K-means聚类算法分析应用研究
基于k-means算法的亚洲足球水平聚类研究

基于k-means算法的亚洲足球水平聚类研究摘要:基于k-means算法对近年来亚洲足球在亚洲杯和世界杯高级赛事中的成绩进行了聚类分析研究,科学地分析了亚洲各个国家足球的水平和实力,判断出目前中国队究竟与哪些国家的实力比较接近。
其中运用软件spss19.0对数据进行整理归纳,使用k-means聚类算法对比赛结果数据进行处理分析并得出结论:中国在亚洲属于第四类水平,距离一流球队差距明显。
关键词:聚类;k-means;亚洲足球Abstract:Based on the k-means algorithm, the results of Asian Football in the Asian Cup and the world cup are analyzed in recent years. The football level and strength of each Asian country are analyzed scientifically and the actual strength of the Chinese team is close to which countries. It uses software spss19.0 to sum up the data, and uses k-means clustering algorithm to analyze and analyze the data of fruit racing and draws a conclusion that China is fourth level in Asia, and the gap between the first class teams is obvious.Key words:Cluster; k-means; Asian football目录摘要 (Ⅰ)Abstract (Ⅰ)目录 (Ⅱ)1绪论 (1)1.1研究背景及现状 (1)1.2研究对象 (2)2数据处理 (3)2.1统计方法和原理解析 (3)2.2聚类分析算法的求解过程 (4)2.3 k-means聚类分析处理数据过程 (4)3结果与分析 (7)3.1结果 (7)3.2分析 (8)4结论 (10)1绪论1.1研究背景及现状足球是一项风靡全球的体育运动项目。
基于K-means聚类算法的数据分析模型应用研究

关键词 : 回归模 型; K — me a n s聚类算法 ; 分析模 型; 预估 ; 显著性
D OI : 1 0 . 1 1 9 0 7 / r j d k . 1 6 2 5 3 4
中图 分 类 号 : TP 3 1 9
文献标识码 : A
文章编号 : 1 6 7 2 — 7 8 0 0 ( 2 0 1 7 ) 0 0 3 — 0 1 0 3 — 0 5 析的技术 , 以期 为 电 网管 理 优 化 提 供 参 考 。
同的 类 群 ; ② 将 每 一 类 典 型 台 区 的基 础 数 据 与 预 测 值 相 关 联, 通 过 线 性 回归 的方 式 建 立 数 学 预 测 模 型 ; ③ 将 需 要 预
测的数据输入模型 , 得 到输 出, 从 而 得 出每 一 类 台 区 的 合
理 预 测 值 。整 个模 型 建 立 的 流 程 如 图 1所 示 。 数据分析过 程 的主 要活 动 由识 别信 息 需求 、 收 集 数 据、 分 析处理数据 、 数据分析模型的建立组成 。
基 于 K— me a n s算 法 的 数 据 预 估 模 型 的 建 立 包 含 K—
me a n s聚类 与线 性 回归 两 部 分 。首 先 通 过 K— me a n s聚类
电 网数 据 , 能 够 带 来 可观 的经 济 与社 会 效 益 。以 分 析 预 测
线损为例 , 台 区线 损 管 理 通 过 比较 理 论 线 损 与 实 际线 损 的
范 围 内 台 区数 量 巨 大 , 彼 此 之 间差 别 较 大 , 无 法 采 用 统 一
模 式 进 行 管 理 。因 此 , 如 何 进 一 步 提 高 台区 线 损 管 理 的精 益化水平 , 给 出每 个 台 区 可 参 照 的 合 理 线 损 范 围 , 并 科 学 合 理 地 对 台 区线 损 进 行 监 视 , 及 时发现 异常 台 区, 分 析 原
