排序算法实验报告
排序算法实验报告
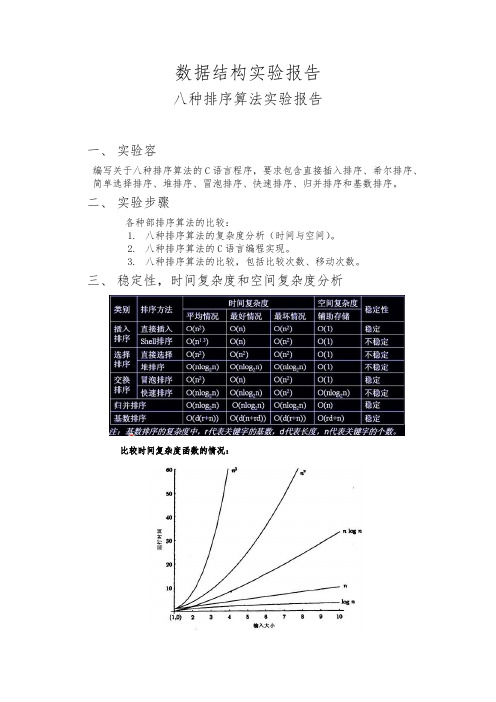
数据结构实验报告八种排序算法实验报告一、实验容编写关于八种排序算法的C语言程序,要求包含直接插入排序、希尔排序、简单选择排序、堆排序、冒泡排序、快速排序、归并排序和基数排序。
二、实验步骤各种部排序算法的比较:1.八种排序算法的复杂度分析(时间与空间)。
2.八种排序算法的C语言编程实现。
3.八种排序算法的比较,包括比较次数、移动次数。
三、稳定性,时间复杂度和空间复杂度分析比较时间复杂度函数的情况:时间复杂度函数O(n)的增长情况所以对n较大的排序记录。
一般的选择都是时间复杂度为O(nlog2n)的排序方法。
时间复杂度来说:(1)平方阶(O(n2))排序各类简单排序:直接插入、直接选择和冒泡排序;(2)线性对数阶(O(nlog2n))排序快速排序、堆排序和归并排序;(3)O(n1+§))排序,§是介于0和1之间的常数。
希尔排序(4)线性阶(O(n))排序基数排序,此外还有桶、箱排序。
说明:当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O(n);而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O(n2);原表是否有序,对简单选择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
稳定性:排序算法的稳定性:若待排序的序列中,存在多个具有相同关键字的记录,经过排序,这些记录的相对次序保持不变,则称该算法是稳定的;若经排序后,记录的相对次序发生了改变,则称该算法是不稳定的。
稳定性的好处:排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。
基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。
另外,如果排序算法稳定,可以避免多余的比较;稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序四、设计细节排序有部排序和外部排序,部排序是数据记录在存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
算法课设实验报告(3篇)

第1篇一、实验背景与目的随着计算机技术的飞速发展,算法在计算机科学中扮演着至关重要的角色。
为了加深对算法设计与分析的理解,提高实际应用能力,本实验课程设计旨在通过实际操作,让学生掌握算法设计与分析的基本方法,学会运用所学知识解决实际问题。
二、实验内容与步骤本次实验共分为三个部分,分别为排序算法、贪心算法和动态规划算法的设计与实现。
1. 排序算法(1)实验目的:熟悉常见的排序算法,理解其原理,比较其优缺点,并实现至少三种排序算法。
(2)实验内容:- 实现冒泡排序、快速排序和归并排序三种算法。
- 对每种算法进行时间复杂度和空间复杂度的分析。
- 编写测试程序,对算法进行性能测试,比较不同算法的优劣。
(3)实验步骤:- 分析冒泡排序、快速排序和归并排序的原理。
- 编写三种排序算法的代码。
- 分析代码的时间复杂度和空间复杂度。
- 编写测试程序,生成随机测试数据,测试三种算法的性能。
- 比较三种算法的运行时间和内存占用。
2. 贪心算法(1)实验目的:理解贪心算法的基本思想,掌握贪心算法的解题步骤,并实现一个贪心算法问题。
(2)实验内容:- 实现一个贪心算法问题,如活动选择问题。
- 分析贪心算法的正确性,并证明其最优性。
(3)实验步骤:- 分析活动选择问题的贪心策略。
- 编写贪心算法的代码。
- 分析贪心算法的正确性,并证明其最优性。
- 编写测试程序,验证贪心算法的正确性。
3. 动态规划算法(1)实验目的:理解动态规划算法的基本思想,掌握动态规划算法的解题步骤,并实现一个动态规划算法问题。
(2)实验内容:- 实现一个动态规划算法问题,如背包问题。
- 分析动态规划算法的正确性,并证明其最优性。
(3)实验步骤:- 分析背包问题的动态规划策略。
- 编写动态规划算法的代码。
