ID3算法实验报告
数据挖掘实验报告1

实验一 ID3算法实现一、实验目的通过编程实现决策树算法,信息增益的计算、数据子集划分、决策树的构建过程。
加深对相关算法的理解过程。
实验类型:验证计划课间:4学时二、实验内容1、分析决策树算法的实现流程;2、分析信息增益的计算、数据子集划分、决策树的构建过程;3、根据算法描述编程实现算法,调试运行;4、对所给数据集进行验算,得到分析结果。
三、实验方法算法描述:以代表训练样本的单个结点开始建树;若样本都在同一个类,则该结点成为树叶,并用该类标记;否则,算法使用信息增益作为启发信息,选择能够最好地将样本分类的属性;对测试属性的每个已知值,创建一个分支,并据此划分样本;算法使用同样的过程,递归形成每个划分上的样本决策树递归划分步骤,当下列条件之一成立时停止:给定结点的所有样本属于同一类;没有剩余属性可以进一步划分样本,在此情况下,采用多数表决进行四、实验步骤1、算法实现过程中需要使用的数据结构描述:Struct{int Attrib_Col; // 当前节点对应属性int Value; // 对应边值Tree_Node* Left_Node; // 子树Tree_Node* Right_Node // 同层其他节点Boolean IsLeaf; // 是否叶子节点int ClassNo; // 对应分类标号}Tree_Node;2、整体算法流程主程序:InputData();T=Build_ID3(Data,Record_No, Num_Attrib);OutputRule(T);释放内存;3、相关子函数:3.1、 InputData(){输入属性集大小Num_Attrib;输入样本数Num_Record;分配内存Data[Num_Record][Num_Attrib];输入样本数据Data[Num_Record][Num_Attrib];获取类别数C(从最后一列中得到);}3.2、Build_ID3(Data,Record_No, Num_Attrib){Int Class_Distribute[C];If (Record_No==0) { return Null }N=new tree_node();计算Data中各类的分布情况存入Class_Distribute Temp_Num_Attrib=0;For (i=0;i<Num_Attrib;i++)If (Data[0][i]>=0) Temp_Num_Attrib++;If Temp_Num_Attrib==0{N->ClassNo=最多的类;N->IsLeaf=TRUE;N->Left_Node=NULL;N->Right_Node=NULL;Return N;}If Class_Distribute中仅一类的分布大于0{N->ClassNo=该类;N->IsLeaf=TRUE;N->Left_Node=NULL;N->Right_Node=NULL;Return N;}InforGain=0;CurrentCol=-1;For i=0;i<Num_Attrib-1;i++){TempGain=Compute_InforGain(Data,Record_No,I,Num_Attrib); If (InforGain<TempGain){ InforGain=TempGain; CurrentCol=I;}}N->Attrib_Col=CurrentCol;//记录CurrentCol所对应的不同值放入DiferentValue[];I=0;Value_No=-1;While i<Record_No {Flag=false;For (k=0;k<Value_No;k++)if (DiferentValu[k]=Data[i][CurrentCol]) flag=true;if (flag==false){Value_No++;DiferentValue[Value_No]=Data[i][CurrentCol] } I++;}SubData=以Data大小申请内存空间;For (i=0;i<Value_No;i++){k=-1;for (j=0;j<Record_No-1;j++)if (Data[j][CurrentCol]==DiferentValu[i]){k=k++;For(int i1=0;i1<Num_Attrib;i1++)If (i1<>CurrentCol)SubData[k][i1]=Data[j][i1];Else SubData[k][i1]=-1;}N->Attrib_Col=CurrentCol;N->Value=DiferentValu[i];N->Isleaf=false;N->ClassNo=0;N->Left_Node=Build_ID3(SubData,k+1, Num_Attrib);N->Right_Node=new Tree_Node;N=N->Right_Node;}}3.3、计算信息增益Compute_InforGain(Data,Record_No, Col_No, Num_Attrib) {Int DifferentValue[MaxDifferentValue];Int Total_DifferentValue;Int s[ClassNo][MaxDifferentValue];s=0;// 数组清0;Total_DifferentValue=-1;For (i=0;i<Record_No;i++){J=GetPosition(DifferentValue,Total_DifferentValue,Data[i][Col_no]);If (j<0) {Total_DifferentValue++;DifferentValue[Total_DifferentValue]=Data[i][Col_no];J=Total_DifferentValue;}S[Data[i][Num_Attrib-1]][j]++;}Total_I=0;For (i=0;i<ClassNo;i++){Sum=0;For(j=0;j<Record_No;j++) if Data[j][Num_Attrib-1]==i