数据挖掘作业
数据挖掘作业讲解

《数据挖掘》作业第一章引言一、填空题(1)数据库中的知识挖掘(KDD)包括以下七个步骤:数据清理、数据集成、数据选择、数据变换、数据挖掘、模式评估和知识表示(2)数据挖掘的性能问题主要包括:算法的效率、可扩展性和并行处理(3)当前的数据挖掘研究中,最主要的三个研究方向是:统计学、数据库技术和机器学习(4)在万维网(WWW)上应用的数据挖掘技术常被称为:WEB挖掘(5)孤立点是指:一些与数据的一般行为或模型不一致的孤立数据二、单选题(1)数据挖掘应用和一些常见的数据统计分析系统的最主要区别在于:(B )A、所涉及的算法的复杂性;B、所涉及的数据量;C、计算结果的表现形式;D、是否使用了人工智能技术(2)孤立点挖掘适用于下列哪种场合?(D )A、目标市场分析B、购物篮分析C、模式识别D、信用卡欺诈检测(3)下列几种数据挖掘功能中,( D )被广泛的应用于股票价格走势分析A. 关联分析B.分类和预测C.聚类分析D. 演变分析(4)下面的数据挖掘的任务中,( B )将决定所使用的数据挖掘功能A、选择任务相关的数据B、选择要挖掘的知识类型C、模式的兴趣度度量D、模式的可视化表示(5)下列几种数据挖掘功能中,(A )被广泛的用于购物篮分析A、关联分析B、分类和预测C、聚类分析D、演变分析(6)根据顾客的收入和职业情况,预测他们在计算机设备上的花费,所使用的相应数据挖掘功能是( B )A.关联分析B.分类和预测C. 演变分析D. 概念描述(7)帮助市场分析人员从客户的基本信息库中发现不同的客户群,通常所使用的数据挖掘功能是( C )A.关联分析B.分类和预测C.聚类分析D. 孤立点分析E. 演变分析(8)假设现在的数据挖掘任务是解析数据库中关于客户的一般特征的描述,通常所使用的数据挖掘功能是( E )A.关联分析B.分类和预测C. 孤立点分析D. 演变分析E. 概念描述三、简答题(1)什么是数据挖掘?答:数据挖掘是指从大量数据中提取或“挖掘”知识。
数据挖掘的功能及应用作业

数据挖掘的其他基本功能介绍一、关联规则挖掘关联规则挖掘是挖掘数据库中和指标(项)之间有趣的关联规则或相关关系。
关联规则挖掘具有很多应用领域,如一些研究者发现,超市交易记录中的关联规则挖掘对超市的经营决策是十分重要的。
1、 基本概念设},,,{21m i i i I =是项组合的记录,D 为项组合的一个集合。
如超市的每一张购物小票为一个项的组合(一个维数很大的记录),而超市一段时间内的购物记录就形成集合D 。
我们现在关心这样一个问题,组合中项的出现之间是否存在一定的规则,如A 游泳衣,B 太阳镜,B A ⇒,但是A B ⇒得不到足够支持。
在规则挖掘中涉及到两个重要的指标:① 支持度 支持度n B A n B A )()(⇒=⇒,显然,只有支持度较大的规则才是较有价值的规则。
② 置信度 置信度)()()(A n B A n B A ⇒=⇒,显然只有置信度比较高的规则才是比较可靠的规则。
因此,只有支持度与置信度均较大的规则才是比较有价值的规则。
③ 一般地,关联规则可以提供给我们许多有价值的信息,在关联规则挖掘时,往往需要事先指定最小支持度与最小置信度。
关联规则挖掘实际上真正体现了数据中的知识发现。
如果一个规则满足最小支持度,则称这个规则是一个频繁规则;如果一个规则同时满足最小支持度与最小置信度,则通常称这个规则是一个强规则。
关联规则挖掘的通常方法是:首先挖掘出所有的频繁规则,再从得到的频繁规则中挖掘强规则。
在少量数据中进行规则挖掘我们可以采用采用简单的编程方法,而在大量数据中挖掘关联规则需要使用专门的数据挖掘软件。
关联规则挖掘可以使我们得到一些原来我们所不知道的知识。
应用的例子:* 日本超市对交易数据库进行关联规则挖掘,发现规则:尿片→啤酒,重新安排啤酒柜台位置,销量上升75%。
* 英国超市的例子:大额消费者与某种乳酪。
那么,证券市场上、期货市场上、或者上市公司中存在存在哪些关联规则,这些关联规则究竟说明了什么?关联规则挖掘通常比较适用与记录中的指标取离散值的情况,如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。
数据挖掘作业

证明决策树生长的计算时间最多为 m D log( D ) 。
3.4 考虑表 3-23 所示二元分类问题的数据集。 表 3-23 习题 3.4 数据集
A
B
类标号
T
F
+
T
T
+
T
T
+
T
F
-
T
T
+
F
F
-
F
F
-
F
F
-
T
T
-
T
F
-
(1) 计算按照属性 A 和 B 划分时的信息增益。决策树归纳算法将会选择那个属性?
