是x,修匀算子是{
}
第二种:参数修匀。
取参数的“最佳”估计值来获得
修匀值。修匀算子是x的函数。
11
作业:p.276 7
12
第12章 表格数据修匀
本章内容:介绍几种常见的表格 数据修匀方法
0.30.2 0.70.5 0.41
3
修匀的定义
定义:一种利用初始估计,结合先验观 点修正初始估计值的数学方法。
在精算实务中的重要应用:编制生命表 (生存模型),根据这个模型计算保费 值。
4
建模工作的第一项任务:通过试验研究产生一 个关于某些特定年龄的死亡率(或概率)序列。 这些死亡率是基于某个观察群休的试验而得到 的,所以常被称为观察数据。
16
对称M-W-A公式中系数的确定
在§11.1中我们提到修匀的目的是减小误差,
第11章卡方检验(0429修改)
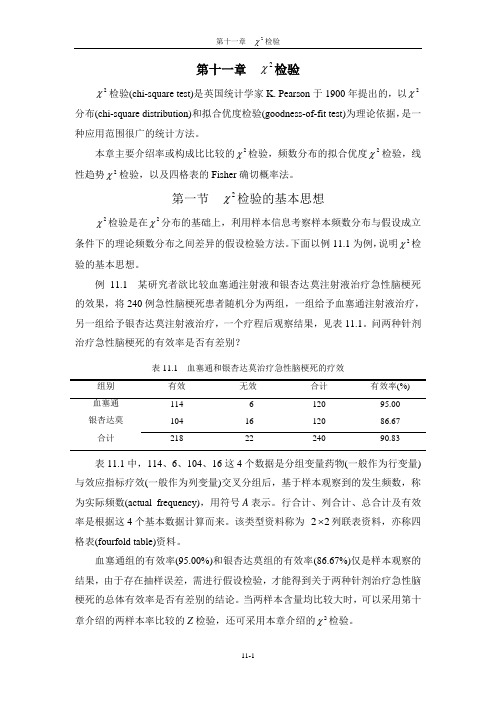
第十一章2χ检验2χ检验(chi-square test)是英国统计学家K. Pearson于1900年提出的,以2χ分布(chi-square distribution)和拟合优度检验(goodness-of-fit test)为理论依据,是一种应用范围很广的统计方法。
本章主要介绍率或构成比比较的2χ检验,频数分布的拟合优度2χ检验,线χ检验,以及四格表的Fisher确切概率法。
性趋势2第一节2χ检验的基本思想2χ检验是在2χ分布的基础上,利用样本信息考察样本频数分布与假设成立条件下的理论频数分布之间差异的假设检验方法。
下面以例11.1为例,说明2χ检验的基本思想。
例11.1 某研究者欲比较血塞通注射液和银杏达莫注射液治疗急性脑梗死的效果,将240例急性脑梗死患者随机分为两组,一组给予血塞通注射液治疗,另一组给予银杏达莫注射液治疗,一个疗程后观察结果,见表11.1。
问两种针剂治疗急性脑梗死的有效率是否有差别?表11.1 血塞通和银杏达莫治疗急性脑梗死的疗效血塞通114 6 120 95.00银杏达莫104 16 120 86.67合计218 22 240 90.83表11.1中,114、6、104、16这4个数据是分组变量药物(一般作为行变量)与效应指标疗效(一般作为列变量)交叉分组后,基于样本观察到的发生频数,称为实际频数(actual frequency),用符号A表示。
行合计、列合计、总合计及有效率是根据这4个基本数据计算而来。
该类型资料称为22⨯列联表资料,亦称四格表(fourfold table)资料。
血塞通组的有效率(95.00%)和银杏达莫组的有效率(86.67%)仅是样本观察的结果,由于存在抽样误差,需进行假设检验,才能得到关于两种针剂治疗急性脑梗死的总体有效率是否有差别的结论。
当两样本含量均比较大时,可以采用第十章介绍的两样本率比较的Z检验,还可采用本章介绍的2χ检验。
一、对总体建立假设例11.1的无效假设为012:H ππ=,即两种针剂治疗急性脑梗死的有效率相同。
如何进行有效的调查研究与样本选择

如何进行有效的调查研究与样本选择调查研究是社会科学中广泛使用的一种研究方法,通过收集、分析和解释数据,来获取对特定问题的深入理解。
而一个有效的调查研究必须依赖于合适的样本选择和严谨的调查方法。
本文将介绍如何进行有效的调查研究与样本选择。
首先,样本选择是调查研究设计中至关重要的一步。
一个好的样本应当具有代表性,即能够准确反映目标群体的特征和态度。
为了实现代表性,我们可以采用随机抽样的方法。
随机抽样是指每个人都有相等机会被选中的抽样方法,可以减小样本的偏倚性。
常用的随机抽样方法有简单随机抽样、系统抽样、分层抽样等。
选择适当的抽样方法取决于研究的具体目的和资源预算。
其次,调查研究中收集数据的方法也需慎重选择。
