cure聚类 中心点计算公式
数据分析笔试题目及答案解析

数据分析笔试题目及答案解析数据分析笔试题目及答案解析——第1题——1. 从含有N个元素的总体中抽取n个元素作为样本,使得总体中的每一个元素都有相同的机会(概率)被抽中,这样的抽样方式称为?A. 简单随机抽样B. 分层抽样C. 系统抽样D. 整群抽样答案:A——第2题——2. 一组数据,均值中位数众数,则这组数据A. 左偏B. 右偏C. 钟形D. 对称答案:B「题目解析」分布形状由众数决定,均值大于众数的化,说明峰值在左边,尾巴在右边,所以右偏。
偏态是看尾巴在哪边。
——第3题——3. 对一个特定情形的估计来说,置信水平越低,所对应的置信区间?A. 越小B. 越大C. 不变D. 无法判断答案:A「题目解析」根据公式,Z减小,置信区间减小。
——第4题——4.关于logistic回归算法,以下说法不正确的是?A. logistic回归是当前业界比较常用的算法,用于估计某种事物的可能性B. logistic回归的目标变量可以是离散变量也可以是连续变量C. logistic回归的结果并非数学定义中的概率值D. logistic回归的自变量可以是离散变量也可以是连续变量答案:B「题目解析」逻辑回归是二分类的分类模型,故目标变量是离散变量,B错;logisitc回归的结果为“可能性”,并非数学定义中的概率值,不可以直接当做概率值来用,C对。
——第5题——5.下列关于正态分布,不正确的是?A. 正态分布具有集中性和对称性B. 期望是正态分布的位置参数,描述正态分布的集中趋势位置C. 正态分布是期望为0,标准差为1的分布D. 正态分布的期望、中位数、众数相同答案:C「题目解析」N(0,1)是标准正态分布。
——第6题——6. 以下关于关系的叙述中,正确的是?A. 表中某一列的数据类型可以同时是字符串,也可以是数字B. 关系是一个由行与列组成的、能够表达数据及数据之间联系的二维表C. 表中某一列的值可以取空值null,所谓空值是指安全可靠或零D. 表中必须有一列作为主关键字,用来惟一标识一行E. 以上答案都不对答案:B「题目解析」B. 关系是一张二维表,表的每一行对应一个元组,每一列对应一个域,由于域可以相同,所以必须对每列起一个名字,来加以区分,这个名字称为属性。
数据挖掘第七章__聚类分析

Chapter 7. 聚类分析
• 聚类分析概述 • 聚类分析的数据类型
• 主要聚类分析方法分类
划分方法(Partitioning Methods)
分层方法
基于密度的方法
基于网格的方法
基于模型(Model-Based)的聚类方法
火龙果 整理
• 差异度矩阵
– (one mode)
0 d(2,1) 0 d(3,1 ) d ( 3, 2 ) : : d ( n,1) d ( n,2)
0 : ... ... 0
火龙果 整理
1.数据矩阵 数据矩阵是一个对象—属性结构。它是n个对象组
6.3 聚类分析中的数据类型
假设一个要进行聚类分析的数据集包含 n
个对象,这些对象可以是人、房屋、文件等。
聚类算法通常都采用以下两种数据结构:
火龙果 整理
两种数据结构
• 数据矩阵
– (two modes)
x11 ... x i1 ... x n1 ... x1f ... ... ... xif ... ... ... xnf ... x1p ... ... ... xip ... ... ... xnp
• 保险: 对购买了汽车保险的客户,标识那些有较高平均赔偿 成本的客户;
• 城市规划: 根据类型、价格、地理位置等来划分不同类型的 住宅; • 地震研究: 根据地质断层的特点把已观察到的地震中心分成 不同的类;
火龙果 整理
生物方面,聚类分析可以用来对动物或植物分类,或 根据基因功能对其进行分类以获得对人群中所固有的
(6.2)
火龙果 整理
空间聚类公式

空间聚类公式
空间聚类公式,又称多距离空间聚类分析,是点格局分析的常用方法。
它是按照一定半径距离的搜索圆范围来统计点数量,用于衡量空间格局中点的集聚程度。
计算公式为:在随机分布状态下,L(t)(观测值)的期望值为0,L(t)与距离t的关系图可以验证依赖于尺度t的点的空间分布格局。
如果t观测值大于t预期值(微分值),则与该距离(分析尺度)的随机分布相比,该分布的聚类程度更高;如果t观测值小于t预期值,则与该距离的随机分布相比,该分布的离散程度更高。
聚集度分析计算公式有哪些