sum++; Total_I=Compute_PI(Sum/Record_No);}EA=0;For (i=0;i<Total_DifferentValue;i++);{ temp=0;sj=0; //sj是数据子集中属于类j的样本个数;For (j=0;j<ClassNO;j++)sj+=s[j][i];For (j=0;j<ClassNO;j++)EA+=sj/Record_No*Compute_PI(s[j][i]/sj);}Return total_I-EA;}3.4、得到某数字在数组中的位置GetPosition(Data, DataSize,Value){For (i=0;i<DataSize;i++) if (Data[i]=value) return I;Return -1;}3.5、计算Pi*LogPiFloat Compute_PI(float pi){If pi<=0 then return 0;If pi>=1 then return 0;Return 0-pi*log2(pi);}五、实验报告要求1、用C语言实现上述相关算法(可选择利用matlab函数实现)2、实验操作步骤和实验结果,实验中出现的问题和解决方法。
决策树ID3分类算法
决策树ID3分类算法一、ID3算法介绍决策树学习是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一颗决策树。
ID3算法的思想就是自顶向下构造决策树,它使用统计测试来确定每一个实例属性单独分类训练样例的能力,继而判断哪个属性是最佳的分类属性,直到建立一棵完整的决策树。
利用这棵决策树,我们可以对新的测试数据进行分类。
二、算法的实现算法实现了对于给定的数据信息, 基于信息增益构造决策树,最后给出决策树和对训练数据集的分类准确率。
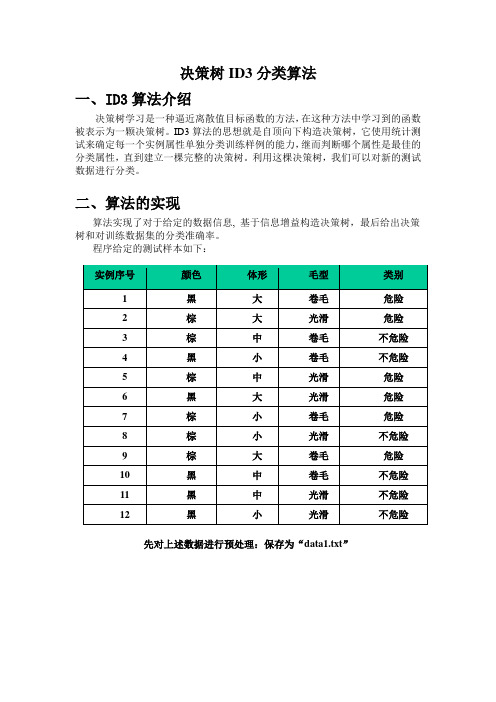
程序给定的测试样本如下:实例序号颜色体形毛型类别1黑大卷毛危险2棕大光滑危险3棕中卷毛不危险4黑小卷毛不危险5棕中光滑危险6黑大光滑危险7棕小卷毛危险8棕小光滑不危险9棕大卷毛危险10黑中卷毛不危险11黑中光滑不危险12黑小光滑不危险先对上述数据进行预处理:保存为“data1.txt”再运行程序,读入数据,输出分析过程和决策规则:中间还有一些过程,为了节约资源,不复制过来了,下面是决策规则:根据该规则,树形图如下:三、程序代码及其部分注释其中最核心的部分:void Generate_decision_tree(Tree_Node * & root,vector<int> Samples, vector<int> attribute_list,int class_id)该函数由给定的训练数据产生一棵判定树。
完整代码:#include <stdio.h>#include <iostream>#include <vector>#include <math.h>#include <string.h>using namespace std;typedef struct tnode{char tdata[100];}tnode;typedef struct Tree_Node{char name[100];bool isLeaf; //标记是否叶子节点vector<tnode> att_list;//属性名称列表vector<Tree_Node * > child_list;}Tree_Node,* pTreeNpde;typedef struct dnode{vector<tnode>row;}dnode;typedef struct D_Node{vector<dnode>DB;vector<tnode> attr_name;tnode class_name;}D_Node;D_Node G_DB;pTreeNpde Root = NULL;typedef struct FreeQNode{char name[100];int count;vector<int> Set_ID;}FreeQNode;typedef struct FreeQNodeDouble{char name[100];int count;vector<int> row_id;vector<FreeQNode> classes;//存放分类属性列表及相应的出现次数}FreeQNodeDouble;typedef struct attr_node{int attr_id;vector<tnode> attr_name;vector<int> count_list;}attr_node;vector<attr_node> G_Attr_List;typedef struct binNode{char name[100];int count;vector<int> Set_ID;struct binNode * lchild;struct binNode * rchild;}binNode;typedef struct binNodeDouble{char name[100];int count;vector<int> row_id;struct binNodeDouble * lchild;struct binNodeDouble * rchild;vector<FreeQNode> classes;}binNodeDouble;void insert_tree(binNode * & r, char str[100]){if (NULL == r){binNode * node = new binNode;strcpy(node->name,str);node->count = 1;//printf("[%s,%d]\n",node->name,node->count);node->lchild = node->rchild = NULL;r = node;}else{if (strcmp(r->name,str) == 0){r->count ++;}else if (strcmp(r->name,str) < 0){insert_tree(r->lchild,str);}else{insert_tree(r->rchild,str);}}}void