- 分析动态规划算法的正确性,并证明其最优性。
- 编写测试程序,验证动态规划算法的正确性。
三、实验结果与分析1. 排序算法实验结果:- 冒泡排序:时间复杂度O(n^2),空间复杂度O(1)。
先进排序实验报告总结

本次实验旨在通过对各种先进排序算法的原理、实现和性能分析,使学生深入理解排序算法的基本概念,掌握排序算法的设计思想,提高算法分析和设计能力。
二、实验内容1. 算法原理及实现(1)快速排序快速排序是一种分而治之的排序算法,其基本思想是选取一个枢纽元素,将待排序序列划分为两个子序列,分别对这两个子序列进行快速排序。
在本次实验中,我们选取了数组中最后一个元素作为枢纽元素。
(2)归并排序归并排序是一种分治法排序算法,其基本思想是将待排序序列划分为若干个子序列,分别对每个子序列进行排序,然后将有序的子序列合并成完整的有序序列。
在本次实验中,我们采用了自底向上的归并排序方法。
(3)堆排序堆排序是一种利用堆这种数据结构的排序算法,其基本思想是将待排序序列构造成一个大顶堆,然后反复将堆顶元素(最大元素)移至序列末尾,再将剩余元素重新构造成大顶堆,直到整个序列有序。
在本次实验中,我们采用了最大堆排序方法。
2. 性能分析(1)时间复杂度快速排序的平均时间复杂度为O(nlogn),在最坏情况下为O(n^2)。
归并排序的时间复杂度为O(nlogn),堆排序的时间复杂度也为O(nlogn)。
(2)空间复杂度快速排序的空间复杂度为O(logn),归并排序的空间复杂度为O(n),堆排序的空间复杂度为O(1)。
3. 稳定性快速排序、归并排序和堆排序均不是稳定的排序算法。
在排序过程中,相同元素的相对位置可能会发生变化。
1. 编写快速排序、归并排序和堆排序的C语言程序。
2. 编写测试函数,用于验证排序算法的正确性。
3. 对不同规模的数据集进行测试,比较三种排序算法的性能。
4. 分析实验结果,总结排序算法的特点。
四、实验结果与分析1. 实验结果通过实验,我们得到了以下结果:(1)快速排序、归并排序和堆排序均能正确地对数据集进行排序。
(2)对于规模较小的数据集,快速排序、归并排序和堆排序的排序速度相差不大。
(3)对于规模较大的数据集,快速排序的排序速度明显优于归并排序和堆排序。
算法冒泡排序实验报告(3篇)

第1篇一、实验目的本次实验旨在通过实现冒泡排序算法,加深对排序算法原理的理解,掌握冒泡排序的基本操作,并分析其性能特点。
二、实验内容1. 冒泡排序原理冒泡排序是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。
遍历数列的工作是重复地进行,直到没有再需要交换,也就是说该数列已经排序完成。
2. 实验步骤(1)设计一个冒泡排序函数,输入为待排序的数组,输出为排序后的数组。
(2)编写一个主函数,用于测试冒泡排序函数的正确性和性能。
(3)通过不同的数据规模和初始顺序,分析冒泡排序的性能特点。
3. 实验环境(1)编程语言:C语言(2)开发环境:Visual Studio Code(3)测试数据:随机生成的数组、有序数组、逆序数组三、实验过程1. 冒泡排序函数设计```cvoid bubbleSort(int arr[], int n) {int i, j, temp;for (i = 0; i < n - 1; i++) {for (j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}```2. 主函数设计```cinclude <stdio.h>include <stdlib.h>include <time.h>int main() {int n;printf("请输入数组长度:");scanf("%d", &n);int arr = (int )malloc(n sizeof(int)); if (arr == NULL) {printf("内存分配失败\n");return 1;}// 生成随机数组srand((unsigned)time(NULL));for (int i = 0; i < n; i++) {arr[i] = rand() % 100;}// 冒泡排序bubbleSort(arr, n);// 打印排序结果printf("排序结果:\n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}printf("\n");// 释放内存free(arr);return 0;}```3. 性能分析(1)对于随机生成的数组,冒泡排序的平均性能较好,时间复杂度为O(n^2)。