聚集度分析计算公式有哪些在社会科学研究中,聚集度分析是一种常用的研究方法,用于衡量一个群体内部成员之间的联系程度。
通过聚集度分析,我们可以了解到群体内部成员之间的联系强度,从而更好地理解群体的结构和特点。
在本文中,我们将介绍一些常用的聚集度分析计算公式,帮助读者更好地理解这一研究方法。
1. 点度中心性。
点度中心性是一种用于衡量网络中节点重要性的指标,通常用于衡量一个节点在网络中的连接数量。
点度中心性的计算公式如下:\[C_i = \frac{k_i}{n-1}\]其中,\(C_i\)表示节点i的点度中心性,\(k_i\)表示节点i的连接数量,\(n\)表示网络中节点的总数。
通过计算每个节点的点度中心性,我们可以了解到网络中各个节点的重要性,从而更好地理解网络的结构和特点。
2. 接近中心性。
接近中心性是一种用于衡量网络中节点之间距离的指标,通常用于衡量一个节点与其他节点之间的接近程度。
接近中心性的计算公式如下:\[C_i = \frac{1}{\sum_{j=1}^{n} d_{ij}}\]其中,\(C_i\)表示节点i的接近中心性,\(d_{ij}\)表示节点i与节点j之间的距离。
通过计算每个节点的接近中心性,我们可以了解到网络中各个节点之间的接近程度,从而更好地理解网络的结构和特点。
3. 中介中心性。
中介中心性是一种用于衡量网络中节点之间信息传递的指标,通常用于衡量一个节点在信息传递中的重要性。
中介中心性的计算公式如下:\[C_i = \sum_{j\neq i\neq k} \frac{\sigma_{jk}(i)}{\sigma_{jk}}\]其中,\(C_i\)表示节点i的中介中心性,\(\sigma_{jk}(i)\)表示节点i在节点j与节点k之间的最短路径中出现的次数,\(\sigma_{jk}\)表示节点j与节点k之间的最短路径数量。
通过计算每个节点的中介中心性,我们可以了解到网络中各个节点在信息传递中的重要性,从而更好地理解网络的结构和特点。
聚类算法实验
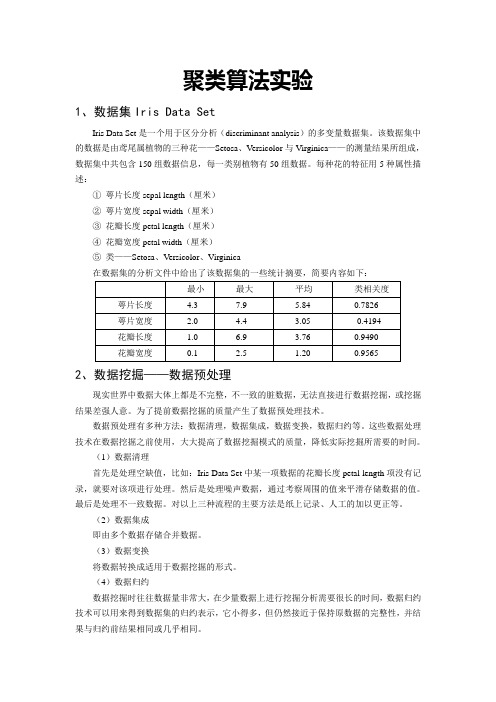
聚类算法实验1、数据集Iris Data SetIris Data Set是一个用于区分分析(discriminant analysis)的多变量数据集。
该数据集中的数据是由鸢尾属植物的三种花——Setosa、Versicolor与Virginica——的测量结果所组成,数据集中共包含150组数据信息,每一类别植物有50组数据。
每种花的特征用5种属性描述:①萼片长度sepal length(厘米)②萼片宽度sepal width(厘米)③花瓣长度petal length(厘米)④花瓣宽度petal width(厘米)⑤类——Setosa、Versicolor、Virginica在数据集的分析文件中给出了该数据集的一些统计摘要,简要内容如下:2、数据挖掘——数据预处理现实世界中数据大体上都是不完整,不一致的脏数据,无法直接进行数据挖掘,或挖掘结果差强人意。
为了提前数据挖掘的质量产生了数据预处理技术。
数据预处理有多种方法:数据清理,数据集成,数据变换,数据归约等。
这些数据处理技术在数据挖掘之前使用,大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间。
(1)数据清理首先是处理空缺值,比如:Iris Data Set中某一项数据的花瓣长度petal length项没有记录,就要对该项进行处理。
然后是处理噪声数据,通过考察周围的值来平滑存储数据的值。
最后是处理不一致数据。
对以上三种流程的主要方法是纸上记录、人工的加以更正等。
(2)数据集成即由多个数据存储合并数据。
(3)数据变换将数据转换成适用于数据挖掘的形式。
(4)数据归约数据挖掘时往往数据量非常大,在少量数据上进行挖掘分析需要很长的时间,数据归约技术可以用来得到数据集的归约表示,它小得多,但仍然接近于保持原数据的完整性,并结果与归约前结果相同或几乎相同。
具体到本实验中,由于Iris Data Set提供的信息比较完善,每个数据对象都由4维的数据和1维的类型组成,这五个数据之间用了“,”隔开没有空缺值、噪声数据等。
cure聚类 中心点计算公式

