蛋白质家族数据库 Pfam - 上海交通大学生物信息学与生物
蛋白质数据库

生物芯片北京国家工程研究中心湖南中药现代化药物筛选分中心暨湖南涵春生物有限公司常用数据库名录1、蛋白质数据库PPI - JCB 蛋白质与蛋白质相互作用网络•Swiss-Prot - 蛋白质序列注释数据库•Kabat - 免疫蛋白质序列数据库•PMD - 蛋白质突变数据库•InterPro - 蛋白质结构域和功能位点•PROSITE - 蛋白质位点和模型•BLOCKS - 生物序列分析数据库•Pfam - 蛋白质家族数据库 [镜像: St. Louis (USA), Sanger Institute, UK, Karolinska Institutet (Sweden)] •PRINTS - 蛋白质 Motif 数据库•ProDom - 蛋白质结构域数据库 (自动产生)•PROTOMAP - Swiss-Prot蛋白质自动分类系统•SBASE - SBASE 结构域预测数据库•SMART - 模式结构研究工具•STRING - 相互作用的蛋白质和基因的研究工具•TIGRFAMs - TIGR 蛋白质家族数据库•BIND - 生物分子相互作用数据库•DIP - 蛋白质相互作用数据库•MINT - 分子相互作用数据库•HPRD - 人类蛋白质查询数据库•IntAct - EBI 蛋白质相互作用数据库•GRID - 相互作用综合数据库•PPI - JCB 蛋白质与蛋白质相互作用网络2、蛋白质三级结构数据库•PDB - 蛋白质数据银行•BioMagResBank - 蛋白质、氨基酸和核苷酸的核磁共振数据库•SWISS-MODEL Repository - 自动产生蛋白质模型的数据库•ModBase - 蛋白质结构模型数据库•CATH - 蛋白质结构分类数据库•SCOP - 蛋白质结构分类 [镜像: USA | Israel | Singapore | Australia]•Molecules To Go - PDB数据库查询•BMM Domain Server - 生物分子模型数据库•ReLiBase - 受体/配体复合物数据库 [镜像: USA]•TOPS - 蛋白质拓扑图•CCDC - 剑桥晶体数据中心 (剑桥结构数据库 (CSD))•HSSP - 蛋白质二级结构数据库•MutaProt - PDB数据库中点突变的比较•SWISS-3DIMAGE - 蛋白质和其他生物分子的三维图像•BioImage - 生物图像数据库 (包含生物大分子图像) 3、蛋白质组数据库和链接•2-D胶数据库以及与2-D胶相关的数据库•蛋白质组链接4、与核酸相关的数据库•EMBL - EMBL核酸序列数据库 (EBI)•Genbank - GenBank核酸序列数据库 (NCBI)•DDBJ - 日本DNA数据库•dbEST - dbEST(表达序列标签)数据库 (NCBI)•dbSTS - dbSTS(序列标签位点)数据库 (NCBI)•AsDb - 异常剪切数据库•ACUTS - DNA非转录保守序列数据库•密码子数据库•EPD - 真核生物启动子数据库•HOVERGEN - 颈椎动物同源基因数据库•IMGT - 免疫遗传学数据库 [镜像: EBI]•ISIS - 内含子序列信息•RDP - 核糖体数据库•gRNAs db - gRNA数据库•PLACE - 植物DNA顺势调控元件数据库•PlantCARE - 植物中DNA顺势调控组件数据库•ssu rRNA - 欧洲核糖体RNA数据库-小核糖体•lsu rRNA - 欧洲核糖体RNA数据库-大核糖体•5S rRNA - 5S核糖体RNA数据库•tmRNA Website - tmRNA站点•tmRDB - tmRNA数据库•tRNA - tRNA剪切( Bayreuth大学)•uRNA db•RNA editing - RNA剪切位点•RNAmod db - RNA修饰数据库•TelDB - 多介质端粒数据库•MPDB - 分子探针数据库•VectorDB - 载体序列数据库5、糖类•FCCA - 糖类论坛•GlycoSuiteDB - 多聚糖数据库•Monosacharide browser - Space filling Fischer projection for monosaccharides•Thorkild's lectin page - 凝集素通道6、特殊物种数据库:人类:•OMIM - 孟德尔遗传在线--人类•GENATLAS - 人类基因图集•GeneClinics - 医学基因学库•GDB - 基因组数据库•GeneCards - 人类基因整合信息数据库•UDB - 人类基因图谱数据库•Ensembl人类基因组浏览器•UCSC人类基因组工作草图•TIGR HGI - TIGR人类基因组索引•Hs UniGene - GenBank中的人类转录本•STACK - 序列标签比对• - 人类基因预测•GenLink - 人类基因组资源数据库•GeneLynx - 人类基因组•HUGE - 人类未知基因-大型蛋白质反转录得到的cDNA (KIAA...)