第22章spss21教程完整版课件
合集下载
SPSS教程全套教学课件

2.3.3 数据的排序
在数据文件中,可根据一个或多个排序变 量的值重排个案的顺序。
图2-10 “Sort Cases”(排序)对话框
2.3.4 数据的行列互换
图2-11 “Transpose”对话框
2.3.5 选取个案子集
在数据统计中可从所有资料中选择部分数 据进行统计分析。
图2-12 “Select Cases”对话框
菜单栏 工具栏 内容区
标题栏
窗口切 换标签
页
状态栏
编辑栏
变量名栏
图1-2 数据编辑窗口
该窗口下方有两个标签:“Data View” (数据视图)和“Variable View”(变量视 图)。
如果使用过电子表格,如Microsoft Excel等,那么数据编辑窗口中“Data View” 所对应表格许多功能应该已经熟悉。但是它和 一般的电子表格处理软件还有以下区别。
数据录入时可以逐行录入,也可以逐列。
2.2.2 录入带有变量值标签的数据
在录入带有变量值标签的数据时,用户手 工输入的是实际的变量值,而屏幕上显示的是 与该变量对应的变量值标签。
图2-6 选中“Value Lables”的效果
2.2.3 SPSS数据文件的保存
在录入数据时,应及时保存数据,防止数 据的丢失,以便再次使用该数据 。
定义变量类型对话框
• SPSS的保留字(Reserved Keywords)不能 作为变量的名称,如ALL、AND、WITH、OR等。
2.定义变量类型(Type)
单击Type相应单元中的按钮,弹出如图23所示的对话框,在对话框中选择合适的变量 类型并单击“OK”按钮,即可定义变量类型。
图2-3 定义变量类型对话框
SPSS21PPT

SPSS是软件英文名称的首字母缩写,原意为Statistical Package for the Social Sciences,即“社会科学统计软件 包”。它是目前世界上流行的三大统计分析软件之一(SAS、 SPSS及SYSTAT)。在我国,SPSS以其强大的统计分析功能、方 便的用户操作界面、灵活的表格式报告及其精美的图形展现, 受到了社会各界统计分析人员的喜爱。
数据编辑窗口
SPSS的结果输出窗口一般随执 行统计分析命令而打开,用于 显示统计分析结果、统计报告、 统计图表等内容,如图1-3所示。 允许用户对输出结果进行常规 的编辑整理,窗口内容可以直 接保存,保存文件的扩展名为 “*.spv”。
图1-3 结果输出窗口
● 【文件】→【新建】→【语法】命令,新建一个SPSS的语 句 文件;如图1-4所示。 ● 或者执行【文件】→【打开】→【语法】命令,打开一个保 存的语句文件。
图1-16【帮助】菜单
●当首次安装软件时,SPSS界面为中文显示,此时可以采用 如下方法将其转换为英文界面: ● 1 选择菜单栏中的【编辑】→【选项】命令,弹出如图117所示的【选项】对话框。 ● 2 在【用户界面】选项组的【语言】下拉列表框中选择 【英语】选项,表示选定软件以英文界面显示 ● 3 单击【确定】按钮,即可将SPSS软件的界面语言转换 成简体中文。 如果需要从中文界面转换为其它语言界面,也可按照上述操 作来实现。
图1-14【图形】菜单
【实用程序】菜单可以显示 数据文件和变量的信息、定 义子集、运行脚本程序、自 定义SPSS菜单等,如图115所示。
图1-15【实用程序】菜单
1.6.11 【窗口】菜单
【窗口】菜单提供了数据窗口最小化、数据编辑窗 口和结果输出窗口等的切换功能。
数据编辑窗口
SPSS的结果输出窗口一般随执 行统计分析命令而打开,用于 显示统计分析结果、统计报告、 统计图表等内容,如图1-3所示。 允许用户对输出结果进行常规 的编辑整理,窗口内容可以直 接保存,保存文件的扩展名为 “*.spv”。
