spss相关分析案例多因素方差分析
使用SPSS软件进行多因素方差分析

使用SPSS软件进行多因素方差分析使用SPSS软件进行多因素方差分析一、引言多因素方差分析是一种重要的统计方法,用于分析多个自变量对因变量的影响。
它可以帮助研究人员确定不同因素对研究对象的差异产生的影响,以及这些因素之间是否存在交互作用。
SPSS软件是一款功能强大且易于使用的统计分析工具,可以帮助用户在进行多因素方差分析时快速、准确地得出结果。
本文将介绍使用SPSS软件进行多因素方差分析的步骤,并通过一个案例来具体说明。
二、SPSS软件介绍SPSS(Statistical Package for the Social Sciences)是一款专业的统计分析软件,被广泛应用于社会科学、医学、商业等领域。
它提供了丰富的统计方法和分析工具,并具备数据清洗、可视化、报告生成等功能。
在多因素方差分析中,SPSS 可以帮助用户进行方差分析表的生成、方差分析的可视化、方差齐性检验和事后比较等操作,大大简化了分析过程。
三、多因素方差分析的步骤1. 数据准备:将需要分析的数据录入SPSS软件,并确定自变量和因变量的测量水平。
一般自变量为定类变量,而因变量可以是定量或定类变量。
2. 方差分析表的生成:选择“分析”菜单中的“一元方差分析”选项,然后将因变量添加到依赖变量框中,将自变量添加到因子框中。
接下来,点击“选项”按钮设置参数,如设定显著性水平和置信区间。
点击“确定”后,SPSS会生成方差分析表。
3. 方差分析的可视化:在方差分析表中,用户可以查看各个因素的主效应和交互作用,以及统计指标如F值、p值等。
此外,SPSS还提供了绘制效应图、交互作用图等功能,帮助用户更直观地理解分析结果。
4. 方差齐性检验:方差齐性检验用于验证因变量的变异是否在各组间具有相同的方差。
SPSS软件可以通过选择“分析”菜单中的“Compare Means”选项,进而进行多个组间方差齐性检验。
5. 事后比较:当发现方差分析存在显著差异时,需要进一步进行事后比较以确定差异所在。
spss 方差分析(多因素方差分析)实验报告

大学经济管理学院学生实验报告实验课程名称:统计软件及应用专业工商管理班级学号姓名成绩实验地点实验性质:演示性 验证性综合性设计性实验项目名称方差分析(多因素方差分析)指导教师一、实验目的掌握利用SPSS 进行单因素方差分析、多因素方差分析的基本方法,并能够解释软件运行结果。
二、实验内容及步骤(包括实验案例及基本操作步骤)实验案例:为研究某商品在不同地区和不同日期的销售差异性,调查收集了以下日平均销售量数据。
销售量日期周一至周三周四至周五周末地区一5000 6000 4000 6000 8000 3000 4000 7000 5000地区二700080008000500050006000500060004000地区三300020004000600060005000800090006000(1)选择恰当的数据组织方式建立关于上述数据的SPSS数据文件。
在SPSS输入数据。
(2)利用多因素方差分析法,分析不同地区和不同日期对该商品的销售是否产生了显著影响。
1. 选择菜单Analyze,General Linear Model,Univariate;2. 指定观测变量销售额到Dependant Variable框中;3. 指定固定效应的控制变量到Fixed Factors框中,4. OK,得到分析结果。
(3)地区和日期是否对该商品的销售产生了交互影响?若没有显著的交互影响,则试建立非饱和模型进行分析,并与饱和模型进行对比。
三、实验结论(包括SPSS输出结果及分析解释)SPSS输出的多因素方差分析的饱和模型分析:表的第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是方差;第五列是F检验统计量的观测值;第六列是检验统计量的概率P-值。
F日期,,F地区,F日期*地区概率P-值分别为0.254,0.313,0.000。
如果显著性水平α为0.05,由于F日期、,F地区大于显著性水平α,所以不应拒绝原假设,不同地区和不同日期对该商品没有显著性影响。
SPSS多因素方差分析

