相关系数法
相关系数法

相关系数法
相关系数法是一种常见的统计学方法,用于评估两个变量之间的线性关系。
它用一个数值来衡量两个变量之间的相关性,该数值通常介于-1到1之间。
如果相关系数为正数,则表示两个变量呈正相关关系;如果相关系数为负数,则表示两个变量呈负相关关系;如果相关系数为零,则表示两个变量之间没有线性关系。
相关系数法可以用于许多不同的应用领域,例如市场研究、经济学、社会学、医学等。
在市场研究中,相关系数法可以用于分析产品销售数据和市场趋势之间的关系。
在经济学中,相关系数法可以用于研究不同变量之间的关系,例如通货膨胀和利率之间的关系。
在医学中,相关系数法可以用于评估药物对疾病的疗效。
为了计算相关系数,需要使用统计软件或计算器。
常用的相关系数包括皮尔逊相关系数和斯皮尔曼相关系数。
皮尔逊相关系数适用于连续性变量之间的相关性分析,而斯皮尔曼相关系数适用于有序变量之间的相关性分析。
需要注意的是,相关系数并不能说明因果关系。
即使两个变量之间有很高的相关系数,也不能证明其中一个变量是导致另一个变量变化的原因。
因此,在进行相关性分析时,需要综合考虑原因和结果之间的关系,以及其他可能的因素。
效标关联效度计算方法

效标关联效度是一种用来评估心理测验、能力测试或其它评估工具有效性的方法,主要通过计算测验分数与某个外部效标(通常是公认的、独立的标准或结果)之间的关系强度来实现。
计算效标关联效度的主要方法包括:
1.相关系数法:
o积差相关系数(Pearson's r):适用于连续变量,当测验分数和效标分数都是连续分布的数据时,可以计算皮尔逊积差相关系数来评估两
者间的线性关系强度。
o斯皮尔曼等级相关(Spearman's rho):当两个变量的等级关系比数值关系更重要时,可以使用非参数的相关分析方法。
o肯德尔和谐系数(Kendall's tau):也是用于非参数等级相关分析的方法之一。
2.回归分析:
o通过建立回归模型,可以分析测验分数对效标分数的预测能力,并计算决定系数(R²)或偏回归系数等指标,以评估预测效度。
3.分组法:
o根据效标分数将被试分成高、低或多组,然后比较各组在测验上的得分是否有显著差异,例如使用t检验或方差分析。
4.命中率分析:
o在预测效度的背景下,特别是对分类变量的预测,可计算各种命中率指标,如真阳性率、假阳性率、真阴性率、假阴性率,以及总的预测
准确性、敏感性和特异性等。
5.区分度分析:
o分析测验分数是否能有效地区分效标所定义的不同群体。
具体操作时,通常收集一组被试的测验分数和相应的效标分数,然后选择合适的方法计算它们之间的关联度。
效标关联效度既可以是同时效度(同时评估测验与效标
的关联),也可以是预测效度(用测验分数预测未来的表现或结果)。
在SPSS等统计软件中,可以方便地进行这些相关分析和回归分析以获得效标关联效度的证据。
线性回归中的相关系数

线性回归中的相关系数山东 胡大波线性回归问题在生活中应用广泛,求解回归直线方程时,应该先判断两个变量就是否就是线性相关,若相关再求其直线方程,判断两个变量有无相关关系的一种常用的简便方法就是绘制散点图;另外一种方法就是量化的检验法,即相关系数法.下面为同学们介绍相关系数法. 一、关于相关系数法统计中常用相关系数r 来衡量两个变量之间的线性相关的强弱,当i x 不全为零,y i 也不全为零时,则两个变量的相关系数的计算公式就是:()()nnii i ixx y y x ynx yr ---==∑∑r 就叫做变量y 与x 的相关系数(简称相关系数).说明:(1)对于相关系数r ,首先值得注意的就是它的符号,当r 为正数时,表示变量x ,y 正相关;当r 为负数时,表示两个变量x ,y 负相关;(2)另外注意r 的大小,如果[]0.751r ∈,,那么正相关很强;如果[]10.75r ∈--,,那么负相关很强;如果(]0.750.30r ∈--,或[)0.300.75r ∈,,那么相关性一般;如果[]0.250.25r ∈-,,那么相关性较弱.下面我们就用相关系数法来分析身边的问题,确定两个变量就是否相关,并且求出两个变量间的回归直线. 二、典型例题剖析(1)对变量y 与x 进行相关性检验;(2)如果y 与x 之间具有线性相关关系,求回归直线方程; (3)如果父亲的身高为73英寸,估计儿子身高.