图1-3 结果输出窗口
● 【文件】→【新建】→【语法】命令,新建一个SPSS的语 句 文件;如图1-4所示。 ● 或者执行【文件】→【打开】→【语法】命令,打开一个保 存的语句文件。
图1-16【帮助】菜单
●当首次安装软件时,SPSS界面为中文显示,此时可以采用 如下方法将其转换为英文界面: ● 1 选择菜单栏中的【编辑】→【选项】命令,弹出如图117所示的【选项】对话框。 ● 2 在【用户界面】选项组的【语言】下拉列表框中选择 【英语】选项,表示选定软件以英文界面显示 ● 3 单击【确定】按钮,即可将SPSS软件的界面语言转换 成简体中文。 如果需要从中文界面转换为其它语言界面,也可按照上述操 作来实现。
图1-14【图形】菜单
【实用程序】菜单可以显示 数据文件和变量的信息、定 义子集、运行脚本程序、自 定义SPSS菜单等,如图115所示。
图1-15【实用程序】菜单
1.6.11 【窗口】菜单
【窗口】菜单提供了数据窗口最小化、数据编辑窗 口和结果输出窗口等的切换功能。
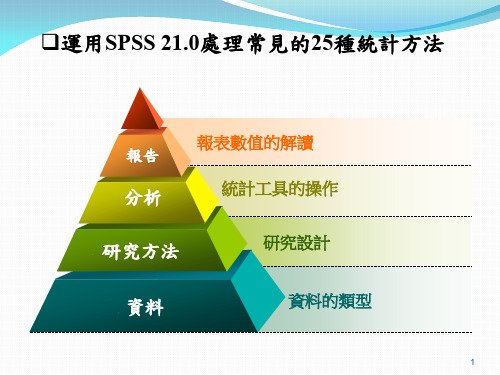
运用SPSS21.0处理常见的 25种统计方法ppt课件
無 因 果 關
係
1.敘述性統計 2.複選題分析 3.(多重)交叉分析 4.卡方(同質,獨立, 適合度)檢定
因 果 9.Logistic迴歸 關 10. 區別分析 係
連續變數
5.主成份分析 6.因素分析 7.集群分析 8.(偏)相關分析
11.偏相關分析 12.迴歸分析 13.路徑分析 14變異數分析 15.偏最小平方迴歸
相關係數介於-1至1之間。
61
迴歸分析(Regression)
基本條件: 連續變項之間的關係 線性關係 (linear relationship) ,指兩個變項的
關係可以被一條最具代表性的直線來表達之時 ,所存在的關連情形。
迴歸分析的結果無法證明 x 和 y 之間有因果關 係存在。
43
複選題實務上的意義
$ c7 次數
$c7a
c7m1 價格便宜
c7m2 功能齊全
c7m3 造形酷炫
c7m4 廠牌因素
c7m5 通話費率
c7m6 國際漫遊
c7m7 服務態度
c7m8 促銷活動
c7m9 申請手續方便
c7m10 通話品質
c7m11 體積小
c7m12 售後服務
c7m13 帳單可靠
c7m14 其他
只能有兩個變數
29
多重交叉分析 (多重列聯表分析)
變數須為名目尺度(不連續變數)
性別:男、女 地區:如北、中、南 傳播媒體:電子媒體、平面媒體、網路媒體
三個變數以上,但仍以三個為主
30
無反應偏差分析
交叉(卡方)分析
1. 同質性檢定 2. 適合度檢定 3. 獨立性檢定
31
平均數、眾數與中位數接近表示資料符合常態。 變異數(或標準差)太小,表示尺度過於集中,該題應予
SPSS入门讲义 ppt课件

医学课件 3
SPSS软件的特点
①集数据录入、资料编辑、数据管理、统 计分析、报表制作、图形绘制为一体。从 理论上说,只要计算机硬盘和内存足够大, SPSS可以处理任意大小的数据文件,无论 文件中包含多少个变量,也不论数据中包 含多少个案例
医学课件
4
②统计功能囊括了《教育统计学》中所有的项 目,包括常规的集中量数和差异量数、 相关 分析、回归分析、方差分析、卡方检验、t检 验和非参数检验;也包括近期发展的多元统计 技术,如多元回归分析、聚类分析、判别分析、 主成分分析和因子分析等方法,并能在屏幕 (或打印机)上显示(打印)如正态分布图、直方 图、散点图等各种统计图表。从某种意义上讲, SPSS软件还可以帮助数学功底不够的使用者学 习运用现代统计技术。使用者仅需要关心某个 问题应该采用何种统计方法,并初步掌握对计 算结果的解释,而不需要了解其具体运算过程, 可能在使用手册的帮助下定量分析数据。
