第3章 查找与排序1
查找与排序算法方案
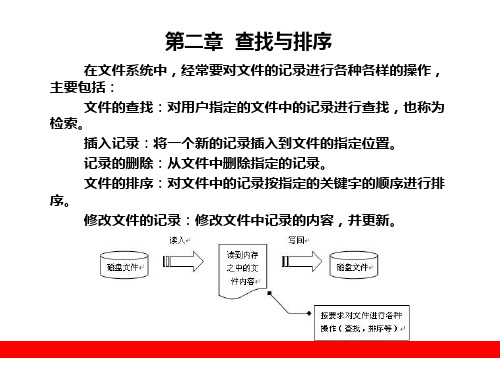
2.2 折半查找
如果从文件中读取的数据记录的关键字是有序排列的, 则可以用一种效率更高的查找方法来查找文件中的记录,这 就是折半查找法,又称为二分搜索。
折半查找的基本思想是:减小查找序列的长度,分而治 之地进行关键字的查找。它的查找过程是:先确定待查找记 录的所在的范围,然后逐渐缩小查找的范围,直至找到该记 录为止(也可能查找失败)。
2.1 顺序查找
如果一个文件具有n个连续的记录,可将该文件读到内 存中的一个顺序表中进行各种操作。顺序查找就是在文件的 关键字集合key[1,2,...,n]中找出与给定的关键字key相等的文 件记录。如图2-2所示,磁盘中有这样一个顺序文件。对文 件中记录的查找就是对其关键字的查找,找到了关键字就找 到了该关键字对应的那条记录。
直接插入排序的基本思想是:第i趟排序将序列中的第 i+1个元素ki&) 中的合适的位置,使得插入后的序列仍然保持按值有序。
2.5 选择排序
选择排序(selection sort)也是一种比较常见的排序方法。它 的基本思想是:第i趟排序从序列的后n-i+1(i=1,2,…,n-1)个元 素中选择一个最小的元素,与该n-i+1个元素的最前面那个元素 进行位置交换,也就是与第i个位置上的元素进行交换,直到 i=n-1。直观地讲,每一趟的选择排序就是从序列中未排好顺序 的元素中选择一个最小的元素,将该元素与这些未排好顺序的 元素的第一个元素交换位置。
2.3 排序的概述
对于文件而言,排序可以理解为:根据文件记录的关键 字的值的递增或者递减关系将文件的记录的次序进行重新排 列的过程。排序后的文件记录一定是按关键字值有序排列的 。例如最开始从磁盘中读出的文件如图2-5所示。
2.4 直接插入排序
第三章 计算机检索基础知识

1. 2. 3. 4.
5.
在实践中,需要根据课题的具体要求,合理 调节查全率和查准率,保证检索效果相对较优。 通常采用以下方法进行调节: 若要提高查全率,进行扩检,可按如下方法 调整检索: 选全同义词并以“OR”方式与原词连接后加入到 检索式中; 降低检索词的专指度,找出一些检索词的上位词 或相关词; 采用分类号进行检索; 删除某个不甚重要的概念组面,减少“AND”运 算; 取消某些过严的限制符,如字段限制符等。
(4)同一事物名词的单复数、不同词性、英美语的不 同形式 单数 复数 名词 动词 computer computers composition composite 英拼 colour fibre 美拼 color fiber (5)隐含概念扩展 隐含概念是显见主题的更确切的表达。 “一个取代高残杀菌剂的理想品种” 隐含了“高效低毒杀菌剂”或“高效低毒农药”
下位词: 下位概念扩展法:概念分析的树形展开法 如:汽车 卡车 轿车 货车等
所有图书馆用户能够在校外使用天津高校文献信息 中心的电子资源,比如超星电子图书、维普期刊全文数据 库、EBSCO电子期刊等。 IP通远程访问系统已开通 IP通用户登录方法: 首先要确保您使用的网络是非教育网。 WEB方式用户请登录 / 客户端软件用户请登录
1. 2. 3. 4. 5.