y ax 转换成可以用最小二乘法求解的线性回归方程。
表 3-25 习题 3.8 数据集
X 0.5 3.0 4.5 4.6 4.9 5.2 5.3 5.5 7.0 9.5
Y-
-
+++-
-
+-
-
根据 1-最近邻、 3-最近邻、 5-最近邻、 9-最近邻,对数据点 x=5.0 分类,使用多数表决。
3.9 表 3-26 的数据集包含两个属性 X 与 Y ,两个类标号“ +”和“ -”。每个属性取三个不同值策略: 0,1 或
记录号
A
B
C
类
1
0
0
0
+
2
0
0
1
-
3
0
1
1
-
4
0
1
1
-
5
0
0
1
+
6
1
0
1
+
7
1
数据挖掘大作业例子

数据挖掘大作业例子1. 超市购物数据挖掘呀!想想看,如果把超市里每个顾客的购买记录都分析一遍,那岂不是能发现很多有趣的事情?比如说,为啥周五晚上大家都爱买啤酒和薯片呢,是不是都打算周末在家看剧呀!2. 社交媒体情感分析这个大作业超有意思哦!就像你能从大家发的文字里看出他们今天是开心还是难过,那简直就像有了读心术一样神奇!比如看到一堆人突然都在发伤感的话,难道是发生了什么大事情?3. 电商用户行为挖掘也很棒呀!通过分析用户在网上的浏览、购买行为,就能知道他们喜欢什么、不喜欢什么,这难道不是很厉害吗?就像你知道了朋友的喜好,能给他推荐最适合的礼物一样!4. 交通流量数据分析呢!想象一下,了解每个路口的车流量变化,是不是就能更好地规划交通啦?难道这不像是给城市的交通装上了一双明亮的眼睛?5. 医疗数据挖掘更是不得了!能从大量的病例中找到疾病的规律,这简直是在拯救生命啊!难道这不是一件超级伟大的事情吗?比如说能发现某种疾病在特定人群中更容易出现。
6. 金融交易数据挖掘也超重要的呀!可以知道哪些交易有风险,哪些投资更靠谱,那不就像有个聪明的理财顾问在身边吗!就好比能及时发现异常的资金流动。
7. 天气数据与出行的结合挖掘也很有趣呀!根据天气情况来预测大家的出行选择,真是太神奇了吧!难道不是像有了天气预报和出行指南合二为一?8. 音乐喜好数据挖掘呢!搞清楚大家都喜欢听什么类型的音乐,从而能更好地推荐歌曲,这不是能让人更开心地享受音乐吗!好比为每个人定制了专属的音乐播放列表。
9. 电影票房数据挖掘呀!通过分析票房数据就能知道观众最爱看的电影类型,这不是超厉害的嘛!就像知道了大家心里最期待的电影是什么样的。
我觉得数据挖掘真的太有魅力了,可以从各种看似普通的数据中发现那么多有价值的东西,真是让人惊叹不已啊!。
数据挖掘作业
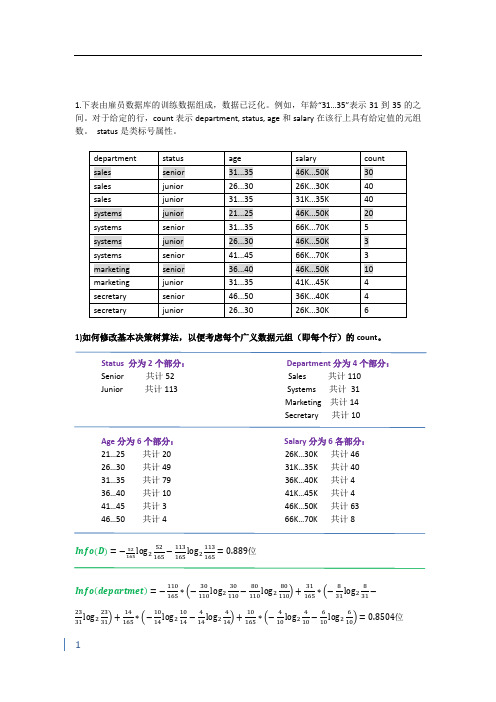
1.下表由雇员数据库的训练数据组成,数据已泛化。
例如,年龄“31…35”表示31到35的之间。
对于给定的行,count表示department, status, age和salary在该行上具有给定值的元组数。
status是类标号属性。
1)如何修改基本决策树算法,以便考虑每个广义数据元组(即每个行)的count。
Status 分为2个部分:Department分为4个部分:Senior 共计52 Sales 共计110Junior 共计113 Systems 共计31Marketing 共计14Secretary 共计10Age分为6个部分:Salary分为6各部分:21…25 共计20 26K…30K 共计4626…30 共计49 31K…35K 共计4031…35 共计79 36K…40K 共计436…40 共计10 41K…45K 共计441…45 共计3 46K…50K 共计6346…50 共计4 66K…70K 