医学课件 2
目前,世界上最著名的数据分析软件是SAS和 SPSS。SAS由于是为专业统计分析人员设计的, 具有功能强大,灵活多样的特点,为专业人士 所喜爱。而SPSS是为广大的非专业人士设计, 它操作简便,好学易懂,简单实用,因而很受 非专业人士的青睐。此外,比起SAS软件来, SPSS主要针对着社会科学研究领域开发,因而 更适合应用于教育科学研究,是国外教育科研 人员必备的科研工具。1988年,中国高教学会 首次推广了这种软件,从此成为国内教育科研 人员最常用的工具。
医学课件 47
示例1
某物质在处理前与处理后分别抽样分析其 含脂率如下 处理前(Xi) 0.19 0.18 0.21 0.30 0.41 0.12 0.27 处理后(Yi) 0.15 0.13 0.07 0.24 0.19 0.06 0.08 0.12
SPSS软件的特点
①集数据录入、资料编辑、数据管理、统 计分析、报表制作、图形绘制为一体。从 理论上说,只要计算机硬盘和内存足够大, SPSS可以处理任意大小的数据文件,无论 文件中包含多少个变量,也不论数据中包 含多少个案例
医学课件
4
②统计功能囊括了《教育统计学》中所有的项 目,包括常规的集中量数和差异量数、 相关 分析、回归分析、方差分析、卡方检验、t检 验和非参数检验;也包括近期发展的多元统计 技术,如多元回归分析、聚类分析、判别分析、 主成分分析和因子分析等方法,并能在屏幕 (或打印机)上显示(打印)如正态分布图、直方 图、散点图等各种统计图表。从某种意义上讲, SPSS软件还可以帮助数学功底不够的使用者学 习运用现代统计技术。使用者仅需要关心某个 问题应该采用何种统计方法,并初步掌握对计 算结果的解释,而不需要了解其具体运算过程, 可能在使用手册的帮助下定量分析数据。
医学课件 2
目前,世界上最著名的数据分析软件是SAS和 SPSS。SAS由于是为专业统计分析人员设计的, 具有功能强大,灵活多样的特点,为专业人士 所喜爱。而SPSS是为广大的非专业人士设计, 它操作简便,好学易懂,简单实用,因而很受 非专业人士的青睐。此外,比起SAS软件来, SPSS主要针对着社会科学研究领域开发,因而 更适合应用于教育科学研究,是国外教育科研 人员必备的科研工具。1988年,中国高教学会 首次推广了这种软件,从此成为国内教育科研 人员最常用的工具。
医学课件 47
示例1
某物质在处理前与处理后分别抽样分析其 含脂率如下 处理前(Xi) 0.19 0.18 0.21 0.30 0.41 0.12 0.27 处理后(Yi) 0.15 0.13 0.07 0.24 0.19 0.06 0.08 0.12
SPSS超级完整版教程PPT课件

▪ 按观察单位(按行输入)输入数据 将光标移 动要输入的观察单位,单击鼠标,将该观察单 位标记,输入变量的第一个值,按“Tab” 或 “”键,输入第二个数据。
▪ 按单元格输入数据 将光标移动到想要输入的
单元格,单击鼠标,输入变量值,按回车键。
2020/1/1也0 可按此法修改变量第一值章 。绪论
35
▪ 定义变量名标签是对变量名做进一步说明。
▪ 如果变量名已经说明了变量的内涵,则不必设置 变量名标签。如性别、血型、name,等
▪ 有时,变量名不能明确表示该变量的含义。如
date_in。变量名标签设置为“入院时间”。
▪ 变量标签不受字符位数的限制,可以用英文或中 文表示。
▪ 在统计分析的输出结果中,可显示变量的英文或 中文标签,使输出结果的可读性更好。
4
4
2 王武 1 65 10/25/200 11/28/200 0
4
4
3 陈杉 2 39 12/14/200 01/13/200 0
4
5
4 李思 2 30 11/22/200 12/29/200 1