提高检索词的专指度,找出一些检索词的下位词或 专指性较强的相关词; 增加概念组面,用“AND”连接一些进一步限定主 题概念的相关检索项; 限制检索词出现的可检字段; 利用文献外表特征限制,如:文献类型、出版年代、 语种、作者等; 用逻辑非“NOT”来排除一些无关的检索项。
截词检索
邻近检索 限制检索 加权检索 检索词的确定
查找排序PPT课件

low=1; high=n;
while(low<=high)
{ mid=(low+high)/2;
if(ST[mid].key= = key) return (mid); /*查找成功*/
else if( key< ST[mid].key) high=mid-1; /*在前半区间继续查找*/
若k==r[mid].key,查找成功 若k<r[mid].key,则high=mid-1 若k>r[mid].key,则low=mid+1
❖重复上述操作,直至low>high时,查找失败 特点:比顺序查找方法效率高。最坏的情况下,需要比较 log2n次。
8
折半查找举例: 已知如下11个元素的有序表:
low
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
low mid
high=mid-1
( 08, 14, 23, 37, 46, 55, 68, 79,
low=mid+1
high
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
low
mid
( 08, 14, 23, 37, 46, 55, 68, 79,
5
讨论:怎样衡量查找效率?
——用平均查找长度(ASL)衡量。
如何计算ASL?
分析: 查找第1个元素所需的比较次数为1; 查找第2个元素所需的比较次数为2; …… 查找第n个元素所需的比较次数为n;
总计全部比较次数为:1+2+…+n = (1+n)n/2 因为是计算某一个元素的平均查找次数,还应当除以n, (假设查找任一元素的概率相同) 即: ASL=(1+n)/2 ,时间效率为 O(n)
数据结构(C语言版)(第2版)课后习题答案

数据结构(C语言版)(第2版)课后习题答案数据结构(C语言版)(第2版)课后习题答案目录第1章绪论1 第2章线性表5 第3章栈和队列13 第4章串、数组和广义表26 第5章树和二叉树33 第6章图43 第7章查找54 第8章排序65 第1章绪论1.简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
答案:数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称。
如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据。
数据元素:是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。
在有些情况下,数据元素也称为元素、结点、记录等。
数据元素用于完整地描述一个对象,如一个学生记录,树中棋盘的一个格局(状态)、图中的一个顶点等。
数据项:是组成数据元素的、有独立含义的、不可分割的最小单位。
例如,学生基本信息表中的学号、姓名、性别等都是数据项。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
例如:整数数据对象是集合N={0,±1,±2,。
},字母字符数据对象是集合C={‘A’,‘B’,。
,‘Z’,‘a’,‘b’,。
,‘z’},学生基本信息表也可是一个数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
换句话说,数据结构是带“结构”的数据元素的集合,“结构”就是指数据元素之间存在的关系。
逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。
因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
存储结构:数据对象在计算机中的存储表示,也称为物理结构。
抽象数据类型:由用户定义的,表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。
具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合。
2.试举一个数据结构的例子,叙述其逻辑结构和存储结构两方面的含义和相互关系。
第三章 3.1查询概述

1.(18)假设有一组数据:工资为 800 元,职称为“讲师”,性别为“男”,在下列逻辑表达式中结果为“假”的是()。