•HUNT - 人类异常转录本•CGAP - 癌症基因组解剖学•MGC - 哺乳动物基因•SCDb - 干细胞数据库•Homophila - 人类疾病基因与果蝇基因对比数据库•Human Protein Atlas - 人类正常组织蛋白质与癌细胞蛋白质表达与位点的比较•Chr at Rutgers - Rutgers的人类染色体信息•Chr at Sanger - Sanger Center的人类染色体信息•Chr Swiss-Prot list - Swiss-Prot的染色体信息脊椎动物:•OMIA - 孟德尔遗传在线--动物•MGI - 小鼠基因组学信息 [镜像: Australia]•Ensembl小鼠基因组浏览器•TIGR MGI - TIGR小鼠基因索引•Mm UniGene - GenBank 中的小鼠转录本(EST clusters) •MGC - 哺乳动物基因•Mouse gene knockouts db - 小鼠基因敲除数据库•RGD - 大鼠基因组数据库•RatMAP - 大鼠基因组数据库•TIGR RGI - TIGR大鼠基因组数据库•Rn Unigene - GenBank 中的大鼠转录本(EST clusters) •BOVMAP - 牛基因数据库 (法国)•DGP - 狗基因数据库•MIS - 孟德尔遗传--羊•Ark-Cat - 猫基因组数据库•Ark-Chicken - 鸡基因组数据库•Ark-Cow - 奶牛基因组数据库•Ark-Deer - 鹿基因组数据库•Ark-Horse - 马基因组数据库•Ark-Pig - 猪基因组数据库•Ark-Sheep - 绵羊基因组数据库•Ark-Turkey - 火鸡基因组数据库•FishBase -鱼类综合信息系统•Fugu genome project - 河豚基因组•Fugu - HGMP 河豚数据•- Ensembl 河豚基因组浏览器•Medakafish - Mekada fish (Oryzias latipes) server •Ark-Tilapia - 罗飞鱼基因组数据库•Ark-Salmon - 大马哈鱼基因组数据库•The fish net - 斑马鱼基因组数据库•Ensembl斑马鱼基因组浏览器线粒体和叶绿体:•GOBASE - 细胞器基因组数据库•MitoDat - 孟德尔遗传和线粒体数据库• C.caldarium - 蓝藻纲PK1菌株叶绿体基因组昆虫•Drosophila Swiss-Prot list - Swiss-Prot中的果蝇链接•FlyBase - 果蝇遗传数据库和分子数据库•BDGP - Berkeley果蝇基因组项目•FlyView - 果蝇图像数据库•Homophila - 人类疾病与果蝇基因对照数据库•蚊子基因组学•AnoDB - 疟蚊数据库•Ensembl蚊子基因组浏览器7、人类突变数据库•HGMD - 人类基因突变数据库•SVD - EBI序列变异数据库•GeneDis - 人类遗传病数据库8、特殊基因和蛋白质数据库•Allergens in Swiss-Prot - Swiss-Prot中过敏反应的命名与索引•Allergome - 过敏症反应分子数据库•Aminoacyl-tRNA synthetases in Swiss-Prot - Swiss-Prot 中氨基化tRNA合成酶列表9、转录后修饰数据库•DSDBASE - 二硫化物数据库 (数据来源于三级结构数据库) •GlycoSuiteDB - 多聚糖结构数据库•LIPID MAPS - 脂类代谢及路径10、系统发生学数据库•COG - 全基因组中编码的蛋白质的系统发生学分类方法•EGO - 真核生物基因分类方法•InParanoid - 真核生物分类11、芯片数据库•ArrayExpress - EBI中芯片数据•ExpressDB - 酵母菌和大肠杆菌表达数据库•GeneX - 基因表达工程12、专利数据库•DPD - DNA专利数据库•Ag Patents - USDA收录的农业工艺专利•Esp@cenet - 欧洲专利事务所专利信息数据库 (世界范围内)13、参考文献(目录数据库)•PubMed Medline server - PubMed查询•AGRICOLA - NAL农业查询数据库•Article@INIST - 科技信息数据库•Korean Journals Abstract db - 韩国杂志摘要数据库•SeqAnalRef - 序列分析文献14、字典, 读物, 课程 ,命名法•BioABACUS - 缩写词•BioTech's life science dictionary生物科技及生命科学字典•DCB - 细胞生物学字典(Julian Dow编写)15、生物软件数据库及目录•CLC Free Workbench - 可在Linux, MacOS X and Windows操作系统上运行的,对DNA、RNA和蛋白质进行算法分析的软件•CLC Protein Workbench - 可在Linux, MacOS X and Windows 操作系统上运行的,对DNA、RNA和蛋白质进行算法分析的软件•BioCatalog - EBI的生物目录16、生命科学资源•Biofind - 生物科技工业信息、评论及新闻•Bioinformatik.de - 生物信息学网页目录17、生物杂志和发行人•生物杂志主页:Swiss-Prot journals list - Swiss-Prot杂志列表• - 电子出版物目录• - 电子期刊目录18、发行人•Allen Press, Inc. - Allen出版社•AMA - 美国医学联合出版物•ACS - 美国化工协会出版物19、生物信息学杂志和通讯•BioInformer - EBI通讯•NCBI Newsletter -NCBI通讯•PDB Quaterly Newsletter - PDB通讯20、基因组通讯•Human Genome Project Information - 人类基因组计划•FGN - 真菌遗传学•Rice Genome Newsletter - 水稻基因组21、其他•IJC - 化学杂志•Plant Gene Register - 植物基因注册22、生物商业杂志•BioCentury - 生物世纪•BioWorld Online - 生物世界•Drug Discovery and Development - 药物发现和发展•GEN - 基因工程新闻23、综合性科学杂志•Nature•New Scientist•La Recherche•Science•Scientific American24、生物学研究机构•APS - 美国缩氨酸社区•ASCB - 美国细胞生物学社区•ASHG - 美国人类遗传学社区25、计算生物学服务器主页欧洲:•EBI - 欧洲生物信息学协会•EMBnet - 欧洲分子生物信息学网•EMBL - EMBL计算生物学机构美国和加拿大:•NCBI - 美国生物学信息中心•ABCC - NCI高级生物医学计算中心•ACGT - Oklahoma大学基因组技术中心亚洲•APBioNet - 亚太生物信息网•BIC-JNU - Jawaharlal Nehru大学生物信息学中心•DIC - Pune (印度)大学生物信息澳洲•APBioNet - 亚太生物信息网•ANGIS - 澳大利亚国家遗传信息服务中心•ANU - 澳大利亚国大学生物信息学研究组•APAF - 澳大利亚蛋白质组分析工具26、其他•HUJI - 耶路撒冷Hebrew大学基因组学和生物信息学服务中心•Weizmann Bioinfo/BCU - Weizmann计算生物学和生物信息学研究协会•SANBI - 南非生物信息学研究协会27、生物公司和制药公司•美国药物研究和制造商目录•Bioportfolio - 生物技术企业•Affymetrix, Inc. - Affymetrix公司28、生物信息公司•Aborygen•Accelrys, Inc•AlgoNomics NV t29、其他链接其他医学查询•HON - 基于网络的健康服务• - 药物网络指南•MedWeb - 医学链接其他科学查询•GPSDB - 基因和蛋白质同义词数据库•Chemcyclopedia Online - 商业化学试剂数据库。
pfam数据库

PFAM数据库PFAM数据库是一个用于蛋白质序列家族分类的工具。
它基于蛋白质序列的共同结构和功能特征,将蛋白质序列分组成家族,从而帮助研究人员理解蛋白质的功能和进化过程。
本文将介绍PFAM数据库的基本概念、分类方法和应用情况。
1. PFAM数据库简介PFAM数据库是一个用于预测蛋白质结构和功能的数据库。
它采用蛋白质序列的保守特征,将相似的序列归类为同一个家族。
PFAM数据库包含了大量的蛋白质家族信息,可以帮助研究人员在蛋白质序列中发现潜在的功能和结构信息。
