地统计分析
arcgis学习--地统计分析
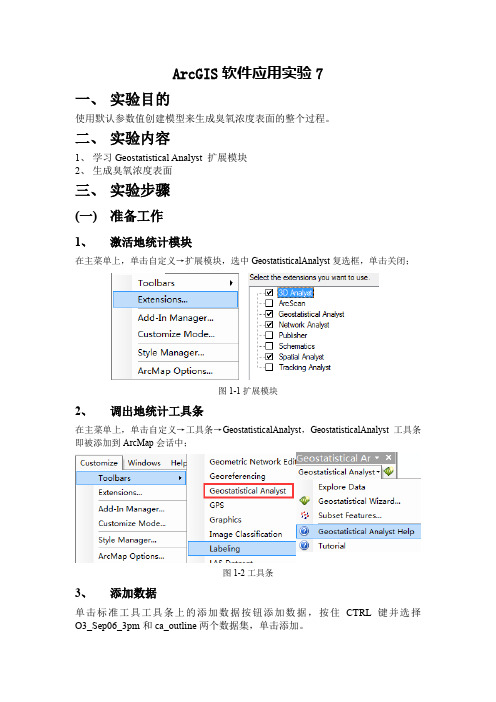
ArcGIS软件应用实验7一、实验目的使用默认参数值创建模型来生成臭氧浓度表面的整个过程。
二、实验内容1、学习Geostatistical Analyst 扩展模块2、生成臭氧浓度表面三、实验步骤(一)准备工作1、激活地统计模块在主菜单上,单击自定义→扩展模块,选中GeostatisticalAnalyst复选框,单击关闭;图1-1扩展模块2、调出地统计工具条在主菜单上,单击自定义→工具条→GeostatisticalAnalyst,GeostatisticalAnalyst工具条即被添加到ArcMap会话中;图1-2工具条3、添加数据单击标准工具工具条上的添加数据按钮添加数据,按住CTRL键并选择O3_Sep06_3pm和ca_outline两个数据集,单击添加。
图1-3添加数据4、修改属性1、右键单击内容列表中的ca_outline图层图例(图层名称下面的框),然后单击无颜色,确保图层无颜色,只有范围;图1-4无颜色2、双击内容列表中O3_Sep06_3pm图层的名称。
打开图层属性对话框,在图层属性对话框中,单击符号系统选项卡。
在显示对话框中,○1单击数量,然后单击分级色彩;○2在字段框中,将值设置为OZONE;○3选择“黑色到白色”色带,以便这些点可以在本教程将要创建的颜色表面之上凸出来;符号系统对话框应如下所示:图1-5分级符号3、经过属性修改后,图层如下:图1-6结果(二)使用默认选项创建表面使用默认GeostatisticalAnalyst设置创建(插值)臭氧浓度表面。
臭氧点数据集(O3_Sep06_3pm)将用作输入数据集,并采用普通克里金法对值未知的位置处插入臭氧值。
在一系列对话框中单击下一步来接受默认设置。
1、地统计分析对话框单击GeostatisticalAnalyst工具条上的GeostatisticalAnalyst箭头,然后单击地统计向导,将弹出地统计向导对话框;图2-1地统计工具条地统计向导对话框,在方法列表框中,单击克里金法/协同克里金法。
地统计分析方法

高维数据分析
发展适用于高维数据的降维和可视化 技术,以更好地处理复杂数据。
大数据处理
利用高性能计算机和云计算技术,提 高地统计分析方法的计算效率和准确 性。
可解释性研究
加强地统计分析结果的解释性和可视 化研究,提高结果的易理解性和可解 释性。
05
地统计分析方法的实际案例
案例一:城市人口密度的空间分布特征分析
总结词
通过地统计分析方法,分析农业产量的空间 相关性,揭示农作物生长的空间依赖性和异 质性。
详细描述
利用地统计分析方法,对农业产量进行空间 相关性分析,探究不同地区间农作物产量的 相互影响关系。通过分析产量数据的空间自 相关性和集聚模式,理解农作物生长过程中 的空间依赖性和异质性,为农业管理和区域 发展提供科学依据。
04
地统计分析方法的优势与局限性
优势
空间依赖性分析
高效的空间预测
地统计分析方法能够揭示数据的空间依赖 性,即相邻观测值之间的相互影响,有助 于理解空间现象的内在机制。
地统计分析方法利用已知观测值对未知区 域进行预测,能够提供更精确和可靠的空 间预测结果。
降维处理
灵活的模型选择
地统计分析方法能够将高维数据降维处理 ,提取关键的空间结构和模式,简化复杂 数据的分析过程。
发展
地统计分析方法在不断发展完善中,出现了许多新的方法和模型,如克里格插值 、马尔科夫链蒙特卡罗方法等,为地统计分析提供了更丰富的工具和手段。
02
地统计分析方法的原理
空间自相关原理