A)工资>800 AND 职称="助教" OR 职称="讲师" B)性别="女" OR NOT 职称="助教"C)工资=800 AND (职称="讲师" OR 性别="女") D)工资>800 AND (职称="讲师" OR 性别="男")2. 18,条件”Not >工资额>2000”的含义是A>选择工资额大于2000的记录B>选择工资额小于2000的记录C>选择除了工资额大于2000之外的记录D>选择除了字段工资额之外的字段,且大于2000的记录3. (18)将表A的记录复制到表B中,且不删除表B中的记录,可以使用的查询是A) 删除查询 B) 生成表查询C) 追加查询D) 交叉表查询4. (19)在一个Access的表中有字段“专业”,要查找包含“信息”两个字的记录,正确的条件表达式是______。
A)=left([专业],2)= "信息" B)like "*信息*"C)="信息*" D)Mid([专业],1,2,)= "信息" 5.(20)如果在查询的条件中使用了通配符方括号“[ ]”,它的含义是______。
A)通配任意长度的字符B)通配不在括号内的任意字符C)通配方括号内列出的任一单个字符D)错误的使用方法6. (19)下面显示的是查询设计视图的“设计网格”部分:从所显示的内容中可以判断出该查询要查找的是A)性别为“女”并且1980以前参加工作的记录B)性别为“女”并且1980以后参加工作的记录C)性别为“女”或者1980以前参加工作的记录D)性别为“女”或者1980以后参加工作的记录7.(20)若要查询某字段的值为“JSJ”的记录,在查询设计视图对应字段的准则中,错误的表达式是A)JSJ B)”JSJ”C)”*JSJ”D)Like “JSJ”8. (19)在下图中,与查询设计器的筛选标签中所设置的筛选功能相同的表达式是A.成绩表.综合成绩>=80 AND成绩表.综合成绩=<90B.成绩表.综合成绩>80 AND成绩表.综合成绩<90 C.80<=成绩表.综合成绩<=90 D.80<成绩表.综合成绩<909.(20)下图中所示的查询返回的记录是A.不包含80分和90分B.不包含80至90分数段C.包含80至90分数段D.所有的记录10.(18)若在“tEmployee”表中查找所有姓“王”的记录,可以在查询设计视图的准则行中输入A)Like "王" B)Like "王*" C)="王" D)="王*"11.(26)下列不属于操作查询的是A)参数查询B)生成表查询C)更新查询D)删除查询12.(17)将表A的记录添加到表B中,要求保持表B中原有的记录,可以使用的查询是______。
查找与排序

快速排序(不稳定) 快速排序(不稳定) 基本思想:
通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另 一部分记录的关键字小,则可分别对这两部分记录进行排序,以达到整个序列有序
具体过程:
附设两个指针low和high ,它们的初值分别为low和high,设枢轴记录的关键字为 pivotKey,则首先从high所指位置起向前搜索找到第一个关键字小于pivotKey的记录和枢轴 记录互换,然后从low所指位置起向后搜索,找到第一个关键字大于pivotKey的记录和枢轴 记录互换,重复这两步知道low=high为止。
6.BST 的查找分析 BST 上查找过程与折半查找类似,是从根结点到所找到结点的一条路径。与给定值 上查找过程与折半查找类似,是从根结点到所找到结点的一条路径。 比较次数等于该路径长度+1(即结点所在层次数),最大层次数不超过树的深度。 ),最大层次数不超过树的深度 比较次数等于该路径长度 (即结点所在层次数),最大层次数不超过树的深度。 但长度为n的折半查找表对应的判定树是唯一的。而含有 个结点的 个结点的BST却不唯一。 却不唯一。 但长度为 的折半查找表对应的判定树是唯一的。而含有n个结点的 的折半查找表对应的判定树是唯一的 却不唯一 45 24 12 37 (a) (45, 24, 53, 12, 37, 93) 53 93 12 24 37 45
3. BST的插入 插入原则:记下查找不成功时比较的最 后一个结点的位置,将插入结点作为该 结点的左或右孩子。
4. BST的生成 从空的二叉排序树开始,每输入一个结 点数据,就调用一次插入算法, 将它插入到当前已经生成的二叉 排序树中
5. BST的删除 删除的原则: 删除的原则: 删除某个结点后仍保持BST的特性。 设:被删除结点为p(指针p所指结点) 其双亲结点为parent。 具体做法: 具体做法: 删除操作必须首先进行查找操作,查找 时令p指向被删除结点,parent为其双亲 结点。若p被找到,则在删除结点p的同 时应保证BST性质不变。