2. PFAM数据库的分类方法PFAM数据库主要基于蛋白质序列的保守结构域来进行分类。
它将蛋白质序列中相同或相似的结构域组合成家族,每个家族都包含了具有相似结构和功能的蛋白质。
PFAM数据库还提供了丰富的注释信息,帮助用户更好地理解每个家族的功能和特点。
3. PFAM数据库的应用情况PFAM数据库在生物信息学和分子生物学领域被广泛应用。
研究人员可以利用PFAM数据库来预测新发现的蛋白质的结构和功能,通过比对已知家族信息来推测未知蛋白质的特性。
此外,PFAM数据库还可以用于蛋白质序列的分类和进化分析,帮助研究人员揭示不同蛋白质家族之间的关系和进化过程。
4. 结语PFAM数据库作为一个用于蛋白质家族分类的重要工具,在生物信息学研究中扮演着重要的角色。
通过分析蛋白质序列的保守结构域,PFAM数据库可以帮助研究人员更好地理解蛋白质的功能和进化过程,为生物学研究提供了有力的支持。
希望本文介绍的内容能够帮助读者更深入地了解PFAM数据库及其在蛋白质研究中的应用。
(完整word版)生物信息学填空题(个人整理)

(完整word版)生物信息学填空题(个人整理)1、BLAST教案所程序中,哪个方法是不存在的?(D)A:BLASTP B:BLASTN C:BLASTX D:BLASTQ2、下列哪个软件不是常用来观察蛋白质结构视图的?(D)A:AVS B:Chimera C:MICE D:HMM3、下列哪个不是点突变的类型?(A)A:染色体畸变 B:错义突变 C:无义突变 D:移码突变4、基因突变的效应不包括:(C)A:有利突变 B:中性突变 C:移码突变D:遗传多态现象5、人类基因组的结构特点不包括:(A)A:基因进化 B:基因数目 C:基因重复序列 D:基因组复制6、世界上三大数据库不包括:(B)A:NCBI B:BLAST C:UCSC D:Ensembl7、常用序列比对方法错误的是:(C)A:编辑距离 B:点阵描图 C:局部比对 D:记分模式8、下列哪个不是蛋白质结构模型?(D)A:同源性模型B:折叠识别C:ab initio折叠D:MoLScript 结构9、下列哪个选项不是微阵列实验设计的内容?(A)A:贝叶斯网络法 B:对照组的选择 C:重复样本的使用 D:随机化原则10、构建序列进化树的一般步骤不包括:(A)A:建立DNA文库 B:建立数据模型 C:建立取代模型 D:建立进化树11、下列中属于一级蛋白质结构数据库的是:(C)A. EMBLB. DDBJC. PDBD.SWISS-PROT12.蛋白质结构预测分为:(B)A.一级和三级结构预测 B. 二级和空间结构预测C. 三级和空间结构预测D. 二级和三级结构预测13.数据挖掘的四个步骤不包括下列哪个:(C)A. 数据选择B. 数据转换C. 数据记录D. 结果分析14.下列哪项不是生物学研究必备的工具:(A)A.数据分析B.数据统计C.因素分析D.多元回归分析15.Linux中rmdir 命令的功能是:(D)A.改变工作目录 B.删除工作目录C. 创建目录D.删除空目录16.BLAST教案所程序中,哪个方法是不存在的?(D)A:BLASTP B:BLASTN C:BLASTX D:BLASTQ17.下列哪个不是蛋白质结构模型?(D)A:同源性模型B:折叠识别C:ab initio折叠D:MoLScript 结构18.人类基因组的结构特点不包括:(A)A:基因进化 B:基因数目 C:基因重复序列 D:基因组复制19、下列哪个选项不是微阵列实验设计的内容?(A)A:贝叶斯网络法 B:对照组的选择 C:重复样本的使用 D:随机化原则20、构建序列进化树的一般步骤不包括:(A)A:建立DNA文库 B:建立数据模型 C:建立取代模型 D:建立进化树三、填空题1、数据格式的建立、数据的准确性和质量控制、方便的数据搜寻方式以及数据的及时更新是数据库建立和维护中的重要问题。
生物信息学
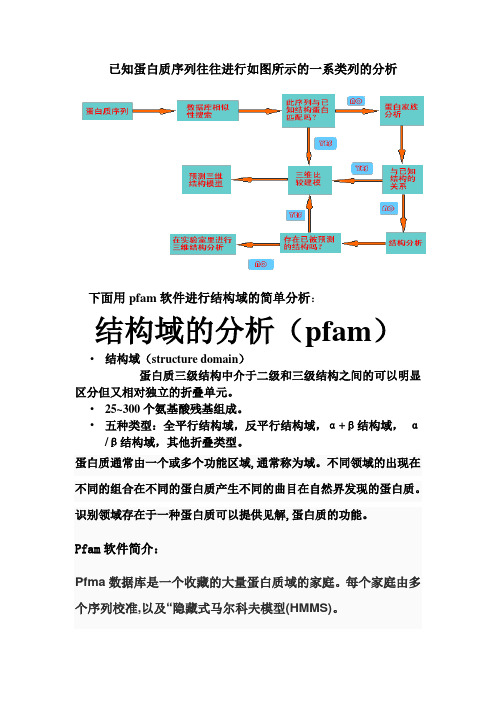
已知蛋白质序列往往进行如图所示的一系类列的分析下面用pfam软件进行结构域的简单分析:结构域的分析(pfam)•结构域(structure domain)蛋白质三级结构中介于二级和三级结构之间的可以明显区分但又相对独立的折叠单元。
•25~300个氨基酸残基组成。
•五种类型:全平行结构域,反平行结构域,α+β结构域,α/β结构域,其他折叠类型。
蛋白质通常由一个或多个功能区域,通常称为域。
不同领域的出现在不同的组合在不同的蛋白质产生不同的曲目在自然界发现的蛋白质。
识别领域存在于一种蛋白质可以提供见解,蛋白质的功能。
Pfam软件简介:Pfma数据库是一个收藏的大量蛋白质域的家庭。
每个家庭由多个序列校准,以及“隐藏式马尔科夫模型(HMMS)。