解:(1)66.8x =,67y =,102144794i i x ==∑,102144929.22i i y ==∑,4475.6x y =,24462.24x =,24489y =,10144836.4i i i x y ==∑,所以10i ix ynx yr -∑44836.4104475.6(4479444622.4)(44929.2244890)-⨯=--80.40.9882.04≈≈, 所以y 与x 之间具有线性相关关系. (2)设回归直线方程为y a bx =+,则101102211010i ii i i x yxyb x x==-=-∑∑44836.4447560.46854479444622.4-=≈-,670.468566.835.7042a y bx =-=-⨯=.故所求的回归直线方程为0.468535.7042y x =+. (3)当73x =英寸时,0.46857335.704269.9047y =⨯+=, 所以当父亲身高为73英寸时,估计儿子的身高约为69、9英寸.点评:回归直线就是对两个变量线性相关关系的定量描述,利用回归直线,可以对一些实际问题进行分析、预测,由一个变量的变化可以推测出另一个变量的变化.这就是此类问题常见题型.例2 10其中x 为高一数学成绩,y 为高二数学成绩. (1)y 与x 就是否具有相关关系;(2)如果y 与x 就是相关关系,求回归直线方程. 解:(1)由已知表格中的数据,利用计算器进行计算得 101710ii x==∑,101723i i y ==∑,71x =,72.3y =,10151467i i i x y ==∑.102150520ii x==∑,102152541i i y ==∑.1010i ix yx yr -=∑0.78=≈.由于0.78r ≈,由0.780.75>知,有很大的把握认为x 与y 之间具有线性相关关系. (2)y 与x 具有线性相关关系,设回归直线方程为y a bx =+,则1011022211051467107172.31.2250520107110i ii i i x yx yb x x==--⨯⨯==≈-⨯-∑∑,72.3 1.227114.32a y bx =-=-⨯=-.所以y 关于x 的回归直线方程为 1.2214.32y x =-.点评:通过以上两例可以瞧出,回归方程在生活中应用广泛,要明确这类问题的计算公式、解题步骤,并会通过计算确定两个变量就是否具有相关关系.。
三种常用的不同变量之间相关系数的计算方法
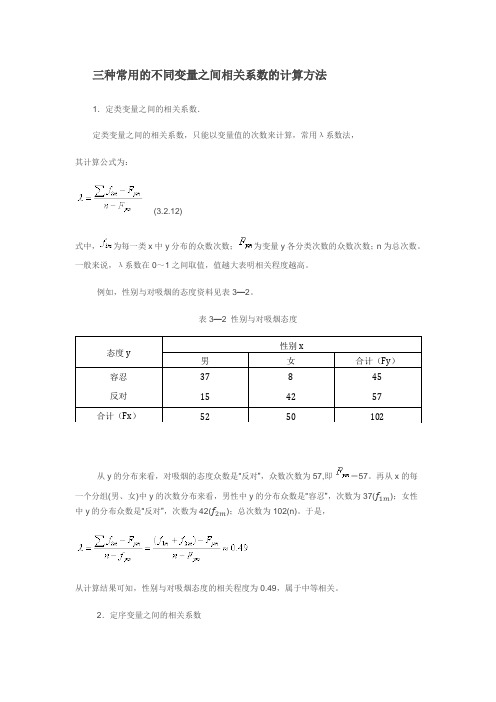
三种常用的不同变量之间相关系数的计算方法1.定类变量之间的相关系数.定类变量之间的相关系数,只能以变量值的次数来计算,常用λ系数法,其计算公式为:(3.2.12)式中,为每一类x中y分布的众数次数;为变量y各分类次数的众数次数;n为总次数。
一般来说,λ系数在0~1之间取值,值越大表明相关程度越高。
例如,性别与对吸烟的态度资料见表3—2。
表3—2 性别与对吸烟态度态度y性别x男女合计(Fy)容忍反对37158424557合计(Fx)52 50 102从y的分布来看,对吸烟的态度众数是“反对”,众数次数为57,即=57。
再从x的每一个分组(男、女)中y的次数分布来看,男性中y的分布众数是“容忍”,次数为37(f1m);女性中y的分布众数是“反对”,次数为42(f2m);总次数为102(n)。
于是,从计算结果可知,性别与对吸烟态度的相关程度为0.49,属于中等相关。
2.定序变量之间的相关系数定序变量之间的相关测量常用Gamma系数法和Spearman系数法。
Gamma系数法计算公式为:(3.2.13)式中,G为系数;Ns为同序对数目;Nd为异序对数目。
所谓序对是指表明高低位次的两两配对,如果一对个案在变量x,y的分类表现位次一致,则为同序对;如果位次相反,则为异序对。
G系数取值在—1--十1之间。
G=1,表示完全正相关;G=-1,表示完全负相关;G=0,表示完全不相关;-1<G<0,表示负相关;0<G<1,表示正相关。
Spearman系数法计算公式为:(3.2.14)式中,P为系数;D为所测定的两个数列中每对项目之间的登记差,这个差的正值之和等于负值之和;N为项数。