空间自相关是地统计分析的核心概念,它描述了空间中某一位置上的现象与周围位 置上同种现象之间的相关性。
空间自相关可以用来检测空间依赖性和异质性,从而揭示空间模式和结构。
《地统计分析》课件

地统计分析案例展 示
案例一:土壤重金属污染空间分布特征分析
数据来源:土壤重金属污染 监测数据
分析方法:地统计分析方法, 如克里金插值、空间自相关 等
背景:土壤重金属污染已成 为全球性问题,对人类健康 和环境安全构成威胁
结果:揭示了土壤重金属污 染的空间分布特征,为污染
治理提供依据
案例二:城市居民收入空间自相关分析
异常值处理原则:保持数据的 完整性和准确性
数据插值与填充
插值方法: 线性插值、 多项式插 值、样条 插值等
插值目的: 填补数据 缺失,提 高数据质 量
插值步骤: 选择插值 方法、确 定插值参 数、执行 插值操作
填充方法: 均值填充、 中位数填 充、众数 填充等
填充目的: 填补数据 缺失,提 高数据完 整性
数据:收集农业种 植结构数据,包括 种植面积、作物类 型、土壤类型等
结果:分析农业种 植结构的空间变异 特征,为农业种植 结构调整提供依据
案例四:地下水位空间插值预测分析
方法:采用地统计分析方法 进行空间插值预测
数据:收集地下水位观测数 据,包括时间、地点、水位
等
背景:地下水位变化对生态 环境和人类活动有重要影响
普通克里格插值分析
原理:基于已知数据点,通过最小二乘法拟合出未知数据点的值 特点:适用于区域化变量,如温度、降雨量等 步骤:选择合适的模型,如线性、多项式、指数等;计算权重;计算预测值 应用:气象、水文、地质等领域
指示克里格插值分析
克里格插值法的优缺点
克里格插值法的基本原理
克里格插值法的应用领域
分类:空间变异模型可以分为空间自相关模型、空间异质性模型、空间回归模型等
应用:空间变异模型广泛应用于地理学、生态学、公共卫生等领域,用于分析空间数据的变 异性,揭示空间数据的空间分布规律。
《土地统计分析》课件

欢迎来到《土地统计分析》的课程。今天我们将学习如何通过数据科学和统 计分析来更好地理解和利用土地资源。
概述
什么是土地统计分析
土地统计分析是一种利用统计学方法,对土地和土地利用进行分析和预测的学科。
为什么需要土地统计分析
土地是有限资源,为了更好地利用土地,需要从统计分析的角度对土地资源进行深入研究。Biblioteka 土地统计分析技术的应用和发展
对土地统计分析技术的研发和应用,将为实现土地资源 的可持续利用提供更好的手段。
总结
1 土地统计分析
是了解土地资源和利用的一种重要手段。
2 应用场景广泛
可以应用于城市规划、土地管理以及农业生产等领域。
3 技术和数据的发展
将为土地统计分析提供更多渠道和思路。
通过对城市土地资源和利用方式进行分析,了解不同区域土地利用的差异性,为城市规划提 供依据。
农村土地利用分析
对乡村土地资源和利用方式进行分析,了解农村土地利用的特点和发展趋势。
生态环境变化分析
通过对土地利用变化对生态环境的影响进行分析,寻求更加可持续的土地利用方式。
发展趋势
数据科学与土地统计分析
数据科学的发展将为土地统计分析带来更大的机遇和挑 战,为土地利用提供更多渠道和思路。
土地统计分析的应用场景
土地统计分析可以应用于城市规划、土地管理、农业生产等领域。
研究对象
土地资源
统计分析土地资源的种类、分布、数量以及空间利用 情况,可以更好地规划土地利用。
土地利用方式
统计分析土地的利用方式,可以了解不同地区的实际 需求和发展趋势。
土地利用变化
统计分析土地利用的变化情况,可以了解土地利用的
如何使用地学统计方法进行测绘数据分析