4
4
5 欧阳山 1 57 12/01/200 01/15/200 2
4
5
6
赵杉
2020/1/10
2 13 10/01/200 11/18/200 1
▪ 本例的性别分别用数值1和2表示男性、女性。这 时的1和2已经没有数值大小的含义,故可以定义 为字符变量,测量类型为Nominal。但为了操作 方便和某些统计分析,还是经常把它定义为数值 变量,默认测量类型为Scale。
▪ 单击变量窗口左下方的Data 2020/窗1/1口0 转为数据窗口。 第一章 绪论
2020/1/10
SPSS21使用教程(最新)

4
SPSS 应用软件试验指导手册
试验1 数据文件管理
一、试验目的与要求
通过本试验项目,使学生理解并掌握 SPSS 软件包有关数据文件创建和整理的 基本操作,学习如何将收集到的数据输入计算机,建成一个正确的 SPSS 数据文件, 并掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排 序等等。
spss应用软件试验指导手册试验1数据文件管理一试验目的与要求通过本试验项目使学生理解并掌握spss软件包有关数据文件创建和整理的基本操作学习如何将收集到的数据输入计算机建成一个正确的spss数据文件并掌握如何对原始数据文件进行整理包括数据查询数据修改删除数据的排序等等
SPSS 应用软件试验指导手册
11
SPSS 应用软件试验指导手册
件进行合并,收集来的数据被放置在一个新的数据文件中。在 SPSS 中实现数据文 件横向合并的方法如下: 选择菜单【数据】→【合并文件】→【添加变量】,选择合并的数据文件,单击 “打开” ,弹出添加变量,如图 2.12 所示。
图 2.12
单击 Ok 执行合并命令。这样,两个数据文件将按观测的顺序一对一地横向 合并。 (5)数据拆分(Split File) 在进行统计分析时, 经常要对文件中的观测进行分组, 然后按组分别进行分析。 例如要求按性别不同分组。在 SPSS 中具体操作如下:
5
SPSS 应用软件试验指导手册
图 2.1 变量视窗
三、试验内容与步骤
1.创建一个数据文件 数据文件的创建分成三个步骤: (1)选择菜单 【文件】→【新建】→【数据】新建一个数据文件,进入数据 编辑窗口。窗口顶部标题为“PASW Statistics 数据编辑器” 。 (2)单击左下角【变量视窗】标签进入变量视图界面,根据试验的设计定义每 个变量类型。 (3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具 体的变量值录入数据库单元格内。 2.读取外部数据 当前版本的 SPSS 可以很容易地读取 Excel 数据,步骤如下: (1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话 框,在文件类型下拉列表中选择数据文件,如图 2.2 所示。
Spss实用统计分析PPT课件
第27页/共84页
单击Statistics按钮,打开OLAP Cubes:Statistics对话框
对话框左边的统计量清单框中,列出供选择使用的各种统计量。右边Cell Statistics框,接纳用户选择的统计量,凡选入的统计量在输出的分层报告表的 单元格里显示他们的值。
第28页/共84页
单击Title按钮,打开OLAP Cubes:Title话框
频数分析
Descriptives Statistics Descriptives…
统计描述
(描述性统计)
Explore…
数据探索
Crosstabs…
交叉表,或列联表
Compare Means
Ratio… Means…
比率统计 均值比较
(均值比较)
One-Sample T Test…
单样本T检验