系数p主要代表两个定序变量的等级相关程度,其取值范围和相关程度含义与G系数相同。
3.定距变量之间的相关系数定距变量之间的相关测量常用Pearson系数法。
对于未分组资料,Pearson系数法计算公式为:对于已分组资料,Pearson系数法计算公式为r系数取值范围和相关程度的含义与G系数相同。
特征选择的常用方法

特征选择的常用方法特征选择是机器学习和数据挖掘中的一个重要步骤,它的目的是从原始数据中选择出最具有代表性和相关性的特征,以提高模型的性能和效果。
特征选择方法有很多种,本文将介绍其中一些常用的方法。
一、过滤式方法过滤式方法是指在特征选择和模型训练之前就进行特征选择的方法。
它通过计算特征与目标变量之间的相关性或其他统计指标,来评估特征的重要性,并选择出相关性较高的特征。
常用的过滤式方法有相关系数法、卡方检验法、互信息法等。
1. 相关系数法相关系数法是通过计算特征与目标变量之间的相关系数来评估特征的重要性。
相关系数的取值范围在-1到1之间,绝对值越接近1表示相关性越强。
可以根据相关系数的大小来选择相关性较高的特征。
2. 卡方检验法卡方检验法是一种统计方法,用于检验两个变量之间的独立性。
在特征选择中,可以将特征与目标变量之间的独立性作为评估指标,计算卡方值来选择特征。
卡方值越大表示特征与目标变量之间的独立性越低,特征的重要性越高。
3. 互信息法互信息法是一种衡量两个随机变量之间的相关性的方法。
在特征选择中,可以将特征与目标变量之间的互信息作为评估指标,来选择特征。
互信息的取值范围在0到正无穷之间,取值越大表示特征与目标变量之间的相关性越高,特征的重要性越高。
二、包裹式方法包裹式方法是指将特征选择作为一个子问题嵌入到模型训练过程中的方法。
它通过构建不同的特征子集,并评估模型在不同特征子集上的性能,来选择出最佳的特征子集。
常用的包裹式方法有递归特征消除法、遗传算法等。
1. 递归特征消除法递归特征消除法是一种自底向上的特征选择方法。
它通过不断地构建模型并剔除权重较小的特征,来选择出最佳的特征子集。
递归特征消除法可以根据模型的性能评估来选择特征,如准确率、均方误差等。
2. 遗传算法遗传算法是一种模拟自然选择和遗传机制的优化算法。
在特征选择中,可以将特征子集看作个体,通过遗传算法的选择、交叉和变异等操作,来搜索最佳的特征子集。
二分类变量降维方法

二分类变量降维方法引言:在数据分析和机器学习中,我们经常会遇到二分类变量的情况,即变量只有两个取值。
然而,对于包含大量二分类变量的数据集,处理起来可能会很复杂,并且可能会导致维度灾难。
因此,降维是一种常用的技术,用于减少变量的数量,同时保留尽可能多的信息。
本文将介绍几种常用的二分类变量降维方法。
一、相关系数法相关系数法是一种常用的二分类变量降维方法。
它通过计算每个二分类变量与目标变量之间的相关系数,来评估变量的重要性。
相关系数的绝对值越大,说明变量对目标变量的影响越大。
因此,可以选择相关系数较大的变量,保留下来进行分析,而将相关系数较小的变量剔除。
二、卡方检验法卡方检验法也是一种常用的二分类变量降维方法。
它通过计算每个二分类变量与目标变量之间的独立性卡方值,来评估变量的重要性。
卡方值越大,说明变量与目标变量之间的关联性越强。
因此,可以选择卡方值较大的变量,保留下来进行分析,而将卡方值较小的变量剔除。
三、信息增益法信息增益法是一种常用的二分类变量降维方法。
它通过计算每个二分类变量与目标变量之间的信息增益,来评估变量的重要性。
信息增益越大,说明变量对目标变量的影响越大。
因此,可以选择信息增益较大的变量,保留下来进行分析,而将信息增益较小的变量剔除。
四、逻辑回归系数法逻辑回归系数法是一种常用的二分类变量降维方法。
它通过训练一个逻辑回归模型,得到每个二分类变量的系数值,来评估变量的重要性。
系数值的绝对值越大,说明变量对目标变量的影响越大。
因此,可以选择系数值较大的变量,保留下来进行分析,而将系数值较小的变量剔除。
五、随机森林法随机森林法是一种常用的二分类变量降维方法。
它通过训练一个随机森林模型,得到每个二分类变量的重要性指标,来评估变量的重要性。
重要性指标越大,说明变量对目标变量的影响越大。
因此,可以选择重要性指标较大的变量,保留下来进行分析,而将重要性指标较小的变量剔除。
六、L1正则化法L1正则化法是一种常用的二分类变量降维方法。