如何使用地学统计方法进行测绘数据分析在现代地理信息系统和测绘领域,地学统计方法应用广泛,可用于测绘数据的分析和解释。
通过对地学统计方法的运用,我们能够从大量的数据中提取有用的信息和规律,并为地理研究和应用提供科学依据。
本文将以如何使用地学统计方法进行测绘数据分析为主题,探讨其原理和应用。
首先,地学统计方法是一种通过搜集和分析数据来获得地理信息的科学方法。
地学统计方法有多种形式,包括描述性统计、假设检验、回归分析、时间序列分析等。
在测绘领域中,主要使用的统计方法包括空间统计和多元统计。
空间统计是研究地理现象在空间上的分布和相关性的方法。
其基本原理是假设地理现象具有一定的空间相关性,即相邻的位置具有相似的特征。
通过空间统计方法,我们可以识别并量化这种相关性,并用地图的形式展示出来。
例如,通过空间自相关分析,我们可以确定某一地区的特定属性在空间上的分布情况,从而为规划和决策提供参考。
多元统计是研究地理现象与多个因素之间关系的方法。
其基本原理是通过建立数学模型来描述地理现象与多个因素之间的线性或非线性关系。
通过多元统计方法,我们可以确定和解释不同因素对于地理现象的影响程度,并预测未来的趋势。
例如,通过回归分析,我们可以确定人口数量与城市面积、经济发展水平和交通状况等因素之间的关系,从而为城市规划和管理提供科学依据。
在测绘数据分析中,地学统计方法的应用主要包括以下几个方面。
首先,地学统计方法可以用于分析地理现象的分布格局。
通过空间自相关分析,我们可以确定某一地区的特定属性在空间上的分布情况,并进一步研究其影响因素及原因。
例如,在城市规划中,我们可以分析不同区域的人口密度分布格局,并进一步探讨其与交通状况、生态环境等因素之间的关系。
其次,地学统计方法可以用于预测地理现象的未来趋势。
通过时间序列分析,我们可以建立数学模型来描述地理现象随时间的变化趋势,并预测其未来的发展趋势。
例如,在气候预测中,我们可以分析过去几十年的气象数据,并建立气象模型来预测未来几年的气候变化情况。
探索性空间统计分析和地统计分析

探索性空间统计分析和地统计分析探索性空间统计分析(Exploratory Spatial Data Analysis,简称ESDA)和地统计分析(Geostatistical Analysis)是两种常用的空间数据分析方法。
它们的目标都是通过统计方法来描述和分析地理现象及其空间分布规律,但在方法和应用上存在一些区别。
首先,探索性空间统计分析是一种通过可视化和统计方法来探索和描述空间数据的分析方法。
它主要关注地理现象的空间分布特征,以及空间相邻性和空间自相关性等空间关联性质。
ESDA通常包括一系列的分析步骤,如制作空间点图、计算空间变量的描述统计指标、绘制空间变量的直方图和箱线图等。
其中最重要的是通过制作空间点图来可视化空间分布特征,以便于进一步分析和解释。
其次,地统计分析是一种基于统计和概率方法来模拟和揭示地理现象的空间变异性的分析方法。
它主要关注地理现象在空间上的变异程度、空间趋势以及随机性等方面。
地统计分析通常基于经验半变异函数,通过计算样点之间的空间自相关性来揭示空间变异性的模式。
在地统计分析中最常用的模型是半变异函数模型,通过拟合半变异函数来估计空间自相关的程度和范围。
此外,地统计分析还可用于插值、空间预测和决策支持等方面的应用。
ESDA和地统计分析在应用上有一些区别。
ESDA更适用于对空间数据进行初步的探索和分析,通过可视化和描述统计的方法来了解空间数据的基本特征和分布规律,进而为后续的分析和建模奠定基础。
而地统计分析则更适合于模拟和预测地理现象的空间变异性,通过拟合空间模型来揭示地理现象的空间趋势和变异程度。