Independent-Sample T Test… 独立样本T检验
Categorize Variables… Rank Cases…
Into Same Variable… Into Defferent Variable…
Automatic Recode… Create Time Series… Replace Missing Values
Run Pending Transforms
下面我们将列出所有的统计分析功能:
第12页/共84页
子菜单
用途说明
OLAP Cubes…
层分析报告
Reports(统计报告)
Case Summaries
观测量概述
Report Summaries in Rows 行概述报告
Report Summaries in Colums 列概述报告
单击Statistics按钮,打开OLAP Cubes:Statistics对话框
对话框左边的统计量清单框中,列出供选择使用的各种统计量。右边Cell Statistics框,接纳用户选择的统计量,凡选入的统计量在输出的分层报告表的 单元格里显示他们的值。
第28页/共84页
单击Title按钮,打开OLAP Cubes:Title话框
频数分析
Descriptives Statistics Descriptives…
统计描述
(描述性统计)
Explore…
数据探索
Crosstabs…
交叉表,或列联表
Compare Means
Ratio… Means…
比率统计 均值比较
(均值比较)
One-Sample T Test…
单样本T检验
Independent-Sample T Test… 独立样本T检验
Categorize Variables… Rank Cases…
Into Same Variable… Into Defferent Variable…
Automatic Recode… Create Time Series… Replace Missing Values
Run Pending Transforms
下面我们将列出所有的统计分析功能:
第12页/共84页
子菜单
用途说明
OLAP Cubes…
层分析报告
Reports(统计报告)
Case Summaries
观测量概述
Report Summaries in Rows 行概述报告
Report Summaries in Colums 列概述报告
SPSS教程PPT课件
优点:数据之间没有间隔,录入速度快。 缺点:易错位,发生错误不易修改。
2-2 SPSS数据编辑器录入
优点:不易错位。 缺点:不易后移,录入速度慢
附1:正规编码表
变量名 Num W01 W01A W02 W03 W04 W05.1 W05.2
码位 1-4 5 6-7 8 9 10 11 12
4-1 编辑一个SPSS可执行的程序(包括数据定义、数据 和统计过程,即命令),然后放在OPEN到SPSS系统中。
4-2 从菜单中选择一个统计过程。 4-3 从SPSS对话框中,选变量清单及统计量,然后点
num 1-4
2-1-3具体规定和要求
1)变量名不能超过8个字符; 2)变量名不能用中文,只能用字母(西文); 3)变量名不能用数字开头,可用字母、符号; 4)变量名中不能包含+、-等运算符号和>、=、&、│、…等逻辑符号; 5)当相邻变量名称上存在顺序且码数相同时,可用简化方式。如:w02
to w04 8-10; 6)当变量是字符时,在码数后加(a);如:w07 12 (a); *当变量值含小数时,在码数后加(n),n表示小数的位数。如:446.79,
或 Data list file= ‘C:\lianxi\lianxi.dat’/ num 1-4 w01 5 w01a 6-7 w02 8 w03 9.