第三章查询

3.3 创建交叉表查询 :
例3.8 在“教学管理设计”数据库中,创建“各系各职称教师人数统计交叉表 查询”。以“教师”表为数据源,行标题为“系别”字段,列标题为“职称” 值为教师人数。
3.4 创建参数查询:
例3.9 在“教学管理设计”数据库中,创建“输入起止工作时间教师参数查 询”。以“教师”表为数据源,通过输入起止工作时间,查询在该时间段内参 加工作的教师。结果显示“教师”表全部字段,提示分别为:“请输入起始时 间”、“请输入终止时间:”。
2、创建总计查询:
例3.5 在“教学管理设计”数据库中,创建“各系教师人数统计”。以“教师” 表为数据源,统计每个系各有多少名教师,结果显示“系别”和“教师人数” 字段。 例3.6 如果学生表中的“学生编号”的前面4位数字表示学生所在的班级号。 统计每个班级的总人数以及学生的平均年龄,结果显示“班级”、“学生人数” 和“平均年龄”字段。 例3.7 以“学生”、“课程”、“选课成绩”表为数据源,创建总计查询。查 询结果要求显示:“学生编号”、“学生姓名”、“合格门数”、“总获学分” 及“所差学分”字段。
3.6.4数据查询
例3.20 以所创建的“学生”为例,设计如下SELECT查询。 (1)从学生表中筛选出所有学生记录,结果显示所有的字段,按“系别”升序、 “年龄”降序排序。 (2)从学生表中筛选出年龄在20到23岁的所有学生记录,结果显示“姓名”、 “年纪”字段,将“年纪”字段重命名为“年龄”。 (3)从学生表中筛选出信息、数学、计算机系的学生记录,结果显示“姓名”、 “性别”、“系别”字段。 (4)从学生表中筛选姓“刘”的学生记录,结果显示“姓名”、“学号”、 “性别”字段。 (5)统计学生表中男、女学生各有多少名,结果显示“性别”、“人数”字段。 (6)从学生、课程、选课成绩表中查询不及格的成绩信息,结果显示“学生编 号”、“姓名”、“课程名称”、“学分”和“成绩”字段。
C语言课件(查找和排序)

查找与排序
简单选择排序
简单选择排序
续
printf("\nTo sort...\n");
for (i=0;i<len-1;i++) { min=i; for (j=i+1;j<len;j++) if (list[min]>list[j]) min=j; tmp=list[i]; list[i]=list[min]; list[min]=tmp; }
printf("Finished! The list has been sorted:\n"); for (i=0;i<len;i++) printf("%-4d",list[i]);
}
查找与排序
冒泡排序
冒泡排序
将相邻两个数比较,把小的调到前面,大数放到后面。
78 45 32 10 29 80 92 8 61 55 45 78 32 10 29 80 92 8 61 55 45 32 78 10 29 80 92 8 61 55 45 32 10 78 29 80 92 8 61 55 45 32 10 29 78 80 92 8 61 55 45 32 10 29 78 80 92 8 61 55 45 32 10 29 78 80 92 8 61 55 45 32 10 29 78 80 8 92 61 55 45 32 10 29 78 80 8 61 92 55 45 32 10 29 78 80 8 61 55 92 32 10 29 45 78 8 61 55 80 92 10 29 32 45 8 61 55 78 80 92
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
哈希码构造常用的几种方法
1.除法
哈希码i=mod(k,n) 2.乘法 哈希码i=mod(k* ,n)
几种常用的哈希表
哈希表技术关键之一就是要处理好冲突问 题。采用不同的方法处理冲突就可以得到 不同的哈希表。常用的有: 1.线性哈希表 2. 随机哈希表 3.溢出哈希表 4.拉链哈希表 5.指标哈希表
1 6 7 12 13 18
22 12 13 8 9 20 33 42 44 38 24 46 60 58 74 47 86 53
分块有序表
47 8 查找元素 38
mid 22 1
low
46 7
86 13
high
12 13
struct indnode{ ET key; int k; }; indnode s[m];
k
顺序查找数据元素 b h
e a w c b m p g
1 2 3 4 5 6 7 8
int search(ET V[],int n,ET x){