有两个等级的品质,pfam家庭:一个和Pfma b。
Pfma a条目包含了许多来自底层序列数据库,称为Pfam seq,这是由最近发布的UniProtKB在给定的时间点。
Pfam a家庭由许多一个策划种子含有少量的对齐代表家族成员,剖面隐马尔可夫模型(HMMS)由种子对齐和一个自动生成的全排列,其中包含所有蛋白质序列检测属于家庭定义为HMM搜索数据库的主序列。
Pfam b家庭联合国注释和低质量为他们从集群自动生成非冗余的最新加入释放。
尽管低的质量,pfam b家庭可以用于识别功能守恒的地区没有发现了pfam a一个条目。
•利用pafm进行蛋白质结构域及功能位点分析MSRQAWIETSALIECISEYGTKCSFDTFQGLTINDISTLSNLM NQISV ASVGFLNDPRTPLQAMSCEFVNFISTADRHAYMLQK NWFDSDV APNVTTDNFIATYIKPRFSRTVSDVLRQVNNFALQ PMENPKLISRQLGVLKAYDIPYSTPINPMDV ARSSANVVGNV SQRRALSTPLIQGAQNVTFIVSESDKIIFGTRSLNPIAPGNFQI NVPPWYSDLNVVDARIYFTNSFLGCTIQNVQVNA VNGNDPV ATITVPTDNNPFIVDSDSVVSLSLSGGAINVTTA VNLTGYAIAI EGKFNMQMNASPSYYTLSSLTIQTSVIDDFGLSAFLEPFRIR LRASGQTEIFSQSMNTLTENLIRQYMPANQA VNIAFVSPWY RFSERARTILTFNQPLLPFASRKLIIRHLWVIMSFIA VFGRYY TVNkeywor d seaSignificant Pfam-A Matches Show or hide all alignments.Description EntrytypeClanEnvelope AlignmentStart End Start Endefhand_like Phosphoinositide-specificphospholipase C, efhand-likeDomain C L0220 245 318 250 318PI-PLC-X Phosphatidylinositol-specificphospholipase C, X domainFamily CL0384 322 465 322 465SH2SH2 domain Domain n/a550 639 550 639 SH2SH2 domain Domain n/a668 741 668 741 SH3_1SH3 domain Domain C L0010 797 843 797 843PI-PLC-Y Phosphatidylinositol-specificphospholipase C, Y domainFamily CL0384 952 1070 952 1070C2C2 domain Domain C L01541090 1177 1092 1176 nsignificant Pfam-A Matches Show or hide all alignments.Family Description EntrytypeClanEnvelope Alignment HMMBiscoStart End Start End From ToPH PH domain Domain C L026634 142 40 139 8 101 24.nsignificant Pfam-A Matches Show or hide all alignments.EF_hand_4EF-handdomainDomain C L0220 156 192 157 183 2 28 10.PH PH domain Domain C L0266 489 575 490 533 2 38 13.PH PH domain Domain C L0266 842 931 873 929 44 102 16. Pfam-B Matches Show or hide all alignments.Pfam-B_12554n/a n/a n/a37 232 45 164#HMM kPKfcpfrLssDesaLiWyskkkeKr..lkLSsvsriiiGqrTavFery....lrpeke #MATCH +P f++ +++++W + + + + + + +i +G+ + F ry + + #PP 5777788888888*****9996555566*********************5443223468 #SEQ R PERKTFQVKLETRQITWSRG ADKIEga IDIREIKEIRPGKTSRDFDRY qedpAFRPD QComments or questions on the site? Send a mail to pfam-help@。