地统计分析较为复杂,需要有一定的空间统计知识和数据处理技巧。
总之,探索性空间统计分析和地统计分析是两种常用的空间数据分析方法,它们通过统计方法来描述和分析地理现象及其空间分布规律。
ESDA 注重空间数据的可视化和描述统计,而地统计分析则注重空间变异性的建模和推断。
两种方法在应用上有所区别,但在实际分析中常常可以相互补充和结合使用,以提高对空间数据的理解和解释能力。
ARCGIS_地统计分析

ARCGIS_地统计分析地统计分析是一种以地理空间数据为基础,通过空间与属性数据的分析与处理,揭示地理现象的分布规律、相互关系及其演化过程的一种科学方法。
ARCGIS(Arc Geographic Information System)是一种常用的地理信息系统软件,具有强大的地理空间数据分析功能。
本文将介绍ARCGIS地统计分析的原理、应用方法及其在研究、规划和决策等领域的重要性。
ARCGIS地统计分析的原理是将地理空间数据与属性数据相结合,通过特定的算法与方法分析地理现象的分布规律与关系。
ARCGIS提供了多种空间分析工具,包括空间数据插值、空间聚类、空间插值、空间模式、空间点格局等,以支持用户对地理现象进行全面的分析和理解。
其中,空间插值分析是一种根据已有的离散空间点数据,推测未知位置点处的属性值的方法,常用于地质勘查、环境监测等领域;空间聚类分析可用于发现空间集群的位置、大小和分布模式,常用于城市规划、交通规划等领域;空间模式分析则可以通过分析地理对象的空间关系,揭示地理对象分布的内在规律。
在ARCGIS地统计分析中,数据的选择与准备是非常重要的环节。
首先,需要选择与研究对象相适应的数据类型,如矢量数据、栅格数据等。
其次,需要对数据进行预处理,包括数据清洗、数据转换等操作,以确保数据质量和一致性。
然后,需要选择合适的统计分析方法,并根据具体情况制定相应的参数设置。
最后,对分析结果进行可视化展示,以便进一步的分析和解释。
总之,ARCGIS地统计分析是一种有效的地理空间数据分析方法,可以揭示地理现象的分布规律和相互关系,并为各个领域的研究、规划和决策提供科学支持。
通过合理选择和处理数据,结合合适的统计分析方法,可以获取有意义的分析结果,并在实际应用中发挥重要作用。
因此,熟练掌握ARCGIS地统计分析技术,对于科研人员、规划师和决策者来说,具有重要的价值和意义。
地统计分析方法

为 .当c0=0,c3=a 1时,称为标准高斯函数模型。
• 幂函数模型:其一般公式为
(h) Ah ,0 2
• 式中:θ为幂指数。当θ变化时,这种模型可以反
映在原点附近的各种性状。但是θ必须小于2,若
θ≧2,则函数r(-h)就不再是一个条件非负定函数 了,也就是说它已经不能成为变异函数了。
• 变异规律分析和空 • 间结构分析的有效 • 工具。
例1
假设某地区降水量Z(x)(单位:mm)是二维区域化随
机变量,满足二阶平稳假设,其观测值的空间正 方形网格数据如图所示(点与点之间的距离为 h=1km)。试计算其南北方向及西北和东南方向 的变异函数。
• 从上图可以看出,空间上有些点,由于某种原因 没有采集到。如果没有缺失值,可直接对正方形 网格数据结构计算变异函数;在有缺失值的情况 下,也可以计算变异函数。只要“跳过”缺失点 位置即可。
c0 c
h0 0ha
ha
当0 h 时 a,有
(h)
c0
( 3c )h 2a
c ( 2a 3
)h3
•
如果记
y
(h),b0
c0 , b1
3c 2a
, b2
, 12则ac3 ,可x1 以h, 得x2 到h3 线性模型
• 根据表中的数据y,对b0上 式b1x进1 行b2最x2 小二乘拟合,得 到