delete_bin_tree(binNode *& r){if (r != NULL){delete_bin_tree(r->lchild);delete_bin_tree(r->rchild);delete(r);r = NULL;}}void Bin_tree_inorder(binNode * r,vector<FreeQNode> & Fq) {if (r != NULL){Bin_tree_inorder(r->lchild,Fq);FreeQNode ft;//printf("%s,%d\n",r->name,r->count);strcpy(,r->name);ft.count = r->count;for (int i= 0;i < r->Set_ID.size();i++){ft.Set_ID.push_back(r->Set_ID[i]); //保存子集对应的ID号}Fq.push_back(ft); //此处少了这条语句,造成结果无法返回Bin_tree_inorder(r->rchild,Fq);}}void Get_attr(binNode * r,attr_node & attr){if (r != NULL){Get_attr(r->lchild,attr);tnode t;strcpy(t.tdata,r->name);//printf("%s,%d\n",r->name,r->count);attr.attr_name.push_back(t);attr.count_list.push_back(r->count);//保存出现次数Get_attr(r->rchild,attr);}}void insert_tree_double(binNodeDouble *& r, int DB_ID,char attr_name[100],char class_name[100]){if (NULL == r){binNodeDouble * node = new binNodeDouble;strcpy(node->name,attr_name);node->count = 1;node->row_id.push_back(DB_ID);node->lchild = node->rchild = NULL;FreeQNode fq;strcpy(,class_name);fq.count = 1;fq.Set_ID.push_back(DB_ID); //保存子集所对应的ID号node->classes.push_back(fq);r= node;}else{if (strcmp(r->name,attr_name) == 0){r->count ++;r->row_id.push_back(DB_ID);//这里也需要保存相应的ID号bool found = false;for (int i = 0; i< r->classes.size();i++){if (strcmp(r->classes[i].name,class_name) == 0){r->classes[i].count ++;r->classes[i].Set_ID.push_back(DB_ID);//保存子集对应的ID号found = true; //发现相同的变量名,计数器增1,break; //并退出循环}}if (!found){FreeQNode fq;strcpy(,class_name);fq.count = 1;fq.Set_ID.push_back(DB_ID);//保存子集所对应的ID号r->classes.push_back(fq);}}else if (strcmp(r->name,attr_name) < 0){insert_tree_double(r->lchild,DB_ID,attr_name,class_name);}else{insert_tree_double(r->rchild,DB_ID,attr_name,class_name);}}void delete_bin_tree_double(binNodeDouble *& r){if (r != NULL){delete_bin_tree_double(r->lchild);delete_bin_tree_double(r->rchild);delete(r);r = NULL;}}void Bin_tree_inorder_double(binNodeDouble *& r,vector<FreeQNodeDouble> &Fq){if (r != NULL){Bin_tree_inorder_double(r->lchild,Fq);FreeQNodeDouble ft;strcpy(,r->name); //保存候属性的名称ft.count = r->count;for (int k = 0;k< r->row_id.size();k++){ft.row_id.push_back(r->row_id[k]);}//printf("doubleTree. %s,%d\n",r->name,r->count);for (int i = 0;i< r->classes.size();i++){FreeQNode fq;strcpy(,r->classes[i].name);fq.count = r->classes[i].count;for (int j = 0;j < r->classes[i].Set_ID.size();j++){fq.Set_ID.push_back( r->classes[i].Set_ID[j]); //保存子集对应的ID号}ft.classes.push_back(fq);}Fq.push_back(ft);ft.classes.erase(ft.classes.begin(),ft.classes.end());//使用完,必须清空Bin_tree_inorder_double(r->rchild,Fq);}}void getFqI(vector<int> S,int class_id,vector<FreeQNode> & Fq){binNode * root = NULL;for (int i = 0;i< S.size();i++){insert_tree(root,G_DB.DB[S[i]].row[class_id].tdata);}Bin_tree_inorder(root,Fq);delete_bin_tree(root);}void getFqIA(vector<int> S,int attr_id,int class_id,vector<FreeQNodeDouble> & Fq){binNodeDouble * root = NULL;for (int i = 0;i< S.size();i++){insert_tree_double(root,S[i],G_DB.DB[S[i]].row[attr_id].tdata,G_DB.DB[S[i]].row[class_id] .tdata);}Bin_tree_inorder_double(root,Fq);delete_bin_tree_double(root);}void readdata(char *filename){char str[1000];FILE * fp;fp = fopen(filename,"r");fgets(str,1000,fp);int len = strlen(str);int attr_no = 0; //属性个数int row_num = 0;if (str != NULL){row_num = 1;}for (int i = 0;i< len;i++){if (str[i] == '\t'){attr_no ++;}}attr_no ++;//最后一个是回车,整个属性值+1printf("%d\n",attr_no);while(fgets(str,1000,fp) != NULL){row_num ++; //统计行数}fclose(fp);fopen(filename,"r");tnode t;for (i = 0;i<attr_no;i++){fscanf(fp,"%s",t.tdata);G_DB.attr_name.push_back(t);printf("%s\n",t.tdata);}strcpy(G_DB.class_name.tdata,G_DB.attr_name[attr_no-1].tdata); for (int j = 1;j< row_num;j++){dnode dt;tnode temp;for (int i = 0;i<attr_no;i++){fscanf(fp,"%s",temp.tdata);dt.row.push_back(temp);}G_DB.DB.push_back(dt);dt.row.erase(dt.row.begin(),dt.row.end());}printf("%d\n",G_DB.DB.size());for (i = 0;i< G_DB.DB.size();i++){for (int j = 0;j< G_DB.DB[i].row.size();j++){printf("%s\t",G_DB.DB[i].row[j].tdata);}printf("\n");}}double Fnc_I(vector<int> S,int class_id){//给定一个子集,计算其按照class_id所对应的分类属性进行分类时的期望I// printf("called Fnc_I(%d)\n ",class_id);vector<FreeQNode> Fq;getFqI(S,class_id,Fq); //调用getFqI获取按照Class_id为分类标准的分类结果,当Fq中为一条数据时,则子集S都属于一个分类//否则,从中找到出现此时最大的,作为返回结果// printf("begin to compute I \n");double total = 0;for (int i = 0;i< Fq.size();i++){total += Fq[i].count;// printf("%s,%d\n",Fq[i].name,Fq[i].count);}double result = 0;if (0 == total){return 0;}for (i = 0;i< Fq.size();i++){double p = Fq[i].count/total;result += -1*(p * log(p)/log(2));}// printf("FNC_I return\n\n");return result;}double Fnc_IA(vector<int> S,int attr_id,int class_id,vector<FreeQNodeDouble> & Fq) {//给定一个子集,计算其按照class_id所对应的分类属性进行分类时的期望I getFqIA(S,attr_id,class_id,Fq);double total = 0;for (int i = 0;i< Fq.size();i++){total += Fq[i].count;}double result = 0;if (0 == total){return 0;}bool pr= false;for (i = 0;i< Fq.size();i++){double stotal = Fq[i].count;double sresult = 0;if (pr) printf("[%s,%d]\n",Fq[i].name,Fq[i].count);for (int j = 0;j < Fq[i].classes.size();j++){if (pr) printf("%s,%d\n",Fq[i].classes[j].name,Fq[i].classes[j].count);for (int k = 0;k < Fq[i].classes[j].count;k++){// printf("%d\t",Fq[i].classes[j].Set_ID[k]+1);}//printf("\n");double sp = Fq[i].classes[j].count/stotal; //计算子集的频率sresult += -1*(sp*log(sp)/log(2));}result += (stotal/total) * sresult;}if (pr) printf("\n");return result;}int SelectBestAttribute(vector<int> Samples,vector<int> attribute_list,int class_id) {//输入训练数据集Samples,候选属性列表attribute_list//分类属性标记class_id//返回best_attributedouble fi = Fnc_I(Samples,5);// printf("%lf\n",fi);double IA = 999999999;int best_attrib = -1;for (int i = 0;i < attribute_list.size();i++){vector<FreeQNodeDouble> fqd;double tfa = Fnc_IA(Samples,attribute_list[i],class_id,fqd);// printf("%d, FIA = %lf\n",i,tfa);if (IA > tfa){IA = tfa;best_attrib = i;}}//printf("%lf\n",IA);printf("gain(%d) = %lf - %lf = %lf\n",best_attrib,fi,IA,fi - IA);return attribute_list[best_attrib];}void fnc_getattr(vector<int> Samples,int att_id,attr_node &at){binNode * root = NULL;for (int i = 0;i< Samples.size();i++){insert_tree(root,G_DB.DB[Samples[i]].row[att_id].tdata);}Get_attr(root,at);delete_bin_tree(root);}void get_class_num_and_name(vector<int> Samples,int class_id,int & class_num,tnode & class_name){attr_node at;binNode * root = NULL;for (int i = 0;i< Samples.size();i++){insert_tree(root,G_DB.DB[Samples[i]].row[class_id].tdata);}Get_attr(root,at);delete_bin_tree(root);//printf("att_size = %d\n",at.attr_name.size());class_num = at.attr_name.size();int num = 0;int id = 0;if (1 == class_num){strcpy(class_name.tdata,at.attr_name[0].tdata);}else{for (int j = 0;j < at.attr_name.size();j++ ){if (at.count_list[j] > num){num = at.count_list[j];id = j;}}}strcpy(class_name.tdata,at.attr_name[id].tdata);//保存最普通的类名}void getAllTheAttribute(vector<int> Samples,vector<int> attribute_list,int class_id){printf("all the attribute are:\n");for (int i = 0;i < attribute_list.size();i++){attr_node at;at.attr_id = attribute_list[i];fnc_getattr(Samples,attribute_list[i],at);G_Attr_List.push_back(at);}for (i = 0;i <G_Attr_List.size();i++){printf("%d\n",G_Attr_List[i].attr_id);for (int j = 0;j< G_Attr_List[i].attr_name.size();j++){printf("%s\t",G_Attr_List[i].attr_name[j].tdata);}printf("\n");}}void Generate_decision_tree(Tree_Node * & root,vector<int> Samples, vector<int>attribute_list,int class_id){/*算法:Generate_decision_tree(samples, attribute)。
ID3算法的合理性证明及实验分析

N ra, om l则适合 打球 ; 规 则 2 如 果 O to = un , H mii = : uok Sny 且 u dt l y Hg , 不适合打球 ; i 则 h 规则3 如果O to= vrat则适合 打球 ; : uok O e s l c , 规 则4 如 果 O to = an 且 Wid Wek : ul k R i, o n= a, 则适 合打球 ; 规则5如果 , u okR i, : O to= a 且WidSrn , l n n=t g o 则不适 合打球 . 本文 首先研 究 了一个 属性 的某 几个属 性值 并 的权熵 之 和与该 属性单 个属 性值 的权熵 之 和 N 的关 系 , 出了如 下结论 : 得 一个 属性 的某几 个属
其中属性的熵定义为该属性单个属性值的权熵之和在生成树的过程中每个结点只有一个属性值权熵相同的属性值看作一个属性值其优点是采用自顶向下不回溯的策略搜索全部的属性空间其建立决策树的算法简单难度小分类速度快
20 年 1 08 O月