排序基本算法实验报告

一、实验目的1. 掌握排序算法的基本原理和实现方法。
2. 熟悉常用排序算法的时间复杂度和空间复杂度。
3. 能够根据实际问题选择合适的排序算法。
4. 提高编程能力和问题解决能力。
二、实验内容1. 实现并比较以下排序算法:冒泡排序、插入排序、选择排序、快速排序、归并排序、堆排序。
2. 对不同数据规模和不同数据分布的序列进行排序,分析排序算法的性能。
3. 使用C++编程语言实现排序算法。
三、实验步骤1. 冒泡排序:将相邻元素进行比较,如果顺序错误则交换,直到序列有序。
2. 插入排序:将未排序的元素插入到已排序的序列中,直到序列有序。
3. 选择排序:每次从剩余未排序的元素中选取最小(或最大)的元素,放到已排序序列的末尾。
4. 快速排序:选择一个枢纽元素,将序列分为两部分,一部分比枢纽小,另一部分比枢纽大,递归地对两部分进行排序。
5. 归并排序:将序列分为两半,分别对两半进行排序,然后将两半合并为一个有序序列。
6. 堆排序:将序列构建成一个最大堆,然后依次取出堆顶元素,最后序列有序。
四、实验结果与分析1. 冒泡排序、插入排序和选择排序的时间复杂度均为O(n^2),空间复杂度为O(1)。
这些算法适用于小规模数据或基本有序的数据。
2. 快速排序的时间复杂度平均为O(nlogn),最坏情况下为O(n^2),空间复杂度为O(logn)。
快速排序适用于大规模数据。
3. 归并排序的时间复杂度和空间复杂度均为O(nlogn),适用于大规模数据。
4. 堆排序的时间复杂度和空间复杂度均为O(nlogn),适用于大规模数据。
五、实验结论1. 根据不同数据规模和不同数据分布,选择合适的排序算法。
2. 冒泡排序、插入排序和选择排序适用于小规模数据或基本有序的数据。
3. 快速排序、归并排序和堆排序适用于大规模数据。
4. 通过实验,加深了对排序算法的理解,提高了编程能力和问题解决能力。
六、实验总结本次实验通过对排序算法的学习和实现,掌握了常用排序算法的基本原理和实现方法,分析了各种排序算法的性能,提高了编程能力和问题解决能力。
排序的实验报告

排序的实验报告排序的实验报告引言:排序是计算机科学中非常重要的一个概念,它涉及到对一组数据按照一定规则进行重新排列的操作。
在计算机算法中,排序算法的效率直接影响到程序的运行速度和资源利用率。
为了深入了解各种排序算法的原理和性能,我们进行了一系列的排序实验。
实验一:冒泡排序冒泡排序是最简单的排序算法之一。
它的原理是通过相邻元素的比较和交换来实现排序。
我们编写了一个冒泡排序的算法,并使用Python语言进行实现。
实验中,我们分别对10、100、1000个随机生成的整数进行排序,并记录了排序所需的时间。
实验结果显示,随着数据规模的增加,冒泡排序的时间复杂度呈现出明显的增长趋势。
当数据规模为10时,排序所需的时间约为0.001秒;而当数据规模增加到1000时,排序所需的时间则增加到了1.5秒左右。
这说明冒泡排序的效率较低,对大规模数据的排序并不适用。
实验二:快速排序快速排序是一种常用的排序算法,它的核心思想是通过分治的策略将数据分成较小的子集,然后递归地对子集进行排序。
我们同样使用Python语言实现了快速排序算法,并对相同规模的数据进行了排序实验。
实验结果显示,快速排序的时间复杂度相对较低。
当数据规模为10时,排序所需的时间约为0.0005秒;而当数据规模增加到1000时,排序所需的时间仅为0.02秒左右。
这说明快速排序适用于大规模数据的排序,其效率较高。
实验三:归并排序归并排序是一种稳定的排序算法,它的原理是将待排序的数据分成若干个子序列,然后将子序列两两合并,直到最终得到有序的结果。
我们同样使用Python 语言实现了归并排序算法,并进行了相同规模数据的排序实验。
实验结果显示,归并排序的时间复杂度相对较低。