SPSS多因素方差分析体育统计与SPSS读书笔记(八)—多因素方差分析(1)具有两个或两个以上因素的方差分析称为多因素方差分析。
多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方差分析的时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因素了:不同教学方法的班级,不同年级。
如果再加上性别上的因素,那就成了三因素了。
如果我们把实验前和试验后的数据用一个时间的变量来表示,那又多了一个时间的因素。
如果每个年级都是不同的老师来上,那又多了一个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑,并确定自己只研究哪些因素。
下面用例子的形式来说说多因素方差分析的运用。
还是用前面说单因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。
形成年级和不同教学法班级双因素。
分析:1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格都是有重复数据(也就是不只一个数据),年级不同教学方法的班级定性班定量班定性定量班五年级页脚内容1(班级每个人)(班级每个人)(班级每个人)初中二年级(班级每个人)(班级每个人)(班级每个人)高中二年级(班级每个人)(班级每个人)(班级每个人)2.因为有重复数据,所以存在在数据交互效应的可能。
我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的影响不同,则说明A、B两因素间存在交互作用。
交互作用是多因素实验分析的一个非常重要的内容。
如因素间存在交互作用而又被忽视,则常会掩盖因素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。
在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。
在大多数场合,交互作用的信息比主效应的信息更为有用。
根据上面的判断。
根据上面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。
spss多因素方差分析报告例子
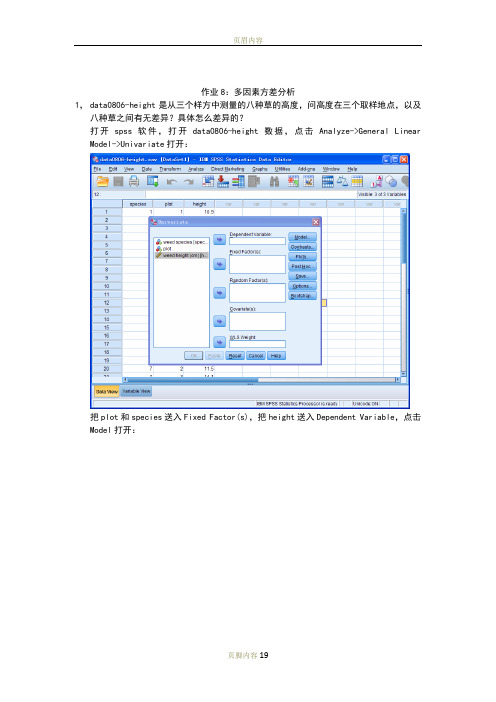
作业8:多因素方差分析1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的?打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate打开:把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model打开:选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择,结果输出:因无法计算MM M rror,即无法分开MM intercept 和MM error,无法检测interaction 的影响,无法进行方差分析,重新Analyze->General Linear Model->Univariate打开:选择好Dependent Variable和Fixed Factor(s),点击Model打开:点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate 主对话框,点击Plots:把date送入Horizontal Axis,把depth送入Separate Lines,点击Add,点击Continue 回到Univariate对话框,点击Options:把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框,输出结果:可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534;Fspecies=3.089,p=0.034<0.05;Fplot=12.130,p=0.005<0.01;所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。
SPSS-多因素方差分析

④在Univariate对话框中,单击Options…按钮。在Options对话框中, 把Factor(s) and Factor Interations栏中的变量“保存时间”、 “保存温度”、 和“保存时间*保存温度”放入Display Means for栏;并在Display多选项中,选择Descriptive statistics, Estimates of effect size,Homogeneity tests。单击Model…,选择 默认项,即Full factorial项(全析因模型),单击Continue按钮返 回。
⑤在Univariate对话框,单击OK按钮得到Univariate过程的运行结果。
7
结果
8
均数分布图
9
例2, 用5×2×2析因设计研究5种 类型的军装在两种环境、两种活动状 态下的散热效果,将100名受试者随 机等分20组,观察指标是受试者的主 观热感觉(从“冷”到“热”按等级评 分),结果见下表。试进行方差分析。
多因素方差分析
1
一、析因设计资料的方差分析 两因素两水平 三因素多水平
2
析因设计的特点
必须是: 两个以上(处理)因素(factor)(分 类变量)。 两个以上水平(level)。 两个以上重复(repeat)。 每次试验涉及全部因素,即因素同时 施加观察指标(观测值)为计量资料 (独立、正态、等方差)。
24
25
spss多因素方差分析报告例子

作业8:多因素方差分析1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的?打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate 打开:把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model 打开:选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择,结果输出:因无法计算rror,即无法分开intercept和error,无法检测interaction的影响,无法进行方差分析,重新Analyze->General Linear Model->Univariate打开:选择好Dependent Variable和Fixed Factor(s),点击Model打开:点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate主对话框,点击Plots:Univariate对话框,点击Options:把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框,输出结果:可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534;Fspecies=3.089,p=0.034<0.05;Fplot=12.130,p=0.005<0.01;所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。
多因素方差分析23460