共计8Info(D)=−52165log252165−113165log2113165=0.889位Info(departmet)=−110165∗(−30110log230110−80110log280110)+31165∗(−831log2831−23 31log22331)+14165∗(−1014log21014−414log2414)+10165∗(−410log2410−610log2610)=0.8504位Gain(department)=Info(D)−Info(department)=0.0386位Info(age)=−20165∗(−020log2020−2020log22020)+49165∗(−049log2049−4949log24949)+79165∗(−3579log23575−3479log23479)+10165∗(−1010log21010−010log2010)+3165∗(−33log233−03log203)+4 165∗(−44log244−04log204)=0.4998位Gain(age)=Info(D)−Info(age)=0.3892位Info(salary)=−46165∗(−046log2046−4646log24646)+40165∗(−040log2040−4040log24040)+4165∗(−44log244−04log204)+63165∗(−3063log23063−3363log23363)+8165∗(−88log288−08log208)=0.3812位Gain(salary)=Info(D)−Info(salary)=0.5078位由以上的计算知按信息增益从大到小对属性排列依次为:salary、age、department,所以定由这个表可知department和age的信息增益将都为0。
数据挖掘作业

1、给出K D D的定义和处理过程。
KDD的定义是:从大量数据中提取出可信的、新颖的、有用的且可以被人理解的模式的高级处理过程。
因此,KDD是一个高级的处理过程,它从数据集中识别出以模式形式表示的知识。
这里的“模式”可以看成知识的雏形,经过验证、完善后形成知识:“高级的处理过程”是指一个多步骤的处理过程,多步骤之间相互影响反复调整,形成一种螺旋式上升的过程。
KDD的全过程有五个步骤:1、数据选择:确定发现任务的操作对象,即目标数据,它是根据用户的需要从原始数据库中抽取的一组数据;2、数据预处理:一般可能包括消除噪声、推到技术却只数据、消除重复记录、完成数据类型转换等;3、数据转换:其主要目的是消减数据维数或降维,即从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数;4、数据挖掘:这一阶段包括确定挖掘任务/目的、选择挖掘方法、实施数据挖掘;5、模式解释/评价:数据挖掘阶段发现出来的模式,经过用户或机器的评价,可能存在冗余或无关的模式,需要剔除;也有可能模式不满足用户的要求,需要退回到整个发现阶段之前,重新进行KDD过程。
2、阐述数据挖掘产生的背景和意义。
数据挖掘产生的背景:随着信息科技的进步以及电子化时代的到来,人们以更快捷、更容易、更廉价的方式获取和存储数据,使得数据及信息量以指数方式增长。
据粗略估计,一个中等规模企业每天要产生100MB以上的商业数据。
而电信、银行、大型零售业每天产生的数据量以TB来计算。
人们搜集的数据越来越多,剧增的数据背后隐藏着许多重要的信息,人们希望对其进行更高层次的分析,以便更好的利用这些数据。
先前的数据库系统可以高效的实现数据的录入、查询、统计等功能,但无法发现数据中存在的关系与规则,无法根据现有的数据来预测未来的发展趋势。
缺乏挖掘数据背后隐藏的知识的手段。
导致了“数据爆炸但知识贫乏”的现象。