保 定 学 院 学 报
J OURNAL OF BAODI NG UNI VERS TY I
权平均值 , 即
A ) 等 . 一
而以/ 重 为根进行分类所得到的信息增益为
g i( =p,, E A) a A) ( ) ( . n n-
个好的分类属性将使信息增益增大. 3 I 选择使 nA) D ( 具有最大的属 值对应的厂 个子集 递归调用上述生成过程生成子节点.
信息熵原理1 选择信息熵最小的属性作为分类 7 1 , 属性 , 递归地拓展决策树的分枝 , 完成决策树的
ID3算法的优化

ID3算法的优化朱琳;杨杨【摘要】随着硬件设备的普及,促使信息技术和移动互联网的快速发展,人们已经告别了信息匮乏的时期,而进入到了信息过载的时期。
人们试图用搜索功能搜索出自己想要的信息,如今已是非常困难,怎样从海量的数据中筛选出有价值的信息是信息提供者和信息需求者都要面对的挑战。
本文对数据分类中的 ID3算法的基本概念和原理以及其构造过程进行了详细阐述,针对 ID3算法倾向于选择取值较多的属性的缺点,引进属性阈值和信息增益率两个概念。
弥补ID3算法属性选择标准的不足,来实现新的属性选择标准,对原有ID3算法进行改进。
通过实验对改进前后的算法进行了比较,实验表明,改进后的算法提高了分类准确度。
%With the popularization of hardware equipment, prompting the rapid development of information tech-nology and mobile Internet, people have already bid farewell to the period of lack of information, and entered the period of information overload. People try to use the search function to search out the information they want, and now it is very difficult, how to filter out from the mass of valuable information is information providers and information needs of those who have to face the challenge. In this paper, the basic concept and principle of ID3 algorithm in data classifica-tion and its construction process are expounded. In view of the shortcomings of ID3 algorithm which tend to choose more attributes, the two concepts of attribute threshold and information gain rate are introduced. Make up for the defi-ciency of attribute selection standard of ID3 algorithm to realize the new attributeselection standard and improve the original ID3 algorithm. Experiments show that the improved algorithm improves the classification accuracy.【期刊名称】《软件》【年(卷),期】2016(037)012【总页数】4页(P89-92)【关键词】数据挖掘;ID3算法;信息增益;信息增益率;分类【作者】朱琳;杨杨【作者单位】北京邮电大学,北京 100876;北京邮电大学,北京 100876【正文语种】中文【中图分类】TP311.13在解决分类问题时,使用次数最多、范围最广的算法是决策树算法。
id3算法实验报告

id3算法实验报告篇一:ID3算法实验报告一、实验原理决策树通过把实例从根节点排列到某个叶子节点来分类实例,叶子节点即为实例所属的分类。
树上的每一个节点说明了对实例的某个属性的测试,并且该节点的每一个后继分支对应于该属性的一个可能值,例如下图。
构造好的决策树的关键在于如何选择好的逻辑判断或属性。
对于同样一组例子,可以有很多决策树能符合这组例子。
人们研究出,一般情况下或具有较大概率地说,树越小则树的预测能力越强。
要构造尽可能小的决策树,关键在于选择恰当的逻辑判断或属性。
由于构造最小的树是NP-难问题,因此只能采取用启发式策略选择好的逻辑判断或属性。
用信息增益度量期望熵最低,来选择分类属性。
公式为ID3算法创建树的Root结点如果Examples都为正,那么返回label=+中的单结点Root 如果Examples都为反,那么返回lable=-单结点树Root如果Attributes为空,那么返回单节点树Root,lable=Examples中最普遍的目标属性值否则开始A 目标属性值 lable=Examples中最普遍的否则在这个新分支下加一个子树ID3(example-vi,target-attribute,attributes-|A|) 结束返回 Root二、算法实现训练数据存放在Data.txt 中第一行为训练样本数量和每个样本中属性的数量第二行为每个属性取值的数量之后n行为所有样本节点数据结构struct DTNode{int name; //用 1,2,3...