2-1-2 注: 1.变量名唯一 一个变量名只能给一个变量。
2.写法 码位中间用“-”连接。 如: Data list file= ‘C:\lianxi\lianxi.dat’/
2. 特 点
2-1 操作简便,易学易用。 2-2 命令语句等绝大部分由“对话框”的操作完成, 无须更多记忆 2-3 运行速度提高。 2-4 与其它软件有数据转换接口 2-5 分析方法丰富 2-6 界面改进
2-2 SPSS数据编辑器录入
优点:不易错位。 缺点:不易后移,录入速度慢
附1:正规编码表
变量名 Num W01 W01A W02 W03 W04 W05.1 W05.2
码位 1-4 5 6-7 8 9 10 11 12
4-1 编辑一个SPSS可执行的程序(包括数据定义、数据 和统计过程,即命令),然后放在OPEN到SPSS系统中。
4-2 从菜单中选择一个统计过程。 4-3 从SPSS对话框中,选变量清单及统计量,然后点
num 1-4
2-1-3具体规定和要求
1)变量名不能超过8个字符; 2)变量名不能用中文,只能用字母(西文); 3)变量名不能用数字开头,可用字母、符号; 4)变量名中不能包含+、-等运算符号和>、=、&、│、…等逻辑符号; 5)当相邻变量名称上存在顺序且码数相同时,可用简化方式。如:w02
to w04 8-10; 6)当变量是字符时,在码数后加(a);如:w07 12 (a); *当变量值含小数时,在码数后加(n),n表示小数的位数。如:446.79,
或 Data list file= ‘C:\lianxi\lianxi.dat’/ num 1-4 w01 5 w01a 6-7 w02 8 w03 9.
2-1-2 注: 1.变量名唯一 一个变量名只能给一个变量。
2.写法 码位中间用“-”连接。 如: Data list file= ‘C:\lianxi\lianxi.dat’/
2. 特 点
2-1 操作简便,易学易用。 2-2 命令语句等绝大部分由“对话框”的操作完成, 无须更多记忆 2-3 运行速度提高。 2-4 与其它软件有数据转换接口 2-5 分析方法丰富 2-6 界面改进
spss基本操作PPT课件
2020/1/10
26
2.2.7 缺失值(Missing)的处理
当数据中存在明显错误或明显不合 理的数据以及存在漏填数据项时,统计 上通称为数据为不完全数据或缺失数据。
SPSS中说明缺失数据的基本方法是 指定用户缺失值。用户缺失值可以是:
o 对字符型或数值型变量,用户缺失值可以是1至 3个特定的离散值(Discrete missing values);
数据编辑窗口中的数据通常以SPSS数据文 件的形式保存在计算机磁盘上,其文件扩展名 为.sav。
数据编辑窗口由窗口主菜单、工具栏、数 据编辑区、系统状态显示区组成。
2020/1/10
5
标题栏
菜单栏
工 具 栏
2020/1/10
输
入
数据显示区:
数
变量名
据
观察序号
栏
数据编辑器的构成
状态栏
6
菜单表
功能
主窗口菜单及功能 解释
17
2020/1/10
频数数据的组织方式
职称 1 1 1 2 2 2 3 3 3 4 4 4
年龄段 1 2 3 1 2 3 1 2 3 1 2 3
人数 0 15 8 10 20 2 20 10 1 35 2 0
18
2.2 SPSS数据的结构和定义方法
SPSS数据的结构包括变量名、类型、宽度、列宽
• 数值型 (1)标准型(Numeric) (2)科学记数法型(Scientific Notation) (3)逗号型(Comma) (4)圆点型(Dot) (5)美元符号型(Dollar) (6)用户自定义型(Custom Currency)
• 字符型(String) • 日期型(Date)
spss入门基本操作ppt课件
19
Independent Samples Test
Levene's Test for Equality of Variances
t-test for Equality of Means
F Sig. t
95% Confidence
df
Sig. (2- Mean Std. Error tailed) Difference Difference
17
§1.3 按题目要求进行统计分析
下面我们要用SPSS来做成组设计两样本均数比较的t检验,选 择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下:
18
将变量X选入test框内,变量group选入grouping框内,注意这时 下面的Define Groups按钮变黑,表示该按钮可用,单击它,系统 弹出比较组定义对话框如右图所示:
22
1.4.2 导出分析结果 文件倒是保存了,但问题还没有完全解决:我们从来写文章什么的 都用的是文字处理软件,尤其是WORD,可WORD不能直接读取 SPO格式的文件,怎么办呢?没关系,SPSS提供了将结果导出为纯 文本格式或网页格式的功能,在结果浏览窗口中选择菜单 File==>Export,系统会弹出Exprot Output对话框如下
现在,第一、第二列的名称均为深色显示,表明这两列已 经被定义为变量,其余各列的名称仍为灰色的“var”,表 示尚未使用。同样地,各行的标号也为灰色,表明现在还 未输入过数据,即该数据集内没有记录。
7
1.1.3 输入数据 在Data View中输入相应的数据,一个单元格输入一个数据, Group中输入1代表患者,2代表健康人。
Independent Samples Test
Levene's Test for Equality of Variances
t-test for Equality of Means
F Sig. t
95% Confidence
df
Sig. (2- Mean Std. Error tailed) Difference Difference
17
§1.3 按题目要求进行统计分析
下面我们要用SPSS来做成组设计两样本均数比较的t检验,选 择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下:
18
将变量X选入test框内,变量group选入grouping框内,注意这时 下面的Define Groups按钮变黑,表示该按钮可用,单击它,系统 弹出比较组定义对话框如右图所示:
22
1.4.2 导出分析结果 文件倒是保存了,但问题还没有完全解决:我们从来写文章什么的 都用的是文字处理软件,尤其是WORD,可WORD不能直接读取 SPO格式的文件,怎么办呢?没关系,SPSS提供了将结果导出为纯 文本格式或网页格式的功能,在结果浏览窗口中选择菜单 File==>Export,系统会弹出Exprot Output对话框如下
现在,第一、第二列的名称均为深色显示,表明这两列已 经被定义为变量,其余各列的名称仍为灰色的“var”,表 示尚未使用。同样地,各行的标号也为灰色,表明现在还 未输入过数据,即该数据集内没有记录。
7
1.1.3 输入数据 在Data View中输入相应的数据,一个单元格输入一个数据, Group中输入1代表患者,2代表健康人。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
5.输出 单击图22-6中的“输出”标签,则弹出如图22-7所示的对话框。各个部分组成如下所
述。 ① 网络结构。 • 描述; • 图表; • 键结值; ② 网络性能。 • 模型汇总; • 分类结果; • ROC曲线; • 累积增益图; • 增益图; • 观测预测值; • 残差分析图。 ③ 个案处理摘要。 ④ 自变量重要性的分析。
22.2.2径向基函数(RBF)的设置 选择菜单“分析→神经网络→径向基函数”
1.变量设置 图22-11中的变量选项栏与多层感知器的设置基本相同,只是在因变量选项
栏的下 方需要设置Rescaling of Scale Dependent Variables,即设置尺度因变量重标度,
下拉菜单 有四个选项,分别是Standardized(Z标准化)、Normalized(标准化)、Adjusted Normalized(调整后的标准化),以及None(不操作)。
第二十二章 神经网络
神经网络的概述 SPSS神经网络模型的参数设置 实例分析
22.2 SPSS神经网络模型的设置
22.2.1 多层感知器(MLP)的设置
选择菜单“分析→神经网络→多层感知器”,则弹出如图22-3所示的对话框,此对话 框用于设置多层感知器的各种参数。此界面中共有8个标签,即Variables(变量)、 Partitions(分区)、Architecture(体系结构)、Training(培训)、Output (输出)、Save(保存)、Export(导出)、Options(选项)。