型、抛物线模型; 孔穴效应模型。
• ①纯块金效应模型:其一般公式为
0
(h) c0
h0 h0
• 式中:c0>0,为先验方差。该模型相当于区域化
变量为随机分布,样本点间的协方差函数对于所
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验五加利佛尼亚州的大气臭氧浓度的地统计分析(综合实验)实验目的:通过对数据的具体分析,掌握ArcGIS下地统计分析模块的功能,了解完整的地统计分析过程,并能使用其解决科研问题中的实际问题。
实验内容:美国环保局负责对加利佛尼亚州的大气臭氧浓度进行监测。
利用地统计分析模块提供的许多工具,通过检测所有采样点之间的关系,对生成一个关于臭氧浓度值、预测标差(不确定性)的连续表面,从而使对其他点的浓度值进行最佳预测成为可能。
1、数据检查2、模型拟合3、模型精度比较4、臭氧浓度制图实验数据:数据集描述Ca_outline 加州轮廓图Ca_ozone_pts 臭氧采样点数据(单位:ppm)Ca_cities 加州主要城市位置图实验步骤:一、数据加载1、生成子集将特定位置上的预测值同这些区域内的实测值相对比,是评价一个输出表面质量的最严格的方法。
其方法是将原始数据集划分成两个部分:一个部分用于建立模型,也就是用来生成输出表面;另外一个部分用于测试,即验证输出表面。
(1)在Geostatistical Analyst 工具栏中单击Create Subsets命令;(2)Input Layer:选择要划分子集的图层;(3)拖动滑块到合适位置,来选择训练和测试数据的相对百分比;(4)单击完成,训练和测试数据集会在Personal Geodatabase中。
2、应用子数据集进行验证(1)validation:input 选择测试数据集(2)attribute:选择与生成表面时相同的属性(3)打开验证图层二、数据检查你可以用三种方式对数据进行检验:(1)检测数据分布(2)发现数据可能存在的趋势(3)找出数据间的空间自相关以及方向效应2.1 检查数据的分布当数据服从正态分布时,里用插值方法生成表面的效果最佳。
如果你的数据是偏态分布的,即向一边倾斜,则你可以选择数据变换使之服从正态分布。
Histogram工具描绘了数据属性的频率直方图,使你能够针对数据集的每一种属性检测其单变量分布。
1.单击Geostatistical Analyst工具条,指向Explore Data,然后单击Histogram。
你也可以改变Histogram对话框的大小以便能够看见地图,正如下图所示:2.单击Layer下拉箭头,点击并选择ca_ozone_pts。
3.单击Attribute下拉箭头,点击并选择OZONE。
通常,描述数据分布的重要特征包括中值,他的展布以及对称性。
对于正态分布,有一个快速检验的方法:如果平均值与中值大致相等,你就可以把它当作数据服从正台分布的证据之一。
上面显示的直方图表面数据是单峰分布的,而且具有较好的对称性,接近于正态分布。
直方图的右侧尾部表明,存在相对少量的具有较高臭氧浓度值的采样点。
2.2 正态QQ图QQ图提供了另外一种度量数据正台分布的方法,利用QQ图你可以将现有数据的分布与标准正态分布对比,如果数据点接近一条直线,则它们越接近于服从正态分布。
1.单击Geostatistical Analyst工具条,指向ExploreData,然后点击Nomal QQplot。
2.单击Layer下拉箭头,点击并选中ca_ozone。
3.单击Attribute下拉箭头,点击并选中OZONE。
在一个普通的QQ图上,两种分布的对应点一一对应。
对于两种相同类型的分布,QQ图应该是一条直线。