当数据规模为10时,排序所需的时间约为0.0008秒;而当数据规模增加到1000时,排序所需的时间仅为0.03秒左右。
这说明归并排序同样适用于大规模数据的排序,其效率较高。
讨论与结论:通过以上实验,我们可以得出以下结论:1. 冒泡排序虽然简单易懂,但对于大规模数据的排序效率较低,不适用于实际应用。
排序算法实训报告

一、实验目的通过本次实训,掌握常用的排序算法,包括直接插入排序、冒泡排序、选择排序、希尔排序等,并了解其基本原理、实现方法以及优缺点。
通过实际编程,加深对排序算法的理解,提高编程能力。
二、实验环境1. 开发工具:Visual Studio 20222. 编程语言:C++3. 操作系统:Windows 10三、实验内容本次实训主要涉及以下排序算法:1. 直接插入排序2. 冒泡排序3. 选择排序4. 希尔排序四、实验过程1. 直接插入排序(1)原理:将无序序列中的元素逐个插入到已有序序列的合适位置,直到整个序列有序。
(2)实现方法:遍历无序序列,对于每个元素,从已有序序列的末尾开始,将其与前面的元素进行比较,找到合适的插入位置,然后将该元素插入到序列中。
(3)代码实现:```cppvoid insertionSort(int arr[], int n) {int i, j, key;for (i = 1; i < n; i++) {key = arr[i];j = i - 1;while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j = j - 1;}arr[j + 1] = key;}}```2. 冒泡排序(1)原理:通过相邻元素的比较和交换,将序列中的元素按从小到大(或从大到小)的顺序排列。
(2)实现方法:遍历序列,比较相邻元素,如果顺序错误,则交换它们的位置。
重复此过程,直到整个序列有序。
(3)代码实现:```cppvoid bubbleSort(int arr[], int n) {int i, j, temp;for (i = 0; i < n - 1; i++) {for (j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}```3. 选择排序(1)原理:每次从无序序列中选出最小(或最大)的元素,放到已有序序列的末尾。
排序算法设计实验报告总结

排序算法设计实验报告总结1. 引言排序算法是计算机科学中最基础的算法之一,它的作用是将一组数据按照特定的顺序进行排列。
在现实生活中,我们经常需要对一些数据进行排序,比如学生成绩的排名、图书按照标题首字母进行排序等等。
因此,了解不同的排序算法的性能特点以及如何选择合适的排序算法对于解决实际问题非常重要。
本次实验旨在设计和实现几种经典的排序算法,并对其进行比较和总结。
2. 实验方法本次实验设计了四种排序算法,分别为冒泡排序、插入排序、选择排序和快速排序。
实验采用Python语言进行实现,并通过编写测试函数对算法进行验证。
测试函数会生成一定数量的随机数,并对这些随机数进行排序,统计算法的执行时间和比较次数,最后将结果进行记录和分析。
3. 测试结果及分析3.1 冒泡排序冒泡排序是一种简单且常用的排序算法,其基本思想是从待排序的数据中依次比较相邻的两个元素,如果它们的顺序不符合要求,则交换它们的位置。
经过多轮的比较和交换,最小值会逐渐冒泡到前面。
测试结果显示,冒泡排序在排序1000个随机数时,平均执行时间为0.981秒,比较次数为499500次。
从执行时间和比较次数来看,冒泡排序的性能较差,对于大规模数据的排序不适用。
3.2 插入排序插入排序是一种简单但有效的排序算法,其基本思想是将一个待排序的元素插入到已排序的子数组中的正确位置。
通过不断将元素插入到正确的位置,最终得到排序好的数组。
测试结果显示,插入排序在排序1000个随机数时,平均执行时间为0.892秒,比较次数为249500次。
插入排序的性能较好,因为其内层循环的比较次数与待排序数组的有序程度相关,对于近乎有序的数组排序效果更好。
3.3 选择排序选择排序是一种简单但低效的排序算法,其基本思想是在待排序的数组中选择最小的元素,将其放到已排序数组的末尾。