embl-ebi的发展史

embl-ebi的发展史EMBL-EBI(欧洲生物信息研究所)是欧洲分子生物学实验室(EMBL)旗下的一个研究机构,致力于生物信息学和计算生物学的研究与发展。
自从其成立以来,EMBL-EBI在生物信息学领域取得了巨大的成就,为全球的生命科学研究和医学进步做出了重要贡献。
EMBL-EBI的发展可以追溯到1980年代,当时生物学家和计算机科学家开始意识到,随着生物学研究的不断进展,大量的生物学数据需要进行存储、管理和分析。
为了满足这一需求,EMBL-EBI应运而生。
成立之初,EMBL-EBI的主要任务是建立一个集中存储和管理生物学数据的数据库。
这个数据库不仅包括基因序列和蛋白质序列,还包括生物学实验数据、三维结构数据以及生物学文献等。
随着时间的推移,EMBL-EBI逐渐壮大并发展出了一系列重要的数据库和工具。
其中最著名的数据库之一是欧洲核酸数据库(ENA),它是全球最大的基因和核酸序列数据库之一。
ENA不仅存储了大量的基因和核酸序列数据,还提供了一系列的分析工具和服务,帮助科学家们进行基因和核酸序列的比对、注释和分析。
另一个重要的数据库是蛋白质家族数据库(Pfam),它收集了全球范围内的蛋白质家族信息,并为科学家们提供了一套丰富的工具和资源,用于研究蛋白质结构、功能和进化。
此外,EMBL-EBI还开发了一系列其他的数据库和工具,包括基因组数据库、代谢组学数据库、系统生物学数据库等,为科学家们提供了丰富的数据资源和分析工具,促进了生命科学研究的进展。
除了数据库和工具的开发,EMBL-EBI还致力于推动生物信息学和计算生物学的研究和教育。
该机构定期举办各种培训课程和研讨会,吸引了大量的国际学者和研究人员参与其中。
此外,EMBL-EBI还与其他研究机构和学术机构合作,开展各种合作研究项目,推动生物信息学的发展和应用。
近年来,随着技术的不断进步和生物学研究的深入,生物信息学和计算生物学的重要性越来越凸显。
EMBL-EBI作为全球领先的生物信息学研究机构之一,继续致力于推动生物信息学的研究和应用。
生物信息学中的基因注释和功能预测

生物信息学中的基因注释和功能预测生物信息学是生物学、计算机科学和统计学的交叉学科。
它应用计算机技术和数学统计工具,对生物系统中的大量数据进行分析和解释。
其中,基因注释和基因功能预测是生物信息学中的重要内容。
一、基因注释基因注释是指对基因组序列中的基因和非编码区域进行描述和解释的过程。
它能够为生物学研究提供重要的基础数据,如基因定位、基因识别、组合规律的发现等。
基因注释的方法可以分为结构注释和功能注释两类。
结构注释是指通过一些基本的生物信息学算法,如基于比对的方法、基于RNA-Seq的方法等,对基因组序列中的基因和非编码区域进行基本结构的预测和揭示。
功能注释是指通过一些软件工具,如Gene Ontology、KEGG、Reactome等,对基因组序列中的基因和非编码区域进行其功能的预测和解释。
结构注释和功能注释是互补的、相辅相成的。
在结构注释方面,目前比较常用的方法包括基于比对的注释和基于RNA-Seq的注释。
基于比对的注释是指将已知的基因组序列(参考基因组)与待注释的基因组序列进行比对,从而推断出待注释基因组序列的基因位置和结构信息。
基于RNA-Seq的注释是指利用高通量测序技术获得一系列RNA序列,从而推断出待注释基因组序列中未知的基因位置和结构信息。
相对而言,基于RNA-Seq的注释有更高的精度和灵敏度。
在功能注释方面,目前比较流行的软件工具包括Gene Ontology、KEGG和Reactome等。
Gene Ontology(GO)是一个标准化的基因功能分类体系,它将基因功能分为“细胞组成”、“生物过程”和“分子功能”三个方面进行描述。
KEGG是一个关于代谢通路、信号通路和疾病等相关信息的数据库,它为非模式生物基因组注释提供了重要的信息来源。
Reactome是一个针对代谢和信号通路的数据库,它能够对基因序列进行功能注释和生物过程解释。
二、基因功能预测基因功能预测是指对未知功能基因进行预测和解释的过程。
蛋白质组学研究中常用的网站和数据库