因此通过绘制相对应的臭氧数据的分布点与标准正态分布的分布点,能够检查臭氧数据的正态分布情况。
从上述正态QQ图可以看出,该图形非常接近于一条直线。
而偏离直线的情况主要发生在臭氧浓度值较高时(因为这些偏离值在直方图中是高亮显示的,所以在这里它们也是被高亮显示的)。
2.3 识别数据中的全局趋势只有在你的数据中存在某种趋势时,你才可能利用某些数学公式对表面的非随机(确定性的)成分进行表达。
如果趋势面不能精确地描绘你实际需要的表面,你可能想到将其移去,通过建立趋势剔除后的残差的模荆来继续你的分析。
在建立残差模型时,你需要分析表面中的短程变异。
这是理想平面或理想“u”型面所无法实现的内容。
Trend Analysis(趋势分析)工具使你能够找出在输入数据集中是否存在趋势。
1.单击Geostatistical Analys工具条,鼠标指向Explore Data,点击Trend Analysis.2 单击layer下拉箭头,点击选中ca_ozone_pts。
3.单击Attribute下拉箭头,选中OZONE,趋势分析图中的每一根竖棒代表了一个数据点的值(高度)和位置。
这些点被投影到一个东西向的和一个南北向的正交平面上。
通过投影点可以作出一条最佳拟合线(一个多项式),并用它来模拟特定方向上存在的趋势。
如果该线是平直的,则表明设有趋势存在。
4.单击Rotate Proiection滚动条并向左拖动,使旋转角为30度。
造成该趋势的一个可能的事实是,在沿海地区污染较轻,而在向内陆推进时,人口增多,污染增大。
到了山区则人口又减少,污染也随之降低。
在练习4中,这些趋势将要被剔除。
5.单击退山对话框。
2.4 理解数据的空间自相关和方向效应1.单击GeostatisticalAnalyst工具条,指向Explore Data,点击Semivariogram/Covariance Cloud。
2.单击Layer框下拉箭头,点击选中ca_ozone_pts。
3.点市Attribute框下拉箭头,单击选中OZONE。
半变异函数/协方差函数云图使你能够检测已测样点间的空间自相关。
空间自相关理论认为彼此之间距离越近的事物越相象。
半变异函数/协方差函数云图使你能够对这种关系进行检测。
为此,可以用Y轴表示半变异函数值,即每一样点对间测量值之差的平方,而相应地用x轴表示每对样点之间的距离。
在半变异函数/协方差函数云图中,每个红点表示一对采样点。
既然越近的点越相似,那么在半变异函数云图中邻近的点(在x轴的左边)应该有较小的半变异函数值(在Y 轴的下部)。
随着样点对间距离的增加(在x轴上向右移动),中变异函数值也要相应增加(在Y轴上向上移动)。
然而,当到达一定的距离后,云图变平,这表明超出这个距离时,样点对之间不再具有相关关系了。
观察半变异函数图,如果某些靠得很近的数据点(在x轴上接近于零)具有——个异常的较高的半变异函数值(在Y轴的上部)时,你就应该仔细检杳这些样点对,看看是不是这些数据不准确。
三、制作臭氧浓度图1.单市Geostatistical Analyst—工具条,然斤单击Geostatistical Wizard。
2.单击Input Data卜拉框箭头,点击选中ca ozone pts。
3.单击Attribute F拉框箭头,点击属性OZONE。
4.在Methods框中选择Kriging。
5.单击Next按钮。
Ordinary Kriging和Prediction被缺省选中。
6.在Geostatistical MethodSelection对话框中,单击Order of Trend Removal下拉箭头,选择Second。