cure聚类中心点计算公式摘要:1.引言2.CURE聚类简介3.中心点计算公式4.公式解释与分析5.实例演示6.结论正文:【提纲】1.引言在数据挖掘和机器学习中,聚类算法是一种重要的分析方法。
CURE (Clustering Using Representatives Uniformly Extracted from Clusters)聚类算法是一种基于代表点的聚类方法,具有较好的聚类性能。
本文将详细介绍CURE聚类算法及其中心点计算公式。
2.CURE聚类简介CURE聚类算法是一种基于代表点的聚类方法。
它在聚类过程中,通过提取每个簇的代表点,使得代表点能够均匀地覆盖整个簇。
CURE算法具有较好的聚类性能,尤其在处理大规模数据集和高维数据时表现出较好的稳定性。
3.中心点计算公式在CURE聚类算法中,中心点的计算公式如下:中心点= ( representatives_sum / representative_count )其中,representatives_sum表示代表点的属性值之和,representative_count表示代表点的数量。
4.公式解释与分析该公式通过计算代表点的属性值之和与代表点数量的比值,得到中心点的属性值。
这样做可以保证中心点能够反映整个簇的平均属性值,同时避免受到极端值的影响。
5.实例演示以下是一个简单的实例来说明CURE聚类算法中中心点的计算过程:假设有一个包含5个数据点的簇,它们的属性值分别为(1,2),(3,4),(5,6),(7,8),(9,10)。
首先,计算代表点的属性值之和:representatives_sum = (1+3+5+7+9) * 2 + (2+4+6+8+10) * 2 = 120 接着,计算代表点的数量:representative_count = 5最后,根据公式计算中心点的属性值:中心点= 120 / 5 = (1+3+5+7+9) / 5 = 56.结论CURE聚类算法通过提取代表点并计算其中心点,实现了对数据集的有效聚类。
基于CURE聚类的可疑金融交易信息搜索研究

基于C R 聚类的可疑金融交易信息搜索研究 UE
R s a c n S s iiu i a ca r n a to n o ma in S a c sd o ee rh o u p co sF n n ilT a s cin I fr t e rh Bae n CURE Alo ih o g rt m
*
张成 虎 赵 小 虎
( 安交 通 大 学 经 济 与 金 融 学 院 西 西安 706) 10 1
摘 要 提 出 了一 种 改进 的 C R 聚类 算 法 , 于搜 索具 有 异 常 交 易行 为 的 可疑 客 户 , 对 此 聚 类 算 法进 行 了 实验 , U E 用 并 验 证 了该 方 法 的 可行 性 与有 效 性 。
的数 据 挖 掘 技 术 , 常 用 于 信 息 的探 索 性 分 析 , 通 过 无 指 通 它 导学 习将 数 据 划 分 成 相 交 或 不 相 交 的 群 组 , 于 簇 (l tr 由 c se) u 不是 预 先 定 义 的 , 类 结 果 具 有 不 确 定 性 , 助 领 域 专 家 对 聚 借 所 产 生 的 簇 的 含 义 进 行 解 释 , 为 后 续 数 据 分 析 提 供 有 价 可
经济的核心 , 交易规模 日益 庞大 , 易手段 不断翻新 , 易 其 交 交
处理 的 自动 化 、 子 化 水 平 逐 步 提 高 。 现 代 金 融 产 品在 为参 电 与者 提 供 便 利 的 同时 , 为 洗 钱 犯 罪 带 来 了 可 乘 之 机 。面 对 也 海 量 的 金 融 交 易 记 录 , 统 的 手 工 核 查 方 式 和 简 单 的 数 据 传
值 的线 索。基 于聚类分 析的这一特点 , 在可 疑金融交易信 息
聚类分析(二)——K中心点算法(k-mediods)