调查方法可以是面对面访谈、电话访谈、邮寄调查或在线调查等。
不同的调查方法适用于不同的研究对象和研究目的。
面对面访谈有利于获取详细和全面的信息,但成本较高且可能引起被访者不真实回答的问题。
电话访谈则成本相对较低,但可能受到抽样偏差和拒绝参与的限制。
邮寄调查对于大规模样本的研究有优势,但需要注意回收率较低的问题。
在线调查则成本较低且方便参与者,但仍面临抽样偏差和样本不够代表性的问题。
根据研究的具体需求和资源条件,我们需要综合考虑选择合适的调查方法。
在实施调查过程中,确保数据的准确性和可靠性是至关重要的。
一些常见的数据收集问题包括问卷设计、访谈技巧和数据录入。
问卷设计时应注意问题的准确性、明确性和序列性,避免提问歧义或导致主观性答案的问题。
访谈人员应接受专业训练以获得高质量的数据。
数据录入过程中应注意对数据进行验证和清理,以确保数据的准确性和一致性。
最后,数据分析是一个关键的环节。
根据研究问题的性质和调查方法的特点,我们可以采用不同的数据分析方法。
对于定性分析,可以通过编码和归纳的方式对数据进行分析。
对于定量分析,我们可以使用统计软件进行描述性统计和推论统计分析。
需要注意的是,数据分析的结果需要客观、准确地反映研究问题,避免主观偏见和不恰当的解释。
卫生统计学第十一章统计设计

做答人数:0
做对人数:0
所占比例: 0
题号: 3 本题分数: 1.7
下列说法正确的是
A. 因抽样误差随抽样样本含量的增大而减小,所以在抽样研究中总是考虑样本含量越大越好
做答人数:0
做对人数:0
所占比例: 0
题号: 2 本题分数: 1.7
实验设计的四原则是
A. 收集、整理、分析、结论
B. 齐同、对照、重复、随机
C. 设计、操作、计算、推断
D. 对照、随机、操作、归纳
E. 对照、随机、操作、汇总
正确答案: B
D. 分组原则、随机原则、重复原则、均衡原则
E. 对照原则、随机原则、分组原则、均衡原则
正确答案: A
做答人数:0
做对人数:0
所占比例: 0
题号: 12 本题分数: 1.7
将实验和对照在同一受试对象身上进行的对照称为
A. 空白对照
B. 实验对照
做答人数:0
做对人数:0
所占比例: 0
题号: 14 本题分数: 1.7
将受试对象完全随机分配到各个处理组中进行实验观察或分别从不同总体中随机抽样进行对比观察,此种设计为
A. 随机区间设计
B. 完全随机设计
C. 配对设计
D. 配伍组设计
E. 以上均不对
做答人数:0
做对人数:0
所占比例: 0
题号: 7 本题分数: 1.7
抽样调查必须遵循
工作总结医学研究中的样本收集与处理

工作总结医学研究中的样本收集与处理在医学研究中,样本的收集与处理是非常重要的环节。
它涉及到研究结果的准确性和可靠性。
本文将从样本收集的主要步骤、样本处理的方法以及注意事项等方面进行总结。
一、样本收集1. 研究对象的选择在进行医学研究时,首先需要明确研究对象。
根据研究的目的和假设,选择合适的研究对象,如人体组织、血液、尿液、细胞等。
同时,要确定样本的数量和质量要求。
2. 规范化的操作步骤在样本收集过程中,需要严格按照规范化的操作步骤进行。
这包括消毒、穿戴无菌手套和口罩,避免污染样本。
3. 采集合适的样本量样本的数量要根据研究的需求和统计学原理进行确定。
过少的样本容易导致研究结果不够准确,而过多的样本则会增加工作量。
在样本采集过程中,要确保获得足够的样本量。
4. 样本记录和标识在收集样本的同时,要记录详细的信息,如样本编号、采集时间、采集者等。
同时,每个样本都需要进行标识,以便后续的处理与分析。
二、样本处理1. 样本保存与储存在医学研究中,样本的保存非常重要。
不同的样本要采用不同的保存方式,如低温冷冻、冷藏、干燥等。
在进行样本储存时,要确保样本的完整性和稳定性。