表示选择的属性,0表示不用分类,即叶节点int data[D_MAX+1]; //表示此节点包含的数据,data[i]=1,表示包含二维数组data[][]中的第i条数据int leaf;//leaf=1 正例叶节点;leaf=2 反例叶节点;leaf=0不是节点 int c; //c=1 正类;c=0 反类DTNode *child[P+1];//按属性值的个数建立子树};定义函数void Read_data() //从数据文件Data.txt中读入训练数据DT_pointer Create_DT(DT_pointer Tree,int name,int value)//创建决策树 int chose(int *da)//选择分类属性float Gain(int *da,int p) //计算以p属性分类的期望熵float Entropy(int *da) //计算数据的熵int test_leaf(int *da) //测试节点属性void Out_DT(DT_pointer Tree) //用线性表形式输出建立的决策树int Class(int *da) //对输入的测试样本分类全局变量FILE *fp;int p_num; //属性的数量int pi[P_MAX+1]; //每个属性有几种取值int d_num;//数据的数量int data[P_MAX+1][D_MAX+1];//存储训练数据三、程序不足1.、默认训练数据是正确的,对是否发生错误不予考虑2、没有考虑训练数据可以包含缺少属性值的实例3、只能分正反两类四、程序源码#include#include#include#include#include#define P_MAX 10#define D_MAX 50#define P 5//一条数据包括所有属性的取值(1,2,3...)和分类的值(0或1) FILE *fp;int p_num; //属性的数量int pi[P_MAX+1]; //每个属性有几种取值int d_num;//数据的数量int data[P_MAX+1][D_MAX+1];//存储训练数据//定义结点类型struct DTNode{int name; //此节点分类属性的名称int data[D_MAX+1]; //表示此节点包含的数据int leaf; //leaf=1 正例叶节点;leaf=2 反例叶节点;叶节点int c; //c=1 正类;c=0 反类DTNode *child[P+1];//按属性值的个数建立子树};typedef struct DTNode *DT_pointer;DT_pointer DT = NULL;int root = 0;int test_leaf(int *da) leaf=0不是int i;int a,b;a = 0;// a=0表示没有0类 a=1表示有0类 for(i = 1; i {if(*(da+i) ==1 && data[i][0] == 0){a = 1;break;}}b = 0;//b=0表示没有1类 b=1表示有1类 for(i = 1;i {if(*(da+i) == 1 && data[i][0] == 1){break;}}if(a == 0 && b == 1)return 1;//是1叶节点else if(a == 1 && b == 0)return 2;//是0叶节点else if(a == 0 && b == 0)return 2;//此节点无数据elsereturn 0;//不是叶节点}int test_c(int a) //给叶节点附属性值{if(a == 1)return 1;elsereturn 0;}float Entropy(int *da) //计算数据的熵{篇二:ID3算法实验报告装订线:ID3算法分析与实现学院xxxxxxxxxxxxxxxxxxxx 专业 xxxxxxxxxxxxxxxx 学号xxxxxxxxxxx 姓名 xxxx 指导教师 xxxxXX年x月xx日题目ID3算法分析与实现摘要:决策树是对数据进行分类,以此达到预测的目的。
ID3算法范文

ID3算法范文ID3算法是一种决策树学习算法,用于在给定数据集中进行分类。
它根据信息论的概念选择最佳的特征来划分数据集,以产生一个有助于分类的决策树模型。
通过理解ID3算法的原理和基本步骤,我们能够更好地理解决策树学习算法的工作原理。
ID3算法基于信息熵的概念,信息熵是衡量数据集的无序程度的度量。
信息熵越高,表示数据集越无序,越难以进行分类。
ID3算法的目标是找到能够最大程度地降低数据集无序程度的特征,将数据集划分为尽可能相似的子集。
算法的基本步骤如下:1.计算整个数据集的信息熵。
首先,需要计算数据集中各个类别的频率,然后使用信息熵公式来计算整个数据集的信息熵。
2.对于每个特征,计算它的信息增益。
信息增益表示使用特征划分数据集后,整个数据集无序程度减少的程度。
信息增益越大,表示该特征对于数据集的分类具有更大的贡献。
信息增益可以通过计算数据集划分后各个子集的信息熵以及它们的权重来计算。
3.选择信息增益最大的特征作为当前节点的划分特征。
选取信息增益最大的特征,意味着该特征能够对数据集进行更好的划分,以便进行更准确的分类。
4.根据选择的划分特征,将数据集划分为几个子集。
每个子集包含特定特征取值的数据样本。
如果属性的取值是离散的,将根据不同的取值来创建子集;如果属性的取值是连续的,可以根据不同的划分点来创建子集。
5.对于每个子集,如果该子集中所有样本都属于同一类别,则将该子集作为叶节点,标记为该类别。
否则,递归地重复步骤2-5,直到所有子集都属于同一类别或者没有更多的可用特征。
ID3算法的优点是简单且易于实现,它适用于处理具有离散属性的问题。
然而,ID3算法也存在一些缺点。
首先,ID3算法倾向于选择具有更多取值的特征作为划分特征,这可能导致过度拟合的问题。
其次,ID3算法无法处理缺失数据和连续属性,需要进行额外的处理。
此外,ID3算法对于噪声和异常值也比较敏感,可能导致不准确的分类结果。
为了弥补ID3算法的不足,后续的决策树学习算法,如C4.5和CART,进行了改进。
PID算法实验报告
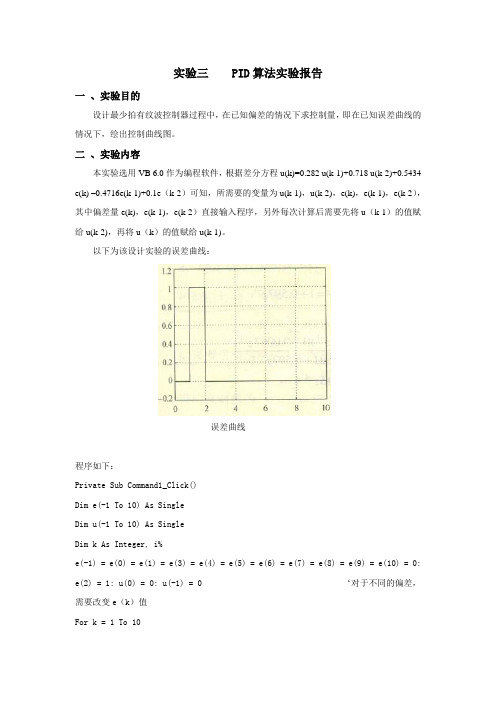
实验三 PID算法实验报告一、实验目的设计最少拍有纹波控制器过程中,在已知偏差的情况下求控制量,即在已知误差曲线的情况下,绘出控制曲线图。