基于K-means算法的亚洲足球聚类研究
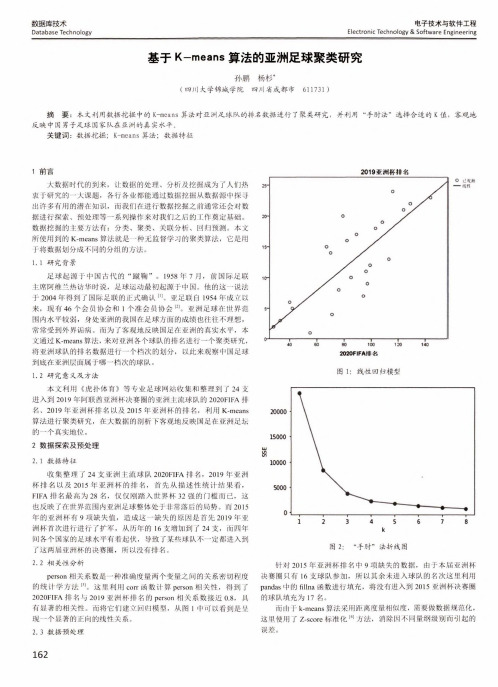
电子技术与软件工程Electronic Technology & Software Engineering数据库技术Database Technology 基于K-means 算法的亚洲足球聚类研究孙鹏杨杉*(四川大学锦城学院 四川省成都市 611731 )摘 要:本文利用数据挖掘中的K-means 算法对亚洲足球队的排名数据进行了聚类研究,并利用“手肘法”选择合适的K 值,客观地 反映中国男子足球国家队在亚洲的真实水平。
关键词:数据挖掘;K-means 算法;数据特征1前言大数据时代的到来,让数据的处理、分析及挖掘成为了人们热 衷于研究的一大课题,各行各业都能通过数据挖掘从数据源中探寻 出许多有用的潜在知识,而我们在进行数据挖掘之前通常还会对数 据进行探索、预处理等一系列操作来对我们之后的工作奠定基础。
数据挖掘的主要方法有:分类、聚类、关联分析、回归预测。
本文 所使用到的K-means 算法就是一种无监督学习的聚类算法,它是用 于将数据划分成不同的分组的方法。
1. 1研究背景足球起源于中国古代的“蹴鞠”。
1958年7月,前国际足联 主席阿维兰热访华时说,足球运动最初起源于中国。
他的这一说法 于2004年得到了国际足联的正式确认⑴。
亚足联自1954年成立以 来,现有46个会员协会和1个准会员协会⑵。
亚洲足球在世界范 围内水平较弱,身处亚洲的我国在足球方面的成绩也往往不理想, 常常受到外界诟病。
而为了客观地反映国足在亚洲的真实水平,本 文通过K-means 算法,来对亚洲各个球队的排名进行一个聚类研究, 将亚洲球队的排名数据进行一个档次的划分,以此来观察中国足球 到底在亚洲层面属于哪一档次的球队。
1. 2研究意义及方法本文利用《虎扑体育》等专业足球网站收集和整理到了 24支 进入到2019年阿联酋亚洲杯决赛圈的亚洲主流球队的2020FIFA 排 名、2019年亚洲杯排名以及2015年亚洲杯的排名,利用K-means 算法进行聚类研究,在大数据的剖析下客观地反映国足在亚洲足坛 的一个真实地位。
《数据挖掘实验》---K-means聚类及决策树算法实现预测分析实验报告

实验设计过程及分析:1、通过通信企业数据(USER_INFO_M.csv),使用K-means算法实现运营商客户价值分析,并制定相应的营销策略。
(预处理,构建5个特征后确定K 值,构建模型并评价)代码:setwd("D:\\Mi\\数据挖掘\\")datafile<-read.csv("USER_INFO_M.csv")zscoredFile<- na.omit(datafile)set.seed(123) # 设置随机种子result <- kmeans(zscoredFile[,c(9,10,14,19,20)], 4) # 建立模型,找聚类中心为4round(result$centers, 3) # 查看聚类中心table(result$cluster) # 统计不同类别样本的数目# 画出分析雷达图par(cex=0.8)library(fmsb)max <- apply(result$centers, 2, max)min <- apply(result$centers, 2, min)df <- data.frame(rbind(max, min, result$centers))radarchart(df = df, seg =5, plty = c(1:4), vlcex = 1, plwd = 2)# 给雷达图加图例L <- 1for(i in 1:4){legend(1.3, L, legend = paste("VIP_LVL", i), lty = i, lwd = 3, col = i, bty = "n")L <- L - 0.2}运行结果:2、根据企业在2016.01-2016.03客户的短信、流量、通话、消费的使用情况及客户基本信息的数据,构建决策树模型,实现对流失客户的预测,F1值。
kmeans应用案例

kmeans应用案例K-means 应用案例。
K-means 是一种常见的聚类算法,它可以对数据进行分组,找出数据中的相似性,并将数据划分为不同的类别。
在实际应用中,K-means 算法被广泛应用于数据挖掘、模式识别、图像分割等领域。
下面将介绍 K-means 算法在实际案例中的应用。