2. 样本预处理有时,样本需要经过预处理才能进行进一步的分析。
例如,血液样本可能需要离心来分离血清或血细胞。
在进行样本预处理时,要确保操作准确,避免对样本造成不必要的损伤。
3. 数据采集与分析样本处理后,需要进行数据采集与分析。
这包括对样本的性质、成分、浓度等进行测量和统计。
根据需要,可以采用各种各样的实验技术和仪器来获取所需数据。
三、注意事项1. 符合伦理要求在进行医学研究时,样本的收集和处理要符合伦理要求,尊重研究对象的权益。
研究项目需经过伦理委员会的审核和批准。
2. 严格控制实验条件样本的收集与处理过程中,实验条件的严密控制是确保结果准确的关键。
如操作环境的清洁、温度的控制、时间的准确记录等。
3. 重复实验与验证结果为了确保结果的可靠性,对于重要的实验结果,需进行重复实验与验证。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(二) 《文学摘要》的厄运
在1936年美国总统选举中,由《文学摘要 》杂志组织了一项民意调查,这项民意调查动 用了大量的人力物力进行调查。 在调查的基础上,该杂志预测共和党候选 人阿尔夫•伦敦将击败在任总统富兰克林•罗斯 福,这个预测准不准呢?
阿尔夫•伦敦 预测结果 55%
富兰克林•罗斯福 41%
沃尔德告诉大家,从数学家的眼光来看,这 张图明显不符合概率分布的规律,而明显违反规 律的地方往往就是问题的关键。 飞行员最终明白了数学家沃尔德这套做法的 意义。如果飞行员座舱中弹,飞行员就完了;如 果飞机尾翼中弹,飞机失去平衡就会坠落—这两 处中弹,轰炸机多半就会掉下来了,难怪顺利返 航的轰炸机只有这两处几乎没有弹孔。 结论很简单,只需给这两个部位焊上防弹钢 板就可以了,一个两难的难题就这样解决了。
2、判断抽样
判断抽样:是按照调研设计者的主观判断选取调 查单位组成样本的一种抽样方法。应用前提是, 调研设计的必须以对调查总体的有关特征相当了 解,或者可以依靠专家判断来决定样本。 在判断抽样中,样本单位的选取通常分为两种情 况: 第一种情况是,选择最能代表普遍情况的调查对 象,即选取“多数型”、或“平均型”的样本作 为调查对象。 第二种情况是,选择那些异乎寻常的个案,目的 是调查造成异常的原因。
分层抽样和整群抽样的不同之处
操作的群体不同,分层抽样操作的是分层群体 ,而整群抽样操作的是子群体; 适用的总体不同,分层抽样适用于容易按属性 差异进行群体划分的总体,而整群抽样适用于 不容易按属性差异但容易按可见标志进行群体 划分的总体。
非概率抽样
1、便利抽样 2、判断抽样 3、推荐抽样 4、配额抽样
第11章
如何选取样本
兔年春晚调查
1、您今年收看了中央电视台春节联欢晚会了吗? A、看了 B、没看 2、如果你收看了,请问您对兔年春晚的评价如何 ? A、满意 B、一般 C、不满意
春晚满意度调查数据
央视市场研究股份有限公司的调查结果是:在全国 收看电视的家庭中,有93.88%的家庭收看了中央电视台 春节联欢晚会,有 81.92%的受访者认为今年中央电视 台春节联欢晚会办得好。 腾讯网对春晚满意度调查结果显示:有38.47%的网 友给春晚打出了60-80分,而有43%的人认为今年春晚表 现不及格。 在1万多人参与的微博小秘书发起的调查中,对兔年 春晚表示“满意”的只有6%,认为“一般”的有25%, 还有59%的人表示“失望”,10%的人“没看”。
上面两个案例都涉及同一个重要问题—抽 样问题。 但是,处理方式不同,导致两种完全不同 的结果—一个有效地解决了问题,另一个则被 问题所拖累,破产倒闭了。
样本和抽样的基本概念
1、总体 2、普查 3、样本和样本单位 4、抽样框和抽样框误差 5、抽样误差
什么是抽样?