二、实验内容本实验选用VB 6.0作为编程软件,根据差分方程u(k)=0.282 u(k-1)+0.718 u(k-2)+0.5434 e(k) –0.4716e(k-1)+0.1e(k-2)可知,所需要的变量为u(k-1),u(k-2),e(k),e(k-1),e(k-2),其中偏差量e(k),e(k-1),e(k-2)直接输入程序,另外每次计算后需要先将u(k-1)的值赋给u(k-2),再将u(k)的值赋给u(k-1)。
以下为该设计实验的误差曲线:误差曲线程序如下:Private Sub Command1_Click()Dim e(-1 To 10) As SingleDim u(-1 To 10) As SingleDim k As Integer, i%e(-1) = e(0) = e(1) = e(3) = e(4) = e(5) = e(6) = e(7) = e(8) = e(9) = e(10) = 0: e(2) = 1: u(0) = 0: u(-1) = 0 ‘对于不同的偏差,需要改变e(k)值For k = 1 To 10u(k) = 0.282 * u(k - 1) + 0.718 * u(k - 2) + 0.5434 * e(k) - 0.4716 * e(k - 1) + 0.1 * e(k - 2)Print "u(" & k & ") = "; u(k)Next kEnd Sub三、实验数据e(k)分别等于[0,1,0,0,0,0,0,0,0,0],结果如下:u(1)= 0u(2)= 0.5434u(3)= - 0.3184u(4)= 0.4004u(5)= - 0.1157u(6)= 0.2549u(7)= - 0.1119u(8)= 0.1798u(9)= 0.0427u(10)= 0.1412以下为求得的控制曲线:控制曲线。
ID3算法实验报告

题目: ID3算法分析与实现学 院 xxxxxxxxxxxxxxxxxxxx专 业 xxxxxxxxxxxxxxxx学 号 xxxxxxxxxxx姓 名 xxxx指导教师 xxxx2015年x 月xx 日装订线ID3算法分析与实现摘要:决策树是对数据进行分类,以此达到预测的目的。
该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集。
决策树代表着决策集的树形结构。
先上问题吧,我们统计了14天的气象数据(指标包括outlook,temperature,humidity,windy),并已知这些天气是否打球(play)。
如果给出新一天的气象指标数据:sunny,cool,high,TRUE,判断一下会不会去打球。
这个问题当然可以用朴素贝叶斯法求解,分别计算在给定天气条件下打球和不打球的概率,选概率大者作为推测结果。
现在我们使用ID3归纳决策树的方法来求解该问题。
预备知识:信息熵熵是无序性(或不确定性)的度量指标。
假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn),那信息熵定义为:通常以2为底数,所以信息熵的单位是bit。
补充两个对数去处公式:ID3算法构造树的基本想法是随着树深度的增加,节点的熵迅速地降低。
熵降低的速度越快越好,这样我们有望得到一棵高度最矮的决策树。
在没有给定任何天气信息时,根据历史数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。
此时的熵为:属性有4个:outlook,temperature,humidity,windy。
我们首先要决定哪个属性作树的根节点。
对每项指标分别统计:在不同的取值下打球和不打球的次数。
下面我们计算当已知变量outlook的值时,信息熵为多少。
outlook=sunny时,2/5的概率打球,3/5的概率不打球。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ID3算法实验
08级第一小组介绍:
ID3算法可分为主算法和建树算法两种。
(1)ID3主算法。
主算法流程如图所示。
其中PE、NE分别表示正例和反例集,它们共同组成训练集。
PE'、PE''和NE'、NE''分别表示正例集和反例集的子集。
ID3主算法流程
(2)建树算法。
采用建树算法建立决策树。
首先,对当前子例进行同类归集。
其次,计算各集合属性的互信息,选择互信息最大的属性Ak。
再次,将在Ak处取值相同的子例归于同一子集,Ak取几个值就几个子集。
最后,对既含正例又含反例的子集递归调用建树算法。
若子集仅含正例或反例,对应分支标上P或N,返回调用处。
ID3算法采用自顶向下不回溯的策略搜索全部属性空间并建立决策树,算法简单、深度小、分类速度快。
但是,ID3算法对于大的属性集执行效率下降快、准确性降低,并且学习能力低下。
考虑到本文所涉及到的数据量并很小,下文分类分析采用了该算法。
决策树学习是把实例从根结点排列到某个叶子结点来分类实例,叶子结点即为实例所属的分类。
学习到的决策树能再被表示成多个if-then的规则。
ID3算法是一种决策树算法。
对下载的ID3算法程序进行阅读和调试后,做了相关实验,以下是相关记录。
1、试验数据
该算法的试验数据有两个:data.dat和data.tag,分别存放训练样例和各个属性列表:
data.dat:
data.tag:
其中,训练样例集合的试验数据由课本第3.4。
2节给出,分别将其属性使用离散值数据表示,在data.tag文件中可以看到离散值其表示的属性分别对应。
2、运行结果
试验结果,是以if-then形式输出决策树,其运行界面如图:
可以将结果整理为:
if { humidity = 2.00 then
if { outlook = 3.00 then
if{ w indy = 2.00 then ON
else OFF }
else ON }
else if { outlook = 2.00 then
if { outlook = 3.00 then
if { windy = 2.00 then ON
else OFF }
else ON }
else OFF }
}
该结果与给定的训练样例是一致的。
可以看出,对于给定的这个训练样例集合,目标函数的取值与temperature这个属性没有太大关系,但是,对于未见实例,则不一定。
所以训练样例的分布是很重要的。