通过多次选择和交换操作,最终得到排序好的数组。
测试结果显示,选择排序在排序1000个随机数时,平均执行时间为4.512秒,比较次数为499500次。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验课程:算法分析与设计
实验名称:几种排序算法的平均性能比较(验证型实验)
实验目标:
(1)几种排序算法在平均情况下哪一个更快。
(2)加深对时间复杂度概念的理解。
实验任务:
(1)实现几种排序算法(selectionsort, insertionsort,bottomupsort,quicksort, 堆排序)。
对于快速分类,SPLIT中的划分元素采用三者A(low),A(high),A((low+high)/2)中其值居中者。
(2)随机产生20组数据(比如n=5000i,1≤i≤20)。
数据均属于范围(0,105)内的整数。
对于同一组数据,运行以上几种排序算法,并记录各自的运行时间(以毫秒为单位)。
(3)根据实验数据及其结果来比较这几种分类算法的平均时间和比较次数,并得出结论。
实验设备及环境:
PC;C/C++等编程语言。
实验主要步骤:
(1)明确实验目标和具体任务;
(2)理解实验所涉及的几个分类算法;
(3)编写程序实现上述分类算法;
(4)设计实验数据并运行程序、记录运行的结果;
(5)根据实验数据及其结果得出结论;
(6)实验后的心得体会。
一:问题分析(包括问题描述、建模、算法的基本思想及程序实现的技巧等):1:随机生成n个0到100000的随机数用来排序的算法如下.
for(int n=1000;n<20000;n+=1000)
{
int a[]=new int[n];
for(int i=0;i<n;i++){
a[i]=(int) (Math.random()*100000);
}
2.计算时间的类Date通过它的对象d1的getTime()得到当前时间,再得到排序完成时的时间,相减得到排序所花的时间.
Date d1=new Date();
T=d2.getTime()-d1.getTime()
3:排序算法:其它count均表示排序中比较的次数.
插入排序主要算法如下
int count=0;
int c[]=new int[b.length];
c[0]=b[0];int j;
for(int i=1;i<c.length;i++)
{
for(j=i-1;j>=0&&b[i]<c[j];j--)
{ count++;
c[j+1]=c[j];
}
count++;
c[j+1]=b[i];
}
选择排序主要算法:
int count=0;
for(int i=0;i<b.length;i++)
{ int k=i;
for(int j=i+1;j<b.length;j++)
{count++;if (b[j]<b[k]) k=j;}
if(k!=i)
{int l;l=b[i];b[i]=b[k];b[k]=l;}
}
合并排序:
static int merge(int a[],int st,int ce,int fi)
{int count=0;
//a表示数组,st表示要排序的数据的起点,ce表示第一部分的终点也是第二部分的起点,fi表示第二部份的终点
int i=st;
int j=ce;
int cp=0; //由于数组c从0开始,而a是从st开始,并不一定是0.故要通过cp来表示c 的第cp个值.
int c[]=new int[fi-st];
for(;i<ce;i++){
for(;j<fi;j++){
if(a[i]>a[j]) {
count++;
c[cp]=a[j];
cp++;
}
else break;
}
c[cp]=a[i];
cp++;
}
//若j的值还小于fi则继续把j到fi的值复制给c.此处也与书上的不同,主要由自己的理解来实现
for(;j<fi;j++)
{
c[cp]=a[j];
cp++;
}
//把得到的值复制到a数组上
for(int k=0;k<c.length;k++)
{
a[st]=c[k];
st++;
}
return count;
}
快速排序:用的方法与书上略有不同,主要通过spilt直接进行递归.