于是人们开始提出“要学会选择、提取、抛弃信息”,并且开始考虑:如何才能不被信息淹没?如何从中及时发现有用的知识、提高信息利用率?如何从浩瀚如烟海的资料中选择性的搜集他们认为有用的信息?这给我们带来了另一些头头疼的问题:第一是信息过量,难以消化;第二是信息真假难以辨别;第三是信息安全难以保证;第四是信息形式不一致,难以统一处理面对这一挑战,面对数量很大而有意义的信息很难得到的状况面对大量繁杂而分散的数据资源,随着计算机数据仓库技术的不断成熟,从数据中发现知识(Knowledge Discovery in Database)及其核心技术——数据挖掘(Data Mining)便应运而生,并得以蓬勃发展,越来越显示出其强大的生命力。
Python数据挖掘课程设计作业
Python数据挖掘课程设计作业一、教学目标本课程旨在通过Python语言的数据挖掘技术,使学生掌握数据处理、分析与挖掘的基本方法,培养学生的数据敏感度、逻辑思维能力和解决实际问题的能力。
知识目标包括:理解数据挖掘的基本概念、方法和流程;掌握Python编程基础,能够使用Python进行简单的数据处理和分析;了解常见的数据挖掘算法,并能够运用这些算法解决实际问题。
技能目标包括:能够使用Python进行数据清洗、数据可视化、数据挖掘算法实现;能够独立完成数据挖掘项目,并对结果进行解释和分析。
情感态度价值观目标包括:培养学生对数据的热爱和好奇心,提高学生运用数据分析和解决实际问题的意识,培养学生的团队合作精神和创新思维。
二、教学内容本课程的教学内容主要包括Python编程基础、数据处理与分析、数据挖掘算法及应用等方面。
教学大纲安排如下:1.Python编程基础:介绍Python的基本语法、数据类型、控制结构、函数、模块等,使学生能够熟练使用Python进行编程。
2.数据处理与分析:讲解如何使用Python进行数据读取、清洗、转换、聚合等操作,以及如何利用Python进行数据可视化,使学生能够对数据进行有效的处理和分析。
3.数据挖掘算法:介绍常见的数据挖掘算法,如分类、回归、聚类、关联规则等,并讲解如何使用Python实现这些算法,使学生能够理解和运用数据挖掘算法。
4.数据挖掘应用:结合实际案例,讲解如何使用Python进行数据挖掘项目的实现,使学生能够独立完成数据挖掘项目,并对结果进行解释和分析。
三、教学方法为了提高学生的学习兴趣和主动性,本课程将采用多种教学方法,如讲授法、讨论法、案例分析法、实验法等。
在教学过程中,教师将引导学生通过实际操作来掌握Python编程和数据挖掘技术,同时鼓励学生积极参与课堂讨论,培养学生的团队协作能力和创新思维。
四、教学资源本课程的教学资源包括教材、参考书、多媒体资料和实验设备等。
南开19春学期(1709、1803、1809、1903)《数据挖掘》在线作业-2(答案)
南开19春学期(1709、1803、1809、1903)《数据挖掘》在线作业-2一、单选题共20题,40分1、( )用替代的、较小的数据表示形式替换原数据。
A维归约B数量归约C离散D聚集【南开】答案是:B2、只有非零值才重要的二元属性被称作( )。
A计数属性B离散属性C非对称的二元属性D对称属性【南开】答案是:C3、职位可以按顺序枚举,对于教师有:助教、讲师、副教授、教授。
职位属性是( )。
A标称属性B序数属性C数值属性D二元属性【南开】答案是:B4、( )去掉数据中的噪声,这类技术包括分箱、回归和聚类。
A光滑B聚集C规范化D属性构造【南开】答案是:A5、在基于规则分类器的中,依据规则质量的某种度量对规则排序,保证每一个测试记录都是由覆盖它的“最好的”规格来分类,这种方案称为( )。
A基于类的排序方案B基于规则的排序方案C基于度量的排序方案D基于规格的排序方案【南开】答案是:B6、分位数是取自数据分布的每隔一定间隔上的点,把数据划分成基本上大小相等的连贯集合。