蛋白质组学研究中常用的网站和数据库蛋白质, 数据库, 研究本帖引用网址:/thread-35586-1-1.html一、蛋白质数据库1.UniProt (The Universal Protein Resource) 网址://uniprot/简介:由EBI(欧洲生物信息研究所)、PIR(蛋白信息资源)和SIB(瑞士生物信息研究所)合作建立而成,提供详细的蛋白质序列、功能信息,如蛋白质功能描述、结构域结构、转录后修饰、修饰位点、变异度、二级结构、三级结构等,同时提供其他数据库,包括序列数据库、三维结构数据库、2-D凝聚电泳数据库、蛋白质家族数据库的相应链接。
2.PIR(Protein Information Resource) 网址:/简介:致力于提供及时的、高质量、最广泛的注释,其下的数据库有iProClass、PIRSF、PIR-PSD、PIR-NREF、UniPort,与90多个生物数据库(蛋白家族、蛋白质功能、蛋白质网络、蛋白质互作、基因组等数据库)存在着交叉应用。
3.BRENDA(enzyme database) 网址:简介:酶数据库,提供酶的分类、命名法、生化反应、专一性、结构、细胞定位、提取方法、文献、应用与改造及相关疾病的数据。
4.CORUM(collection of experimentally verifiedmammalian protein complexes) 网址:http://mips.gsf.de/genre/proj/corum/index.html简介:哺乳动物蛋白复合物数据库,提供的数据包括蛋白复合物名称、亚基、功能、相关文献等5.CyBase(cyclic protein database) 网址:.au/cybase简介:环状蛋白数据库,提供环状蛋白的序列、结构等数据,提供环化蛋白预测服务。
6.DB-PABP 网址:/DB_PABP/简介:聚阴离子结合蛋白数据库。
生物信息学填空题

填空题:1、蛋白质结构数据来源:①实验测定方法: X-ray 、 NMR 、Cryo-EM ②理论预测:同源建模、折叠识别、从头计算2、一级数据库:①一级核酸数据库:Genbank(美国)、EMBL (欧洲)、DDBJ(日本) NCBI②一级蛋白质序列数据库:SWISS-PORT 、PIR 、 NCBI③一级蛋白质结构数据库:PDB、 pfam 、 prosite大分子序列格式:fasta数据库基本文件格式:genbank蛋白质分类数据库:SCOP、CATH 、 FSSP二次数据库: GDB 、 Prosite、 TRANSFAC3、本地软件: Clustal-x 、 BioEdit 、 Mega、 sequencher、 spdbv、 Discovery-studio4、本课程主要理论依据:相似性、同源性、序列比对(3D结构比对)、数学方法、分子动力、分子力学5、基因鉴定三步骤:①找到序列中的非编码区(低复杂度区)②找基因③鉴定找到的基因6、主要的生物大分子数据:①DNA:基因组序列、基因序列、cDNA、EST、碱基修饰DNA 功能模块 /位点(如启动子、剪接体、表达调控位点等)②蛋白质:氨基酸组成、氨基酸序列、理化性质、原子坐标;二级结构、核体、结构域、功能域 /位点; 3D 结构常见的生物信息数据记录格式:FASTA 、GenBank、EMBL、 PDBFASTA 格式:序列文件的第一行由大于符号>大头的任意文字说明,主要为标记序列用。
从第二行开始是序列本身,标准核苷酸符号或氨基酸单字母符号,通过核苷酸符号大小写均可,而氨基酸一般用大写字母。
文件中和每一行都不要超过80 个字符(通常60 个字符)GenBank格式:序列名称、长度。
日期;序列说明、编号、版本号;物种来源、学名、分类60学位置;相关文献作者、题目、刊物、日期;序列特征表;碱基组成;序列本身(每行个)二 .填空题1.常用的三种序列格式: NBRF/PIR,FASTA 和 GDE2.初级序列数据库: GenBank, EMBL 和 DDBJ3.蛋白质序列数据库: SWISS-PROT 和 TrEMBLPIR (蛋白4. 提供蛋白质功能注释信息的数据库:KEGG (京都基因和基因组百科全书)和质信息资源) 5. 目前由 NCBI 维护的大型文献资源是PubMed6.数据库常用的数据检索工具: Entrez, SRS, DBGET7.常用的序列搜索方法: FASTA 和 BLAST8.高分值局部联配的 BLAST 参数是 HSPs(高分值片段对), E(期望值) 9. 多序列联配的常用软件: Clustal10.蛋白质结构域家族的数据库有:Pfam, SMART11. 系统发育学的研究方法有:表现型分类法,遗传分类法和进化分类法12. 系统发育树的构建方法:距离矩阵法,最大简约法和最大似然法13. 常用系统发育分析软件:PHYLIP 14.