在线性表V中查找 其元素等于给定值 x的数据元素,若 找到,则返回其在 V中的下标,否则 返回-1。 k=1; while(k<=n)andV(k)!=x) k++; if(k==n+1) k=-1;
k
c head
e
b
d 0
顺序查找数据元素b
3.1.2. 有序表的对分查找
有序表的对分查找只适用于顺序存 储的有序表,即线性表中的元素按 值非递减排列。
25 查找元素 24
mid
1 2 3 4 5 6 7 8 9 10 11 12 13 2 5 7 9 12 15 17 19 24 28 30 34 36
low
int bsearch(ET v[],int n,ET x){ low=1;high=n; while(low<=high){ mid=(low+high)/2; if(v[mid]==x) return mid; if(v[mid]<x) low=mid+1; else high=mid-1; } return -1;
(1)计算元素k的2)伪随机序列初始化,令j=1,即发生冲 突时从伪随机序列第一个开始试探。 造 (3)检查表中第i项的内容: 过 *若第i项为空,则将元素k填入该位置。 程 *若第i向不空,则令
i=mod(i0+RN(j),n),并令j=j+1,即取下 一个随机数进行试探,转(3)继续检查。
例如:将线性表 (9,31,26,19,1,13,2,11,27,16,5,21)依次 填入长度n=12的溢出哈希表中,哈希函数为 i=INT(k/3)+1,其中INT为取整符。 溢出哈希表 i 1 2 3 4 5 6 7 8 9 10 11 12 哈希表 k 1 5 9 13 16 19 21 26 27 31 i 1 2 3 4 溢出表 k 2 11
外 拉 链 哈 希 表
1 2 3 4 5 6 7 8 9 10 11 12
1 2
0
0 0 0 0 0 0 0 0 0
5
0
11 9 13 16 19 21 26 27 31
0
5.指标哈希表
当表中各数据元素的类型不同,即 长度不相等时,则哈希表表项的空 间设计很困难,如果都按最大长度 设计,则会造成存储空间浪费。在 这种情况下,需要用指标哈希表。 指标哈希表包括指标表与内容表。
例如:将线性表 (9,31,26,19,1,13,2,11,27,16,5,21)依次 填入长度n=16的随机哈希表中,哈希函数为 i=INT(k/3)+1,其中INT为取整符。
位随机序列为: 1,6,15,12,13,2,11,8,9,14,7,4,5,10,3,0
表项序号 元素值k 冲突次数
1 1 0
但直接查找表的哈希函数是不容易构造的, 在实际应用中,往往会出现不同的元素值 k1!=k2,会有i(k1)!=i(k2),这就发生了元素 的冲突,即两个不同的元素需要存放在同 一个存储位置上。
哈希表:设表的长度为n,如果存在一个 例如:线性表 函数i=i(k),对于表中的任意一个元素k (9,31,26,19,1,13,2,11,27,16,5,21)依次 均满足1<=i<=n,则称此表为哈希表。 填入长度n=12的表中,哈希函数为 函数i=i(k)称为哈希码或哈希函数。 i=INT(k/3)+1,其中INT为取整符。 哈希表 填入结果 表项序号 1 2 3 4 5 6 7 8 9 10 11 12 9 13 16 19 21 26 27 31 按i=INT(k/3)+1 1 5 填入的元素值 2 11
哈希表技术需要处理好冲突问题,主要包 括以下两方面工作: (1)哈希码的均匀性要比较好。即尽量减 少元素冲突的次数。 (2)当表中发生冲突是要进行适当的处理。
哈希码的构造
哈希表技术的主要目标是提高查找效率, 因此在实际设计哈希码是主要考虑: (1)哈希码的均匀性要好。即尽量减少冲 突发生的机会,使元素尽可能均匀地分布 在哈希表中。 (2) 哈希码的计算要尽量简单。
在线性哈希表中查找元素k (1)计算元素k的哈希码i=i(k) (2)检查表中第i项的内容: *若第i项内容为k,则取出该元素值即可 *若第i向为空,则表示在哈希表中没有 该元素。 *若第i项不空,且其内容不是k,则令 i=mod(i+1,n),转(2)继续检查。
2. 随机哈希表 长度为n=2a
其中,CH1 表示元素中第1 个字母,Ord 为字符的次序 函数。则以表长为14的顺序 表表示的查找表如图
0 1 Chen 2 Dei 3 4 Han 5 6 Li 7 8 Qian 9 Sun 10 11 Wu 12 Ye 13 Zhao
上例表为直接查找表,其满足以下条件: 设表的长度为n,如果存在一个函数i=i(k), 对于表中的任意一个元素值k,满足: (1)1<=i<=n; (2)对于任意元素值k1=k2,都存在i(k1)=i(k2).