首先,我们来看一个简单的 K-means 应用案例,鸢尾花数据集。
鸢尾花数据集是一个经典的数据集,其中包含了鸢尾花的四个特征,花萼长度、花萼宽度、花瓣长度和花瓣宽度。
我们可以利用 K-means 算法对这些特征进行聚类,找出不同种类的鸢尾花。
通过 K-means 聚类分析,我们可以将鸢尾花数据集分为三个类别,分别对应于不同的鸢尾花种类。
这样的聚类结果有助于我们更好地理解鸢尾花数据的特点,对鸢尾花进行分类和识别。
除了鸢尾花数据集,K-means 算法还可以应用于其他领域。
例如,在市场营销中,我们可以利用 K-means 算法对客户进行分群,找出具有相似行为和偏好的客户群体,从而针对不同的客户群体制定个性化的营销策略。
在医学影像分析中,K-means 算法可以用于图像分割,将医学影像中的不同组织和结构进行分离,有助于医生更准确地诊断疾病。
在互联网广告投放中,K-means 算法可以对用户进行行为分析,找出具有相似兴趣和偏好的用户群体,从而提高广告的投放效果。
总的来说,K-means 算法是一种简单而有效的聚类算法,它在实际应用中具有广泛的应用前景。
通过对数据进行聚类分析,我们可以更好地理解数据的特点,发现数据中的规律和趋势,为决策提供有力的支持。
希望本文介绍的 K-means 应用案例能够帮助大家更好地理解和应用这一算法。
K-means聚类算法研究

个数据对象作为初始的聚类中心 , 初 始的代表一个 聚类 。对于剩下的其他数据集 。 则分别计算它们 到 这些聚类中心的相似度 ( 以欧 氏距离作 为相似度 测 量准则) ,并根据最短距离将每个数据对象赋给 各 个聚类中心 。然后再计算新获得 的每一个聚类的距 离平均值得 到新 的聚类 中心 , 如果连续两次计算 出
进 行 了详 细 的分析 。
关键词 : 聚类分析 ; K — m e a n s 算法 中图分类号 : T P 3 1 1 文献标识码 : A 文章编号 : 1 6 7 2 - 4 4 7 X ( 2 0 1 3 ) 0 5 - 0 0 1 7 - 0 3 文 采 用 Ma l t a b 7 . 0实 现 了 K- me a n s 聚 类 算
法, 下面这个例子 , 显示 K - me a d s 聚类算法对于一 组二维数据集合 的聚类效果。
输入 : 包含 n 个数据对象的集合置,
x ={ X l , x 2 , … , X n }
b e i g n f o r j = 1 t o k d o
c o m p u t e D ( , z j ) = x i 一 l; / / 计算剩下的数
据对象到各聚类中心的距离 i f D ( , z ) = m i n { D ( X i Z ) } t h e n ∈ C j ; / / 根 据最 短距离将数据对象分类
J 已经收敛 , 聚类算法结束。通常采用平方误差准则
函数 作为 聚类目 标准则, 即 . , = ∑ : 。 ∑ 鹇I P 一 『,
∑g z 。 是分类 的中心 , 即 = 。 的数据 , 可以降低数据量及计算量 , 并可 以避免 杂 p是一个数据 对象 , ¨ 一,目 质的不 良影响。 上述算法的特 点是首先必须指定 k个初 始聚类 中 本 文简要介绍了 K - me a n s 聚类算法 的算法流 心, 然后借着 反复迭代运算 , 逐次降低 目标准则函 程, 复杂度 , 并用 Ma d a b实现 , 根据实验结果分析 了
K-means聚类算法在高校图书馆读者群细分中的应用研究
t i e t f t e ne d o d f e e t r up o c a a t r s i s f h r a e , e a l c t o o r s u c s a d u l c e s f r h lb a y o d n i y h e s f if r n g o s f h r c e i t c o t e e d r r - lo a i n f e o r e n f l a c s o t e i r r r a e s n o ma i n , e l p t a e i s o r v d t e r tc l a me h d l g e l g i a c e d r i f r to d ve o s r t g e t p o i e h o e i a nd t 0 o o i a u d n e.