线性回归中的相关系数

线性回归中的相关系数文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]线性回归中的相关系数山东胡大波线性回归问题在生活中应用广泛,求解回归直线方程时,应该先判断两个变量是否是线性相关,若相关再求其直线方程,判断两个变量有无相关关系的一种常用的简便方法是绘制散点图;另外一种方法是量化的检验法,即相关系数法.下面为同学们介绍相关系数法.一、关于相关系数法统计中常用相关系数r来衡量两个变量之间的线性相关的强弱,当x不全为零,y ii也不全为零时,则两个变量的相关系数的计算公式是:r就叫做变量y与x的相关系数(简称相关系数).说明:(1)对于相关系数r,首先值得注意的是它的符号,当r为正数时,表示变量x,y正相关;当r为负数时,表示两个变量x,y负相关;(2)另外注意r的大小,如果[]r∈,,那么正相关很强;如果[]0.751r∈--,,那10.75么负相关很强;如果(],或[)r∈,,那么相关性一般;如果0.300.75r∈--0.750.30[]r∈-,,那么相关性较弱.0.250.25下面我们就用相关系数法来分析身边的问题,确定两个变量是否相关,并且求出两个变量间的回归直线.二、典型例题剖析例1测得某国10对父子身高(单位:英寸)如下:(1)对变量y 与x 进行相关性检验;(2)如果y 与x 之间具有线性相关关系,求回归直线方程; (3)如果父亲的身高为73英寸,估计儿子身高.解:(1)66.8x =,67y =,102144794i i x ==∑,102144929.22i i y ==∑,4475.6x y =,24462.24x =,24489y =,10144836.4i i i x y ==∑,所以10i ix ynx yr -=∑80.40.9882.04≈≈, 所以y 与x 之间具有线性相关关系.(2)设回归直线方程为y a bx =+,则101102211010i ii i i x yxyb x x==-=-∑∑44836.4447560.46854479444622.4-=≈-,670.468566.835.7042a y bx =-=-⨯=.故所求的回归直线方程为0.468535.7042y x =+. (3)当73x =英寸时,0.46857335.704269.9047y =⨯+=, 所以当父亲身高为73英寸时,估计儿子的身高约为英寸.点评:回归直线是对两个变量线性相关关系的定量描述,利用回归直线,可以对一些实际问题进行分析、预测,由一个变量的变化可以推测出另一个变量的变化.这是此类问题常见题型.例2 10名同学在高一和高二的数学成绩如下表:其中x 为高一数学成绩,y 为高二数学成绩. (1)y 与x 是否具有相关关系;(2)如果y 与x 是相关关系,求回归直线方程. 解:(1)由已知表格中的数据,利用计算器进行计算得 101710i i x ==∑,101723i i y ==∑,71x =,72.3y =,10151467i i i x y ==∑.102150520ii x==∑,102152541i i y ==∑.0.78=≈.由于0.78r ≈,由0.780.75>知,有很大的把握认为x 与y 之间具有线性相关关系. (2)y 与x 具有线性相关关系,设回归直线方程为y a bx =+,则1011022211051467107172.31.2250520107110i ii i i x yx yb x x==--⨯⨯==≈-⨯-∑∑,72.3 1.227114.32a y bx =-=-⨯=-.所以y 关于x 的回归直线方程为 1.2214.32y x =-.点评:通过以上两例可以看出,回归方程在生活中应用广泛,要明确这类问题的计算公式、解题步骤,并会通过计算确定两个变量是否具有相关关系.。
确定权重的方法

确定权重的方法在进行数据分析和建模的过程中,确定特征的权重是非常重要的一步。
特征的权重可以帮助我们理解特征对于模型预测的贡献程度,进而可以进行特征选择或者模型优化。
本文将介绍几种常用的确定权重的方法,帮助大家更好地理解和应用。
一、相关系数法。
相关系数法是一种常见的确定特征权重的方法。
它通过计算特征与目标变量之间的相关系数来确定特征的重要性。