如:4-分位数是( )个数据点,它们把数据分布划分成4个相等的部分,使得每部分表示数据分布的四分之一。
A1B2C3D4【南开】答案是:C7、决策树学习:决策树算法对数据处理过程中,将数据按( )结构分成若干分枝形成决策树,从根到树叶的每条路径创建一个规则。
A树状B网状C星形D雪花形【南开】答案是:A8、以下属于可伸缩聚类算法的是( )。
ACUREBDENCLUECCLIQUEDOPOSSUM【南开】答案是:A9、( )将两个簇的邻近度定义为不同簇的所有点对的平均逐对邻近度,它是一种凝聚层次聚类技术。
AMIN(单链)BMAX(全链)C组平均DWard方法【南开】答案是:C10、如果规则集R中不存在两条规则被同一条记录触发,则称规则集R中的规则为( )。
A无序规则B穷举规则C互斥规则D有序规则【南开】答案是:C11、( )是KDD。
A数据挖掘与知识发现B领域知识发现C文档知识发现D动态知识发现【南开】答案是:A12、在有关数据仓库测试,下列说法不正确的是( )。
数据挖掘期末大作业
数据挖掘期末大作业1.数据挖掘的发展趋势是什么?大数据环境下如何进行数据挖掘。
对于数据挖掘的发展趋势,可以从以下几个方面进行阐述:(1)数据挖掘语言的标准化描述:标准的数据挖掘语言将有助于数据挖掘的系统化开发。
改进多个数据挖掘系统和功能间的互操作,促进其在企业和社会中的使用。
(2)寻求数据挖掘过程中的可视化方法:可视化要求已经成为数据挖掘系统中必不可少的技术。
可以在发现知识的过程中进行很好的人机交互。
数据的可视化起到了推动人们主动进行知识发现的作用。
(3)与特定数据存储类型的适应问题:根据不同的数据存储类型的特点,进行针对性的研究是目前流行以及将来一段时间必须面对的问题。
(4)网络与分布式环境下的KDD问题:随着Internet的不断发展,网络资源日渐丰富,这就需要分散的技术人员各自独立地处理分离数据库的工作方式应是可协作的。
因此,考虑适应分布式与网络环境的工具、技术及系统将是数据挖掘中一个最为重要和繁荣的子领域。
(5)应用的探索:随着数据挖掘的日益普遍,其应用范围也日益扩大,如生物医学、电信业、零售业等领域。
由于数据挖掘在处理特定应用问题时存在局限性,因此,目前的研究趋势是开发针对于特定应用的数据挖掘系统。
(6)数据挖掘与数据库系统和Web数据库系统的集成:数据库系统和Web数据库已经成为信息处理系统的主流。
2. 从一个3输入、2输出的系统中获取了10条历史数据,另外,最后条数据是系统的输入,不知道其对应的输出。
请使用SQL SERVER 2005的神经网络功能预测最后两条数据的输出。
首先,打开SQL SERVER 2005数据库软件,然后在界面上右键单击树形图中的“数据库”标签,在弹出的快捷菜单中选择“新建数据库”命令,并命名数据库的名称为YxqDatabase,单击确定,如下图所示。
然后,在新建的数据库YxqDatabas中,根据题目要求新建表,相应的表属性见下图所示。
在新建的表完成之后,默认的数据表名称为Table_1,并打开表,根据题目提供的数据在表中输入相应的数据如下图所示。
weka数据挖掘期末大作业
Weka数据挖掘期末大作业是一个非常重要的任务。
它涉及到许多数据挖掘技术,可以帮助学生们了解数据挖掘的核心概念,以及如何应用这些技术来解决实际问题。
首先,学生需要了解Weka数据挖掘工具,包括其特点和功能。
Weka是一个开源的数据挖掘工具,它提供了各种有用的算法,可以帮助学生们进行数据分析,比如分类、聚类和关联分析。
Weka还有一个灵活的用户界面,可以让学生们轻松地查看和编辑数据。
其次,学生还需要了解如何通过Weka来完成期末大作业。