在TrendAnalysis对话框中已经检测到一条南西-北东方向的“u”型曲线,所以选择二阶多项式拟合是合适的。
7.在Geostatistical Method Selection对话框中点击Next按钮。
缺省情况下,地统计分析模块将绘制数据集中的全局趋势。
从下图可以看出,南西-北东向的变化最快,而北西-南东向的变化则较平缓(从而形成椭圆形)。
8.点击Detrending对话框中的Next按钮。
3.1 半变异函数/协方差函数模型半变异函数是一个关于数据点的半变异值(或称变异性)与数据点间距离的函数。
对它的图形表述可以得到一个数据点与其相邻数据点的空间相关关系图。
在Semivariogra/Covariance Modeling对话框中你可以模拟数据集的空间关系。
缺省情况下,将以球面半变异函数模刑来计算其最佳参数值。
拟合一个球面半变异函数模则(在各个方向都能拟合的很好)以及它们的相关参数值,这些参数通常被称为块金效应、自相关阐值及偏基台值(结构方差)。
9.输入—个新步K值12000。
10.单击输入框,设定步长组的数目为10。
当距离很小时,半变异函数值也很低(即越靠近的事物相似性越大):随着距离的增加,其值也增大(即越远离的事物变异性越强)。
3.2 方向半变异函数方向效应会对半变异函数中的点以及将要拟合的模型产生影响。
邻近的事物在某些方向上的相似性比其他方向的相似性更强。
方向效应又被称为各向异性,地统计分析模块能够对它们进行解释。
引起各向异性的因素可能足风、侵蚀、地质构造或者许多多其他过程。
你可以用Search Direction工具来分析某一方向上数据点的变异性,利用该工具你可以在半变异函数图上检测方向效应,这并不影响输出的表面。
11.选中Show Search Direction复选框。
12.在Search Direction的中心线上点击并按住鼠标,移动搜索工具的方向。
13.选中Anisotropy复选框。
在变异函数表面图中的椭圆表明了在不同方向上的半变异函数的自相关阈值。
在这种情况下,椭圆主轴大致位于北北西-南南东方向。
现在你可以在模型中加入各向异性,用以调整输出表面中自相关的方向效应。
半变异函数棋到达到的稳定水平时的值相同,我们称之为基台值。
而半变异函数模刮达到其限值(基台值)时经过的距离,即为模型的自相关阈值。
超出这个自相关阈值后,各点之间的变异性将随着步长距离的增加而变为常数。
步长是通过点对间的距离来界定的。
步长距离大于自相关阈值的样点对之间空间无关。
块金效应代表了测量误差和(或)微观尺度的变异(该变异在空间尺度上太小以至于无法检测到)。
3.3 领域搜索为避免某一特定方向上的偏差,可以把这个圆(或者椭圆)分为若干个小扇形,在各扇形内选取相同数目的点。
利用Searching Neighborhood对话框,你可以指定点的数目(最大为200)、半径(或者长/短轴)以及用来预测的圆(或者椭圆)中的扇形个数。
3.4 交叉验证交叉验证可以让你知道你的模型对未知值的预测效果究竟怎样。
对于一个预测精确的模型,其均差应接近于0,其均方根误差和平均标准差应该尽可能地小(这在比较模型时很有用),并且其均方根标准误差应该接近于1。
25.单击Finish按扭。
Output layer information 对话框显示了用于创建表面的模型的信息摘要。
四、模型对比1.在“Trendremoved”层上右击,在快捷菜单中点击“Compare….”,就可以将不同的图层进行比较。
2.在CrossValidationComparison(交叉验证对话框)中点击Close按钮。