检测系统发育树可靠性的技术: bootstrapping 和 Jack-knifing 15. 原核生物和真核生物基因组中的注释所涉及的问题是不同的16. 检测原核生物ORF 的程序: NCBI ORF finder17. 测试基因预测程序正确预测基因的能力的项目是GASP(基因预测评估项目)18.二级结构的三种状态:α螺旋,β折叠和β转角19.用于蛋白质二级结构预测的基本神经网络模型为三层的前馈网络,包括输入层,隐含层和输出层20.通过比较建模预测蛋白质结构的软件有SWISS-PDBVIEWER ( SWISS — MODEL 网站) 21. 蛋白质质谱数据搜索工具:SEQUEST 22. 分子途径最广泛数据库:KEGG23. 聚类分析方法,分为有监督学习方法,无监督学习方法24. 质谱的两个数据库搜索工具:1、 SEQEST 和 Lutkefi 三大数据库:核酸序列数据库、蛋白质序列数据库、结构数据库世界三大核酸序列数据库:GenBank、 EMBL-Bank 、 DDBJ蛋白质序列数据库:Swiss-Prot、 TrEMBL 、UniProt蛋白质结构数据库:PDB 、SCOP、CATH2、 GenBank 文献、提供了提供的服务:提供了EntrezBLAST 序列类似性检索。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
蛋白质家族数据库 Pfam
蛋白质家族数据库(Pfam)是蛋白质家族的集合,每个蛋白质家族由多序列比对和隐马尔科夫模型描述文件表示。
Pfam是在1995年由Erik Sonnhammer,Sean Eddy和Richard Durbin建立起来的,最初的目的是为了收集常见蛋白结构域,这些结构域可用于注释多细胞动物的复合蛋白质。
他们工作的灵感来自于Cyrus Chothia的预测:世界上存在1500个左右不同的蛋白质家族,大部分的蛋白质来自于不超过1000个蛋白质家族。
所以Pfam的科学意义在于完整和精确地分类蛋白家族和结构域。
直至2013年11月4日,Pfam已经发布了27.0,其中包含了14831个人工管理的条目,覆盖了UniProtKB将近80%的序列信息。
在Pfam中,蛋白质家族被分为质量高低的两类:Pfam-A和Pfam-B。
Pfam-A是高质量的、人工管理的蛋白质家族。
其中的条目来自于Pfamseq(Pfam的序列数据库),这个数据库的建立基于最新发布的UniProtKB。
每个Pfam-A家族由种子的比对(包含家族中一小部分具有代表性的序列),来自种子的序列比对的隐马尔科夫模型(HMMs)的描述以及一个自动生成的全局比对(包含家族中所有可以找到的蛋白序列,找到哪些蛋白序列由搜索序列数据库得到的HMM描述决定)。
Pfam-B是未经注释的、从最新发布的ADDA中非冗余聚类中自动生成的低质量蛋白质家族。
ADDA(Automatic Domain Decomposition Algorithm)是一个用于对所有蛋白质结构域家族进行结构域分解和聚类的自动算法,专门用于建立Pfam-B家族。
虽然Pfam-B的质量很差,但是在找功能保守性区域且在Pfam-A 中找不到结果的时候,Pfam-B家族就显得非常有用了。
Pfam的条目用四种方式进行分类,家族(相关蛋白区域的集合)、结构域(一个结构单元)、重复(单独存在不稳定但是多次出现能形成稳定结构的短的单元)和模体(在球形域以外的短单元)。
相关的Pfam条目会被合并成一族(clan),这种关系由序列相关性、结构或HMM描述决定。
family页面是在Pfam上获取信息的主要页面,它描述了Pfam每个条目的信息。
在这个页面上用户可以直接链接到其他有用的界面上,网站的组织结构如下图所示。
网站开发了几种非常强大的搜索功能:首先是“Jump to”搜索。
用户可以在搜索框中输入Pfam-A、B的登记号或标示符、UniProt序列的ID或登记号、NCBI的“GI”号或第二登记号、metaseq的ID或登记号、PDB的条目、蛋白质组物种名称等来搜索需要的蛋白家族。
其次是关键字搜索,这个搜索框出现在Pfam每个页面的右上角。
用于搜索Pfam-A家族,可以输入家族描述、UniProt的序列描述、PDB条目中的标题等、GO的ID和条目以及InterPro的摘要。
其次是找蛋白序列,如果要查的蛋白已经存在于UniProt、NCBI Genpept或metagenomic序列集,这个蛋白序列的结构域的情况已经在数据库中计算好了,只要输入序列的ID就可以查到。
如果序列不存在与数据库中,可以进行单序列搜索或批量搜索。
用户也可以用结构域查询工具来检索具有特定结构域组合的蛋白质。
更细节的研究可以用PfamAlyzer。