在哈希码比较均匀且冲突不多的情况下,溢 出哈希表具有一定的适用价值。
4.拉链哈希表
拉链哈希表分为外拉链哈希表和内拉 链哈希表,这里介绍外拉链哈希表。 外拉链哈希表由哈希表及表外结点组成。 将哈希码相同的结点连接成单链表,单链 表的头指针就存放在哈希表中。 例如:将线性表 (9,31,26,19,1,13,2,11,27,16,5,21)依次 填入长度n=12的外链哈希表中,哈希函数为 i=INT(k/3)+1,其中INT为取整符。
2 2 1
3 5 1
4 5 6 7 8 9 13 16 19 21 0 0 0 0 0
表项序号 9 10 11 12 13 14 15 16 元素值k 26 11 31 27 冲突次数 0 2 0 2
3.溢出哈希表
溢出哈希表处理冲突的策略是将发 生冲突的元素安排另外的空间内, 则就不会产生新的冲突,这就是溢 出表。所以溢出哈希表包括哈希表 和溢出表两部分。
return k; }
顺序查找缺点:对于大的线性表来说 效率低。
顺序查找优点:算法简单而且适用面广, 适用于: (1)线性表为无序表时 (2)有序表采用链式存储结构时。
在头指针为head的线性链表中顺序查找元 素x,函数返回被查找元素x所在结点的存 储地址。
node* lsearch (node* head, ET x ){ node k=head; while(k!=NULL&&k->data!=x) k=k->next; return k; }
i=s[high].k; j=s[high+1].k-1;
int insearch(ET v[],int m,int n,ET x,indnode s[]){ //分块有序表v,长度为n,索引表数组s的结点数m,查找x low=1;high=m; while(high-1>low){//对分查找索引表 mid=(low+high)/2; if(x<=s[mid].key) high=mid; else low=mid;} i=1; //i是所在子表的起始位序 if((low!=high)&&(x>s[low].key)) i=s[high].k; j=n; //j是所在子表的终止位序 if(high!=m&&x>s[low].key) j=s[high+1].k-1; else j=s[high].k-1; while((i<=j)&&(v[i]!=x)) i++; if(i>j) i=-1; return i; }
第3章
查找与排序技术
3.1 基本的查找技术 3.2 哈希表技术 3.3 基本的排序技术 3.4 二叉排序树及其查找
3.1 基本的查找技术
查找是数据处理领域的一个重要内容, 查找的效率将直接影响到数据处理的 效率。所谓查找是指在一个给定的数 据结构中查找指定的元素。通常,根 据不同的数据结构应采用不同的查找 方法。
3.2 哈希表技术
哈希表技术是一种重要的查找技术,其基 本思想是对被查元素做某种运算后直接确 定其在表中的位置。所以哈希查找方法是 用元素值进行计算元素存储位置的查找方 法。
元素在表中的位置为该元素的某个函数, 通常称这种函数为“哈希函数”或“哈希码”
例如,对于关键字序列 { Zhao,Qian,Sun, Li,Wu,Chen,Han,Ye,Dei }, 可设关键字的哈希函数如下: i(k)=[(ord(CH1)-ord(‘A’)+1)/2]
学习要求
1.熟练掌握顺序表和有序表的链式存 储结构的顺序查找方法; 2.熟悉掌握有序表的对分查找方法; 3.了解分块有序表的分块查找方法; 4.熟练掌握常用哈希表的构造方法,深刻 理解哈希表与其它结构的表的实质性的差别;