抽样:是根据一定的规则和程序,从研究总体中抽取其 中的一部分样本来代表总体的过程。
1、便利抽样
便利抽样:就是依据方便原则抽取样本,对抽 样单位的选择主要是由调查人员完成,通常被 访者由于碰巧在适当的时间出现在适当的地点 而被选中。 例如: “街头拦人法”是在街上或路口任意找某个行 人,将其作为被调查者进行调查。 利用客户的名单进行调查 将问卷登在宣传媒体上,被调查者自填后寄回
概率抽样
1、简单随机抽样 2、系统抽样 3、整群抽样 4、分层抽样
1、简单随机抽样
简单随机抽样:在简单随机抽样中,总体中所 有的成员被选为样本的概率是相等的。 简单随机抽样即完全按照随机的原则来抽取样 本。 最常见的有抽签法和随机数表法。
简单随机抽样的优点: 最简单、最典型的概率抽样技术,易于理解; 抽样框不需要其他(辅助)信息就能进行抽样; 样本结果可以推论到目标总体上,大多数统计 推论方法都假定数据是由简单随机抽样方法收 集的。
排列调查总体单位时所依的标准有两种: 一种是按与调查项目无关的标志排队。例如: 在住户调查时,选择住户可以按住户所在街区 的门牌号码排队,然后每隔若干个号码抽选一 户进行调查; 另一种是按与调查项目有关标志排队。例如: 住户调查时,可按住户平均月收入排队,再进 行抽选。
总体单位的排序决定着系统抽样的代表性,并 决定系统抽样调查结果的统计效率,分三种情 况说明: 如果排序与要研究的特征无关,则结果与简单 随机抽样相似; 当排序与要研究的特征有关时,系统抽样能增 加样本的代表性。 若排序呈现循环形式,抽样间距又与循环周期 相同时,系统抽样会降低样本的代表性。
ቤተ መጻሕፍቲ ባይዱ
分层抽样的必要性
设计抽样方法时,最核心的问题是考虑如何使 抽取的具有代表性,为此在设计抽样方法时, 我们应考虑如何利用已有的总体。 例如:调查高一学生平均身高 由经验知,男同学一般要比女同学高,这时就 要采用分层抽样,因为简单随机抽样或系统抽 样都有可能产生部分是男生(或女生)或全部 是男生(或女生)的样本,这样的样本是不能 代表总体的。
为何抽样
首先,从成本的角度看,抽样比普查更优越; 其次,专业调研公司或调研人员不可能分析处 理由普查产生的大量数据。
两种基本的抽样方法
概率抽样:样本设计采取随机的办法,排除研 究人员主观因素的干扰,使样本总体中的每一 个成员都有一个事先确定好抽中概率。 非概率抽样:样本设计依赖于研究人员的个人 判断而非随机原则选择样本个体,事先并不确 定每个样本单位被抽中的概率。
美国空军请来数学家亚伯拉罕· 沃尔德。 数学家沃尔德的方法十分简单。他把统计表 发给地勤技师,让他们把飞机上中弹弹孔的位置 报上来。他自己铺开一张大纸,画出轰炸机的轮 廓,再把那些小窟窿一个个地填上去。 画完后大家一看,飞机浑身上下都是窟窿, 只有飞行员座舱和尾翼两个地方几乎是空白。 为什么是这样? 防弹钢板应该焊在哪里呢?