3 0.0 35 a
3 .0 0 0
3 0.0 35 a
3 .0 0 0
3 0.0 35 a
3 .0 0 0
3 0.0 35 a
3 .0 0 0
.54 1 a
3 .0 0 0
.54 1 a
3 .0 0 0
.54 1 a
3 .0 0 0
.54 1 a
3 .0 0 0
Error df 3 6.0 00 3 6.0 00 3 6.0 00 3 6.0 00 3 6.0 00 3 6.0 00 3 6.0 00 3 6.0 00
a
11
SPSS统计软件
交叉设计方差分析
例2. 以睡眠时间增加量(小时)为效应,观察 A、B两种药物对改善失眠者的睡眠效果。已 知A、B之间没有交互作用,并且收治的失眠 患者不多,共12名。应采用何种设计较合理? (数据睡眠.sav)
a
12
SPSS统计软件design) 基本模式
SPSS统计软件
复习
1、某医生为了研究一种四类降糖新药的疗效,以统一的纳 入和排除标准选择了60名2型糖尿病患者,按完全随机设 计方案将患者分为三组进行双盲临床试验。其中,降糖新 药高剂量组21人、低剂量组19人、对照组20人。对照组服 用公认的降糖药物,治疗4周后测得其餐后两小时血糖的 下降值,问治疗4周后,餐后2小时血糖下降值的三组总体
a.
a Design: Intercept+分 组
Within Subjects Design: weight
Sig. .329 .317 .368 .547
31
SPSS统计软件
重复测量资料的方差分析
下表为受试者内因素、受试者内因素与自变量的一级交互作用的多元 方差分析统计学检验结果。
SPSS实验多因素方差分析8
29.211a
1.597
24.778
33.644
a. Based on modified population marginal mean.
Multiple Comparisons
Dependent Variable:语言能力测试得分(X3)
(I)阶层(X1)
2.两个因素即年龄和阶层对语言表达能力的影响都不显著,而且两个变量各自对语言表达能力的影响都是不显著的。
3.由于本数据中的方差齐性检验结果是具有方差齐性的,所以应就LSD的输出结果进行分析,有以上数据分析的结果表中比较相应两组均值的P值与显著性水平为0.05下可知阶层两两之间没有显著性可言,也就进一步说明了阶层对语言能力的影响不是显著性的。
Intercept
23859.980
1
23859.980
336.849
.000
阶层(X1)
300.323
2
150.162
2.120
.236
年龄(月)X2
1226.352
22
55.743
.787
.689
阶层(X1)*年龄(月)X2
24.807
1
24.807
.350
.586
Error
283.332
4
70.833
F
df1
df2
Sig.
1.328
25
4
.434
Tests the null hypothesis that the error variance of the dependent variable is equal across groups.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。
本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。
在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为:
表一
如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。
由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态
分布,并对城镇居民月平均消费状况做出近似的度量。
另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。
如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。
具体情况这里不再赘述。
下面进行多因素方差分析:
一、多变量检验
表二
由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。
二、主体间效应检验
表三
如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。
三、多重比较
表四
Contrast Results (K Matrix)
地区 Simple Contrast a
Dependent Variable 人均副食支出(元/人)
人均日用杂品支出(元
/人)
人均衣着支出(元/人)
Level 1 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.001
.036
.517
95% Confidence Interval for Difference
Lower Bound
.173
Upper Bound
Level 2 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.668
.343
.638
95% Confidence Interval for Difference
Lower Bound
Upper Bound
表四
Contrast Results (K Matrix)
地区 Simple Contrast a
Dependent Variable 人均副食支出(元/人)
人均日用杂品支出(元
/人)
人均衣着支出(元/人)
Level 1 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.001
.036
.517
95% Confidence Interval for Difference
Lower Bound
.173
Upper Bound
Level 2 vs. Level 3 Contrast Estimate
Hypothesized Value
0 0 0 Difference (Estimate - Hypothesized) Std. Error Sig.
.668
.343
.638
95% Confidence Interval for Difference
Lower Bound
Upper Bound
a. Reference category = 3
如表四,在显著水平下,东部和西部的人均副食支出(Sig.值为)和日用杂品支出(Sig.值为)指标有明显差别(小于,拒绝原假设),而在人均衣着支出(Sig.值为)指标上没有明显的差别。
并且东部的人均副食支出、衣着支出和日
用杂品支出三项指标均高于西部地区,说明东部的城镇居民月平均消费水平较西部来说,高出很多,符合实际的情况。
另外,中部和西部的人均副食支出、衣着支出和日用杂品支出(Sig.值分别为、、,均大于显著水平)三个指标均无明显差别,但中部的人均副食支出和日用杂品支出指标低于西部地区,人均衣着支出指标高于西部,说明中、西部的城镇居民月平均消费水平差不多,但消费结构有差异,符合实际的情况。
表五
表五是上面多重比较可信性的度量,由Sig.的值可以看到(均小于),比较检验是可信的。
四、协方差阵相等检验
表六
Box's Test of Equality of
Covariance Matrices a
Box's M
F
df112
df2
Sig..085
Tests the null hypothesis that
the observed covariance
matrices of the dependent
variables are equal across
groups.
a. Design: + 地区
如表六,是协方差阵相等检验,检验统计量是Box’s M,由Sig.值>可以看到,可以认为三个地区(总体)的协方差阵是相等的。
表七
表七给出了各地区同一指标误差的方差检验,在水平下,人均副食支出、衣着支出和日用杂品支出(Sig.值分别为、、,均大于)三个指标的误差平方在三个地区间均没有显著差别,这说明,除了地区因素外,其他因素对人均副食支出、衣着支出和日用杂品支出三个指标的影响很小。
综上所述,对三个地区的城镇居民月平均消费水平进行了具体的比较分析,所得结果表明,东部地区较中、西部地区的城镇居民月平均消费水平差别较大,远高于中、西部两个地区。
而中部和西部之间的城镇居民月平均消费水平差别不太明显,主要是消费结构有所不同,这说明西部地区在国家施行西部大开发政策之后发展很快,人民生活水平显著提高,赶上中部地区,体现政策的有效性。