相关系数的绝对值越大,表示特征对目标变量的影响越大。
在实际应用中,我们可以使用皮尔逊相关系数、斯皮尔曼相关系数或者肯德尔相关系数来进行计算。
相关系数法的优点是简单易懂,但是它只能捕捉线性关系,无法发现非线性关系。
二、决策树法。
决策树法是一种基于树形结构的机器学习算法,可以用来确定特征的重要性。
在决策树算法中,我们可以通过计算特征在决策树中的节点分裂次数或者信息增益来确定特征的重要性。
通常情况下,分裂次数越多或者信息增益越大的特征,其重要性越高。
决策树法的优点是可以发现非线性关系,但是对于高维数据和噪声数据比较敏感。
三、模型权重法。
模型权重法是一种基于模型参数的确定特征权重的方法。
在训练好的模型中,我们可以通过查看特征对应的权重或者系数来确定特征的重要性。
例如,在线性回归模型中,特征的系数大小可以反映其重要性;在逻辑回归模型中,特征的权重可以表示其对于分类的贡献程度。
模型权重法的优点是可以直接捕捉模型的预测能力,但是需要先训练好模型,计算成本较高。
四、特征选择法。
特征选择法是一种基于特征选择算法的确定特征权重的方法。
特征选择算法可以通过计算特征的得分或者重要性来确定特征的权重。
常见的特征选择算法包括方差选择法、互信息法、基于模型的选择法等。
特征选择法的优点是可以综合考虑特征之间的相关性,但是需要根据具体问题选择合适的特征选择算法。
总结。
确定特征的权重是数据分析和建模过程中非常重要的一步。
本文介绍了几种常用的确定权重的方法,包括相关系数法、决策树法、模型权重法和特征选择法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
指标体系的建立
最小均方差法 极大极小离差法 相关系数法
最小均方差法
x1 对于 个取定的被评价对象(或系统), x2 ,, xn,每 个被评价对象都可以用 个指标的观测值
n
来表示。容易看出,如果 个被评价对象关于某 项评价指标的取值都差不多,那么尽管这个评价指 标是非常重要的,但对于这 个被评价对象的评 价结果来说,它并不起什么作用。因此,为了减少 计算量就可以删除这个评价指标。
12 22
1m 2m
mm
m2
②求
max{ ij }
③将指标归并。
推荐文献
徐巧玲 企业技术创新能力评价指标体系筛 选研究 求索 2012年7月 郭秀玲 上官铁梁 旅游影响区等级划分及旅 游影响指标的分析 自然资源学报 2012年1 月 第27卷 第1期 罗亚非 李郭敏 R&D国际化评价指标体系的 构建 科技进步与对策 2011年7月 第28卷第 14期
若存在 k 0 ( 1 k 0 m ),使得 s k0 min{s j }
1 j m
且
s k0 0
则可删除掉与
s k0相应的评价指标 xk
。
0
最小均方差法的实现
EXCEL 应用函数VAR求方差 应用函数SQRT求标准差
推荐文献
张金巍 张延莹 近红外光谱法在线质量监控 白芍工业化提取 中草药 2011年12月第42 卷第12期
极大极小离差法
先求出
x j 个评价指标的最大离差
rj max{ xij xkj }
1i ,k n
rj
,即Βιβλιοθήκη min 再求出 r j 的最小值,即令 r0 1 j m{r j } 当 接近于零时,则可删除掉与 相 0 0 应的评价指标。
r
r
推荐文献
赵安周 白凯 卫海燕 入境旅游目的地城市的 旅游意象评价指标体系研究—以北京和上 海为例 旅游科学 2011年2月 第25卷第1期 邹亮 朱玲湘 基于数据挖掘的地下燃气管道 风险指标体系设计 鞍山科技大学学报 2007 年8月 第30卷第4期
xij (i 1,2,, n; j 1,2,, m)
m
n
n
1 n 记:s ( xij x j ) 2 j n i 1
为评价指标 的按 j 构成的样本均方差。
1 n xij n i 1
j 1,2,, m
x
n 个被评价对象取值
n
其中 x j , j 1,, m , 为评价指标 x j 的按 个被评价对象 取值构成的样本均值。
方法实现
EXCEL
相关系数法
先计算出两两指标的相关系数,形成相关 系数矩阵,从相关系数矩阵中选出相关系 数最大的两个指标进行归并。
x ,x
i j
cov(xi , x j ) Dxi Dx j
(1 i, j m)
①
11 21 m1