聚类分析(⼆)——K中⼼点算法(k-mediods)K中⼼点算法(K-medoids)前⾯介绍了k-means算法,并列举了该算法的缺点。
⽽K中⼼点算法(K-medoids)正好能解决k-means算法中的 “噪声”敏感这个问题。
如何解决的呢?⾸先,我们得介绍下k-means算法为什么会对“噪声”敏感。
还记得K-means寻找质点的过程吗?对某类簇中所有的样本点维度求平均值,即获得该类簇质点的维度。
当聚类的样本点中有“噪声”(离群点)时,在计算类簇质点的过程中会受到噪声异常维度的⼲扰,造成所得质点和实际质点位置偏差过⼤,从⽽使类簇发⽣“畸变”。
Eg: 类簇C1中已经包含点A(1,1)、B(2,2)、 C(1,2)、 D(2,1),假设N(100,100)为异常点,当它纳⼊类簇C1时,计算质点Centroid((1+2+1+2+100)/5,(1+2+2+1+100)/5)=centroid(21,21),此时可能造成了类簇C1质点的偏移,在下⼀轮迭代重新划分样本点的时候,将⼤量不属于类簇C1的样本点纳⼊,因此得到不准确的聚类结果。
为了解决该问题,K中⼼点算法(K-medoids)提出了新的质点选取⽅式,⽽不是简单像k-means算法采⽤均值计算法。
在K中⼼点算法中,每次迭代后的质点都是从聚类的样本点中选取,⽽选取的标准就是当该样本点成为新的质点后能提⾼类簇的聚类质量,使得类簇更紧凑。
该算法使⽤绝对误差标准来定义⼀个类簇的紧凑程度。
如果某样本点成为质点后,绝对误差能⼩于原质点所造成的绝对误差,那么K中⼼点算法认为该样本点是可以取代原质点的,在⼀次迭代重计算类簇质点的时候,我们选择绝对误差最⼩的那个样本点成为新的质点。
Eg:样本点A –>E1=10样本点B –>E2=11样本点C –>E3=12原质点O–>E4=13,那我们选举A作为类簇的新质点。
与K-means算法⼀样,K-medoids也是采⽤欧⼏⾥得距离来衡量某个样本点到底是属于哪个类簇。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
cure聚类中心点计算公式
(原创版)
目录
1.概述 CURE 聚类算法
2.介绍 CURE 聚类的中心点计算公式
3.总结 CURE 聚类的优点和应用场景
正文
CURE(Cluster Ensembles) 聚类算法是一种基于集成学习的聚类方法,通过结合多个聚类结果来得到最终的聚类结果。
CURE 聚类算法的主要思想是首先对数据进行多个聚类,然后对每个聚类的中心点进行投票,最终得到一个新的中心点。
这个过程会重复进行,直到满足停止条件。
在 CURE 聚类算法中,计算中心点的公式是非常重要的。
CURE 聚类的中心点计算公式如下:
中心点 = (x1 + x2 +...+ xn) / n
其中,x1, x2,..., xn 是每个聚类的中心点,n 是聚类的数量。
通过这个公式,我们可以得到 CURE 聚类的中心点,从而得到最终的聚类结果。
CURE 聚类算法具有很多优点,例如具有良好的稳定性和鲁棒性,可以处理不同形状的数据集,同时也可以处理不同密度的数据集。
因此,CURE 聚类算法在很多应用场景中都得到了广泛的应用,例如数据挖掘、图像处理和生物信息学等领域。
总的来说,CURE 聚类算法是一种非常有效的聚类方法,其中心点计算公式也非常简单易懂。
第1页共1页。