Ke wo d K—me n a g r t Li r r Re d r y r s: a s l o ihm l b a yj a e gr u s g n a i n o p e me t to
1 问题的提 出
聚 类 分 析 是 数 据 挖 掘 领 域 的 核 心 技 术 之 一 。 聚 类 技 术 运 用 到 商 业 领 域 对 客 户 将 细 分 可 以 有 效 地 解 决 多 种 市 场 问 题 , 现 实 高效 的 、 差异 化 的精 确 营 销 。 校 图 书馆 服 高 务 营 销 不 是 图 书馆 与 读 者 之 间真 正 意 义 上 的交 易 , 但两 者 间的 顾 客 关 系 依 然存 在 。 针 对如何 高效完成对读者 群细分 的问题 , 笔 者 依 据 读者 的 需 求 特 点 、 阅 行为 、 阅 习 借 借 惯 等 方 面 的 差 异 , K—me n 聚 类 算 法 运 将 as 用 于 高 校 读 者 群 细 分 , 读 者 划 分 成 为 若 把 干 个 读 者 群 , 出 不 同读 者 类 群 的 需 求 特 找 点, 重新 配 置 服 务 资 源 , 足 不 同的 知 识 需 满 求 倾 向 , 图书 馆 充 分 获 取读 者 信 息 、 定 为 制 策 略提 供 理 论 和 方 法 指 导 。
K-means聚类算法实现及应用
K-means聚类算法的实现及应用内容摘要本文在分析和实现经典k-means算法的基础上,针对初始类中心选择问题,结合已有的工作,基于对象距离和密度对算法进行了改进。
在算法实现部分使用vc6.0作为开发环境、sql sever2005作为后台数据库对算法进行了验证,实验表明,改进后的算法可以提高算法稳定性,并减少迭代次数。
关键字 k-means;随机聚类;优化聚类;记录的密度1 引言1.1聚类相关知识介绍聚类分析是直接比较各事物之间性质,将性质相近的归为一类,将性质不同的归为一类,在医学实践中也经常需要做一些分类工作。
如根据病人一系列症状、体征和生化检查的结果,将其划分成某几种方法适合用于甲类病的检查,另几种方法适合用于乙类病的检查,等等。
聚类分析被广泛研究了许多年。
基于聚类分析的工具已经被加入到许多统计分析软件或系统中,入s-plus,spss,以及sas。
大体上,聚类算法可以划分为如下几类:1) 划分方法。
2) 层次方法。
3) 基于密度的算法。
4) 基于网格的方法。
5) 基于模型的方法。
1.2 研究聚类算法的意义在很多情况下,研究的目标之间很难找到直接的联系,很难用理论的途径去解决。
在各目标之间找不到明显的关联,所能得到的只是些模糊的认识,由长期的经验所形成的感知和由测量所积累的数据。
因此,若能用计算机技术对以往的经验、观察、数据进行总结,寻找个目标间的各种联系或目标的优化区域、优化方向,则是对实际问题的解决具有指导意义和应用价值的。
在无监督情况下,我们可以尝试多种方式描述问题,其中之一是将问题陈述为对数分组或聚类的处理。
尽管得到的聚类算法没有明显的理论性,但它确实是模式识别研究中非常有用的一类技术。
聚类是一个将数据集划分为若干聚类的过程,是同一聚类具有较高相似性,不同聚类不具相似性,相似或不相似根据数据的属性值来度量,通常使用基于距离的方法。
通过聚类,可以发现数据密集和稀疏的区域,从而发现数据整体的分布模式,以及数据属性间有意义的关联。
K-means聚类算法的研究的开题报告
K-means聚类算法的研究的开题报告一、选题背景K-means聚类算法是一种常用的聚类算法,它可以把数据分成K个簇,每个簇代表一个聚类中心。