分层抽样的适用条件: 分层抽样比较适用于总体由差异明显的几 个层次组成且层内差异较小进行的抽样。
分层抽样和整群抽样的相同之处
都是先对总体中的群体再对个体进行操作; 都不是完全随机地抽取样本,都涉及一定的规则 :分层随机抽样涉及的规则是分层群体之间属性 的差异,而整群随机抽样涉及的规则是子群体之 间的相似; 都能提高随机抽样的效率和改善随机抽样的结果 。
整群抽样以群体为单位进行抽选,抽选单位 比较集中,明显得影响了样本分布的均衡性。 因此,整群抽样与其他抽样比较,在抽样单 位数目相同的条件下抽差误差较大,代表性较低 ,在抽样调查实践中,采用整群抽样技术一般都 要比其他抽样技术抽选更多的单位,以降低抽样 误差,提高抽样结果的准确程度。 当然,整群抽样的可靠程度主要还是取决于 群与群之间的差异的大小,当各群间差异较小时 ,整群抽样的调查结果就越准确。 因此,在大规模的市场调查中,当群体内各 单位间的误差较大,而各群之间的差异较小时, 最适宜采用整群抽样方式。
等比例分层抽样
等比例分层抽样是按各层中的个体数量占 总体数量的比例分配各层的样本数量。 这种方法简单易行,分配合理,计算方便 ,适用于各类型之间的个数差异不大的分类抽 样调查。
不等比例分层抽样
不等比例分层抽样不提按照各层中个体数 占总体数的比例分配样本个体,而是根据其他 因素,调整各层的样本数。 不等比例分层抽样适用于各类总体的个数 相差很大的情况。
简单随机抽样的局限性: (1)采用简单随机抽样,一般必须对总体各单 位加以编号,而实际所需调查总体往往是十分 庞大的,单位非常多,逐一编号几乎是不可能 的; (2)在总体单位数不清楚的情况下,无法采用 简单随机抽样;
(3)当总体各单位差异较大时,采用简单随 机抽样抽出的样本可能会集中于某类单位,不 能做到在各种类型的单位中较为均匀分布,其 样本的代表性就比较差; (4)采用简单随机抽样抽出的样本分布较为 分散,实地调查消耗的人力、物力、费用较大 ;
【教学目标】
熟悉抽样设计的术语 了解概率抽样与非概率抽样方法的区别 了解如何使用四种概率抽样 了解如何使用四种非概率抽样 掌握不同类型抽样技能 能够制定一份抽样计划
开篇案例:两种抽样两种命运
(一)防弹钢板应焊在哪里? 第二次世界大战后期,美军对德国和日本 展开了大规模战略轰炸,每天都有成千架轰炸 机呼啸而去,返回时则往往伤亡惨重。 美国空军对此十分头痛:如果要降低损失 ,就要往飞机上焊防弹钢板;但是飞机焊上防 弹钢板后,速度、航程、载弹量都会受影响, 同样也会影响轰炸机安全返航。 这是一个两难选择,怎么办呢?
整群抽样的适用条件: 整群抽样比较适用于适用群体内各单位间 的误差较大,而各群之间的差异较小的情况。 另一种适用情况:工业抽样 例如:对工业产品进行质量调查时,每隔五个 小时,抽取一个小时的产品进行检查。
4、分层抽样
分层抽样:指将调查总体中的所有单位按照一 定的属性或特征分成不相重叠的若干层次(或 类),然后在每一个层次(或类)中进行简单随 机抽样或等距抽样。 抽样程序: 1)确定分层变量 2)分层 3)确定各层的样本量 4)在各层内部进行抽样
有人会问,81.92%的受访者满意和43%的 人认为不及格,我们相信谁? 应该说,我们都没有绝对相信的理由,因 为我们不能确知调查的科学性。例如,由央视 自己调查自己的成绩,本身就缺乏公信力;其 次,调查方法我们也不知道,包括样本如何选 择、问题如何设置都会直接影响到调查结果。 因此,我们与其相信调查数据,还如靠自 己的判断。
实际结果
37%
61%
这项全国瞩目的民意调查得出了完全错误 的结论,《文学摘要》也因此关门倒闭。 为什么会出现这样严重的错误?
一个原因是抽样框架主要是根据电话号码 簿和汽车登记册建立的。 在1936年,拥有汽车或电话的这些人显然 是富裕的美国人,这些人大多是共和党的坚定 支持者,而大多数投票选民既不拥有电话,也 不拥有汽车。 另一个问题可能是由于无回答引起的偏倚 ——总共寄出了一千多万份的问卷,但是返回 的问卷不足25%。