学生可以使用Weka的GUI工具,轻松地训练和评估机器学习模型。
另外,学生还可以使用Weka的API,在Java或其他编程语言中编写自己的算法。
第三,学生还需要考虑如何将实际问题转换为可以在Weka中解决的问题。
这要求学生们了解数据挖掘的基本概念,如数据预处理、特征选择、模型训练和评估。
最后,期末大作业还需要学生提交一份报告,说明他们在数据挖掘中学到的内容。
报告中需要包括算法的细节,以及实验结果分析,以便说明学生们是如何使用Weka解决实际问题的。
总之,Weka数据挖掘期末大作业是一个很重要的任务,可以帮助学生们更好地理解数据挖掘技术,以及如何将其应用于实际问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第3章分类与回归
3.1简述决策树分类的主要步骤。
3.2给定决策树,选项有:(1)将决策树转换成规则,然后对结果规则剪枝,或(2)对决策树剪枝,然后将剪
枝后的树转换成规则。
相对于(2),(1)的优点是什么?
3.3计算决策树算法在最坏情况下的时间复杂度是重要的。
给定数据集D,具有m个属性和|D|个训练记录,
证明决策树生长的计算时间最多为)
⨯。
m⨯
D
log(D
3.4考虑表3-23所示二元分类问题的数据集。
(1)计算按照属性A和B划分时的信息增益。
决策树归纳算法将会选择那个属性?
(2)计算按照属性A和B划分时Gini系数。
决策树归纳算法将会选择那个属性?
3.5证明:将结点划分为更小的后续结点之后,结点熵不会增加。
3.6为什么朴素贝叶斯称为“朴素”?简述朴素贝叶斯分类的主要思想。
3.7考虑表3-24数据集,请完成以下问题:
(1)估计条件概率)
|-
C。
P)
A
(+
|
(2)根据(1)中的条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号;
(3)使用Laplace估计方法,其中p=1/2,l=4,估计条件概率)
P,)
C
(+
|
(-
P,
A
|
|
(+
P,)
P,)
A
(+
B
|
(-
P。
|
C
(-
P,)
|
)
B
(4)同(2),使用(3)中的条件概率
(5)比较估计概率的两种方法,哪一种更好,为什么?
3.8考虑表3-25中的一维数据集。
表3-25 习题3.8数据集
根据1-最近邻、3-最近邻、5-最近邻、9-最近邻,对数据点x=5.0分类,使用多数表决。
3.9 表3-26的数据集包含两个属性X 与Y ,两个类标号“+”和“-”。
每个属性取三个不同值策略:0,1或
2。
“+”类的概念是Y=1,“-”类的概念是X=0 and X=2。
(1) 建立该数据集的决策树。
该决策树能捕捉到“+”和“-”的概念吗?
(2) 决策树的准确率、精度、召回率和F1各是多少?(注意,精度、召回率和F1量均是对“+”类定
义)
(3) 使用下面的代价函数建立新的决策树,新决策树能捕捉到“+”的概念么?
⎪⎪⎪⎩⎪
⎪⎪⎨⎧+=-=+--=+===
j i j i j i j i C ,,10),(如果实例个数
实例个数如果如果
(提示:只需改变原决策树的结点。
)
3.10 什么是提升?陈述它为何能提高决策树归纳的准确性? 3.11 表3-27给出课程数据库中学生的期中和期末考试成绩。
表3-27 习题3.11数据集
(1) 绘制数据的散点图。
X 和Y 看上去具有线性联系吗?
(2) 使用最小二乘法,由学生课程中成绩预测学生的期末成绩的方程式。
(3) 预测期中成绩为86分的学生的期末成绩。
3.12通过对预测变量变换,有些非线性回归模型可以转换成线性模型。
指出如何将非线性回归方程
β
y=转换成可以用最小二乘法求解的线性回归方程。
ax。