该算法适用于大数据分析、图像分析等领域。
由于其具有简单、快速、效果明显等特点,因此备受研究者的关注。
二、研究意义K-means聚类算法在大数据分析、图像分析等领域的应用广泛,研究该算法有着十分重要的意义。
本次研究将对该算法进行探究,通过改进和优化算法,提高其聚类效果和运行效率,为实际应用提供更加可靠、有效的解决方案。
三、研究内容与方法本研究将围绕K-means聚类算法展开,重点探讨以下内容:1. K-means聚类算法原理及优缺点分析2. 基于距离的K-means聚类算法优化3. 基于密度的K-means聚类算法研究4. 算法的实现与效果评估在研究方法上,将采用文献调研、数学统计方法、算法实现和效果评估等多种方法对K-means聚类算法进行研究。
四、计划进度安排本研究总计时长为12周,具体进度安排如下:第1-2周:文献调研,研究K-means聚类算法的原理和优缺点分析第3-4周:基于距离的K-means聚类算法优化第5-6周:基于密度的K-means聚类算法研究第7-8周:算法实现第9-10周:效果评估第11-12周:论文撰写和答辩准备五、预期研究结果本研究将针对K-means聚类算法进行深入探究,并尝试改进和优化算法,提高其聚类效果和运行效率。
预期研究结果将包括以下几个方面:1.对该算法的优缺点进行全面分析,揭示其内在机制和局限性。
2.基于距离和密度两种方法对算法进行优化,提高其聚类效果和运行效率。
3.通过实验评估算法效果,得出具体的结论。
4.输出论文成果,向相关领域进行贡献。
六、研究的难点1.算法优化的设计,需要具备一定的数学和计算机知识。
2.实验的设计需要满足实际应用场景,需要有较强的应用能力。
3.研究过程中可能遇到一些技术难点,需要耐心解决。
七、可行性分析K-means聚类算法是广泛使用的算法之一,其研究具有实际意义和可行性。
多维数据的分组和聚类分析方法及应用研究
多维数据的分组和聚类分析方法及应用研究随着数据产生和积累的飞速增长,多维数据的分组和聚类分析变得日益重要。
这些分析方法帮助人们理解和发现数据背后的模式和关系,从而为决策提供基础和洞察力。
本文将介绍多维数据的分组和聚类分析的常见方法,并探讨它们在不同领域的应用研究。
1. 多维数据分组分析方法多维数据分组分析的目标是将数据集划分为不同的组,使得每个组内的成员具有相似的特征。
以下是几种常见的多维数据分组分析方法:1.1. K-means聚类K-means聚类是一种基于距离的分组方法,将数据集划分为K个类别,使得每个数据点与其所属类别的质心之间的距离最小化。
该方法适用于连续变量和欧几里得距离度量的数据集。
K-means聚类具有简单、高效的优点,但对初始聚类中心的选择敏感。
1.2. 层次聚类层次聚类是一种自底向上或自顶向下的分组方法,通过计算样本间的距离或相似度来确定聚类结构。
该方法生成一个树形结构,可视化地表示不同类别之间的关系。
层次聚类不需要预先指定类别数量,但对于大规模数据集计算复杂度较高。
1.3. 密度聚类密度聚类方法基于数据点周围的密度来划分组,将样本点密度较高的区域作为一个组,较低的区域作为另一个组。
该方法可以识别复杂的聚类形状和噪声数据,适用于非凸数据集。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种常见的密度聚类方法。
2. 聚类分析方法聚类分析的目标是将数据集划分为若干个不相交的子集,每个子集中的数据点在某种意义上具有相似性。