1.变量 • 因变量:用于选入因变量; • 因子:用于选入因变量; • 协变量:用于设置协变量; • 协变量重标度:用于设置协变量的标度,其下拉菜单中有四个选择项,分别是标准
化、Normalized、调整,以及None。 2.分区
单击图22-3中的“分区”标签,则弹出如图22-4所示的对话框。 ① 变量:用于存放待分析的变量。 ② 分区数据集:用于设置分区数据集, 有两个选项。 • 根据个案的相对数量随机分配个案: 根据个案的相对数量随机的分配个案, 其下的选项栏有分区、相对数量、培训、 检验、支持、总计。 • 使用分区变量分配个案:使用分区变 量分配个案,其下的分区变量表示分区 变量。
包括。 • 具有用户缺失值协变量或者尺度因变量的个案始终被视为无效。 ② 中止规则。 • 预测误差未减少情况下的最大步骤数。 • 用于计算预测误差的数据,其下有自 动选择;培训及测试数据。 • 最长培训时间,在其后的Minutes中填 写数据。 • 最长培训时程,其下有自动计算;指 定自定义值,其后的 Maximum number of epochs表示最大时程数。 • 培训错误的最小相对变化。 • 培训错误率的最小相对变化。 ③ 存储在内存中的最大个案数。
2.体系架构设置 • 单击图22-11中的“体系架构”标签,则弹出如图22-12所示的对话框,此对话框用
于设置体系结构,各个组成部分如下所述。 ① 隐藏层中的单位数。 • 在某个范围内查找最佳单位数。其下的选项栏用于设置范围,有自动计算范围;使
用指定范围,其下的选项栏有最小,最大。 • 使用指定单元数,其下的数用于指定数量。 ② 隐藏层激活函数。 • 标准化径向基函数; • 一般的径向基函数。 ③ 隐藏单位中的重叠。 • 自动计算允许的重叠数量; • 允许指定数量的重叠,在其下的重叠因子 选项栏中填入重叠因子。
③ 单位数。
• 自动计算;
• 设定:用户自定义,如下有隐藏层1, 隐藏层2。
4.培训 单击图22-5中的“培训”标签,则弹出如图22-6所示的对话框。
① 培训类型。 • 批处理; • 在线; • 袖珍型批处理,选择此项后激活其下的选项栏,自动计算表示自动计算;设定表示
拥护自定义,在其下的记录数选项栏中填入记录数。 ② 优化算法。 • 调整的共轭梯度法; • 梯度下降法。 ③ 培训选项。 • 初始Lambda值; • 初始的Sigma值; • 初始的中心点; • 间隔偏移量。
3.选项设置 单击图22-11中的“选项”标签,则弹出如图22-13所示的对话框各部分组成
如下所 述。 • 用户缺失值。 • ① 指定如何使用因子及类别因变量的用户缺失值处理个案。其下有两个选项即 • 排除; • 包括。 • ② 具有用户缺失值协变量或者尺度因变量的个案始终被视为无效
22.3 实例分析
22.3.1 参数设置
首先产生随机数来选择样本数据集,选择菜单“转换→随机数生成器”,则 弹出 如图22-15所示的对话框,选择“设置起点”选项栏,并选中“固定值”选项,填入 9191972,然后单击图22-15中的“确定”按钮。
6.保存 单击图22-7中的“保存”标签,则弹出如图22-8所示的对话框。 ① 保存各个因变量的预测值或类别。 ② 保存各个因变量预测拟概率或类别。 ③ 保存变量名称选项栏:用于保存变量名称。 • 自动生成唯一的名称:自动生成唯一的名称。如果要在每次运行模型时将一组新的
保存变量添加到数据集,则选择此项。 • 自定义名称:为变量指定名称,如果选择此项,具有相同名称或者根名称的任何现
3.体系结构
(1)自动体系结构的选择 • 隐藏层中最小单位数; • 隐藏层中最大单位数。 (2)自定义体系结构 ① 隐藏层数。 • One:一个; • Two:两个。 ② 激活函数。 • 双曲正切; • S型函数。
(3)输出层 ① 激活函数。 恒等函数; Softmax; 双曲正切; Sigmoid。 ② 尺度因变量重标度。 标准化(Z; 标准化; 调整标准化; 无。
有自变量将在每次运行模型时刻被替换。
7.导出 单击图22-8中的“导出”标签,则弹出如图22-9所示的对话框。此对话框用
于导出 数据。其中将键结值估算导出至XML文件选项表示将键结值估算数据导出到XML文件之 中。
SUCCESS
THANK YOU
2019/7/1
8.选项 ① 用户缺失值。 • 指定如何使用因子及类别因变量的用户缺失值处理个案,其下有两个选项即排除和