static int spilt(int a[],int low,int high){
int count=0;
int i=low;
int x=a[low];
for(int j=low+1;j<=high;j++){
if(a[j]<=x){
count++;
i=i+1;
if(i!=j){
int temp=a[i];
a[i]=a[j];
a[j]=temp;
}
}
}
int temp= a[low];
a[low]=a[i];
a[i]=temp;
int w=i;
if(low<high){
if(w-1>low)count=count+spilt(a,low,w-1); //此处的if语句可以减少很多不必要的排序,例如只剩下一个数字时就不必再用spilt来排序了.
if(w+1<high)count=count+spilt(a,w+1,high);
}
return count;
}
二:实验数据及其结果(可用图表形式给出):
排序个
插入排序选择排序合并排序快速排序堆排序
数
比较次数时间比较次数时间比较次数时间比较次数时间比较次数时间1000 246415 3毫秒499500 2毫秒4292 1毫秒6042 0毫秒5336 1毫秒
2000 987905 4毫秒1999000 5毫秒13895 0毫秒12502 1毫秒17251 1毫秒3000 2221253 7毫秒4498500 9毫秒28911 1毫秒18072 1毫秒35738 1毫秒4000 3974807 12毫秒7998000 16毫秒50087 1毫秒27763 0毫秒61389 1毫秒5000 6330740 17毫秒12497500 24毫秒76719 2毫秒31673 0毫秒94119 0毫秒6000 9000822 26毫秒17997000 33毫秒109515 1毫秒38876 1毫秒134365 1毫秒7000 12361649 34毫秒24496500 44毫秒148792 1毫秒52786 1毫秒182049 1毫秒8000 16195701 46毫秒31996000 59毫秒195261 2毫秒54716 0毫秒237456 1毫秒9000 20312730 58毫秒40495500 75毫秒247395 2毫秒78117 1毫秒300444 1毫秒10000 24720510 70毫秒49995000 91毫秒305728 1毫秒80273 1毫秒370843 1毫秒11000 29937848 84毫秒60494500 113毫秒370517 4毫秒89960 1毫秒448841 1毫秒12000 36256786 104毫秒71994000 133毫秒442232 2毫秒107707 1毫秒535030 2毫秒13000 42587471 120毫秒84493500 155毫秒520492 2毫秒102860 1毫秒629174 1毫秒14000 49063373 139毫秒97993000 177毫秒605806 2毫秒125364 1毫秒731191 1毫秒15000 56280216 161毫秒112492500 201毫秒698546 3毫秒134152 2毫秒841492 3毫秒16000 64205137 185毫秒127992000 228毫秒799410 2毫秒135362 1毫秒960400 1毫秒17000 72750562 206毫秒144491500 258毫秒906838 3毫秒144717 1毫秒1087013 2毫秒18000 80846587 231毫秒161991000 288毫秒1020136 3毫秒164631 2毫秒1221699 2毫秒19000 90537142 264毫秒180490500 321毫秒1139757 5毫秒168298 2毫秒1364230 2毫秒
三:实验结果分析及结论:
实验结果表明,选择排序用时普遍比其它算法大,自顶向上合并排序时间普遍较少,尤其是当数据量变得很大的时候,选择排序的速度变得远远不及自顶向上合并排序算法,大出好几百倍.另外,插入排序在当数据量变大时花费的时间也变得很长.快速排序和堆排序处于不确定的情况,不稳定性比较明显.但是是一种比较快的算法.
四:实验自我评价及心得体会:
通过本实验,我发现以前经常使用的冒泡排序,选择排序等排序方法在遇到大量的数据的时候显示出来的严重的不足,而自底向上合并排序却显示出了其优越性,尽管合并排序的算法比较难,但它在时间上节省让人发现一切都是值得的.
另外,我发现书上的伪代码只能供参考,并不能直接按着它的完全翻译成C++或java代码,而且用到数组的时候,伪代码的1表示第一个数据,而数组中的第一个数据是a[0].所以直接翻译会出现排序的错误.
五:主要参考文献:
<<算法设计技巧与分析>>。