以下是几种常见的聚类分析方法:2.1. 分层聚类分层聚类是一种基于相似性度量的聚类方法,将数据集划分为多个子集,类别数量从1逐渐增加到N。
该方法可通过树状图表示不同层级之间的相似性关系。
分层聚类的优点是不需要预先指定聚类数量,但对于大规模数据集计算复杂度较高。
2.2. 期望最大化(EM)算法EM算法是一种基于概率模型的聚类方法,通过迭代生成最大似然估计的方法来拟合数据分布。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
K-means聚类算法分析应用研究
发表时间:2011-05-09T08:59:20.143Z 来源:《魅力中国》2011年3月上作者:李曼赵松林
[导读] 本文浅谈了数字图像处理的发展概况、研究背景并对彩色图像K-means算法进行分析。
李曼赵松林
(商丘职业技术学院河南商丘,476000)
中图分类号:TP39 文献标识码:A 文章编号:1673-0992(2011)03-0000-01
摘要:本文浅谈了数字图像处理的发展概况、研究背景并对彩色图像K-means算法进行分析.主要详细谈论了是对K-means算法的一些认识,并且介绍K-means聚类的算法思想、工作原理、聚类算法流程、以及对算法结果进行分析,得出其特点及实际使用情况。
关键字:数字图像处理;K-means算法;聚类
一、数字图像处理发展概况及边缘的概念
数字图像处理(Digital Image Processing)即计算机图像处理,就是利用计算机对图像进行去除噪声、增强、复原、分割、特征提取、识别等处理的理论、方法和技术[1]。
最早出现于20世纪50年代,它作为一门学科大约形成于20世纪60年代初期。
它以改善图像的质量为对象,以改善人的视觉效果为目的。
在处理过程中,输入低质量图像,输出质量高图像,图像增强、复原、编码、压缩等都是图像处理常用的方法[1]。
数字图像处理在航天、航空、星球探测、通信技术、军事公安、生物工程和医学等领域都有广泛的应用,并取得了巨大的成就。
边缘就是图像中灰度有阶跃变化或屋顶变化的像素的集合,边缘是图像最重要的特征之一,它包含了图像的大部分信息。
实质上边缘检测就是采用算法提取图像中对象与背景间的交界线。
在目标与背景、目标与目标、区域与区域、基元与基元之间都存在边缘,这是图像分割所依赖的最重要的特征之一。
根据灰度变化的剧烈程度,边缘可以分为两种:一种是屋顶边缘,一种为阶跃性边缘。
对于屋顶状边缘,二阶导数在边缘初取极值,而对阶跃性边缘,二阶导数在边缘处零交叉;。
二、彩色图像的K-means聚类算法
(一)K-means聚类
聚类就是把数据分成几组,按照定义的测量标准,同组内数据与其他组数据相比具有较强的相似性。
K-means聚类就是首先从n个数据对象任选k个对象作为初始聚类中心;剩下的其它对象,则根据它们与这些聚类中心的距离(相似度),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);一直重复此过程直至标准测度函数收敛为止。
通常都采用均方差作标准测度函数。
k个聚类有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
聚类的用途是很广泛的。
在商业上,聚类可以帮助市场分析人员从消费者数据库中区分出不同的消费群体来,并且概括出每一类消费者的消费模式或者说习惯。
它作为数据挖掘中的一个模块,可以作为一个单独的工具以发现数据库中分布的一些深层的信息,并且概括出每一类的特点,或者把注意力放在某一个特定的类上以作进一步的分析;并且,聚类分析也可以作为数据挖掘算法中其他分析算法的一个预处理步骤。
(二)算法思想分析
输入:聚类个数k,以及包含 n个数据对象的彩色图片。
输出:满足方差最小标准的k个聚类。
处理流程:
(1)从 n个数据对象任意选择 k 个对象作为初始聚类中心;
(2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3)重新计算每个(有变化)聚类的均值(中心对象);
(4)循环(2)到(3)直到每个聚类不再发生变化为止。
首先设置K值,也就是确定若干个聚类中心。
使用rand函数随机获得K个颜色值,存放在矩阵miu中,第一次对每个像素点中的K种颜色进行迭代运算,得到最小的颜色矩阵的2范数,同时标记该颜色,依次相加的到各点的颜色矩阵总值。
再次迭代得到K中颜色的各个矩阵均值。
最后提取出标记的各个颜色,依次对各个点进行颜色赋值,使每个像素点的颜色归类。
得到聚类后的图像。
(三)算法的数学描述
(四)算法过程分析
设置K值为8,读入一幅图片后计算图像上所有的像素点个数为N,即令N=size(X,1)*size(X,2),令颜色矩阵R为矩阵[N,K]并清零。
随机获得颜色聚类中心为Miu=fix(255*rand(K,3))。
在10次迭代中,对每一个像素点进行k=8次迭代,计算该点颜色值与各个聚类中心的欧氏距离dis。
若dis最小,则标记此时颜色矩阵为R(n,k)=1。
依次对8个聚类中心迭代,计算标记的每一个坐标点的颜色总值sum1和总数量sum2,计算新的聚类中心Miu(k,:)=sum1/sum2。
再次对所有点进行迭代,根据第一次迭代时标记的R(n,k)值,若R(n,k)为真时,对该点颜色赋值为聚类中心k的颜色值。
依次分析聚类出最终效果图。
图 K-means聚类算法流程图
(五)K-means算法结果分析
K-means算法取K值为8,就是通过对每个像素点进行8次迭代找到欧式距离最小的聚类中心,依次迭代,得出平均聚类中心,以最后得到的8个平均聚类中心为图像的最优聚类中心,依次为各个像素点进行聚类操作,最后得到聚类后的图像边缘。
本算法由于要对图像的各个像素均进行多次迭代,因此执行算法将会耗费很长时间,对一幅800x600的图片进行一次聚类需要耗时200s左右,其运行效率较低。
但是由于本算法采用的是动态获取聚类中心,且直接对彩色图像的RGB颜色进行分析聚类,故得到的图像边缘检测效果比较好。
K-means算法的特点:聚类中心用各类别中所有数据的平均值表示。
三、结语
K-means算法的一个特点就是在每次迭代中都要考察每个样本的分类是否正确。
如果不正确必须调整,在调整完全部样本后,修改聚类中心,然后再进入下一次的迭代。
K-means算法工作原理[3]:首先算法随机从数据集中选K个点作为初始聚类中心,再计算每个样本到聚类中距离,把样本归到离它最近的聚类中心所在的类。
通过计算新形成的每一个聚类的数据对象的平均值得出新聚类中心,若相邻两次的聚类中心没有变化,则证明样本调整结束,聚类准则函数已经收敛。
若再一次迭代算法中,所有的样本被正确分类,就不会有调整,聚类中心也不变化,这就标志着已经收敛,算法结束。
参考文献:
[1] 何东健.数字图像处理.西安:西安电子科技大学出版社,2008;
[2] 史习云.改进的k-means聚类算法在图像检索中的应用研究[D].中国优秀硕士学位论文全文数据库,2010,(08);
[3] 赖玉霞,刘建平. K-means算法的初始聚类中心的优化[J].计算机工程与应用, 2008,(10)。